mpi performance in a production environment david e. skinner, nersc user services scicomp 10
DESCRIPTION
MPI Performance in a Production Environment David E. Skinner, NERSC User Services ScicomP 10 Aug 12, 2004. Abstract. - PowerPoint PPT PresentationTRANSCRIPT

MPI Performance in a Production Environment
David E. Skinner, NERSC User Services
ScicomP 10 Aug 12, 2004

Abstract
Discussion of a variety of topics related to deploying and optimizing MPI based applications on the IBM SP. Information on application performance, variability in performance, and memory usage is presented within the context of code microkernels and a few selected applications. Comparisons of different MPI libraries are presented as is initial work done to characterize the diverse scientific workload currently running at NERSC.
Load Balance, MPI Performance and Profiling, Gotchas,

National Energy Research Scientific Computing Center
•~2000 Users in ~400 projects
•Serves all disciplines of the DOE Office of Science
NERSC
• Focus on large-scale computing

NERSC: Mission and Customers
NERSC is DOE’s flagship center for capability computing, providingreliable computing infrastructure, HPC consultancy, accurate resourceaccounting.
NERSC Usage by Scientific Discipline, FY02
4%13%
9%
9%
1%
1%24%
19%
3%
14%3%
Accelerator Physics
Astrophysics
Chemistry
Climate and Environmental Sciences
Computer Science and Mathematics
Earth and Engineering Sciences
Fusion Energy
Lattice Gauge Theory
Life Sciences
Materials Science
Nuclear Physics

NERSC Hardware

Seaborg.nersc.gov: system diagram

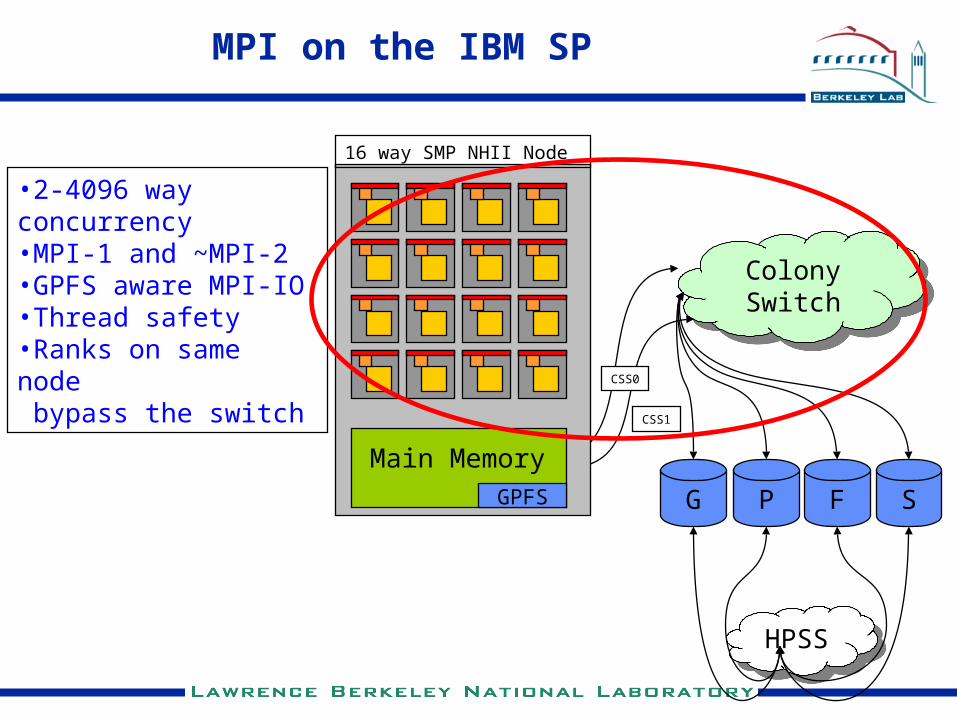
Colony switch fabric in two planes:400 MB/sec 19 usec latency
380 compute nodes allowing 6080 tasks,In production as of last month.

