intel® xeon phiâ„¢ product family - an overview - scicomp
TRANSCRIPT

S c i c o m P 2 0 1 3 Tu t o r i a l
Intel® Xeon Phi™ Product Family Architecture Overview
Klaus-Dieter Oertel, May 28th 2013
Software and Services Group Intel Corporation

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Intel Architecture Multicore and Manycore More cores. Wider vectors. Co-Processors.
Intel® Xeon®
processor
64-bit
Intel Xeon
processor
5100 series
Intel Xeon processor
5500 series
Intel Xeon processor
5600 series
Intel Xeon
processor
E5 Product Family
Intel Xeon
processor code name
Ivy Bridge
Intel Xeon
processor code name
Haswell
Intel® Xeon Phi™
Coprocessor
Core(s) 1 2 4 6 8 10 To be determined
61
244 Threads 2 2 8 12 16 20
Intel® Xeon Phi™ Coprocessor extends established CPU architecture and programming concepts to highly parallel applications
Images do not reflect actual die sizes. Actual production die may differ from images.
2

© 2013, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others.
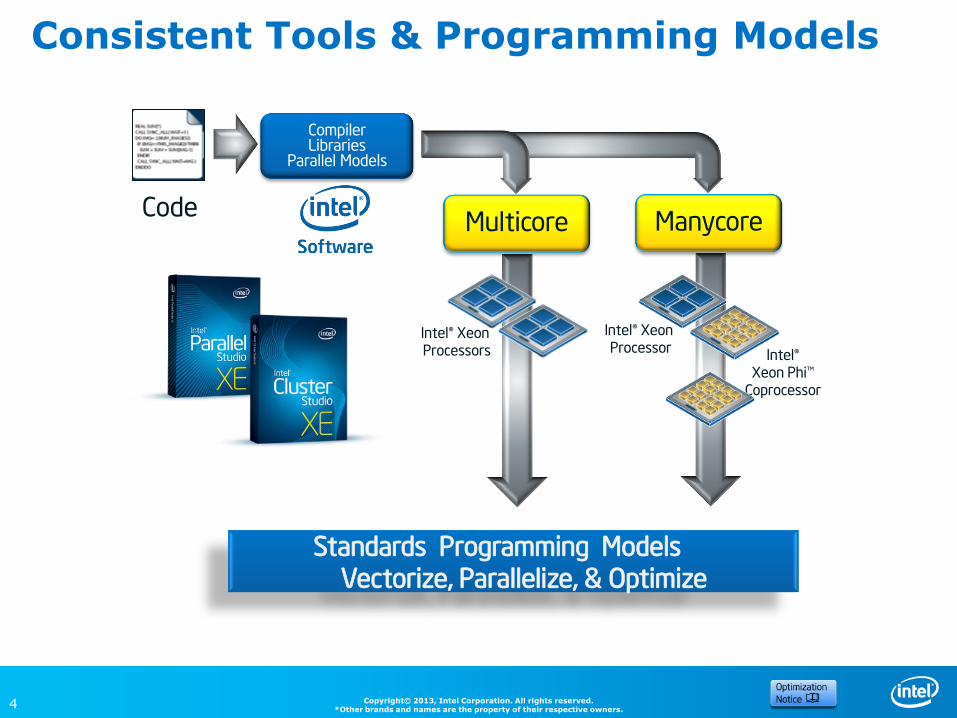
vision span from few cores to many cores with consistent models, languages, tools, and techniques
3
Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Consistent Tools & Programming Models
Code
Compiler Libraries
Parallel Models
Manycore
Intel® Xeon Processor
Intel® Xeon Phi™
Coprocessor
Multicore
Intel® Xeon Processors
4
Standards Programming Models Vectorize, Parallelize, & Optimize

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Each Intel® Xeon Phi™ Coprocessor core is a fully functional multi-thread execution unit
Scalar unit based on Intel® Pentium® processor family
• Two pipelines (U and V)
– Dual-issue on scalar instructions
• Scalar pipeline 1 clock latency
• 64-bit data path
4 hardware threads per core
• “Smart” round-robin scheduling
– Prefetch buffers 2 instr-bundles / context
– Next ready context selected in order
5
Ring
Scalar
Registers
Vector
Registers
512K L2 Cache
32K L1 I-cache 32K L1 D-cache
Vector Unit
Scalar Unit
U V
Instruction Decoder

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Each Intel® Xeon Phi™ Coprocessor core is a fully functional multi-thread vector unit
A new vector unit: 512 bits wide!
• 32 512-bit vector registers per context
– Each holds 16 floats or 8 doubles
– ALUs support int32/float32 operations, float64 arithmetic, int64 logic ops
– Ternary ops including Fused-Multiply-Add
– Broadcast/swizzle support
– 8 vector mask registers for per lane conditional operations
– Most ops: 4-cycle latency, 1-cycle thrput – Matches 4-cycle round robin of integer unit
– Mostly IEEE 754 2008 compliant – Not supported: MMX™ technology,
Streaming SIMD Extensions (SSE), Intel® Advanced Vector Extensions (Intel AVX)
7
Ring
Scalar
Registers
Vector
Registers
512K L2 Cache
32K L1 I-cache 32K L1 D-cache
Vector Unit
Scalar Unit
U V
Instruction Decoder

