trash talk: accelerating garbage collection on integrated
TRANSCRIPT

Trash Talk: Accelerating Garbage Collection onIntegrated GPUs is Worthless
Mohammad DashtiUniversity of British Columbia
Vancouver, [email protected]
Alexandra FedorovaUniversity of British Columbia
Vancouver, [email protected]
Abstract—Systems integrating heterogeneous processors withunified memory provide seamless integration among these pro-cessors with minimal development complexity. These systemsintegrate accelerators such as GPUs on the same die withCPU cores to accommodate running parallel applications withvarying levels of parallelism. Such integration is becoming verycommon on modern chip architectures, and it places a burden(or opportunity) on application and system programmers toutilize the full potential of such integrated chips. In this paperwe evaluate whether we can obtain any performance benefitsfrom running garbage collection on integrated GPU systems, anddiscuss how difficult it would be to realize these gains for theprogrammer.
Proliferation of garbage-collected languages running on avariety of platforms from handheld mobile devices to data centersmakes garbage collection an interesting target to examine onsuch platforms and can offer valuable lessons for other appli-cations. We present our analysis of running garbage collectionon integrated systems and find that the current state of thesesystems does not provide an advantage for accelerating such atask. We build a framework that allows us to offload garbagecollection tasks on integrated GPU systems from within the JVM.We identify dominant phases of garbage collection and study theviability of offloading them to the integrated GPU. We show thatperformance advantages are limited, partly because an integratedGPU has limited advantage in memory bandwidth over the CPU,and partly because of costly atomic operations.
Index Terms—GPGPU, Garbage collection, Heterogeneous sys-tems
I. INTRODUCTION
High performance and energy efficiency are the ultimategoals of any computing system. However, as Dennard’s scal-ing [15], [17] comes to an end, chip designers can no longerrely on increasing transistor density and clock frequenciesto boost performance within a fixed power envelope. Thefocus has turned to multicore chip designs where multiplesymmetric or asymmetric cores occupy the chip area [6], [14],[34], [36]. One of the emerging hardware architectures in theasymmetric realm places the GPU and the CPU on the samedie, sharing the same physical memory (figure 1). This typeof architecture can eliminate data transfer costs compared totraditional discrete systems where the accelerator (GPU) sitson a separate chip connected to the CPU through a PeripheralComponent Interconnect (PCI) bus. Such tight integrationenables the CPU and the accelerator to share and collaborateon data without explicit copying. The elimination of data
CPU1
L1
CPU0
L1
CPU2
L1
CPU3
L1
CPU GPU
DRAM
L2Cache
UnifiedNorthBridge
L2Cache
CUL1
CUL1
CUL1
CUL1
CUL1
CUL1
CUL1
CUL1
GraphicsMemoryController
L2Cache
MemoryController
Fig. 1: Abstract memory system architecture of the integratedsystem used in our work.
copies can significantly improve performance even comparedto much more powerful discrete GPUs. For compute-intensiveapplications, a discrete GPU is generally much better due toits superior compute capabilities. However, for applicationsthat need to transfer large amounts of data, a less powerfuland more energy-efficient integrated GPU can significantlyoutperform a discrete GPU [13], [14], [37].
In this paper, we aim to answer the question of whether wecan obtain performance benefits from offloading garbage col-lection (GC) in the JVM onto a GPU in integrated CPU/GPUsystems. We approach this question via a case study offour memory intensive applications that are affected by GC:Apache Spark [41], GraphChi [25], Apache Lucene [9] and h2from the DaCapo suite [11]. We also use microbenchmarksstressing particular aspects of the system to support ourconclusions.
We contribute the following new experimental insights andengineering artifacts. First, we evaluate GC activities in ourtarget applications to determine which GC phases are the bestcandidates for offloading to the integrated GPU. Although theimpact of GC on application performance has been extensivelyanalyzed in previous studies [11], [18]–[20], none of themhave been done in the context of our research question on ourintegrated system discussed in Section III-A.
arX
iv:2
012.
0628
1v1
[cs
.DC
] 1
1 D
ec 2
020

Second, we create a framework for offloading GC taskson integrated CPU-GPU systems from within the JVM. Ourframework is based on the Heterogeneous System Architecture(HSA [1]) and we describe it in Section IV.
Third, we use our framework to offload the major iden-tified phases of GC to the GPU, analyze the performance(Sections IV-A and IV-B), and present our findings, showingthat there is generally no observable benefits for acceleratingGC on current HSA-capable integrated CPU-GPU systems.We conclude with the discussion of hardware and softwarelimitations that led to our observations.
II. BACKGROUND
A. GPUs and Integrated SystemsIntegrated CPU-GPU systems provide a unified memory
view from both the CPU and the GPU. This unification, atleast in theory, allows for seamless processing of complexpointer-based data structures from both processors. In systemswhere the CPU and GPU do not share the virtual memoryaddress space, pointers to memory allocated by the CPUcannot be used on the GPU. For example, data structurescontaining pointers to objects cannot be simply referenced onthe GPU without deep-copying the objects from the CPU tothe GPU and back to the CPU when needed. With sharedvirtual memory, the CPU can simply pass the same pointerto the data structure and the GPU will be able to seamlesslytraverse the structure and its contained pointers and objects.
Memory unification between the CPU and GPU, however,has software and hardware limitations, and hence adaptingapplications to run on such integrated systems can be chal-lenging. For example, it is still impractical to implement a fullcache coherency scheme between the CPU and GPU since thiscan be very costly and would require complex architecturaldesign choices. Furthermore, the existing heterogeneous pro-gramming frameworks such as CUDA and OpenCL providea variety of memory management methods that interact withthe driver and hardware in poorly understood ways, addingprogramming complexity and limiting performance [14].
B. Garbage CollectionA garbage collector is the component in managed runtimes
that is responsible for memory allocation and deallocation. Thecollector tracks down unused objects and deletes them with-out programmers’ intervention. In contrast, in non-managedlanguages such as C/C++, programmers must explicitly deleteobjects when they decide that the objects are no longer needed.Managed runtime environments are becoming increasinglypopular as they eliminate common memory bugs. However,GC may have exceedingly higher overheads than explicitmemory management [10], [21], [22]. Many of the current GCimplementations use generational or regional schemes wherethey divide the heap into multiple areas to reduce the overheadof collection. One of the major costs of these tracing collectorsis having to traverse all live objects and their descendantsduring a collection. Furthermore, many “big data” applicationsretain lots of live data for long periods of time, contradicting
the hypothesis that most objects die young [26]. With manylive objects, the young generation will quickly fill up and causefrequent collection cycles, which involve heap traversal andobject copying and can be costly compared to explicit memorymanagement. The activities of GC can account for a significantportion of application’s execution time, specially for big datasystems [40].