Colony Switch
Colony Switch
PG F S
understanding seaborg.nersc.gov
Resource Speed Bytes
Registers 3 ns 2560 B
L1 Cache 5 ns 32 KB
L2 Cache 45 ns 8 MB
Main Memory 300 ns 16 GB
Remote Memory 19 us 7 TB
GPFS 10 ms 50 TB
HPSS 5 s 9 PB
380 x
HPSSHPSS
CSS0
CSS1
•6080 dedicated CPUs, 96 shared login CPUs•Hierarchy of caching, prefetching to hide latency•Bottleneck determined by first depleted resource
16 way SMP NHII Node
Main MemoryGPFS
IBM SP

This Talk: Parallel Code Topics
In order of importance
– Scalar Performance (important at any scale) – Load Balance– Message Sizes– Topology and Synchronization – MPI Implementation gotchas
importance ~ scale

Load Balance
• If one task lags the others in time to complete synchronization suffers, e.g. a 3% slowdown in one task can mean a 50% slowdown for the code overall
• Seek out and eliminate sources of variation
• Decompose problem uniformly among nodes/cpus
0 50 100
0
2
FLOPI/OSYNCFLOPI/OSYNC

Load Balance: contd.
key Unbalanced:
Balanced:
Time saved by load balance

Load Balance: Real World Application
Time
MP
I R
ank

Load Balance: Real World Application
Time
MP
I R
ank

Load Balance: Summary
•Imbalance most often a byproduct of data decomposition•Must be addressed before further MPI tuning can happen
•How to quickly identify and quantify imbalance? •NERSC consultant can help with visual analysis •poe+ provides a simple quantitative means
•Good software exists to help with graph partitioning / remeshing
•For regular grids consider padding or contracting

load balance via poe+
• How can I quickly determine load balance w/o recompiling or perturbing an exisiting code?
1) hpmcount’s new parallel aware “-a” option---------------HPM------------------------------------------------- hpmcount (V 2.5.3) summary Execution time (wall clock time): 133.128812 seconds on 64 tasks ## Resource Usage Statistics Average Total MIN MAX ## Wall Clock Time (in sec.) : 132.465758 8477.808501 130.002884 133.128812 s Time in user mode (in sec.) : 116.304219 7443.470000 107.020000 117.990000 s Time in system mode (in sec.): 2.216562 141.860000 1.000000 4.990000 s Maximum resident set size : 98324 6292764 97952 98996 KB Shared mem use in text seg. : 37889 2424926 35043 38309 KB*s Unshared mem use in data seg.: 11265782 721010109 10498632 11365248 KB*s Page faults w/out IO activity: 26440 1692189 26320 27002 Page faults with IO activity : 14 942 8 37 Times process was swapped out: 0 0 0 0 Times file system perf. INPUT: 0 0 0 0 Times file system perf.OUTPUT: 0 0 0 0 IPC messages sent : 0 0 0 0 IPC messages received : 0 0 0 0 signals delivered : 315 20196 314 317 voluntary context switches : 2530 161961 594 7705

load balance via poe+
2) poe+ -mpi 8 : ---------------Balance-comp#-Comm*--------------------------------- 32 : ##########################################************************ 62 : ###########################################*********************** 31 : ############################################********************** 30 : ############################################********************** 34 : ############################################********************** 49 : ############################################********************** 63 : ############################################********************** 33 : ############################################********************** 50 : ############################################********************** 53 : ############################################********************** 26 : ############################################********************** 17 : #############################################********************* 43 : #############################################********************* 18 : #############################################********************* 12 : #############################################********************* 3 : #############################################********************* 8 : #############################################********************* 6 : #############################################********************* 10 : #############################################********************* 9 : #############################################********************* 38 : #############################################********************* 15 : #############################################********************* 7 : #############################################********************* 2 : #############################################********************* 11 : #############################################********************* 47 : #############################################********************* 46 : #############################################********************* 4 : #############################################********************* 1 : #############################################********************* 19 : ##############################################******************** 45 : ##############################################******************** 20 : ##############################################******************** 0 : #################################################*****************