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
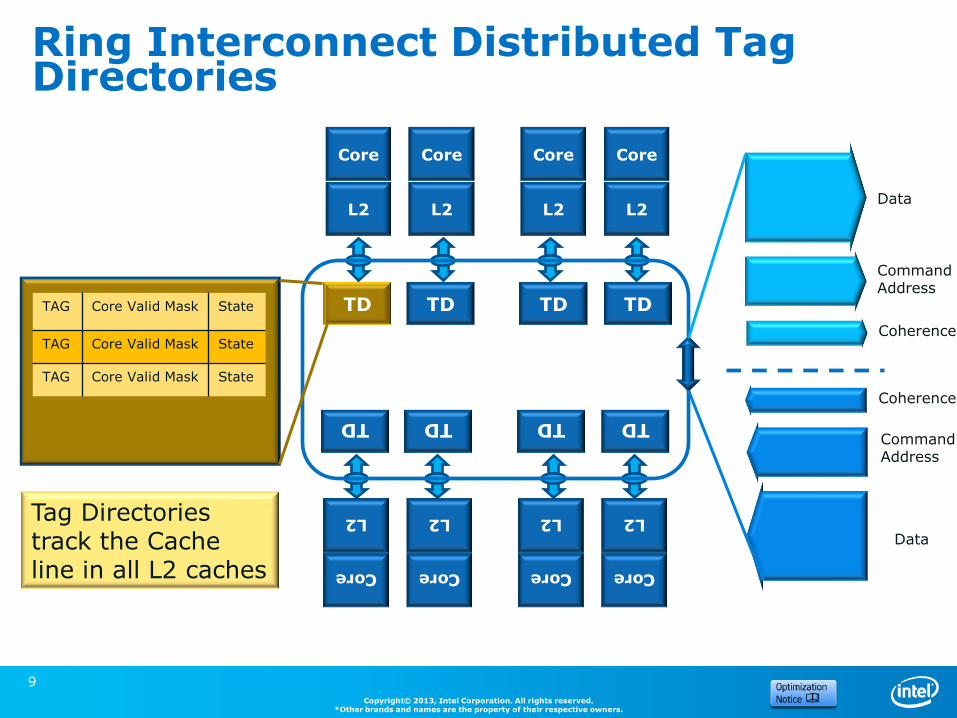
Individual cores are tied together via fully coherent caches into a bidirectional ring
8
GDDR
GDDR
GDDR
GDDR
PCIexp
L1 32K I/D-cache per core
1 cycle access latency 3 cycle addr-gen interlock l. 8-way associativity 64-byte cache line ~38 concurrent access/core
L2 512K cache per core
11 cycle raw latency 8-way associativity 64-byte cache line Streaming HW prefetcher ~38 concurrent access/core
GDDR5 Memory
16 32-bit channels - Up to 5.5 GT/sec 8 GB - 300ns access
Bidirectional ring 200 GB/sec Distributed Tag Directory (DTD) reduces ring snoop traffic Gen2x16 PCI Express* 64-256 byte packets peer-to-peer R/W
Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Ring Interconnect Distributed Tag Directories
9
Core
L2
Core
L2
Core
L2
Core
L2
TD TD TD TD
Core
L2
Core
L2
Core
L2
Core
L2
TD TD TD TD TAG Core Valid Mask State
TAG Core Valid Mask State
TAG Core Valid Mask State
Tag Directories track the Cache line in all L2 caches
Data
Data
Command Address
Coherence
Command Address
Coherence

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Vector Processing Unit and Intel® IMCI
Vector Processing Unit Execute Intel® IMCI
• Intel® Initial Many Core Instructions
512-bit Vector Execution Engine
• 16 lanes of 32-bit single precision and integer operations
• 8 lanes of 64-bit double precision and integer operations
• 32 512-bit general purpose vector registers in 4 thread
• 8 16-bit mask registers in 4 thread for predicated execution
Read/Write
• One vector length (512-bits) per cycle from/to Vector Registers
• One operand can be from the memory free
IEEE 754 Standard Compliance
• 4 rounding Model, even, 0, +∞, -∞
• Hardware support for SP/DP denormal handling
• Sets status register VXCSR flags but not hardware traps
10

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Examples of Intel® IMCI
Ternary Operands
• vop ::: zmm1, zmm2, zmm3 zmm1 = zmm2:::vop:::zmm3
• vop ::: zmm1, zmm2, [ptr] zmm1 = zmm2::: vop:::MEM[ptr]
Fused operation Multiply-Add, Multiply-subtract
• vfmadd132ps::: zmm1, zmm2, zmm3 zmm1=zmm1Xzmm3+zmm2
• vfmadd213ps::: zmm1, zmm2, zmm3 zmm1=zmm2Xzmm1+zmm3
• vfmadd231ps::: zmm1, zmm2, zmm3 zmm1=zmm2Xzmm3+zmm1
• Standard IEEE 754-2008R 0.5 ulps not 1 upls as two operations
Prefetching
• Memory Prefetching minimize the likelihood of L1, L2 cache misses
• Intel® Xeon Phi Coprocessor has a hardware prefetcher
• L1 prefetch: vprefetch1::: ptr, hint
• L2 prefetch: vprefetch2::: ptr, hint
11