Different garbage collectors apply different techniques tohave as little effect as possible on applications. The main aimof all techniques is to maintain application throughput andreduce pause times, the periods of times in which applicationthreads are interrupted. Some collectors use the stop-the-world strategy, where they let an application run uninterruptedoutside of collection cycles, but during the collection cycle allapplication threads are halted. A garbage collector may usemultiple cooperating threads to perform its work during thecollection cycle, which gives it the property of being a parallelcollector as opposed to being a serial one. Using multiplethreads aims at reducing the pause times during collections.However, this involves trade-offs as the GC threads need tocoordinate their work.
Other techniques for reducing GC overhead include dividingthe heap into multiple regions and keeping statistics abouteach, so that garbage can be quickly collected from regionswith the most garbage; the Garbage First or G1GC collec-tor [16] uses such a technique. The downside of this methodis that it requires a large memory footprint for maintainingmetadata about regions and must track cross-region memoryreferences.
Some collectors, including G1GC, also employ concurrentphases for some of their activities. Concurrent phases allow thecollector to perform its work while the application threads areexecuting. This adds complexity since both the GC threads andapplication threads may potentially modify the same objectsconcurrently. Therefore, concurrent collectors must use tech-niques such as write barriers, or read/load barriers to ensurecorrectness. These barriers are snippets of code that are addedto the application code by the JIT (Just In Time) compilerwhenever a read or write reference is encountered. They ensureatomicity of memory accesses and perform bookkeeping.
Regardless of how a garbage collector is designed, themain activities in any collector are essentially graph traversals(with possibly concurrent node modifications) and bandwidth-constrained memory operations for copying, moving, and/orcompacting memory objects on the heap. GPUs have relativelylarge memory bandwidths and their architectures are designedto hide memory latency with extreme parallelism. Such ob-servations arguably make GPUs a potential target for runningGC. Furthermore, hardware systems are increasingly movingtoward integrating GPUs on chip along with a multicore CPUto eliminate the high costs of copying data from/to CPU/GPU.Although these integrated GPUs have less memory bandwidthand are less computationally capable than discrete GPUs,not needing to copy data can offer both performance andprogrammability advantages.

III. ANALYZING THE OVERHEAD OF GARBAGECOLLECTORS
In this section, we measure the effects of GC on ourtarget applications running only on the CPU. We describe ourexperimental setup in section III-A, and analyze the overheadof GC in section III-B. We also break down the major phasesof GC to show that object copying and marking are dominant.
A. Experimental SetupIn all of the experiments in this paper we use an AMD
Carrizo A10-9600P APU running Ubuntu Linux 18.04. It isa 7th generation Bristol Ridge series APU with 4 CPU cores(two Excavator modules) clocked at 2.4 - 3.3 GHz. The L2cache is 2 MB. The integrated GPU is a Radeon R5 composedof 6 Compute Units (CU) and clocked at 720 MHz. The totalmemory capacity of the system is 12GB.
For our case study we use Apache Spark (spark-sql-perf),Apache Lucene (text search using a Wikipedia input file),GraphChi (Pagerank using Twitter input graph), and h2 fromDacapo. We analyzed many more applications and bench-marks, but identified these four as the most affected by GCand showing a variety of nuance in how GC can affectperformance. We use the following standard garbage collectorsthat are available on modern OpenJDK versions:
• SerialGC: A generational stop-the-world throughput-oriented collector. This is an old GC, but it serves a usefulreference point.
• ParallelGC: A generational stop-the-world throughput-oriented collector that uses multiple threads during somecollection phases. This is the default collector in Java 8 1.
• G1GC: A generational, parallel, regional, and mostly-concurrent garbage collector. It is mostly-concurrent sinceit only employs concurrency with application threadsduring marking. Other phases in this collector are stop-the-world. This collector has become the default garbagecollector since Java 9.
We use a number of configurations for each collectordepending on the experiment, as specified in the followingsections.
B. Running GC on the CPU1) First Experiment: Effects of GC on applications:
How much GC affects applications depends on many factors,including the behavior of the application itself. If it rarelyallocates any objects in the heap, there will hardly be anyGC cycles that might delay its execution. The impact alsovaries depending on how long the application retains allocatedobjects. Furthermore, the time spent on GC is not always adirect predictor of GC-related performance degradation, as wewill see below.
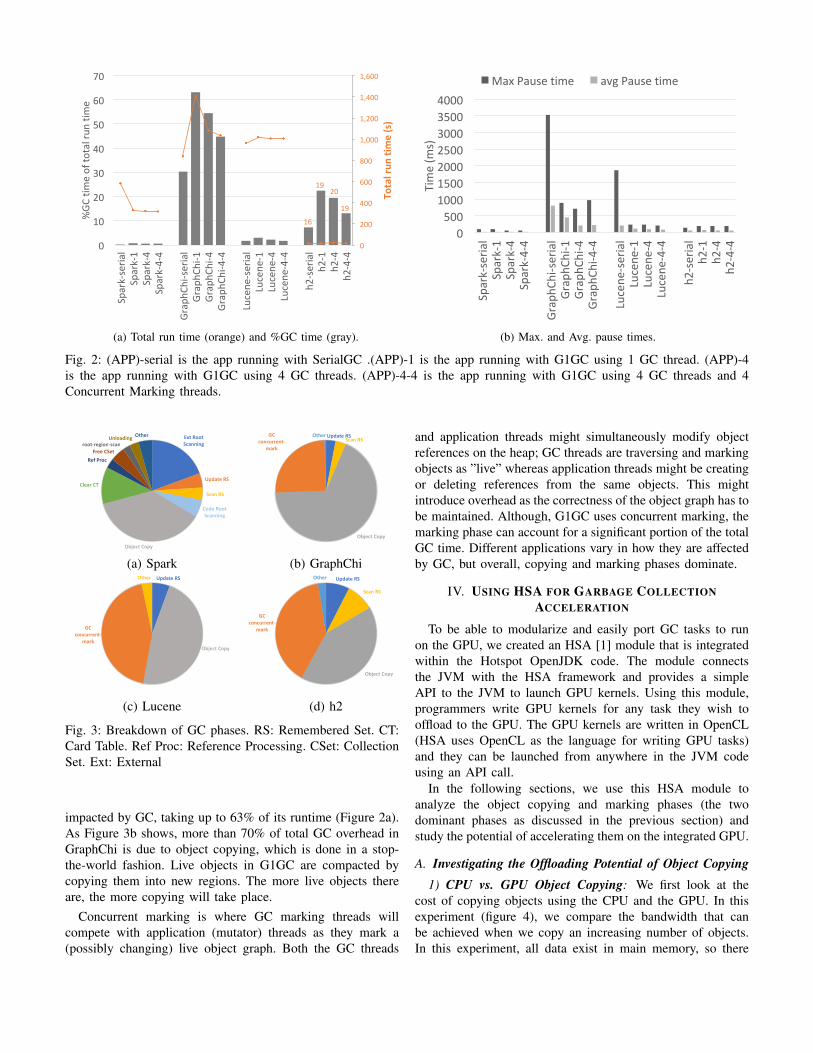
Figure 2a shows the percentage of the application timespent on GC. Each application (APP) is run under four
1Java 8 is still widely used and is maintained until the end of 2030.Furthermore, in this work we evaluate GPU offloading of copying and markingwhich are major phases in almost all modern garbage collectors, so we believeour results are applicable to different GCs in any Java version.
