web search jan pedersen chief scientist, search and marketplace yahoo! inc
TRANSCRIPT

Web Search
Jan Pedersen
Chief Scientist, Search and MarketplaceYahoo! Inc.

Agenda
• A Short History
• Internet Search Fundamentals– Web Pages– Indexing
• Ranking and Evaluation
• Third Generation Technologies

A Short History

Precursors
• Information Retrieval (IR) Systems– online catalogs, and News
• Limited scale, homogeneous text
– recall focus– empirical
• Driven by results on evaluation collections
– free text queries shown to win over Boolean
• Specialized Internet access– Gopher, Wais, Archie
• FTP archives and special databases• Never achieved critical mass

First Generation Systems
• 1993: Mosaic opens the WWW– 1993 Architext/Excite (Stanford/Kleiner Perkins)– 1994 Webcrawler (full text Indexing)– 1994 Yahoo! (human edited Directory)– 1994 Lycos (400K indexed pages)– 1994 Infoseek (subscription service)
• Power systems– 1994 AltaVista (Dec Labs, advanced query syntax,
large index)– 1996 Inktomi (massively distributed solution)

Second Generation Systems
• Relevance matters– 1998 Direct Hit (clickthrough based re-ranking)– 1998 Google (link authority based re-ranking)
• Size matters– 1999 FAST/AllTheWeb (scalable architecture)
• The user matters– 1996 Ask Jeeves (question answering)
• Money matters– 1997 Goto/Overture (pay-for-performance search)

Third Generation Systems
• Market consolidation– 2002 Yahoo! Purchases Inktomi– 2003 Overture purchases AV and FAST/AllTheWeb– 2003 MSN announces intention to build a Search Engine– 2004 Google IPO
• Search matures– $2B market projected to grow to $6B by 2005– required capital investment limits new players
• Gigablast?
– traffic focused in a few sites• Yahoo!, MSN, Google, AOL
– consumer use driven by Brand marketing

