productivity measurements applied to ten english prefixes: a
TRANSCRIPT

Department of English
Bachelor Degree Project
English Linguistics
Spring 2012
Supervisor: Alan McMillion
Productivity
Measurements Applied
to Ten English Prefixes A comparison of different measures of
morphological productivity based on ten
prefixes in English
Linnéa Joandi

Productivity Measurements
Applied to Ten English Prefixes A comparison of different measures of morphological productivity
based on ten English prefixes
Linnéa Joandi
Abstract
Morphological productivity is difficult to define and describe. Nevertheless have several
measures been proposed by scholars, in order to quantify this notion. This paper
investigates ten common English prefixes with meanings related to degree or size. The
aims of the study are (1) to review several measures of morphological productivity, (2)
via a sample of corpus occurrences of ten prefixes, to calculate productivity figures
using five different measures of productivity, and (3), perhaps most importantly, to
discuss the differences and similarities of the five measures. The results suggest that
while several of the measures are quite similar (e.g. type frequency and hapax legomena
frequency), other measures are different (e.g. 'Productivity in the narrow sense'). While
three of the measures could be said to provide information concerning past or 'factual'
productivity, two of the measures seem instead to indicate an aspect of productivity that
is referred to as potential productivity.
Keywords
Morphological productivity, word-formation, prefixation, type frequency, token
frequency, hapax legomena, 'Productivity in the narrow sense'

Contents
1. Introduction ................................................................................1
2. Background .................................................................................2
2.1 Theoretical issues ..........................................................................2
2.1.1 Definitions of morphological productivity ...........................................2
2.1.2 Others issues concerning the notion of productivity ............................3
2.1.3 Approaches to the issues concerning the notion of productivity ............4
2.2 Methodological issues ...................................................................4
2.2.1 The corpus ...................................................................................4
2.2.2 The selection criteria .....................................................................5
2.2.3 The data ......................................................................................5
2.3 Notions ......................................................................................5
2.3.1 Type frequency ............................................................................5
2.3.2 Token frequency ..........................................................................6
2.3.3 Hapax legomena ..........................................................................6
2.3.4 Neologisms .................................................................................7
2.3.5 'Productivity in the narrow sense' ...................................................7
2.3.6 Method Q – type frequency related to token frequency ......................8
2.4 Research questions .....................................................................8
3. Methodology ...............................................................................8
3.1 The data and the BNC ..................................................................9
3.1.1 The BNC .....................................................................................9
3.1.2 The data .....................................................................................9
3.2 The prefixes ...............................................................................9
3.3 Selection criteria ..........................................................................12
4. Results .......................................................................................12
4.1 Results of type frequency ..............................................................12
4.2 Results of token frequency .............................................................14
4.3 Results of hapax frequency ............................................................15
4.4 Results of 'Productivity in the narrow sense' .....................................15
4.5 Method Q – Type frequency related to token frequency ......................16
4.6 Correlations .................................................................................17
4.7 Summary of results .......................................................................17
5. Discussion ...................................................................................18
5.1 Sizing up the productivity measures ................................................18
5.2 Measurement correlations ...............................................................20
5.3 Hapaxes´ importance concerning productivity ...................................20
5.4 Conclusion ....................................................................................20
References ......................................................................................22
Appendix A ......................................................................................24

Stockholms universitet
106 91 Stockholm
Telefon: 08–16 20 00
www.su.se

1
1. Introduction
Word-formation, also referred to as word-coinage or just coinage, has gone from being a
neglected area of linguistic research to becoming a field that has received a lot of attention
in the recent decades (Bauer, 1983; Bauer, 2005; Fernández-Domínguez et al., 2007).
Word-formation is the process by which new words are constructed from smaller elements
(affixes, other words, or morphemes) (Plag, 2003).
Many scholars have recently realized the value of morphological and word-formation
studies because of the general relevance to the broad notion of linguistic productivity
(Bauer, 1983). This can especially be seen by the numerous studies that have been
published within this area of linguistic research in the recent decades (see for example the
list of recent work mentioned in Fernández- Domínguez et al., 2007). Furthermore, this
study has chosen to focus on prefixes, and not suffixes, because they have received less
attention in morphological studies so far (Lehrer, 1995).
Many word-formation studies deal with the concept of morphological productivity, in
short, also referred to as productivity. Productivity can be viewed as the probability of
morphological-rules or affixes to be used in the production or comprehension of new word-
forms. It refers to “the property of an affix or a morphological process [word-formation
rule,] to give rise to new [word] formations” (McMahon, 2006: 122; Bauer, 1983: 18; Plag,
2003: 44). A word-formation rule or affix is considered productive if it has the ability to
coin new words by other word-formation processes. In contrast, if it is unproductive, new
coinages will not (in general) take place (Plag, 2006). As will be seen below, the concept of
morphological productivity is not unproblematic and there are several issues, both
theoretical and methodological, that remain unresolved.
Morphological productivity still remains an important notion however, despite the
problems, because it is widely used in linguistics and because it not only concerns
morphology, but also syntax, lexicology and phonology. While there seems to be a
consensus concerning the importance of productivity studies (Bauer, 1983), the current
research situation has been described as being “in a rather poor state” (Bauer, 2001: 25).
The study described below investigates several productivity measures that have been
encountered in the literature and that, additionally, have been applied on the ten English
degree/size prefixes in this study. The British National Corpus (BNC) has been used in
order to collect data for these prefixes. This paper also considers several research articles
within the area of morphological productivity as well as other relevant literature (see for
example Bauer, 2001; Bauer, 1983; Fernández- Domínguez et al., 2007; McMahon, 2006
and Plag, 2003).