GC configurations: (APP)-serial uses SerialGC .(APP)-1 usesG1GC using one GC thread. (APP)-4 uses G1GC with fourGC threads and one marking thread. (APP)-4-4 uses G1GCusing four GC threads and four concurrent marking threads.All configurations use four application threads to perform theactual work.
We see in figure 2a that GC affects applications differently,which has already been demonstrated by many previous workssuch as [10], [16], [21], [31]. For some applications (i.e. Sparkand Lucene), GC does not constitute a significant portion ofthe execution time. This, however, doesn’t mean that theseapplications are not affected by the GC implementation sincethere are many other factors such as barriers and lock con-tention. For example, we found out that when an applicationruns with multiple mutator threads, it is possible that thesethreads compete for lock-based new memory allocations onsome shared regions. This is true for Spark with Paralleland Serial GC. We also noticed that when the thread-localallocation buffers (TLABs) become full and new ones need tobe acquired from the JVM, the contention for acquiring newbuffers can negatively affect performance. These effects aresometimes not counted as GC overhead, since they may bepart of the JIT-generated code.
Furthermore, although SerialGC might appear to providea low-overhead and high-throughput alternative to concurrentor parallel collectors, it causes massive pause times. Sincethe serial collector must stop all application threads to clearthe garbage and only utilizes a single CPU core to do thecollection, applications will become unresponsive during thisperiod. This may be unacceptable to interactive applications orthose with soft-real time requirements. Figure 2b demonstratesthese effects by showing the maximum and average pausetimes for the applications.
2) Second Experiment: Breakdown of GC phases:Garbage collection consists of several phases and the impactof each phase differs depending on the behaviour of a givenapplication. In this section we break down the overhead ofthese phases. We focus only on G1GC here, since major phasesare similar in other garbage collectors, and for brevity we showthe break-down of APP-1 experiments. Running multiple GCand marking threads impacts the total time spent in the phases,but not their relative contribution to the total overhead.
Figure 3 shows the breakdown of the GC overhead. Themain observation from these charts is that object copyingand concurrent marking are the dominant phases for all GC-impacted applications. The only exception is Spark. Thebehavior of Spark is that it allocates huge amounts of data andhas a very high allocation rate, yet it does not retain most ofthis data so almost all the allocated objects become garbageinstantaneously in the young generation. Since generationalcollectors will allocate objects in the young generation first,and many of these objects will quickly be dead, the phases ofgarbage collection will quickly terminate without much work(i.e. there is not much traversing of the live object graph).
Also, we showed in the previous experiment that GraphChi,which retains a large portion of its allocated objects, is heavily
16
1920
19
0
200
400
600
800
1,000
1,200
1,400
1,600
0
10
20
30
40
50
60
70
Spark-seria
lSpark-1
Spark-4
Spark-4-4
GraphC
hi-serial
GraphC
hi-1
GraphC
hi-4
GraphC
hi-4-4
Lucene
-serial
Lucene
-1
Lucene
-4
Lucene
-4-4
h2-serial
h2-1
h2-4
h2-4-4
Totalrun
time(s)
%GC
timeofto
talrun
time
(a) Total run time (orange) and %GC time (gray).
05001000150020002500300035004000
Spark-seria
lSpark-1
Spark-4
Spark-4-4
GraphC
hi-serial
GraphC
hi-1
GraphC
hi-4
GraphC
hi-4-4
Lucene
-serial
Lucene
-1
Lucene
-4
Lucene
-4-4
h2-serial
h2-1
h2-4
h2-4-4
Time(m
s)
MaxPausetime avgPausetime
(b) Max. and Avg. pause times.
Fig. 2: (APP)-serial is the app running with SerialGC .(APP)-1 is the app running with G1GC using 1 GC thread. (APP)-4is the app running with G1GC using 4 GC threads. (APP)-4-4 is the app running with G1GC using 4 GC threads and 4Concurrent Marking threads.
Ext Root Scanning
Update RS
Scan RS
Code Root Scanning
Object Copy
Clear CT
Ref ProcFree CSet
root-region-scanUnloading Other Update RS
Scan RS
Object Copy
GC concurrent-
mark
Other
(a) Spark (b) GraphChiUpdate RS
Object Copy
GC concurrent-
mark
Other Update RS
Scan RS
Object Copy
GC concurrent-
mark
Other
(c) Lucene (d) h2
Fig. 3: Breakdown of GC phases. RS: Remembered Set. CT:Card Table. Ref Proc: Reference Processing. CSet: CollectionSet. Ext: External
impacted by GC, taking up to 63% of its runtime (Figure 2a).As Figure 3b shows, more than 70% of total GC overhead inGraphChi is due to object copying, which is done in a stop-the-world fashion. Live objects in G1GC are compacted bycopying them into new regions. The more live objects thereare, the more copying will take place.
Concurrent marking is where GC marking threads willcompete with application (mutator) threads as they mark a(possibly changing) live object graph. Both the GC threads
and application threads might simultaneously modify objectreferences on the heap; GC threads are traversing and markingobjects as ”live” whereas application threads might be creatingor deleting references from the same objects. This mightintroduce overhead as the correctness of the object graph has tobe maintained. Although, G1GC uses concurrent marking, themarking phase can account for a significant portion of the totalGC time. Different applications vary in how they are affectedby GC, but overall, copying and marking phases dominate.
IV. USING HSA FOR GARBAGE COLLECTIONACCELERATION
To be able to modularize and easily port GC tasks to runon the GPU, we created an HSA [1] module that is integratedwithin the Hotspot OpenJDK code. The module connectsthe JVM with the HSA framework and provides a simpleAPI to the JVM to launch GPU kernels. Using this module,programmers write GPU kernels for any task they wish tooffload to the GPU. The GPU kernels are written in OpenCL(HSA uses OpenCL as the language for writing GPU tasks)and they can be launched from anywhere in the JVM codeusing an API call.
In the following sections, we use this HSA module toanalyze the object copying and marking phases (the twodominant phases as discussed in the previous section) andstudy the potential of accelerating them on the integrated GPU.
