development of a virtual agent€¦ · capable of performing anamnesis tesi di laurea di paolo...
TRANSCRIPT

SCUOLA POLITECNICA
Corso di Laurea Magistrale in Ingegneria Informatica
Dipartimento dell'Innovazione Industriale e Digitale (DIID)
DEVELOPMENT OF A VIRTUAL AGENT
CAPABLE OF PERFORMING ANAMNESIS
USING IBM WATSON PLATFORM
TESI DI LAUREA DI
PAOLO DAVID RELATORE
PROF. MARCO LA CASCIA
RELATORE AZIENDALE
SIMO EKHOLM
ANNO ACCADEMICO 2016-17

1
Index
Introduction ...................................................................................................................... 7
Chapter 1 – IBM WATSON ............................................................................................ 9
1.1 Cognitive computer science: systems and calculation ....................................... 9
1.2 The ages of information technology ................................................................. 13
1.3 Cloud computing .............................................................................................. 15
1.4 Cloud service models........................................................................................ 17
1.4.1 Infrastructure as a service (IaaS) .............................................................. 17
1.4.2 Platform as a service (PaaS)...................................................................... 18
1.4.3 Software as a Service (SaaS) ..................................................................... 19
1.5 IBM Bluemix ..................................................................................................... 20
1.5.1 Architecture.............................................................................................. 21
1.5.2 IBM Bluemix ecosystem ........................................................................... 23
1.5.2.1 Services ................................................................................................. 23
1.5.2.2 Runtimes .............................................................................................. 24
1.5.2.3 Operating environments ...................................................................... 25
1.5.2.3.1 Eclipse............................................................................................. 25
1.5.2.3.2 Cloud Foundry ................................................................................ 26
1.5.2.3.3 DevOps ........................................................................................... 27
1.5.2.3.4 DevOps services.............................................................................. 28
1.6 IBM Watson ...................................................................................................... 30
1.6.1 Watson Developer Cloud .......................................................................... 31
1.6.2 IBM Watson services ................................................................................ 32
1.6.2.1 Conversation service ............................................................................ 33
1.6.2.1.1 Deep QA ......................................................................................... 34
1.6.2.1.2 Architecture.................................................................................... 36
1.6.2.1.3 Conversation turn ........................................................................... 38
1.6.2.1.4 Intents and entities ........................................................................ 39

2
1.6.2.1.5 Dialog ............................................................................................. 41
1.6.2.1.6 Context ........................................................................................... 41
1.6.2.1.7 Conditions and answers ................................................................. 42
1.6.2.2 Watson Speech to Text service ............................................................. 43
1.6.2.3 Watson Text to Speech service ............................................................. 45
1.7 Other API Watson ............................................................................................. 46
1.8 Representational State Transfer (REST) architecture ....................................... 47
1.9 Node.js ............................................................................................................. 49
1.10 JSON ................................................................................................................. 49
1.11 Organizations and Roles ................................................................................... 49
1.11.1 Spaces....................................................................................................... 51
1.11.2 Routes and domains ................................................................................. 51
1.11.3 Quotas ...................................................................................................... 52
1.11.4 Regions ..................................................................................................... 52
Chapter 2 - ANAMNESIS ............................................................................................. 54
2.1 What is, what is not and what are its features ................................................. 54
2.2 History and origin of the term .......................................................................... 55
2.3 Types ................................................................................................................ 55
2.3.1 Heteroanamnesis ..................................................................................... 56
2.4 Structure .......................................................................................................... 56
2.4.1 Collection of general information ............................................................. 57
2.4.2 Familiar anamnesis ................................................................................... 57
2.4.3 Personal anamnesis .................................................................................. 58
2.4.3.1 Physiological anamnesis ....................................................................... 58
2.4.3.2 Remote pathological anamnesis ........................................................... 59
2.4.3.3 Next pathological anamnesis ................................................................ 60
2.5 Anamnesis sheet .............................................................................................. 60
2.6 The anamnesis today........................................................................................ 62
2.6.1 Social anamnesis ...................................................................................... 62
2.6.2 Pharmacological anamnesis ..................................................................... 63
2.6.3 Functional anamnesis ............................................................................... 63
2.7 The physiotherapeutic functional evaluation ................................................... 63

3
Chapter 3 – DEVELOPMENT ..................................................................................... 66
3.1 Anamnesis: why change ................................................................................... 66
3.2 Physio R&D and the idea to create a virtual agent ........................................... 66
3.3 Objectives ......................................................................................................... 67
3.4 Development of a Watson application in Node.js ............................................ 68
3.4.1 Necessary tools ........................................................................................ 68
3.4.2 Initial setting ............................................................................................. 68
3.4.3 Starting project ......................................................................................... 70
3.5 Use of the Conversation service ....................................................................... 70
3.5.1 Dialog scheme .......................................................................................... 70
3.5.2 Dialog creation ......................................................................................... 73
3.5.3 API integration .......................................................................................... 75
3.6 Use of the Speech to Text service .................................................................... 75
3.6.1 API integration .......................................................................................... 76
3.7 Use of the Text to Speech service .................................................................... 76
3.7.1 SSML ......................................................................................................... 76
3.7.2 API integration .......................................................................................... 77
3.8 Graphic editing and GUI ................................................................................... 78
3.8.1 Options buttons ........................................................................................ 78
3.8.2 Microphone and audio buttons ................................................................ 79
3.8.3 Lateral menu ............................................................................................ 79
3.9 Deploy and final result ..................................................................................... 79
3.10 Statistical report ............................................................................................... 80
3.11 Android project ................................................................................................ 82
Conclusion ...................................................................................................................... 84
Appendix ......................................................................................................................... 85
Code A.1 API Conversation service ............................................................................. 85
Code A.2 API Speech to Text service .......................................................................... 86
Code A.3 API Text to Speech service .......................................................................... 86
Code A.4 CSS buttons.................................................................................................. 87
Code A.5 HTML microphone and audio buttons ......................................................... 87

4
Code A.6 CSS microphone and audio buttons ............................................................. 88
Code A.7 HTML lateral menu ..................................................................................... 89
Code A.8 CSS lateral menu.......................................................................................... 90
References ....................................................................................................................... 91
Ringraziamenti ............................................................................................................... 95

5
Ad Antonio, Rosaria e Giovanni
che oggi si laureano con me

6

7
Introduction
The use of technology has had a considerable impact on modern society,
becoming part of our daily lives and completely changing our habits. This
progress has led in the last decades to the development of some artificial
intelligences, i.e. machines able to make decisions autonomously based on
the knowledge acquired, offering possibilities and scenarios that can first be
traced back to the field of science fiction. The perspectives of a world in
which human beings and artificial systems are fully integrated and can
collaborate efficiently and naturally are there, and their respective limits /
opportunities inevitably depend on the contributions of different scientific
fields, technologies and multidisciplinary approaches. Artificial Intelligence
(AI) is the great hope of the 21st century in all sectors, including medicine.
The AI has already brought important transformations in the world's health
systems, and will take them over the next few years: it will help doctors to
gather, analyze and organize clinical data, make early diagnoses, plan
treatments and find the best solutions for patients. While medical robots and
medical records management software are already well established, projects
have recently been launched and decidedly futuristic products that reinforce
the link between Artificial Intelligence and medicine. Among the various
companies that have taken a prominent position in this new area, there is
certainly IBM, which with its Artificial Intelligence Watson has entered
permanently in the wards of the hospitals. Its remote accessible
development system called Watson Developer Cloud is now used in various
hospitals and university research centers1 to analyze radiographs and
medical records in order to diagnose more or less rare diseases, but also by
offering a "cognitive tutor" for assist both doctors and medical students.
The objective of my thesis is therefore to analyze this interaction between
man and the cognitive system in the medical field and specifically in the
field of physiotherapy. I could do it working in a Danish company called
1 https://www-03.ibm.com/press/us/en/pressrelease/50803.wss

8
Physio R&D IVS where I spent the last months of my university experience
for writing and developing a project developed in Node.js.
Even if Artificial Intelligence is a promising and powerful technology, we
cannot forget that, at least at the moment, it cannot replace man: they are of
enormous help analyzing an amount of data impossible to process for the
human brain, but it is always this last is the element that gives meaning to
the data analyzed.

9
Chapter 1 – IBM WATSON
1.1 Cognitive computer science: systems and
calculation
Current demands driven by big data and the need for more complex
evidence-based decisions have highlighted today the need for an approach
that is different from logic-based computing. Data has become the
competitive advantage and most of it is invisible to traditional computing
platforms. At present, 80% of all data is not structured, i.e. not structured in
a machine-readable format [16]. Unstructured data includes news articles,
research reports, posts on social media and corporate system data [4].
Understanding unstructured data in the form of text documents, images,
video and raw sensor outputs therefore provides great opportunities [26].
Figure 1-1 shows the data growth forecasts.
Figure 1-1 Data in the competitive advantage
The explosion of such data in the last few years, mainly unstructured
(Figure 1-2), has led to the development of a new type of information
system known as the cognitive system.

10
Figure 1-2 Exponential growth of unstructured data drives the need for a new kind of
computer systems (cognitive)
To give a first definition in October 2015 was Dr. John E. Kelly III 2:
"Those of us engaged in serious information science and its application in
the real world of business and society understand the enormous potential of
intelligent systems - the future of such technology - which we believe will be
cognitive, not "artificial" - has characteristics very different from those
generally attributed to AI, generating different types of technological,
scientific and social challenges and opportunities, with different
requirements of governance, politics and management. "
In the same paper, Dr. Kelly defines cognitive calculus:
"Cognitive calculus refers to those systems that learn on a large scale,
reason with purpose and interact with humans in a natural way, rather than
being explicitly programmed, they learn and reason from their interactions
with us and their experiences with the environment. that surrounds them ".
Unlike the programmable computers that preceded them, the goal of
cognitive systems is not to make fast calculations on large amounts of data
through traditional computer programs. Cognitive systems are interested in
2 “Computing, cognition and the future of knowing: How humans and machines are forging a new age of
understanding”

11
the exploration of data, the search for new correlations between them and
the search for a new context in which to provide new solutions. Cognitive
calculus is among the subdisciplines that model artificial intelligence and
uses techniques such as machine learning, data mining, natural language
processing (NLP) and pattern matching to simulate the functioning of a
human brain. These systems are ideal for interacting with an increasingly
complex world. They aim to broaden the boundaries of human cognition by
improving it rather than replacing or replicating the way the human brain
works.
Humans excel at thinking deeply and solving complex problems, yet our
ability to read, analyze and process huge volumes of data is scarce. This is
instead the strength of a cognitive system, which combines these two
strengths (human and computer) in a collaborative solution.
Figure 1-3 Humans and cognitive systems are complementary
The system must do enough analysis to extract the key elements, understand
the problem that the human being is trying to solve and rely on this context
to find the information useful to clarify the problem. The goal is that a
human being can easily exploit the information provided by the cognitive
system and allow the human being to explore the evidence and use this
insight to solve problems or make decisions. Until recently, to interact with
computers, humans had to adapt their way of working at the computer
interface, which was often rigid and inflexible. Cognitive systems provide a

12
much more natural involvement between the computer and the human. For
example, speech recognition allows human beings to interact with the
computer using voice commands. In the cognitive calculation model, users
do not need to spend time learning complex details about tools to effectively
use them or interpret large amounts of information to draw conclusions.
Instead they will spend their time identifying useful models, making
decisions and taking action to improve business and operational processes.
Using these applications a feedback mechanism captures the results of that
interaction and the system must learn from the resulting interaction and
automatically evolve over time, improving its performance.
Figure 1-4 Cognitive systems free users to focus on building better solutions for day-
to-day and big problems
Since cognitive computing mimics thinking, the quality of the output is
based on the quality of the algorithm that wants to imitate it. These models
are improved with machine learning. While a human expert could spend
weeks analyzing data volumes, the computer model can do it in seconds.
Today, several vendors have established cloud computing environments and
offer access to the cloud on the Internet. Users demand the services they
need and provide access to their data. Suppliers offer a pay-per-use model
and provide personalization of the environment to meet the particular needs

13
of users. The cloud computing model greatly reduces access barriers and
with global availability anyone in the world with Internet connectivity has
access to these services.
Cognitive calculation is already having an impact on our lives, even if we
do not realize it. In the immediate future high growth is expected for
traditional IT processes. The same is true for many industries, such as
financial services, media, entertainment and professional services, as
computing power and big data analysis significantly drive job growth in
each area. To build a web that is entirely cognitive, it is necessary to support
this revolution, instructing a new generation of qualified developers whose
task will be not only to give support to the end user, but also to think of new
applications to meet future needs and think creative solutions for new
activities that do not even exist today.
1.2 The ages of information technology
To understand the future of cognitive computing, it is important to place it
in the historical context. To date, two distinct calculation periods have
occurred: the era of tabulation and the era of programming. We are entering
the third and most transformative era of computer evolution, the era of
cognitive computing.The ages can be described as follows:
Figure 1-5 The three eras of computing

14
Tabulating era (1890s – 1940s)
The first era of computer science consisted of single-use electromechanical
systems that counted, using punched cards to insert and store data and
finally instruct the machine on what to do. These tab machines were
essentially calculators designed to count and summarize information and
they did it really well, but in the end they were limited to a single task.
Programming era (1950s - Present)
This began with the transition from mechanical tabulators to electronic
systems and began during the Second World War, driven by military and
scientific needs. After the war, digital "computers" evolved rapidly and
moved into companies and governments. The era of programmable
calculation begins. The big change is the introduction of general-purpose
computer systems that are programmable: they can be reprogrammed to
perform different tasks and solve more problems in the business world and
society. But in the end, they have to be programmed and they are still a bit
'limited in the interaction with humans. Everything we now know as an
information technology device, from the mainframe to the personal
computer, to the smartphone and the tablet, is a programmable computer.
Some experts believe that this computer age will continue to exist
indefinitely.
Cognitive era (2011 - future)
Cognitive calculation is a necessary and natural evolution of programmable
calculation. Cognitive computing systems are intended to extend the
boundary of human cognition. Cognitive computing technologies are not
about replacing or necessarily replicating the way the human brain works,
but it is about extending its capabilities [29]. The first role of a cognitive
computing system is to combine human and machine strengths in a
collaborative environment.

