this class u how stemming is used in ir u stemming algorithms u frakes: chapter 8 u kowalski: pages...
Post on 20-Dec-2015
220 views
TRANSCRIPT

This Class This Class
How stemming is used in IR Stemming algorithms Frakes: Chapter 8 Kowalski: pages 67-76

Stemming algorithmsStemming algorithms
Affix removing stemmers Dictionary lookup stemmers n-gram stemmers Successor variety stemmers

StemmingStemming
Conflation - combining morphological term variants
Done manually or automatically Automatic algorithms called stemmer
s

Stemming algorithmsStemming algorithms
Conflation methods
Manual Automatic
Affix Removal
SuccessorVariety
DictionaryLookup
n-grams
LongestMatch
SimpleRemoval

Stemming is used for:Stemming is used for: Enhance query formulation
(and improve recall)
by providing term variants Reduce size of index files
by combining term variants
into single index term
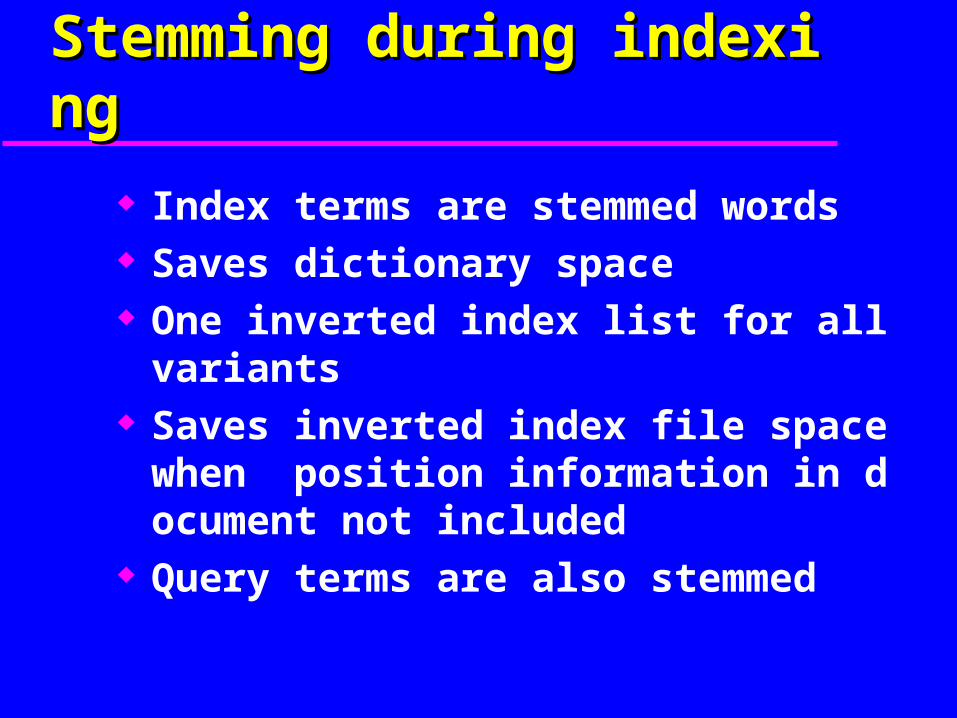
Stemming during indexingStemming during indexing
Index terms are stemmed words Saves dictionary space One inverted index list for all variants Saves inverted index file space when pos
ition information in document not included
Query terms are also stemmed

Index is not stemmedIndex is not stemmed
In this case the index contains words No compression is achieved No information is lost Enables wild card searches Enables long phrase searches
when position information included

