ee 5359 multimedia processing spring 2011 final report fpga
TRANSCRIPT

EE 5359 MULTIMEDIA PROCESSING
SPRING 2011
Final Report
FPGA IMPLEMENTATION OF H.264 VIDEO ENCODER
Under guidance of
DR K R RAO
DEPARTMENT OF ELECTRICAL ENGINEERING
UNIVERSITY OF TEXAS AT ARLINGTON
SPRING 2011
Presented by
KUSHAL KUNIGAL
1000662485

Introduction:
This project presents a detailed study on H.264 video encoder and the algorithms for evaluating the
transform and quantization suitable for high speed implementation on FPGA/ASIC. Along with this,
detailed architectures of intra Prediction, integer transforms and quantization processors are presented.
Overview:
To achieve a real-time H.264 encoding solution, multiple FPGAs and programmable DSPs are often
used. The computational complexity alone does not determine if a functional module should be mapped
to hardware or remain in software. The architectural issues that influence the overall design decision are:
Data Locality: In a synchronous design, the ability to access memory in a particular order and
granularity while minimizing the number of clock cycles due to latency, bus contention, alignment,
DMA transfer rate and the types of memory used is very important. The data locality issue (Figure 1) is
primarily dictated by the physical interfaces between the data unit and the arithmetic unit (or the
processing engine) [2].
Fig 1: H.264 encoder block diagram [2].

Computational Complexity: Programmable DSPs are bounded in computational complexity, as
measured by the clock rate of the processor. Signal processing algorithms implemented in the FPGA
fabric are typically computationally-intensive. By mapping these modules onto the FPGA fabric, the
host processor or the programmable DSP has the extra cycles for other algorithms. Furthermore, FPGAs
can have multiple clock domains in the fabric, so selective hardware blocks can have separate clock
speeds based on their computational requirements [2].
Block diagram of H.264 advanced Video Encoder:
Fig.2 shows the block diagram of H.264 encoder. Therein the modules designed in this work are shown
in grey shades. An input frame or field Fn is processed in units of a macro block. A macro block consists
of 16x16 pixels. Each macro block is encoded in intra or inter mode and for each block in the macro
block, a prediction P is formed based on the reconstructed picture samples. In Intra mode, P is formed
from samples in the current slice that have been previously constructed. In inter mode, P is formed by
motion-compensated prediction from one or two reference picture(s) selected from the set of reference
pictures.
Fig 2: Modules in H.264 video encoder [3].
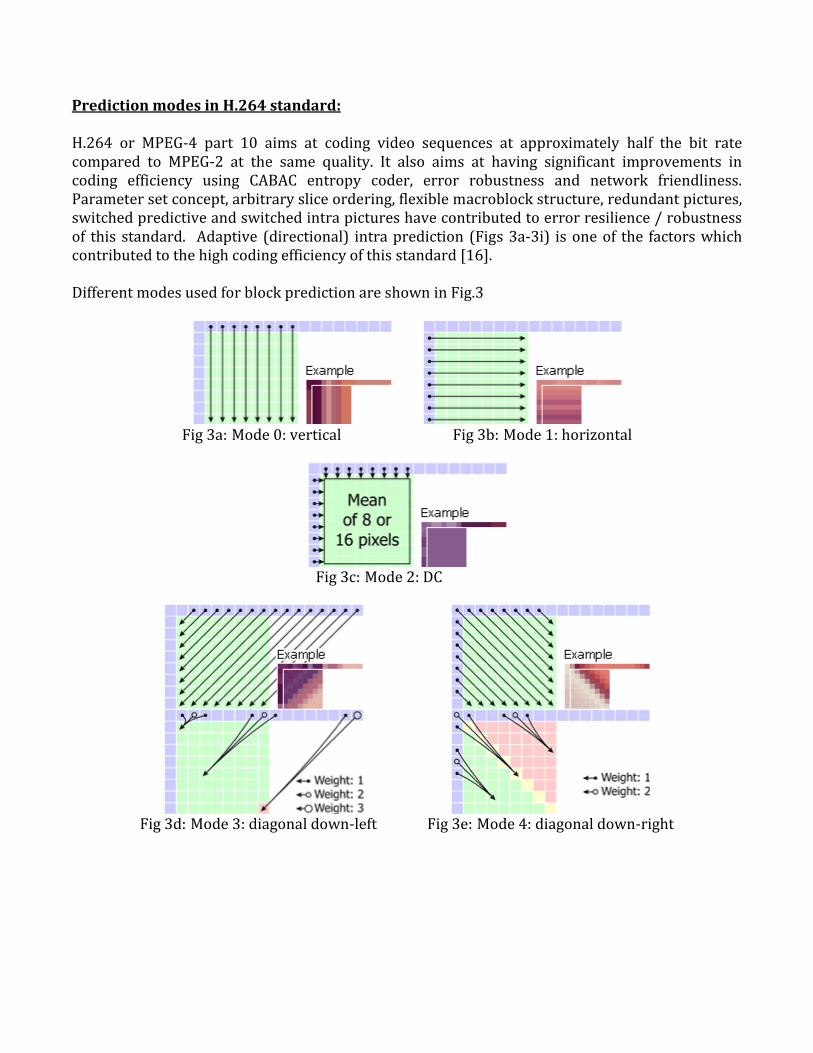
Prediction modes in H.264 standard: H.264 or MPEG-4 part 10 aims at coding video sequences at approximately half the bit rate compared to MPEG-2 at the same quality. It also aims at having significant improvements in coding efficiency using CABAC entropy coder, error robustness and network friendliness. Parameter set concept, arbitrary slice ordering, flexible macroblock structure, redundant pictures, switched predictive and switched intra pictures have contributed to error resilience / robustness of this standard. Adaptive (directional) intra prediction (Figs 3a-3i) is one of the factors which contributed to the high coding efficiency of this standard [16]. Different modes used for block prediction are shown in Fig.3
Fig 3a: Mode 0: vertical Fig 3b: Mode 1: horizontal
Fig 3c: Mode 2: DC
Fig 3d: Mode 3: diagonal down-left Fig 3e: Mode 4: diagonal down-right
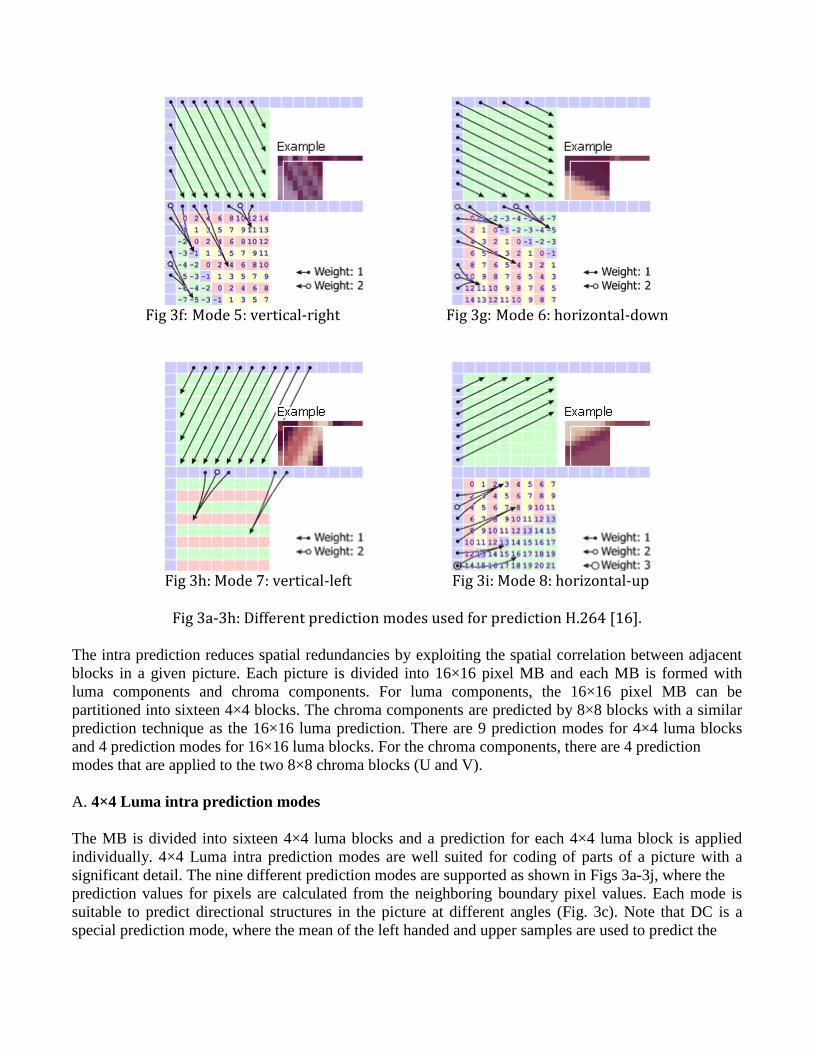
Fig 3f: Mode 5: vertical-right Fig 3g: Mode 6: horizontal-down
Fig 3h: Mode 7: vertical-left Fig 3i: Mode 8: horizontal-up
Fig 3a-3h: Different prediction modes used for prediction H.264 [16].
The intra prediction reduces spatial redundancies by exploiting the spatial correlation between adjacent
blocks in a given picture. Each picture is divided into 16×16 pixel MB and each MB is formed with
luma components and chroma components. For luma components, the 16×16 pixel MB can be
partitioned into sixteen 4×4 blocks. The chroma components are predicted by 8×8 blocks with a similar
prediction technique as the 16×16 luma prediction. There are 9 prediction modes for 4×4 luma blocks
and 4 prediction modes for 16×16 luma blocks. For the chroma components, there are 4 prediction
modes that are applied to the two 8×8 chroma blocks (U and V).
A. 4×4 Luma intra prediction modes
The MB is divided into sixteen 4×4 luma blocks and a prediction for each 4×4 luma block is applied
individually. 4×4 Luma intra prediction modes are well suited for coding of parts of a picture with a
significant detail. The nine different prediction modes are supported as shown in Figs 3a-3j, where the
prediction values for pixels are calculated from the neighboring boundary pixel values. Each mode is
suitable to predict directional structures in the picture at different angles (Fig. 3c). Note that DC is a
special prediction mode, where the mean of the left handed and upper samples are used to predict the

