workload characterization and performance for a network
TRANSCRIPT

Workload Characterization and Performance for a Network Processor
Mitsuhiro MiyazakiPrinceton Architecture Laboratory for
Multimedia and Security (PALMS)May. 16. 2002

Objectives
n To evaluate a NP from the computer architect’s point of view, rather than the network infrastructure point of view
n To understand hardware multithreading effect for NPs
n To guide the architectural design of future NPs

Outline
n Router Processing Characterizationn Workload Characterizationn Intel’s IXP1200 Architecturen Simulation Setupn IXP1200 Evaluation
n Instruction Mixn Latencyn Executing, Aborted, Stalled and Idle ration CPIn Throughput
n Other NPsn Conclusion and Future work

Router Processing Characterization
Input Port
IS
FW
FWQA
FW
OS
FIB
FIB
FIB
CF
LB
TQB
TQB
TQB
RPB
RPB
RPB
Output Port
FL
PacketDiscard
RFIFOTFIFO
InputScheduler
Classifier&
FilterForwarder Queuing
Assignment
OutputScheduler
&Load
balancing
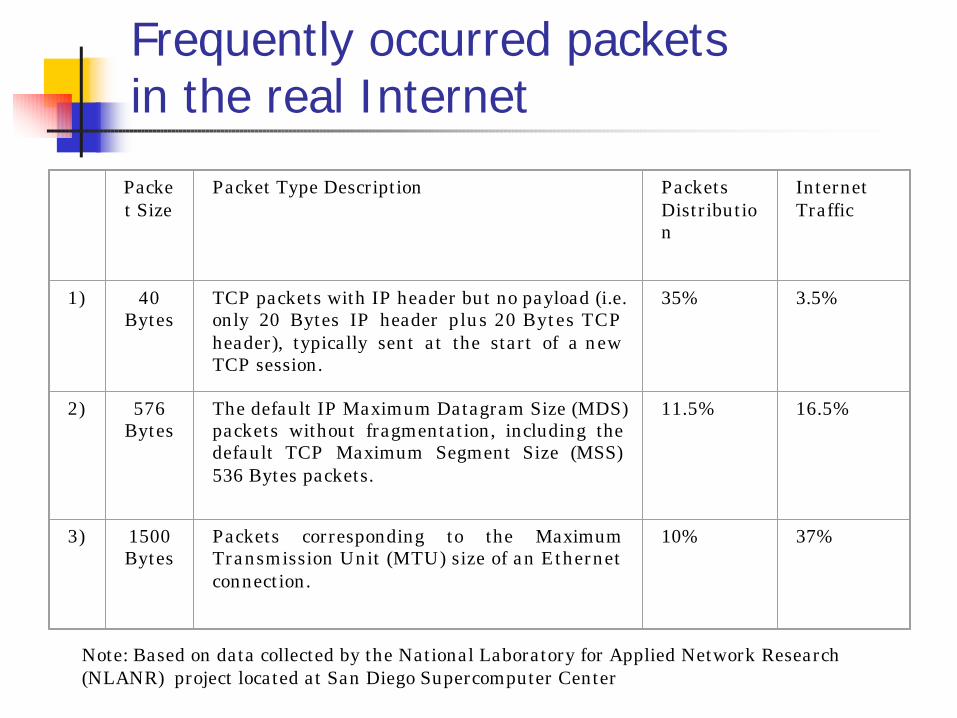
Frequently occurred packets in the real Internet
Packet Size
Packet Type Description Packets Distribution
Internet Traffic
1) 40 Bytes
TCP packets with IP header but no payload (i.e. only 20 Bytes IP header plus 20 Bytes TCP header), typically sent at the start of a new TCP session.
35% 3.5%
2) 576 Bytes
The default IP Maximum Datagram Size (MDS) packets without fragmentation, including the default TCP Maximum Segment Size (MSS) 536 Bytes packets.
11.5% 16.5%
3) 1500 Bytes
Packets corresponding to the Maximum Transmission Unit (MTU) size of an Ethernet connection.
10% 37%
Note: Based on data collected by the National Laboratory for Applied Network Research (NLANR) project located at San Diego Supercomputer Center