Web Search Fundamentals
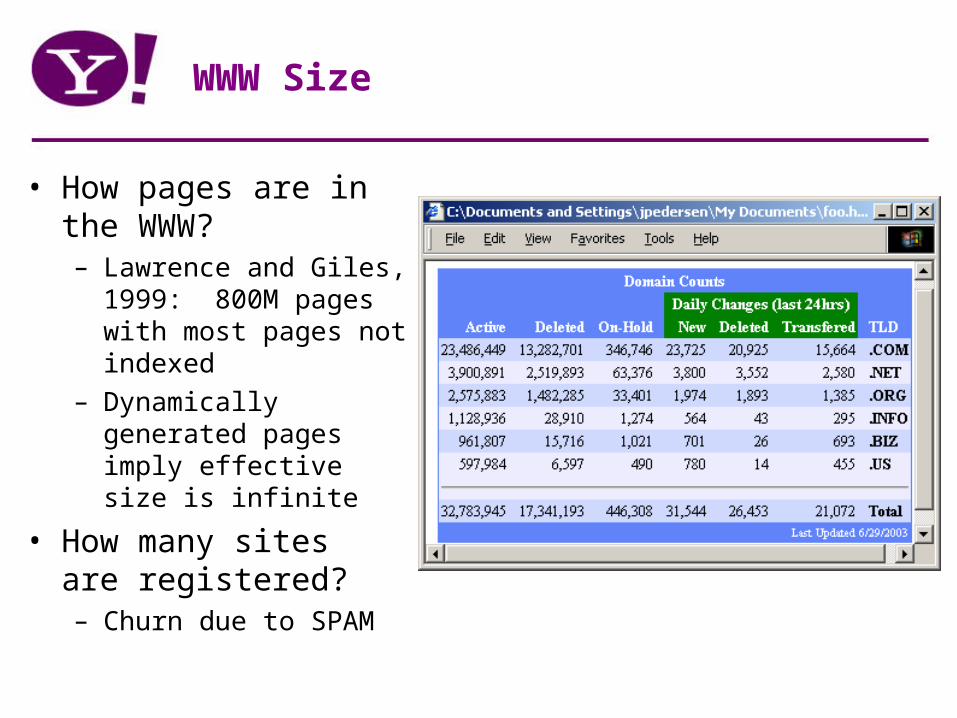
WWW Size
• How pages are in the WWW?– Lawrence and Giles,
1999: 800M pages with most pages not indexed
– Dynamically generated pages imply effective size is infinite
• How many sites are registered?– Churn due to SPAM
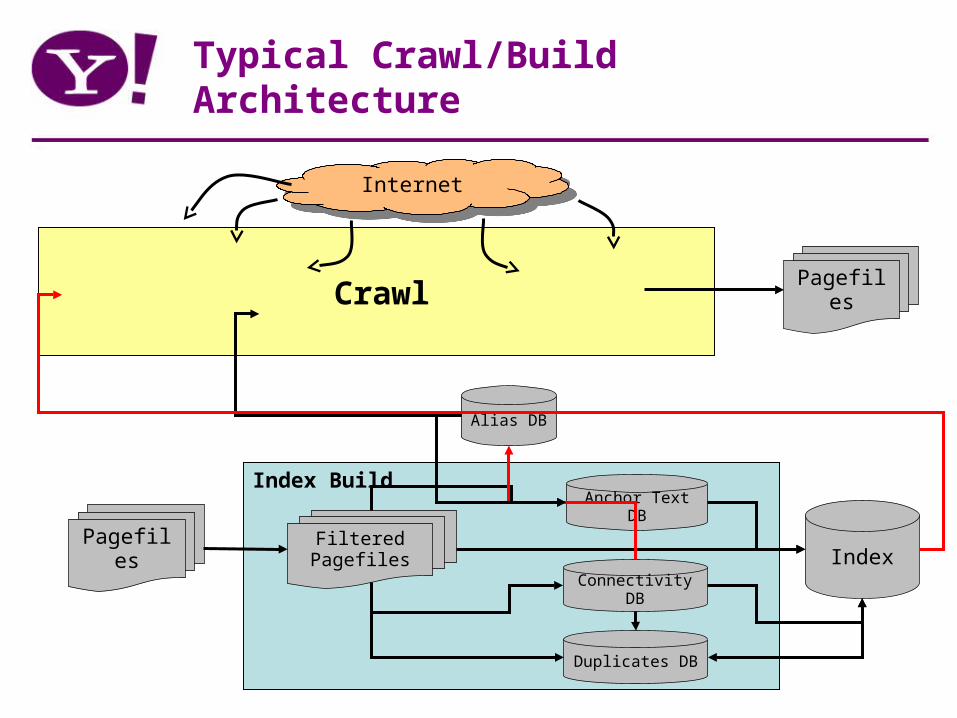
Typical Crawl/Build Architecture
Grab
URL DBSeed List
Discovery
InternetInternet
Pagefiles
Filtered Pagefiles IndexPagefiles
Anchor Text DB
Connectivity DB
Duplicates DB
Alias DB
Index Build
Crawl
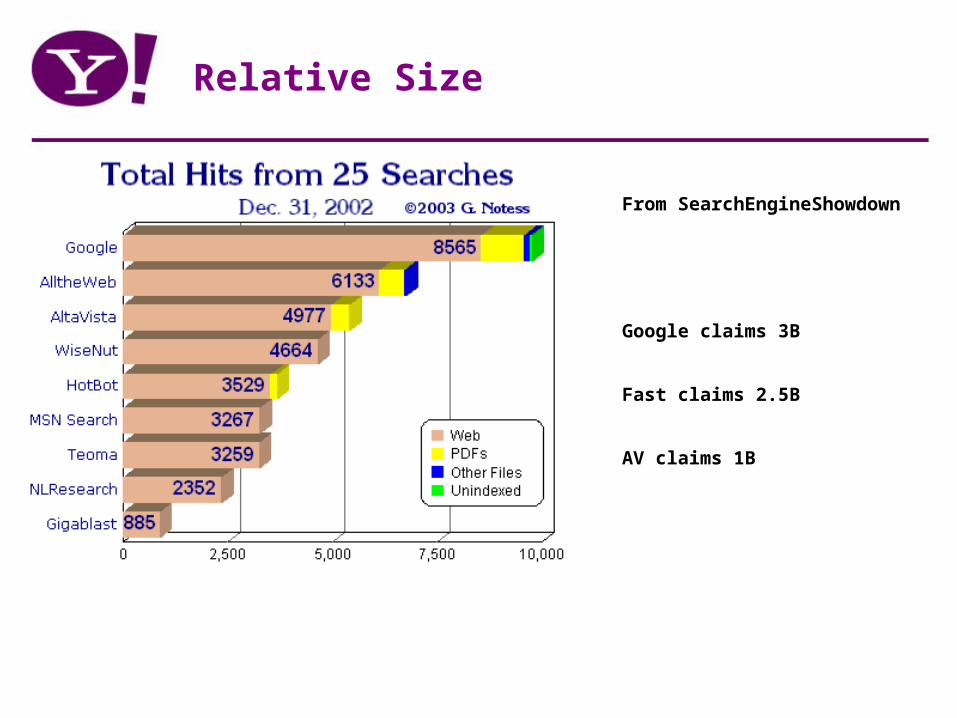
Relative Size
From SearchEngineShowdown
Google claims 3B
Fast claims 2.5B
AV claims 1B

