computer architecture: a constructive approach branch prediction - 1 arvind computer science &...
TRANSCRIPT

Computer Architecture: A Constructive Approach
Branch Prediction - 1
ArvindComputer Science & Artificial Intelligence Lab.Massachusetts Institute of Technology
April 9, 2012 L16-1http://csg.csail.mit.edu/6.S078

http://csg.csail.mit.edu/6.S078
I-cache
Fetch Buffer
IssueBuffer
Func.Units
Arch.State
Execute
Decode
ResultBuffer Commit
PC
Fetch
Branchexecuted
Next fetch started
Modern processors may have > 10 pipeline stages between next PC calculation and branch resolution !
Control Flow Penalty
How much work is lost if pipeline doesn’t follow correct instruction flow?
~ Loop length x pipeline width
April 9, 2012 L12-2

Average Run-Length between BranchesAverage dynamic instruction mix from SPEC92:
SPECint92 SPECfp92ALU 39 % 13 % FPU Add 20 %FPU Mult 13 %load 26 % 23 %store 9 % 9 %branch 16 % 8 %other 10 % 12 %
SPECint92: compress, eqntott, espresso, gcc , liSPECfp92: doduc, ear, hydro2d, mdijdp2, su2cor
What is the average run-length between branches? April 9, 2012 L16-3http://csg.csail.mit.edu/6.S078

Instruction Taken known?Target known?
J
JR
BEQZ/BNEZ
MIPS Branches and JumpsEach instruction fetch depends on one or two pieces of information from the preceding instruction:
1. Is the preceding instruction a taken branch?
2. If so, what is the target address?
After Inst. Decode
After Inst. Decode After Inst. Decode
After Inst. Decode After Reg. Fetch
After Exec
April 9, 2012 L16-4http://csg.csail.mit.edu/6.S078

Currently our simple pipelined architecture does very simple branch prediction
What is it?
Branch is predicted not taken: pc, pc+4, pc+8, …
Can we do better?
April 9, 2012 L16-5http://csg.csail.mit.edu/6.S078

Branch Prediction Bits• Assume 2 BP bits per instruction• Use saturating counter
On ¬taken
On taken
1 1 Strongly taken
1 0 Weakly taken
0 1 Weakly ¬taken
0 0 Strongly ¬taken
April 9, 2012 L16-6http://csg.csail.mit.edu/6.S078

Branch History Table (BHT)
4K-entry BHT, 2 bits/entry, ~80-90% correct predictions
0 0Fetch PC
Branch? Target PC
+
I-Cache
Opcode offset
Instruction
k
BHT Index
2k-entryBHT,2 bits/entry
Taken/¬Taken?
April 9, 2012 L16-7http://csg.csail.mit.edu/6.S078

Where does BHT fit in the processor pipeline?
BHT can only be used after instruction decode
What should we do at the fetch stage?
Need a mechanism to update the BHT where does the update information come from
April 9, 2012 L16-8http://csg.csail.mit.edu/6.S078

Overview of branch prediction
PC
Need next PC immediately
DecodeRegRead
Execute
Instr type, PC relative
targets available
Simple conditions,
register targets available
Complex conditions available
Next AddrPred
BP,JMP,Ret
Loose loop Loose loop Loose loopTight loop
Best predictors reflect program
behavior
April 9, 2012 L16-9http://csg.csail.mit.edu/6.S078

Next Address Predictor (NAP)first attempt
BP bits are stored with the predicted target address. IF stage: nPC = If (BP=taken) then target else pc+4 later: check prediction, if wrong then kill the instruction and update BTB & BPb else update BPb
iMem
PC
Branch Target Buffer (2k entries)
k
BPbpredicted
target BP
target
April 9, 2012 L16-10http://csg.csail.mit.edu/6.S078

