computer architecture: a constructive approach sequential circuits arvind computer science &...
TRANSCRIPT

Computer Architecture: A Constructive Approach
Sequential Circuits
ArvindComputer Science & Artificial Intelligence Lab.Massachusetts Institute of Technology
Revised February 21, 2012 (Slides from #16 onwards)
February 15, 2012 L3-1http://csg.csail.mit.edu/
6.S078
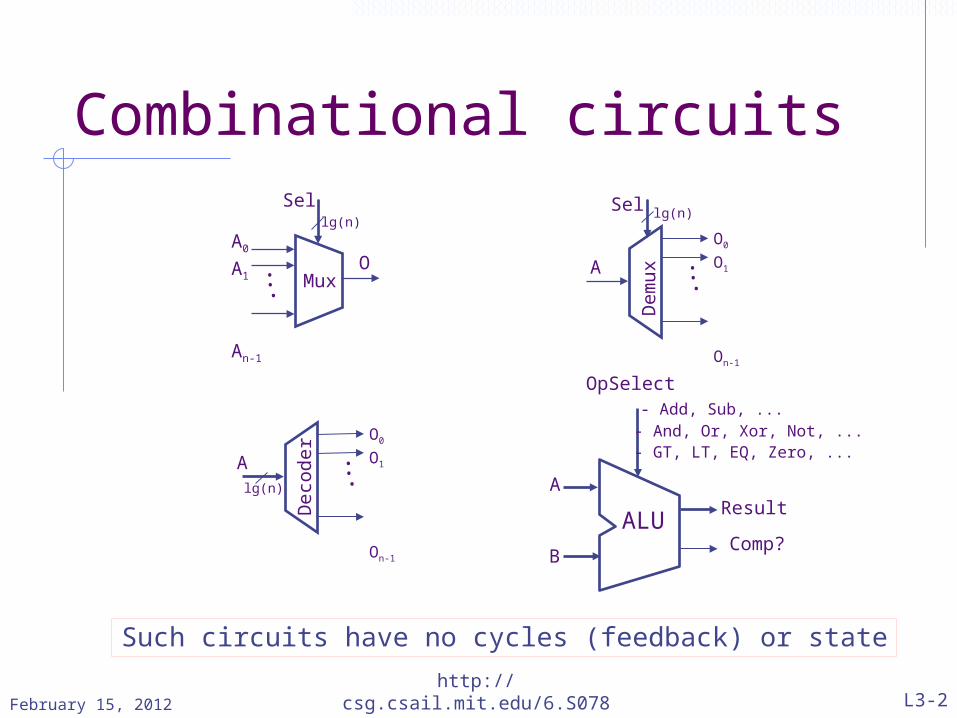
Combinational circuits
OpSelect - Add, Sub, ... - And, Or, Xor, Not, ... - GT, LT, EQ, Zero, ...
Result
Comp?
A
B
ALU
Sel
OA0
A1
An-1
Mux...
lg(n)Sel
O0
O1
On-1
A
Dem
ux ...
lg(n)
A
Deco
der
...
O0
O1
On-1
lg(n)
Such circuits have no cycles (feedback) or state
February 15, 2012 L3-2http://csg.csail.mit.edu/
6.S078

A simple synchronous state element
ff QD
C
C
D
Q
Metastability
Data is sampled at the rising edge of the clock
Edge-Triggered Flip-flop
February 15, 2012 L3-3http://csg.csail.mit.edu/
6.S078

Flip-flops with Write Enables
ff QD
C
EN
C
D
Q
EN
ff QDC
EN
01
ff QD
CEN
dangerous!
Data is captured only if EN is on
February 15, 2012 L3-4http://csg.csail.mit.edu/
6.S078

Registers
Register: A group of flip-flops with a common clock and enable
Register file: A group of registers with a common clock, input and output port(s)
ff
D
ff
D
ff
D
ff
D
ff
D
ff
D
ff
D
ff
QQQQQQQQ
D
C
En
February 15, 2012 L3-5http://csg.csail.mit.edu/
6.S078

Register Files
ReadData1ReadSel1
ReadSel2
WriteSel
Register file
2R + 1W
ReadData2
WriteData
WEClock
No timing issues in reading a selected register
register 1
WSel C
register 0
WData
WE RSel2
RData2
RSel1
RData1
February 15, 2012 L3-6http://csg.csail.mit.edu/
6.S078

Register Files and Ports
Ports were expensive multiplex a port for read & write
ReadData1ReadSel1
ReadSel2
WriteSel
Register file
2R + 1W
ReadData2
WriteData
WE
ReadDataReadSel
R/WSel Register file
1R + 1R/W
R/WData
WE
February 15, 2012 L3-7http://csg.csail.mit.edu/
6.S078