Providing term variantsProviding term variants during search during search
A stemming algorithm generate term variants
Term variants added to query automatically (query expansion)
or The user is provided
with term variants and
decides which ones to include
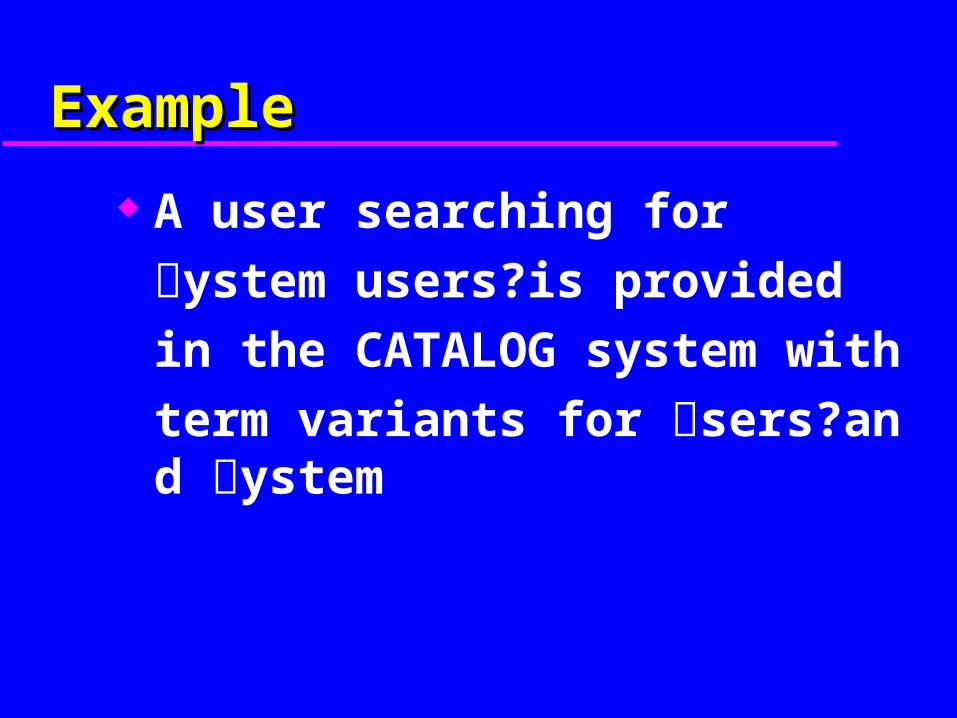
ExampleExample
A user searching for
ystem users?is provided
in the CATALOG system with
term variants for sers?and ystem
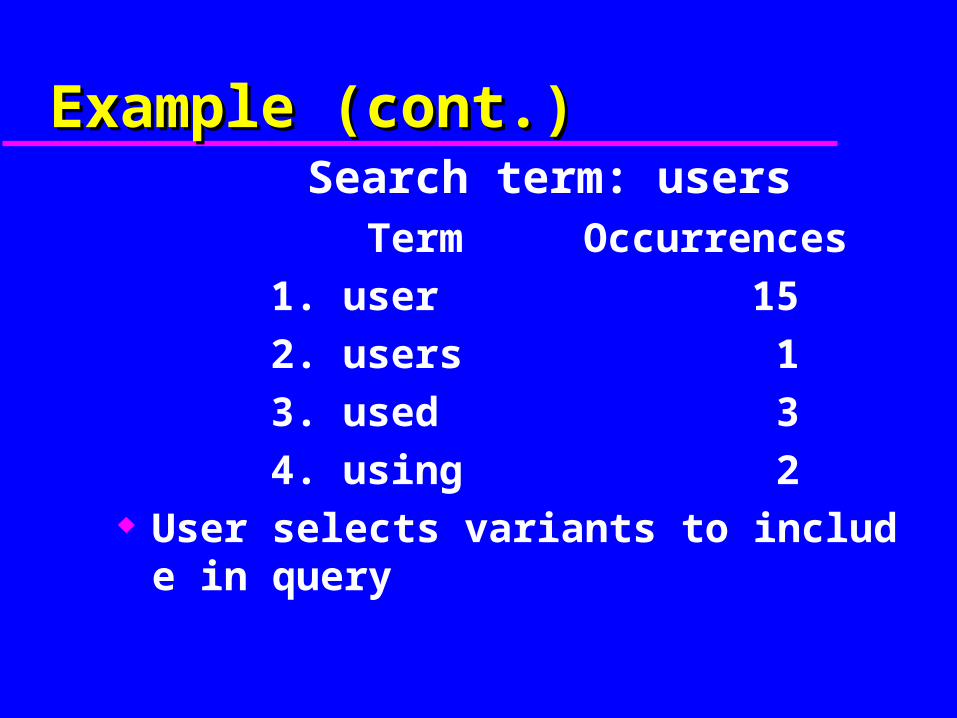
Example (cont.)Example (cont.)Search term: users
Term Occurrences
1. user 15
2. users 1
3. used 3
4. using 2 User selects variants to include in query

Stemmer correctnessStemmer correctness A stemmer can be incorrect by either
– Under-stemming or by
– Over-stemming Over-stemming can reduce precision Under-stemming can affect recall

Over-stemmingOver-stemming Terms with different meanings are confla
ted onsiderate? and
onsider?and
onsideration
should not be stemmed to on? with
ontra?
ontact? etc.

Under-StemmingUnder-Stemming Prevents related terms from being confl
ated Under-stemming
onsideration?to
onsiderat?
prevents conflating it with
onsider

Evaluating stemmersEvaluating stemmers
In information retrieval stemmers are evaluated by their: – effect on retrieval and
– compression rate, and
– not linguistic correctness

Evaluating stemmersEvaluating stemmers
Studies have shown that stemming has a positive effect on retrieval.
Performance of algorithms comparable Results vary between test collections

Affix removal stemmersAffix removal stemmers
Remove – suffixes and and/or
– prefixes from terms
– leaving a stem

Affix removal stemmersAffix removal stemmers
In English stemmers are suffix removers
In other languages,
for example Hebrew,
both prefix and suffix are removed

Affix removal stemmersAffix removal stemmers
Most affix removal stemmers in use are:– iterative - for example, onsideration
?stemmed first to onsiderat?then to onsider
– longest match stemmers using a set of stemming rules.

