slides - scicomp
TRANSCRIPT

S c i c o m P 2 0 1 3 T u t o r i a l
Intel® Xeon Phi™ Product Family Programming Models
Klaus-Dieter Oertel, May 28th 2013
Software and Services Group Intel Corporation

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Agenda
• Overview
• Execution options
• Parallelization options
• Vectorization options
3

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Range of models to meet application needs
Programming Models and Mindsets
Foo( ) Main( ) Foo( ) MPI_*( )
Main( ) Foo( ) MPI_*( )
Main( ) Foo( ) MPI_*( )
Main( ) Foo( ) MPI_*( )
Main( ) Foo( ) MPI_*( ) Multi-core
(Xeon)
Many-core
(MIC)
Multi-Core Centric Many-Core Centric
Multi-Core Hosted
General purpose serial and parallel
computing
Offload
Codes with highly- parallel phases
Many Core Hosted
Highly-parallel codes
Symmetric
Codes with balanced needs
Xeon MIC
Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
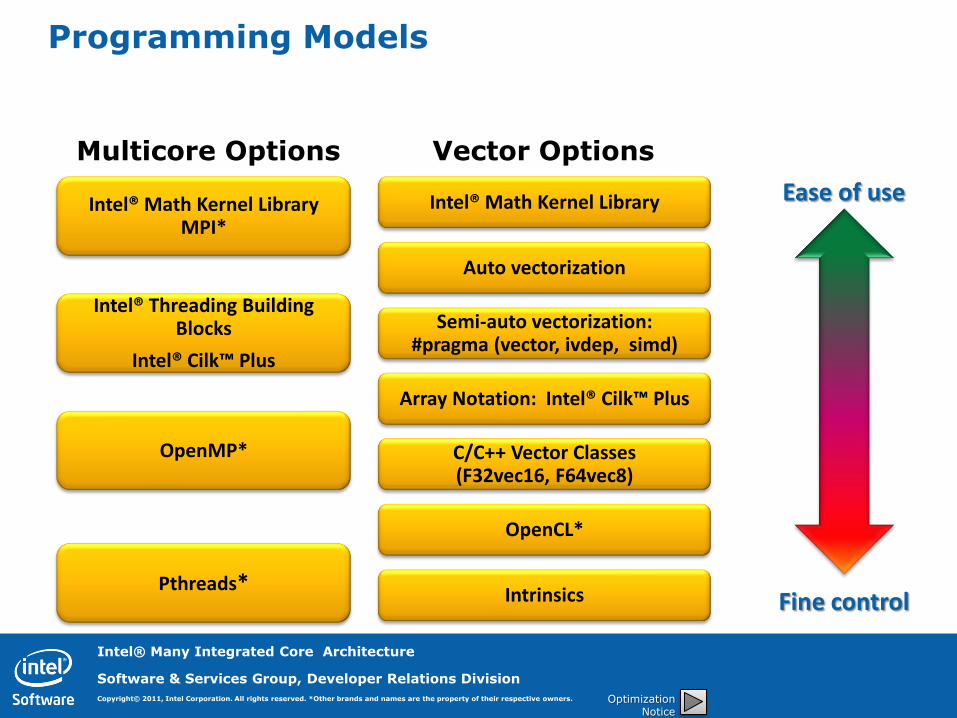
Programming Models
Intel® Math Kernel Library MPI*
Intel® Threading Building Blocks
Intel® Cilk™ Plus
OpenMP*
Pthreads*
Intel® Math Kernel Library
Array Notation: Intel® Cilk™ Plus
Auto vectorization
Semi-auto vectorization: #pragma (vector, ivdep, simd)
OpenCL*
C/C++ Vector Classes (F32vec16, F64vec8)
Intrinsics
Ease of use
Fine control
Multicore Options Vector Options

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Comparison of Options
• Programming models that abstract the target Intel architecture
– Intel® MKL
– Intel® Cilk™ Plus
– OpenMP*
– Intel® Threading Building Blocks
– Compiler-based full autovectorization
• Technologies that may involve architecture-specific user hints
– Compiler-based full autovectorization
o Ex: explicit cache-blocking of data
– Semiautomatic vectorization with annotation
o #pragma vector, #pragma ivdep, and #pragma simd
• Programming models that require writing architecture-specific code
– C/C++ Vector Classes (F32vec16, F64vec8)
– Vector intrinsics (mm_add_ps, addps)
– Pthreads*
10

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Agenda
• Overview
• Execution options
– Native Execution
– Offload Execution
• Parallelization options
• Vectorization options
11