15
Another key element of cognitive systems is a more natural interaction
between man and machine, combined with the ability to learn and adapt
over time.
1.3 Cloud computing
Cloud computing is a generic term that describes the provision of services
on demand, usually via the Internet, on a pay-per-use basis. The term cloud
is used as a metaphor to indicate a virtualized set of hardware resources. It is
actually an abstraction that hides a very complex infrastructure containing
networks, servers, data storage, applications and services.
The definition of the National Institute of Standards and Technology (NIST)
says that:
"Cloud computing is a model for enabling convenient and on-demand
network access to a shared pool of configurable computing resources that
can be quickly delivered and released with minimal management effort or
interaction with the service provider ".
Figure 1-6 What is cloud computing?
Cloud computing as an implementation model is replacing a previous
approach in which each application with which the user interacted had their
own personalized services for networking, data storage and computing
power [3]. In the old approach, IT staff had to manage the entire stack, from

16
hardware to the latest software changes. This model does not scale up as
companies and organizations today demand.
Figure 1-7 As opposed to...
Today's applications require a short delivery time. The developers want to
put their product on the market as soon as possible, quickly receive
feedback and make the product better quickly. Precisely the ability to
quickly reuse hardware and accommodate multiple applications and systems
within a single hardware set in isolation, led to the adoption of cloud
computing. The cloud makes hardware resources readily available and quick
to configure, reducing the time it takes developers to show a working
version of their products. It also allows the same resources to be reused for
several successive projects, which is cheaper. Developers expect to be able
to use many languages and interact with predefined services. Cloud
computing provides them with pre-packaged language support, which
allows the support of many more languages than the traditional do-it-
yourself environment.
Developers often want to be able to add more resources to a specific
application (horizontal or vertical scaling) or add multiple duplicate
instances of an application (horizontal or scalar scaling) to handle increased
customer load. Cloud platforms offer standard methods for application

17
scalability, and a pay-as-you-go utility based billing method. Other
advantages offered to developers are:
- Predefined templates and examples that help developers get started
quickly.
- A smaller learning curve to understand the application life cycle.
- Wide range of choices for developers in areas such as programming
languages and frameworks, services and APIs.
- Facilitates integrated development, testing and debugging.
1.4 Cloud service models
There are three different types of cloud service models:
- Infrastructure as a service (IaaS)
- Platform as a service (PaaS)
- Software as a Service (SaaS)
1.4.1 Infrastructure as a service (IaaS)
In the Infrastructure as a service (IaaS) cloud services model, a set of
physical resources such as servers, network devices, and storage disks are
offered to consumers in a confidential and accessible manner. The services
in this model support the application infrastructure. IaaS provides the cloud
computing infrastructure (including servers, storage, network and operating
systems) on-demand and uses self-service tools. Instead of purchasing
servers, software, data center space, or network equipment, organizations
purchase or reserve these resources through an application or API that
automatically reserves or reserves the resources and makes them available.
IaaS offers are built on a standardized, secure and scalable infrastructure.
Hardware virtualization is performed by a program known as hypervisor,
which manages virtual machines or virtual servers, that is, multiple
instances of the operating system running on a specific physical machine.
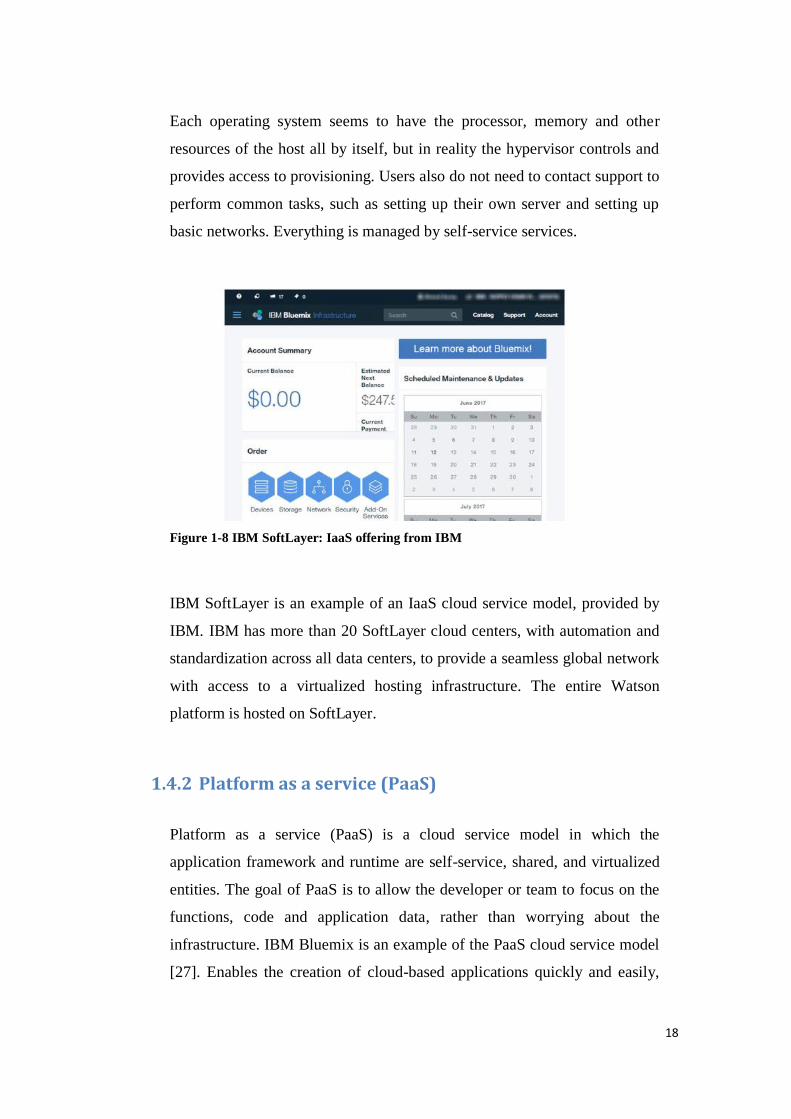
18
Each operating system seems to have the processor, memory and other
resources of the host all by itself, but in reality the hypervisor controls and
provides access to provisioning. Users also do not need to contact support to
perform common tasks, such as setting up their own server and setting up
basic networks. Everything is managed by self-service services.
Figure 1-8 IBM SoftLayer: IaaS offering from IBM
IBM SoftLayer is an example of an IaaS cloud service model, provided by
IBM. IBM has more than 20 SoftLayer cloud centers, with automation and
standardization across all data centers, to provide a seamless global network
with access to a virtualized hosting infrastructure. The entire Watson
platform is hosted on SoftLayer.
1.4.2 Platform as a service (PaaS)
Platform as a service (PaaS) is a cloud service model in which the
application framework and runtime are self-service, shared, and virtualized
entities. The goal of PaaS is to allow the developer or team to focus on the
functions, code and application data, rather than worrying about the
infrastructure. IBM Bluemix is an example of the PaaS cloud service model
[27]. Enables the creation of cloud-based applications quickly and easily,

19
without the complexity of configuring the necessary hardware and software
resources. Typically the PaaS implies that the developer loads the
application code and lets the PaaS complete the following tasks:
- Obtain binary and runtime dependencies for the application.
- Structuring their application bits in the directory tree appropriate for
containerization.
- Provide a container (or a series of containers) on which the application
can be performed.
- Automatically generate a simple and basic network configuration for
accessing the application.
- Provide automatic and integrated monitoring of the application.
- Allow to update and redistribute the application with zero downtime.
PaaS uses external services or APIs that allow a rapid composition of
applications by reusing parts of the infrastructure (for example, a database)
that require minimal or no investment in installation and configuration. PaaS
also offers the developer some automatic methods for resizing. For example,
consider a situation in which the developer wants more hardware resources
dedicated to an application (vertical or vertical scaling) or multiple
application instances to handle the load (horizontal or horizontal scaling).
PaaS also provides integrated application monitoring: for example, the
platform sends notifications to inform developers when their application
crashes abnormally.
1.4.3 Software as a Service (SaaS)
Applications in the SaaS model are provided on-demand to users over the
Internet, as opposed to desktop applications. Examples of SaaS applications
are Google Apps, IBM Cloud for SAP and Facebook applications.
SaaS is a delivery model that provides access to features via web-based
services and enables organizations to access business capabilities, typically
at a lower cost than payment for licensed applications. SaaS prices are often

20
based on a monthly rate. Because the software is hosted remotely,
organizations do not have to invest in new hardware to run the application.
SaaS eliminates the need for organizations to manage installation and
maintenance. Sometimes SaaS applications are free and providers generate
revenue such as from web ads. Alternatively, SaaS application providers
generate revenue directly from the use of the service. These scenarios may
seem familiar because this cloud service model is omnipresent. If you use an
email service to check your mail, you are certainly familiar with this cloud
service model. Thousands of SaaS applications are available and the number
grows every day, mainly due to Web 2.0 technologies [31] [33].
Under the SaaS model, the software vendor is responsible for the creation,
updating, and maintenance of the software, including responsibility for the
software license. Usually, customers rent the software based on usage or
purchase a subscription to access it that includes a separate license for each
person using the software.
In this model, the service user only needs to access the service and not the
platform or infrastructure on which the service is running. The service is
generally used as a Web application or retrieved using REST or other Web-
based APIs.
1.5 IBM Bluemix
IBM Bluemix is the IBM open cloud platform that provides mobile and web
developers with access to IBM software for integration, security,
transactions and other key and software functions from commercial
partners. Use as Paas Cloud Foundry, which is an open service platform
offering a choice of cloud, framework and application services, includes a
command-line interface (CLI) with scripts and integrates various
development tools to facilitate the deployment process . IBM Bluemix is
deployed on IBM SoftLayer data centers.

21
1.5.1 Architecture
Cloud Foundry uses the architecture of Diego to manage the application
lifecycle for implementing and launching the application on Cloud Foundry.
The following notes correspond to the numbers shown in the Figure
1-9:
Figure 1-9 Bluemix architectural overview: behind the scenes
1. The developer interacts with IBM Bluemix using the web browser or
CLI.
2. When sending an application to Cloud Foundry, requests are sent to the
Cloud Controller, which is responsible for managing the application
lifecycle. The CF CLI forwards a request to the Cloud controller to
create a record for the application.
3. The cloud controller stores the application metadata in the Cloud
Controller database (CCDB). Application metadata includes the
application name, the number of instances specified by the user, and the
buildpack and other information about the application.
4. The CF sends a request to the Cloud Controller to load all the
application files.
5. The cloud controller stores the application package in the blobstore.
6. The CF CLI issues an application start command.

22
7. The cloud controller sends a staging request to Diego, which then
schedules a cell to perform the staging task. The activity downloads the
buildpacks and, if present, the app's buildpack cache. Then use the
buildpack to create the droplet. The activity uses the instructions in the
build package to stage the application.
8. The Diego cell transmits the output of the staging process so that the
developer can solve the problems of staging applications.
9. The activity performs the packaging of the resulting staged application
in an archive called "droplet" and the cell Diego stores it in the
blobstore. The task also loads the buildpack cache on the blobstore for
use the next time the application is started.
10. Diego's cell reports to the cloud controller that the animation is
complete. The process must be completed within 15 minutes otherwise
it is considered unsuccessful.
11. The application is planned as a long-lasting process on one or more
Diego cells.
12. Diego's cells report the application status on the Cloud controller and
the output continues streaming to the developer.
Through IBM Bluemix we can build:
- Web and mobile applications created by developers in IBM Bluemix
Cloud Foundry environments.
- Services, i.e. cloud extensions hosted by Bluemix with:
Functionality ready for use by the application.
Predefined services that include databases, messaging, push
notifications for mobile apps, and elastic caching for Web apps.
IBM Bluemix can also host application code that the developer would prefer
to run on a back-end server in a container-based environment.

23
1.5.2 IBM Bluemix ecosystem
The IBM Bluemix environment is an open ecosystem of services, runtimes,
and operating environments.
Figure 1-10 IBM Bluemix ecosystem
1.5.2.1 Services
The services are extensions to the cloud environment that IBM Bluemix
hosts and manages and provides the building blocks for the deployment of
large applications. IBM Bluemix offers a wide range of pre-defined services
that can be used during application assembly. These include those that
include the NoSQL and SQL databases, the ability to send push
notifications to the mobile application and the automatic translation of the
language. You can add services to the IBM Bluemix application from the
IBM Bluemix catalog by choosing from the following service categories:
- Data & Analytics
- Watson
- Internet of Things
- APIs
- Network

24
- Storage
- Security
- DevOps
- Application Services
- Integrate
The services provide a default endpoint that can be accessed by the
application to use the default functionality of that service. The service
infrastructure is managed by IBM Bluemix and the application should focus
only on the endpoint provided. An app can be shared between multiple
services.
1.5.2.2 Runtimes
A runtime is the set of resources used to run an application. IBM Bluemix
provides runtime environments as containers for different types of
applications. Runtime starts with a simple sample application based on
templates that you can customize to meet your needs. These runtimes do not
include any services by default, but you can add and associate their services
later. With IBM Bluemix, developers are given a certain amount of
autonomy on how to run their applications. The IBM runtimes include:
- Tomcat, is an open source Java web application server.
- IBM runtime environments such as IBM WebSphere Liberty, which is
another Java EE application server. Liberty can deploy any Tomcat
application, but it also offers support for many other Java web features.
- SDK for Node.js., provides a stand-alone JavaScript solution for
JavaScript and a server-side JavaScript solution for IBM platforms. It
also provides a high-performance, highly scalable, event-based
environment with non-blocking I / O programmed with the familiar
JavaScript programming language. IBM SDK for Node.js is based on
the open source project Node.js.

