pattern classification chapter 2 (part 2)0 pattern classification all materials in these slides were...
TRANSCRIPT

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
11
Pattern Classification
All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors and the publisher

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
22
Chapter 2 (Part 2): Chapter 2 (Part 2): Bayesian Decision TheoryBayesian Decision Theory
(Sections 2.3-2.5)(Sections 2.3-2.5)
Minimum-Error-Rate ClassificationMinimum-Error-Rate Classification
Classifiers, Discriminant Functions and Classifiers, Discriminant Functions and Decision SurfacesDecision Surfaces
The Normal DensityThe Normal Density

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
33
2.3 Minimum-Error-Rate 2.3 Minimum-Error-Rate ClassificationClassification
Actions are decisions on classesActions are decisions on classesIf action If action ii is taken and the true state of nature is is taken and the true state of nature is jj then: then:
the decision is correct if the decision is correct if i = ji = j and in error if and in error if i i j j
Seek a decision rule that minimizes the Seek a decision rule that minimizes the probability of errorprobability of error which is the which is the error rateerror rate

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
44
Introduction of the zero-one loss function:Introduction of the zero-one loss function:
Therefore, the conditional risk is: Therefore, the conditional risk is:
““The risk corresponding to this loss function is The risk corresponding to this loss function is the average probability error”the average probability error”
c,...,1j,i ji 1
ji 0),( ji
ijij
cj
jjjii
xPxP
xPxR
)|(1)|(
)|()|()|(1

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
55
Minimize the risk requires maximize Minimize the risk requires maximize P(P(ii | x) | x)
(since (since R(R(i i | x) = 1 – P(| x) = 1 – P(ii | x) | x)))
For Minimum error rateFor Minimum error rate
Decide Decide ii if P ( if P (ii | x) > P( | x) > P(jj | x) | x) j j i i

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
66
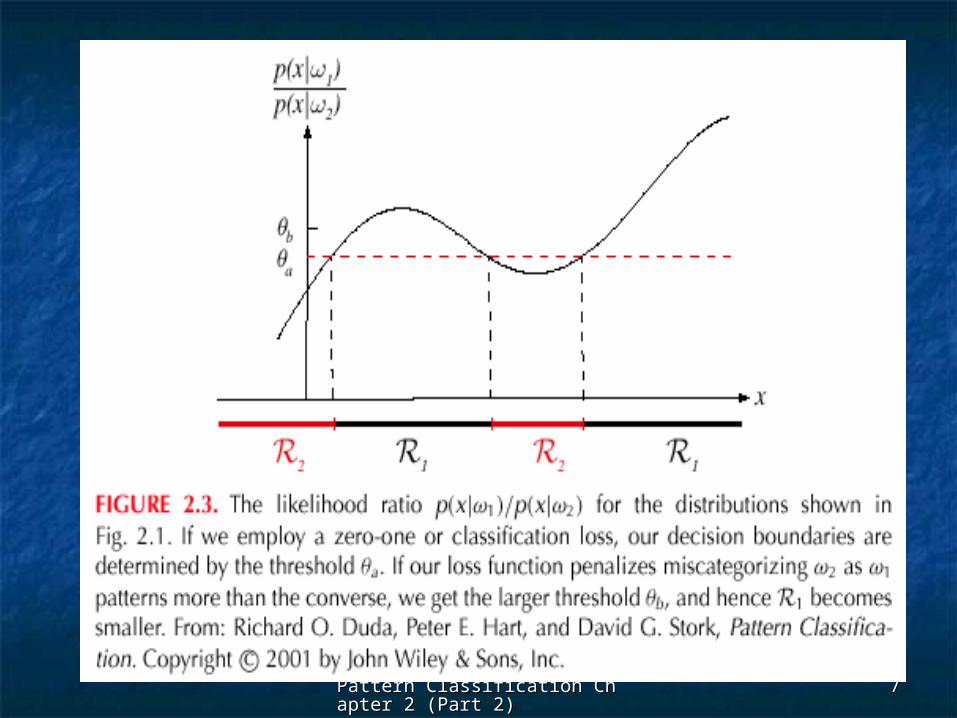
Regions of decision and zero-one loss Regions of decision and zero-one loss function, therefore:function, therefore:
If If is the zero-one loss function which is the zero-one loss function which means:means:
b1
2
a1
2
)(P
)(P2 then
0 1
2 0 if
)(P
)(P then
0 1
1 0
)|x(P
)|x(P :if decide then
)(P
)(P. Let
2
11
1
2
1121
2212
Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
77

