pattern classification, chapter 3 pattern classification all materials in these slides were taken...
Post on 20-Dec-2015
236 views
TRANSCRIPT

Pattern Classification, Chapter 3
Pattern Classification
All materials in these slides were taken from
Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley
& Sons, 2000 with the permission of the authors and
the publisher

Chapter 3:Maximum-Likelihood & Bayesian
Parameter Estimation (part 1)
Introduction Maximum-Likelihood Estimation
Example of a Specific Case The Gaussian Case: unknown and Bias
Appendix: ML Problem Statement

Pattern Classification, Chapter 3
Introduction Data availability in a Bayesian framework
We could design an optimal classifier if we knew: P(i) (priors)
P(x | i) (class-conditional densities)
Unfortunately, we rarely have this complete information!
Design a classifier from a training sample No problem with prior estimation Samples are often too small for class-conditional
estimation (large dimension of feature space!)

Pattern Classification, Chapter 3
A priori information about the problem
Normality of P(x | i)
P(x | i) ~ N( i, i)
Characterized by 2 parameters
Estimation techniques
Maximum-Likelihood (ML) and the Bayesian estimations
Results are nearly identical, but the approaches are different

Pattern Classification, Chapter 3
Parameters in ML estimation are fixed but unknown!
Best parameters are obtained by maximizing the probability of obtaining the samples observed
Bayesian methods view the parameters as random variables having some known distribution
In either approach, we use P(i | x)for our classification rule!

Pattern Classification, Chapter 3
Maximum-Likelihood Estimation
Has good convergence properties as the sample size increases
Simpler than any other alternative techniques
General principle
Assume we have c classes and
P(x | j) ~ N( j, j)
P(x | j) P (x | j, j) where:
)...)x,xcov(,,,...,,(),( nj
mj
22j
11j
2j
1jjj

Pattern Classification, Chapter 3
Use the informationprovided by the training samples to estimate
= (1, 2, …, c), each i (i = 1, 2, …, c) is associated with each category
Suppose that D contains n samples, x1, x2,…, xn
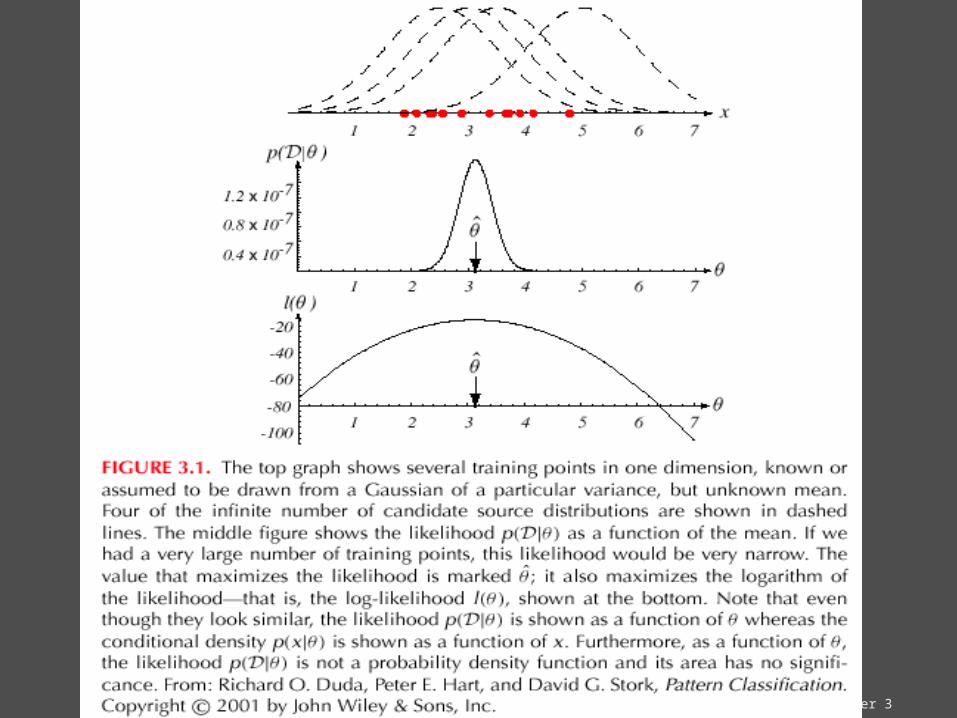
ML estimate of is, by definition the value that maximizes P(D | )
“It is the value of that best agrees with the actually observed training sample”
samples) ofset the w.r.t. of likelihood the called is )|D(P
)(F)|x(P)|D(Pnk
1kk
Pattern Classification, Chapter 3

Pattern Classification, Chapter 3
Optimal estimation Let = (1, 2, …, p)t and let be the gradient operator
We define l() as the log-likelihood function
l() = ln P(D | )
New problem statement:
determine that maximizes the log-likelihood
t
p21
,...,,
)(lmaxargˆ