Workloads of fixed size packets
Packet Size
Packet Type Description
1) 64 Bytes The minimum-size Ethernet packets, consisting of 14 Bytes Ethernet header, 20 Bytes IP header, 26 Bytes Payload, and 4 Bytes Ethernet trailer (FCS), and being expected to be used for TCP handshake
2) 594 Bytes Ethernet packets including 14 Bytes Ethernet header, 20 Bytes IP header, 556 Bytes Payload (assuming 20 Bytes TCP header plus 536 Bytes MSS), and 4 Bytes Ethernet trailer (FCS)
3) 1518 Bytes
The maximum-size Ethernet packets, consisting of 14 Bytes Ethernet header, 20 Bytes IP header, 1480 Bytes Payload and 4 Bytes Ethernet trailer (FCS)
Note: Workloads use Ethernet packets because the simulation assumes a router with 16x100Mbps Ethernet ports
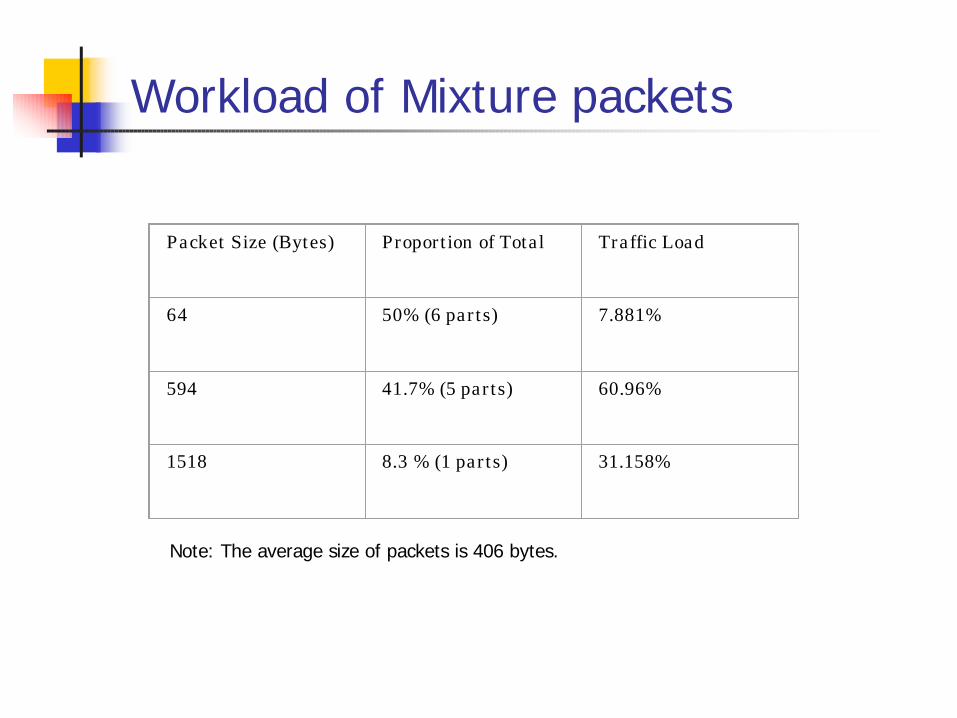
Workload of Mixture packets
Packet Size (Bytes) Proportion of Total Traffic Load
64 50% (6 parts) 7.881%
594 41.7% (5 parts) 60.96%
1518 8.3 % (1 parts) 31.158%
Note: The average size of packets is 406 bytes.
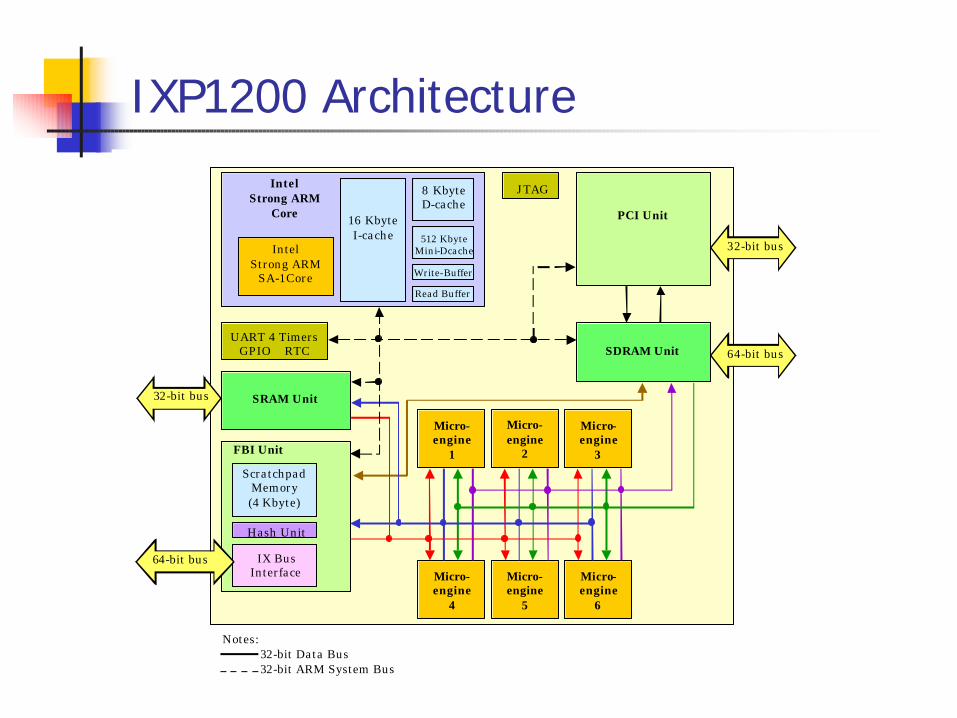
IXP1200 Architecture
IntelStrong ARM
Core 16 KbyteI-cache
8 KbyteD-cache
512 KbyteMini-Dcache
Write-Buffer
Read Buffer
JTAG
PCI Unit
32-bit bus
UART 4 TimersGPIO RTC
SRAM Unit32-bit bus
SDRAM Unit
FBI Unit
ScratchpadMemory(4 Kbyte)
64-bit bus
Micro-engine
1
Micro-engine
2
Micro-engine
3
Micro-engine
4
Micro-engine
5
Micro-engine
6
64-bit bus
Notes: 32-bit Data Bus32-bit ARM System Bus
IX BusInterface
Hash Unit
IntelStrong ARM
SA-1Core

