la langue comme capital
TRANSCRIPT

La langue comme capital. !!!!Frédéric Kaplan Digital Humanities Laboratory / EPFL / Suisse.

Résumé des épisodes précédents.



5
FREDERIC KAPLAN
Linguistic Capitalism andAlgorithmic Mediation
GO O G L E M A D E 50 B I L L I O N D O L L A R S in revenue in 2012, animpressive financial result for a company created less than fifteen year ago.1
That figure represents about 140 millions dollars per day, 5 million dollarsper hour. By the time you have finished reading this article (about sixminutes), Google will have made about 500,000 dollars. What does Googleactually sell to get such astonishing results? Words. Millions of words.
The success of Google’s highly original business model is the story of twoalgorithms. The first—pioneering a new way of associating web pages toqueries based on keywords—has made Google popular. The second—assigning a commercial value to those keywords—has made Google rich.
In 1998, search engines could be used to search for web pages contain-ing certain keywords, but they used inefficient and easily hackable rankingmethods, such as the number of occurrences of a search keyword withina page. Most of those methods were not scalable as the number of web pagesgrew.2 Larry Page, Google’s cofounder, designed an alterative computationof the relevance of search results by adapting a ranking principle that is wellestablished in the academic world: the most important documents are themost cited. He invented a recursive formulation of this principle by com-puting the value of a page based on the sum of the values of documentsciting it.3 Each citation behaved like a vote whose weight was proportional tothe number of citations of the citing document. With this voting principle,classification and search results kept improving as the World Wide Webcontinued to extend: the more documents, the finer the ranking. The rel-evance of the results provided rapidly outperformed the other major search
abstract Google’s highly successful business model is based on selling words that appear in searchqueries. Organizing several million of auctions per minute, the company has created the first globallinguistic market and demonstrated that linguistic capitalism is a lucrative business domain, one in whichbillions of dollars can be realized per year. Google’s services need to be interpreted form this perspective.This article argues that linguistic capitalism implies not an economy of attention but an economy of expression.As several million users worldwide daily express themselves through one of Google’s interfaces, the textsthey produce are systematically mediated by algorithms. In this new context, natural languages couldprogressively evolve to seamlessly integrate the linguistic biases of algorithms and the economicalconstraints of the global linguistic economy. Representations 127. Summer 2014 © The Regentsof the University of California. ISSN 0734-6018, electronic ISSN 1533-855X, pages 57–63. All rightsreserved. Direct requests for permission to photocopy or reproduce article content to the University ofCalifornia Press at http://www.ucpressjournals.com/reprintinfo.asp. DOI: 10.1525/rep.2014.127.4.57. 57

Vincent Buntinx
Dana Kianfar

Le capitalisme linguistique en 5 thèses.

Thèse 1 !
Le capitalisme linguistique est un nouveau régime économique caractérisé par la monétisation des langues au niveau mondial.

Google réalise 50 milliards de dollars par an * simplement en organisant la vente des mots à l’échelle planétaire. !
* 137 M / jour, 5+ M / heures
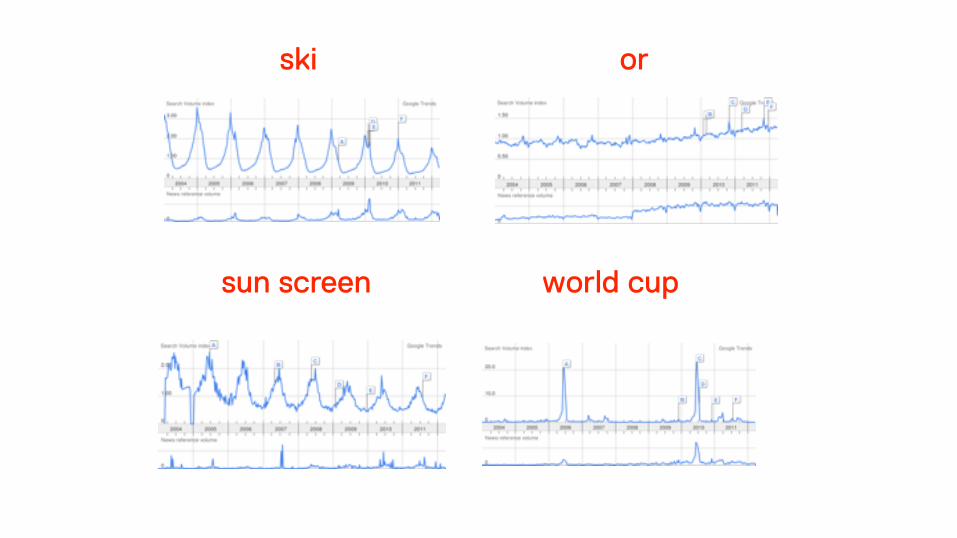
ski
sun screen
or
world cup