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
88
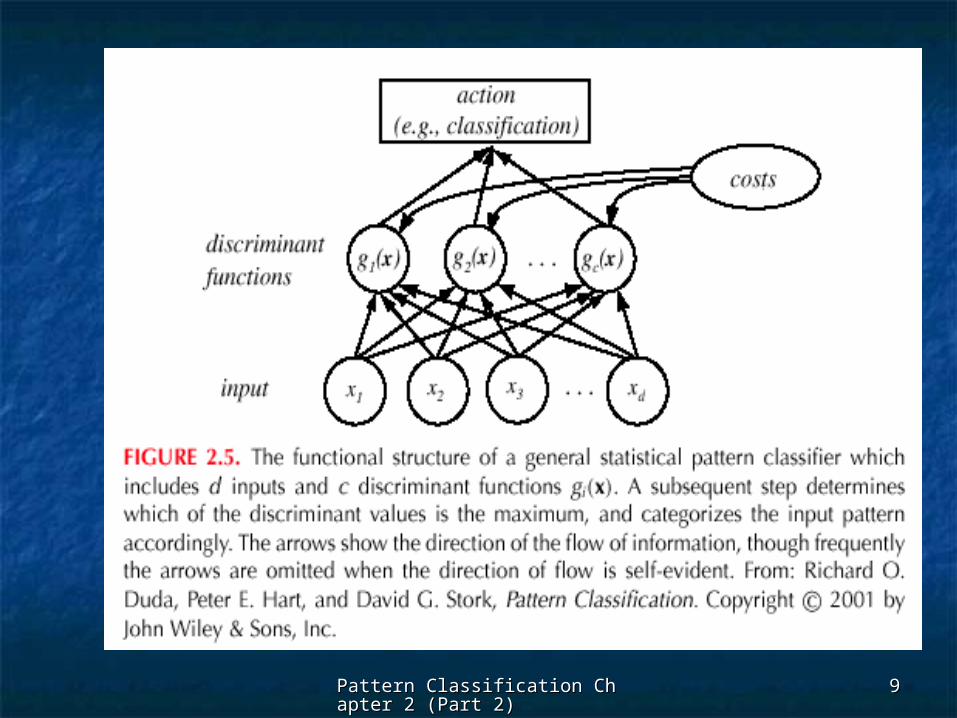
2.4 Classifiers, Discriminant 2.4 Classifiers, Discriminant FunctionsFunctions
and Decision Surfacesand Decision Surfaces The multi-category caseThe multi-category case
Set of discriminant functions Set of discriminant functions ggii(x), i = 1,…, (x), i = 1,…, cc
The classifier assigns a feature vector x to The classifier assigns a feature vector x to class class ii
if: if:
ggii(x) > g(x) > gjj(x)(x) j j i i
Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
99

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1010
For For the minimum the minimum risk caserisk case
Let gLet gii(x) = - R((x) = - R(ii | x) | x)
(max. discriminant corresponds to min. (max. discriminant corresponds to min. risk!)risk!)
For the minimum error rate cae, we take For the minimum error rate cae, we take ggii(x) = P((x) = P(ii | x) | x)
(max. discrimination corresponds to max. (max. discrimination corresponds to max. posterior!)posterior!)
ggii(x) (x) p(x | p(x | ii) P() P(ii))
ggii(x) = ln p(x | (x) = ln p(x | ii) + ln P() + ln P(ii))
(ln: natural logarithm!)(ln: natural logarithm!)