25
Runtime is provided through the use of a buildpack, which is a set of scripts
that execute the application packaging process and its dependencies in the
droplets available.
1.5.2.3 Operating environments
The following options are available to develop and deploy the IBM Bluemix
application:
- Eclipse
- Command line interface (CLI), provides an easy way to manage your
application on Bluemix from your workstation. Two possibilities exist in
this regard:
Bluemix command line interface (bx)
Cloud Foundry command line interface (cf)
N.B. : Some IBM Bluemix commands are wrappers of existing cf
commands, while others provide extended functionality for IBM Bluemix
users.
- Continuous delivery using DevOps practices
Figure 1-11 Options to develop and deploy your IBM Bluemix app
1.5.2.3.1 Eclipse
Eclipse is an open source integrated development environment (IDE) that
provides tools for designing, developing, packaging and distributing
software as a desktop application. To integrate it with Bluemix we use IBM
Eclipse for IBM Bluemix, an open source plug-in for interacting with IBM
Bluemix for the management and implementation of applications and

26
services from the Eclipse interface. IBM Eclipse Tools for IBM Bluemix
adds functionality to the Eclipse IDE to start, stop, debug and publish
applications in the IBM Bluemix account, associate a project in the Eclipse
workspace with an IBM Bluemix application, manage and configure
services IBM Bluemix within Eclipse, define the IBM Bluemix environment
variables as part of the deployment process.
1.5.2.3.2 Cloud Foundry
Cloud Foundry is an open-source service platform (PaaS) that provides a
wide range of cloud environments, frameworks and application services.
IBM Bluemix implements IBM Open Cloud Architecture, which is based on
Cloud Foundry. With Cloud Foundry apps, IBM Bluemix provides basic
application management functionality and allows you to connect to pre-
packaged services. The Cloud Foundry Apps catalog contains the following
applications:
Figure 1-12 IBM Bluemix catalog: Cloud Foundry Apps
IBM Bluemix integrates into the Eclipse IDE. Despite the available GUI, it
is reasonable to use CLI if:

27
- You want to implement, update and manage your IBM Bluemix
environment with a quick and minimal tool.
- You want to automate the management and deployment process with
shell scripts.
- You want to use specific tools for each project to provide a certain level
of separation.
1.5.2.3.3 DevOps
The term DevOps derives from the union of the words development (Dev)
and operations (Ops), which before its advent represented the two unique
teams responsible for the delivery of the code:
- Development Team: this team designed the code, provided new features,
fixed bugs and tested the code.
- Operations Team: This team distributed the code to different
environments, maintained production time and diagnosed faults.
With DevOps, both teams work together to support the software life cycle,
from code design to distribution to production. This collaboration includes
the automation of all activities. The developer only needs to develop code
and can then rely on the DevOps platform to do the rest. For example, the
developer can automate the compilation process, code testing and
distribution in different environments.
DevOps offers among others the following advantages:
- From code to production in minutes: work alone or use collaboration
tools to work with a team. In just a few minutes, you can switch from
the source code to a running app.
- Deploy with confidence: automatically distribute your projects every
time a member of the project sends code to your repository. Just
distribute the files as they are inserted, or you can configure more
advanced compilation options.

28
1.5.2.3.4 DevOps services
IBM Bluemix DevOps services are Software as a Service (SaaS) capabilities
that support continuous delivery for the following activities:
- Developing
- Tracking
- Planning
- Deploying
With IBM Bluemix DevOps Services, you can then develop, track, plan and
deploy software in one place. After creating an application, you can deploy
it on the IBM Bluemix cloud platform [17]. It is possible to switch from the
source code to an app running in a few minutes.
Figure 1-13 What services does Bluemix DevOps provide?
Web IDE is an integrated Web-based development environment (Web ID)
where code can be developed (for example, Node.js, Java or any other
code). No other software is needed, in addition to your web browser. The
current job is saved in a cloud-based file directory, which is known as a
local repository. IBM Bluemix provides Eclipse Orion as an integrated

29
development environment (IDE) Web where you can create, edit, run, debug
and perform source code control tasks. You can easily switch it from editing
to execution, sending and distribution. Although the use of Web IDE works
correctly, you can still use a desktop IDE, such as Eclipse with DevOps
services.
Its main features are:
- A working area for the development of source code and configuration
files.
- A complete environment for writing application code using the web
browser.
- Rich code completion functionality for CSS, HTML and JavaScript.
- Ability to deploy, stop and run applications from the Run bar.
- Ability to view logs from the Run bar.
- Ability to make live changes to your application from Web ID
(currently only available for Node.js applications) without the need to
redistribute it via the Bluemix Live Sync feature.
- Debug (currently only available for Node.js applications): When an
Node.js application is in "Live Edit" mode, it is possible to execute its
shell and debug it.
- Desktop Sync: You can synchronize any desktop directory tree with a
cloud-based project workspace similar to the way Dropbox works.
The IBM Bluemix DevOps toolchain offers many options for source control
but the most common choice is to use a Git repository. The Toolchains
feature includes a Git-based Git repository. Git is an open source change
management system. When you enable continuous delivery for a project, a
Git repository is created to manage the source code. Choosing to use Git
repositories in the IBM Bluemix DevOps Web IDE services supports
common Git commands to manage the code. You can also develop the
application on your workstation and transfer the changes to the Git
repository with a standard Git client.

30
The Build & Deploy service automates the process of creating and
distributing code as an IBM Bluemix application. You can also configure
the generation, distribution, or testing of scripts within Web IDE.
The Track & Plow service is used for problem detection and tracks the
progress of development services and IBM Bluemix DevOps.
1.6 IBM Watson
All the great actors of the cognitive services market provide their services
and tools on the Internet on cloud platforms, as in these examples:
- IBM provides Watson cognitive services on IBM Bluemix.
- Amazon AI services are provided through Amazon Web Services
(AWS).
- Microsoft AI tools are available on the MS Azure cloud.
- Google AI services are available in the Google Cloud Platform.
IBM Watson is a cognitive system born in 2014 that allows a new
collaboration between people and computers and represents IBM's cognitive
computing offering [5]. IBM Watson is a technology platform that uses
natural language processing and machine learning to reveal information
from large amounts of unstructured data. Watson analyzes unstructured data
and combines five key features:
1. Interacts with people in a more natural way, based on the person's
preferences.
2. Quickly swallow key industry materials, working with experts to scale
and elevate skills.
3. Allows new products and services to perceive, reason and learn about
their users and the world around them.
4. Use data to improve business processes and forecasts, increasing
operational effectiveness.

31
5. Improve exploration and discovery, discovering unique models,
opportunities and viable hypotheses.
Data, information and skills create the basis for working with Watson.
Figure 1-14 shows examples of data and information that Watson can
analyze and learn and obtain new information that has never been
discovered before.
Figure 1-14 Watson relies on collections of data and information
1.6.1 Watson Developer Cloud
IBM Watson Developer Cloud is a cloud-hosted marketplace where
application providers of all sizes and industries can draw resources for
developing applications based on Watson services. It includes a developer
toolkit, educational materials, and a set of cognitive services such as
RESTful APIs, provided on IBM Bluemix. The goal of Watson Developer
Cloud is to provide the most robust and flexible platform for creating
cognitive applications in deep industry domains. The microservice
architecture allows developers to imagine a wide range of potential
applications by mixing and combining services.
Developers can combine Watson services (and other services available in
IBM Bluemix) with additional logic to create cognitive applications (Figure
1-15).

32
Figure 1-15 Building Cognitive Applications with IBM Watson Services
The extraction analysis of the information provided by Watson's APIs is
open domain, which means that they are able to recognize named entities
belonging to basic types such as company, person and location, but do not
have the ability to recognize more specific distinctions, as the names of
banks, insurance companies and their products. Because most Watson
services rely on a supervised machine learning approach, you can train them
by providing manually labeled data.
1.6.2 IBM Watson services
IBM Bluemix provides resources to your applications through a service
instance. Before you can use Watson services, you must create an instance
of the corresponding service. The IBM Bluemix catalog includes the
Watson services shown in Figure 1-16 (new services are introduced
periodically).

33
Figure 1-16 Watson services in IBM Bluemix
1.6.2.1 Conversation service
The IBM Watson Conversation service is the evolution of the previous
Watson Dialog service, developed to allow a developer to automate
branching conversations between a user and the application. It has allowed
applications to understand what users say and use natural language to
automatically answer their questions. It allows you to quickly create, test
and implement a virtual agent or bot on mobile devices, messaging
platforms like Slack or even a physical robot. The service may track and
store user profile information to learn more about that user, guide the user
through processes based on the user's unique situation, or pass user
information to a back-end system to help user to take action and get the
necessary help. The languages used in the conversation service are English,
Portuguese (Brazilian), French, Italian, Spanish and Japanese and have
experimental support for German, Traditional Chinese, Simplified Chinese
and Dutch. Arabic is supported through the use of the conversation API, but
not through the tools interface [13].

34
1.6.2.1.1 Deep QA
If the Conversation service shows an alternation of questions-answers, it is
necessary to understand how this is managed on an architectural level by the
system under examination.
DeepQA is a QA (Question Answering) architecture originally designed by
IBM to interpret the interactions of the well-known "Jeopardy!" Game in the
USA [9]. DeepQA collects hundreds of possible candidate responses (also
called hypotheses) and, for each of them, generates tests using an extensible
collection of natural language processing algorithms, machine learning and
reasoning [12]. These algorithms collect and evaluate evidence on both
unstructured and structured content to determine the response with
maximum confidence. The general architecture is as follows:
Figure 1-17 DeepQA high level architecture
The simplified version, known as the "DeepQA pipeline", is shown in
Figure 1-18.
Figure 1-18 DeepQA pipeline: the question

35
The pipeline receives a question as input, returns an answer and an
associated confidence score as output, and includes the following
components:
- Analysis of the questions, in which the parsing algorithms decompose
the application in its grammar components while other algorithms
identify and tag specific semantic entities, such as names, places or
dates.
- Primary research and hypothesis generation, in which DeepQA
performs a series of general research for each of the different
interpretations of the application. These searches are performed on a
combination of unstructured data (documents in natural language) and
structured data (available databases and knowledge bases) provided to
Watson during training. We need to generate a broad set of hypotheses,
which for this application are called candidate answers.
- Hypothesis and test score, in which the candidate's answers are first
evaluated independently of any further tests by more in-depth analysis
algorithms.
- Final merging & ranking, in which the many possible answers are
evaluated by numerous algorithms to produce hundreds of
characteristics scores. The trained models are applied to evaluate the
relative importance of these feature scores. These models are trained
with machine learning methods to predict, based on past performance,
the best way to combine all these scores to produce definitive numbers,
unique to each candidate's answer and to produce the final ranking of
all candidates. The answer with the utmost confidence is Watson's final
answer.

36
1.6.2.1.2 Architecture
Watson Conversation brings together the features represented by Natural
Language Classifier, Natural Language Understanding and Dialog and
exposes them through a single tool. It is possible to integrate this service
with additional functionalities, such as Tone Analyzer, Speech to Text and
Text to Speech.
Figure 1-19 Conversation: Reference architecture
With the IBM Watson Conversation service, you can create an application
and user agents that understand natural language input and communicate
with users by simulating a real human conversation. The conversation
service uses deep learning techniques to respond to clients in a way that
simulates a conversation between humans. Let's take a closer look at its
basic architecture.

37
Figure 1-20 Typical architecture of a Conversation application
1. Users interact with the application through one or more chosen
interfaces. The common choices could be messaging services (Facebook
Messenger, Slack, Twitter Direct Messages (DM)), a chat window
within a website or even audio interfaces when combined with Watson
to Text speech synthesis services.
2. The application sends user input to the conversation service.
3. The application connects to a workspace. Natural language processing
for the Conversation service takes place within a workspace, which is a
container for all the elements that define the conversation flow for an
application. You can define multiple workspaces in an instance of the
Watson Conversation service. Each work area will be trained to
recognize certain concepts and to direct the flow of conversation that
governs user interaction.
4. The conversation service interprets the user's input, directs the flow of
the conversation and gathers the information it needs. The Watson
conversation service uses machine learning to identify the concepts for
which it has been trained. Based on the concepts identified, it directs the
conversation flow, to provide the user with information or to gather
additional information from users. Additional Watson services can be
linked to analyze user input, such as Tone Analyzer or Speech to Text.
5. The application can also interact with existing back-end systems based
on the user's intentions and additional information. For example, search

38
for information in public or private databases, open tickets, show
diagrams and maps, or write user input into your registration systems.
1.6.2.1.3 Conversation turn
A single user input cycle and a response is called a conversation shift
(Figure 1-21). Each conversation shift begins in a dialog node, called an
active node. Let's see how it works more specifically:
Figure 1-21 Next active node selection criteria
1. The conversation starts in a starting node set with the special
conversation_start condition.
2. After a few conversation turns, the dialog box switches to the node
marked as active node.
3. The response configured in this node is shown to the user. User input is
parsed for intent and entity and used to select the next dialog node in
the stream.

39
4. The conditions in the child nodes are evaluated in descending order
using the intents and the extracted entities. The first child node that
matches a condition is selected as the next active node and a new
conversation shift is started (not shown in the figure).
5. If no child node matches the condition, the Conversation service
evaluates the conditions of each base node in the dialog and selects the
first node of the corresponding dialog as the next active node.
6. A useful approach is to have a base node configured with the special
nothing_else condition so that the conversation is set to this node when
no other node matches the conditions. The nothing_else condition is
always valid. You can use this node in the dialog box to tell the user
that the input was not understood and to suggest a valid interaction.
1.6.2.1.4 Intents and entities
Natural language processing for the Watson Conversation service takes
place in a workspace, which is a container for all artifacts that define the
conversation flow for an application [1].
The conversation is managed via three key concepts (Figure 1-22):
#intents: the purpose of user input; what the user wants to reach.
@entity: a term or object that is relevant to the intent. Provides the
context.
Dialog: allows the service to respond to users based on the intentions
and entities recognized in their queries. Using dialog nodes you can
instruct the service to give simple answers when it detects certain
intentions, to request clarification when key information is missing, or
to guide users through more elaborate processes using the advanced
features of the Conversation service, creating natural conversations
between apps and users, without requiring any coding experience.