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
12
D2 E VC1 VC2 V1 V2 V3 V4
D2 E VC1 VC2 V1-V4 WB
D1 D2 E PPF PF D0
Core extension Vector Processing Unit
Vector ALUs 16 X 32-bit Wide 8 X 64-bit Wide
Fuse Multiply Add
LD
EMU
ST
VPU RF
3R,1W
Scatter Gather
DEC
Mask RF
WB
12

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
EMU - Extended Math Unit
Single Precision Transcendental function
Minimax quadratic polynomial approximation
Directly implement 4 Elementary functions
• vrcp23ps v1 {k1}, v0 // Reciprocal
• vrsqrt23ps v1 {k1}, v0 // Reciprocal square root
• vlog223ps v1 {k1}, v0 // Logarithmic
• vexp223ps v1 {k1}, v2 // Exponential
Benefit other Derived Functions
• pow(x,y), sqrt(), div(), ln()
13
Function name Latency Throughput
exp2() 8 2
log2() 4 1
rcp() 4 1
rsqrt() 4 1
sqrt() 8 2
pow() 16 4
div() 8 2
ln() 8 2

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Synthetic Benchmark Summary
640
1,729
1,860
0
500
1000
1500
2000
E5-2670
Baseline
(2x 2.6GHz, 8C,
115W)
5110P
(60C,
1.053GHz, 225W)
SE10P
(61C, 1.1GHz,
300W)
SGEMM (GF/s)
Up to 2.9X
309
833
883
0
200
400
600
800
1000
E5-2670
Baseline
(2x 2.6GHz, 8C,
115W)
5110P
(60C,
1.053GHz, 225W)
SE10P
(61C, 1.1GHz,
300W)
DGEMM (GF/s)
303
722
803
0
200
400
600
800
1000
E5-2670
Baseline
(2x 2.7GHz, 8C,
115W)
5110P
(60C,
1.053GHz, 225W)
SE10P
(61C, 1.1GHz,
300W)
SMP Linpack (GF/s)
80
159
174
0
50
100
150
200
E5-2670
Baseline
(2x 2.6GHz, 8C,
115W)
5110P
(60C,
1.053GHz, 225W)
SE10P
(61C, 1.1GHz,
300W)
STREAM Triad (GB/s)
Up to 2.8X Up to 2.6X Up to 2.2X Higher is Better Higher is Better Higher is Better Higher is Better
85%
Eff
icie
nt
86%
Eff
icie
nt
82%
Eff
icie
nt
82%
Eff
icie
nt
71%
Eff
icie
nt
75%
Eff
icie
nt
ECC O
n
ECC O
n
Coprocessor results: Benchmark run 100% on coprocessor, no help from Intel® Xeon® processor host (aka native)
14

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
http://software.intel.com/mic-developer
15

Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Intel® Xeon Phi™ Coprocessor High Performance Programming, Jim Jeffers, James Reinders, (c) 2013, publisher: Morgan Kaufmann
It all comes down to PARALLEL PROGRAMMING! (applicable to processors and Intel® Xeon Phi™coprocessors Forward, Preface Chapters: 1. Introduction 2. High Performance Closed Track
Test Drive! 3. A Friendly Country Road Race 4. Driving Around Town:
Optimizing A Real-World Code Example
5. Lots of Data (Vectors) 6. Lots of Tasks (not Threads) 7. Offload 8. Coprocessor Architecture 9. Coprocessor System Software 10. Linux on the Coprocessor 11. Math Library 12. MPI 13. Profiling and Timing 14. Summary, Glossary, Index
Available NOW
This book belongs on the bookshelf of every HPC
professional. Not only does it successfully and accessibly teach
us how to use and obtain high performance on the Intel MIC architecture, it is about much
more than that. It takes us back to the universal fundamentals of
high-performance computing including how to think and reason
about the performance of algorithms mapped to modern architectures, and it puts into
your hands powerful tools that will be useful for years to come.
—Robert J. Harrison Institute for Advanced
Computational Science, Stony Brook University
Learn more about this book:
lotsofcores.com
“© 2013, James Reinders & Jim Jeffers, book image used with permission
16


Copyright© 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
INFORMATION IN THIS DOCUMENT IS PROVIDED “AS IS”. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO THIS INFORMATION INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Copyright © , Intel Corporation. All rights reserved. Intel, the Intel logo, Xeon, Xeon Phi, Core, VTune, and Cilk are trademarks of Intel Corporation in the U.S. and other countries.
Optimization Notice
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Notice revision #20110804
Legal Disclaimer & Optimization Notice
Copyright© 2012, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
18
5/28/2013