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1111
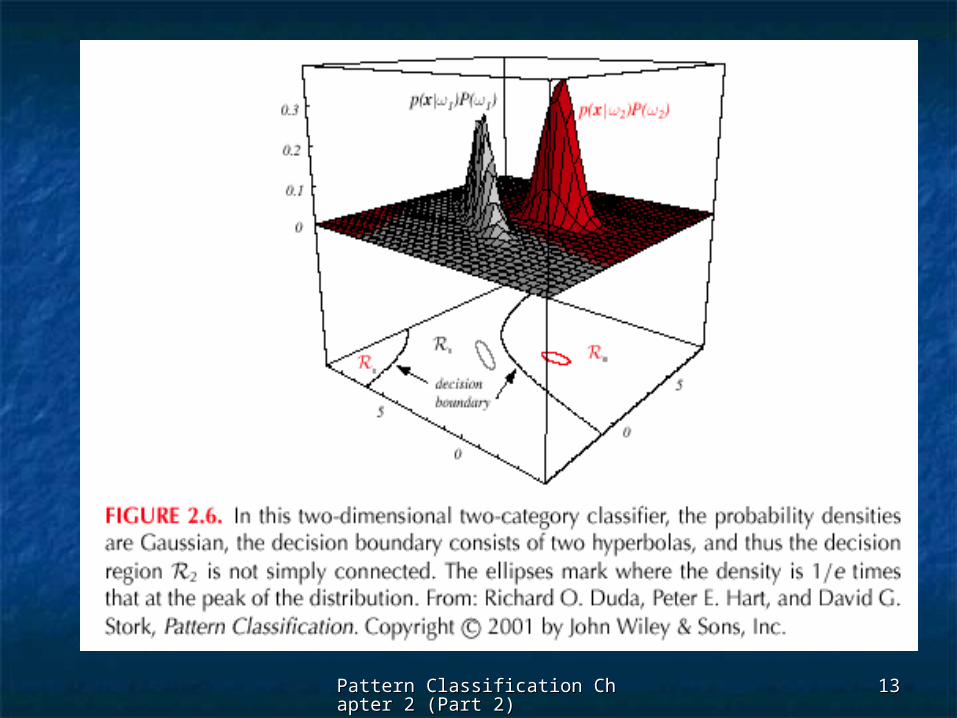
Feature space divided into c decision Feature space divided into c decision regionsregions
if gif gii(x) > g(x) > gjj(x) (x) j j i then x is in i then x is in RRii
((RRii means assign means assign xx to to ii)) The two-category caseThe two-category case
A classifier is a “dichotomizer” that has two A classifier is a “dichotomizer” that has two discriminant functions discriminant functions gg11 and and gg22
Let Let g(x) g(x) g g11(x) – g(x) – g22(x)(x)
Decide Decide 1 1 if g(x) > 0 if g(x) > 0 ; Otherwise decide ; Otherwise decide 22

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1212
The computation of g(x)The computation of g(x)
)(
)(ln
)|(
)|(ln )g(
)|()|()(
2
1
2
1
21
P
P
xp
xpx
xPxPxg
Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1313

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1414
2.5 The Normal Density2.5 The Normal Density Univariate densityUnivariate density
Continuous densityContinuous density A lot of processes are asymptotically GaussianA lot of processes are asymptotically Gaussian Handwritten characters, speech sounds are Handwritten characters, speech sounds are
ideal or prototype corrupted by random process ideal or prototype corrupted by random process (central limit theorem)(central limit theorem)
Where: Where: = mean (or expected value) of = mean (or expected value) of xx 22 = expected squared deviation or = expected squared deviation or
variancevariance
,x
2
1exp
2
1)x(P
2
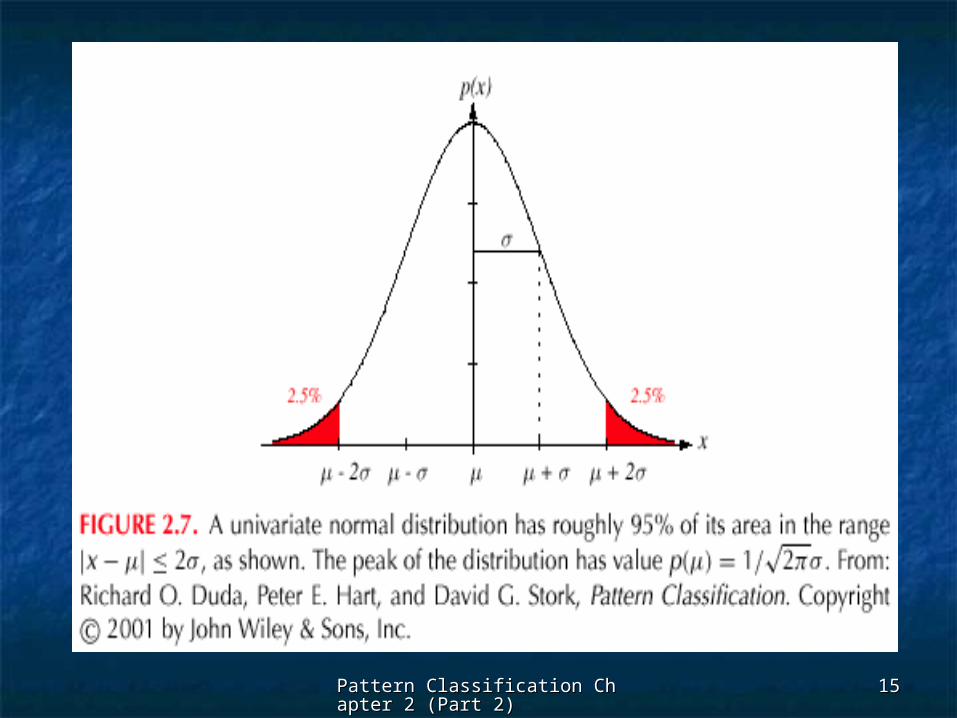
Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1515