2
The broad aims of this paper are the following:
1. Analyse the notion of morphological productivity.
2. Investigate the morphological productivity of ten English prefixes by using several
measures that are frequently encountered in the relevant literature.
3. Compare and evaluate these morphological productivity measures based on the results and
methodology of this study.
This study is qualitative in nature. The general aim is to explore notions and measurements
of morphological productivity. Although a sample of ten prefixes is selected from searches
in the British National Corpus for estimating quantities, the counts are meant to be
indicative of the usefulness of various measures, not to quantitatively study the occurrence
of types and tokens of the prefixed items.
Section 2 of this paper will (1) present some background information concerning
morphological productivity, (2) discuss different definitions of relevant morphological
concepts as well as (3) discuss various issues that affect both the theoretical and
methodological study of productivity. Section 3 reviews the methodology applied in this
study while section 4 presents the results. Section 5 will discuss the results and offer some
conclusions.
2. Background
Bauer points out that “there is, at the moment, no single ´theory of word-formation´, nor
even agreement on the kind of data that is relevant for the construction of such a theory”
(Bauer, 1983: 1), and this, apparently, continues to be the case (Bauer, 2001; Bauer, 2003;
van Marle, 1992).
van Marle expresses a ‘common sense’ view of morphological productivity where it is
simply a property of morphological patterns that gives rise to new words, although he
recognizes that this description is in need of further definition (van Marle, 1992).
Consequently, it seems reasonable to address some of these definitional problems before
investigating specific measures of morphological productivity.
2.1 Theoretical issues
2.1.1 Definitions of morphological productivity
The term morphological productivity, often referred to as productivity in morphological
research, was defined by Hockett (1958) as a “property of language which allows us to say
things which have never been said before” (cited in Bauer, 2001, p. 1). Chomsky (1965)
later relates to productivity as the creativity of a language (as cited in Bauer, 2001, p. 1).
Shultink (1961) views productivity as the possibility for users of a language to
unintentionally produce a (more or less) uncountable number of formations (cited in Bauer,
2001, p. 1). His definition is thus somewhat similar to Hockett´s since they both stress the

3
potential of a language to coin new words. Bauer (1983) claims that a productive process is
one that can be used synchronically in the production of new word-forms. Bauer (2001)
goes on to say that while there may be features of morphological processes that allow for
new coinages, to be productive, these features must give rise to some degree of repetition in
the speech community. Plag (2006) in contrast, defines productivity as a feature of an affix
(rather than one of a language as Hockett proposes), or one of a morphological process
(Bauer, 2001). He claims that productivity is a property of the affix or a morphological
process that is used in order to produce "[word-] formations on a systemic basis” (Plag,
2003: 44; Plag, 2006: 122). There seems to be considerable agreement on this general
definition (Plag, 2003; Plag, 2004; Bauer, 1983; Plag, 2006). Yet another definition of
morphological productivity is that of Baayen which says that “the term 'morphological
productivity' is generally used informally to refer to the number of words [the type
frequency of an affix] in use in a language community that a rule describes” (Baayen,
2012). The basic intuition underlying the term is perhaps reflected in Plag et al. (1999)
where it is claimed that "productivity is generally loosely defined as the possibility to coin
new complex words according to the word formation rules of a given language" (p. 10).
Definitions of morphological productivity are thus based on several different constructs:
1. A definition based on a language's potential to coin new words (see Hocket´s definition as well as
Chomsky´s term creativity cited in Bauer, 2001, p. 1).
2. A definition based on the potential of language users to unintentionally coin new words (Shultink
(1961) cited in Bauer, 2001 p. 1).
3. A definition based on the availability of processes at the time of coinage, i.e. processes that can
produce new words when necessary (Bauer, 1983).
4. A definition based on the assumption that it is a feature of morphological processes (and not a whole
language nor an affix) that allows coinage (Bauer, 2001).
5. A definition based on the assumption that it is a feature of affixes, and not morphological processes
that enables the morphological productivity (Plag, 2002).
6. A definition based on the assumption that it is the features of affixes or morphological rules that
enables the morphological productivity (Plag, 2006).
7. A type-frequency based definition that presupposes that the words are in use in the language
community at the time productivity is estimated in order to be considered productive (Baayen,
2012).
2.1.2 Other issues concerning the notion of productivity
While the notion of productivity is struggled with (Aronoff, 1976; Bauer, 2001; Bauer,
2005; van Marle, 1991), there are three additional issues on which there is no consensus
that need to be addressed, namely:
1. What it is that is productive or unproductive; whether it is a particular affixes, morphological
processes or words themselves (Bauer, 2001)
2. Whether productivity is an (a) all-or-nothing process, (b) whether it can be analysed as one of three
different degrees of productivity (non-productive, intermediate and fully productive (Bauer, 2001;
Ljung, 2003)) or (c) whether it can range along a scale (Bauer, 2001).
3. When an affix, word or morphological-rule is to be considered productive. An affix could be said to