Microengine Pipelining
Note: Context switching can be made by 4PCs, 128GPRs, 64SDRAM Xfer regs , 64 SRAM Xfer regs and other CSRs

Hardwre Multi-Threading
n Multithreading keeps Microengine execution pipeline active without numerous stalled cycles
Thread0
Thread1
Thread2
Thread3
Thread stalled*
Thread stalled*
Thread stalled*
Thread stalled**Note: Threads stalled are caused by memory access

Memory Access Flow

Branch and Context switch Instructions
Class 3 Class2 Class1
br_bclr and br_bset br=0 br sdram
br=byte and br!=byte br!=0 br=ctx sram
jump br>0 br!=ctx hash1_48
rtn br>=0 ctx_arb hash2_48
br_!signal br<0 csr hash3_48
br_inp_state br<=0 r_fifo_rd hash1_64
br=cout t_fifo_wr hash2_64
br!=cout scratch hash3_64
Note: Blue colored instructions indicate context switch instructions.

Branch pipeline examplewith Class 3 Instruction

Branch pipeline examplewith Class 2 Instruction
Case 2
Case 1

Branch/Context switch pipeline example with Class 1 Instruction

Solutions for branch penalties
n Deferred branch instructionn Guess branch instructionn Condition Code set earlier

Deferred branch Instruction

Guess Branch Instruction

Combination of Guess and Deferred Branch

Simulation Setup
n Workbench – GUI interface to all Microengine toolsn Microcode assemblern Microcode linkern Transactor – Debug and Simulation engine with
IXP1200 Architectural Model and Memoryn The verilog model of an IX bus device(i.e. MAC
device) n Reference program(L2L3fwd16)

Simulation Image
MACIXF4408 ports
MACIXF4408 ports
SixMicro
engines
IX Bus
32bit
FBIUnit
32bit
SRAMUnit
SDRAMUnit
SDRAM
SRAM
IXP1200
100Mbps(Full Duplex)x 16 ports