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1616
Multivariate densityMultivariate density
Multivariate normal density in d dimensions is:Multivariate normal density in d dimensions is:
where:where:
x = (xx = (x11, x, x22, …, x, …, xdd))tt (t stands for the transpose (t stands for the transpose vector form)vector form)
= (= (11, , 22, …, , …, dd))tt mean vector mean vector = d*d= d*d covariance matrix covariance matrix
|||| and and -1-1 are determinant and inverse are determinant and inverse respectivelyrespectively
)x()x(
2
1exp
)2(
1)x(P 1t
2/12/d
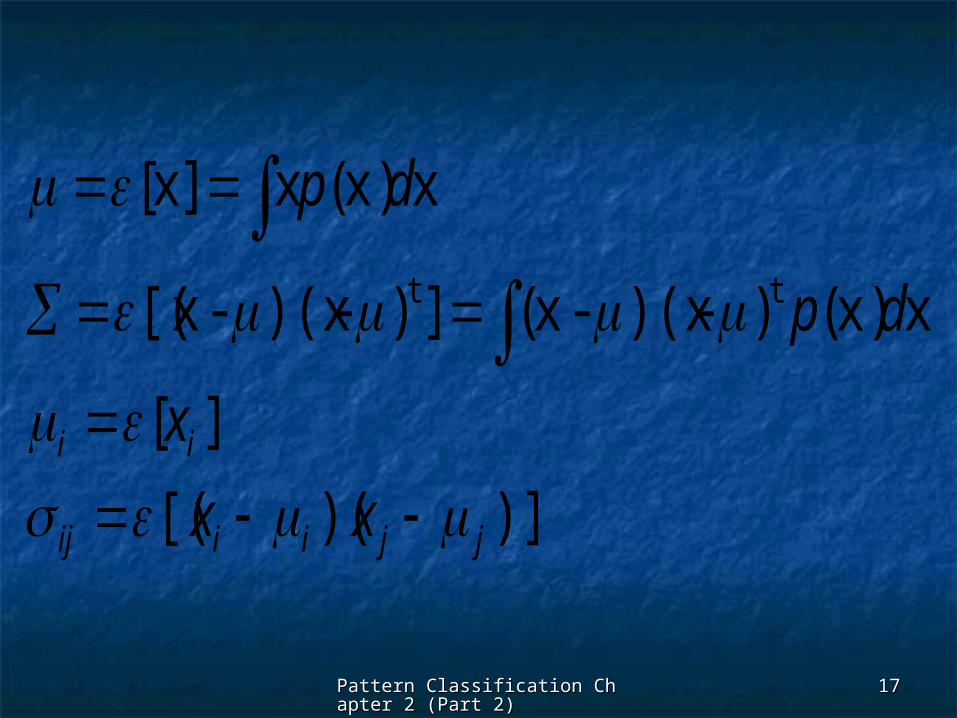
Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1717
)])([(
][
xx)()-)(x-x(])-)(x-x[(
xx)(x]x[
tt
jjiiij
ii
xx
x
dp
dp

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1818
Linear combinations of normally distributed Linear combinations of normally distributed random variables are normally distributedrandom variables are normally distributed
ifif
then then
Whitening transform:Whitening transform:
:The orthonormal eigenvectors of:The orthonormal eigenvectors of
:The diagonal matrix of the eigenvalues:The diagonal matrix of the eigenvalues
xy,:),,(~)x( tAkdANp
A)A,A(~y)( tt Np2/1wA

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
1919
Mahalanobis distance from x to Mahalanobis distance from x to
)-x()-x( 1t2 r

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
2020
EntropyEntropy Measure the fundamental Measure the fundamental
uncertainty in the values of points uncertainty in the values of points selected randomlyselected randomly
Measured in nats, bit, Measured in nats, bit, Normal distribution has max entropy Normal distribution has max entropy
of all distributions having a given of all distributions having a given mean and variancemean and variance
dxxpxpxpH )(ln)())((

Pattern Classification Chapter 2 (Pattern Classification Chapter 2 (Part 2)Part 2)
2121
Assignment :2.3.12, 2.4.14,2.5.22,2.5.23