A. Investigating the Offloading Potential of Object Copying1) CPU vs. GPU Object Copying: We first look at the
cost of copying objects using the CPU and the GPU. In thisexperiment (figure 4), we compare the bandwidth that canbe achieved when we copy an increasing number of objects.In this experiment, all data exist in main memory, so there

0
2
4
6
8
10
121 2 4 8 16
32
64
128
256
512 1K
2K
4K
8K
16K
32K
64K
128K
256K
512K
1M
2M
4M
8M
16M
32M
64M
128M
Band
width(G
B/s)
Numberofcopiedobjects
1CPU 4CPUs 4CPUs-blocks GPU GPU(w/olaunchoverhead)
0
0.1
0.2
0.3
0.4
1 2 4 8 16 32 64 128
Fig. 4: CPU vs. GPU object copy bandwidth
are no disk accesses or page faults that affect the results.Each single object has a size of 8 bytes; when we copy128K objects, for example, we are copying 1MB of totaldata. We compare five cases: 1) A single CPU thread copiesthe objects using memcpy. It copies all of the objects atonce (a single memcpy call is issued to copy any number ofobjects). 2) Four CPU threads split the total number of objectsamong them and perform the copying with memcpy. 3) FourCPU threads split the total number of objects among thembut further divide their portion into multiple smaller blocksthat each thread will copy in a for loop (this is 4 CPUs-blocks in the figure). This way each memcpy call will copy asmaller buffer in each loop iteration instead of one big portionwhich can sometimes be more efficient. 4) The GPU performsthe copying using direct assignment (to_buffer[i] =from_buffer[i]) where each entry in the array is of sizeequal to 8 bytes (uint64t_t). 5) The GPU performs thecopying but we exclude the kernel launch overhead. This casecould represent future systems where the cost of launchingkernels is negligible.
For GPU copying, the GPU kernel is launched with as manythreads as there are objects to copy; hence, the launched kernelwill utilize up to all of the 6 Compute Units (CU) available.There are 384 SIMD (Single Instruction Multiple Data) laneswithin these CUs, and these lanes can be used simultaneously.Each GPU thread in a kernel copies 8 Bytes of data. So, if welaunched, for example, 1024 GPU threads, we will copy 8KBof data simultaneously (of course, we are still limited by thephysical SIMD lanes available, but all of the threads will beready to run hiding the memory latency of accesses [8]).
There are two main insights which can be drawn fromthe results in figure 4. First, if we do not consider thecost of launching GPU kernels, using the GPU to performobject copying provides the best bandwidth utilization. Objectcopying consists of simple operations for reading from andwriting to memory addresses. GPUs excel at hiding the latencyof memory accesses and can launch thousands of threads toperform the copying. CPUs, however, have to rely on limited-
width SIMD instructions (when using memcpy) which cannotseem to fully utilize the available bandwidth when copyingdata.
The second insight is that the GPU (including the launchoverhead) only becomes better than the CPU when copyingmany objects (and hence large data sizes). The GPU exceedssingle CPU thread copying at 64K objects (512KB), and itonly becomes better than four CPU threads at 128K (1 MB).Although the GPU might not offer a substantial bandwidthadvantage except for relatively larger data copies, it could stillbe used as an alternative processor to perform the copying.Therefore, having a GPU on board could still be favourableas the CPU becomes available for other more complex com-putations.
2) Offloading Promotional Object Copying to the GPU:To further analyze offloading object copying, we targetedheap object copying during the promotion phase of a parallelgenerational garbage collector. The promotion phase copies alllive objects from the young generation to the old generation.Object copying from young to old generation occurs when theyoung generation becomes full of live objects that cannot becollected, so they need to be copied to the old generation. Wemodify OpenJDK’s Java 8 Hotspot parallel garbage collectorto use our HSA framework for launching GPU kernels thatperform object copying. We call this scheme ParallelGPU-Copy.
Our HSA framework allows us to target any garbage collec-tor, but for our tests in this section we augmented ParallelGCwith HSA for three main reasons. First, this collector is thedefault collector in Java 8, so we can compare our results whenoffloading to the GPU to the default collector performance.Second, ParallelGC is a stop-the-world collector, which makesthe implementation much easier. We will discuss later insection IV-B some of the issues with concurrent GCs. Finally,we targeted ParallelGC since it allows using multiple GCthreads, so we can verify that our HSA module enablesconcurrent kernel launches from multiple GC threads. Thisverification ensures that the implementation is thread-safe andguarantees the ability to launch GPU kernels concurrentlyfrom any JVM thread.
We wrote a Java micro-benchmark and run it using our mod-ified JVM (ParallelGPUCopy scheme) to test the performanceimpact of offloading the object copying tasks. This is similarto the experiment in figure 4 but applied to a real scenariointegrating the GPU copying functionality into the JVM usingour HSA module.
In order to create a scenario to test promotional objectcopying, we need to make sure that the benchmark keeps onallocating objects that remain to stay alive. A simple way todo this is by adding objects into a linked list. The micro-benchmark does this by specifying the total number of objectsto allocate and the size of objects. In the tests, a total amount ofdata equal to 4GB is allocated. So, the linked list will contain512K objects of size 8KB each, 256K objects of size 16K,128K objects of size 64K, and so on. The heap object graphin this application is not very parallelizable: the graph looks

0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
512K/8K
256K/16K
128K/32K
64K/64K
32K/128K
16K/256K
8K/512K
4K/1M
2K/2M
1K/4M
512/8M
Normalized
speedu
p
Numberofobjects/Objectsize
ParallelGC-4 ParallelGPUCopy-1 ParallelGPUCopy-4
Fig. 5: Normalized speedup comparing ParallelGC and Paral-lelGPUCopy for promotional object copying. Each collectoris configured to use either 1 CPU thread, or 4 CPU threads.In the case of multiple threads, GPU kernels are launchedconcurrently from threads.
like a linked list which has minimal parallelization advantage;However the objects will remain alive as they won’t be quicklyorphaned and hence would continuously be promoted to theold generation. The microbenchmark is intentionally designedto stress such behaviour so that the potential of using the GPUto do the object copying during promotion is analyzed.
We compare four garbage collectors: 1) the baseline is thedefault single threaded ParallelGC, 2) a 4-thread ParallelGCwhich only uses the CPU cores, 3) ParallelGPUCopy with asingle thread performing copy operations on the GPU, and 4)a 4-thread version of ParallelGPUCopy where multiple threadslaunch GPU kernels concurrently. Figure 5 shows the speedupof the collectors over the baseline. The x-axis shows both thetotal number of object and the size of each object. The totalnumber of objects is 4GB divided by the size of the object(we allocate a total of 4GB in each case). For smaller objectsizes, the GPU is inferior as was demonstrated in the earlierexperiments. As the number of objects to be copied exceeds32K (128KB), we start to gain performance improvementscompared to the baseline single CPU copying.