4
have been productive in the past, to be currently productive, or to be potentially productive (see
Bauer, 2005 or section 2.1.3 step 3 below where the different cases are explained and exemplified).
According to Plag (2006), the second problem stated here above is one of the main issues
concerning the nature of productivity. It is concerned with whether productivity is a
qualitative or a quantitative notion. The qualitative approach assumes that affixes or
processes either have the feature of productivity, or that they do not. The quantitative
aspect, on the other hand, adopts the approach that productivity is a gradient whereby
morphological processes (or affixes) can be more or less productive than others, and that
those that are not productive at all, or those that are very productive, only mark the
beginning and the end of a productivity scale.
2.1.3 Approaches to the issues concerning the notion of productivity
The above mentioned issues make it necessary to adopt certain assumptions in order to
enable a corpus-based study of the productivity of affixes. For the study described below,
the following assumptions are made:
1. What it is that is productive: That morphological productivity is a property of morphological
processes or affixes, which can give rise to new words (Plag, 2003; Plag, 2006; Bauer, 1983; Adams
(1973) cited in Plag, 2006, p. 122; and Spencer (1991) cited in Plag, 2006, p. 122). It is thus not
words or languages as a whole that have the property of being productive or unproductive.
2. Whether it is an all-or-nothing feature, a three-step scale, or a continuous scalar: In agreement with
Bauer (2005), it will be assumed that morphological productivity ranges from unproductive to
productive on a continuous scale.
3. When an affix or morphological process is considered to be productive: It is assumed below that
whether (and when) an affix or process is productive will depend on the measurements used, and the
kinds of productivity they consider (either past, current or potential productivity), this is further
discussed below in section 5. The different time aspects of productivity can be exemplified by the
following affixes:
The suffixes -ter and -th (laughter, length) were productive in the past, but are no longer considered
to be productive as they are not used in coinages of new words (Plag, 2006).
The suffix -ness (indecisiveness) is currently productive because it is used in the production of new
word-forms (although it has not been as productive in the past) (Plag, 2006).
The prefix over- has been productive (over-empty) and is currently productive (over-administer,
over-charged). Moreover, it is also potentially productive according to measures such as
'Productivity in the narrow sense' for example (see section 2.3.5).
2.2 Methodological issues
2.2.1 The corpus
The current study makes use of the British National Corpus (BNC), which is a general
corpus containing a representative language sample of British-English from the late 1980s
and early 1990s. Clearly, this corpus cannot be the bases of a diachronic study of
productivity, but should be adequate for synchronic and potential productivity studies.
Historical corpora (e.g. the Oxford English Dictionary (OED)) or genre-specific corpora
would of course be more useful for measures of diachronic productivity (Plag, 2006; Plag
et al., 1999).