entire block.For the 8×8 intra prediction, 9 prediction modes are used which are the same as that of 4×4
intra prediction. However, the computational complexity of the H.264 encoder is dramatically increased
according to this feature of the new extended profile.
B. 16×16 Luma Intra Prediction Modes
16×16 Luma Intra Prediction Modes are more suitable for coding very smooth areas of a picture by
prediction for the whole luma component of a MB. Four different prediction modes are supported:
Vertical, Horizontal, DC and Plane prediction. Plane prediction mode uses a linear function between the
neighboring samples to the left and to the top in
order to predict the current samples.
C. 8×8 Chroma Intra Prediction Modes
The chroma intra prediction of a MB is similar to the 16×16 luma intra prediction because the chroma
signals are very smooth in most cases. It is performed always on chroma blocks using vertical
prediction, horizontal prediction, DC-prediction or plane-prediction.
Concept: By understanding the ideas and importance behind video compression, it is possible to use the idea and
implement an efficient and high performance encoder, such that it consumers less power and take less
clock cycles to encode an image frame. The implementation is considered a lite version of the H.264
encoder, similar to the MPEG-4 digital video codec which is known to achieving high data compression.
The same building blocks implemented in the H.264 encoder will be used in the lite version with
exceptions of a few optimizing modifications.
For example the Motion Estimation algorithm, it was suggested to use a full search algorithm but after
some research, it was discovered that the motion estimation process consumes 66-94% of the cycles [3].
Therefore if there was any optimization to be made, here would be the place to start.
Therefore, instead of applying the full search algorithm, an alternative algorithm was used, which will
be discussed under the background section. The motion compensation would produce the predicted
frame from the motion vectors (from motion estimation) and reference frame. The residual frame would
be generated by the difference between the predicted frame and current frame. To compress the data
even further, Discrete Cosine Transform (DCT), a type of linear transform, will be performed on the
residual frame. In addition, quantization will be used as well to compress the data. This project will be
simulated and synthesized on the Xilinx 8.1 ISE (to determine chip size and power consumption),
ModelSim (to simulate and observe waveforms). The purpose of this implementation is to improve
behavioral VHDL modeling and FPGA design process. In addition, to learn about video compression
system and be able to incorporate other simulation tools with VHDL. Hopefully, with this
implementation of the H.264 encoder, it will result in a design that is efficient and achieves high
performance, the hardware design that runs faster, with less power consumption and smaller area.

Modified Encoder Hardware Design:
Fig 3: Modified Encoder Hardware Design (derived from Fig 2).
The encoder will be used to encode a frame from a video sequence:
30 frames/second.
Each frame is 176 x 144 pixels (QCIF resolution, very typical for low bit-rate video contents in
cell phones).
Fig 4: Reference frame 1 [4] . Fig 5: Current frame 2 [4].
Fig 6: Residual of current frame [4].

The following are the different stages in designing the video encoder:
Motion Estimation:
Motion estimation is the most computationally demanding task in image compression applications, and
can require as much as 66%-94% of the processor cycles spent in the video encoder [6]. Therefore an
efficient motion estimation algorithm is essential for creating an efficient implementation of the H.264
encoder. This section will briefly cover different motion estimation algorithms and the tradeoffs between
them, and the proposed algorithm that will be implemented on this project.
Fig 7: The principle of block matching motion estimation algorithm is finding the best matching block in the searching area of a reference frame for each macroblock in the original frame.
Motion estimation attempts to find a region in a previously encoded frame (called the "reference frame")
that closely matches each macro block in the current frame. In this implementation, each frame is
divided into macro blocks of 4x4 pixels. To find the best matching block, Minimum Absolute
Difference (MAD) is very often exploited as the matching criterion because of its simple operation and
efficiency. Distance vector between this best matching block and current original macroblock is so-
called the motion vector. The motion vector is comprised of the horizontal and vertical offsets from the
location of the macro block in the current frame to the location in the reference frame. The full search
algorithm, also referred to as exhaustive block matching algorithm (EBMA) was the suggested
algorithm to perform the motion estimation in the encoder. The full search algorithm, would find the
“best matched” macro block within a search range of 8 pixels (resulting in a 20x20 pixel search range)
in the reference frame. This algorithm will simply exhaustively test all possible motion representations.
Which means that within the 20x20 pixel search range, the algorithm will start at the top left corner of
the search range and move the 4x4 macro block one pixel at a time and scan that area to search for the
“best match”. Once the entire search area has been scanned, the location of the macro block that was the
„best match‟ will be used to calculate the motion vector. Then a new macro block in the current frame
will be selected, and the process will start all over again, until all the macro blocks in the current frame
has been processed.

• This means that for every search area (20x20 pixels) there are 289 possible macro block locations, that
will be scanned by the full search algorithm.
• In addition, given that the frame size is 176 x 144 pixels (44 x 36 macro blocks), which gives a total of
1584 macro blocks.
• To compute the motion vector for each macro block in the current frame, the algorithm will have to
scan 1584 x 289 = 457776 blocks.
Using the full search algorithm scans and processes many macro blocks are involved, which consumes
too many clock cycles. An alternative algorithm would be the four-step search (4SS) motion estimation
algorithm. The four-step search was developed from the popular three-step search algorithm in order to
improve efficiency. The 4SS algorithm performs similar to a hierarchal search algorithm, starting at a
very broad search, and performs narrower searches after. The 4SS algorithm uses a center-biased search
pattern, with nine checking points on a 5x5 window in the first step. The center of the search window is
then shifted to the point with the “best match” macro block. The search window of the next two steps
depends on the location of the “best match”.
The 4SS is summarized in 4 steps [5]:
• Step 1: A macro block that is the “best match” is found from a nine-checking-points pattern on a 5x5
window located at the center of the 15 x 15 search area (Fig. 8a).
• Decision: If the “best matched” macro block is found at the center of the search window, go to Step 4
otherwise go to Step 2.
• Step 2: The search-window size is maintained at 5 x 5. However, the search patter will depend on the
position of the previous “best matched” macro block location.
a. If the previous “best matched” macro block is located at the corner of the search window, five
additional checking points (Figure 8b) are used.
b. If the previous “best matched” macro block is located at the middle of the horizontal or vertical axis
of the previous search window, three additional checking points (Figure 8c) are used.
• Decision: If the “best matched” macro block is found at the center of the search window, go to Step 4;
otherwise go to Step 3.
• Step 3: The searching pattern strategy is the same as Step 2, but finally it will go to Step 4.
• Step 4: The search window is reduced to 3 x 3 (Figure 8d) and the direction of the overall motion
vector is considered as the “best matched” macro block is among these nine macro blocks.

Fig 8a: A 20x20 pixel search range divided up by 4x4 pixel search [5].
Fig 8b: A 20x20 pixel search range with 5 additional checkpoints during step 2 of the four-step search algorithm [5].
Fig 8c: A 20x20 pixel search range with 3 additional checkpoints during step 3 of the four-step search algorithm [5].
4x4 macroblock
Check points for motion estimation
A 20x20 pixel search range divided up by 4x4 pixel search range

Fig 8d: A 20x20 pixel search range with 5x5 search window, now reduced to 3x3 during step 4 of the four-step search algorithm [5].
Figs 8a-8b of the 4SS algorithm does not use the same search area dimensions as specified in the Full
Search Algorithm, but the overall implementation of the 4SS search algorithm can be easily seen,
especially how the algorithm is able to optimize and reduce the number of searches. The algorithm only
scans a fraction of the search area, starts off with a broad scan, and narrows each of its scan afterwards.
A modified version of the 4SS search algorithm will be used in this implementation of the motion
estimation process.
Motion vector description:
Fig 9. Motion vector description.
After the user get the best match on the picture, each macro-block will have their own motion vector.
After the motion vectors are obtained, a predicted frame can be formed with the reference frame (RF)
and the motion vectors (MV) with the following pseudo code:
Fig 10: Psuedo code for obtaining predicted frame [6].