Freshness
From
Search Engine Showdown
Note hybrid indices; subindices
with differing update rates

Query Serving Architecture
• Index divided into segments each served by a node
• Each row of nodes replicated for query load
• Query integrator distributes query and merges results
• Front end creates a HTML page with the query results
Load Balancer
FE1
QI1
Node1,1 Node1,2 Node1,3 Node1,N
Node2,1 Node2,2 Node2,3 Node2,N
Node4,1 Node4,2 Node4,3 Node4,N
Node3,1 Node3,2 Node3,3 Node3,N
QI2 QI8
FE2 FE8
“travel”
“travel”
“travel”
“travel”
“travel”
…
…
…………
…
…
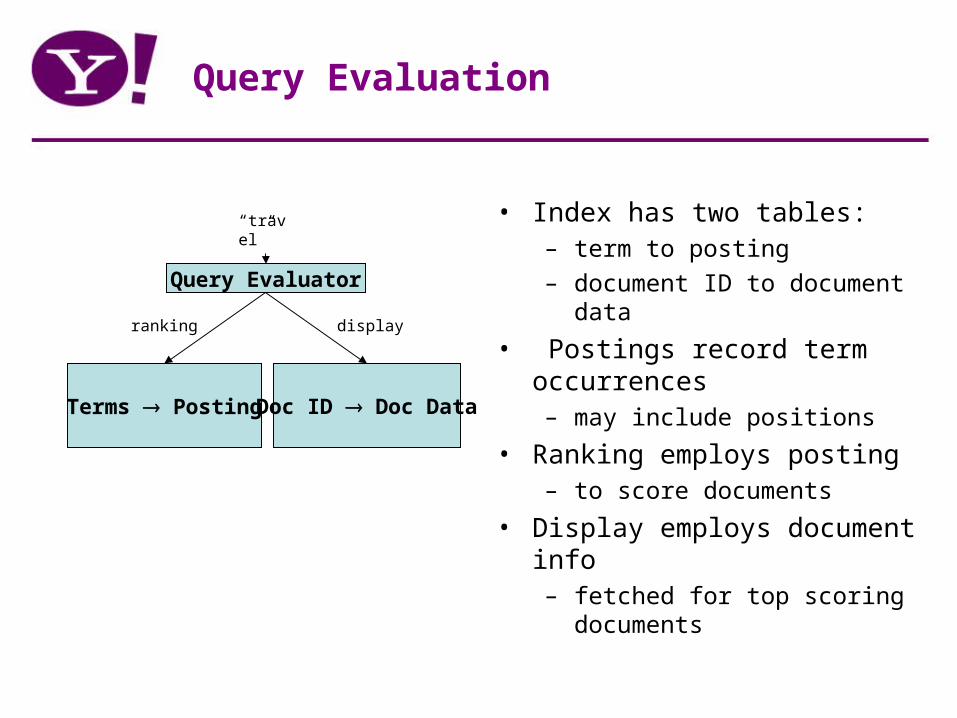
Query Evaluation
• Index has two tables: – term to posting
– document ID to document data
• Postings record term occurrences– may include positions
• Ranking employs posting– to score documents
• Display employs document info– fetched for top scoring documents
Terms Posting Doc ID Doc Data
Query Evaluator
“travel”
ranking display

Scale
• Indices typically cover billions of pages– terrabytes of data
• Tens of millions of queries served every day– translates to hundreds of queries per second
• User require rapid response– query must be evaluated in under 300 msecs
• Data Centers typically employ thousands of machines– Individual component failures are common

Search Results Page
• Blended results– multiple sources
• Relevance ranked• Assisted search
– Spell correction
• Specialized indices– via Tabs
• Sponsored listing– monetization
• Localization– Country language
experience

Relevance Evaluation

Relevance is Everything
• The Search Paradigm: 2.4 words, a few clicks, and you’re done
– only possible if results are very relevant
• Relevance is ‘speed’– time from task initiation to resolution– important factors:
• Location of useful result• UI Clutter• latency
• Relevance is relative– context dependent
• e.g. ‘football’ in the UK vs the US
– task dependent• e.g. ‘mafia’ when shopping vs researching

Relevance is Hard to Measure
• Poorly defined, subjective notion– depends on task, user context, etc.
• Analysts have Focused on Easier-to-Measure Surrogates– index size, traffic, speed– anecdotal relevance tests
• e.g. Vanity queries
• Requires Survey Methodology– averaged over queries– averaged over users

Survey Methodologies
• Internal expert assessments– assessments typically not replicated– models absolute notion of relevance
• External consumer assessments– assessments heavily replicated– models statistical notion of relevance
• A/B surveys– compare whole result sets– visual relevance plays a large role
• Url surveys– judge relevance of particular url for query