5
2.2.2 The selection criteria
An important issue in word formation studies is exactly what is to count as an example of
the relevant category. In some previous studies, criteria for inclusion/exclusion of types or
tokens have not been stated explicitly. Bauer (2001), for example, writes about calculating
the productivity of the suffix -ment, and says that "when irrelevant words have been
deleted, this leaves 1,110 words containing the affix -ment" without giving any further
specification of what would be considered irrelevant (p. 8). Such lack of explicitness
makes replication and other studies difficult. In the methods section below, this issue is
further discussed and the selection criteria for this study are stated explicitly.
2.2.3 The data
It is generally accepted that different genres show different degrees of productivity of
different affixes (Plag et al., 1999; Plag, 2002, 2006; Baayen & Renouf, 1996). Plag et al.
(1999) among others stress the importance of different genres in morphological
productivity studies and claims that some texts have a higher frequency of certain affixes
than others. For example, derivational affixes have been shown to be more productive in
written than in spoken language (Plag, 2006).
The data used for the current study will be assumed to apply quite generally to current
British English since the BNC is considered a balanced and general corpus (Plag, 2002).
2.3 Notions
2.3.1 Type frequency
Type frequency is considered to be the frequency of different words, where 'words' refers
to what is often called lexemes (i.e. abstract words disregarding inflectional variation). Plag
(2006) writes that word types are simply different words (presumably, he means lexemes).
This rough definition of word-type is not without problems. For affixes such as super-,
arch- and re-, one would like to know whether items such as names (e.g. Supermec), loan
words (e.g. architecto), hyphenated items (e.g. superstars-in-the-making), and conversion
forms (e.g. rebound as noun or verb) should be included as word types in type-frequency
counts or not. Such items are given as lemmas in the Lancaster interface of the BNC.
Additionally, more precise definitions or a set of selection criteria would be helpful for
anyone carrying out studies on such lemmas.
Another issue concerning types is that of combined- and lexicalized forms. While a
particular word may have been historically a combined form (e.g. respond), it may no
longer be processed as one, but might rather be processed as a single, 'lexicalixed', item.
Thus, historically, we would have a prefix+stem item word, but psycholinguistically we
might have a single item. Even though there are often pronunciation changes that
accompany lexicalization (compare rebound with respond for example), it might be
difficult to determine at what point a word form becomes lexicalized (see e.g. Hay &
Baayen, 2001). A pronunciation change-check has nevertheless been applied to the lemmas
in this study in order to spot this kind of changes (see section 2.3 and 3.3 for explanation).

6
Another issue concerning type frequency (as well as token frequency) is that some
researchers claim that it is only indirectly related to productivity. The ground for this claim
is that some affixes, for example the suffix -ment, has a “high” type frequency without
being used in current word-coinage (Lehnert (1971) cited in Bauer, 2001, p. 48). In the
present-day English corpus The Barnhart Dictionary of new English, only one new word is
listed (Englishment) (Bauer, 2001). Additionally, Bauer (2001) and Plag (2002, 2006) state
that type frequency is rather a result of past, rather than present, productivity. Certainly, if
productivity is only looked at from a synchronic point of view and a suffix like -ment is not
used in the production of new words, then the underlying word-formation processes that
handle the suffixation should be considered unproductive. As Bauer and Plag claim that the
type frequency is the result of past productivity, one way of approaching this difficulty is
simply to view productivity from a more diachronic point of view (Bauer, 2001; Plag,
2002).
2.3.2 Token frequency
Token frequency refers to the number of times a word form (or lexeme) occurs in a text or
corpus. In general, a word with a high token frequency indicates that the word is more
commonly used than a word with a low token frequency and is therefore considered to be
more productive (Fernandez-Dominguez et al., 2007; Hay & Baayen 2001). The problems
mentioned above concerning word types certainly apply equally to the selection of tokens
as well, i.e. what is to be included as a token of a particular type (names, loans and/or
expressions). Token frequency, in similarity with type frequency, measures past
productivity.
2.3.3 Hapax legomena
Hapax legomena or hapaxes, as they are often referred to, are forms that only occur once in
the corpus (Bauer, 2005; Plag, 2006). They have a type frequency, as well as a token
frequency, of one and are considered to estimate prefixes current productivity (Plag, 2006).
The number of hapaxes for a particular affix is an important measurement of its
productivity on the grounds that new words will be rare, or newly coined, and consequently
will only occur with a very low frequency, often once (Plag et al., 1999). Another reason is
that many hapaxes of a given affix may indicate many neologisms, and many neologisms in
turn indicate high productivity of the affix or its morphological process. The proportion of
neologisms would therefore be an indication of the likelihood of meeting a newly coined
word (Fernandez-Dominguez et al., 2007; Plag, 2006; Lehrer, 1995; Bauer, 1983; Plag et
al., 1999). The number of hapaxes is thus considered to be an important measurement for
estimating morphological productivity (Plag, 2006; Plag et al., 1999; Plag, 2003; Baayen
and Renouf, (1997) cited in Plag et al., 1999, p. 12).
A large number of hapaxes implies what Plag (1999) and Bauer (2001) refer to as
availability, i.e. that a process can be used in order to produce new words. A word-
formation rule is considered to be productive (available) if the morphological processes,
concerning a given affix, result in many low-frequency words (such as hapaxes) and a low