We can build useful and compact circuits using registers
Example: Multiplication by repeated addition
February 15, 2012 L3-8http://csg.csail.mit.edu/
6.S078
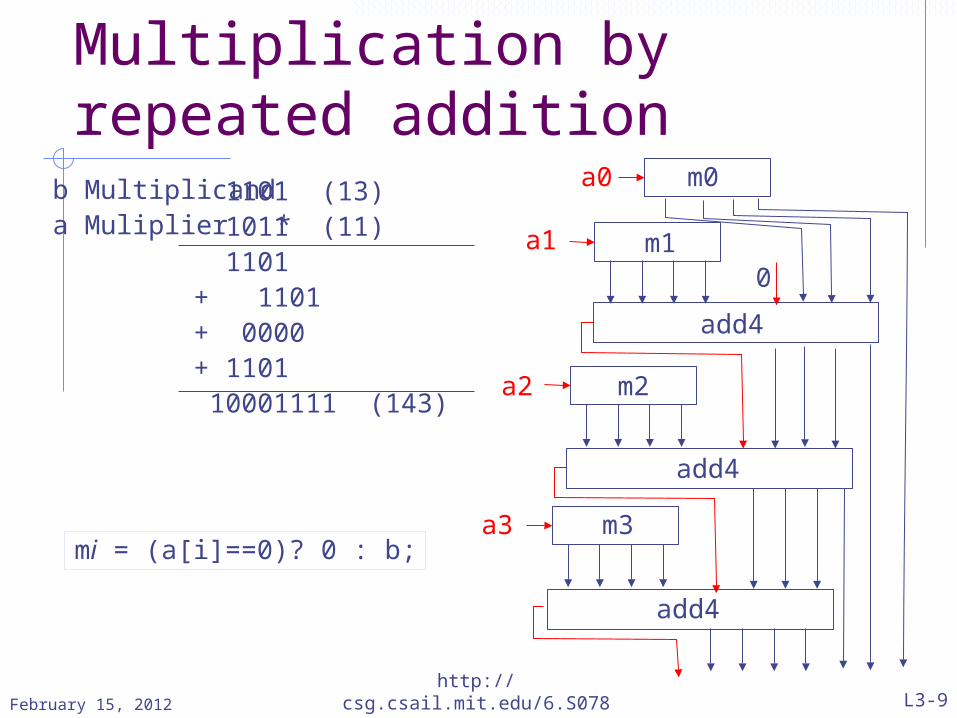
Multiplication by repeated addition
1101 (13)1011 (11)1101
+ 1101 + 0000 + 1101 10001111 (143)
b Multiplicanda Muliplier *
add4
add4
add4
a0
a1
a2
a3
m0
m1
m2
m3
0
mi = (a[i]==0)? 0 : b;
February 15, 2012 L3-9http://csg.csail.mit.edu/
6.S078

Combinational 32-bit multiplyfunction Bit#(64) mul32(Bit#(32) a, Bit#(32) b);
Bit#(32) prod = 0; Bit#(32) tp = 0;
for(Integer i = 0; i < 32; i = i+1) begin Bit#(32) m = (a[i]==0)? 0 : b; Bit#(33) sum = add32(m,tp,0); prod[i] = sum[0]; tp = truncateLSB(sum); end return {tp,prod};endfunction
February 15, 2012 L3-10http://csg.csail.mit.edu/
6.S078

Design issues with combinational multiply
Lot of hardware 32-bit multiply uses 31 addN circuits
Long chains of gates 32-bit ripple carry adder has a 31 long chain
of gates 32-bit multiply has 31 ripple carry adders in
sequence!
The speed of a combinational circuit is determined by its longest input-to-output path
February 15, 2012 L3-11http://csg.csail.mit.edu/
6.S078

Expressing a loop using registersfunction Bit#(64) mul32(Bit#(32) a, Bit#(32) b);
Bit#(32) prod = 0; Bit#(32) tp = 0;
for(Integer i = 0; i < 32; i = i+1) begin Bit#(32) m = (a[i]==0)? 0 : b; Bit#(33) sum = add32(m,tp,0); prod[i] = sum[0]; tp = truncateLSB(sum); end return {tp,prod};endfunction
February 15, 2012 L3-12http://csg.csail.mit.edu/
6.S078
Need registers to hold a, b, tp prod and i
Update the registers every cycle until we are done

Expressing a loop using registers
February 15, 2012 L3-13http://csg.csail.mit.edu/
6.S078
for(Integer i = 0; i < 32; i = i+1) begin let s = f(s); endreturn s;
s
fs0
i (init 0)
+1
<32

Sequential multiply Reg#(Bit#(32)) a <- mkRegU(); Reg#(Bit#(32)) b <- mkRegU();
Reg#(Bit#(32)) prod <-mkRegU();Reg#(Bit#(32)) tp <- mkRegU();Reg#(Bit#(6)) i <- mkReg(32);
rule mulStep if (i < 32); Bit#(32) m = (a[i]==0)? 0 : b; Bit#(33) sum = add32(m,tp,0); prod[i] <= sum[0]; tp <= sum[32:1]; i <= i+1; endrule
state elements
a rule to describe dynamic behavior
February 15, 2012 L3-14http://csg.csail.mit.edu/
6.S078
So that the rule won’t fire until i is set to some other value