Pattern Classification, Chapter 3
Set of necessary conditions for an optimum is:
l = 0
))|x(Plnl( k
nk
1k

Pattern Classification, Chapter 3
Example of a specific case: unknown
P(xi | ) ~ N(, )(Samples are drawn from a multivariate normal population)
= therefore:
• The ML estimate for must satisfy:
)x()|x(Pln and
)x()x(21
)2(ln21
)|x(Pln
1
kk
1
kt
kd
k
0)ˆx( k
nk
1k
1

Pattern Classification, Chapter 3
• Multiplying by and rearranging, we obtain:
Just the arithmetic average of the samples of the training samples!
Conclusion: If P(xk | j) (j = 1, 2, …, c) is supposed to be Gaussian in a d-
dimensional feature space; then we can estimate the vector
= (1, 2, …, c)t and perform an optimal classification!
nk
1kkx
n1
ˆ

Pattern Classification, Chapter 3
ML Estimation: Gaussian Case: unknown and
= (1, 2) = (, 2)
02
)x(
21
0)x(1
0))|x(P(ln
))|x(P(ln
l
)x(2
12ln
21
)|x(Plnl
22
21k
2
1k2
k2
k1
21k
22k

Pattern Classification, Chapter 3
Summation:
Combining (1) and (2), one obtains:
n
)x( ;
n
x
nk
1k
2k
2nk
1k
k
nk
1k
nk
1k22
21k
2
nk
1k1k
2
(2) 0ˆ
)ˆx(ˆ1
(1) 0)x(ˆ1

Pattern Classification, Chapter 3
Bias
ML estimate for 2 is biased
An elementary unbiased estimator for is:
222i .
n1n
)xx(n1
E
matrix covariance
1
)ˆ)(ˆ(1-n
1C
Sample
nk
k
tkk xx

Pattern Classification, Chapter 3
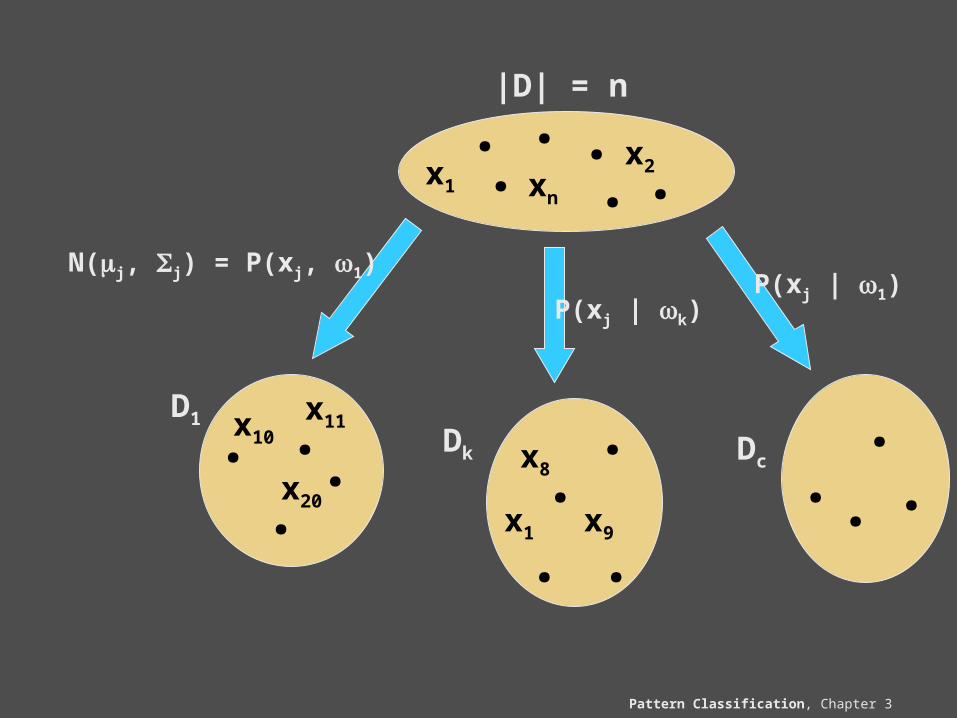
Appendix: ML Problem Statement
Let D = {x1, x2, …, xn}
P(x1,…, xn | ) = 1,nP(xk | ); |D| = n
Our goal is to determine (value of that makes this sample the most representative!)
Pattern Classification, Chapter 3
|D| = n
x1
x2xn
.. ..
.
..
..
..
...
..
..
x11
x20
x10x8
x9x1
N(j, j) = P(xj, 1)
D1
DcDk
P(xj | 1)P(xj | k)

Pattern Classification, Chapter 3
= (1, 2, …, c)
Problem: find such that:
n
1kk
n1
)|x(PMax
)|x,...,x(MaxP)|D(PMax