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® Xeon Phi™ Coprocessor runs as a native or MPI* compute node via IP or OFED
12
ssh or telnet connection to coprocessor IP address
Virtual terminal session
Linux* OS Linux* OS
PCI-E Bus PCI-E Bus
Intel® Xeon Phi™ Coprocessor communication
and application-launch support
Intel® Xeon Phi™ Coprocessor Host Processor
System-level code System-level code
User-level code User-level code
Target-side “native” application
User code
Standard OS libraries plus any 3rd-party or Intel
libraries
Intel® Xeon Phi™ Coprocessor Architecture support libraries,
tools, and drivers
IB fabric
Advantages • Simpler model
• No directives • Easier port
• Good kernel test
Use if • Not serial • Modest memory • Complex code • No hot spots
for offloading

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
The Intel® Manycore Platform Software Stack (Intel® MPSS) provides Linux* on the coprocessor
13
• Authenticated users can treat it like another node
• Intel MPSS supplies a virtual FS and native execution
• Add –mmic to compiles to create native programs
ssh mic0 top Mem: 298016K used, 7578640K free, 0K shrd, 0K buff, 100688K cached
CPU: 0.0% usr 0.3% sys 0.0% nic 99.6% idle 0.0% io 0.0% irq 0.0% sirq
Load average: 1.00 1.04 1.01 1/2234 7265
PID PPID USER STAT VSZ %MEM CPU %CPU COMMAND
7265 7264 fdkew R 7060 0.0 14 0.3 top
43 2 root SW 0 0.0 13 0.0 [ksoftirqd/13]
5748 1 root S 119m 1.5 226 0.0 ./sep_mic_server3.8
5670 1 micuser S 97872 1.2 0 0.0 /bin/coi_daemon --coiuser=micuser
7261 5667 root S 25744 0.3 6 0.0 sshd: fdkew [priv]
7263 7261 fdkew S 25744 0.3 241 0.0 sshd: fdkew@notty
5667 1 root S 21084 0.2 5 0.0 /sbin/sshd
5757 1 root S 6940 0.0 18 0.0 /sbin/getty -L -l /bin/noauth 1152
1 0 root S 6936 0.0 10 0.0 init
7264 7263 fdkew S 6936 0.0 6 0.0 sh -c top
sudo scp /opt/intel/composerxe/lib/mic/libiomp5.so root@mic0:/lib64
scp a.out mic0:/tmp
ssh mic0 /tmp/a.out my-args
icc –O3 –g –mmic –o nativeMIC myNativeProgram.c

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
• Pros:
– Very easy to use
o Just compile and run
o Handling similar to any compute node (e.g. With NFS)
– Can help in the decision for or against an investment in offload programming
o Does my application benefit already from the coprocessor architecture
o Can it be optimized for better parallelization and vectorization
o No need to start immediately with offload programming (although it is fun)
• Cons:
– Limited memory
– Slow I/O
14
Pros and Cons of Native Execution

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Agenda
• Overview
• Execution options
– Native Execution
– Offload Execution
• Parallelization options
• Vectorization options
15

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® Xeon Phi™ Coprocessor runs as an accelerator for offloaded host computation
16
Linux* OS
Intel® Xeon Phi™ Coprocessor support libraries, tools, and
drivers
Linux* OS
PCI-E Bus PCI-E Bus
Intel® Xeon Phi™ Coprocessor communication
and application-launch support
Intel® Xeon Phi™ Coprocessor Host Processor
System-level code System-level code
User-level code User-level code
Offload libraries, user-level driver, user-
accessible APIs and libraries
User code
Host-side offload application
User code
Offload libraries, user-accessible
APIs and libraries
Target-side offload application
Advantages • More memory available • Better file access • Host better on serial code • Better uses resources

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Use the Offload capabilities of Intel® Composer XE to access the Coprocessor
• Offload directives in source code trigger Intel Composer to compile objects for both host and coprocessor
• When the program is executed and a coprocessor is available, the offload code will run on that target
– Required data can be transferred explicitly for each offload
– Or use Virtual Shared Memory (_Cilk_shared) to match virtual addresses between host and target coprocessor
• Offload blocks initiate coprocessor computation and can be synchronous or asynchronous
17
#pragma offload target(mic) inout(A:length(2000)) C/C++
!DIR$ OFFLOAD TARGET(MIC) INOUT(A: LENGTH(2000)) Fortran
#pragma offload_transfer target(mic) in(a: length(2000)) signal(a)
!DIR$ OFFLOAD_TRANSFER TARGET(MIC) IN(A: LENGTH(2000)) SIGNAL(A)
_Cilk_spawn _Cilk_offload asynch-func()