Motion compensation
After the motion vectors are obtained, motion compensation uses the motion vectors encoded in the
video bit stream to predict the pixels in each macro block. A predicted frame can be formed with the
reference frame and the motion vectors (Figure 11).
Figure 11: Generating predicted frame using reference frame and motion vectors.
Like motion estimation, motion compensation requires the video decoder to keep one or two reference
frames in memory, often requiring external memory chips for this purpose. However, motion
compensation makes fewer accesses to reference frame buffers than motion estimation. Therefore,
memory bandwidth requirements are less stringent for motion compensation compared to motion
estimation. The predicted frame, shown in Figure 11, still fails to new elements that were absent in the
previous frame (i.e.illumination). To correct that a residual frame, which is the difference between the
predicted frame and the actual current frame, is also computed. The residual frame is shown in Figure
12.
Figure 12: The residual frame formed by subtracting the predicted frame from the actual current frame.
Discrete cosine transform
After the residual frame has been produced, it goes through a discrete cosine transform which transforms
each block (in residual frame) into a frequency-domain representation. This is a lossless process,
because it is just a direct transformation into frequency coefficients. In the H.264 standard, real DCT is
factored into the following form:

Figure 13: Real DCT factor.
Where:
X denotes the original macroblock
a = 0.5
b = sqrt(2/5)
denotes array multiplication
The DCT has strong energy compaction properties. Most of the signal information tends to be
concentrated in a few low frequency components of the DCT. However, the human eye is
more sensitive to the information contained in DCT coefficients that represent low frequencies
(corresponding to large features in the image) than to the information contained in DCT coefficients that
represent high frequencies (corresponding to small features). Therefore, the DCT helps
separate the more perceptually significant information.
As mentioned above, the DCT coefficients for each block are encoded using more bits for the more
perceptually significant low-frequency DCT coefficients and fewer bits for the less significant high-
frequency coefficients. This encoding of coefficients is accomplished in two steps: First, quantization
is used to discard perceptually insignificant information. Quantization rounds each DCT coefficient to
the nearest of a number of predetermined values. By reducing the number of discrete symbols in a given
stream, the stream becomes more compressible.
QP QStep QP Qstep
1 0.6875 7 1.3750
2 0.8125 8 1.6250
3 0.8750 9 1.7500
4 1.0000 10 2.0000
5 1.1250 11 2.2500
6 1.2500 12 2.5000
Table 1: Quantization step sizes in H.264 CODEC
The quality of reconstructed frame is determined by the QP used. The higher the QP, the lower the
decoded quality and vice versa. In the encoder, each pixel, yij, in the current macroblock is quantized by
the following equation:
Zij = round(Yij Eij / QStep)

Overall view of operations in encoder module:
Fig 14. Overall view of operations in encoder module [6].
Results:
Platform:
ModelSim: Version XE III 6.0d.
Quartus II: Version 10.1 -sp1 Web Edition (64-Bit).
The hardware description language used was VHDL (Very high speed integrated circuit Hardware Description language). Figure 15 shows the list of code segments used.
Figure 15: List of code segments used to design the H.264 encoder.

Figure 16: List of tasks performed.
Figure 17: Analysis and synthesis summary.

Figure 18: Resource usage summary.
Figure 19: Generated register transfer logic for the H.264 encoder.
Conclusion:
The H.264 encoding algorithms were discussed. A complete analysis of the motion estimation
algorithm, motion compensation, DCT and quantization was made. VHDL code was written to
implement the H.264 video encoder. The code was compiled and synthesized using ModelSim and
Quartus ii sofwares. The Register transfer schematic for the code was generated.

Appendix
VHDL code for the design of the H.264 encoder.
library IEEE;
use IEEE.std_logic_1164.all;
use IEEE.Numeric_STD.all;
use IEEE.std_logic_unsigned."+";
use IEEE.std_logic_unsigned."-";
use IEEE.std_logic_signed.">";
use IEEE.std_logic_signed."<";
use work.config.all;
entity me_top is
port ( clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
register_file_address : in std_logic_vector(4 downto 0); -- 32 general purpose registers
register_file_write : in std_logic;
register_file_data_in : in std_logic_vector(31 downto 0);
register_file_data_out : out std_logic_vector(31 downto 0);
done_interrupt : out std_logic; -- high when macroblock processing has completed
best_sad_debug : out std_logic_vector(15 downto 0); --debugging ports
best_mv_debug : out std_logic_vector(15 downto 0);
best_eu_debug : out std_logic_vector(3 downto 0);
partition_mode_debug : out std_logic_vector(3 downto 0);
qp_on_debug : out std_logic; --running qp
dma_rm_re_debug : in std_logic; --set to one to enable reading the reference area
dma_rm_debug : out std_logic_vector(63 downto 0); -- reference area data out
dma_address : in std_logic_vector(10 downto 0); -- next reference memory address
dma_data_in : in std_logic_vector(63 downto 0); -- pixel in for reference memory or
macroblock memory
dma_rm_we : in std_logic; --enable writing to reference memory
dma_cm_we : in std_logic; --enable writing to current macroblock memory
dma_pom_we : in std_logic; -- enable writing to point memory
dma_prm_we : in std_logic; -- enable writing to program memory

dma_residue_out : out std_logic_vector(63 downto 0); -- get residue from winner mv
dma_re_re : in std_logic -- enable reading residue
);
end;
architecture struct of me_top is
component mv_cost --calculate mv cost using Lagrangian optimization
generic (pipelines : integer);
port (
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
load : in std_logic; -- start
mvp_x : in std_logic_vector(7 downto 0); --predicted mv x
mvp_y : in std_logic_vector(7 downto 0); -- predicted mv y
mvx_c : in std_logic_vector(7 downto 0); -- motion vector candidate x
mvy_c : in std_logic_vector(7 downto 0); -- motion vector candidate y
rest_mvx_c : in rest_type_points; -- rest of motion vector candidates x
rest_mvy_c : in rest_type_points; -- rest of motion vector candidates y
quant_parameter : in std_logic_vector(5 downto 0); -- quantization parameter
p_cost_mv : out std_logic_vector(15 downto 0);
rest_p_cost_mv : out rest_type_displacement
);
end component;
component phy_address
port (
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
partition_count : in std_logic_vector(3 downto 0); --identify the subpartition active
line_offset : in std_logic_vector(5 downto 0); -- read multiple lines
mvx : in std_logic_vector(7 downto 0);
mvy : in std_logic_vector(7 downto 0);
phy_address : out std_logic_vector(13 downto 0));
end component;
component sad_selector
generic (integer_pipeline_count : integer);

port (
clk : in std_logic;
reset : in std_logic;
clear : in std_logic;
calculate_sad_done : in std_logic;
active_pipelines : in std_logic_vector(CFG_PIPELINE_COUNT-1 downto 0);
update : in std_logic; -- completed program reset the stored sad
update_fp : in std_logic; -- end of iteraction
best_eu : out std_logic_vector(3 downto 0);
best_sad : in std_logic_vector(15 downto 0);
best_mv : in std_logic_vector(15 downto 0);
rest_best_sad : in rest_type_displacement;
rest_best_mv : in rest_type_displacement;
best_sad_out : out std_logic_vector(15 downto 0);
best_mv_out : out std_logic_vector(15 downto 0));
end component;
component sad_selector_qp
port (
clk : in std_logic;
reset : in std_logic;
clear : in std_logic;
calculate_sad_done : in std_logic;
active_pipelines : in std_logic_vector(CFG_PIPELINE_COUNT_QP-1 downto 0);
update : in std_logic; -- completed fp part set the stored sad
update_qp : in std_logic; -- end of iteraction
best_eu : out std_logic_vector(3 downto 0);
best_sad : in std_logic_vector(15 downto 0);
best_mv : in std_logic_vector(15 downto 0);
rest_best_sad : in rest_type_displacement_qp;
rest_best_mv : in rest_type_displacement_qp;
best_sad_out : out std_logic_vector(15 downto 0);
best_mv_out : out std_logic_vector(15 downto 0));
end component;
component distance_engine64
generic (qp_mode : std_logic);
port(
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
enable : in std_logic;
update : in std_logic;

load_mv : in std_logic;
mode_in : in mode_type;
mv_cost_on : in std_logic;
mv_cost_in : in std_logic_vector(15 downto 0);
candidate_mvx : in std_logic_vector(7 downto 0);
candidate_mvy : in std_logic_vector(7 downto 0);
reference_data_in : in std_logic_vector(63 downto 0);
current_data_in : in std_logic_vector(63 downto 0);
residue_out : out std_logic_vector(63 downto 0);
enable_fifo : out std_logic;
reset_fifo : out std_logic;
winner1 : out std_logic;
calculate_sad_done : out std_logic;
distance_engine_active : out std_logic;
best_sad : out std_logic_vector(15 downto 0);
best_mv : out std_logic_vector(15 downto 0));
end component;
component register_file
generic (integer_pipeline_count : integer);
port(
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
addr : in std_logic_vector(4 downto 0);
write : in std_logic;
data_in : in std_logic_vector(31 downto 0);
data_out : out std_logic_vector(31 downto 0);
start : out std_logic;
all_done_qp : in std_logic; -- program completes
all_done_fp : in std_logic; -- fp part completes
mvc_done : out std_logic; -- all motion vector candidates evaluated
mvc_to_do : out std_logic_vector;
instruction_zero : in std_logic;
partition_done_fp : in std_logic; -- fp partition terminates
partition_done_qp : in std_logic; -- qp partition terminates
done_interrupt : out std_logic;
start_row : out std_logic;
update_fp : in std_logic;
load_mv : in std_logic; -- force the mvc to move foward
mode_out : out mode_type;
mv_cost_on : out std_logic; -- activate the costing of mvs

best_sad_fp : in std_logic_vector(15 downto 0);
best_mv_fp : in std_logic_vector(15 downto 0);
first_mv_fp : out std_logic_vector(15 downto 0);
rest_first_mv_fp : out rest_type_displacement;
mbx_coordinate : out std_logic_vector(7 downto 0);
mby_coordinate : out std_logic_vector(7 downto 0);
mvp_x : out std_logic_vector(7 downto 0);
mvp_y : out std_logic_vector(7 downto 0);
quant_parameter : out std_logic_vector(5 downto 0);
frame_dimension_x : out std_logic_vector(7 downto 0);
frame_dimension_y : out std_logic_vector(7 downto 0);
update_qp : in std_logic;
partition_count : in std_logic_vector(3 downto 0); --identify the subpartition active
best_sad_qp : in std_logic_vector(15 downto 0);
best_mv_qp : in std_logic_vector(15 downto 0);
first_mv_qp : out std_logic_vector(15 downto 0));
end component;
component fp_pipeline
port ( clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
next_point_displacement_fp : in std_logic_vector(15 downto 0); --next point to be
processed
first_mv_fp : in std_logic_vector(15 downto 0); -- first point to start the search from
start : in std_logic;
start_mb : in std_logic; -- once per macroblock
mode_in : in mode_type;
partition_count : in std_logic_vector(3 downto 0); --identify the subpartition active
frame_dimension_x : in std_logic_vector(7 downto 0); --in mb
frame_dimension_y : in std_logic_vector(7 downto 0);
mbx_coordinate : in std_logic_vector(7 downto 0); --in mb
mby_coordinate : in std_logic_vector(7 downto 0);
candidate_mvx : out std_logic_vector(7 downto 0); -- port for Lagrangian optimizaton
candidate_mvy : out std_logic_vector(7 downto 0);
mv_cost : in std_logic_vector(15 downto 0);
mv_cost_on : in std_logic; -- enable mv cost
all_done_fp : in std_logic; -- program completes
calculate_sad_done : out std_logic;
best_sad_fp : out std_logic_vector(15 downto 0);
best_mv_fp : out std_logic_vector(15 downto 0);