Thread assignment & Sim Conditions
n Receive threads are assigned to Microengine 0-3n Transmit threads are assigned to Microengine 4-5n One thread per Microengine works as output
scheduler in Microengine 4-5n Operation Frequency
n Microengine runs at 232MHzn The IX bus transfers packets at 104MHzn SRAM and SDRAM bus transfer data at 116MHz
n The simulation had to forward 3000 packets

Instruction Mix for Receive Processing
40.8%
32.5%
30.3%
31.9%
28.0%
37.8%
40.8%
39.8%
16.6%
14.2%
7.6%
5.8%
5.3%
5.6%10.0%
7.2%
7.3%15.2%
16.4%
6.9%
0% 20% 40% 60% 80% 100%
64B
594B
1518B
Mixture
Pac
ket
Typ
es
Instruction Ratio
Arithmetic,Rotate, andShift InstructionsBranch and JumpInstructionsReference Instructions
Local RegisterInstructionsMiscellaneousInstructions

Instruction Mix for Transmit Processing
48.2%
51.3%
50.9%
50.7%
30.7%
30.7%
31.1%
31.0%
10.6%
8.2%
8.5%
8.5%
8.2%
8.6%
8.6%
8.7%
2.4%
1.2%
0.9%
1.1%
0% 20% 40% 60% 80% 100%
64B
594B
1518B
Mixture
Pac
ket
Typ
es
Instruction Ratio
Arithmetic,Rotate, andShift InstructionsBranch and JumpInstructionsReference Instructions
Local RegisterInstructionsMiscellaneousInstructions

Instruction Mix for Overall Processing
43.4%
39.8%
38.4%
39.2%
29.0%
35.1%
37.0%
8.6%11.7%
12.0%
13.4%
12.7%36.4%
6.5%
6.9%
6.6%
4.9%
4.7%
6.6%
7.4%
0% 20% 40% 60% 80% 100%
64B
594B
1518B
Mixture
Pac
ket
Typ
es
Instruction Ratio
Arithmetic,Rotate, andShift InstructionsBranch and JumpInstructionsReference Instructions
Local RegisterInstructionsMiscellaneousInstructions

SDRAM Latency
0
20
40
60
80
100
40 60 80 100 120 140 160 180 200 220 240
cycles
cum
ula
tive
per
cen
tage
Microengine0Microengine1
Microengine2Microengine3

SRAM Latency (unlocked)
0
20
40
60
80
100
15 35 55 75 95 115 135 155 175 195 215 235
cycles
cum
ula
tive
per
cen
tage
Microengine0Microengine1
Microengine2
Microengine3Microengine4
Microengine5

Execution, Aborted, Stalled and Idle Ratio on 64bytes packets
73.4
73.7
69.1
69.4
69.3
69.1
25.3
25.1
26.4
26.5
26.4
27.3
4
3.7
3.80.5
0.5
0.4
0.5
1.1
1.2
3.2
0% 20% 40% 60% 80% 100%
Microengine5
Microengine4
Microengine3
Microengine2
Microengine1
Microengine0
ratio
Executing
Aborted
Stalled
Idle

Execution, Aborted, Stalled and Idle Ratio on 594bytes packets
75.8
76.1
60.2
60.3
60.4
60.4
23.6
23.3
37.7
37.7
37.6
37.9
2
0.6
0.7
0.1
0.1
0.1
0.1
1.9
1.9
1.6
0% 20% 40% 60% 80% 100%
Microengine5
Microengine4
Microengine3
Microengine2
Microengine1
Microengine0
ratio
Executing
Aborted
Stalled
Idle

Execution, Aborted, Stalled and Idle Ratio on 1518bytes packets
74.4
74.2
57.7
57.6
57.6
57.8
25
25.3
41.6
41.7
41.6
41.6
0.6
0.5
0.6
0.7
0.7
0.7
0% 20% 40% 60% 80% 100%
Microengine5
Microengine4
Microengine3
Microengine2
Microengine1
Microengine0
ratio
Executing
Aborted
Stalled
Idle