A simple stemmerA simple stemmer
Harman experimented – concluded minimal stemming helpful
Her simple stemmer changes:– Plural to singular
– Third person to first person

A simple stemmerA simple stemmer
Algorithm changes: kies?to ky? ies->y etrieves?to etrieve? es->s, and oors?to oor? s->NULL (leaves orpus?or ellness? ies?to y?

A simple stemmerA simple stemmer1. word ends in es?but not
ies?or ies?change end to ?
2. word ends in s? but not es? es?or es?change to ?
3. word ends in ?but not s?or s?
remove s

The Paice/Husk stemmerThe Paice/Husk stemmer
Uses a table of rules grouped into sections Section for each last letter of a suffix (rul
es for forms ending in a, then b, etc.) A form is any word or part of a word con
sidered for stemming

The Paice/Husk stemmerThe Paice/Husk stemmer
Each rule specifies a deletion or a replacement of an ending
The order of the rules in each section is important.
Rules tried until one can be applied, and the current form is updated

Rule structureRule structure Each rule contains 5 parts (2 are optional
): An ending (one or more characters in rev
erse order) An optional ntact?flag ??denoting form
not yet stemmed

Rule structureRule structure A digit (>=0) specifying no. characters to
remove An optional string to append (after remo
val) A rule ending with
??denotes stemming should continue
?? terminating the stemming process

Examples of rulesExamples of rules
ei3y>? if form ends in es?then replace the last
3 letters by ?and continue stemming
( ries?becomes ry?

Examples of rulesExamples of rules
u*2.? if form ends with m?and word is intact
remove 2 last letters and terminate stemming.
aximum?is stemmed to axim? but resum?from resumably?remains unchanged

Examples of rulesExamples of rules
lp0.?- if word terminates in ly?terminate. Next rule l2>?does not remove y?from ultiply
ois4j>?causes ion?to be replaced by ?
?acts as dummy ending rovision?converted to rovij?and then
to rovid

Acceptability conditionsAcceptability conditions
Rule not applied unless conditions satisfied
Attempt to prevent over-stemming Without them
ent? ant? ice? ate?
ation?iver?reduce to ? There are 2 rules:

Acceptability conditionsAcceptability conditions
If form starts with a vowel then at least 2 letters must remain (owed/owing->ow but not ear->e)
If a form starts with a consonant then at least 3 letters must remain, and
at least one must be a vowel or
(saying->say, crying->cry, but not string->str, meant->me, or cement->ce)

Acceptability conditionsAcceptability conditions
These rules cause error in the stemming of some short-rooted words
(doing, dying, being). These could be dealt with separately with
a table lookup

Example with Paice stemmingExample with Paice stemming
eparately?- use ?section mismatch ylb1>, yli3y>, ylp0. match yl2>. Form becomes eparate? use rule 1>?in ?section form changes to eparat?- use t section mismatch with acilp4y.? match with a2
>? change form to epar use r section, match with a2.? So ep

Other examplesOther examples
preparation prepare prepared
rule nois4j> fails
rule e1> prepar
rule de2>prepar
rule noix4ct.fails
rule ra2.prep
rule ra2. prep
rule noi2> preparatrule ta2> preparrule ra2.
prep

n-gramsn-grams
Fixed length consecutive series of ?characters
Bigrams:– Sea colony -> (se ea co ol lo on ny)
Trigrams– Sea colony -> (sea col olo lon ony), or
-> (#se sea ea# #co col olo lon ony ny#)

Usage of n-grams Usage of n-grams
Used in world war II by cryptographers Spell checking Text compression Signature files Stemming

n-gram temmersn-gram temmers
Adamson and Borcham (1974) Method for grouping term variants Language independent

n-gram temmersn-gram temmers
Each term transformed to n-gram A similarity value
is generated between
any pair of terms in database,
resulting in a similarity matrix

n-gram temmersn-gram temmers
A clustering method (single link) groups highly similar terms into clusters
Most matrix elements had value 0. Used a cutoff value of 0.6 for their cl
ustering algorithm

Dice Coefficient Dice Coefficient
Many formulas for computing set similarity
Dice coefficient:
S=2(|A B|)/(|A|+|B|) 0 S 1 S=1 if A=B, S=0 if A B=