dma_address : in std_logic_vector(10 downto 0); -- next reference memory address
mb_data_in : in std_logic_vector(63 downto 0); -- pixel in for macroblock memory (shared
this memory among the pipelines)
dma_data_in : in std_logic_vector(63 downto 0); -- pixel in for reference memory
dma_rm_we : in std_logic; --enable writing to reference memory
--dma_cm_we : in std_logic; --enable writing to current macroblock memory
dma_residue_out : out std_logic_vector(63 downto 0); -- get residue from winner mv
dma_re_re : in std_logic -- enable reading residue
);
end component;
component program_memory
port (
addr: in std_logic_vector(7 downto 0);
clk: in std_logic;
din: in std_logic_vector(19 downto 0);
dout: out std_logic_vector(19 downto 0);
we: in std_logic);
end component;
component reference_memory64_remap -- This memory stores the 5x7 reference data (1120
words of 64 bit)
port ( -- It also remaps the addresses
addr_r: in std_logic_vector(10 downto 0);
addr_w: in std_logic_vector(10 downto 0);
enable_hp_inter : in std_logic; -- working in interpolation mode
clk: in std_logic;
start : in std_logic;
next_configuration : in std_logic; -- move to the next configuration
start_row : in std_logic;
reset : in std_logic;
clear : in std_logic;
din: in std_logic_vector(63 downto 0);
dout: out std_logic_vector(63 downto 0);
dout2: out std_logic_vector(63 downto 0);
we: in std_logic);
end component;
component reference_memory64_remap_compact -- This memory stores the 5x5 reference data
(800 words of 64 bit)
port ( -- It also remaps the addresses
addr: in std_logic_vector(9 downto 0);

enable_hp_inter : in std_logic; -- working in interpolation mode
clk: in std_logic;
next_configuration : in std_logic; -- move to the next configuration
start_row : in std_logic;
reset : in std_logic;
clear : in std_logic;
din: in std_logic_vector(63 downto 0);
dout: out std_logic_vector(63 downto 0);
dout2 : out std_logic_vector(63 downto 0); -- from the second read port
we: in std_logic);
end component;
component concatenate64_qp
port(
addr : in std_logic_vector(2 downto 0);
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
din : in std_logic_vector(63 downto 0);
din2 : in std_logic_vector(63 downto 0);
dout : out std_logic_vector(63 downto 0);
enable : in std_logic;
quick_valid : out std_logic; --as valid but one cycle earlier
valid : out std_logic); -- indicates when 64 valid bits are in the output
end component;
component concatenate64 -- this unit makes sure that 16 valid pixels are assemble depending on
byte address
port(
addr : in std_logic_vector(2 downto 0);
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
din : in std_logic_vector(63 downto 0);
din2 : in std_logic_vector(63 downto 0);
dout : out std_logic_vector(63 downto 0);
enable_hp_inter : in std_logic; -- working in interpolation mode
enable : in std_logic;
quick_valid : out std_logic; --as valid but one cycle earlier
valid : out std_logic); -- indicates when 16 valid bytes are in the output
end component;

component qp_interpolate_engine
port(
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
qp_mode : in std_logic; -- in qp mode two lines must be written to interpolate
enable_hp_inter : in std_logic;
write_interpolate_register : in std_logic;
interpolate_in_pixels_a : in std_logic_vector(63 downto 0);
interpolate_in_pixels_b : in std_logic_vector(63 downto 0);
write_block1 : out std_logic; -- control which of the two blocks is being read and written
(interpolate and dist engine)
rma_address : out std_logic_vector(4 downto 0); -- extracted reference pixels use this address
rma_we : out std_logic;
interpolate_out_pixels : out std_logic_vector(63 downto 0)
);
end component;
component forward_engine
port(
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
enable_hp_inter : in std_logic; -- when hp interpolation is being performed in the background
write_register : in std_logic;
mode_in : in mode_type;
partition_count_in : in std_logic_vector(3 downto 0);
in_pixels : in std_logic_vector(63 downto 0);
write_block1 : out std_logic; -- control which of the two blocks is being read and written
(interpolate and dist engine)
rma_address : out std_logic_vector(4 downto 0); -- extracted reference pixels use this address
rma_we : out std_logic;
out_pixels : out std_logic_vector(63 downto 0)
);
end component;
-- half pel interpolation engine
component systolic_array_top
port (
clear : in std_logic;
reset : in std_logic;
enable_interpolation : in std_logic;

enable_estimation : in std_logic;
clk : in std_logic;
data_in : in std_logic_vector(63 downto 0);
data_in_valid : in std_logic;
data_request : out std_logic;
all_done : out std_logic;
next_point : out std_logic; -- tell the main control unit that the next point is required
shift_concatenate_valid : in std_logic; -- need to know when 64 bits are valid
-- memory interface for o,h,v and d memories
candidate_mvx : in std_logic_vector(7 downto 0);
candidate_mvy : in std_logic_vector(7 downto 0);
hp_address_a : out std_logic_vector(2 downto 0);
hp_address_b : out std_logic_vector(2 downto 0);
data_out_a : out std_logic_vector(63 downto 0); --interpolated data out
data_out2_a : out std_logic_vector(63 downto 0); --interpolated data out
data_out_b : out std_logic_vector(63 downto 0); --interpolated data out
data_out2_b : out std_logic_vector(63 downto 0); --interpolated data out
data_out_valid : out std_logic --signal to indicate 8 bytes of data valid
);
end component;
component cm -- This memory stores the current macroblock(256 bytes))
port (
addr: in std_logic_vector(4 downto 0);
clk: in std_logic;
din: in std_logic_vector(63 downto 0);
dout: out std_logic_vector(63 downto 0);
we: in std_logic
);
end component;
component point_memory
port (
addr: IN std_logic_VECTOR(7 downto 0);
clk: IN std_logic;
din: IN std_logic_VECTOR(15 downto 0);
dout: OUT std_logic_VECTOR(15 downto 0);
we: IN std_logic);
end component;

--component point_memory
-- port (
-- addr: in std_logic_vector(7 downto 0);
-- clk: in std_logic;
-- dout: out std_logic_vector(15 downto 0));
--end component;
component me_control_unit
generic ( integer_pipeline_count : integer);
port ( clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
start : in std_logic;
range_ok : in std_logic; --keep track of the mv range
best_sad_in : in std_logic_vector(15 downto 0); -- to make SAD-based decisions
mv_length_in : in std_logic_vector(15 downto 0); -- to make LENGTH-based decisions
mode_in : in mode_type;
mvc_done : in std_logic; -- all motion vector candidates evaluated
mvc_to_do : in std_logic_vector(3 downto 0);
qp_on : in std_logic; -- qp on
partition_count_out : out std_logic_vector(3 downto 0); --identify the subpartition active
start_pipelines : out std_logic_vector(CFG_PIPELINE_COUNT-1 downto 0);
active_pipelines : out std_logic_vector(CFG_PIPELINE_COUNT-1 downto 0); -- so
sad selector ignores the non active ones
shift_concatenate_valid : in std_logic; -- valid output from the concantenate unit (64 bit
ready)
instruction_address : out std_logic_vector(7 downto 0); -- address to fetch next instruction
instruction_opcode : in std_logic_vector(3 downto 0); -- opcode
point_count : in std_logic_vector(7 downto 0); -- how many points to test
point_address : in std_logic_vector(7 downto 0); -- which is the first point to test
best_eu : in std_logic_vector(3 downto 0);
calculate_sad_done : in std_logic;
distance_engine_active : in std_logic;
interpolation_done : in std_logic; -- interpolation completes
interpolate_data_request : in std_logic; -- interpolator requests data
next_point : out std_logic_vector(7 downto 0); -- next point address to ROM
line_offset : out std_logic_vector(5 downto 0); -- multiple line reading
enable_concatenate_unit : out std_logic;
--enable_dist_engine : out std_logic;
write_register : out std_logic;
load_mv : out std_logic;

update : out std_logic;
instruction_zero : out std_logic;
all_done : out std_logic; -- program completes or qp mode started (fp finished)
partition_done : out std_logic;
qpel_loc_x : in std_logic_vector(1 downto 0); -- detect qp mode
qpel_loc_y : in std_logic_vector(1 downto 0);
start_qp : out std_logic;
enable_hp_inter : out std_logic; -- start the interpolation core
-- write_block1 : out std_logic;
-- next_rm_address_ready : in std_logic;
next_rm_addresss : in std_logic_vector(13 downto 0); --physical address for reference
(macroblock upper left corner
rm_address : out std_logic_vector(13 downto 0) -- reference memory write from address
-- cm_address : out std_logic_vector(4 downto 0); -- address to extract 4x4 blocks from
current macroblock
-- rma_address : out std_logic_vector(4 downto 0); -- reference macroblock write to
address
-- rma_we : out std_logic
);
end component;
component me_control_unit_qp
port ( clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
start : in std_logic; -- start qp refinement
next_point_inter : in std_logic; -- tell the main control unit that the next point is required by
the interpolation unit
shift_concatenate_valid : in std_logic; -- valid output from the concantenate unit
qp_starting_address : in std_logic_vector(7 downto 0); -- start fetching qp instructions from
this point
instruction_address : out std_logic_vector(7 downto 0); -- address to fetch next instruction
point_count : in std_logic_vector(7 downto 0); -- how many points to test
point_address : in std_logic_vector(7 downto 0); -- which is the first point to test
calculate_sad_done : in std_logic; -- signals when the distance engine has finished
instruction_opcode : in std_logic_vector(3 downto 0); -- opcode
best_eu : in std_logic_vector(3 downto 0); -- best execution unit
next_point : out std_logic_vector(7 downto 0); -- next point address to ROM
qp_mode : out std_logic; --enable qp estimation
qp_on : out std_logic; -- qp active
load_mv : out std_logic;
update : out std_logic;
all_done : out std_logic -- program completes