Thèse 2 !
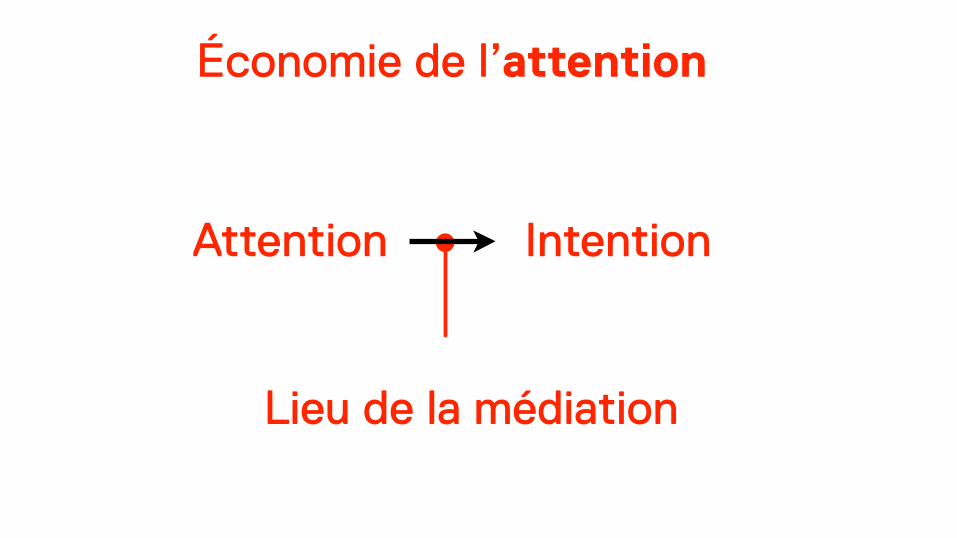
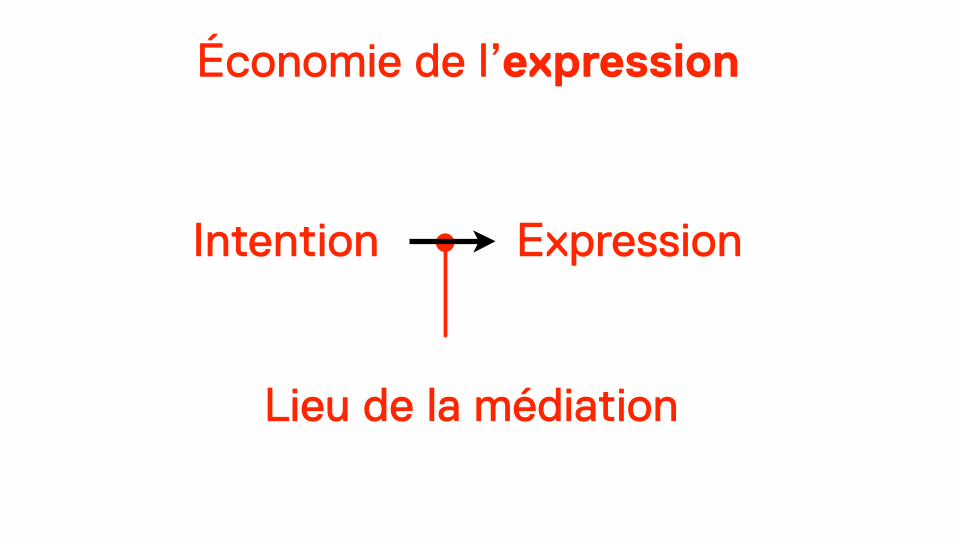
Le capitalisme linguistique n’est pas une économie de l’attention, mais une économie de l’expression.
Attention Intention
Économie de l’attention
Lieu de la médiation
Intention Expression
Économie de l’expression
Lieu de la médiation

Dans une économie de l’expression, il faut développer des relations linguistiques intimes et durables avec un grand nombre d’utilisateurs, pour pouvoir modéliser et infléchir la langue.

Nous sommes déjà des millions à nous exprimer tous les jours au travers des prothèses linguistiques de Google : Google docs, Gmail, Google+ …

Thèse 3 !
Le capitalisme linguistique tend à optimiser la langue pour la faire entrer dans son domaine commercialement exploitable.