40
Figure 1-22 Conversation service: Showing intent, entity, dialog
In developing a chat, one of the biggest challenges in developing a
conversation interface is the anticipation of every possible way in which
users will try to communicate with the chatbot [23]. A component will
provide a history of conversations with users. It is recommended to use this
history to improve the understanding of the chatbot on user input [30].
Let's look at an example where we try to extract intent and entities from a
conversation between two people (Figure 1-23).
Figure 1-23 Example of intents and entities in a conversation

41
If you want to create a conversational application that can help Nelson in the
same way that Marie can do it, you must train it to identify the intent
#find_a_place and the @transp_landmark entity, and its possible values.
Thus, you can activate a mapping API to direct Nelson to his destination.
1.6.2.1.5 Dialog
Users are unlikely to provide all the required information in a single step.
Instead, it is necessary to organize a conversation flow that will ask users
the questions that are useful in order to gather all the inputs necessary to
provide a useful answer.
A dialog is a branched conversation flow that defines how your application
responds when it recognizes the intended intent and entities. Create a branch
of dialog for each purpose, to collect all the required information and
provide a useful answer. Dialog nodes are concatenated in a tree structure to
create an interactive conversation with the user. Each node starts with one or
more lines that the bot shows the user to request an answer. Each node
includes conditions for the node to be activated and also an output object
that defines the response provided. It is possible to think of the node as an
if-then construct: if this condition is true, return this answer. The simplest
condition is a single intent, which means that the response is returned if user
input is mapped to that intent. The dialog nodes that originate on another
node are the related child nodes. Dialog nodes that do not depend on other
nodes are basic nodes.
1.6.2.1.6 Context
The dialog context is the mechanism for passing information between the
dialog and the application code, and how in a real conversation the context
matters. It allows you to store information to continue to pass it back and
forth between the different dialog nodes. For example, if you identify the

42
names of users in the conversation stream, you can store information in
context and retrieve it each time you want to call the user by name. The
context is described as a JSON entry within the node or can be changed in
the app before the REST call. Dialog is stateless, which means that it does
not retain information from one interchange to the next. The application is
responsible for maintaining any continuous information. However, it can
pass information to the dialog and the dialog can update context information
and pass it back to the application. In the context, you can define any
supported JSON type, such as simple string variables, numbers, JSON
arrays, or JSON objects.
1.6.2.1.7 Conditions and answers
The condition part of a dialog node determines whether that node is used in
the conversation. Conditions are logical expressions that are evaluated as
true or false and are used to select the next dialog node in the stream or to
choose from possible responses to the user. The conditions are expressed in
the Spring Expression Language (SpEL) and usually evaluate the intent and
entities identified in the user responses, but they can also evaluate the
information stored in the context. This context information can be stored in
the previous dialog nodes or application code as part of an API call.
Figure 1-24 shows a sample dialog node conditioned on a specific location
(NYC) and time (31-Dec-2017) so you can recommend visiting Times
Square for New Year's Eve. The responses are messages based on the intent
and the identified entities that are communicated to the user when the dialog
node is activated. You can add variations of the response for a more natural
experience or add conditions to choose a response among many in the same
dialog node.

43
Figure 1-24 Special condition (place and time) to celebrate New Year's Eve in Times
Square
1.6.2.2 Watson Speech to Text service
Watson Speech to Text, Text to Speech, Visual Recognition and Language
Translator services have been developed to complement Watson's machine
perception capabilities in addition to the NLP tools highlighted in the
question analysis phase. The Speech to Text service converts the voice, the
speech into written text readable according to the language specified by the
user [14]. The service is able to transcribe speech from various languages
and audio formats in text with low latency. This service uses speech
recognition features to convert text to Arabic, English, Spanish, French,
Brazilian Portuguese, Japanese and Mandarin. For most languages, the
service supports two sample rates: broadband and narrowband. The speech
synthesis service has been developed for a wide general public. The basic
vocabulary of the service contains many words used in everyday
conversation. This general model provides sufficiently accurate recognition
for a variety of applications, but may present gaps in the knowledge of

44
specific terms associated with particular domains. To customize speech
synthesis for a given domain, a new language model is needed to provide
the nuances in that domain in terms of words and pronunciations of words.
With the language model customization interface, it is possible to improve
the accuracy of speech recognition for domains such as medicine, law,
computer technology and others. Customization allows you to expand and
adapt the vocabulary of a base model to include domain-specific data and
terminology. After providing data for the domain and creating a custom
language template that reflects this data, you can use the model with your
own applications to provide customized speech recognition.
Simple APIs can be used in the following technologies:
- Node.js
- Java
- cURL
- Node-RED
You can log in to the Speech to Text service using the username and
password provided as credentials for the service instance that you want to
use. The flow of the Speech to Text service is shown in Figure 1-25.
Figure 1-25 Speech to Text flow
1. The user specifies an audio file, which can be recorded live or
previously prepared.
2. The speech is sent to the Speech to Text service for processing.
3. The Speech to Text service generates text based on the audio file.

45
1.6.2.3 Watson Text to Speech service
Text to Speech Watson service converts text written in sound from natural
sound into a variety of languages and voices. It is multilingual, so it accepts
text as input and generates an audio file in various languages. The input text
can be plain text or written in speech synthesis language (SSML). In
addition, it emits various styles of pronunciation, height and speed of
conversation. The Voices feature synthesizes audio text in a variety of
languages, including English, French, German, Italian, Japanese, Spanish
and Brazilian Portuguese. The service offers at least one male or female
voice, sometimes both, for each language and different dialects, such as
American English and British and Castilian Spanish, Latin American and
North American. The audio uses appropriate cadence and pitch.
Synthesizing the text with the speech synthesis service, the service applies
language-dependent pronunciation rules to convert the ordinary (spelling)
spelling of each word into a phonetic spelling. The normal rules of service
pronunciation work well for common words [15]. However, they may
produce imperfect results for unusual words such as special terms with
foreign origins, personal or geographical names and abbreviations and
acronyms. When the application lexicon includes these words, the service
can produce imperfect pronunciations. To solve this problem, the service
provides a customization interface that you can use to specify how to
pronounce unusual words that occur in your input.
The speech synthesis service customization interface allows you to create a
dictionary of words and their translations for a specific language. This
dictionary of words and their translations is referred to as a personalized
voice model, or just a personalized template. Each entry in a customized
voice model consists of a pair of words / translations. The translation of a
word indicates to the service how to pronounce the word when it occurs in
the input text. The customization interface provides methods for creating
and managing custom templates, which the service stores permanently. The
interface includes methods for adding, editing, deleting and querying words
and translations in a custom template.
46
Simple APIs can be used in the following technologies:
- Node.js
- Java
- cURL
- Node-RED
You can authenticate yourself to the text-to-speech service by providing the
username and password provided in the service credentials for the service
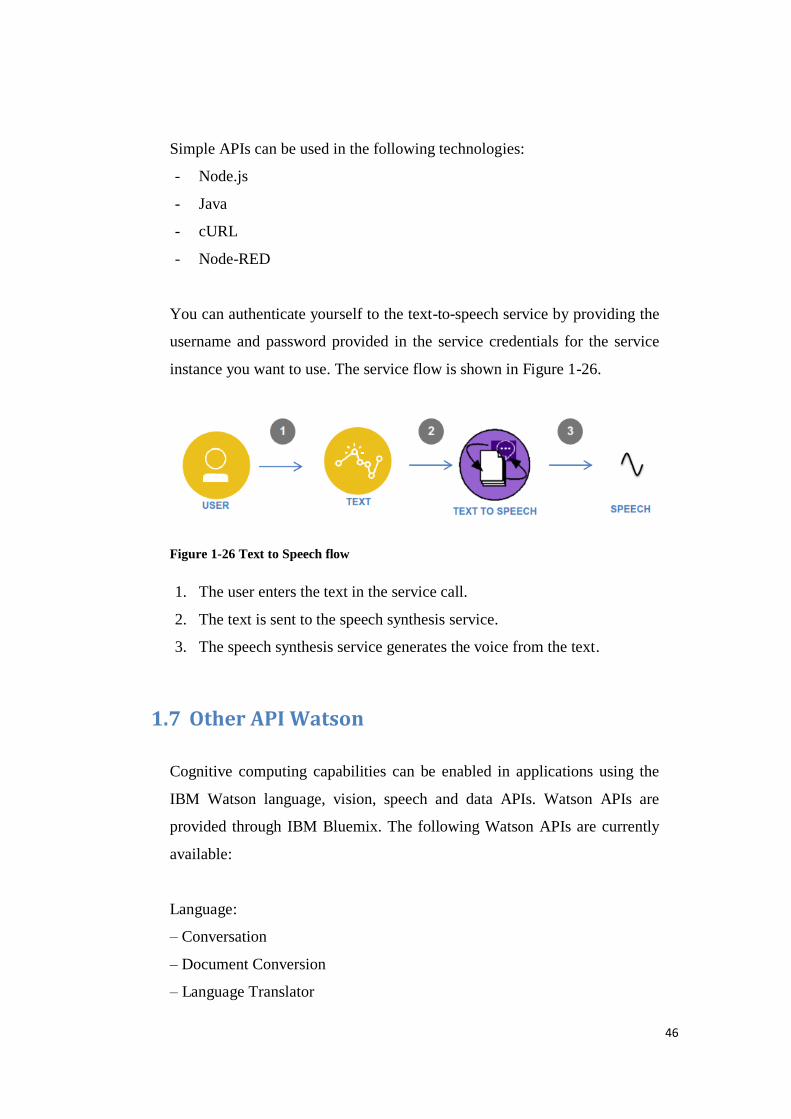
instance you want to use. The service flow is shown in Figure 1-26.
Figure 1-26 Text to Speech flow
1. The user enters the text in the service call.
2. The text is sent to the speech synthesis service.
3. The speech synthesis service generates the voice from the text.
1.7 Other API Watson
Cognitive computing capabilities can be enabled in applications using the
IBM Watson language, vision, speech and data APIs. Watson APIs are
provided through IBM Bluemix. The following Watson APIs are currently
available:
Language:
– Conversation
– Document Conversion
– Language Translator

47
– Natural Language Classifier
– Natural Language Understanding
– Personality Insights
– Retrieve and Rank
– Tone Analyzer
Speech:
– Speech to Text
– Text to Speech
Vision:
– Visual Recognition
Data Insights:
– Discovery
– Discovery News
The various APIs that provide access to various services allow quick, easy
and intuitive access to IT systems. Most APIs are independent of the
programming language, which means developers can work in any
programming language they want. The use of APIs for sharing data, services
and business functions between endpoints (such as applications, devices and
websites) creates the opportunity to reduce costs and integration time.
1.8 Representational State Transfer (REST)
architecture
Representational State Transfer (REST) is a style of architecture for creating
resources on the Web. In a broader sense, web resources are a source of
information. For example, HTML documents define the structure of a web
page, CSS documents (Cascading Style Sheet) define the presentation of a
Web page and image files provide a visual representation of the information

48
[7]. REST then allows you to create services for client / server interactions,
which are based on Web resources. To identify which resource to retrieve or
update, REST uses a Uniform Resource Identifier (URI) to describe the
network path of the server application resource.
Various HTTP methods are used to call a REST service:
- GET, used to retrieve information from the server. When you use the
browser to navigate to any URI, you use the GET method to get the
HTML of that website. The query string that contains the parameters
required for the request is sent to the URL by placing a question mark
(?) at the end of the URI and then writing the parameters. Each
parameter is represented as a name-value pair. The parameters are
separated by an ampersand (&).
- POST, used to send data to the server. In this case, the parameters are
recorded in the request body, not in the URI.
- DELETE, used to delete a resource from the server.
- PUT
- OPTIONS
- HEAD
- TRACE
- CONNECT
N.B. : There is a misconception that REST can only work on the HTTP
protocol, but this idea is not completely true. Although the most common
scenarios for using REST are based on the HTTP protocol, REST can be
used on other transfer protocols, such as SMTP.
REST services tend to use lightweight data models, such as JSON. It is also
used for XML.

49
1.9 Node.js
Node.js is an open-source language that runs on V8, an open source engine
developed by Google for the Google Chrome browser. Although developers
can still use JavaScript for client-side browser functionality in the
framework, such as angularJS, dojo, and jQuery, they can now use Node.js
as a server component in the same language in the same part of the
architecture in which they use Java, Perl, C ++, Python and Ruby. Node.js is
event-based and uses asynchronous and non-blocking I / O.
1.10 JSON
JavaScript Object Notation (JSON) is a text format for structured data. Its
syntax is derived from JavaScript literal objects, according to the ECMA-
262 ECMAScript standard, third edition, which is the standard of the
scripting language. JSON is a data format that is neutral to the platform and
neutral to the language. The main goal of JSON's design is to provide a
minimal, portable textual data exchange format.
JSON is not a markup language because it does not use descriptive tags to
encapsulate its data. Instead, XML is a markup language because it uses
tags, such as <title> </ title>, to declare the page title. JSON is built on two
structures: a collection of name-value pairs known as objects and a list of
values known as arrays.
1.11 Organizations and Roles
Organizations, users, and spaces are the building blocks for organizing
resources in the IBM Bluemix environment. The organization is the main
organizational unit for IBM Bluemix. In IBM Bluemix, organizations can be
used to enable collaboration between team members and facilitate logical
grouping of project resources.

50
Organizations are defined by the following elements:
- Users or team members
- Domains
- Quote
A user (team member) has a role with basic permissions in organizations
and spaces:
- Users must be assigned to an organization before authorizations can be
granted to spaces within an organization.
- Users can belong to more than one organization (which is how you
share access to control and monitor applications and services).
Figure 1-27 IBM Bluemix organizations: User roles
Users can take the following roles in spaces and organizations:
- Organization manager controls who has access to the organization.
- Billing manager can view usage information for the organization.
- Reviewer can view the content of the application and service in the
organization.
- Responsible space can control who has access to the space.
- Space developer can create, delete and manage apps and services within
the space.
- Space auditors only read access to settings, logs, apps and services.

51
The managers of the organization can invite users to the organization and
assign them the various roles.
1.11.1 Spaces
A space is a mechanism for grouping together a set of applications, services,
and team members within an organization. Spaces represent the lowest level
of organizations. Spaces can be used to represent different types of
deployment environments, for example, a development, test, staging, or
production environment.
The following rules apply:
- An organization can have multiple spaces, but these spaces must have
unique names within an organization.
- Two organizations may have their own spaces with the same name, but
two organizations can not share the same space.
- All applications and services are associated with a space.
- You must belong to an organization to belong to one of its spaces.
- Users must be members of an organization to gain access to a space
within that organization.
- A member of a space can view applications within the space.
- Only users in the developer role can create applications and services in
space.
- You must be a developer in the space where an application or service
exists to interact with that application or service as an IBM Bluemix
user.
1.11.2 Routes and domains
A route consists of:
- A domain.