);
end component;
component range_checker --make sure that MVs are not out of range
port (
clk : in std_logic;
clear : in std_logic;
reset : in std_logic;
candidate_mvx : in std_logic_vector(7 downto 0);
candidate_mvy : in std_logic_vector(7 downto 0);
frame_dimension_x : in std_logic_vector(7 downto 0); --in mb
frame_dimension_y : in std_logic_vector(7 downto 0);
mbx_coordinate : in std_logic_vector(7 downto 0); --in mb
mby_coordinate : in std_logic_vector(7 downto 0);
range_ok : out std_logic
);
end component;
signal test : std_logic;
signal rest_next_point_fp : rest_type_points;
signal rest_point_memory_address : rest_type_points;
signal rest_next_point_displacement_fp : rest_type_displacement;
signal rest_start_pipeline,rest_calculate_sad_done :
std_logic_vector(CFG_PIPELINE_COUNT-1 downto 0);
signal rest_best_sad_fp,rest_best_mv_fp,rest_first_mv_fp: rest_type_displacement;
signal rest_next_point_qp : rest_type_points_qp;
signal rest_point_memory_address_qp : rest_type_points_qp;
signal rest_next_point_displacement_qqp : rest_type_displacement_qp;
signal rest_start_pipeline_qp,rest_calculate_sad_done_qp :
std_logic_vector(CFG_PIPELINE_COUNT_QP-1 downto 0);
signal rest_best_sad_qp,rest_best_mv_qp: rest_type_displacement_qp;
signal
mvp_x,mvp_y,frame_dimension_x,frame_dimension_y,mby_coordinate,mbx_coordinate,progra
m_memory_address,program_memory_address_qp,instruction_address_fp,instruction_address_
qp,point_count_fp,point_count_qp,point_address_fp,point_address_qp,candidate_mvx_fp,candi
date_mvy_fp,candidate_mvx_qp,candidate_mvy_qp : std_logic_vector(7 downto 0);
signal quant_parameter,line_offset : std_logic_vector(5 downto 0);
signal partition_count,instruction_fp,instruction_qp : std_logic_vector(3 downto 0); --op code
signal
next_point_fp,point_memory_address,next_point_qp,point_memory_address_qp,candidate_mv
x_int,candidate_mvy_int : std_logic_vector(7 downto 0);

signal
one_bit,zero_bit,distance_engine_active_fp,range_ok,quick_valid,quick_valid_qp,next_point_in
ter,enable_concatenate_unit,dma_cm_we_m1,dma_cm_we_m2,dma_cm_we_fp,dma_cm_we_q
p,done_interrupt_int,mv_cost_on : std_logic;
signal
distance_engine_address_m2,distance_engine_address_m1,distance_engine_address_qp,cm_ad
dress_m1,cm_address_m2,address1_fp,address2_fp,address1_qp,address2_qp:
std_logic_vector(4 downto 0);
signal
zero,best_sad_out_qp,best_mv_out_qp,next_point_displacement_qp,next_point_displacement_f
p,best_sad_fp,best_sad_qp,best_sad_qp_distance_engine,best_mv_fp,best_mv_qp,best_sad_out
_fp,best_mv_out_fp,p_cost_mv,p_cost_mv_qp : std_logic_vector(15 downto 0);
signal point_count_position_qp,point_count_position_fp : std_logic_vector(19 downto 0);
signal mv_length_in,first_mv_fp,first_mv_qp,mv_displacement_fp,mv_displacement_qp :
std_logic_vector(15 downto 0);
signal
mvc_done,instruction_zero,qp_on,partition_done_fp,partition_done_qp,mux_control_write,mux
_control_read,qp_mode,start_qp,qp_pixels_valid,hp_pixels_valid,hp_interpolation_done,data_re
quest_hp_inter,all_done_fp,all_done_qp,start_row,reset_fifo_fp,reset_fifo_qp,reset_fifo1_qp,res
et_fifo2_qp,reset_fifo1_fp,reset_fifo2_fp,fifo_enable_w1,fifo_enable_w2,fifo_enable_r1,fifo_e
nable_r2,enable_fifo_fp,enable_fifo_qp,winner1_fp,winner1_qp,start,write_register,write_interp
olate_register,next_rm_address_ready,shift_concatenate_valid_qp,shift_concatenate_valid_fp,r
ma_we_qp,rma_we_fp,rma_we1_qp,rma_we2_qp,rma_we1_fp,rma_we2_fp,write_block1_qp,l
oad_mv_fp,load_mv_qp,update_fp,update_qp,calculate_sad_done_qp,calculate_sad_done_fp,en
able_hp_inter : std_logic;
signal rm_address_r,rm_address_w : std_logic_vector(10 downto 0);
signal rm_address_c : std_logic_vector(9 downto 0);
signal best_eu,best_eu_qp,mvc_to_do : std_logic_vector(3 downto 0);
signal next_rm_address,int_rm_address : std_logic_vector(13 downto 0);
signal
current_pixels,current_pixels_fp,current_pixels_qp,current_pixels_m1,current_pixels_m2,refere
nce_data_in1_fp,reference_data_in2_fp,reference_data_in1_qp,reference_data_in2_qp,reference
_data_in_fp,reference_data_in_qp : std_logic_vector(63 downto 0);
signal
reference_pixels_in,reference_pixels_in2,residue_out_fp,residue_out_qp,residue_out_1_2,resid
ue_out_2_2,residue_out_1_1,residue_out_2_1 : std_logic_vector(63 downto 0);
signal
out_pixels_fp,out_pixels_qp,qp_pixels_out_a,qp_pixels_out_b,hp_pixels_out_a,hp_pixels_out2
_a,hp_pixels_out_b,hp_pixels_out2_b,reference_pixels_out_qp_a,reference_pixels_out_qp_b,re
ference_pixels_out_fp : std_logic_vector(63 downto 0); --for the interpolate unit
signal rma_address_qp,rma_address_fp : std_logic_vector(4 downto 0);
signal hp_address_a, hp_address_b : std_logic_vector(2 downto 0);
--signal sad : std_logic_vector(15 downto 0);

signal qpel_loc_x,qpel_loc_y : std_logic_vector(1 downto 0);
signal point_memory_data_in : std_logic_vector(15 downto 0);
signal program_memory_data_in : std_logic_vector(19 downto 0);
signal partition_mode : mode_type;
signal active_pipelines : std_logic_vector(CFG_PIPELINE_COUNT-1 downto 0);
signal active_pipelines_qp : std_logic_vector(CFG_PIPELINE_COUNT_QP-1 downto 0);
signal rest_mvx_c,rest_mvy_c : rest_type_points;
signal rest_p_cost_mv : rest_type_displacement;
begin
-- program memory for fp engine
program_memory_data_in <= dma_data_in(19 downto 0);
program_memory_address <= dma_address(7 downto 0) when dma_prm_we = '1' else
instruction_address_fp;
qp_on_debug <= qp_on;
zero_bit <= '0';
one_bit <= '1';
mode_process : process(partition_mode)
begin
case partition_mode is
when m16x16 => partition_mode_debug <= "0000";
when m8x8 => partition_mode_debug <= "0001";
when others => partition_mode_debug <= "0000";
end case;
end process;
program_memory1 : program_memory
port map(
addr =>program_memory_address,
clk =>clk,
din =>program_memory_data_in,
dout => point_count_position_fp,
we => dma_prm_we
);

