expectation - maximization for text cassification
TRANSCRIPT

IntroduzioneModello generativo
Naive BayesEM
Risultati
EM per la classificazione del testo
Apprendimento AutomaticoAnno accademico 2014/2015
Federico D’Amato EM per la classificazione del testo 1/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
ProblemaCome funzionaAlgoritmoCaso base
Task: Classificazione automatica di documenti di testo
I Uso di un set di documenti etichettati (labeled) per allenareclassificatori
I Problema: per ottenere buoni classificatori, il train set di documentietichettati deve essere sufficientemente grande → COSTOSO
I Idea: aumentare la capacita di classificazione utilizzando anchedocumenti NON etichettati (unlabeled)
Federico D’Amato EM per la classificazione del testo 2/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
ProblemaCome funzionaAlgoritmoCaso base
I I documenti non etichettati portano informazioni sulle jointprobability tra parole di un documento
I In altre parole, aiutano a evidenziare le correlazioni tra parole didocumenti di una determinata classe
Federico D’Amato EM per la classificazione del testo 3/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
ProblemaCome funzionaAlgoritmoCaso base
I L’algoritmo utilizzato e Expectation-Maximization (EM). Essoprocede in 2 step principali:
1. Addestra un classificatore utilizzando solo i documenti labeled e usail classificatore ottenuto per assegnare un’etichetta probabilistica adognuno dei documenti unlabeled
2. Addestra un nuovo classificatore che usa sia i documenti labeled chequelli unlabeled e itera finche la likelihood aumenta
I Il risultato di EM e un classificatore i cui parametri massimizzanolocalmente la likelihood dei dati
Federico D’Amato EM per la classificazione del testo 4/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
ProblemaCome funzionaAlgoritmoCaso base
Supponiamo che gli elementi di 2 classi siano generati da 2 distribuzioniGaussiane, come mostrato in figura.
La figura mostra la soglia ottima d calcolata utilizzando la regola diBayes a partire da media e varianza delle due Gaussiane
Federico D’Amato EM per la classificazione del testo 5/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
ProblemaCome funzionaAlgoritmoCaso base
I A partire da un set di infiniti documenti unlabeled e possibilericostruire perfettamente le due Gaussiane
I Pero, non e possibile assegnare ad ognuna delle 2 Gaussiane unaclasse⇒ i documenti labeled vengono usati per determinare qualeGaussiana appartiene a quale classe
I IMPORTANTE: questo discorso dipende dall’assunzione forte che idati siano stati generati dallo stesso modello usato nellaclassificazione. In contesti reali questa assunzione e VIOLATA
Federico D’Amato EM per la classificazione del testo 6/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Il modello generativo dei dati che viene illustrato incorpora 2 assunzioni:
1. i dati sono generati da un mixture model
2. c’e una corrispondenza biunivoca tra classi e componenti dellamixture
La distribuzione di probabilita, parametrizzata da un insieme di parametriθ, consiste di una mixture di componenti
cj ∈ C = {c1, ..., c|C |}
Un documento di e generato
1. selezionando una componente cj della mixture in accordo con unacerta probabilita a priori P(cj |θ)
2. usando la componente selezionata per generare il documento inaccordo con i suoi parametri, con distribuzione P(di |cj ; θ)
Federico D’Amato EM per la classificazione del testo 7/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
La likelihood di un documento di viene espressa come