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Offload using Explicit Copies – Modifier Example
18
float reduction(float *data, int numberOf)
{
float ret = 0.f;
#pragma offload target(mic) in(data:length(numberOf))
{
#pragma omp parallel for reduction(+:ret)
for (int i=0; i < numberOf; ++i)
ret += data[i];
}
return ret;
}
Note: copies numberOf*sizeof(float) elements to the coprocessor, not numberOf bytes – the compiler knows data’s type

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Offload using Explicit Copies – Data Movement
• Default treatment of in/out variables in a #pragma offload
statement
– At the start of an offload:
o Space is allocated on the coprocessor
o in variables are transferred to the coprocessor
– At the end of an offload:
o out variables are transferred from the coprocessor
o Space for both types (as well as inout) is deallocated on the coprocessor
19
Host coprocessor
#pragma offload inout(pA:length(n)) {...}
Allocate
1
Copy back
4
Copy over
2
Free
5
pA
3

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
C/C++ Offload using Explicit Copies
C/C++ Syntax Semantics
Offload pragma #pragma offload <clauses>
<statement>
Allow next statement to execute on coprocessor or host CPU
Offload transfer #pragma offload_transfer
<clauses>
Initiates asynchronous data transfer, or initiates and completes synchronous data transfer
Offload wait #pragma offload_wait <clauses>
Specifies a wait for a previously initiated asynchronous activity
Keyword for variable & function definitions
__attribute__((target(mic))) Compile function for, or allocate variable on, both CPU and coprocessor
Entire blocks of code
#pragma offload_attribute(push,
target(mic))
#pragma offload_attribute(pop)
Mark entire files or large blocks of code for generation on both host CPU and coprocessor
Intel® Many Integrated Core Architecture

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Fortran Offload using Explicit Copies
Fortran Syntax Semantics
Offload directive !dir$ omp offload <clauses> <statement>
Execute next OpenMP* parallel construct on coprocessor
!dir$ offload <clauses> <statement>
Execute next statement (function call) on coprocessor
Offload transfer !dir$ offload_transfer <clause>
Initiates asynchronous data transfer, or initiates and completes synchronous data transfer
Offload wait
!dir$ offload_wait <clauses>
Specifies a wait for a previously initiated asynchronous activity
Keyword for variable/function definitions
!dir$ attributes offload:<mic> :: <ret-name> OR <var1,var2,…>
Compile function or variable for CPU and coprocessor
Intel® Many Integrated Core Architecture

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Offload using Explicit Copies – Modifiers
22
Clauses / Modifiers Syntax Semantics
Target specification target( name[:card_number] ) Where to run construct
Conditional offload if (condition) Boolean expression
Inputs in(var-list modifiersopt) Copy from host to coprocessor
Outputs out(var-list modifiersopt) Copy from coprocessor to host
Inputs & outputs inout(var-list modifiersopt) Copy host to coprocessor and back when offload completes
Non-copied data nocopy(var-list modifiersopt) Data is local to target
Modifiers
Specify pointer length length(element-count-expr) Copy N elements of the pointer’s type
Control pointer memory allocation
alloc_if ( condition ) Allocate memory to hold data referenced by pointer if condition is TRUE
Control freeing of pointer memory
free_if ( condition ) Free memory used by pointer if condition is TRUE
Control target data alignment
align ( expression ) Specify minimum memory alignment on target
Variables and pointers restricted to scalars, structs of scalars, and arrays of scalars

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Offload using Explicit Copies - Rules & Limitations
• The HostCoprocessor data types allowed in a simple offload:
– Scalar variables of all types
o Must be globals or statics if you wish to use them with nocopy, alloc_if, or free_if (i.e. if they are to persist on the coprocessor
between offload calls)
– Structs that are bit-wise copyable (no pointer data members)
– Arrays of the above types
– Pointers to the above types
• What is allowed within coprocessor code?
– All data types can be used (incl. full C++ objects)
– Any parallel programming technique (Pthreads*, Intel® TBB, OpenMP*, etc.)
– Intel® Xeon Phi™ versions of Intel® MKL
23