-- program memory for qp engine
program_memory2_qp : if CFG_PIPELINE_COUNT_QP = 1 generate
program_memory_address_qp <= dma_address(7 downto 0) when dma_prm_we = '1' else
instruction_address_qp;
program_memory2 : program_memory
port map(
addr =>program_memory_address_qp,
clk =>clk,
din =>program_memory_data_in,
dout => point_count_position_qp,
we => dma_prm_we
);
end generate;
no_qpgen0 : if CFG_PIPELINE_COUNT_QP = 0 generate
point_count_position_qp <= (others => '0');
end generate;
range_checker1 : range_checker --make sure that MVs are not out of range
port map(
clk => clk,
clear => clear,
reset => reset,
candidate_mvx => candidate_mvx_fp,
candidate_mvy => candidate_mvy_fp,
frame_dimension_x =>frame_dimension_x,
frame_dimension_y =>frame_dimension_y,
mbx_coordinate => mbx_coordinate,
mby_coordinate => mby_coordinate,
range_ok => range_ok
);
phy_address1 : phy_address
port map(

clk => clk,
clear => clear,
reset => reset,
partition_count => partition_count, --identify the subpartition active
line_offset => line_offset,
mvx => candidate_mvx_int,
mvy => candidate_mvy_int,
phy_address => next_rm_address
);
instruction_fp <= point_count_position_fp(19 downto 16);
point_count_fp <= point_count_position_fp(15 downto 8);
point_address_fp <= point_count_position_fp(7 downto 0);
instruction_qp <= point_count_position_qp(19 downto 16);
point_count_qp <= point_count_position_qp(15 downto 8);
point_address_qp <= point_count_position_qp(7 downto 0);
candidate_mvx_fp <= first_mv_fp(15 downto 8)+mv_displacement_fp(15 downto 8);
candidate_mvy_fp <= first_mv_fp(7 downto 0)+mv_displacement_fp(7 downto 0);
-- check that MVX is in the reference area
in_range_x : process(candidate_mvx_fp)
begin
if candidate_mvx_fp > 47 then
candidate_mvx_int <= x"2f";
elsif candidate_mvx_fp < -48 then
candidate_mvx_int <= x"d0";
else
candidate_mvx_int <= candidate_mvx_fp;
end if;
end process;
-- check that MVY is in the reference area
in_range_y: process(candidate_mvy_fp)
begin
if candidate_mvy_fp > 31 then
candidate_mvy_int <= x"1f";
elsif candidate_mvy_fp < -32 then
candidate_mvy_int <= x"e0";
else
candidate_mvy_int <= candidate_mvy_fp;
end if;
end process;

--this has to change the first mv for qp should be the winner from fo
candidate_mvx_qp <= first_mv_qp(15 downto 8)+mv_displacement_qp(15 downto 8);
candidate_mvy_qp <= first_mv_qp(7 downto 0)+mv_displacement_qp(7 downto 0);
no_qpgen11 : if CFG_PIPELINE_COUNT_QP = 0 generate
qpel_loc_x <= (others => '0');
qpel_loc_y <= (others => '0');
end generate;
qpgen11 : if CFG_PIPELINE_COUNT_QP = 1 generate
qpel_loc_x <= candidate_mvx_fp(1 downto 0);
qpel_loc_y <= candidate_mvy_fp(1 downto 0);
end generate;
-- fp point memory
--point_memory_fp : point_memory
-- port map(
-- addr =>next_point_fp,
-- clk =>clk,
-- dout => next_point_displacement_fp
--);
point_memory_address <= dma_address(7 downto 0) when dma_pom_we = '1' else
next_point_fp;
point_memory_data_in <= dma_data_in(15 downto 0);
point_memory_fp : point_memory
port map(
addr =>point_memory_address,
clk =>clk,
din =>point_memory_data_in,
dout =>next_point_displacement_fp,
we => dma_pom_we
);
--generate enough memories to hold the point memories for each aditional pipeline
generate_pipelines1 : for i in 1 to (CFG_PIPELINE_COUNT-1) generate
begin
rest_next_point_fp(i) <= next_point_fp when mvc_done = '0' else next_point_fp + i;
rest_point_memory_address(i) <= dma_address(7 downto 0) when dma_pom_we = '1'
else rest_next_point_fp(i);

rest_point_memory_fp : point_memory
port map (
addr => rest_point_memory_address(i),
clk => clk,
din =>point_memory_data_in,
dout => rest_next_point_displacement_fp(i),
we => dma_pom_we
);
end generate;
--generate integer pipelines
generate_pipelines2 : for i in 1 to (CFG_PIPELINE_COUNT-1) generate
begin
fp_pipelines1 : fp_pipeline
port map( clk =>clk,
clear =>clear,
reset =>reset,
next_point_displacement_fp =>rest_next_point_displacement_fp(i), --next point to be
processed
first_mv_fp =>rest_first_mv_fp(i), -- first point to start the search from
start =>rest_start_pipeline(i), -- enable the pipeline by main me
start_mb => start, -- once per macroblock
mode_in => partition_mode,
partition_count => partition_count, --identify the subpartition active
frame_dimension_x =>frame_dimension_x, --in mb
frame_dimension_y =>frame_dimension_y,
mbx_coordinate =>mbx_coordinate, --in mb
mby_coordinate =>mby_coordinate,
candidate_mvx =>rest_mvx_c(i), -- port for Lagrangian optimizaton
candidate_mvy =>rest_mvy_c(i),
mv_cost =>rest_p_cost_mv(i),
mv_cost_on => mv_cost_on, -- enable mv cost
all_done_fp => all_done_fp,
calculate_sad_done => rest_calculate_sad_done(i),
best_sad_fp =>rest_best_sad_fp(i),
best_mv_fp =>rest_best_mv_fp(i),
dma_address =>dma_address, -- next reference memory address
mb_data_in => current_pixels_fp, -- shared mb memory
dma_data_in =>dma_data_in, -- pixel in for reference memory
dma_rm_we =>dma_rm_we, --enable writing to reference memory

--dma_cm_we =>dma_cm_we, --enable writing to current macroblock memory
dma_residue_out =>open, -- get residue from winner mv
dma_re_re => dma_re_re-- enable reading residue
);
end generate;
point_memory_qp_qp : if CFG_PIPELINE_COUNT_QP = 1 generate
-- qp point memory
point_memory_qp : point_memory
port map(
addr =>point_memory_address_qp,
din =>point_memory_data_in,
clk =>clk,
dout => next_point_displacement_qp,
we => dma_pom_we
);
point_memory_address_qp <= dma_address(7 downto 0) when dma_pom_we = '1' else
next_point_qp;
end generate;
no_qpgen1 : if CFG_PIPELINE_COUNT_QP= 0 generate
next_point_displacement_qp <= (others => '0');
end generate;
-- displace the mv by 2 pixels to define the interpolation area when interpolation active
mv_displacement_fp <= next_point_displacement_fp when enable_hp_inter = '0' else x"14FC";
--(20,-4)
mv_displacement_qp <= next_point_displacement_qp;
done_interrupt <= done_interrupt_int;
register_file1 : register_file
generic map(integer_pipeline_count => (CFG_PIPELINE_COUNT))
port map(

clk => clk,
clear => clear,
reset => reset,
addr => register_file_address,
write => register_file_write,
data_in => register_file_data_in,
data_out => register_file_data_out,
start => start,
mode_out => partition_mode,
mv_cost_on => mv_cost_on, -- activate the costing of mvs
all_done_fp => all_done_fp,
all_done_qp => all_done_qp,
mvc_to_do => mvc_to_do,
mvc_done => mvc_done, -- all motion vector candidates evaluated
instruction_zero => instruction_zero,
partition_done_fp => partition_done_fp,
partition_done_qp => partition_done_qp,
done_interrupt => done_interrupt_int,
start_row => start_row,
load_mv => load_mv_fp, -- force the mvc to move foward
update_fp => update_fp,
best_sad_fp => best_sad_out_fp,
best_mv_fp => best_mv_out_fp,
first_mv_fp => first_mv_fp,
rest_first_mv_fp => rest_first_mv_fp,
mbx_coordinate =>mbx_coordinate,
mby_coordinate =>mby_coordinate,
mvp_x => mvp_x,
mvp_y => mvp_y,
quant_parameter => quant_parameter,
frame_dimension_x =>frame_dimension_x,
frame_dimension_y =>frame_dimension_y,
partition_count => partition_count,
update_qp => update_qp,
best_sad_qp => best_sad_out_qp,
best_mv_qp => best_mv_out_qp,
first_mv_qp => first_mv_qp
);
compact_memory0 : if CFG_CM = 0 generate

reference_memory_large : reference_memory64_remap --This memory stores the 7x5
port map(
addr_r => rm_address_r,
addr_w => rm_address_w,
enable_hp_inter => enable_hp_inter, -- working in interpolation mode
clk => clk,
next_configuration => start, -- use the start signal to move between configurations
all_done_fp, -- move to the next configuration when programs completes
start => start,
start_row => start_row,
reset => reset,
clear => clear,
din =>dma_data_in,
dout =>reference_pixels_in,
dout2 => reference_pixels_in2,
we => dma_rm_we
);
end generate;
compact_memory1 : if CFG_CM = 1 generate
rm_address_c <= rm_address_w(9 downto 0) when dma_rm_we = '1' else rm_address_r(9
downto 0);
reference_memory_compact : reference_memory64_remap_compact -- This memory stores the
5x5 reference data (800 words of 64 bit)
port map( -- It also remaps the addresses
addr => rm_address_c,
enable_hp_inter => enable_hp_inter, -- working in interpolation mode
clk => clk,
next_configuration => start, -- move to the next configuration
start_row => start_row,
reset => reset,
clear => clear,
din => dma_data_in,
dout => reference_pixels_in,
dout2 => reference_pixels_in2, -- from the second read port
we => dma_rm_we
);
end generate;