P(di |θ) =|C |∑j=1
P(cj |θ)P(di |cj ; θ)
Essendoci corrispondenza biunivoca tra classi e componenti della mixture,cj viene usata per indicare sia la j-esima classe che la j-esima componente
Federico D’Amato EM per la classificazione del testo 8/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Modello generativoTrainingClassificazioneImplementazione
Naive Bayes utilizza un particolare modello generativo, che e unaspecializzazione di quello a mixture. Oltre alle assunzioni gia discusse, neviene aggiunta un’altra:
I le parole di un documento sono indipendenti fra loro
Un documento di e costituito da una lista ordinata di parole
< wdi ,1,wdi ,2, ... >
dove le parole wt sono quelle di un dizionario V =< w1, ...,w|V | >.Quando un documento e generato da una particolare componente cj , lalunghezza del documento |di | e scelta indipendentemente dalla classe. Laprobabilita di un documento data una componente puo essere espressacome:
P(di |cj ; θ) = P(< wdi ,1, ...,wdi ,|di | > |cj ; θ) = P(|di |)|di |∏k=1
P(wdi ,k |cj ; θ)
Federico D’Amato EM per la classificazione del testo 9/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Modello generativoTrainingClassificazioneImplementazione
Assumendo che la lunghezza dei documenti sia identicamente distribuitaper tutte le classi, i parametri di interesse sono:
I θwt |cj = P(wt |cj ; θ) con t = {1, .., |V |}
I θcj = P(cj |θ)
Per cui l’insieme di parametri del modello, θ, e
θ = {θwt |cj : wt ∈ V , cj ∈ C ; θcj : cj ∈ C}
Federico D’Amato EM per la classificazione del testo 10/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Modello generativoTrainingClassificazioneImplementazione
L’addestramento di un classificatore Naive Bayes consiste nella stima deiparametri del modello generativo usando un set di documenti labeledD = {d1, ..., d|D|}. L’obiettivo del classificatore e trovare un insieme di
parametri θ tali che
θ = argmaxθP(θ|D)
La stima θwt |cj di θwt |cj e calcolata come:
θwt |cj =1+|D|∑i=1
N(wt ,di )P(yi=cj |di )
|V |+|V |∑s=1
|D|∑i=1
N(ws ,di )P(yi=cj |di )
La stima θcj di θcj e calcolata come:
θcj =1+|D|∑i=1
P(yi=cj |di )
|C |+|D|
Federico D’Amato EM per la classificazione del testo 11/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Modello generativoTrainingClassificazioneImplementazione
Una volta calcolata la stima θ dei parametri e possibile calcolare laprobabilita che una particolare componente cj abbia generato undocumento di dato:
P(yi = cj |di ; θ) =P(cj |θ)P(di |cj ;θ)
P(di |θ)=
P(cj |θ)|di |∏k=1
P(wdi ,k|cj ;θ)
|C|∑r=1
P(cr |θ)|di |∏k=1
P(wdi ,k|cr ;θ)
Se il task e quello di assegnare una singola classe al documento di test di ,allora viene selezionata la classe j con la maggiore probabilita aposteriori, ossia
argmaxjP(yi = cj |di ; θ)
Federico D’Amato EM per la classificazione del testo 12/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Modello generativoTrainingClassificazioneImplementazione
I Analizzando il termine|di |∏k=1
P(wdi ,k |cj ; θ) si puo capire che, essendo le
P(wdi ,k |cj ; θ) generalmente molto piccole, spesso la produttoriacausa underflow
I Per far fronte a questo problema, si pone
zj = log(P(cj |θ)) +|di |∑k=1
log(P(wdi ,k |cj ; θ))
In questo modo posso scrivere
P(yi = cj |di ; θ) = ezj|C|∑r=1
ezr
che ha la forma della funzione softmax. Il problema si ripresenta,poiche le zj tendono a −∞
Federico D’Amato EM per la classificazione del testo 13/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Modello generativoTrainingClassificazioneImplementazione