Dynamic selection requires a mux
February 15, 2012 L3-15http://csg.csail.mit.edu/
6.S078
a[i]a
i
a[0],a[1],a[2],…a
>>
0

Replacing repeated selections by shifts Reg#(Bit#(32)) a <- mkRegU(); Reg#(Bit#(32)) b <- mkRegU();
Reg#(Bit#(32)) prod <-mkRegU();Reg#(Bit#(32)) tp <- mkRegU();Reg#(Bit#(6)) i <- mkReg(32);
rule mulStep if (i < 32); Bit#(32) m = (a[0]==0)? 0 : b; a <= a >> 1; Bit#(33) sum = add32(m,tp,0); prod <= {sum[0], (prod >> 1)[30:0]}; tp <= sum[32:1]; i <= i+1; endrule
February 15, 2012 L3-16http://csg.csail.mit.edu/
6.S078

Sequential MultiplybIn
b
ai
February 15, 2012 L3-17http://csg.csail.mit.edu/
6.S078
== 32
0
done
+1
prod
result (low)
<<
[30:0]
aIn
<<
31:0
tp
result (high)
add
&……………&0
310
0
s1 s1
s1
s2 s2 s2 s2
s1
s1 = start_ens2 = start_en | !done
32:1

rdyenInt#(32)
Int#(64)
rdy
start
resu
lt Mult
iply
module
Int#(32)
implicit conditions
interface Multiply; method Action start (Int#(32) a, Int#(32) b); method Int#(64) result();endinterface
Multiply Module
Many different implementations can provide the same interface: module mkMultiply (Multiply)
February 15, 2012 L3-18http://csg.csail.mit.edu/
6.S078

Multiply Modulemodule mkMultiply32 (Multiply32); Reg#(Bit#(32)) a <- mkRegU(); Reg#(Bit#(32)) b <- mkRegU();
Reg#(Bit#(32)) prod <-mkRegU();Reg#(Bit#(32)) tp <- mkRegU();Reg#(Bit#(6)) i <- mkReg(32);
rule mulStep if (i < 32); Bit#(32) m = (a[0]==0)? 0 : b; Bit#(33) sum = add32(m,tp,0); prod <= {sum[0], (prod >> 1)[30:0]}; tp <= sum[32:1]; a <= a >> 1; i <= i+1; endrule method Action start(Bit#(32) aIn, Bit#(32) bIn) if (i == 32); a <= aIn; b <= bIn; i <= 0; tp <= 0; prod <= 0; endmethod method Bit#(64) result() if (i == 32); return {tp,prod}; endmethod endmodule
February 15, 2012 L3-19http://csg.csail.mit.edu/
6.S078
State
Internalbehavior
Exte
rnal
inte
rface

Module: Method Interface
February 15, 2012 L3-20http://csg.csail.mit.edu/
6.S078
s1 = start_ens2 = start_en | !done
bIn
b
ai
== 32
0
done
+1
prod
result (low)
<<
[30:0]
aIn
<<
31:0
tp
result (high)
add
&……………&0
310
0
s1 s1
s1
s2 s2 s2 s2
s1
32:1
aInbIn
enrdy
resultrdy
start
resu
lt
s1
ORs1 s2

rdyenabInt#(32)
Int#(64)
rdy
start
resu
lt Mult
iply
module
Int#(32)
implicit conditions
interface Multiply; method Action start (Int#(32) a, Int#(32) b); method Int#(64) result();endinterface
Polymorphic Multiply Module
n
#(Numeric type n)
n
Tadd(n+n)
n nTAdd#(n,n)
n could beInt#(32),Int#(13), ...
The module can easily be made polymorphic
http://csg.csail.mit.edu/SNU L02-21January 11, 2012

Sequential n-bit multiplymodule mkMultiplyN (MultiplyN); Reg#(Bit#(n)) a <- mkRegU(); Reg#(Bit#(n)) b <- mkRegU();
Reg#(Bit#(n)) prod <-mkRegU();Reg#(Bit#(n)) tp <- mkRegU();
Reg#(Bit#(Add#(Tlog(n),1)) i <- mkReg(n); nv = valueOf(n); rule mulStep if (i < nv); Bit#(n) m = (a[0]==0)? 0 : b; Bit#(TAdd#(n,1)) sum = addn(m,tp,0); prod <= {sum[0], (prod >> 1)[(nv-2):0]}; tp <= sum[n:1]; a <= a >> 1; i <= i+1; endrule method Action start(Bit#(n) aIn, Bit#(n) bIn) if (i == nv); a <= aIn; b <= bIn; i <= 0; tp <= 0; prod <= 0; endmethod method Bit#(TAdd#(n,n)) result() if (i == nv); return {tp,prod}; endmethod endmodule
February 15, 2012 L3-22http://csg.csail.mit.edu/
6.S078