Quand Google corrige à la volée un mot que vous avez mal orthographié, il transforme un matériau sans valeur en une ressource économique potentiellement rentable.

Quand Google prolonge une phrase que vous avez commencée à taper, il ramène votre expression dans le domaine de la langue qu’il peut exploiter.

la langue exploitable
commercialement
la langue vivante

L’autocompletion s’est aujourd’hui généralisée sur presque toutes les interfaces de saisie.

Thèse 4 !
La langue exploitable commercialement est une langue prédictible par les algorithmes.

La langue prédictible sert non seulement à l’autocompletion mais aussi à proposer de nouveaux services linguistiques (traduction automatique, écriture automatique)

L’objectif du capitalisme linguistique est donc de régulariser la langue pour maximiser son potentiel économique.

Thèse 5 !
Dans le capitalisme linguistique, la langue est un capital.

Les acteurs du capitalisme linguistique tendent à engranger un capital fait de modèles toujours plus vastes de la langue prédictible.

Ce capital se transforme en produits et services de médiation linguistique qui à leur tour génèrent plus de capital linguistique.

Parallèlement, par l’organisation de la vente des mots, le capital linguistique en croissance est convertible en capital économique.

Capital linguistique de langue prédictible
Extension des services de médiation
linguistique
Capital linguistique de langue prédictible
plus étendu
Capital économique Capital économique plus étendu

Ce nouveau contexte économique et technique est susceptible d’être à la base d’une transformation linguistique majeure.

Il convient de distinguer les ressources linguistiques primaires produites sans médiation algorithmique (conversations écrites, contenus de livres numérisés, etc.) …

… des resources linguistiques secondaires produites comme transformations algorithmiques de ressources primaires.

Par exemple, les algorithmes de traduction automatique permettent de transformer le capital linguistique d’une langue en une autre.

Ils ont une double importance économique car ils proposent des services linguistiques précieux et ils décuplent le capital linguistique accumulé.

Mais cette intermédiation algorithmique n’est pas sans effet.
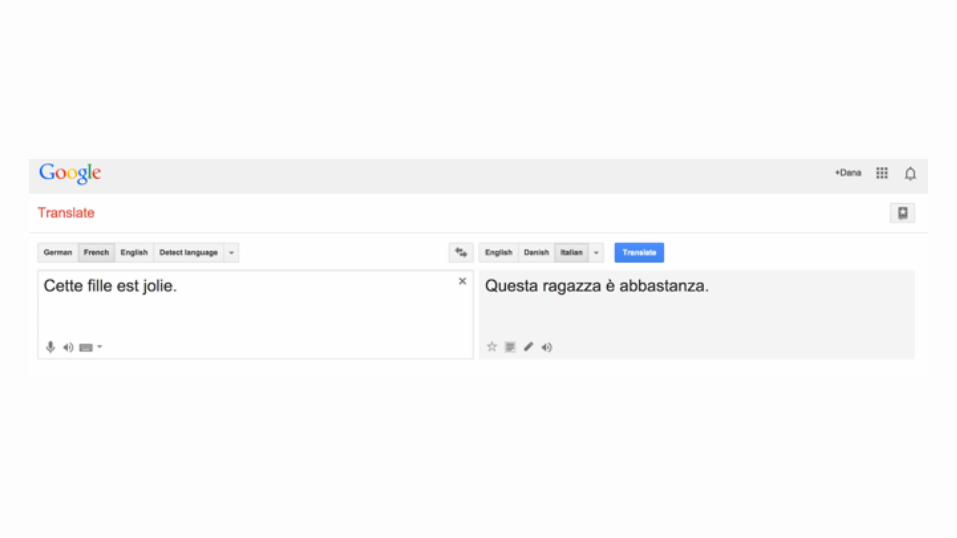