I Il trucco sta nel moltiplicare numeratore e denominatore per lastessa costante e−m, dove m = maxj zj . In questo modo i terminizj −m tenderanno ad essere vicini a 0. In definitiva si ottiene
P(yi = cj |di ; θ) = ezj−m
|C|∑r=1
ezr−m
Federico D’Amato EM per la classificazione del testo 14/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Basic EMLambda EMMultiple Mixture per class
EM: Schema Formale
I Input: un insieme D l di documenti labeled ed un insieme Du di documenti unlabeled
I Costruisci un classificatore Naive Bayes θ usando solo l’insieme dei documenti labeled D l
I Itera finche la stima dei parametri migliora, sulla base dei cambiamenti della log-likelihoodI (E-step) Usa il classificatore corrente θ per calcolare, per ogni documento di ∈ Du il
termine P(cj |di ; θ)I (M-step) Calcola un nuovo classificatore θ come risultato di argmaxθP(D|θ)P(θ)
I Output: un classificatore θ che, dato un documento unlabeled, ne predice la classe
Federico D’Amato EM per la classificazione del testo 15/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Basic EMLambda EMMultiple Mixture per class
I Quando il numero di documenti unlabeled e di gran lunga superiorea quello dei documenti labeled :
I EM effettua sostanzialmente unsupervised clustering, poiche la stimadei parametri deriva quasi interamenti dai documenti unlabeled
I I documenti labeled hanno il solo effetto di inizializzare i parametridel classificatore e di associare ad ogni componente della mixtureuna classe
I Quando le assunzioni del modello generativo non sono verificate, ilclustering ottenuto a partire dai soli documenti unlabeled puoprodurre componenti della mixture che non sono in corrispondenzacon le classi
I Inoltre, quando il numero di documenti labeled e sufficientementeelevato, l’influenza dei numerosi documenti unlabeled puopeggiorare la stima dei parametri
Federico D’Amato EM per la classificazione del testo 16/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Basic EMLambda EMMultiple Mixture per class
I Si introduce un nuovo parametro λ, con 0 ≤ λ ≤ 1 che riduce ilcontributo dei documenti unlabeled nella stima dei parametri.Definendo:
Λ(i) =
{λ if di ∈ Du
1 if di ∈ D l
si possono riscrivere le stime dei parametri come
θwt |cj =1+|D|∑i=1
Λ(i)N(wt ,di )P(yi=cj |di )
|V |+|V |∑s=1
|D|∑i=1
Λ(i)N(ws ,di )P(yi=cj |di )
θcj =1+|D|∑i=1
Λ(i)P(yi=cj |di )
|C |+|D l |+λ|Du|
Federico D’Amato EM per la classificazione del testo 17/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Basic EMLambda EMMultiple Mixture per class
I Questa variante di EM rilassa l’assunzione forte che ci sia unacorrispondenza uno-a-uno tra componenti della mixture e classi
I Viene usata una assunzione meno restrittiva: piu componenti dellamixture sono associate ad una singola classe
I Sia ta la a-esima classe e sia cj la j-esima componente della mixture,allora
P(ta|cj ; θ) ∈ {0, 1}e una mappatura tra componenti della mixture e classi che epredeterminata e deterministica.
Federico D’Amato EM per la classificazione del testo 18/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
Basic EMLambda EMMultiple Mixture per class
I M-Step: invariato
I E-Step: le probabilita P(cj |di ; θ) che in precedenza, per i documentilabeled, era fissata e ∈ {0, 1}, ora puo avere valori tra 0 e 1 per lecomponenti della mixture cj assegnate alla classe ta del documento
I Si noti che tutte le P(cj |di ; θ) per cui P(yi = ta|cj ; θ) = 0 sonofissate a 0, e le rimanenti sono normalizzate affinche sommino 1
I Le P(cj |di ; θ) sono inizializzate campionando da una distribuzione
uniforme per quelle componenti per cui P(yi = ta|cj ; θ) = 1