Code Topics Continued
• Once load is balanced move on to
– Message Sizes– Synchronization – MPI Implementation gotchas

Inter-Node Bandwidth
csss
css0
• Tune messagesize to optimize throughput• Aggregate messages when possible

MPI Performance on Seaborg
Colony Switch
Colony Switch
PG F S
MPI on the IBM SP
HPSSHPSS
CSS0
CSS1
16 way SMP NHII Node
Main MemoryGPFS
•2-4096 way concurrency•MPI-1 and ~MPI-2 •GPFS aware MPI-IO•Thread safety•Ranks on same node bypass the switch

Scaling of MPI_Barrier()

Synchronization: User Driven Improvements
• Performance variation reported by users running with > 1024 tasks
• USG/NSG/IBM identified and resolved slight asymmetries in how the CWS polls batch nodes about their health.
• Direct benefit for highly parallel applications
• Process driven by feedback from users about performance variability.
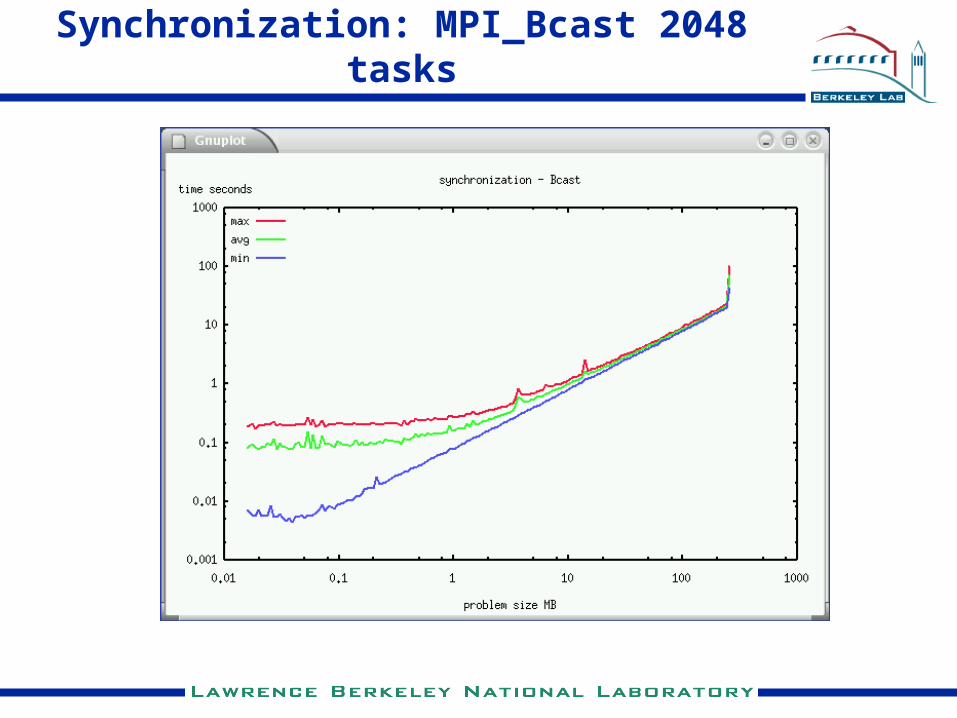
Synchronization: MPI_Bcast 2048 tasks

Synchronization: MPI_Alltoall 2048 tasks

How are we using MPI
• As with load balance we need an easy to use lwo impact way of profiling (or characterizing) time spent in MPI.
• At NERSC we have adopted poe+ to accomplish this