Execution, Aborted, Stalled and Idle Ratio on Mixture packets
74.5
75
58.2
58.3
58.2
58.6
24.7
24.4
41.5
41.1
41.5
41.1
0.7
0.7
0.2
0.3
0.3
0.3
0% 20% 40% 60% 80% 100%
Microengine5
Microengine4
Microengine3
Microengine2
Microengine1
Microengine0
ratio
Executing
Aborted
Stalled
Idle

Cycle per Instruction (CPI)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
64BPackets-uEngine5
594BPackets-uEngine5
1518BPackets-uEngine5
MixturePackets-uEngine5
64BPackets-uEngine4
594BPackets-uEngine4
1518BPackets-uEngine4
MixturePackets-uEngine4
64BPackets-uEngine3
594BPackets-uEngine3
1518BPackets-uEngine3
MixturePackets-uEngine3
64BPackets-uEngine2
594BPackets-uEngine2
1518BPackets-uEngine2
MixturePackets-uEngine2
64BPackets-uEngine1
594BPackets-uEngine1
1518BPackets-uEngine1
MixturePackets-uEngine1
64BPackets-uEngine0
594BPackets-uEngine0
1518BPackets-uEngine0
MixturePackets-uEngine0
CPI

Throughput (bounded)
0.40
0.130.33
2.38
0.47
0.130.33
2.38
0.38
0.100.26
2.83
0.00
0.50
1.00
1.50
2.00
2.50
3.00
Mixture 1518bytes 594bytes 64bytes
Mpp
s Sim Rate
Ideal Sim Rate
OC-24(CRC16)
Note: The reason why OC-24 is higher than Sim rate comes from the difference of protocol overheadEthernet protocol overhead:38bytes per packet.(82.6% overhead for 46bytes IP packet)Protocol header and trailer(18bytes)+IFG(12bytes)+preamble/SFD(8bytes)= 38bytesOC-24 POS overhead:7bytes per packet(15.2% overhead for 46bytes IP packet)

Throughput (unbounded)
0.58
0.150.46
3.07
0.380.10
0.26
2.16
0.75
0.200.52
4.32
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
4.00
4.50
Mixture 1518bytes 594bytes 64bytes
Mpp
s Sim Rate
1.244GEther(OC-24class)
2.488GEther(OC-48class)
Note: These throughputs don’t include 12bytes IFG overhead.

Features of Other NPsn Lexra’s NetVortex
n 32-bit MIPS-1 Instruction set plus 18 extended instructions for context control and bit-field operation
n Supports up to 8 contexts per processorn Each context includes 32 GPRs, its own PC and a status reg.n Uses delay slot of memory reference for context switching(ex. LW.CSW reg. addr.) n Performs in the similar way to IXP1200
n Motrola’s C-5n A subset of MIPS-1 Instruction set (excluding multiply, divide, floating point, and
Coprocessor Zero(CpO))n Provides its own special purpose CpO instructions for context switching(ex. MTC0 $1 $3) n 16 x Channel Processor RISC Cores(CPRCs), each supports up to 4 contexts and 32 GPRs
n IBM’s PowerNPn 16 x picoprocessors performing operation codes, each supports 2 contextsn 4 threads perform context switch in a clustern 4 categories: 1) ALU opcodes, 2) control opcodes, 3) data movement opcodes, 4)
coprocessor execution opcodes(supporting context switching)n Context switching occurs when the picoprocessor is waiting for a shared resource (ex.
Waiting for one of the coprocessors to complete an operation, access memory, etc)

Conclusion and Future work
n H/W multithreading can hide large latencies effectively, but another issue has come up
n Aborted cycles occurred by branch and context switch are not small
n Some dynamic hardware prediction or speculation could be necessary to reduce penalties for future NPs, but should consider cost issue
n An IXP1200 has achieved OC-24 class router processing, but not enough to perform OC-48 class router processing