Address Collisions
What will be fetched after the instruction at 1028?NAP prediction = Correct target =
Assume a 128-entry NAP BPbtarget
take236
1028 Add .....
132 Jump 100
InstructionMemory
2361032
kill PC=236 and fetch PC=1032
Is this a common occurrence?Can we avoid these bubbles?
April 9, 2012 L16-11http://csg.csail.mit.edu/6.S078

Use NAP for Control Instructions onlyNAP contains useful information for branch and jump instructions only
Do not update it for other instructions
For all other instructions the next PC is (PC)+4 !
How to achieve this effect without decoding the instruction?
April 9, 2012 L16-12http://csg.csail.mit.edu/6.S078

Branch Target Buffer (BTB)a special form of NAP
• Keep the (pc, predicted pc) in the BTB • pc+4 is predicted if no pc match is found• BTB is updated only for branches and jumps
2k-entry direct-mapped BTBI-Cache PC
k
Valid
valid
Entry PC
=
match
predicted
target
target PC
Permits nextPC to be determined before instruction is decodedApril 9, 2012 L16-13http://csg.csail.mit.edu/6.S078

Consulting BTB Before Decoding
1028 Add .....
132 Jump 100
BPbtarget
take236
entry PC
132
• The match for pc =1028 fails and 1028+4 is fetched eliminates false predictions after ALU
instructions
• BTB contains entries only for control transfer instructions
more room to store branch targetsEven very small BTBs are very effective
April 9, 2012 L16-14http://csg.csail.mit.edu/6.S078

ObservationsThere is a plethora of branch prediction schemes – their importance grows with the depth of processor pipelineProcessors often use more than one prediction schemeIt is usually easy to understand the data structures required to implement a particular schemeIt takes considerably more effort to understand how a particular scheme with its lookup and updates is integrated in the pipeline and how various schemes interact with each other
April 9, 2012 L16-15http://csg.csail.mit.edu/6.S078

PlanWe will begin with a very simple 2-stage pipeline and integrate a simple BTB scheme in it
We will extend the design to a multistage pipeline and integrate at least one more predictor, say BHT, in the pipeline (next lecture)
revisit the simple two-stage pipeline without branch prediction
April 9, 2012 L16-16http://csg.csail.mit.edu/6.S078

Decoupled Fetch and Execute
Fetch Execute
<instructions, pc, epoch>
<updated pc>
ir
nextPC
Fetch sends instructions to Execute along with pc and other control informationExecute sends information about the target pc to Fetch, which updates pc and other control registers whenever it looks at the nextPC fifo
April 9, 2012 L16-17http://csg.csail.mit.edu/6.S078