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Heterogeneous Compiler – Implicit: Offloading using _Cilk_offload Example
// Shared variable declaration for pi
_Cilk_shared float pi;
// Shared function declaration for
// compute
_Cilk_shared void compute_pi(int count)
{
int i;
#pragma omp parallel for \
reduction(+:pi)
for (i=0; i<count; i++)
{
float t = (float)((i+0.5f)/count);
pi += 4.0f/(1.0f+t*t);
}
}
void findpi()
{
int count = 10000;
// Initialize shared global
// variables
pi = 0.0f;
// Compute pi on target
_Cilk_offload
pi /= count;
}
24
_Cilk_offload
compute_pi(count);
_Cilk_shared void compute_pi(int count)
{
int i;
#pragma omp parallel for \
reduction(+:pi)
for (i=0; i<count; i++)
{
float t = (float)((i+0.5f)/count);
pi += 4.0f/(1.0f+t*t);
}
}
Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
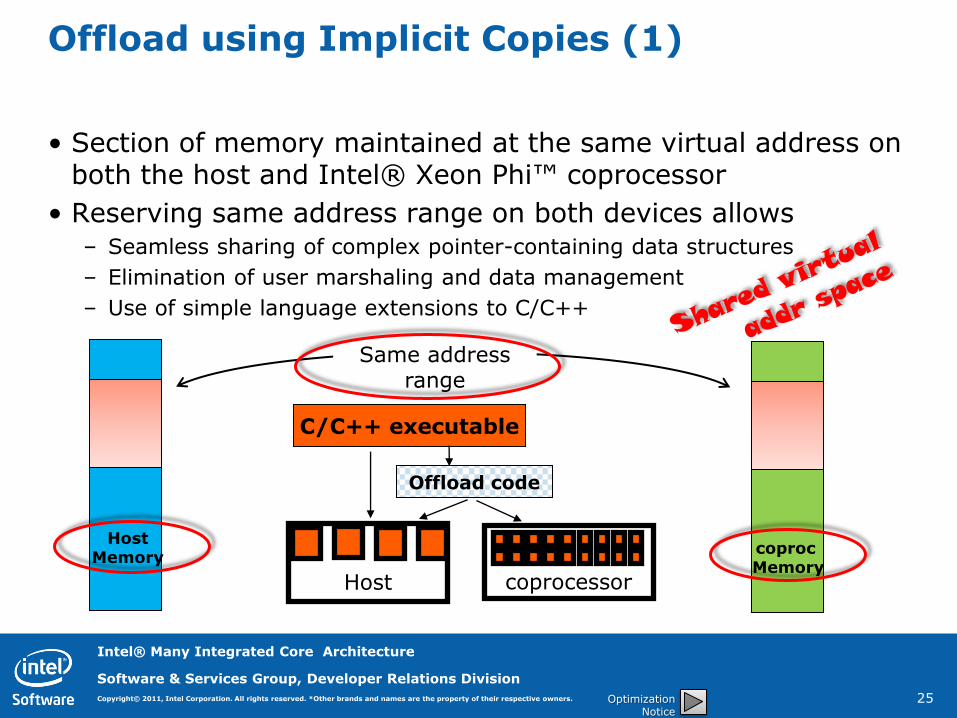
Offload using Implicit Copies (1)
• Section of memory maintained at the same virtual address on both the host and Intel® Xeon Phi™ coprocessor
• Reserving same address range on both devices allows – Seamless sharing of complex pointer-containing data structures
– Elimination of user marshaling and data management
– Use of simple language extensions to C/C++
25
Host Memory
coproc Memory
Offload code
C/C++ executable
Host
coprocessor
Same address range

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Offload using Implicit Copies (2)
• When “shared” memory is synchronized
– Automatically done around offloads (so memory is only synchronized on entry to, or exit from, an offload call)
– Only modified data is transferred between CPU and coprocessor
• Dynamic memory you wish to share must be allocated with special functions: _Offload_shared_malloc(), _Offload_shared_aligned_malloc(), _Offload_shared_free(),
_Offload_shared_aligned_free()
• Allows transfer of C++ objects
– Pointers are no longer an issue when they point to “shared” data
• Well-known methods can be used to synchronize access to shared data and prevent data races within offloaded code
– E.g., locks, critical sections, etc.
This model is integrated with the Intel® Cilk™ Plus parallel extensions
26
Note: Not supported on Fortran - available for C/C++ only