52
- A subdomain, is the host name, which is usually the name of the
application.
A domain could be a system domain or a custom domain registered for the
application. Provides an Internet route assigned to an organization and
together with the path determine how users interact with IBM Bluemix
applications on the network. Each application must have a unique host and
domain name. For IBM Bluemix public applications, the default domain
name is mybluemix.net.
1.11.3 Quotas
Quotas are the limits of resources that can be allocated for use by the
organization, including the following limits:
- Number of services.
- Amount of memory.
Quotas are assigned when organizations are created. Any application or
service in an organization's space contributes to the use of the quota. With
subscription plans, you can change the quota for Cloud Foundry
applications and containers as your organization's needs change.
1.11.4 Regions
An IBM Bluemix region is a defined geographical territory where
applications can be deployed. It is recommended that you select the region
closest to your users and deploy applications in this region to achieve low
application latency. Applications can provide better performance by being
physically closer to users.

53
Figure 1-28 Bluemix: Regions
Different countries with different data security requirements may require the
IBM Bluemix application to run in a different region. Running the
application in multiple regions also helps make the application highly
available. If the application does not work in one region, it is still available
from another region. Not all IBM Bluemix services are available in all
regions. You can easily switch between the IBM Bluemix regions in the
IBM Bluemix web interface.

54
Chapter 2 - ANAMNESIS
2.1 What is, what is not and what are its features
The anamnesis (or clinical history), in medicine, is a survey carried out by
the doctor through the interrogation of the patient or his relatives, in order to
gather information, news and sensations that can help the doctor to address a
diagnosis of a certain pathology. It is a very important element in the
process of identifying a, not yet specified, morbid condition. Sometimes the
anamnesis is sufficient for a definitive diagnosis. Other times, instead, it
only leads to approximate conclusions. In many cases, it delimits an
investigation program, in the sense that it clarifies which in-depth
examinations have a certain type of value and which, on the contrary, are
not very significant.
Together with the objective examination of the patient, it is of fundamental
help in the formulation of the diagnosis as it reconstructs the methods of
onset and the course of the pathology underway, also investigating the
possible genetic inclinations (predisposition to genetic diseases) of the
family group towards the onset of certain types of diseases (familial
anamnesis). In this sense it is also used to launch surveillance programs for
those at risk. Some examples of diseases diagnosed only on the basis of
anamnesis are headaches, psychological illnesses but also mental illnesses.
Tumulty3 wanting to describe what an anamnesis was, he used to compare it
to a chess game:
"The patient makes a statement and, based on its content and mode of
expression, the doctor counteracts with a question. An answer then
3 Tumulty PA, Obtaining the history. In the Effective clinician, in Saunders, december 1973, pp. 17-28.

55
stimulates another question until the doctor is convinced that he has
understood precisely all the details of the patient's illness."
Everybody for make their own job make an anamnesis (accountants,
lawyers) only that the medical anamnesis is a bit special.
The anamnesis is not a pure registration and list of facts reported by the
patient or relatives. The doctor, in fact, must carefully examine every
collected data, according to his own experience and his own preparation
(critical study). In general, anamnesis is totally up to a doctor. However, it
should be noted that any qualified medical assistant has all the skills to
adequately gather the data needed for a subsequent critical analysis.
2.2 History and origin of the term
The word anamnesis derives from the Greek ἀνά-μνησις, "I remember / a
memory". In ancient times the first work done on the anamnesis that has
come to our time was by Rufus Ephesius (in the 150s BC - 80 BC). The
work was then made public once translated into French by Daremberg and
Ruelle, only in the nineteenth century. The term 'anamnesis' was used
initially only in countries that spoke German, in addition to the Netherlands.
The classic anamnesis has changed somewhat over time to take account of
different welfare and organizational aspects and to respect some ministerial
indications for assistance to patients admitted to hospital.
2.3 Types
The anamnesis can be of two types that do not necessarily exclude each
other, indeed, very often the best result comes from their integration:
- Direct, when the information comes directly from the patient (when it is
considered reliable), which shows the signs and testifies to its

56
symptoms. Most of the times the degree of discrepancy between what is
objectively observable (the signs) and what the patient reports (the
symptoms) can give the physician the measure of the reliability of the
patient himself, who can often err on his own condition, not necessarily
due to bad faith.
- Indirect (or Heteroanamnesis), when the patient, in relation to his
psychophysical state, is not considered reliable, in this case we refer to
the documentation that the patient has with him, as well as to the
testimonies of his family members or in any case of those people who
normally they take care of his assistance.
2.3.1 Heteroanamnesis
The anamnesis that the doctor performs through the voice of relatives is also
known as heteroanamnesis. The prefix "hetero" derives from the Greek
word "heteros" (ἕτερος), which means "other" or "different".
The practice of heteroanamnesis occurs when the patient:
- He is a small or very small child, unable to speak.
- He is an elder who has lost the ability to communicate clearly.
- He has some mental disorder.
- For various reasons, it appears not very lucid in the exposition of the
symptomatology.
- He is in a coma or is unconscious.
2.4 Structure
As in the objective examination, it is useless to follow the pattern of the
anamnesis to the letter: the questions to be asked must be adapted to the
context in which we find ourselves. Never rely completely when possible on
what has been said by the patient: in fact, he may not know the proper terms
to express his problem, and omit (voluntarily or not) some information

57
about himself or his relatives risking in this way to mislead the anamnesis. It
is also useless to torment a patient when he says he does not know how to
respond: what he says we use it at his own risk.
In general, anamnesis consists of a questionnaire, a series of questions that
follow a path with 3 main steps, which "touch" various topics and topics:
1. The part dedicated to the patient's general information.
2. The part dedicated to the so-called familiar anamnesis.
3. The part dedicated to the so-called personal anamnesis.
The collection of anamnestic data will be different depending on the age and
sex of the person [20].
2.4.1 Collection of general information
First data are collected on name, age, sex, marital status, place of birth and
residence. These details are used to identify the person you are about to
interrogate. This part is written only the first time that the person comes to
the nurse or doctor's observation, then becoming part of the clinical card (or
the medical record).
2.4.2 Familiar anamnesis
The familiar anamnesis concerns data referring to family members and
diseases suffered by them. It is particularly important for hereditary
diseases, which often occur in several members of the same family group or
are transmitted in a characteristic way.
It provides for only two areas: the ascendants (parents and grandparents)
and collaterals (brothers and sisters). It is therefore investigated on the
health status of the patient's parents and collaterals or on their possible age
and cause of death. This point is very important to know the genetic risk
factors (which can be visualized through a genogram), environmental, or
any family predisposition.

58
Figure 2-1 Impact of familiarity on some frequent pathologies in the clinical setting
[20]
It is a very useful part to clarify whether a particular affection has a
hereditary nature or not and, if it has one, to establish the modalities of
transmission.
The finding of some diseases of a hereditary nature motivates the
prescription of genetic tests: these are used to pinpoint the location of the
genetic mutation and to delineate the type of condition in place.
The family anamnesis is particularly important in cases of: diabetes, obesity,
endocrine diseases, abnormalities of the genital system, gout, hypertension,
cardiovascular diseases, kidney disease, allergic diseases, headaches,
hemorrhagic diseases, jaundices, myopathies etc..
2.4.3 Personal anamnesis
It includes 3 sub-categories: the physiological anamnesis, the remote
pathological anamnesis and the next pathological anamnesis.
2.4.3.1 Physiological anamnesis
It consists of questions, from birth to current time, related to:
- The somatic growth (that is of the body).
- The daily life environment, to clarify working or school conditions.

59
- The habits of life and physiological functions, to understand if the
patient uses or abuses alcohol, smokes, takes drugs.
A possible series of categories to which these questions belong is:
- Birth
- Puberty
- Military service
- Marriage and pregnancies
- Sexuality
- Menopause
- Lifestyles
- Environmental allergies or drugs.
- Alvo
- Urination
- Working activity
- Structural features of the personality
2.4.3.2 Remote pathological anamnesis
The remote pathological anamnesis (APR) concerns affections suffered in
the past and consists of chronological and orderly investigation of the
diseases, traumas and surgical interventions suffered by the patient in the
past (for example, childhood diseases, but also allergic manifestations).
The remote pathological anamnesis is important because it could detect the
presence of a link between the current condition and the past.
At this stage of anamnesis, it is up to the doctors to investigate:
- Infectious diseases.
- Diseases whose recurrences (or distant manifestations) may be
responsible for the patient's current symptomatology.
- Previous surgical interventions.
- Previous bone trauma (eg fractures).
- Previous hospital admissions.

60
- Past surgical interventions.
- Medical visits or laboratory tests previously performed.
2.4.3.3 Next pathological anamnesis
The next pathological anamnesis concerns symptoms and manifestations of
the disease possibly occurring. Also called "recent pathological" or
"anamnesis of the current disease", it concerns the disorder for which the
patient consults the doctor.
It involves a thorough investigation of the disorders, since the latter began
when the patient decided to contact the doctor for further study.
Investigate on:
- Mode of onset of disorders, at the exact moment of their appearance, on
the location, intensity, shape, character and irradiation of pain (if
present).
- Pharmacological anamnesis: medicines prescribed or self-administered
(over-the-counter medications).
- Toxicological anamnesis: use of drugs.
In general, once the patient has exposed his ailments, the doctor focuses his
attention on these and on the anatomical areas they are interested in. The
modalities with which to carry out the next pathological anamnesis depend
on the previous stages of anamnesis.
2.5 Anamnesis sheet
Let's see an example of anamnesis sheet as complete as possible, which will
give us some useful indications [8]. The following are its main components:
- Customer Anamnesis, this is the initial part of the form in which the
Personal Data and the Profession are recorded.

61
- General Anamnesis, detects general information useful for
programming, such as availability at the frequency of workouts,
available time, lifestyle and desired aims.
- Sporty anamnesis, focuses on the sports practiced by the subject in the
past years. It is important to know how long they have been practiced
and how long they have been stopped. This anamnesis, although not yet
specific, will however help the doctor to get a general idea of the level
of motor coordination of the subject, of his relationship with his body,
as well as of his physical condition.
- Clinical Anamnesis, addresses one of the most important points of data
collection as it provides information on the health status of the subject,
which will be fundamental for the development of the work program.
- Alimentary anamnesis, is aimed at defining the customer's food style:
the foods that he usually takes (both liquid and solid), hours of
employment, possible additions, intolerances and allergies. It offers an
overview of its "food culture".
- Physiological Anamnesis, it is the first "practical approach". Through
specific measurements it allows to frame the subject at a morphological
level.
- Postural Anamnesis, evaluate the client, through appropriate tests on
the degree of joint mobility of ankles, knees, hip, lumbar spine and
scapular girdle. Subsequently evaluates the presence of dysmorphism
and / or paramorphism.
Such detailed data collection must be accompanied by an information sheet
of the law on privacy rights; from the customer's consent for the processing
of sensitive, semi-sensitive and judicial personal data, but also of the related
law on how to store these documents.
It is also appropriate and useful to be able to make use of the collaboration
of some or all the medical figures specialized in the various types of
anamnesis to which the subject has been submitted, in order to arrive at the

62
most correct interpretation of the information collected and obtain any
useful indications for the work planning.
2.6 The anamnesis today
In recent times, doctors have lost interest in a careful anamnesis
increasingly relegating the practice to a simple questionnaire, forgetting that
the anamnesis is absolutely the best way to obtain important information.
There are also various diagnostic software, which would allow to carry out
through the use of a normal computer, even very complicated diagnoses.
Lately, in the US, it has also been tried to insert an anamnesis test on the
internet with which the various patients could respond. Alongside the classic
3 parts of the anamnesis, over time the doctor has had to pay attention and
devote much more attention than in the past to important medical matters.
These issues are part of:
1. Social anamnesis
a. Economic / organizational anamnesis
b. Home care assistance anamnesis
2. Pharmacological anamnesis
3. Functional anamnesis
2.6.1 Social anamnesis
An integral part of the anamnesis, of this "subgroup" of anamnesis all the
information concerning different conditions are part of it. The tool evaluates
various variables:
- Living condition.
- Family condition.
- Network of care and support, in particular the presence of relatives /
friends / carers who can help and / or supervise the elderly or presence
of local support services.