A solution using epochAdd fEpoch and eEpoch registers to the processor state; initialize them to the same value The epoch changes whenever Execute determines that the pc prediction is wrong. This change is reflected immediately in eEpoch and eventually in fEpoch via nextPC FIFOAssociate the fEpoch with every instruction when it is fetched In the execute stage, reject, i.e., kill, the instruction if its epoch does not match eEpoch
April 9, 2012 L16-18http://csg.csail.mit.edu/6.S078
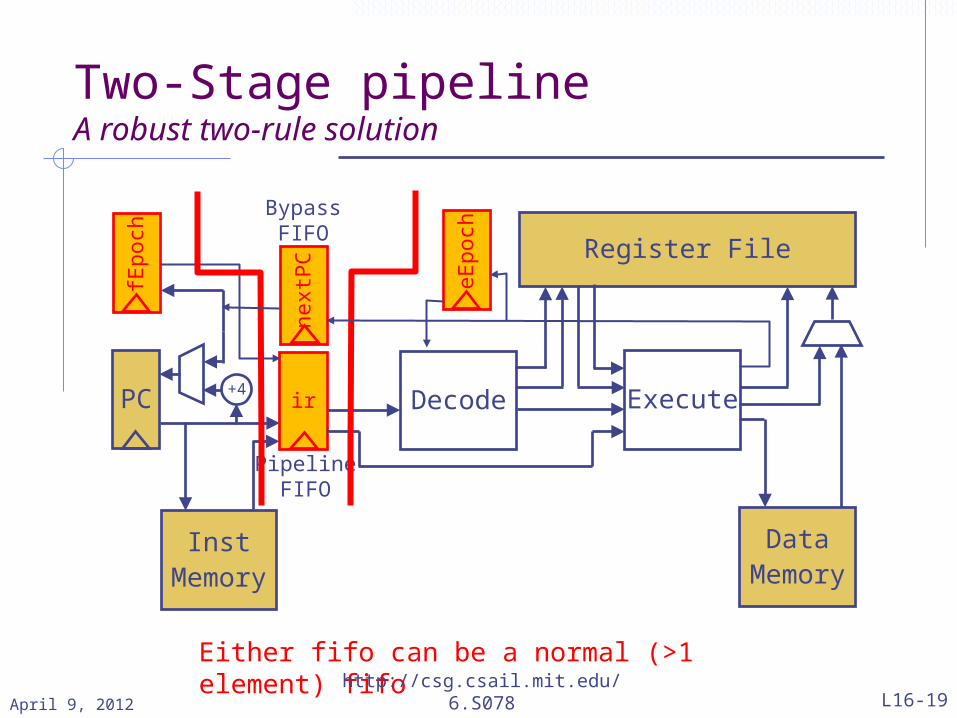
Two-Stage pipelineA robust two-rule solution
PC
InstMemory
Decode
Register File
Execute
DataMemory
+4ir
BypassFIFO
PipelineFIFO
nextP
C
fEpoch
eEpoch
Either fifo can be a normal (>1 element) fifo
April 9, 2012 L16-19http://csg.csail.mit.edu/6.S078

Two-stage pipeline Decoupledmodule mkProc(Proc); Reg#(Addr) pc <- mkRegU; RFile rf <- mkRFile; IMemory iMem <- mkIMemory; DMemory dMem <- mkDMemory; PipeReg#(TypeFetch2Decode) ir <- mkPipeReg; Reg#(Bool) fEpoch <- mkReg(False); Reg#(Bool) eEpoch <- mkReg(False); FIFOF#(Addr) nextPC <- mkBypassFIFOF; rule doFetch (ir.notFull); let inst = iMem(pc); ir.enq(TypeFetch2Decode {pc:pc, epoch:fEpoch, inst:inst}); if(nextPC.notEmpty) begin pc<=nextPC.first; fEpoch<=!fEpoch; nextPC.deq;end else pc <= pc + 4; endrule
explicit guard
simple branch prediction
April 9, 2012 L16-20http://csg.csail.mit.edu/6.S078

Two-stage pipeline Decoupled cont
rule doExecute (ir.notEmpty); let irpc = ir.first.pc; let inst = ir.first.inst; if(ir.first.epoch==eEpoch) begin let eInst = decodeExecute(irpc, inst, rf); let memData <- dMemAction(eInst, dMem); regUpdate(eInst, memData, rf); if (eInst.brTaken) begin nextPC.enq(eInst.addr); eEpoch <= !eEpoch; end end ir.deq;endruleendmodule
April 9, 2012 L16-21http://csg.csail.mit.edu/6.S078

Two-Stage pipeline with a Branch Predictor
PC
InstMemory
Decode
Register File
Execute
DataMemory
ir+
ppc
nextP
C
fEpoch
eEpoch
BranchPredictor
April 9, 2012 L16-22http://csg.csail.mit.edu/6.S078

Branch Predictor Interface
interface NextAddressPredictor; method Addr prediction(Addr pc); method Action update(Addr pc, Addr target);
endinterface
April 9, 2012 L16-23http://csg.csail.mit.edu/6.S078

Null Branch Predictionmodule mkNeverTaken(NextAddressPredictor); method Addr prediction(Addr pc); return pc+4; endmethod
method Action update(Addr pc, Addr target); noAction; endmethod
endmodule
Replaces PC+4 with … Already implemented in the pipeline
Right most of the time Why?
April 9, 2012 L16-24http://csg.csail.mit.edu/6.S078