7
number of high-frequency words (Fernandez-Dominguez et al., 2007, Baayen and Renouf
(1996) cited in Plag et al., 1999, p. 12; Plag, 2003; Plag, 2006). We can subsequently
reason that the larger the number of hapaxes is in relation to the token frequency, the
greater the productivity of that affix (Plag, 2003; Plag, 2006).
One problem with hapax legomena is that there are several definitions of the notion in the
literature (Fernandez-Dominguez et al., 2007). An additional problem is that hapaxes vary
with corpora, whether it is genre-specific or general, and corpus size (Plag et al., 1999;
Plag, 2003; Plag, 2006). As the corpus size increases, words that were hapaxes in a small
corpus become words with a higher token frequency in a larger corpus, i.e. the set of
hapaxes changes (Plag, 2006; Plag, 2003). Despite this, hapaxes in this study are looked at
in a general sense, referring to lemmas with a token frequency of one that may or may not
appear in dictionaries.
2.3.4 Neologism
Another frequency model for determining the current or contemporary productivity of an
affix is the number of newly coined words in a given period of time, the so called
neologisms (Plag, 2006; Plag, 2003; Lehrer, 1995; Bauer, 1983). A hapax legomena may
be an occurrence of a low frequency item that happens to only appear once in a corpus, a
coinage, or a neologism. Tests for contemporary neologisms would normally exclude items
that occur in dictionaries or occur regularly in certain genres.
With a sufficiently large corpus, the proportion of neologism among the hapax items
should increase so that the number of hapaxes can be used as an estimation of the number
of neologisms, and subsequently of the productivity of an affix. The hapax legomena are, in
the study below, not scrutinized for whether they are neologisms or not.
2.3.5 'Productivity in the narrow sense'
As mentioned above, the number of hapaxes is considered to be a measure of productivity,
the more hapaxes of a specific affix there are, the more productive is the prefix considered
to be (Fernandez-Dominguez et al., 2007; Plag, 2006, 2002; Plag et al., 1999; Baayen &
Renouf, 1996). If the number of hapaxes is related to the overall token frequency of all the
types with a particular affix, the resulting quotient will vary positively with the number of
hapaxes and negatively with the token frequency (van Marle, 1992). This quotient (P) can
be viewed as a measure of the affix´s likelihood to create new words and to, thus, be
productive1. Plag (2006) credits Baayen with this measure that is referred to as
'Productivity in the narrow sense':
P = hapax frequency / token frequency
1 In the limiting case where the hapax frequency equals the token frequency, the quotient of 1 should not be
interpreted as 'certainty' in any sense.

8
Since the hapax frequency depends on the corpus, its size and genres (see section 2.3.3
above), the P measurement will be highly corpus specific. Consequently, this measure is
difficult to compare across corpora. Nonetheless, this measure will be considered in the
study described below where (only) the BNC has been used.
2.3.6 Method Q - Type frequency related to token frequency
Chitashvili & Baayen (1993) (cited in Plag et al., 1999, p. 11) are credited for describing
the situation in which the number of hapaxes will approximate half of the observed
vocabulary size in a “sufficiently large” corpus. This distribution of hapaxes is referred to
as a "Large Number of Rare Events" (LNRE).
As will be seen below (see tables 4.2 and 5.1), the hapax frequency (n1) for individual
affixes seems to be roughly half the total type frequency for that affix (Vtot, type frequency
including hapax frequency). This implies that using type frequency instead of hapax
frequency in the calculation of P will produce a very similar quotient as that one of
'Productivity in the narrow sense'. One might therefore ask whether hapax frequency is
providing so much more important information than simple type frequency. Consequently,
in the study described below will a calculation using type frequency (excluding hapax
frequency (V)), instead of hapax frequency, be compared to the P values (which are based
on hapax frequency). This quotient (Q) is simply total type frequency minus hapax
frequency divided by the token frequency of a particular affix:
Q = type frequency (excluding hapax frequency) / token frequency
2.4 Research questions
Based on the discussion above, several research questions can now be formulated.
(1) How do the prefixes compare using the different measures of productivity.
(2) To what extent do the measures correlate with each other.
(3) To what extent does the occurrence of hapax legomena provide useful information
concerning productivity.
3. Methodology
This study comprises the methods described in the preceding section. The direct
measurements include type frequency, token frequency, and hapax legomena, with
'Productivity in the narrow sense' (P) and Method Q (Q) calculations based on these
measurements.