63
- Education / training, useful for assessing the degree of understanding of
the need for care and their needs.
- Work condition.
- Economic situation.
All these infos is a good idea to request and have them available from the
patient's entrance in order to be able to direct the therapeutic-care procedure
from the first stages of admission..
2.6.2 Pharmacological anamnesis
In the section of the pharmacological anamnesis all the drugs taken by the
patient at the time of admission should be reported, with relative dosages
and hours of intake. It is also important to report any previous therapies
taken by the patient. The privileged source of information is represented by
the patient; in this way it is possible to verify the actual use of the
medicines, coherent or not with the indications of the attending physician,
and to become aware of further products taken on their own initiative.
2.6.3 Functional anamnesis
An integral part of the nursing anamnesis allows to evaluate the residual
functions of the patient, particularly of the elderly patient. The functional
evaluation of the elderly patient is based on multiple scales that are an
integral part of the multidimensional geriatric evaluation.
2.7 The physiotherapeutic functional evaluation
A fundamental aspect in the work of the physiotherapist is the evaluation of
the patient, who in this specific case takes the name of physiotherapeutic
evaluation or physiotherapy functional evaluation. This is based on a data

64
collection, that is the anamnesis and on the objective examination. The
functional assessment serves to personalize the chosen healing path. Two
people may have the same diagnosis, but present themselves with different
signs and symptoms. The curative path can not, or rather should not, be the
same for both, but will have to adapt to the individual case. Each patient
will present his nuances, and the professional, in our case the
physiotherapist, will have to catch them and interpret them.
The priority is given to how it works (this explains why the functional
adjective), or rather how the painful part does not work properly. And with
functional evaluation, we try to quantify how individual body structures
contribute to the problem. At the end of the anamnesis the physiotherapist
must understand fundamentally whether the patient is in the right place to
try to solve his problem.
Otherwise, on the other hand, the physiotherapeutic functional evaluation
process will continue with the objective physical examination of the patient,
which provides the physiotherapist with a global (or postural) assessment of
the patient and, based on the functional diagnostic hypotheses formulated in
anamnesis, a district survey of the hypothetically compromised segment or
body segments.
Once the objective functional examination has been completed, the
physiotherapist, if he does not identify any "red flags" that have escaped or
did not emerge in anamnesis, which may require sending (or re-sending) to
the doctor, formulates the physiotherapeutic functional diagnosis which
provides for the identification of the dysfunction of the patient and of the
physical or environmental causes that determine it.
At this point the physiotherapist proposes to the patient the eventual
rehabilitation project, specific and personalized, which aims to establish and
achieve the shared objectives regarding the resolution or reduction of the
disability of the patient, in relation to his physical impairment and / or
possible environmental "obstacles", which may limit their social and / or
work participation. To the folder must be enclosed the forms of informed
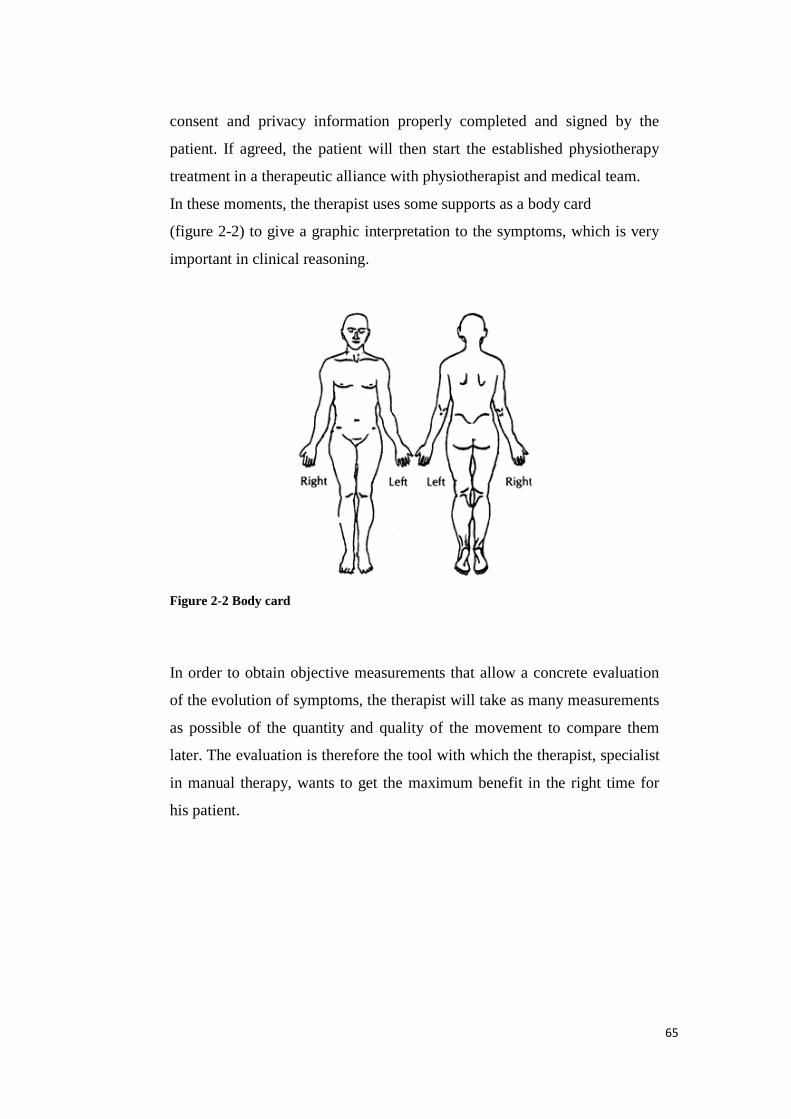
65
consent and privacy information properly completed and signed by the
patient. If agreed, the patient will then start the established physiotherapy
treatment in a therapeutic alliance with physiotherapist and medical team.
In these moments, the therapist uses some supports as a body card
(figure 2-2) to give a graphic interpretation to the symptoms, which is very
important in clinical reasoning.
Figure 2-2 Body card
In order to obtain objective measurements that allow a concrete evaluation
of the evolution of symptoms, the therapist will take as many measurements
as possible of the quantity and quality of the movement to compare them
later. The evaluation is therefore the tool with which the therapist, specialist
in manual therapy, wants to get the maximum benefit in the right time for
his patient.

66
Chapter 3 – DEVELOPMENT
3.1 Anamnesis: why change
The process of anamnesis is certainly of fundamental importance for the
detection and identification of pathologies by the attending physician, but
the methodologies with which it has been carried out until now make it
often incomplete and late in providing accurate and precise answers. In a
world that is always faster, professional figures in the medical field could
find considerable advantages in using tools that, managing the same
informative content, improve response times and multi - usability. The
different types of patients must be managed with anamnesis processes that
require different times and analyzes4. The use of preformatted models has
tried to reduce the time of anamnesis but has made it unattractive for the
doctor, who often considers it an office job and prefers to delegate it to
some of his assistant, trusting his summary report of the answers given, both
of the patient who believes he is under interrogation, not understanding the
real motivations that lead the medical personnel to question him.
Technologies to improve the phase of anamnesis exist and do not always
require the physical presence of a doctor.
3.2 Physio R&D and the idea to create a virtual agent
Physio R&D IVS is a Danish company based in Copenhagen that has
worked in the field of tele-physiotherapy in the last 7 years. The research
carried out aims to make physiotherapy increasingly smart and user-
4 Since the first interviews with Dr. Cerdan he has repeatedly confirmed that for the doctor to reduce the times of the classic anamnesis is a priority

67
friendly, configured with the new technologies in use and aimed at an
audience that in the past knew little about the potential of this branch of
medicine. The company is led by a physiotherapist, Dr. Jose Cerdan who
works at the Department of Respiratory Medicine and Allergy at Arhus
University Hospital and is the CEO of the company, and by Simo Ekholm
Graduated M.Sc. in Medialogy, which has the role of CTO. My personal
goal was to write an experimental thesis that could improve my technical
background in order to create a technology that would be useful to the
company for future use. After some meetings to evaluate objectives and
technologies to be used we decided to try to create, through the advantages
previously exposed by the IBM Watson platform, a virtual agent that
simulates the process of anamnesis making it modern and interactive.
3.3 Objectives
The gaps previously exposed linked to the process of anamnesis could
certainly be solved by using this new virtual agent. The ease of use that will
be visible in the next paragraphs, managed through a simple and intuitive
interface, guides the patient to interact very easily with a doctor who is not
really connected in real time, but is replaced by a virtual agent who poses to
the patient a certain type of questions, receiving different answers. The
interaction can take place either from the keyboard or via voice commands,
using the Software Development Kits (SDK) made available to us. The
doctor prepares a series of technical questions to guide him for future
analysis of the answers, and inserts them into the SaaS platform using
methods that are described in detail in this chapter. The list of responses
provided to this agent are also stored in the IBM platform to be
subsequently consulted by the real doctor who will create an ad hoc
physiotherapeutic path for the different types of clients to whom this 2.0
anamnesis has been submitted. The process therefore becomes fast,
differentiated, modern and allows one of the two protagonists of this

68
interaction to support the test and the other to analyze the answers in the
most appropriate times.
3.4 Development of a Watson application in Node.js
3.4.1 Necessary tools
The use of a SaaS platform we have already seen offer among many
advantages that the user does not need different software and tools available
stored locally on their PC because these are offered by the platform manager
on the associated website. All you need is a web browser (the official IBM
documentation suggests Chrome or Mozilla Firefox) and an internet
connection to perform most of the necessary work. For the development we
suggest the use of an environment including a text / code editor (Eclipse is
the one suggested also because it is well integrated by an official plugin
with IBM Watson). It is also necessary to install the Cloud Foundry
Command Line Interface (cf CLI) to interact with the project especially in
the phase of uploading the files needed for the first start [6] and the
distributed version control software Git usable from the command line
interface [10]. For the development of a Watson application in Node.js it is
necessary to install this Javascript runtime from its web site [21] including
the package manager NPM [22] .
3.4.2 Initial setting
The start of any project or application on the IBM Bluemix platform must
be preceded by the creation of a new user and by the classic procedures for
choosing the access data to the platform by going to the address
https://console.bluemix.net/. Then follows an initial setting of the Cloud
Foundry parameters: we choose an organization name, a region of use (I
chose the United Kingdom) and give the name to a space of use. At this

69
point we choose to create a "Cloud Froundry Application" in the IBM
Bluemix catalog, using the SDK for Node.js, to which we assign a name and
a certain amount of memory (512MB in my case). This application must be
connected to all those services that are necessary for its correct functioning:
in my case the Conversation service, the Speech to Text service and its
complementary Text to Speech. For each of them, a service name, a usage
plan (that widens / limits the use possibilities) must be chosen and a new
credential must be created, that is a triad of URL, username and password
automatically generated by the platform, which identify the Node.js
application among the thousands of applications around the world in the
platform we are using. Binding can be done either from the control panel
attached to our application, or by editing the code contained in the
/manifest.yml file in the list of files that are part of the project. By selecting
the "Connections" option in the side menu of our application, you can make
the connection. It is also necessary to add runtime environment variables
and to do this select the "Runtime" option in the side menu and by clicking
on environment variable, add a pair for each of the connected services
NAME_SERVICE_PASSWORD, NAME_SERVICE_USERNAME. An
exception is the Conversation service to which a third WORKSPACE_ID
parameter must be added containing the id of the Workspace on which our
dialog is to be created. To find this value just go back to the dashboard,
click on the "Conversation" service and after selecting the "Launch tool" we
will be redirected to a new page where our workspaces will appear. If we
have not created one, just click on the "Create" button at the top, choose a
name, a description and the language in which the interaction will take place
(I chose English). Once created we open the relative options menu
connected to the single workspace and selecting "View details" we could
copy the "workspace-id" that we were looking for.

70
3.4.3 Starting project
To create a Watson Node.js app, you need to start from an existing
application that is on the hosting service for GitHub software projects [2].
By going to the official Watson project repository [11] is possible to find
several basic examples to choose from to start a project. The choice must be
made on the basis of the integrated services to be used and based on the
SDK. Towards the end of 2017, IBM added the ability to select an initial
starting kit for developing its application directly from the user dashboard
[34], offering an alternative to cloning GitHub projects or deploying it
locally. In my case I started from the "conversation-simple" project [32]
which integrates only the Conversation service in order to create a chatbot.
3.5 Use of the Conversation service
3.5.1 Dialog scheme
Before moving on to the insertion phase of the nodes, I consulted with Dr.
Cerdan to see how he carries out the anamnesis with his patients and starting
from an existing anamnesis scheme used in the past in his career we have
made the appropriate changes to make it compatible with the project
specifications.
The final scheme that we have adopted is the following:
Part 1 - Personal background
Part 2 - Physical condition
Part 3 - Select a part to train
Part 4 - Body part
Part 5 - Goals and preferences
Part 6 - Goals

71
Part 1 takes the name of "Personal background" and aims to gather
information on the patient undergoing anamnesis. We have chosen to
conduct an anamnesis anonymously, so the patient is only asked about sex,
height and weight, current work and diagnosis related to their physical
situation when they are undergoing the trial.
Part 2 takes the name of "Physical condition" and asks 7 questions to the
user to identify a training program with a degree of difficulty that meets
their needs.
Part 3 is a window of options through which the user / patient can select
which part of their body to train. The choice is between 18 possible parts:
- head
- neck
- left shoulder
- right shoulder
- left elbow
- right elbow
- left hand
- right hand
- upper back
- diaphragm / ribs
- lower back
- entire back
- left hip
- right hip
- left knee
- right knee
- left ankle / foot
- right ankle / foot
Part 4 is specific to each of the 18 parts of the body listed above and in turn
follows the following pattern:

72
4.1) Consider the pain in this body part to be (1 = very painful, 5 = not
painful).
4.2) I consider the discomfort in this body part to be (1 = very
uncomfortable, 5 = no discomfort).
4.3) Consider the range of movement in this body part to be (1 = no freedom
of movement, 5 = free).
4.4) VIDEO
4.5) I assess the pain in this body during the exercise to be (1 = very painful,
5 = not painful).
4.6) I consider the discomfort in this body part during exercise to be (1 =
very uncomfortable, 5 = no discomfort).
4.7) Consider the range of movement in this body part during exercise to be
(1 = no freedom of movement, 5 = free).
For each of the questions it is possible to choose between 1 and 5 the option
that is considered most appropriate. A first novelty concerning the new
process of anamnesis is the introduction of some videos that show the
patient how to perform some exercises according to a specific part of the
body in which they find a certain pain or pathology. In this way the
anamnesis becomes very dynamic, becoming a sort of training. The first 3
questions serve to understand the feeling of pain the patient experiences in
that specific part of the body before undergoing an exercise. After viewing
the video of the exercise to be played, the same questions are repeated. The
pattern is repeated according to the number of videos, which changes from
section to section. The last question posed at the end of the single section
before asking again if the user wants to train another part of the body, is the
one regarding the possible swelling found after completing the exercises
correctly. The answer is of fundamental importance to provide the doctor
with indications on the therapy to be formulated for the patient. There is no
minimum or maximum number of body parts that the user can choose.
Part 5 concerns the "Goals and preferences" and serves to understand if the
training to which the patient was subjected during the anamnesis, is liked