Branch Target Prediction (BTB)module mkBTB(NextAddressPredictor); RegFile#(LineIdx, Addr) tagArr <- mkRegFileFull; RegFile#(LineIdx, Addr) targetArr <- mkRegFileFull;
method Addr prediction(Addr pc); LineIdx index = truncate(pc >> 2); let tag = tagArr.sub(index); let target = targetArr.sub(index); if (tag==pc) return target; else return (pc+4); endmethod
method Action update(Addr pc, Addr target); LineIdx index = truncate(pc >> 2); tagArr.upd(index, pc);
targetArr.upd(index, target); endmethodendmoduleApril 9, 2012 L16-25http://csg.csail.mit.edu/6.S078

Two-stage pipeline + BPmodule mkProc(Proc); Reg#(Addr) pc <- mkRegU; RFile rf <- mkRFile; IMemory iMem <- mkIMemory; DMemory dMem <- mkDMemory; PipeReg#(TypeFetch2Decode) ir <- mkPipeReg; Reg#(Bool) fEpoch <- mkReg(False); Reg#(Bool) eEpoch <- mkReg(False); FIFOF#(Tuple2#(Addr,Addr)) nextPC <- mkBypassFIFOF; NextAddressPredictor bpred <- mkNeverTaken; The definition of TypeFetch2Decode is changed to
include predicted pc typedef struct { Addr pc; Addr ppc; Bool epoch; Data inst; } TypeFetch2Decode deriving (Bits, Eq);
April 9, 2012 L16-26http://csg.csail.mit.edu/6.S078
Some target predictor

Two-stage pipeline + BP Fetch rule rule doFetch (ir.notFull); let ppc = bpred.prediction(pc); let inst = iMem(pc); ir.enq(TypeFetch2Decode {pc:pc, ppc:ppc, epoch:fEpoch, inst:inst}); if(nextPC.notEmpty) begin match{.ipc, .ippc} = nextPC.first; pc <= ippc; fEpoch <= !fEpoch; nextPC.deq; bpred.update(ipc, ippc); end else pc <= ppc; endrule
April 9, 2012 L16-27http://csg.csail.mit.edu/6.S078

Two-stage pipeline + BP Execute rulerule doExecute (ir.notEmpty); let irpc = ir.first.pc; let inst = ir.first.inst; let irppc = ir.first.ppc; if(ir.first.epoch==eEpoch) begin let eInst = decodeExecute(irpc, irppc, inst, rf); let memData <- dMemAction(eInst, dMem); regUpdate(eInst, memData, rf); if (eInst.missPrediction) begin nextPC.enq(tuple2(irpc, eInst.brTaken ? eInst.addr : irpc+4)); eEpoch <= !eEpoch; end end ir.deq;endruleendmodule
April 9, 2012 L16-28http://csg.csail.mit.edu/6.S078

Execute Functionfunction ExecInst exec(DecodedInst dInst, Data rVal1, Data rVal2, Addr pc, Addr ppc); ExecInst einst = ?;
let aluVal2 = (dInst.immValid)? dInst.imm : rVal2 let aluRes = alu(rVal1, aluVal2, dInst.aluFunc); let brAddr = brAddrCal(pc, rVal1, dInst.iType, dInst.imm); einst.itype = dInst.iType; einst.addr = (memType(dInst.iType)? aluRes : brAddr; einst.data = dInst.iType==St ? rVal2 : aluRes; einst.brTaken = aluBr(rVal1, aluVal2, dInst.brComp); einst.missPrediction = brTaken ? brAddr!=ppc : (pc+4)!=ppc; einst.rDst = dInst.rDst; return einst;endfunction
April 7, 2012 L7-29http://csg.csail.mit.edu/
6.s078Rev