9
3.1 The data and the BNC
3.1.1 The BNC
The data used in this study is derived from the British National Corpus (BNC). The BNC is
a collection of 100 million British English words of written (90%) and spoken (10%)
language-samples from a broad range of contexts ranging from radio shows to
governmental meetings and is collected between the years 1970s-1993. This is a
monolingual, synchronic, very general corpus and is considered by Plag et al. (1999) and
Plag (2002) among others, to be a balanced corpus for use in morphological corpora-based
studies.
3.1.2 The data
The data for this study have been taken from the entire corpus, without regard to genre, text
type, or any sociolinguistic variables.
3.2 The prefixes
The prefixes used in this study were selected on the basis of meaning, viz. degree and/or
size (Ljung 2003: 70) and comprise the following: arch-, hyper-, mega-, mini-, over-, out-,
semi-, super-, ultra-, under-. Because a rigorous and minute study of each type and token
for each of the prefixes was considered beyond the scope of this project, a random sample
of 50 word types for each prefix type was carried out (see sampling procedure below). The
central aim of the sampling was to estimate the number of types, tokens and hapax
legomena that fulfilled the selection criteria (see section 3.3). The sampling procedure was
the following:
1. For each prefix, the initial list of types based on a lemma search for each prefix (using the
Lancaster interface of the BNC) was scanned for obvious typographical errors and
nonsense strings (e.g. lemmas including numbers and/or signs (out12, minister.he and
hyper.0/1) etc.). These were removed.
2. In order to get a random sample of 50 types for each prefix (see Appendix A), the list of the
remaining types (i.e. after step 1, which included both hapaxes and non-hapaxes), was
divided by 50, giving a quotient q.
3. A random number between 1 and q was then generated by using a random number table.
4. Every q-th type was included as part of the random sample. These 50 types (for each
prefix) were then checked for whether they met the selection criteria or not (see section
3.3). If an item did not meet the selection criteria, it was discounted. It should be kept in
mind that these types included both hapaxes and non-hapaxes.
5. Among the non-hapax types in the random sample (see step 4 above), the proportion of
discounted items that did not meet the selection criteria was applied to the entire set of non-
hapax types for that prefix (to what was left after typological errors and nonsense strings
were removed).
6. Among the hapaxes in the random sample (see step 4 above), the proportion of discounted
hapaxes that did not meet the selection criteria was applied to the total number of hapaxes
in the list that step 1 resulted in (for that particular affix) and was then removed.
7. The proportion of discounted sample non-hapax types was also applied to the total number

10
of tokens for a given prefix, giving an estimate of the acceptable number of tokens for that
prefix.
If, for example, prefix X had an initial type list of 110 items, and 10 typographically faulty,
then these 10 would be removed, leaving 100 items. Of these 100 types, q would be equal
to 2, in order to get a sample of 50 items (lemmas). Every second type, including hapaxes,
would then be selected. Among these 50 sample items, some would be hapax legomena,
others would have frequencies greater than 1 (and be so-called non-hapax types). These 50
items would then be scrutinized to see whether they fulfilled the selection criteria. If,
among the 50 samples, 30 were non-hapax types and 20 hapaxes, and say that 5 of the non-
hapaxes did not meet the criteria for selection, then, the total number of non-hapax types
would be reduced by 5/30. The number of tokens corresponding to the 30 types would then
be reduced by the same factor. The proportion of acceptable hapaxes was similarly
calculated, so that if, say, 5 of the 20 hapaxes did not fulfill the selection criteria, then the
total number of hapaxes was reduced by 5/20. In spite of a very large number of tokens,
types, and hapaxes, this sampling method allowed for reasonable estimates of the three
statistics.
For the prefix arch-, a rather large proportion of types and hapaxes did not meet the
selection criteria. As many as 58% of the hapaxes (n1) were discounted (compared to an
average of 10% discounted types for the other prefixes); and 63% of the rest of the types
(V) were discounted (compared to an average of 12% in the other cases). Since the total
number of hapaxes was 154, this number was reduced by 89, giving 65 as the estimate of
acceptable hapaxes. The procedure was the same for the non-hapax types leaving 55
acceptable non-hapax types. Thus, the total number of types including hapaxes (Vtot)
resulted in 120. The token frequency was calculated by excluding the same proportion of
tokens (as the one that was excluded for types), giving a rough estimate of the number of
tokens for each affix. This was 63% in the case of arch-, leaving 5464 tokens for the prefix.
The proportion of discounted items for the other nine prefixes was considerably less, as can
be seen in Table 3.1 below.
The large differences between the original number of tokens (row 12) and the revised
number of tokens (row 13) for out-, over-, and under- is due to prepositions and adverbs
with the same form as the prefix included in the list of types for the prefixes. The number
of tokens for out as a preposition, for example, is about 200,000.

11
Table 3.1 Sampling procedures applied to types, tokens and hapaxes and the 10 investigated prefixes results.
Arch- Hyper- Mega- Mini- Out- Over- Semi- Super- Ultra- Under-
1. Original number
of types 331 367 251 668 898 2122 814 1006 315 1036
2. Revised number
of types 303 358 241 622 797 2013 814 965 297 1036
3. Revised types
after hapaxes
removed
149 162 88 237 456 1054 294 433 123 519
4. Per cent of types
excluded based on
sample
63 5 17 28 25 0 0 27 10 0
5. Number of
lemmas excluded 94 8 15 66 114 0 0 116 12 0
6. Remaining
number of lemmas 55 154 73 171 342 1054 294 317 111 519
7. Original number
of hapaxes 181 204 165 429 434 1052 520 572 191 472
8. Revised number
of hapaxes 154 196 88 385 341 959 487 265 174 404
9. Per cent of
hapaxes excluded
based on sample
58 4 11 10 27 0 6 18 3 9
10. Number of
hapaxes excluded 89 8 15 39 92 0 29 48 5 36
11. Remaining
number of hapaxes 65 188 136 346 249 959 458 217 169 368
12. Original number
of tokens 18446 2889 1381 51167 264577 181924 7425 23738 2000 128024
13. Revised number
of tokens 16557 2736 1216 49885 67077 50015 6557 21495 1336 66337
14. Per cent tokens
excluded based on
type sample
63 5 17 28 25 0 0 27 10 0
15. Number of
tokens excluded 11093 136 206 13967 16769 0 0 5804 134 0
16. Remaining
number of tokens 5464 2600 1010 35918 50308 50015 6557 15691 1202 66337