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Implicit: Keyword _Cilk_shared for Data and
Functions
27
What Syntax Semantics
Function int _Cilk_shared f(int x)
{ return x+1; }
Versions generated for both CPU and card; may be called from either side
Global _Cilk_shared int x = 0; Visible on both sides
File/Function static
static _Cilk_shared int x; Visible on both sides, only to code within the file/function
Class class _Cilk_shared x {…}; Class methods, members, and and operators are available on both sides
Pointer to shared data
int _Cilk_shared *p; p is local (not shared), can point to shared data
A shared pointer int *_Cilk_shared p; p is shared; should only point at shared data
Entire blocks of code
#pragma offload_attribute(
push, _Cilk_shared)
#pragma offload_attribute(pop)
Mark entire files or large blocks of code _Cilk_shared using this pragma
Intel® Many Integrated Core Architecture

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Implicit: Offloading using _Cilk_offload
28
Feature Example Description
Offloading a function call
x = _Cilk_offload func(y); func executes on
coprocessor if possible
x = _Cilk_offload_to (card_num)
func(y);
func must execute on
specified coprocessor
Offloading asynchronously
x = _Cilk_spawn _Cilk_offload
func(y);
Non-blocking offload
Offload a parallel for-loop
_Cilk_offload _Cilk_for(i=0; i<N;
i++)
{
a[i] = b[i] + c[i];
}
Loop executes in parallel on target. The loop is implicitly outlined as a function call.

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Comparison of Offload Techniques (1)
29
Offload via Explicit Data Copying
Offload via Implicit Data Copying
Language Support Fortran, C, C++ (C++ functions may be called, but C++ classes cannot be transferred)
C, C++
Syntax Pragmas/Directives: • #pragma offload in
C/C++ • !dir$ omp offload
directive in Fortran
Keywords: _Cilk_shared and _Cilk_offload
Used for… Offloads that transfer contiguous blocks of data
Offloads that transfer all or parts of complex data structures, or many small pieces of data

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Comparison of Offload Techniques (2)
30
Offload via Explicit Data Copying
Offload via Implicit Data Copying
Offloaded data allowed
Scalars, arrays, bit-wise copyable structures
All data types (pointer-based data, structures, classes, locks, etc.)
Which data is transferred
User has explicit control of data movement at start of each offload directive
All _Cilk_shared data
synchronized at start and end of _Cilk_offload
statements
When data movement occurs
Data transfer can overlap with offload execution
Not available
When offload code is copied to card
At first #pragma offload At program startup

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Agenda
• Overview
• Execution options
• Parallelization options
• Vectorization options
31

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Options for Thread Parallelism
Intel® Math Kernel Library
OpenMP*
Intel® Threading Building Blocks
Intel® Cilk™ Plus
Pthreads* and other threading libraries Programmer control
Ease of use / code maintainability
Choice of unified programming to target Intel® Xeon and Intel® Xeon Phi™!

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® Math Kernel Library (1)
• Highly optimized, multi-threaded (when appropriate) math libraries providing functions often found in:
– Engineering and Manufacturing
– Financial Services
– Geological/Energy Industries
• Automatically optimized for the platform on which the functions are called:
– Called on the Intel® MIC Architecture, they will make best use of SIMD and parallelism
• Intel® MKL Functional Domains with Intel® MIC Architecture support:
– Linear Algebra: BLAS, LAPACK, LINPACK
– Sparse BLAS
– Fast Fourier Transforms (FFT) 1D/2D/3D FFT
– Vector Math and Statistical Libraries
33

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® MIC
•Native execution (of course)
• Identical usage syntax on host and coprocessor
•Functions called from the host execute on the host, functions called from the coprocessor execute on coprocessor
–User is responsible for data transfer and execution management between the two domains
Intel® Math Kernel Library Use in Offload Code
Host
Hetero App
MIC optimized
Intel® MKL
<Offloaded code>
Host optimized
Intel® MKL Intel® MIC support stack
35
Native code

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® Math Kernel Library Offload Example
36
Calculates the new value of matrix C based on the matrix product of matrices A
and B, and the old value of matrix C
where α and β values are scalar coefficients
void foo(…) /* Intel MKL Offload Example */
{
float *A, *B, *C; /* Matrices */
#pragma offload target(mic)
in(transa, transb, N, alpha, beta) \
in(A:length(N*N)) \
in(B:length(N*N)) \
inout(C:length(N*N))
sgemm(&transa, &transb, &N, &N, &N, &alpha,
A, &N, B, &N, &beta, C, &N);
}
C AB + C