73
and what is the patient's willingness to undergo the therapy. Based on the
availability and time that the user intends to make available to his body the
doctor formulates his therapy, a mix of exercises that combined with a
detailed program will allow the user to solve their physical problems.
Part 6 is the one that closes the whole process and is the one in which the
agent asks to set the objectives of the training and try to understand how
much the user believes are more or less important.
3.5.2 Dialog creation
The schema behind the dialog is a JSON file within which, respecting the
syntax of the language, are inserted all the questions that the virtual agent
must ask the patient after he has answered correctly, i.e. by selecting one of
the different options shown or respecting the parameters that can be set for
the individual question during the creation of the single node of the dialog.
The file is generated automatically within the conversation service
workspace and integrated into the project using the previously mentioned
workspace-id. It is therefore necessary to "translate" in the language of IBM
Watson all the questions previously exposed and insert each one in one of
the different nodes of the tree, creating appropriate links and branches in
order to connect all the parts. To do this, the Conversation service, through
its tools, provides as a first step the creation of a workspace and within it the
creation of the many intents or entities (nodes) to be connected through the
dialog. To each of the entities of the conversation corresponds a
management panel for the creation, deletion and modification. After a study
of the textual content of the previous anamnesis used by Dr. Cerdan I
decided not to use the entities (much more useful at the technical level when
the agent has to perform more dynamic actions) but only the intents, 65 in
all. Each question or node, can contain one or more intents, must have a

74
name beginning with "#", an optional description and some examples that
allow the other intents to the dialog to refer to it.
The construction of the dialog is very simple and intuitive thanks to the
tools made available to the IBM Bluemix platform. Each node of the dialog
contains at least one condition and one answer: if a certain condition has
been verified, a certain answer must be satisfied, all based on the well-
known if-then or if-then-else construct. For example, the node containing
the sentence "I assess the pain in this body part during the exercise to be (1
= very painful, 5 = not painful)" is structured:
Figure 3-1 Node example
Depending on the answer given by the user, if the answer is one of the
answers provided, the system responds with another question, with an
affirmation or with reference to the next node (Jump), if the answer is not
provided, the system provides redrafting of the application.
The nodes are connected to each other by means of Jump, which can be
operated on the basis of different actions by the user (in our case as soon as
the user answers). The "translation" of the old anamnesis scheme into the
new one based on the IBM Watson Conversation service required 1239
nodes, 65 intents and about 500 jumps. Each node contains a JSON text

75
editor that we used to work on text formatting, graphic appearance and
syntax (paragraph 3.7.1).
3.5.3 API integration
To be able to integrate the Conversation service in my Watson application
developed in Node.js, it was necessary to modify the /app.js file located in
the saved local folder of the conversation-simple project from which I
started. Opening it with a simple text editor I added the relevant API as in
[A.1].
It is not necessary to enter the specific credentials of the Conversation
service, as the application will look at the environment variables that we
have previously set with the respective USERNAME and PASSWORD.
The script must also be added to the /public/index.html file
<script src="js/conversation.js"></script>
for the Conversation service.
3.6 Use of the Speech to Text service
The Speech to Text service is used for the transcription of the patient / user
voice in characters that can be easily interpreted by the virtual agent. Recall
that the voice interaction is optional and that the user can easily choose to
use mouse and keyboard to interact with the application [25]. Voice
commands, however, have the considerable advantage of making
communication much easier and more immediate, opening up to a possible
use of the app even to people suffering from physical deficits. It must be
said that the service is clearly improving. To date there are several bugs that
make the transcription often wrong and highly influenced by the noisy
context in which we are at the time of interaction, but we are sure that the
increasingly widespread use of services related to IBM Watson will lead to
improvements already in the next years.

76
3.6.1 API integration
The integration of the API for the Speech to Text service is done by editing
the /app.js file in the local folder of the conversation-simple project from
which I started to develop the Node.js app, adding the lines of code reported
in [A. 2].
In the /public/ibm/directory, you must add the speech-to-text.js file and the
watson-speech.min.js file for the Speech to Text module. The script must
also be added to the /public/index.html file
<script src="ibm/watson-speech.min.js"></script>
<script src="ibm/speech-to-text.js"></script>
for the Speech to Text service.
3.7 Use of the Text to Speech service
The Text to Speech service performs a complementary task to the previous
Speech to Text, as it deals with transforming text into speech. In my app is
the voice of the virtual agent, reading all the questions that the agent poses
and pronouncing all his statements. Unlike its complementary it is much
more editable, since Watson provides the personalization of voices (male,
female), syntax, pronunciations and dialects through simple parameters to
be included in the JSON editor present in each node of the dialog.
3.7.1 SSML
SSML (Speech Synthesis Markup Language) is an XML-based markup
language, adopted as a standard markup language for speech synthesis using
the VoiceXML 2.0 specification [18]. It provides developers with a standard
way to control aspects of the synthesis process by allowing them to specify
pronunciations, intonations, pauses, speeds and other attributes via markup

77
tags. An XML parser first separates simple input text from the markup
specifications. These specifications are then processed and sent as a series
of instructions in a form that can be understood by the synthesizer to
produce the desired effects [28]. In my project I used the break attribute to
put a pause between one option and another in all those questions in which
the agent proposes a multiple choice to the user. The following example
taken from the project, provides a break of 6 minutes before the virtual
agent pronounces the 5 different options (numbers from 1 to 5) with a
"medium" speed:
<p>I assess the pain in this body part during the exercise to be (1 = very
painful, 5 = not painful).</p>
<p>
<speak version="1.0"><break time="600s"></break>
<button id="button-no" onclick="n1();">1</button><break strength="medium">
</break>
<button id="button-no" onclick="n2();">2</button><break strength="medium">
</break>
<button id="button-no" onclick="n3();">3</button><break strength="medium">
</break>
<button id="button-no" onclick="n4();">4</button><break strength="medium">
</break>
<button id="button-no" onclick="n5();">5</button><break strength="medium">
</break>
</speak></p>
3.7.2 API integration
As in the two previous cases, the integration of the APIs for the Text to
Speech service is done by editing the /app.js file contained in the local
folder of the conversation-simple project adding the lines of code shown in
[A.3].
In the /public/ibm/directory, the text-to-speech.js file for the Text to Speech
module must be added. The script must also be added to the
/public/index.html file
<script src="ibm/text-to-speech.js"></script>
for the Text to Speech service.

78
3.8 Graphic editing and GUI
The GUI offered by IBM Bluemix is certainly simple, intuitive and
customizable on the code side depending on the needs of the developer and
the aims of the project. Below are the parts that have undergone my
modification with the relative codes mapped in the appendix.
3.8.1 Options buttons
My virtual agent often poses questions with multi-options, so the creation of
some equally spaced buttons to show to the user, has been one of the first
necessities right away. In order to do this I made some changes on the
HTML and CSS side of the two files that in the conversation-simple startup
project take care of and manage this side of the application, namely the file
/public/index.html and the file /public/css/app.css. Each button in the
/index.html file corresponds to a script containing a function with a specific
name:
function diabetes() {
var latestResponse = Api.getResponsePayload();
var context = latestResponse.context;
Api.sendRequest("diabetes", context);
}
function osteoarthritis() {
var latestResponse = Api.getResponsePayload();
var context = latestResponse.context;
Api.sendRequest("osteoarthritis", context);
}
function heartdisease() {
var latestResponse = Api.getResponsePayload();
var context = latestResponse.context;
Api.sendRequest("Heart disease", context);
}
Each time the user selects an option among those proposed in the multi
choice of the conversation, a different intent is selected, which in turn calls
one of these functions present in the HTML file. The name of the function is

79
the same as the intent and the message contained in the double quotes is
shown. The code shown in [A.4] must be inserted on the CSS side.
3.8.2 Microphone and audio buttons
The user can choose whether he wants to interact or not with the application
using voice commands. Thus, buttons are provided which, interacting with
the functions specified in the SDKs contained in the /public/ibm folder,
enable these features to be activated [24]. Specifically we add the HTML
code shown in [A.5] and CSS side, in the /app.css file, the code shown in
[A.6].
3.8.3 Lateral menu
The right-hand side menu of the original project was helpful in analyzing
what happened back-end side to every interaction with the individual
components of the project, but once I reached the final stage I decided to
replace this part with a menu containing title and information on the author,
speakers, my home university and project sponsor. Also in this case the
change has concerned the HTML side the file /public/index.html [A.7] and
the CSS side the file /app.css [A.8] .
3.9 Deploy and final result
Once the previously mentioned parts of some files in use are edited, the
project is ready for the final deployment. Among the 3 different options
proposed in 1.5.2.3 the one that after several field trials gave me the best
results is certainly the uploading of files via command line, which are
integrated GIT services and Cloud Foundry Command Line Interface (cf

80
CLI). Once the Windows command prompt has been opened, follow the
steps below:
1. Type the command cf api followed by the address of the public API
depending on the region (in my case with the UK region cf api
https://api.eu-gb.bluemix.net).
2. Choose organization and space previously created.
3. Type the cf login command to log in to the IBM platform via email and
password.
4. Type the command cd NAME_FOLDER to move to the folder
containing the entire project.
5. Type the cf push command to upload the folder to the available Bluemix
space.
Following these steps you can go to the IBM dashboard and launch the
application from the link provided by IBM under the heading "Applications
Cloud Foundry". The final result of my project is visible at the following
address: https://anamnesis.eu-gb.mybluemix.net/.
3.10 Statistical report
At the end of the development phase, in agreement with Dr. Jose Cerdan,
we applied the application to 10 people to receive feedbacks, understand
what they liked and where the agent can be improved. Analyzing the
statistics, the data are encouraging: 100% of users liked to interact with the
virtual agent and all have followed the video exercises before answering the
questions asked. 80% of them believe that using voice commands can help
interact. As for the favorite devices where to perform the anamnesis these
are the results:

81
Figure 3-2 Which device would you preffer to use to answer such interview?
We have finally asked what are the pros and cons found in the use of the
virtual agent. Among the pros there are 7 users that emphasize the
significant time savings, ease of use, the fact of being able to get a diagnosis
anywhere and at any time of day. Among the cons, there are 3 users who do
not trust 100% of the correctness of anamnesis and those who would prefer
to have a real doctor anyway. We asked what could prevent the interview
from proceeding smoothly, and despite 6 users answered "nothing", 4 others
pointed out that the process is repetitive and can lead the user to get bored or
forget the answers given above. Consequently, some suggest the reduction
of the number of questions, the addition in the future of a real face for the
agent or the possibility of being able to choose which part of the body to
train directly from an image representing the various possibilities of choice.

82
3.11 Android project
Nowadays the devices preferred by users are definitely smartphones and the
reasons for this choice are many. So I decided to create a mobile version of
my Node.js project so as to capture these advantages and make the
anamnesis even smarter. To do this I left once again from an existing project
in the library GitHub Watson titled "WatBot" [19], designed for Android
devices and aimed at creating an Android chatbot based on IBM Watson
that exploits services such as Conversation, Speech to Text and Text to
Speech, in order to simulate in our case an anamnesis process. Starting from
the original project download, using the official Android Studio IDE, I have
exported the services in use in the Node.js application into an Android app,
which in the future can be included in the Google Play Store and distributed
in world scale. It was necessary only to insert the username and password of
the 3 used IBM Watson services inside the MainActivity class, within the
sendMessage() method, as well as the workspace-id containing nodes and
dialog. Once the application has been debugged through one of the AVD
(Android Virtual Device) provided by the IDE, I have been able to develop
some tricks and improvements. In addition, editing the graphic appearance
with the change of the background colors and the splash screen I gave
uniformity to the project, trying to make it in all respects similar to the
application developed previously and navigable only for PC and tablet. Here
are some screenshoots.

83
Figure 3-3 Android App Screenshoot

84
Conclusion
This thesis offers a theoretical and technical description useful for the
realization of a virtual agent able to perform an anamnesis using a cognitive
system that can create many advantages both for the doctor and for the
patient.
Through its 3 chapters I have tried to describe the history, advantages and
characteristics of cognitive systems and in particular of IBM Watson. In
chapter 2, I gave a medical-technical definition of anamnesis and the
methods with which it has been carried out until now, trying to understand
how artificial intelligence and cognitive systems can make it more useful
and interactive. In the final chapter I described the characteristics of the
development project carried out using the IBM technology in order to create
a virtual agent capable of simulating an anamnesis process that could
support the treating physician for the identification of possible diseases or
physiotherapeutic pathologies, through a Question Answering systems (QA)
and video-exercises.
My personal goal has been reached. The hope is that tomorrow I can gather
the fruits of my work by making available to doctors and hospitals this new
anamnesis, which wants to be supportive and not a substitute for the doctor
himself.
It is therefore up to man to use AI in a virtuous way, from both a scientific
and a moral point of view, without ever forgetting the ethical dimension of
the relationship with the patient.