Where can profiling happen?
• Code Developer– Heavy weight tools (TV, TAU, VAMPIR)– Invasive to code, recompilation– Difficult to compare metrics across projects.
• Center Managers– Transparent Liteweight tools (poe+, ja, hpm)– Uniformity, possible centrally stored records
• HW/OS Vendor– Custom ASICs to record performance system wide with
~ no overhead– Center has limited control

Who cares?
• Some users care about performance profiling, many do not.
– Time spent on code is time spent away from obtaining publishable results
• HPC centers care or are made to care
– Evaluating match/conflicts between computers and codes is possible only through
• Generalities / Folk Wisdom • Specifics that users tell us • Specifics that we can measure quantitatively
– Center performance often tied to code+computer performance
• Profiling has no bearing on the scientific quality of any calculation
– E.g., FLOPs meaningless w/o context of algorithm and the motivations for using a particular algorithm
– ALE / Tree codes vs. dense / full

poe+ : Motivation
• Provides an easy to use low overhead (to user and code) interface to performance metrics. – Uses hpmcount to gather and aggregate HPM data. – Can generate an MPI Profile via PMPI interface– Load balance information
• Clear, concise performance reports to user and to NERSC center– Reports go to stdout and to www.nersc.gov
• There are other options PMAPI / PAPI / HPMLIB
ERCAP GFLOP/S : 502.865839 GFLOP/S
ERCAP MB/TASK : 96.01953125 MB

poe+ : Usage
usage: poe+ [-hpm_group n] [-mpi] executable
• “-hpm_group” selects HPM group
– Default group 1 for flops and TLB
– Group 2 for L1 cache load/store misses
• “-mpi” maps MPI* calls to PMPI*
– MPI calls get wrapped to records data movement and timings
– ~1.5 microsecond overhead to each MPI call
– When MPI_Finalize is reached
• Application level summary • Task level summary • Load balance histogram

poe+ : Summary
Easy to use, low overhead Performance ProfilingBenefits Everyone
User Applications:•Scalar performance (HPM)•Parallel efficiency (MPI)•Disk I/O performance (TBA)
Center Policies:•Runtime settings•Queues•SW Versioning
Compute Resources:•System settings•Parallel efficiency (MPI)•Future Machines.
Understanding workload Getting more science done!