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® Math Kernel Library Automatic Offload • Transparent load balancing between host and coprocessors
• Initiated by calling mkl_mic_enable() on the host before calling
Intel® MKL functions that implement Automatic Offload
• Call the function from the host code
– No “_Cilk_offload” or “#pragma offload” needed
– Intel® MKL is responsible for data transfer and execution management
Host Side
User’s App
Intel® MIC Side
Intel® MIC optimized
Intel® MKL Intel® MKL Worker process
Host Optimized Intel® MKL
Hetero Intel® MKL
library
37
Transparent load balancing
Intel® MIC support stack
Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
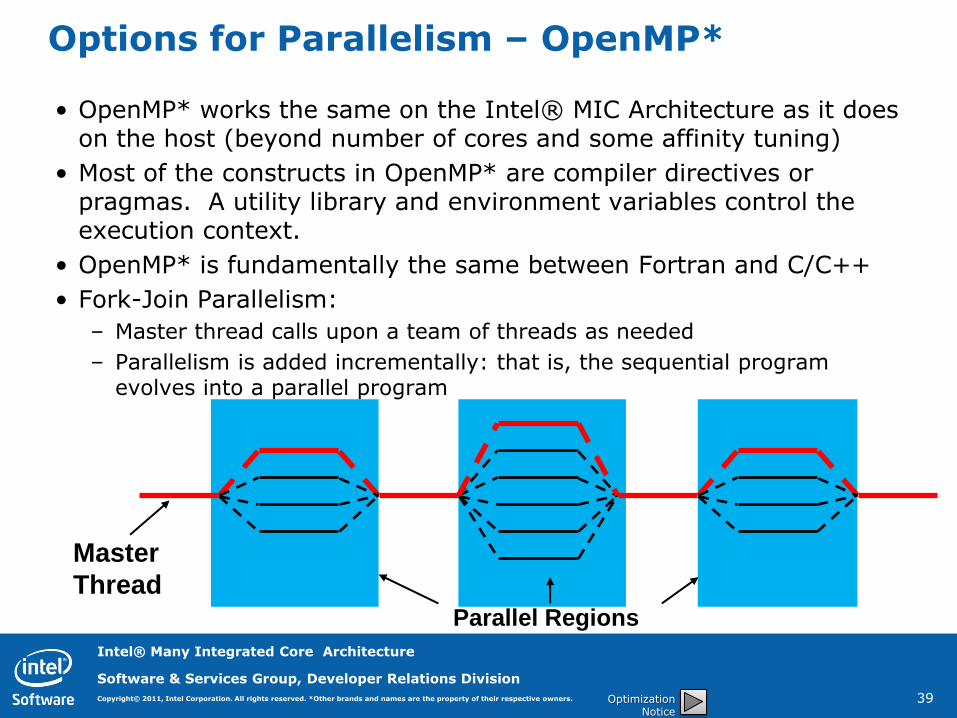
Options for Parallelism – OpenMP*
• OpenMP* works the same on the Intel® MIC Architecture as it does on the host (beyond number of cores and some affinity tuning)
• Most of the constructs in OpenMP* are compiler directives or pragmas. A utility library and environment variables control the execution context.
• OpenMP* is fundamentally the same between Fortran and C/C++
• Fork-Join Parallelism:
– Master thread calls upon a team of threads as needed
– Parallelism is added incrementally: that is, the sequential program evolves into a parallel program
39
Parallel Regions
Master
Thread

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
OpenMP* parallelism can be easily finessed into offload parallelism
• OpenMP is a simple way to add parallelism
41
#pragma omp parallel for for (i=1; i < N-1; ++i) B2[i] = m * B1[i-1] + n * B1[i] + p * B1[i+1];
!$OMP PARALLEL DO do I=2, N-1 B2(I) = m * B1(I-1) + n * B1(I) + p * B1(I+1) end do

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
OpenMP* parallelism can be easily finessed into offload parallelism
• OpenMP is a simple way to add parallelism
42
#pragma omp parallel for for (i=1; i < N-1; ++i) B2[i] = m * B1[i-1] + n * B1[i] + p * B1[i+1];
!$OMP PARALLEL DO do I=2, N-1 B2(I) = m * B1(I-1) + n * B1(I) + p * B1(I+1) end do
Offload easily shifts that parallelism to the coprocessor #pragma offload target(mic: CPID) if (N > Limit) #pragma omp parallel for for (i=1; i < N-1; ++i) B2[i] = m * B1[i-1] + n * B1[i] + p * B1[i+1];
!DIR$ OFFLOAD BEGIN target(mic : CPID) IF (N .GT. Limit) !$OMP PARALLEL DO do I=2, N-1 B2(I) = m * B1(I-1) + n * B1(I) + p * B1(I+1) end do !DIR$ END OFFLOAD