12
3.3 Selection criteria
A type or hapax had to meet the criteria listed below in order to be included in the counts of
the sample:
1. Names of any kind were excluded (e.g. SuperSparc-II and SuperMax).
2. Items that were not prefix+stem words were excluded (e.g. superb, overt, minister, etc.)
3. Items where a pronunciation change was evident (indicating lexicalization) were excluded
(e.g. minister).
4. Multi-hyphenated items, lemmas with more than 2 hyphens (e.g. superstar-in-the-making),
were excluded.
5. Loan word (e.g. architecto) were excluded.
6. Misspelling were included if the intended words was clear (e.g. super-heroe (super-hero)).
While other criteria could have been applied, this set seems to conform to the practices
indicated (however vaguely) in the relevant literature. The results of the sampling
procedure and the relevant calculations (P and Q) are provided in the results section below.
4. Results Having discussed the theoretical and methodological groundwork, the results of this study
can now be presented. As previously mentioned, all the counts are based on the BNC data
and selected according to the selection criteria presented in the preceding section.
4.1 Results of type frequency
The first measurement concerns type frequency, which is calculated by counting all the
unique derivatives of a given affix (Bauer, 2001; Plag, 2006; Plag, 2003). The lemmas are
all counted once and include hapaxes, low frequency words, as well as high frequencies
items.
In general, the larger the number of types of a prefix, the more productive is the prefix
considered to be (Plag, 2003; Fernandez-Dominguez et al., 2007; Hay & Baayen 2001). A
low number of types thus indicates unproductive affixes, while a high number of types
indicate the opposite. For example, the suffix –ter has the type frequency of two as it does
not occur in any other words than laughter and slaughter in English (Bauer, 2001). This
would, for example, be considered as a less productive affix than the suffix -ness that has
2466 occurrences listed in the BNC (Plag, 2006).
As seen in Figure 4.1 below where hapaxes as well as types of a particular affix are
included in the counts (V + n1, also referred to as Vtot); arch- has the lowest number of
different derivatives listed in the BNC corpus. It should thus be considered to have the
lowest productivity of the investigated affixes according to this productivity measure.
Over- should, in contrast to arch- then, be considered as the most productive one. Under-
with less than half the type frequency of over- (887) is the second most productive affix,
the other seven prefixes range between 209 and 752 types.

13
Figure 4.1. Type frequency for ten prefixes (hapaxes included).
If the hapaxes (n1) are excluded from the type counts (Vtot – n1, leaving V), the overall
order of the prefixes is nearly the same as in the case of the total number of types (Vtot);
i.e. arch- is still the least productive, and over- the most productive (see Figure 4.2). In the
case of V, the remaining prefixes range from 73 to 519.
Figure 4.2. Type-frequencies of ten prefixes.
120
342 209
517 591
2013
752 534
280
887
0
500
1000
1500
2000
2500
arch- hyper- mega- mini- out- over- semi- super- ultra- under-
To
tal n
um
ber
of
typ
es
(V +
n1)
Prefix
Total type frequency
55
154
73
171
342
1054
294 317
111
519
0
200
400
600
800
1000
1200
arch- hyper- mega- mini- out- Over- semi- super- ultra- under-
Nu
mb
er
of
typ
es
(V
)
Prefix
Type frequency

14
4.2 Results of token frequency
The token frequency value (N) for a particular affix has been calculated by summing all the
token frequency-values listed for the prefix´s different derivatives. Token frequency is also
considered to be an indicator of productivity, i.e. the higher the token frequency, the more
productive the prefix. For example, Plag (2004: 11) gives the token frequency of the suffix
-wise as 2091, and that of -ness as 106957. He then states that -ness is considered to be the
more productive one of the two (from a token frequency point of view).
The prefix under- has the highest token frequency (66337) of the investigated prefixes and
is, therefore, considered to be the most productive prefix based on this count. Out-, over-
and mini- also have high token frequencies while mega-, ultra- and hyper- have
comparatively fewer tokens. The prefix with the smallest token frequency is mega-, with
only 1.3% as many occurrences as under- (1010 versus 66337 occurrences). Based on this
count, one can claim that under- is close to 65 times more productive than mega-.
As seen in Figure 4.3, it seems that the prefixes fall into two somewhat distinct groups;
those with relatively high token frequencies (mini-, out-, over- and under-) and those with
relatively low token frequencies (arch-, hyper-, mega-, semi-, super- and ultra).
Figure 4.3. The token frequencies of the investigated prefixes.
5464 2600 1010
35918
50308 50015
6557
15691
1202
66337
0
10000
20000
30000
40000
50000
60000
70000
arch- hyper- mega- mini- out- over- semi- super- ultra- under-
Nu
mb
er
of
token
s
(N)
Prefix
Token frequency