Backup Slide

Instruction Categories
Instruction Description Instruction Description
Arithmetic,Rotate, and Shift Instructions Reference Instructions
alu Perform an alu operation csr Csr reference
alu_shf Perform an alu and shift operation fast_wr W rite immediate data to thd_done csrs
local_csr_rd, local_csr_wr Read and write csrs
r_fifo_rd Read the receive fifo
Branch and Jump Instructions pcl_dma Issue a request to the pci unit
scratch Scratchpad reference
sdram Sdram reference
sram Sram reference
t_fifo_wr W rite to the transmit fifo
br_bset, br_bclr Branch on bit set or bit clear Local Register Instructions
br=byte, br!=byte Brabch on byte equal find_bset, find_bset_w ith_maskDetermine position number of first bit set in an arbitrary 16-bit field of a register.
br=ctx, br!=ctx Branch on current context immed Load immediate word and sign extend or zero fill with shift.
br_inp_state Branch on event state (e,g.,sram done). immed_bo, immed_b1, immed_b2, immed_b3 Load immediate byte to a field.
br_!signal Branch if signal deasserted immed_wo, immed_w1 Load immediate word to a field.
jum p Jump to label ld_field, ld_field_w_clr Load byte(s) into specified field(s).
rtn Return from a branch or a jump load_addr Load instruction address.
M iscellaneous Instructions
ctx_arb Perform context swap and wake on event.
nop Perform no operation.
hash1_48, hash2_48, hash3_48 Perform 48-bit hash.
hash1_64, hash2_64, hash3_64 Perform 64-bit hash.
load_bset_result1, load_bset_result2Load the result of a find_bset or find_bset_with_mask instruction.
dbl_shfConcatenate two longwords, shift the result, and save a longword.
br, br=0, br!=0, br>=0, br>=0, br<0, br<=0, br>0, br=cout, br!=cout
Branch on condition code

SRAM Latency (locked)
0
20
40
60
80
100
20 40 60 80 100 120 140 160 180 200 220 240
cycles
cum
ula
tive
per
cen
tage
Microengine0
Microengine1
Microengine2
Microengine3
Microengine4
Microengine5

FBI Architecture
8 commandPull Queue
8 commandHash Queue
8 commandPush Queue
fast _ wr
AMBA (Core) Command BusMicroengine Command Bus
TFIFO16 elements
(10 quadwords each)
CSRs
From SDRAM
Pull Engine
TFIFO RdCRS/ScratchHash RdPull Command
CRS/Scratch
Hash Return
Push commandRFIFO
From SRAMMicroengineWrite TransferRegister
To SRAMMicroengineRead TransferRegister
To SDRAM
Push Engine1k x 32Scratchpad
Hash Unit
IX Bus Interface
Ready BusSequencer
TransmitState Machine
ReceiveState Machine
IX Bus Arbiter
64-bit IX Bus
Ready Bus
RFIFO16 elements
(10 quadwords each)
Push and Pull Engine Arbiters

Ready Bus and Ready Flags

Theoretical IP ThroughputMedia
64- byte PPS (46-byte IP packet)
594-byte PPS (576-byte IP packet)
1518-byte PPS (1500- byte IP packet)
Mixture (avg 406-byte) PPS (avg 388-byte IP packet)
100Mbps Ethernet 148,810 20,358 8,127 29,343
Gigabit Ethernet 1,488,095 203,583 81,274 293,427
10Gigabit Ethernet 14,880,952 2,035,831 812,744 2,934,272
OC-3 POS CRC-16 348,491 31,681 12,256 46,759
OC-12 POS CRC-16 1,412,830 128,439 49,688 189,570
OC-24 POS CRC-16 2,825,660 256,878 99,376 379,139
OC-48 POS CRC-16 5,651,321 513,756 198,752 758,278
OC-192 POS CRC-16 22,605,283 2,055,026 795,010 3,033,114
OC-3 POS CRC-32 335,818 31,573 12,240 46,524
OC-12 POS CRC-32 1,361,455 128,000 49,622 188,615
OC-24 POS CRC-32 2,722,909 256,000 99,245 377,229
OC-48 POS CRC-32 5,445,818 512,000 198,489 754,458
OC-192 POS CRC-32 21,783,273 2,048,000 793,956 3,017,834
ATM OC- 3 174,245 26,807 10,890 38,721ATM OC- 12 706,415 108,679 44,151 156,981ATM OC- 24 1,412,830 217,358 88,302 313,962ATM OC- 48 2,825,660 434,717 176,604 627,925ATM OC- 192 11,302,642 1,738,868 706,415 2,511,698