I La classificazione di un documento si ottiene da
P(ta|di ; θ) =∑cj
P(ta|cj ; θ)P(cj |θ)
|di |∏k=1
P(wdi ,k|cj ;θ)
|C|∑r=1
P(cr |θ)|di |∏k=1
P(wdi ,k|cr ;θ)
Federico D’Amato EM per la classificazione del testo 19/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Figure: Confronto di accuratezza nella classificazione tra Naive Bayes e EM neldataset 20 Newsgroups
Federico D’Amato EM per la classificazione del testo 20/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Figure: Confronto di accuratezza nella classificazione di EM al variare delnumero di documenti unlabeled nel dataset 20 Newsgroups
Federico D’Amato EM per la classificazione del testo 21/28
IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
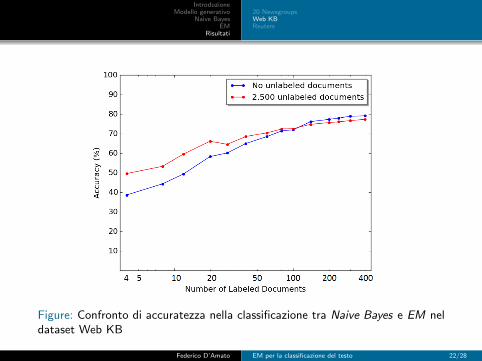
Figure: Confronto di accuratezza nella classificazione tra Naive Bayes e EM neldataset Web KB
Federico D’Amato EM per la classificazione del testo 22/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Figure: Scarto quadratico medio dell’accuratezza nella classificazione di NaiveBayes e di EM nel dataset Web KB
Federico D’Amato EM per la classificazione del testo 23/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Figure: Confronto di accuratezza nella classificazione di λ-EM al variare di λ
Federico D’Amato EM per la classificazione del testo 24/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Figure: Confronto di accuratezza nella classificazione tra Naive Bayes, EM eλ-EM (con λ cross-validato)
Federico D’Amato EM per la classificazione del testo 25/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Category NB1 NB2 NB3 NB4 NB5 NB10acq 76.4 80.0 81.3 81.5 82.2 81.3corn 46.4 46.8 50.2 45.9 46.1 43.3crude 61.1 68.7 67.3 67.8 69.9 69.2earn 89.5 90.0 90.0 90.2 89.0 89.1grain 66.3 67.1 67.7 67.9 65.9 66.3interest 61.7 63.1 62.2 59.9 62.3 57.6money-fx 70.6 66.1 68.5 67.7 68.0 62.1ship 53.6 57.7 52.9 55.1 52.6 48.2trade 62.1 64.3 65.2 60.5 61.2 60.3wheat 54.2 58.2 56.8 55.2 60.3 55.5
Tabella 1: Precision-Recall Breakeven Points dei classificatori binariottenuti usando Naive Bayes con un numero variabile di componenti perclasse
Federico D’Amato EM per la classificazione del testo 26/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Category EM1 EM2 EM3 EM4 EM5 EM10acq 88.9 90.6 90.1 90.6 91.0 90.8corn 46.8 50.2 47.8 50.4 49.5 42.1crude 66.1 68.4 72.2 74.3 70.2 66.6earn 91.8 92.3 92.1 92.6 91.6 91.6grain 67.8 69.1 69.5 65.4 67.7 67.9interest 59.6 60.3 63.9 61.2 58.9 58.8money-fx 72.3 66.5 69.8 64.1 68.9 62.7ship 58.9 57.1 60.0 57.3 55.3 55.9trade 59.9 60.6 64.9 64.6 61.8 59.4wheat 59.1 58.3 60.5 59.3 58.1 56.9
Tabella 2: Precision-Recall Breakeven Points dei classificatori binariottenuti usando EM con un numero variabile di componenti per classe
Federico D’Amato EM per la classificazione del testo 27/28

IntroduzioneModello generativo
Naive BayesEM
Risultati
20 NewsgroupsWeb KBReuters
Category NB1 NB* EM1 EM* EM* vs NB1 EM* vs NB*acq 76.4 82.2(5) 88.9 91.0(5) +14.6 +8.8corn 46.4 50.2(3) 46.8 50.4(4) +4.0 +0.2crude 61.1 69.9(5) 66.1 74.3(4) +13.2 +4.4earn 89.5 90.2(4) 91.8 92.6(4) +3.1 +2.4grain 66.3 67.7(3) 67.8 69.5(3) +3.2 +1.8interest 61.7 63.1(2) 59.6 63.9(3) +2.2 +0.8money-fx 70.6 70.6(1) 72.3 72.3(1) +1.7 +1.7ship 53.6 57.7(2) 58.9 60.0(3) +6.4 +2.3trade 62.1 65.2(3) 59.9 64.9(3) +2.8 -0.3wheat 54.2 60.3(5) 59.1 60.5(3) +6.3 +0.2
Tabella 3: Confronto finale tra Naive Bayes classico, Naive Bayesmulti-componente, EM ed EM multi-componente
Federico D’Amato EM per la classificazione del testo 28/28