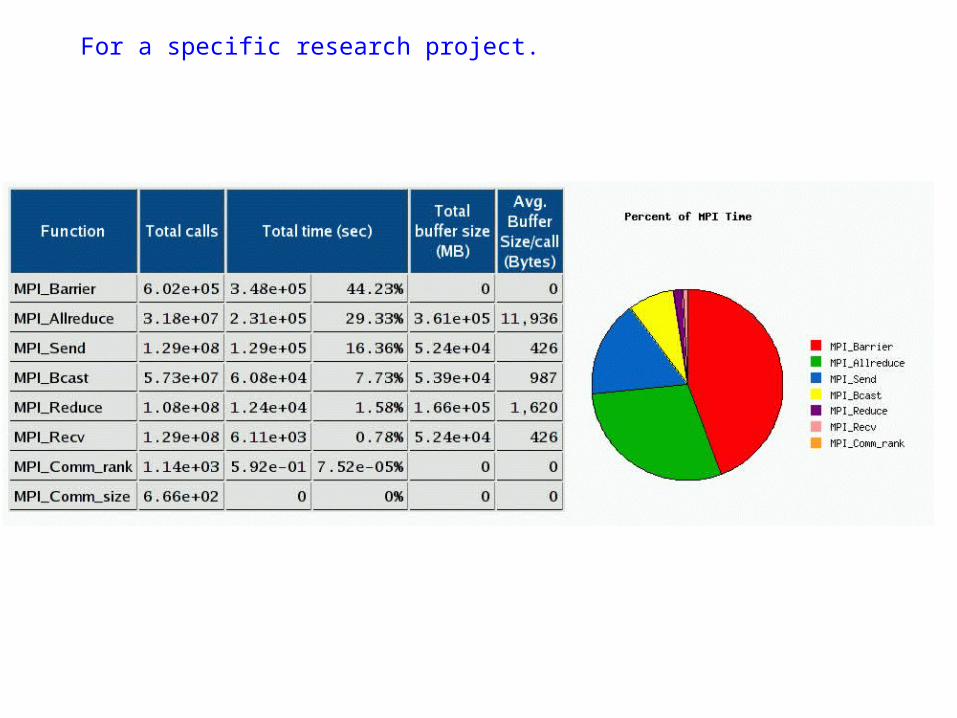
For a specific research project.
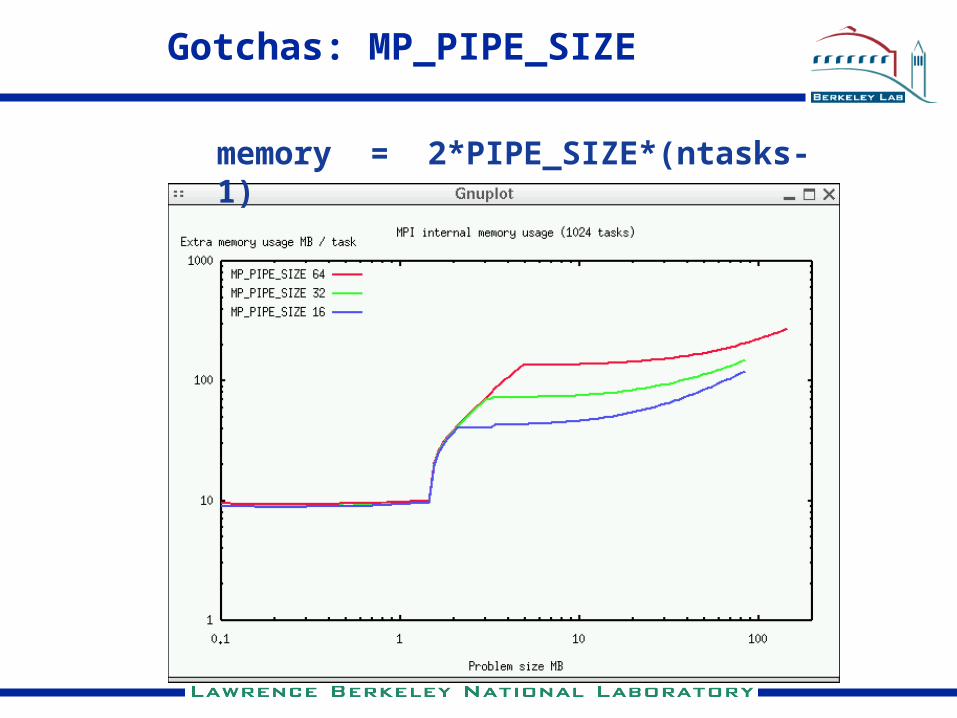
Gotchas: MP_PIPE_SIZE
memory = 2*PIPE_SIZE*(ntasks-1)
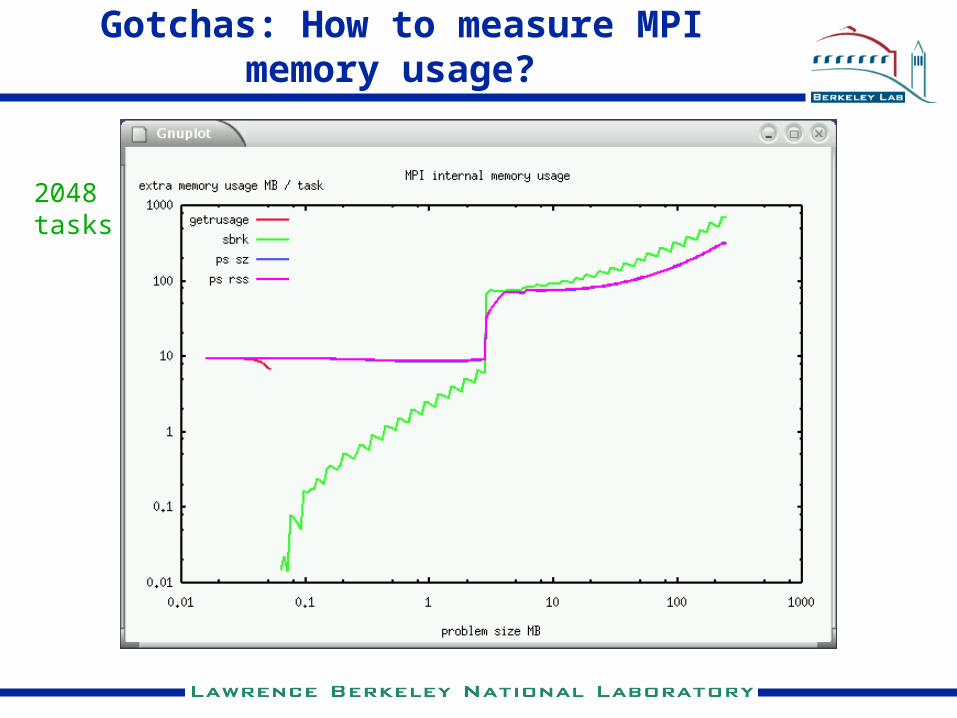
Gotchas: How to measure MPI memory usage?
2048tasks