NetVortex extended Instruction setInstruction
Context-Control InstructionsDescription
MYCXPOSTCX
CSWLW.CSWLT.CSW
WD
WD.CSWWDLW.CSWWDLT.CSW
Bit-Field InstructionsSETI
CLRIEXTIVINSVACS2
Cross-Context Access Instructions
MFCXGMTCXGMFCXC
Read my contextPost event to a contextContext SwitchLoad word with context switchLoad twinword* with context switchWrite descriptor to device
Write descriptor to device with context switchWrite descriptor to device,load word with context switchWrite descriptor to device,load twinword with context switch
Set subfield to ones
Clear subfield to zeroesExtract subfield and prepare for insertionInsert extracted subfieldDual 16-bit ones complement add for checksum
Move from a context general-purpose registerMove to a context general-purpose registerMove from a context-control registerMove to a context-control registerMTCXC
InstructionContext-Control Instructions
Description
MYCXPOSTCX
CSWLW.CSWLT.CSW
WD
WD.CSWWDLW.CSWWDLT.CSW
Bit-Field InstructionsSETI
CLRIEXTIVINSVACS2
Cross-Context Access Instructions
MFCXGMTCXGMFCXC
Read my contextPost event to a contextContext SwitchLoad word with context switchLoad twinword* with context switchWrite descriptor to device
Write descriptor to device with context switchWrite descriptor to device,load word with context switchWrite descriptor to device,load twinword with context switch
Set subfield to ones
Clear subfield to zeroesExtract subfield and prepare for insertionInsert extracted subfieldDual 16-bit ones complement add for checksum
Move from a context general-purpose registerMove to a context general-purpose registerMove from a context-control registerMove to a context-control registerMTCXC

NetVortex Context Switch Mechanism
Thread Context 1(r0 - r31)Thread Context 1(r0 - r31)
Thread Context 2(r0 - r31)Thread Context 2(r0 - r31)
Thread1 CXPC = I4(T1)Thread1 CXSTATUS = WaitThread1 CXPC = I4(T1)Thread1 CXSTATUS = Wait
General PurposeRegister File
General PurposeRegister File
Context RegistersContext Registers
Thread 1 ProgramI1(T1): …I2(T1): LW.CSW (reg, addr)I3(T1): Delay slot instructionI4(T1): Next instructionI5(T1): …
Thread 2 ProgramI1(T1): …I2(T1): LW.CSW (reg, addr)I3(T1): Delay slot instructionI4(T1): Next instructionI5(T1): … Thread2 CXPC = PC
Thread2 CXSTATUS = ActiveThread2 CXPC = PCThread2 CXSTATUS = Active
PC = I1(T2)PC = I1(T2)
Context Switch to Thread 2Context Switch to Thread 2
Context Switch to next available threadContext Switch to next available thread
Thread Context 1(r0 - r31)Thread Context 1(r0 - r31)
Thread Context 2(r0 - r31)Thread Context 2(r0 - r31)
Thread1 CXPC = I4(T1)Thread1 CXSTATUS = WaitThread1 CXPC = I4(T1)Thread1 CXSTATUS = Wait
General PurposeRegister File
General PurposeRegister File
Context RegistersContext Registers
Thread 1 ProgramI1(T1): …I2(T1): LW.CSW (reg, addr)I3(T1): Delay slot instructionI4(T1): Next instructionI5(T1): …
Thread 2 ProgramI1(T1): …I2(T1): LW.CSW (reg, addr)I3(T1): Delay slot instructionI4(T1): Next instructionI5(T1): … Thread2 CXPC = PC
Thread2 CXSTATUS = ActiveThread2 CXPC = PCThread2 CXSTATUS = Active
PC = I1(T2)PC = I1(T2)
Context Switch to Thread 2Context Switch to Thread 2
Context Switch to next available threadContext Switch to next available thread

PowerNP Context Switch Example
IF Reduction_OR(mask16(i) = coprocessr. Busy(i))THENPC <= stall
ELSE
PC <=PC +1END IF
IF p=1 THEN
Priority Over(other thread)<= TRUEELSE
PriorityOwner(Other thread)<= PriorityOwner(Other thread)
END IF;