An important difference between the setup of the experimenthere and the previous experiment (figure 4) is that the HSAmodule is used in isolation outside the JVM in the previousexperiment; therefore, there are no other JVM activities whichmight indirectly affect object copying. Here (figure 5), theHSA module is integrated within the JVM, and the objectcopying kernel is called from within the JVM by the GCthreads that are performing the promotions of live objects.
Although the trends in both experiments are the same,we notice that there is a slightly lower advantage to GPUcopying when applied inside the JVM. The reason for this issubtle and has to do with synchronization. The JVM launches
2279.4 2289.3
1710.0 1715.0
2.6 2.5
0
500
1000
1500
2000
2500
ParallelGPUCopy ParallelGC
Tim
e (s
ec.)
Total App. time Total GC time Avg. pause time
Fig. 6: Performance of GraphChi with object copying of-floaded to the GPU compared to default ParallelGC.
many threads to handle various activities. One of the corethreads is the thread responsible for orchestrating a so-called”safe point”. A safe point is required, for example, when allapplication threads need to come to a stop to perform a stop-the-world phase in any garbage collector (this not specificto ParallelGC and is also applicable to G1GC during theyoung evacuation pause where live objects get copied to otherregions). After the GC threads finish their tasks, they haveto communicate with the VM thread to indicate that they aredone. This synchronization may take an unpredictable amountof time. So even though the GC threads using the GPU forcopying may be done sooner than their CPU counterparts, theystill have to wait for the VM ”safe point” enforcer thread toallow them to proceed, and so the overall advantage of fastercopying is dampened.
Although object copying is a major performance bottleneckduring GC cycles for “big data” applications, as shown inprior work [12] and reconfirmed here, applications need togenerate lots of live and relatively large data objects to reapany benefits of GPU copying. One application in our study,GraphChi, possesses this property and in the following sectionwe examine it further.
3) Further Investigation of GraphChi: We further testedGraphChi under ParallelGPUCopy to see if there are anybenefits to offloading object copying. GraphChi uses a lot ofbig objects which makes it a good candidate application totest the offloading of copying to the GPU as opposed to theDaCapo applications. In the promotional object copy code inthe JVM, we only use the GPU for copying objects with sizesgreater than or equal to 32KB 2. So, all smaller object sizeswill be copied using the CPU.
When we profiled GraphChi, we observed that more than5K objects with sizes greater than 32KB are promoted during
2We tested several values for this threshold including 64K, 128K, and 1M,and there wasn’t a significant difference in performance.

the execution of the application. The average size of theseobjects is 3.26MB (GraphChi is memory intensive, so weuse a heap size of 6GB in this experiment to pressure theJVM to start GC cycles). Therefore, such statistics fit wellfor having the copying offloaded to the GPU. However, theresults shown in figure 6 do no show any substantial benefitsfor such offloading. GraphChi spends a lot of time in GC,with object copying being the most significant portion ofits time. From figure 4, we see that we can copy objectsizes of around 3MB at 6GB/s using the GPU compared to4GB/s using 4 CPUs. So, theoretically (not considering anyother JVM side effects), we should expect to speedup thecopying of these large objects at a rate of 1.5x. However, thisimprovement of object copying time does not translate intoany significant total run or pause time reduction because ofthe JVM synchronization we described earlier.
B. Investigating the Offloading Potential of the MarkingPhase
Marking is the process of traversing the live heap objectgraph from the roots and setting a bit to identify that an objectis ”marked”. The object graph may keep on evolving as newobjects are created, or new links between objects are modified.Marking can either be done in a stop-the-world fashion orconcurrently with application threads. Concurrent markingis more complex as application threads may continuouslymutate the shape of the object graph by adding, modifying, orremoving references to and from objects.
GPUs have been demonstrated to work well with somegraph algorithms such as breadth-first search (BFS). Markingis essentially a BFS process on a possibly morphing graphstructure. In order to assess the practicality of offloadingmarking to the GPU using our HSA framework, we usedmicrobenchmarks to model object graphs with varying shapes.We first explore stop-the-world marking and then concurrentmarking.
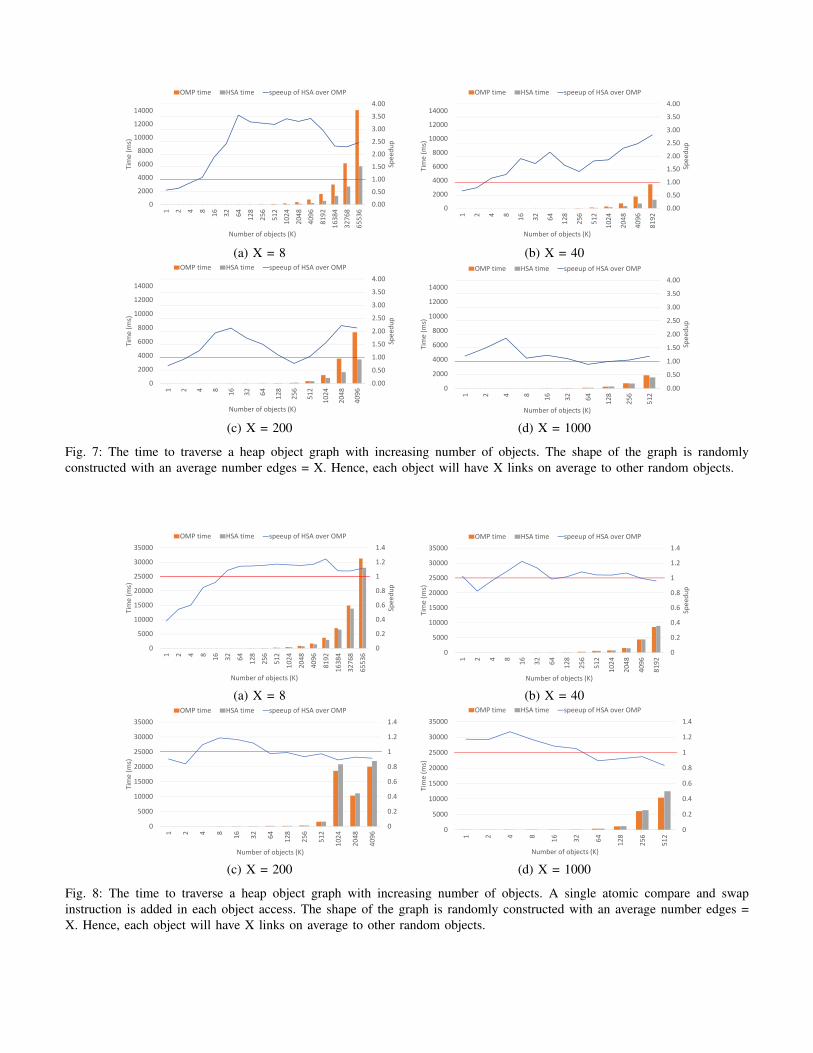
1) Stop-The-World Marking: Figure 7 shows the resultsfrom performing the marking phase on four different graphheap shapes represented by a variable ’X’ that indicates theaverage number of edges among nodes (or objects). The shapesrange from sparsely distributed objects with few connections(less marking work) to more densely packed connectionsamong objects (more marking work). These tests emulate astop-the-world marking since there are no mutator threadsmodifying objects. Hence, the assumption in these tests is thatthe garbage collector is the sole entity modifying (marking)the graph. The shapes in each example in the figure arestatic and do not change throughout the execution of themarking phase. However, looking at the different shapes givesan estimate on how good offloading the marking phase is.In these experiments, two variables control the shape ofthe object graph. The first variable is the total number ofobjects (nodes) that will be created. The second variable isthe connectivity level between these objects, or the averagenumber of links (edges) between objects. The object graph isconstructed randomly using these two variables, and the result
is a random graph shape which represents a live object graphthat is traversed from the roots.