--when qp mode it is the systolic array which decides when data is valid
concatenate_qp_qp : if CFG_PIPELINE_COUNT_QP = 1 generate
concatenate_qp_a : concatenate64_qp -- this unit makes sure that 8 valid pixels are assemble
depending on byte address
port map(
addr => hp_address_a,
clk => clk,
clear => clear,
reset => reset,
din => hp_pixels_out_a,
din2 => hp_pixels_out2_a,
dout => reference_pixels_out_qp_a,
enable => hp_pixels_valid,
quick_valid => quick_valid_qp, --as valid but one cycle earlier
valid => shift_concatenate_valid_qp -- indicates when 64 valid bits are in the output
);
concatenate_qp_b : concatenate64_qp -- this unit makes sure that 8 valid pixels are assemble
depending on byte address
port map(
addr => hp_address_b,
clk => clk,
clear => clear,
reset => reset,
din => hp_pixels_out_b,
din2 => hp_pixels_out2_b,
dout => reference_pixels_out_qp_b,
enable => hp_pixels_valid,
quick_valid => open, --as valid but one cycle earlier
valid => open -- indicates when 64 valid bits are in the output
);
end generate;
no_qpgen2 : if CFG_PIPELINE_COUNT_QP = 0 generate
reference_pixels_out_qp_a <= (others => '0');
reference_pixels_out_qp_b <= (others => '0');

shift_concatenate_valid_qp <= '0';
end generate;
-- when no qp mode different concatenate unit
concatenate_fp : concatenate64 -- this unit makes sure that 8 valid pixels are assemble
depending on byte address
port map(
addr => int_rm_address(2 downto 0),
clk => clk,
clear => clear,
reset => reset,
din => reference_pixels_in,
din2 => reference_pixels_in2,
dout => reference_pixels_out_fp,
enable => enable_concatenate_unit,
enable_hp_inter => enable_hp_inter, -- working in interpolation mode
quick_valid => quick_valid, --as valid but one cycle earlier
valid => shift_concatenate_valid_fp -- indicates when 64 valid bits are in the output
);
-- half pel interpolation engine
interpolate2_qp : if CFG_PIPELINE_COUNT_QP = 1 generate
interpolate2 : systolic_array_top
port map(
clear =>clear,
reset => reset,
enable_interpolation =>enable_hp_inter,
enable_estimation =>qp_mode,
clk =>clk,
data_in =>reference_pixels_out_fp,
data_in_valid =>shift_concatenate_valid_fp,
data_request =>data_request_hp_inter,
all_done =>hp_interpolation_done,
next_point => next_point_inter, -- tell the main control unit that the next point is required
shift_concatenate_valid =>shift_concatenate_valid_qp, -- need to know when 64 bits are valid
-- memory interface for o,h,v and d memories
candidate_mvx => candidate_mvx_qp,
candidate_mvy => candidate_mvy_qp,
hp_address_a => hp_address_a,

hp_address_b => hp_address_b,
data_out_a => hp_pixels_out_a, --interpolated data out port a
data_out2_a => hp_pixels_out2_a, --interpolated data out
data_out_b => hp_pixels_out_b, --interpolated data out port b
data_out2_b => hp_pixels_out2_b, --interpolated data out
data_out_valid => hp_pixels_valid --signal to indicate 8 bytes of data valid
);
end generate;
no_qpgen3 : if CFG_PIPELINE_COUNT_QP = 0 generate
data_request_hp_inter <= '0';
hp_interpolation_done <= '0';
next_point_inter <= '0';
hp_address_a <= (others => '0');
hp_address_b <= (others => '0');
hp_pixels_out_a <= (others => '0'); --interpolated data out
hp_pixels_out_b <= (others => '0');
hp_pixels_valid <= '0';
end generate;
-- data for qp engine always comes from the concatenate unit
qp_pixels_valid <= shift_concatenate_valid_qp;
qp_pixels_out_a <= reference_pixels_out_qp_a;
qp_pixels_out_b <= reference_pixels_out_qp_b;
forward1 : forward_engine
port map(
clk =>clk,
clear =>clear,
reset =>reset,
mode_in => partition_mode,
partition_count_in => partition_count,
enable_hp_inter =>enable_hp_inter, -- when hp interpolation is being performed in the
background
write_register =>shift_concatenate_valid_fp,
in_pixels =>reference_pixels_out_fp,
write_block1 =>open, -- control which of the two blocks is being read and written
(interpolate and dist engine)
rma_address =>rma_address_fp, -- extracted reference pixels use this address

rma_we => rma_we_fp,
out_pixels => out_pixels_fp
);
interpolate1_qp : if CFG_PIPELINE_COUNT_QP = 1 generate
interpolate1 : qp_interpolate_engine
port map(
clk=>clk,
clear=>clear,
reset=>reset,
qp_mode => qp_mode, -- in qp mode two lines must be written to interpolate
enable_hp_inter => enable_hp_inter,
write_interpolate_register=> qp_pixels_valid,
interpolate_in_pixels_a => qp_pixels_out_a,
interpolate_in_pixels_b => qp_pixels_out_b,
write_block1 => open, -- control which of the two blocks is being read and written
(interpolate and dist engine)
rma_address => rma_address_qp, -- extracted reference pixels use this address
rma_we => rma_we_qp,
interpolate_out_pixels => out_pixels_qp
);
end generate;
no_qpgen4 : if CFG_PIPELINE_COUNT_QP = 0 generate
write_block1_qp <= '0'; -- control which of the two blocks is being read and written
(interpolate and dist engine)
rma_address_qp <= (others => '0'); -- extracted reference pixels use this address
rma_we_qp <= '0';
out_pixels_qp <= (others => '0');
end generate;
reference_data_in_fp <= out_pixels_fp;
rm_address_r <= int_rm_address(13 downto 3) when (dma_rm_re_debug = '0') else
dma_address;
rm_address_w <= dma_address;
dma_rm_debug <= reference_pixels_in;
reference_data_in_qp <= out_pixels_qp;

--These two memories will alternate if they are fp or qp
dma_cm_we_m2 <= dma_cm_we when mux_control_write = '1' else '0';
dma_cm_we_m1 <= dma_cm_we when mux_control_write = '0' else '0';
current_pixels_fp <= current_pixels_m1 when mux_control_read = '0' else current_pixels_m2;
current_pixels_qp <= current_pixels_m1 when mux_control_read = '1' else current_pixels_m2;
distance_engine_address_m1 <= rma_address_fp when mux_control_read = '0' else
rma_address_qp;
distance_engine_address_m2 <= rma_address_fp when mux_control_read = '1' else
rma_address_qp;
--two so you can write one while you read the other. Dual port is not enough since you cannot
destroy the contents
cm_address_m1 <= distance_engine_address_m1 when dma_cm_we_m1 = '0' else
dma_address(4 downto 0);
cm_address_m2 <= distance_engine_address_m2 when dma_cm_we_m2 = '0' else
dma_address(4 downto 0);
me_control_unit_qp1_qp : if CFG_PIPELINE_COUNT_QP = 1 generate
me_control_unit_qp1 : me_control_unit_qp
port map( clk =>clk,
clear =>clear,
reset =>reset,
start =>start_qp,
next_point_inter => next_point_inter, -- next point address to ROM
shift_concatenate_valid =>quick_valid_qp,
qp_starting_address =>instruction_address_fp,
instruction_address =>instruction_address_qp,
point_count =>point_count_qp,
point_address =>point_address_qp,
calculate_sad_done =>calculate_sad_done_qp,
instruction_opcode => instruction_qp,
best_eu => best_eu_qp,
next_point =>next_point_qp,

qp_mode =>qp_mode, --enable qp estimation
qp_on => qp_on, -- qp active
load_mv => load_mv_qp,
update =>update_qp,
all_done =>all_done_qp -- program completes
);
end generate;
no_qpgen7 : if CFG_PIPELINE_COUNT_QP = 0 generate
instruction_address_qp <= (others => '0'); -- address to fetch next instruction
next_point_qp <= (others => '0');
qp_mode <= '0'; --enable qp estimation
load_mv_qp <= '0';
update_qp <= '0';
all_done_qp <= '0'; -- program completes
qp_on <= '0';
end generate;
best_eu_debug <= best_eu;
me_control_unit1 : me_control_unit
generic map(
integer_pipeline_count => (CFG_PIPELINE_COUNT)
)
port map( clk =>clk,
clear =>clear,
reset =>reset,
start => start,
range_ok => range_ok,
mode_in => partition_mode,
best_sad_in => best_sad_out_fp, -- to make SAD-based decisions
mv_length_in => mv_length_in, -- to make LENGTH-based decisions
qp_on => qp_on, -- qp on
mvc_done => mvc_done, -- all motion vector candidates evaluated
mvc_to_do => mvc_to_do,
partition_count_out => partition_count, --identify the subpartition active
start_pipelines => rest_start_pipeline,
active_pipelines => active_pipelines,
shift_concatenate_valid => quick_valid, -- valid output from the concantenate unit (64 bit
ready)

instruction_address => instruction_address_fp, -- address to fetch next instruction
instruction_opcode => instruction_fp, -- the opcode
point_count => point_count_fp, -- how many points to test
point_address => point_address_fp, -- which is the first point to test
calculate_sad_done => calculate_sad_done_fp,
distance_engine_active => distance_engine_active_fp,
interpolation_done => hp_interpolation_done,-- interpolation completes
interpolate_data_request => data_request_hp_inter,-- interpolator requests data
line_offset => line_offset, -- read the different lines of the reference macroblock
enable_concatenate_unit => enable_concatenate_unit,
-- enable_dist_engine => enable_dist_engine,
write_register => write_register,
load_mv => load_mv_fp,
best_eu => best_eu,
update => update_fp,
instruction_zero => instruction_zero,
all_done => all_done_fp,
partition_done => partition_done_fp,
qpel_loc_x =>qpel_loc_x, -- detect qp mode
qpel_loc_y =>qpel_loc_y,
next_point => next_point_fp,
start_qp => start_qp,
enable_hp_inter =>enable_hp_inter,
-- write_block1 => write_block1, -- control which of the two blocks is being read and
written (interpolate and dist engine)
-- next_rm_address_ready => next_rm_address_ready,
next_rm_addresss => next_rm_address, --physical address for reference (macroblock upper
left corner
rm_address => int_rm_address -- internal reference memory addresses
-- rma_address => rma_address, -- extracted reference pixels use this address
-- rma_we => rma_we
);
-- calculate the length of the motion vector
mv_length_in <= (best_mv_out_fp(15 downto 8) - mvp_x) & (best_mv_out_fp(7 downto 0)
- mvp_y);
gen_mv_cost_qp : if (CFG_MV_COST = 1 and CFG_PIPELINE_COUNT_QP = 1) generate
-- mv cost unit
mv_cost_qp : mv_cost