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Options for Parallelism – OpenMP* Example - Parallel Sections
• Specify blocks of code to execute in parallel
• Almost identical functionality can be obtained using the OpenMP* 3.0 task construct
Serial
Parallel
#pragma omp parallel sections
{
#pragma omp section
task1();
#pragma omp section
task2();
#pragma omp section
task3();
}
47

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Simultaneous Host/Coprocessor Computing – Using OpenMP*
• Simply use OpenMP* task on host to spawn
the offload call
– Then use OpenMP* for parallelism on the coprocessor
• Use other OpenMP* task calls to
simultaneously run code on the host
48
#pragma omp parallel
#pragma omp single
{
#pragma omp task
#pragma offload target(mic) …
{
<various serial code>
#pragma omp parallel for
for (int i=0; i<limit; i++)
<parallel loop body>
}
#pragma omp task
{<host code or another offload>}
}

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Options for Parallelism – Intel® Threading Building Blocks (Intel® TBB)
• Intel® TBB works the same on the Intel® MIC Architecture as it does on the host (beyond number of cores)
• Consists of C++ classes and templates that implement task-based parallelism
– Threads persist in a pool, dispatched upon lighter weight “tasks”
– Makes use of “work stealing” to evenly distribute work across threads and ensure good cache behavior
• Provides a wide range of services needed to implement efficient parallel algorithms
– Generic parallel patterns
– Concurrent containers
– Synchronization primitives
– Dynamic memory management
– Task scheduling
– Thread local storage
– Etc.
50

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Options for Parallelism – Intel® TBB - Services
51
Concurrent Containers
concurrent_hash_map
concurrent_queue
concurrent_bounded_queue
concurrent_vector
concurrent_unordered_map
Miscellaneous tick_count
Generic Parallel Algorithms
parallel_for(range)
parallel_reduce
parallel_for_each(begin, end)
parallel_do tbb::graph
parallel_invoke
pipeline, parallel_pipeline
parallel_sort
parallel_scan
Task scheduler
task_group
task_structured_group
task_scheduler_init
task_scheduler_observer
Synchronization Primitives
atomic; mutex; recursive_mutex;
spin_mutex; spin_rw_mutex;
queuing_mutex; queuing_rw_mutex;
reader_writer_lock; critical_section;
condition_variable;
lock_guard; unique_lock;
null_mutex; null_rw_mutex;
Memory Allocation
tbb_allocator; cache_aligned_allocator; scalable_allocator; zero_allocator
Threads
tbb_thread, thread
Thread Local Storage
enumerable_thread_specific
combinable

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Example: Affinity Partitioner
• Applicable to parallel_for, parallel_reduce, and parallel_scan
•
void sum(int* result, const int* a, const int* b, std::size_t size) { static affinity_partitioner partitioner; parallel_for( blocked_range<std::size_t>(0, size), [=](const blocked_range<std::size_t>& r) { for (std::size_t i = r.begin(); i != r.end(); ++i) { result[i] = a[i] + b[i]; } }, partitioner ); }
52 5/28/2013

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® Cilk™ Plus Keywords for Task Parallelism
• Array notation provides single-core SIMD-based data parallelism
• Fine-grained task parallelism provided by new keyword extensions to C and C++
– Shared memory multiprocessing, not distributed memory
• Three keywords
_Cilk_spawn (cilk_spawn with cilk/cilk.h)
o Function call may be run in parallel with caller – determined at runtime
_Cilk_sync (cilk_sync with cilk/cilk.h)
o Caller waits for all children to complete
_Cilk_for (cilk_for with cilk/cilk.h)
o Any or all iterations may execute in parallel with one another.
o All iterations complete before program continues.
o Subject to the constraint of a single control variable
56

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Intel® Cilk™ Plus keywords for Task Parallelism - Examples
Spawn and sync
Parallel for
57
int fib(int n)
{
int x, y;
if (n < 2) return n;
x = _Cilk_spawn fib(n-1); // non-blocking – x & y values
y = fib(n-2); // calculated in parallel
_Cilk_sync; // wait here until both done
return x+y;
}
_Cilk_for (int i = begin; i < end; i += 2)
f(i);
_Cilk_for (T::iterator i(vec.begin()); i != vec.end(); ++i)
g(i);