We compare the performance of our HSA framework to anOpenMP version performing the heap traversals on the CPUusing all available cores. The results show that dependingon the object graph shape, a potential speedup of 3.5x isattainable by offloading the marking phase to the GPU. Ofcourse, as the graph becomes denser and less parallelizable,this potential diminishes as can be seen in figure 7d. Real-world applications produce object graphs of varying dynamicshapes with a changing level of parallelizing potential. So,our results show an upper bound on the maximum attainablespeedup on the integrated system used in this paper.
2) Concurrent Marking: The previous results do not con-sider the case of concurrent marking. Concurrent markingrequires atomic operations to ensure that mutator threads donot conflict with marking threads when they need to modifyreferences simultaneously. Figure 8 shows the same experi-ments shown in figure 7 but with atomically marking objectsfrom the GPU. We use an atomic compare and exchangeoperation that is available for use in HSA and allows for acoherent CPU-GPU view and atomicity of the data that willbe accessed. Concurrent marking using only CPU threads usesthis atomic operation to update the mark bit when traversingobjects. Hence, we apply the same technique for concurrentCPU-GPU marking. However, the cost of such operation isprohibitive. We can see from the figure that the use of atomicoperations quickly diminishes the benefits that were observedby the results in figure 7. For these graphs, the performancefrom atomically marking objects on the GPU is 6.5x sloweron average than non-atomic accesses; atomic marking onthe CPU, however, is around 4.1x slower than non-atomicmarking.
C. Programmability Challenges for Offloading Garbage Col-lection
One of our main concerns while investigating the potentialof offloading garbage collection was programmability. In ourprevious work [14], we concluded that HSA would providethe easiest (highest programmable) platform for seamlessintegration between CPU and GPU code. However, we raninto some compatibility issues.
There are several challenges when it comes to trying tooffload some of the GC work to the integrated GPU. Althoughwe have a unified memory view from both CPU and GPUthreads, there are still some software/programmability limi-tations. For example, GPU kernels are written in OpenCL.These kernels are compiled using a C compiler and do notknow anything about the many classes and functions used inthe JVM.
It is not possible to simply pass objects of specific types toGPU kernels to work on them on the GPU. However, the GPUcan access the same address space as the CPU and can access(read and write) any memory location that is passed to it. Forexample, let’s say that we decided to offload a specific functionin the JVM GC code where this function manipulates some
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
4.00
0
2000
4000
6000
8000
10000
12000
14000
1 2 4 8 16 32 64 128
256
512
1024
2048
4096
8192
1638
4
3276
8
6553
6
Spee
dup
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
4.00
0
2000
4000
6000
8000
10000
12000
14000
1 2 4 8 16 32 64 128
256
512
1024
2048
4096
8192
Spee
dup
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
(a) X = 8 (b) X = 40
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
4.00
0
2000
4000
6000
8000
10000
12000
14000
1 2 4 8 16 32 64 128
256
512
1024
2048
4096
Spee
dup
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
4.00
0
2000
4000
6000
8000
10000
12000
14000
1 2 4 8 16 32 64 128
256
512
Spee
dup
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
(c) X = 200 (d) X = 1000
Fig. 7: The time to traverse a heap object graph with increasing number of objects. The shape of the graph is randomlyconstructed with an average number edges = X. Hence, each object will have X links on average to other random objects.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0
5000
10000
15000
20000
25000
30000
35000
1 2 4 8 16 32 64 128
256
512
1024
2048
4096
8192
1638
4
3276
8
6553
6
Spee
dup
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0
5000
10000
15000
20000
25000
30000
35000
1 2 4 8 16 32 64 128
256
512
1024
2048
4096
8192
Spee
dup
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
(a) X = 8 (b) X = 40
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0
5000
10000
15000
20000
25000
30000
35000
1 2 4 8 16 32 64 128
256
512
1024
2048
4096
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0
5000
10000
15000
20000
25000
30000
35000
1 2 4 8 16 32 64 128
256
512
Tim
e (m
s)
Number of objects (K)
OMP time HSA time speeup of HSA over OMP
(c) X = 200 (d) X = 1000
Fig. 8: The time to traverse a heap object graph with increasing number of objects. A single atomic compare and swapinstruction is added in each object access. The shape of the graph is randomly constructed with an average number edges =X. Hence, each object will have X links on average to other random objects.

class objects. If the class is not a simple class (i.e, it containsvirtual methods and uses inheritance), we cannot manipulateobjects of this class on the GPU. In other words, we won’tbe able to perform parallel work on the GPU where we canmodify or use these objects. So, we have to overlay the datastructures that we need when offloading in a way where wecan easily manipulate them when running on the GPU. Thisproved to be very tedious and error-prone.
Although with HSA ”a pointer is a pointer” on both theCPU and the GPU, passing a pointer to a complex C++ classobject does not allow us to seamlessly manipulate this objecton the GPU. Although compiler toolchains such as HCC [2],[3] allow the offloading of parallel work using HSA fromwithin C++ code, it is not compatible with the JVM. We triedto compile the JVM using HCC (which is LLVM-based) butfailed to produce a successfully built JVM.
Therefore, it is essential to identify and be able to manipu-late and represent all relevant data structures and functionsfor a specific task to be able to use them on the GPU.However, we have found that the engineering effort requiredto convert GC code to run on GPU is massive. Current GPUprogramming frameworks don’t provide a clean and easy wayof manipulating JVM C++ objects on the GPU side. Althoughother frameworks exist which might improve programmabilitysuch as SYCL [4], [5], we are not aware of their compatibilitywith the JVM on our testing platform, so we leave theirinvestigation for a future work.