Pour traduire deux langues européennes, l’anglais est souvent utilisé comme langue pivot.
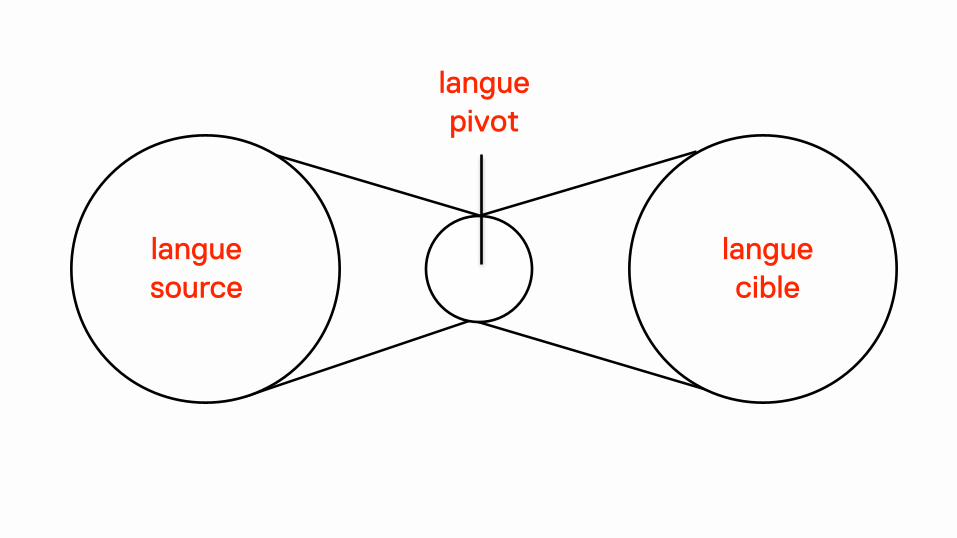
langue source
langue cible
langue pivot

Le biais culturel d’un tel procédé est évidemment important. Le Français et l’Italien sont des langues relativement proches. !En comparaison, l’anglais est une langue particulière, compacte, idiomatique. !Projeter vers l’espace anglophone puis reprojeter vers une langue cible induit des effets linguistiques et culturels qu’il faut étudier.

Dans le cadre du capitalisme linguistique, l’impérialisme linguistique de l’anglais a donc des effets beaucoup plus subtils que ne le laisseraient penser les approches qui n’étudient que la “guerre des langues”. !Le fait de pivoter par une langue conduit à introduire dans les autres langues des logiques linguistiques propres et donc insensiblement des modes de pensée spécifiques.

À l’échelle mondiale, c’est un réseau de chaines de traduction qui est en train de se mettre en place et qui impose parfois, pour traduire une expression d’une langue à une autre, de pivoter par une série de langues intermédiaires.

Dans d’autres cas, le capital linguistique sert à produire des contenus textuels inédits.