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Simultaneous Host/Coprocessor Computing – Using Intel® Cilk™ Plus
• _Cilk_spawn statements in host code can be combined with statements marked with _Cilk_offload to allow asynchronous
processing
– Example: x = _Cilk_spawn _Cilk_offload func(y);
<Host code runs simultaneously on host while _Cilk_offload
code runs on coprocessor>
_Cilk_sync; // Host here waits for all spawns to complete
• Note that the following is not asynchronous, but instead blocks in this host thread until the _Cilk_for completes on the coprocessor
_Cilk_offload _Cilk_for (i=0;i<10000;i++)
{
<loop_body;>
}
58

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Pthreads*
• Pthreads* works the same on the Intel® MIC Architecture as it does on the host (beyond number of cores and some affinity tuning)
– Just do Pthread* programming like you normally would
– Load balancing and thread safety are entirely up to you
• Avoid core 0 (threads 0-3) using the thread affinity API, as that is where the card OS and interrupt-processing occur
– High-level parallel models do this automatically
• Support for other threading libraries will require porting them to the Intel® MIC Architecture
• Be especially careful to make sure all code called by pthread* functions is marked __attribute__((target(mic))) or _Cilk_shared
60

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Pthreads* Partial Example
61
#pragma offload_attribute(push,target(mic))
#include <pthread.h>
#include <pthread_affinity_np.h>
#pragma offload_attribute(pop)
__attributes__((target(mic))) const int
N_THREADS(124);
__attributes__((target(mic))) pthread_t
_knfThreads[N_THREADS];
__attributes__((target(mic))) KnfReductionTask
_knfTasks[N_THREADS];
…
…
__attributes__((target(mic)))
void _knfReductionPThreadsCleanup()
{
for(int i = 0; i < N_THREADS; i++) {
_knfTasks[i].alive = false;
}
pthread_barrier_wait(_knfTasks[0].barrier);
for (int i = 0; i < N_THREADS; i++) {
pthread_join(_knfThreads[i], NULL);
}
pthread_barrier_destroy(_knfTasks[0].barrier);
}
void reductionPThreadsInit()
{
#pragma offload target(mic)
_knfReductionPThreadsInit();
}
float reduction(float *data, size_t size)
{
float ret(0.f);
#pragma offload target(mic) in(data:length(size))
ret = _knfReductionPThreads(data, size);
return ret;
}
void reductionPThreadsCleanup()
{
#pragma offload target(mic)
_knfReductionPThreadsCleanup();
}

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Agenda
• Overview
• Execution options
• Parallelization options
• Vectorization options
64

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Software Behind the Vectorization
float *restrict A, *B, *C;
for(i=0;i<n;i++){
A[i] = B[i] + C[i];
}
66
• [SSE2] 4 elems at a time addps xmm1, xmm2
• [AVX] 8 elems at a time vaddps ymm1, ymm2, ymm3
• [IMCI] 16 elems at a time vaddps zmm1, zmm2, zmm3
Vector (or SIMD) Code computes more than one element at a time.
X3
Y3
X3opY3
0 127
X2
Y2
X2opY2
X1
Y1
X1opY1
X0
Y0
X0opY0
X7
Y7
X7opY7
128 255
X6
Y6
X6opY6
X5
Y5
X5opY5
X4
Y4
X4opY4
X11
Y11
X11opY11
256 383
X10
Y10
X10opY10
X9
Y9
X9opY9
X8
Y8
X8opY8
X15
Y15
X15opY15
384 512
X14
Y14
X14opY14
X13
Y13
X13opY13
X12
Y12
X12opY12
X87 SSE 2 AVX IMIC

Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
Options for SIMD Width Abstraction
68
Intel® MKL Libraries
Array Notation: Intel® Cilk™ Plus
Automatic vectorization
Semiautomatic vectorization with annotation: #pragma vector, #pragma ivdep, and #pragma simd
C/C++ Vector Classes (F32vec16, F64vec8)
Vector intrinsics (mm_add_ps, addps) Programmer control
Ease of use / code maintainability
(depends on problem)


Intel® Many Integrated Core Architecture
Software & Services Group, Developer Relations Division
Copyright© 2011, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Optimization Notice
INFORMATION IN THIS DOCUMENT IS PROVIDED “AS IS”. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO THIS INFORMATION INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Copyright © , Intel Corporation. All rights reserved. Intel, the Intel logo, Xeon, Xeon Phi, Core, VTune, and Cilk are trademarks of Intel Corporation in the U.S. and other countries.
Optimization Notice
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Notice revision #20110804
Legal Disclaimer & Optimization Notice
Copyright© 2012, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
101