Gotchas: MP_LABELIO, phost
• LL’s hostlist environment variable breaks for large jobs
• Run NERSC tool /usr/common/usg/bin/phost prior to your parallel program to map machine names to POE tasks
– MPI and LAPI versions available– Hostslists are useful for large runs (I/O perf, failure)
• Labeled I/O will let you know which task generated the message “segmentation fault” , gave wrong answer, etc.
export MP_LABELIO=yes
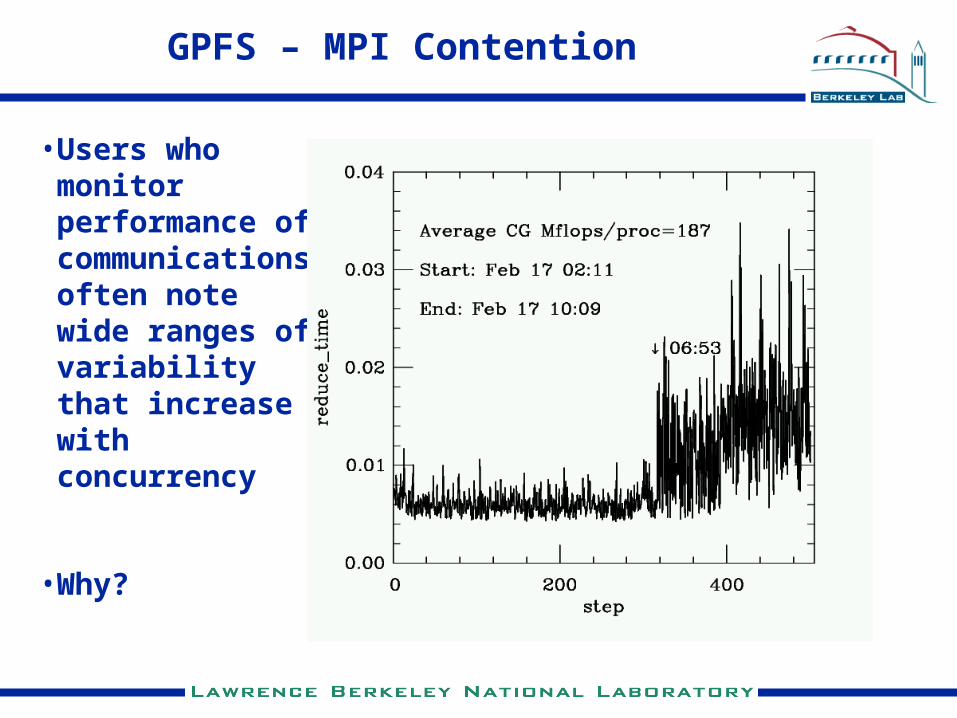
GPFS – MPI Contention
• Users who monitor performance of communications often note wide ranges of variability that increase with concurrency
• Why?