Sets of Unique BigramsSets of Unique Bigrams
Let A and B denote the sets of unique bigrams associated with two terms, and let C=A B
statistics -> (st ta at ti is st ti ic cs) Set of unique bigrams for statistics:
A={at cs ic is st ta ti}, |A|=7

n-gram temmersn-gram temmers
statistical= (st ta at ti is st ti ic ca al) Set of unique bigrams for statistical
B= {al at ca ic is st ta ti}, |B|=8 C={at ic is ta st ti}, |C|=6 S=2|C|/(|A|+|B|)=2x6/(7+8)=.8

Table lookup methodTable lookup method
Ideally, a table is constructed with stem for every word
Stemming - look up word find stem There is no such data for English Systems use a combination of diction
ary lookup and conflation rules

Dictionary lookup methodDictionary lookup method
INQUERY uses Kstem Kstem is a morphological analyzer t
hat conflates word variants to root form

Dictionary lookup methodDictionary lookup method
Tries to avoid collapsing words with different meaning to same root
The original word or a stemmed version is looked up in a dictionary and replaced by the best stem

Successor variety stemmerSuccessor variety stemmer
Based on work in structural linguistic (Hafer and Weiss)
Performed less well than affix removing stemmers
Given a set of words,
the successor variety (SV) of a string is the number of different characters that follow it in words in the set

Successor variety stemmersSuccessor variety stemmers
Terms : {able, axle, accident, ape, about, apply, application, applies}
The SV of p?is 2 p?is followed by ?in pe?and
by ?in pply application and applies The SV of ?is 4
?followed in set by ? ?? and
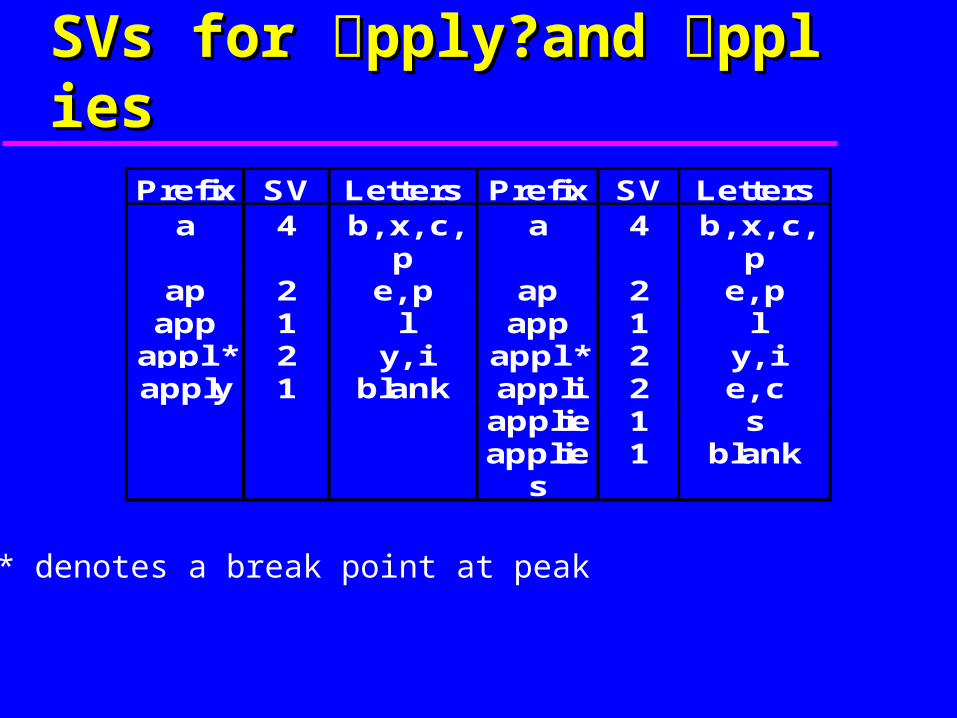
SVs for pply?and ppliesSVs for pply?and ppliesPrefix SV Letters Prefix SV Letters
a 4 b, x, c,p
a 4 b, x, c,p
ap 2 e, p ap 2 e, papp 1 l app 1 l
appl * 2 y, i appl * 2 y, iapply 1 blank appli 2 e, c
applie 1 sapplie
s1 blank
* denotes a break point at peak

SV for pplication
Prefix SV Lettersa 4 b, x, c, p
ap 2 e, papp 1 lappl 2 y, i
appli * 3 c, y, eapplic 1 a
applica 1 tapplicat 1 iapplicati 1 o
applicatio 1 napplication 1 blank

Segmenting wordsSegmenting words 4 ways:
– Cut-off SV is reached
– SV eaks
– A substring of a word is equal to another word in the set
eadable?breaks into ead?and ble
– Entropy based method

Selecting a stemSelecting a stem
First segment is selected if it occurs in at most 12 words,
Otherwise the second segment is selected (3 segments are unlikely)

SummarySummary
All automatic stemmers - sometimes incorrect
n-gram method can be used for different languages
In general affix removing stemmers are more orrect
Longest match stemming does not always generate satisfactory word stems