generic map(pipelines => CFG_PIPELINE_COUNT_QP)
port map(
clk => clk,
clear => clear,
reset => reset,
load => load_mv_qp, -- start calculation of mv costs for qp
mvp_x => mvp_x, -- predicted mv x
mvp_y => mvp_y, -- predicted mv y
mvx_c =>candidate_mvx_qp, -- motion vector candidate x
mvy_c =>candidate_mvy_qp, -- motion vector candidate y
rest_mvx_c =>rest_mvx_c, -- rest of motion vector candidates x
rest_mvy_c =>rest_mvy_c, -- rest of motion vector candidates y
quant_parameter => quant_parameter,
p_cost_mv => p_cost_mv_qp,
rest_p_cost_mv => open
);
end generate;
no_gen_mv_cost_qp : if (CFG_MV_COST = 0 or CFG_PIPELINE_COUNT_QP = 0) generate
p_cost_mv_qp <= (others => '0');
end generate;
gen_mv_cost_fp : if CFG_MV_COST = 1 generate
-- mv cost unit
mv_cost_fp : mv_cost
generic map(pipelines => CFG_PIPELINE_COUNT)
port map(
clk => clk,
clear => clear,
reset => reset,
load => rest_start_pipeline(0), -- start calculation of mv costs for fp
mvp_x => mvp_x, -- predicted mv x
mvp_y => mvp_y, -- predicted mv y
mvx_c =>candidate_mvx_int, -- motion vector candidate x
mvy_c =>candidate_mvy_int, -- motion vector candidate y
rest_mvx_c =>rest_mvx_c, -- rest of motion vector candidates x
rest_mvy_c =>rest_mvy_c, -- rest of motion vector candidates y
quant_parameter => quant_parameter,
p_cost_mv => p_cost_mv,
rest_p_cost_mv => rest_p_cost_mv
);

end generate;
no_gen_mv_cost_fp : if CFG_MV_COST = 0 generate
p_cost_mv <= (others => '0');
end generate;
-- fp distance engine
distance_engine_fp : distance_engine64
generic map (qp_mode => '0')
port map(
clk =>clk,
clear =>clear,
reset =>reset,
enable => rma_we_fp, -- calculate when new data available
update => update_fp, -- instruction completes set the best sad register to FFFF
load_mv => load_mv_fp,
mode_in => partition_mode,
mv_cost_on => mv_cost_on,
mv_cost_in => p_cost_mv,
candidate_mvx => candidate_mvx_fp,
candidate_mvy => candidate_mvy_fp,
reference_data_in => reference_data_in_fp,
current_data_in => current_pixels_fp,
residue_out => residue_out_fp,
enable_fifo => enable_fifo_fp,
reset_fifo => reset_fifo_fp,
winner1 => winner1_fp,
calculate_sad_done => calculate_sad_done_fp,
distance_engine_active => distance_engine_active_fp,
best_sad => best_sad_fp,
best_mv => best_mv_fp
);
-- mv/sad selector
sad_selector_fp : sad_selector
generic map(integer_pipeline_count => CFG_PIPELINE_COUNT)
port map(
clk =>clk,
reset =>reset,

clear =>clear,
calculate_sad_done =>calculate_sad_done_fp,
update =>partition_done_fp,
update_fp => update_fp, -- end of iteraction
best_eu => best_eu, --id of best execution unit
active_pipelines => active_pipelines,
best_sad => best_sad_fp,
best_mv => best_mv_fp,
rest_best_sad => rest_best_sad_fp,
rest_best_mv => rest_best_mv_fp,
best_sad_out => best_sad_out_fp,
best_mv_out => best_mv_out_fp
);
best_sad_debug <= best_sad_fp;
best_mv_debug <= best_mv_fp; --debugging port
--qp distance engine
pipeline_qp_qp : if CFG_PIPELINE_COUNT_QP = 1 generate
sad_selector_qp1 : sad_selector_qp
port map (
clk =>clk,
reset =>reset,
clear =>clear,
calculate_sad_done =>calculate_sad_done_qp,
active_pipelines => active_pipelines_qp,
update =>all_done_fp, -- complete fp part set the stored sad
update_qp =>update_qp,
best_eu => best_eu_qp,
best_sad =>best_sad_qp,
best_mv =>best_mv_qp,
rest_best_sad =>rest_best_sad_qp,
rest_best_mv =>rest_best_mv_qp,
best_sad_out =>best_sad_out_qp,
best_mv_out =>best_mv_out_qp
);
distance_engine_qp : distance_engine64
generic map (qp_mode => '0')
port map(
clk =>clk,

clear =>clear,
reset =>reset,
enable =>rma_we_qp,
update => update_qp, -- instruction completes set the best sad register to FFFF
load_mv => load_mv_qp,
mode_in => partition_mode,
mv_cost_on => mv_cost_on,
mv_cost_in => p_cost_mv_qp,
candidate_mvx => candidate_mvx_qp,
candidate_mvy => candidate_mvy_qp,
reference_data_in => reference_data_in_qp,
current_data_in => current_pixels_qp,
residue_out => residue_out_qp,
enable_fifo => enable_fifo_qp,
reset_fifo => reset_fifo_qp,
winner1 => winner1_qp,
calculate_sad_done => calculate_sad_done_qp,
distance_engine_active => open,
best_sad => best_sad_qp_distance_engine,
best_mv => best_mv_qp
);
best_sad_qp <= best_sad_qp_distance_engine when all_done_fp = '0' else best_sad_out_fp; --
stored best sad fp in qp part
end generate;
no_qpgen8 : if CFG_PIPELINE_COUNT_QP = 0 generate
distance_engine_address_qp <= (others => '0');
residue_out_qp <= (others => '0');
enable_fifo_qp <= '0';
reset_fifo_qp <= '0';
winner1_qp <= '0';
calculate_sad_done_qp <= '0';
best_sad_qp <= (others => '0');
best_mv_qp <= (others => '0');
end generate;

next_rm_address_ready <= '1';
-- control the wiring of the memories
regs : process(clk,clear)
begin
if (clear = '1') then
mux_control_write <= '0';
mux_control_read <= '0';
elsif rising_edge(clk) then
if (reset = '1') then
mux_control_write <= '0';
mux_control_read <= '0';
elsif (start = '1') then
mux_control_write <= not(mux_control_write);
elsif (all_done_fp = '1') then
mux_control_read <= not(mux_control_read);
end if;
end if;
end process regs;
end;
References:
[1] T. Wiegand, G. et al , “Overview of the H.264/AVC Video Coding Standard”, IEEE Trans. on Circuits and Systems for
Video Technology vol. 13, no. 7, pp.560–576, July 2003.

[2]Data locality description: http://www.eetimes.com/design/embedded/4007043/How-to-map-the-H-264-AVC-video-
standard-onto-an-FPGA-fabric.
[3] N. Keshaveni, S. Ramachandran and K. S. Gurumurthy “Design and FPGA Implementation of Integer Transform and
Quantization Processor and Their Inverses for H.264 Video Encoder”, Advances in Computing, Control, &
Telecommunication Technologies, 2009. ACT 2009. International Conference on, pp. 646-649, July 2009
[4] I. Richardson, “The H.264 advanced video compression standard”, Wiley, 2nd edition, 2010.
[5] L. Po and W. C. Ma, IEEE Transactions on “A novel four-step search algorithm for fast block motion estimation”,
Circuits and Systems for Video Technology, vol. 6, no. 3, pp. 313-317, August 1996.
[6] W. I. Choi, B. Jeon and J. Jeong, “Fast motion estimation with modified diamond search for variable motion block sizes”,
Image Processing, 2003. ICIP 2003. Proceedings. 2003 International Conference on, vol. 2, no. 2, pp. 11,
Sept 2003.
[7] How to map the H.264/AVC video standard onto an FPGA fabric -
http://www.eetimes.com/design/embedded/4007043/How-to-map-the-H-264-AVC-video-standard-onto-an-FPGA-fabric.
[8]CODEC Architecture for modules- http://www.drtonygeorge.com/Video/h264/comp_architecture.htm
[9] Q. Peng and J. Jing, “H.264 System on Chip Design and Verification”, The IEEE 2003 Workshop on Signal Processing
Systems(SIPS‟03), 2003.
[10] DSP-Enabled efficient motion estimation for Mobile MPEG-4 video encoding-
http://www.techonline.com/community/21066.
[11] T. Wiegand et al, "Overview of the H.264/AVC Video Coding Standard", IEEE Transactions on Circuits and Systems
for Video Technology, Vol. 13, No. 7, pp. 560-576, July 2003.
[12] T. Wedi and H. G. Musmann, "Motion- and aliasing-compensated prediction for hybrid video coding," IEEE
Transactions on Circuits and Systems for Video Technology, Vol. 13, No. 7, pp. 577- 586, July 2003.
[13] H. S. Malvar et al, "Low-complexity transform and quantization in H.264/AVC," IEEE Transactions on Circuits and
Systems for Video Technology, Vol. 13, No. 7, pp. 598- 603, July 2003.
[14] S. Yeping and S. Ting, "Fast Multiple Reference Frame Motion Estimation for H.264/AVC," IEEE Transactions on
Circuits and Systems for Video Technology, Vol. 16, no. 3, pp 447 – 452, June 2006.
[15] ModelSim simulation software: http://model.com/content/modelsim-pe-student-edition-hdl-simulation .
[16] AIC website: http://www.bilsen.com/aic/
[17] DCT: http://www.domagoj-babic.com/uploads/Pubs/MSC03/msc03.pdf