85
Appendix
Code A.1 API Conversation service
var express = require('express'); // app server
var bodyParser = require('body-parser'); // parser for post requests
var Conversation = require('watson-developer-cloud/conversation/v1');
// watson sdk
var request = require('request'); // request module
var watson = require('watson-developer-cloud');
var app = express();
// Create the service wrapper
var conversation = new Conversation({
url: 'https://gateway.watsonplatform.net/conversation/api',
version_date: '2016-10-21',
version: 'v1'
});
// Endpoint to be call from the client side
app.post('/api/message', function(req, res) {
var workspace = process.env.WORKSPACE_ID || '<workspace-id>';
if (!workspace || workspace === '<workspace-id>') {
return res.json({
'output': {
'text': 'The app has not been configured with a <b>WORKSPACE_ID</b>
environment variable.
}
});
}
var payload = {
workspace_id: workspace,
context: req.body.context || {},
input: req.body.input || {}
};
// Send the input to the conversation service
conversation.message(payload, function(err, data) {
if (err) {
return res.status(err.code || 500).json(err);
}
updateMessage(payload, data, function(response){
return res.json(response);
});
});
});

86
Code A.2 API Speech to Text service
var sttEndpoint = vcap.speech_to_text[0].credentials.url;
var stt_credentials = Object.assign({
username: process.env.SPEECH_TO_TEXT_USERNAME || '<username>',
password: process.env.SPEECH_TO_TEXT_PASSWORD || '<password>',
url: process.env.SPEECH_TO_TEXT_URL ||
'https://stream.watsonplatform.net/speech-to-text/api',
version: 'v1',},vcap.speech_to_text[0].credentials);
app.get('/api/speech-to-text/token', function(req, res, next){
watson.authorization(stt_credentials).getToken({ url:
stt_credentials.url }, function(error, token){
if (error) {
if (error.code !== 401)
return next(error);
} else {
res.send(token);
}
});
});
Code A.3 API Text to Speech service
var ttsEndpoint = vcap.text_to_speech[0].credentials.url;
var tts_credentials = Object.assign({
username: process.env.TEXT_TO_SPEECH_USERNAME || '<username>',
password: process.env.TEXT_TO_SPEECH_PASSWORD || '<password>',
url: process.env.TEXT_TO_SPEECH_URL ||
'https://stream.watsonplatform.net/text-to-speech/api',
version: 'v1',
},vcap.text_to_speech[0].credentials);
app.get('/api/text-to-speech/token', function(req, res, next){
watson.authorization(tts_credentials).getToken({ url:
tts_credentials.url }, function(error, token){
if (error) {
if (error.code !== 401)
return next(error);
} else {
res.send(token);
}
});
});

87
Code A.4 CSS buttons
#button-no {
-webkit-border-radius: 28;
-moz-border-radius: 28;
border-radius: 28px;
font-family: Arial;
color: #07b7a2;
font-size: 16px;
background: #ffffff;
padding: 10px 10px 10px 10px;
border: solid #07b7a2 2px;
text-decoration: none;
}
Code A.5 HTML microphone and audio buttons
<div id="output-audio" class="audio-on" onclick="TTSModule.toggle()"
value="ON"></div>
<div class="chat-column">
<div id="scrollingChat"></div>
<div id="input-wrapper" class="responsive-columns-wrapper">
<div id="input-mic-holder">
<div id="input-mic" class="inactive-mic"
onclick="STTModule.micON()">
</div>
</div>
<label for="textInput" class="inputOutline">
<input id="textInput" class="input responsive-column"
placeholder="Type something" type="text"
onkeydown="ConversationPanel.inputKeyDown(event, this)">
</label>
</div>
</div>
</div>

88
Code A.6 CSS microphone and audio buttons
#input-wrapper {
padding: 1.25rem;
background: white;
position: relative;
}
#input-mic-holder {
height: 3rem;
width: 3rem;
position: relative;
}
#input-mic {
display: inline-block;
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
height: 2.5rem;
width: 2.5rem;
border-radius: 1.5rem;
transition: 0.4s;
cursor: pointer;
background-color: #BCC8C8;
background-repeat: no-repeat;
background-position: 50% 50%;
background-size: 55%;
}
#input-mic.inactive-mic {
background-image: url("../img/mic-off.svg");
}
#input-mic.active-mic, #input-mic:active {
background-image: url("../img/mic-on.svg");
background-color: #32D0B6;
border: 0.25rem solid #01745E;
}
#output-audio.audio-on {
background-image: url("../img/audio-on.svg");
}
#output-audio.audio-off {
background-image: url("../img/audio-off.svg");
}
#output-audio {
position: absolute;
z-index: 10;
left: 2rem;
top: 1rem;
height: 3.5rem;
width: 3.5rem;
border-radius: 1.75rem;
cursor: pointer;
background-repeat: no-repeat;
background-position: 50% 50%;
background-size: 100%;
}

89
Code A.7 HTML lateral menu
<div class="">
<div id="contentParent" class="responsive-columns-wrapper">
<div id="chat-column-holder" class="responsive-column content-column">
<div class="fixed-column content-column">
<div class='chat-column'>
<div class='payload-initial-message'>
<h1>Master thesis Paolo David</h1>
<h3><strong>Title:</strong> Development of a virtual agent capable of
performing an amnesis using IBM Watson platform<br /><br /><strong>Supervisor:
</strong> Simo Ekholm and Jose Cerdan<br /><strong>University Professor:
</strong> Marco La Cascia</h3><h3><strong>Partner:</strong> Physio R&D,
Copenhagen (Denmark)<br /><br /><br /></h3>
<a href="https://ibb.co/dskxPR"><img
src="https://preview.ibb.co/j27BjR/Logo_Unipa_1111.jpg" alt="Logo_Unipa_1111"
border="0" width="154" height="68" /></a> <a
href="https://imgbb.com/" style="color: #23527c; text-decoration-line:
underline; outline: 0px;"><img
src="https://image.ibb.co/jzD1jR/Physio_RD_logo.jpg" alt="Physio_RD_logo"
border="0" width="102" height="69" /></a><a href="https://ibb.co/kxeJW6"><img
src="https://preview.ibb.co/cU7SPR/Optimov_Logo.png" alt="Optimov_Logo"
border="0" width="152" height="93" /></a>
</div>
</div>
<div id="payload-initial-message" class="hide"></div>
<div id="payload-initial-message" class="hide"></div>
<div id="payload-request" class="hide"></div>
<div id="payload-response" class="hide"></div>
</div>
</div>
</div>
</div>

90
Code A.8 CSS lateral menu
.fixed-column {
font-family: Monaco, monospace;
font-size: 0.75rem;
letter-spacing: 0;
line-height: 1.125rem;
background-color: #855ca7;
color: #fff;
overflow-x: auto;
margin-top: 0;
width: 45%;
max-width: 28rem;
min-width: 27rem; }
.fixed-column.full {
width: 100%;
max-width: none;
min-width: initial; }
.fixed-column .header-text, .fixed-column .payload-initial-message {
font-family: Helvetica Neue for IBM, Helvetica Neue, Helvetica, Arial, sans-
serif;
font-size: 0.8rem;
letter-spacing: 0.01875rem;
padding-left: 3rem;
padding-right: 3rem;
padding-top: 3rem;
margin-top: 0; }

91
References
[1] A. Azraq, H. Aziz, N. Nappe, C. R. Bravo, L. Sri, Building Cognitive Applications with
IBM Watson Services: Volume 2 Conversation, 1-3, 5-8, IBM Redbooks, 2017.
[2] A. Azraq, M. Ewies, A. E. Marzouk, Developing Node.js Applications on IBM
Bluemix, 1-4, IBM Redbooks, 2017.
[3] A. Azraq, H. A Aziz, M. El-Khouly, S. Fikry, A. S Hassan, M. Rasmy, B. Smith,
Essentials of Cloud Application Development on IBM Bluemix, 1-7, IBM Redbooks, 2017.
[4] G. Banavar. 2015. Watson and the Era of Cognitive Computing. SIGARCH Comput.
Archit. News 43, 1 (March 2015), 413-413. DOI:
https://doi.org/10.1145/2786763.2694376.
[5] E. W. Brown. 2012. Watson: the Jeopardy! challenge and beyond. In Proceedings of the
35th international ACM SIGIR conference on Research and development in information
retrieval (SIGIR '12). ACM, New York, NY, USA, 1020-1020. DOI:
https://doi.org/10.1145/2348283.2348446.
[6] Cloud Foundry Command Line Interface, CloudFroundry,
https://docs.cloudfoundry.org/cf-cli/install-go-cli.html, 2017.
[7] B. Costa, Paulo F. Pires, Flávia C. Delicato, and Flávio Oquendo. 2015. Towards a
View-Based Process for Designing and Documenting RESTful Service Architectures.
In Proceedings of the 2015 European Conference on Software Architecture
Workshops (ECSAW '15). ACM, New York, NY, USA, , Article 50 , 7 pages.
DOI=http://dx.doi.org/10.1145/2797433.2797485.
[8] A. De Vettor, Il biglietto da visita del personal trainer: la scheda di anamnesis,
http://www.my-personaltrainer.it/allenamento/scheda-anamnesis.html, 2017.
[9] D. Ferrucci. 2010. Build Watson: an overview of DeepQA for the Jeopardy! challenge.
In Proceedings of the 19th international conference on Parallel architectures and

92
compilation techniques (PACT '10). ACM, New York, NY, USA, 1-2.
DOI=http://dx.doi.org/10.1145/1854273.1854275.
[10] Git, https://gitforwindows.org/, 2017.
[11] GitHub Watson repository, https://github.com/watson-developer-cloud, 2017.
[12] A. Gliozzo, C. Ackerson, R. Bhattacharya, A. Goering, A. Jumba, S. Y. Kim, L.
Krishnamurthy, T. Lam, A. Littera, I. McIntosh, S. Murthy, M. Ribas, Building Cognitive
Applications with IBM Watson Services: Volume 1 Getting Started, 1-5, IBM Redbooks,
2017.
[13] IBM, IBM Official Conversation service Documentation,
https://console.bluemix.net/docs/services/conversation/index.html, 2017.
[14] IBM, IBM Official Speech to Text service Documentation,
https://console.bluemix.net/docs/services/speech-to-text/getting-started.html, 2017.
[15] IBM, IBM Official Text to Speech service Documentation,
https://console.bluemix.net/docs/services/text-to-speech/getting-started.html, 2017.
[16] J. Kalyanam and Gert R.G. Lanckriet. 2014. Learning from unstructured multimedia
data. In Proceedings of the 23rd International Conference on World Wide Web (WWW '14
Companion). ACM, New York, NY, USA, 309-310. DOI:
http://dx.doi.org/10.1145/2567948.2577318.
[17] K. Kobylinski. 2015. Agile software development for Bluemix with IBM DevOps
services. In Proceedings of the 25th Annual International Conference on Computer Science
and Software Engineering (CASCON '15), Jordan Gould, Marin Litoiu, and Hanan
Lutfiyya (Eds.). IBM Corp., Riverton, NJ, USA, 284-286.
[18] C. Kolias, Vassilis Kolias, Ioannis Anagnostopoulos, Georgios Kambourakis, and
Eleftherios Kayafas. 2008. A pervasive wiki application based on VoiceXML.
In Proceedings of the 1st international conference on PErvasive Technologies Related to
Assistive Environments (PETRA '08), Fillia Makedon, Lynne Baillie, Grammati Pantziou,
and Ilias Maglogiannis (Eds.). ACM, New York, NY, USA, Article 58, 7 pages. DOI:
https://doi.org/10.1145/1389586.1389656.

93
[19] V. Machupalli, Watbot: an Android ChatBot powered by IBM Watson Services
(Conversation, Text-to-Speech, and Speech-to-Text with Speaker Recognition) on IBM
Cloud, https://github.com/VidyasagarMSC/WatBot, 2017.
[20] R. Manfredini, Modulo di medicina interna,
http://www.unife.it/medicina/lm.medicina/studiare/minisiti/metodologia-clinica-ii/modulo-
di-medicina-interna/2016-17/anamnesis-08_03.pdf, 2016.
[21] Node.js runtime, Node.js, https://nodejs.org/en/#download, 2017.
[22] NPM, https://www.npmjs.com/, 2017.
[23] S. Packowski and Arun Lakhana. 2017. Using IBM watson cloud services to build
natural language processing solutions to leverage chat tools. In Proceedings of the 27th
Annual International Conference on Computer Science and Software
Engineering (CASCON '17). IBM Corp., Riverton, NJ, USA, 211-218.
[24] Redbooks project, redbooks-conv-201-stt-tts-nodejs, https://github.com/snippet-
java/redbooks-conv-201-stt-tts-nodejs, 2017.
[25] F. Santiago, P. Singh, L. Sri, Building Cognitive Applications with IBM Watson
Services: Volume 6 Speech to Text and Text to Speech, 1-2, 4, IBM Redbooks, 2017.
[26] C. W. Smullen, IV, Shahrukh Rohinton Tarapore, Sudhanva Gurumurthi,
Parthasarathy Ranganathan, and Mustafa Uysal. 2008. Active storage revisited: the case for
power and performance benefits for unstructured data processing applications.
In Proceedings of the 5th conference on Computing frontiers (CF '08). ACM, New York,
NY, USA, 293-304. DOI=http://dx.doi.org/10.1145/1366230.1366280.
[27] M. Soni. 2014. Cloud computing basics platform as a service (PaaS). Linux J. 2014,
238.
[28] SSML, https://console.bluemix.net/docs/services/text-to-speech/SSML.html#ssml,
2017.
[29] S. Sudarsan. 2014. Evolving to a new computing ERA: cognitive computing with
Watson. J. Comput. Sci. Coll. 29, 4 (April 2014), 4-4.

94
[30] M. Yan, Paul Castro, Perry Cheng, and Vatche Ishakian. 2016. Building a Chatbot
with Serverless Computing. In Proceedings of the 1st International Workshop on Mashups
of Things and APIs (MOTA '16). ACM, New York, NY, USA, Article 5, 4 pages. DOI:
https://doi.org/10.1145/3007203.3007217.
[31] Watson Developer Cloud, car-dashboard project, https://github.com/watson-developer-
cloud/car-dashboard, 2017.
[32] Watson Developer Cloud, conversation-simple project, https://github.com/watson-
developer-cloud/conversation-simple/, 2017.
[33] Watson Developer Cloud, conversation-with-discovery project,
https://github.com/watson-developer-cloud/conversation-with-discovery, 2017.
[34] Watson user dashboard, https://console.bluemix.net/developer/watson/dashboard,
2017.

95
Ringraziamenti
Vorrei utilizzare questo paragrafo per ringraziare quelle persone che mi
sono state d’aiuto per la realizzazione della mia tesi di Laurea.
Comincio col ringraziare il mio relatore universitario, il Prof. Marco La
Cascia, che sempre è stato professionale nei miei confronti dandomi tutto il
supporto didattico necessario per portare avanti questa esperienza danese e
questo progetto.
Grazie a Simo Ekholm, mio relatore aziendale, che con la sua esperienza ed
il suo modo di fare ha reso semplice un percorso ed un progetto molto
ambizioso che spero in futuro possa essere d’aiuto a tutte le figure tecniche
e specialistiche che lavorano nel campo del MedTech ed healthcare.
Grazie a tutto il team di Physio R&D, in maniera particolare al Dott. Jose
Cerdan per il tempo messo a mia disposizione per la scelta del progetto, le
consulenze mediche sul mondo dell’anamnesis ed i meeting necessari per
mettere a punto le specifiche dell’agente virtuale, a Hristina Georgieva per
la revisione dei testi e delle traduzioni, a Beatris Ilieva per il supporto
grafico per la versione Android del progetto.
Un grazie particolare va alla mia famiglia che sempre mi è stata accanto e
mi ha supportato, ed in particolare vorrei ringraziare i miei zii Mariangela
ed Antonio senza cui non avrei potuto vivere questa esperienza estera a
Copenaghen.
Il grazie finale, last but not least, va a mia madre Rosaria, a mio padre
Antonio ed a mio fratello Giovanni a cui ho voluto dedicare l’intero lavoro.