V. RELATED WORK
The idea of offloading garbage collection to specializedprocessors has been explored in a number of previous works.GPUs were first proposed to run garbage collection tasksin [24]. The patent only provides a general description ofcoordinating garbage collection between a CPU and GPU, andsuggests that the GPU is a potential candidate for offloadingsuch a task since it is highly parallel. There are no design andimplementation details to verify these claims. Furthermore, theauthors in [38] provide an implementation of a stop-the-worldmark and sweep garbage collector for the GPU. They onlyprovide a garbage collector for GPU tasks, and do not offloada garbage collector to the GPU. In other words, they provide animplicit (or managed) memory management for GPU memoryallocations, which is different that what we propose.
Two related works tried to accelerate the marking phaseof a stop-the-world serial garbage collection on integratedbut old systems that did not have the utilities of unifiedmemory [30], [33]. They had to overcome the shortcomingsof these systems by creating a copy of the heap object graphthat is kept consistent between the CPU and the GPU. Also,they only accelerated part of the marking phase of SerialGCand only considered Dacapo benchmarks. Our analysis andsolution in this work is different in that we try to see ifthe programmability advantage of unified-memory integratedsystems allows us to create a general framework for offloadingany tasks in GC without any custom workarounds.
One further work explored the scheduling of garbagecollection on heterogeneous multicore systems [7]. To ourknowledge, this is the only work that explored distributingconcurrent garbage collection tasks between two types ofprocessors. However, their system is a single-ISA bigLittlearchitecture where the same type of CPU cores exist but asubset of the cores is in-order and low-power, and the otheris out-of-order with higher performance. Therefore, the aimof their work is to choose where to run garbage collectionbased on metrics that measure the criticality of GC. Ourwork is different as we aim to offload parallel phases ofgarbage collection to an accelerator (GPU), which presentsmany programmability challenges as opposed to single-ISAsystems.
GPUs have been used to accelerate general tasks that sharesome behaviors with garbage collation tasks. For example,graph traversals have been shown to provide good perfor-mance when accelerated on GPUs [27], [32]. These worksuse elaborate techniques to demonstrate the usefulness ofperforming graph operations on GPU. We, however, exploreunified integrated systems where one can simply utilize theGPU to perform basic graph operations such as BFS, whichis the main component during the marking phases in GC.
There is a large body of works that provide general analysisof garbage collection such as [10], [21], [23], [39]. In our workwe provide experimentation and analysis relevant to our testingplatform. Furthermore, there is a number of related works thattarget redesigning garbage collection algorithms to adapt themto specific types of applications such as big data [12], [28],[29], [35], or specific hardware such as NUMA systems [18]–[20].
VI. CONCLUSION
In this paper, we looked at a number of aspects of garbagecollection and investigated the possibility of offloading sucha subsystem from a programmability perspective on a hetero-geneous platform. Programming languages and runtimes willhave to utilize the heterogeneity of such platforms. Therefore,we presented a case study of such integration by implementinga module that is integrated into the JVM for general purposeoffloading of parallel tasks from within the JVM. We used thismodule to offload some garbage collection tasks to study theviability of such offloading.
We conclude that non-optimized (having programmabilityin mind) GPU offloading of parallel garbage collection tasksdoes not yield any performance benefits on current integratedCPU-GPU systems. Although previous work has shown somepromising results for running the marking phase of garbagecollection on GPUs, they rely on custom solutions that arespecifically tailored to certain systems and collectors. Thereis still a lot of limitations both in software and hardwarewhich inhibit any benefits from trying to accelerate garbagecollection tasks on integrated CPU-GPU systems. Althoughthere might not be any performance advantage for GC, usingthe GPU as an additional processor might still be useful forother tasks.

REFERENCES
[1] HSA Foundation. http://www.hsafoundation.com/standards/.[2] HCC : An open source C++ compiler for heterogeneous devices. https:
//github.com/RadeonOpenCompute/hcc.[3] AMD ROCm Open Software Platform. https://github.com/
RadeonOpenCompute/ROCm.[4] SYCL, Khronos Group. https://www.khronos.org/sycl/.[5] hipSYCL - a SYCL implementation for CPUs and GPUs. https://github.
com/illuhad/hipSYCL.[6] Matthew Agostini, Francis O’Brien, and Tarek Abdelrahman. Balancing
graph processing workloads using work stealing on heterogeneous cpu-fpga systems. In 49th International Conference on Parallel Processing-ICPP, pages 1–12, 2020.
[7] Shoaib Akram, Jennifer B Sartor, Kenzo Van Craeynest, Wim Heirman,and Lieven Eeckhout. Boosting the priority of garbage: Schedulingcollection on heterogeneous multicore processors. ACM Transactionson Architecture and Code Optimization (TACO), 13(1):4, 2016.
[8] Michael Bauer, Sean Treichler, and Alex Aiken. Singe: leveraging warpspecialization for high performance on gpus. In Proceedings of the19th ACM SIGPLAN symposium on Principles and practice of parallelprogramming, pages 119–130. ACM, 2014.
[9] Andrzej Białecki, Robert Muir, Grant Ingersoll, and Lucid Imagination.Apache lucene 4. In SIGIR 2012 workshop on open source informationretrieval, page 17, 2012.
[10] Stephen M Blackburn, Perry Cheng, and Kathryn S McKinley. Mythsand realities: The performance impact of garbage collection. ACMSIGMETRICS Performance Evaluation Review, 32(1):25–36, 2004.
[11] Stephen M Blackburn, Robin Garner, Chris Hoffmann, Asjad M Khang,Kathryn S McKinley, Rotem Bentzur, Amer Diwan, Daniel Feinberg,Daniel Frampton, Samuel Z Guyer, et al. The dacapo benchmarks:Java benchmarking development and analysis. In ACM Sigplan Notices,volume 41, pages 169–190. ACM, 2006.
[12] Rodrigo Bruno, Luıs Oliveira, and Paulo Ferreira. Ng2c: Pretenuringn-generational gc for hotspot big data applications. arXiv preprintarXiv:1704.03764, 2017.
[13] Mayank Daga and Mark Nutter. Exploiting coarse-grained parallelismin b+ tree searches on an apu. In High Performance Computing,Networking, Storage and Analysis (SCC), 2012 SC Companion:, pages240–247. IEEE, 2012.
[14] Mohammad Dashti and Alexandra Fedorova. Analyzing memory man-agement methods on integrated cpu-gpu systems. In ACM SIGPLANInternational Symposium on Memory Management (ISMM), pages 59–69. ACM, 2017.