Ranking
• Given 2.4 query terms, search 2B documents and return 10 highly relevant in 300 msecs– Problem queries:
• Travel (matches 32M documents)• John Ellis (which one)• Cobra (medical or animal)
• Query types– Navigational (known item retrieval)– Informational
• Ingredients– Keyword match (title, abstract, body)– Anchor Text (referring text)– Quality (link connectivity)– User Feedback (clickrate analysis)

The Components of Relevance
• First Generation:– Keyword matching
• Title and abstract worth more
• Second Generation:– Computed document authority
• Based on link analysis
– Anchor text matching• Webmaster voting
• Development Cycle:Tune Ranking
Evaluate Metrics

SPAM
• Manipulation of content purely to influence ranking– Dictionary SPAM– Link sharing– Domain hi-jacking– Link farms
• Robotic use of search results– Meta-search engines– Search Engine optimizers– Fraud

Third Generation Technologies
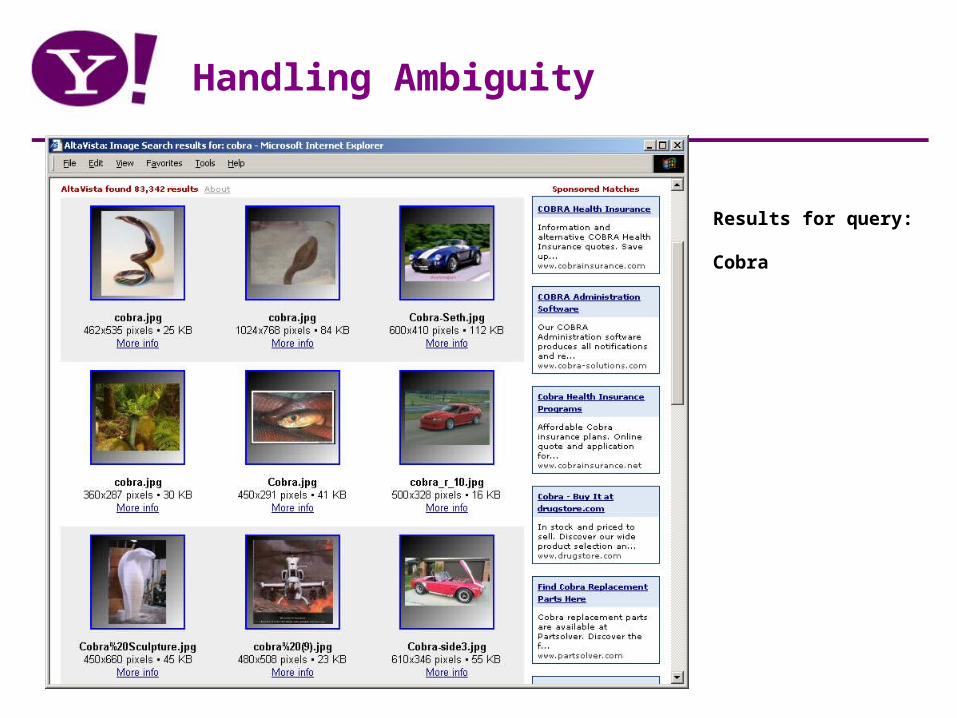
Handling Ambiguity
Results for query: Cobra

Impression Tracking
Incoherent urls are those that receive high rank for a large
diversity of queries. Many incoherent urls indicate SPAM or a
bug (as in this case).

Clickrate Relevance Metric
Average highest rank clicked perceptibly increased with the release of
a new rank function.

User Interface
• Ranked result lists– Document summaries are critical
• Hit highlighting• Dynamic abstracts• url
– No recent innovation• Graphical presentations not well fit to the task
• Blending– Predefined segmentation
• e.g. Paid listing
– Intermixed with results from other sources• e.g. News

Future Trends
• Question Answering– WWW as language model
• Enables simple methods
• e.g. Dumais et al. (SIGIR 2002)
• New contexts– Ubiquitous Searching
• Toolbars, desktop, phone
– Implicit Searching• Computed links
• New Tasks– E.g. Local/ Country Search

Bibliography
• Modeling the Internet and the Web: Probabilistic Methods and Algorithmsby Pierre Baldi, Paolo Frasconi, and Padhraic SmythJohn Wiley & Sons; May 28, 2003
• Mining the Web: Analysis of Hypertext and Semi Structured Databy Soumen ChakrabartiMorgan Kaufmann; August 15, 2002
• The Anatomy of a Large-scale Hypertextual Web Search Engine by S. Brin and L. Page.7th International WWW Conference, Brisbane, Australia; April 1998.
• Websites:– http://www.searchenginewatch.com/– http://www.searchengineshowdown.com/
• Presentations– http://infonortics.com/searchengines/sh03/slides/evans.pdf