GPFS – MPI Contention : simple spectrum
• Regularity points to identifiable cause
• Detective work like this is laborious, requires both admin/app skills and resources
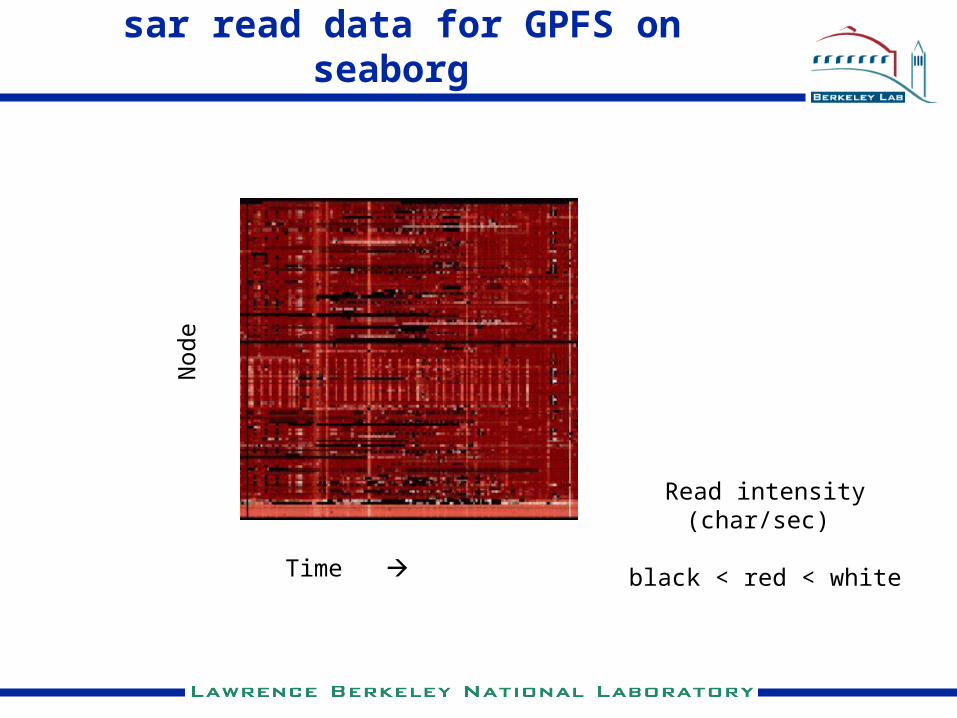
sar read data for GPFS on seaborg
Time
Nod
e
Read intensity (char/sec)
black < red < white

Contention at the NSB layer?
•Looking into how to delve deeper into this •Different networks for Disk and MPI (BG/L)

Parallel Enviroment 4.1
• New MPI library is available.
• Not based on MPCI PIPES layer but rather over LAPI. Solves PIPEs memory issues.
• Latency is currently higher that PE3.2, IBM is working on this
• Several improvments to MPI Collectives
• Though LAPI uses threads, your code need not
– A pass through library for non “_r” is provided

PE 4.1 : usage
• Simply do “module load USG pe”– No need to recompile– This is still beta software (but close to release)
• We turn off threading by default for performance reasons. To get it back, e.g. to use certain MPI-2 features, unset MP_SINGLE_THREAD
• Best way to estimate impact on your code is to try it

PE 4.1 : preliminary performance data