[15] Robert H Dennard, Fritz H Gaensslen, V Leo Rideout, Ernest Bassous,and Andre R LeBlanc. Design of ion-implanted mosfet’s with very smallphysical dimensions. IEEE Journal of Solid-State Circuits, 9(5):256–268, 1974.
[16] David Detlefs, Christine Flood, Steve Heller, and Tony Printezis.Garbage-first garbage collection. In Proceedings of the 4th internationalsymposium on Memory management, pages 37–48. ACM, 2004.
[17] Hadi Esmaeilzadeh, Emily Blem, Renee St Amant, Karthikeyan Sankar-alingam, and Doug Burger. Dark silicon and the end of multicore scaling.In ACM SIGARCH Computer Architecture News, volume 39, pages 365–376. ACM, 2011.
[18] Lokesh Gidra, Gael Thomas, Julien Sopena, and Marc Shapiro. Assess-ing the scalability of garbage collectors on many cores. In Proceedings ofthe 6th Workshop on Programming Languages and Operating Systems,page 7. ACM, 2011.
[19] Lokesh Gidra, Gael Thomas, Julien Sopena, and Marc Shapiro. A studyof the scalability of stop-the-world garbage collectors on multicores. InACM SIGPLAN Notices, volume 48, pages 229–240. ACM, 2013.
[20] Lokesh Gidra, Gael Thomas, Julien Sopena, Marc Shapiro, and NhanNguyen. Numagic: a garbage collector for big data on big numamachines. In ACM SIGARCH Computer Architecture News, volume 43,pages 661–673. ACM, 2015.
[21] Matthew Hertz and Emery D Berger. Quantifying the performance ofgarbage collection vs. explicit memory management. In ACM SIGPLANNotices, volume 40, pages 313–326. ACM, 2005.
[22] Matthew Hertz, Yi Feng, and Emery D Berger. Garbage collectionwithout paging. In ACM SIGPLAN Notices, volume 40, pages 143–153. ACM, 2005.
[23] Ahmed Hussein, Mathias Payer, Antony Hosking, and Christopher AVick. Impact of gc design on power and performance for android.In Proceedings of the 8th ACM International Systems and StorageConference, page 13. ACM, 2015.
[24] Azeem S Jiva and Gary R Frost. Gpu assisted garbage collection,October 30 2012. US Patent 8,301,672.
[25] Aapo Kyrola, Guy Blelloch, and Carlos Guestrin. Graphchi: Large-scale graph computation on just a {PC}. In Presented as part ofthe 10th {USENIX} Symposium on Operating Systems Design andImplementation ({OSDI} 12), pages 31–46, 2012.
[26] Henry Lieberman and Carl Hewitt. A real-time garbage collector basedon the lifetimes of objects. Communications of the ACM, 26(6):419–429,1983.
[27] Hang Liu and H Howie Huang. Enterprise: Breadth-first graph traversalon gpus. In High Performance Computing, Networking, Storage andAnalysis, 2015 SC-International Conference for, pages 1–12. IEEE,2015.
[28] Martin Maas, Krste Asanovic, Tim Harris, and John Kubiatowicz.Taurus: A holistic language runtime system for coordinating distributedmanaged-language applications. ACM SIGOPS Operating SystemsReview, 50(2):457–471, 2016.
[29] Martin Maas, Tim Harris, Krste Asanovic, and John Kubiatowicz. Trashday: Coordinating garbage collection in distributed systems. In HotOS,2015.
[30] Martin Maas, Philip Reames, Jeffrey Morlan, Krste Asanovic, An-thony D Joseph, and John Kubiatowicz. Gpus as an opportunity foroffloading garbage collection. In ACM SIGPLAN Notices, volume 47,pages 25–36. ACM, 2012.
[31] Simon Marlow, Tim Harris, Roshan P James, and Simon Peyton Jones.Parallel generational-copying garbage collection with a block-structuredheap. In Proceedings of the 7th international symposium on Memorymanagement, pages 11–20. ACM, 2008.
[32] Duane Merrill, Michael Garland, and Andrew Grimshaw. Scalable gpugraph traversal. In ACM SIGPLAN Notices, volume 47, pages 117–128.ACM, 2012.
[33] Rupesh Nasre et al. Fastcollect: offloading generational garbagecollection to integrated gpus. In Proceedings of the InternationalConference on Compilers, Architectures and Synthesis for EmbeddedSystems, page 21. ACM, 2016.
[34] Angeles Navarro, Francisco Corbera, Andres Rodriguez, AntonioVilches, and Rafael Asenjo. Heterogeneous parallel for templatefor cpu–gpu chips. International Journal of Parallel Programming,47(2):213–233, 2019.
[35] Khanh Nguyen, Lu Fang, Guoqing (Harry) Xu, Brian Demsky, ShanLu, Sanazsadat Alamian, and Onur Mutlu. Yak: A high-performancebig-data-friendly garbage collector. In OSDI, pages 349–365, 2016.
[36] Andres Rodrıguez, Angeles Navarro, Rafael Asenjo, Francisco Corbera,Ruben Gran, Darıo Suarez, and Jose Nunez-Yanez. Parallel multipro-cessing and scheduling on the heterogeneous xeon+ fpga platform. TheJournal of Supercomputing, pages 1–21, 2019.
[37] Kyle L Spafford, Jeremy S Meredith, Seyong Lee, Dong Li, Philip CRoth, and Jeffrey S Vetter. The tradeoffs of fused memory hierarchiesin heterogeneous computing architectures. In Proceedings of the 9thconference on Computing Frontiers, pages 103–112. ACM, 2012.
[38] Ronald Veldema and Michæl Philippsen. Iterative data-parallelmark&sweep on a gpu. In ACM SIGPLAN Notices, volume 46, pages1–10. ACM, 2011.
[39] Yang Yu, Tianyang Lei, Weihua Zhang, Haibo Chen, and Binyu Zang.Performance analysis and optimization of full garbage collection inmemory-hungry environments. In Proceedings of the12th ACM SIG-PLAN/SIGOPS International Conference on Virtual Execution Environ-ments, pages 123–130. ACM, 2016.
[40] Yuan Yuan, Meisam Fathi Salmi, Yin Huai, Kaibo Wang, Rubao Lee, andXiaodong Zhang. Spark-gpu: An accelerated in-memory data processingengine on clusters. In Big Data (Big Data), 2016 IEEE InternationalConference on, pages 273–283. IEEE, 2016.
[41] Matei Zaharia, Reynold S Xin, Patrick Wendell, Tathagata Das,Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, ShivaramVenkataraman, Michael J Franklin, et al. Apache spark: a unified enginefor big data processing. Communications of the ACM, 59(11):56–65,2016.