Show and Tell: A Neural Image Caption Generator
Oriol VinyalsGoogle
Alexander ToshevGoogle
Samy BengioGoogle
Dumitru ErhanGoogle
Abstract
Automatically describing the content of an image is afundamental problem in artificial intelligence that connectscomputer vision and natural language processing. In thispaper, we present a generative model based on a deep re-current architecture that combines recent advances in com-puter vision and machine translation and that can be usedto generate natural sentences describing an image. Themodel is trained to maximize the likelihood of the target de-scription sentence given the training image. Experimentson several datasets show the accuracy of the model and thefluency of the language it learns solely from image descrip-tions. Our model is often quite accurate, which we verifyboth qualitatively and quantitatively. For instance, whilethe current state-of-the-art BLEU score (the higher the bet-ter) on the Pascal dataset is 25, our approach yields 59, tobe compared to human performance around 69. We alsoshow BLEU score improvements on Flickr30k, from 55 to66, and on SBU, from 19 to 27.
1. IntroductionBeing able to automatically describe the content of an
image using properly formed English sentences is a verychallenging task, but it could have great impact, for instanceby helping visually impaired people better understand thecontent of images on the web. This task is significantlyharder, for example, than the well-studied image classifi-cation or object recognition tasks, which have been a mainfocus in the computer vision community [26]. Indeed, adescription must capture not only the objects contained inan image, but it also must express how these objects relateto each other as well as their attributes and the activitiesthey are involved in. Moreover, the above semantic knowl-edge has to be expressed in a natural language like English,which means that a language model is needed in addition tovisual understanding.
Most previous attempts have proposed to stitch togetherexisting solutions of the above sub-problems, in order to gofrom an image to its description [6, 15]. In contrast, we
A group of people shopping at an outdoor market. !There are many vegetables at the fruit stand.
Vision!Deep CNN
Language !Generating!
RNN
Figure 1. NIC, our model, is based end-to-end on a neural net-work consisting of a vision CNN followed by a language gener-ating RNN. It generates complete sentences in natural languagefrom an input image, as shown on the example above.
would like to present in this work a single joint model thattakes an image I as input, and is trained to maximize thelikelihood p(S|I) of producing a target sequence of wordsS = {S1, S2, . . .} where each word S
t
comes from a givendictionary, that describes the image adequately.
The main inspiration of our work comes from recent ad-vances in machine translation, where the task is to transforma sentence S written in a source language, into its transla-tion T in the target language, by maximizing p(T |S). Formany years, machine translation was also achieved by a se-ries of separate tasks (translating words individually, align-ing words, reordering, etc), but recent work has shown thattranslation can be done in a much simpler way using Re-current Neural Networks (RNNs) [3, 2, 29] and still reachstate-of-the-art performance. An “encoder” RNN reads thesource sentence and transforms it into a rich fixed-lengthvector representation, which in turn in used as the initialhidden state of a “decoder” RNN that generates the targetsentence.
Here, we propose to follow this elegant recipe, replac-ing the encoder RNN by a deep convolution neural network(CNN). Over the last few years it has been convincinglyshown that CNNs can produce a rich representation of theinput image by embedding it to a fixed-length vector, suchthat this representation can be used for a variety of visiontasks [27]. Hence, it is natural to use a CNN as an image“encoder”, by first pre-training it for an image classification
1
arX
iv:1
411.
4555
v1 [
cs.C
V]
17 N
ov 2
014
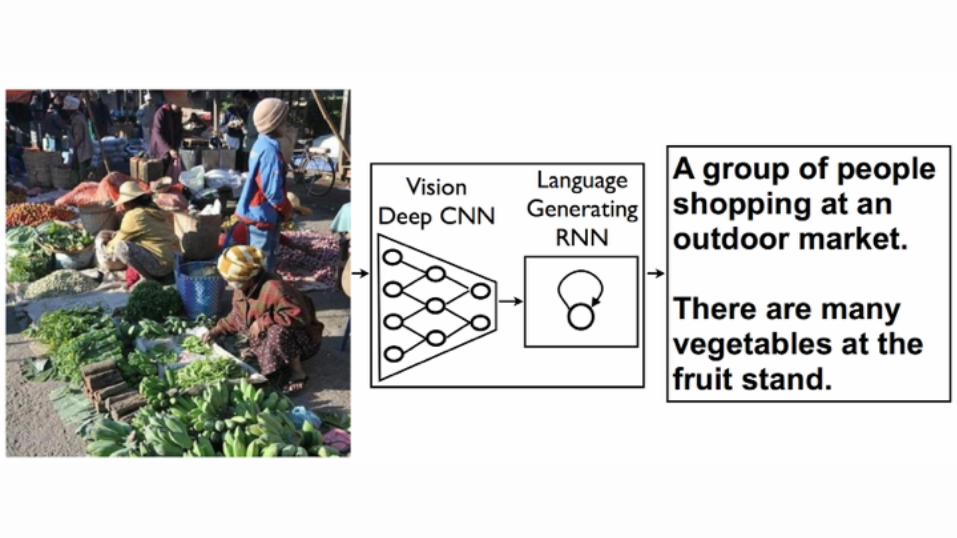


Ici le capital linguistique génère un extension linguistique artificielle, avec des expressions potentiellement inédites.

Pour juger la pertinence de ces expressions, des “armées” de juges humains doivent être recrutées.


La description systématique des images par des algorithmes peut être à l’origine d’un tsunami de nouvelles tournures linguistiques.

De plus en plus souvent, de telles ressources secondaires sont présentées comme des ressources primaires.


lsjbot Wikipedia bot auteur de 2.7M articles sur Wikipedia, 10K par jour

Les algorithmes qui analysent la langues ne font pas souvent la différence entre ces ressources secondaires et les ressources primaires.

Les nouvelles formes hybrides entrent ainsi dans le capital linguistique et seront peut-être un jour proposées comme suggestions ou corrections.

Nous sommes face à une nouvelle forme de “créolisation”.

Une prédiction !
Avec le développement général de l’autocompletion, il n’y aura plus d’ici 5 ans aucune nouvelle ressource primaire.

Scenario 1 !Cette évolution linguistique est globalement acceptée ou ignorée. !La langue predictible et économiquement exploitable converge avec la langue naturelle vers un nouveau créole. !Le capitalisme linguistique se développe et se complexifie pour devenir un des secteurs économiques les plus importants.

Scenario 2 !Suite à une prise de conscience et pour tenter d’inverser le phénomène, la médiation algorithmique est mieux comprise et labellisée. !Des “gisements” de ressources primaires (grandes bibliothèques numérisées) sont exploitées pour mieux detecter les phénomènes d’hybridation.

Scenario 2 (suite) !Dans l’objectif de comprendre et maitriser cette évolution, une nouvelle linguistique se développe. !Cette linguistique utilise massivement les algorithmes pour mieux comprendre et surveiller l’effet des algorithmes.
Frédéric Kaplan [email protected] @frederickaplan !http://dhlab.epfl.ch