15
4.3 Results of hapax frequency
Hapaxes (n1) are word-forms that only occur once in the corpus. This means that they have
a token frequency of one, and that there is no variation of inflectional forms. For each
prefix, the number of hapaxes is shown in Figure 4.4.
Over-, in comparison to the other prefixes, is the prefix with the highest number of hapaxes
(959) and thus the most productive one from a hapax perspective. It is almost twise as
productive as semi- which has 458 hapaxes and is the second most productive affix, while
arch- is the least productive one.
Figures 4.1, 4.2, and 4.3 show quite similar patterning. As will be shown below and
discussed in the following section, the correlation-values for type and hapax frequency will
be high.
Figure 4.4. Hapax frequencies (n1).
4.4 Results of 'Productivity in the narrow sense'
By calculating the hapax frequency (n1) divided with the token frequency (N), we get a
statistic which could be thought of as indicating the probability of encountering new word-
formations with a specific prefix (Plag, 2006). This probability is called 'Productivity in the
narrow sense' (P). According to Plag (2006), the higher the value of P, the higher the
potential of the prefix to produce new word formations.
A high hapax freqency combined with a low token frequency results in a high value of P
indicating a high likelihood of coinability for that specific prefix. When the opposite
relation holds on the other hand (low hapax frequency and high token frequency), it is an
indication of low probability of encountering new word-formations with that particular
affix.
As can be seen in Figure 4.5, mega- and ultra- have the highest P values while out- has the
lowest.
65
188 136
346
249
959
458
217 169
368
0
200
400
600
800
1000
1200
arch- hyper- mega- mini- out- over- semi- super- ultra- under-
Nu
mb
er
of
hap
axes
(n1)
Prefix
Hapax frequency

16
Figure 4.5 The P quotient: hapax frequency divided by token frequency.
4.5 Method Q – Type frequency related to token frequency
Method Q has been calculated by dividing type frequency of a prefix (V) by the token
frequency (N). The quotient Q is hypothesized to be similar to P in the sense of being an
indicator of potential productivity. Like in the case of P will a high quotient indicate a high
potential productivity of the prefix.
As seen in Figure 4.6, the most productive prefix, based on the Q measurement, is ultra-
which is approximately eighteen times more productive than the least productive prefix
mini-. It is noticeable that Figure 4.6 is quite similar to 4.5 (P). This will be discussed in the
subsequent section.
Figure 4.6. The Q-values of ten affixes.
0,000
0,020
0,040
0,060
0,080
0,100
0,120
0,140
0,160
arch- hyper- mega- mini- out- over- semi- super- ultra- under-
P
(n1/N
)
Prefix
'Productivity in the narrow sense' (P)
0,000
0,010
0,020
0,030
0,040
0,050
0,060
0,070
0,080
0,090
0,100
arch- hyper- mega- mini- out- over- semi- super- ultra- under-
Q
(V/N
)
Prefix
Method Q (Q)

17
4.6 Correlations
The results of the five methods for calculating productivity have been presented above. In
order to get a picture of the extent to which these different methods could be measuring
similar aspects of productivity, correlation figures were calculated for the five methods (see
Table 4.1 below).
In Table 4.1, 4.3 and 5.1, V refers to type frequency (hapaxes excluded), N to token
frequency, n1 to hapax frequency, P to 'Productivity in the narrow sense' (n1/N), and Q to
Method Q (V/N). All tables, except 4.1, also include Vtot that refers to type frequency
including hapax legomena.
The table shows that type frequency (N) and hapax frequency (n1) correlate to a very high
degree (0.93). However, the highest correlation value is between 'Productivity in the
narrow sense' (P) and Method X (Q) (0.98). A high correlation indicates that there may be
common underlying processes for both calculations.
Correlation
values
N n1 P
(n1/N)
Q
(V/N)
V 0.69 0.93 -0.42 -0.51
N 0.54 -0.67 -0.70
n1 -0.30 -0.18
P (n1/N) 0.98
Table 4.1. Correlation values for the five measures.
4.7 Summary of results
Table 4.2 below presents the values for each prefix and each measure. The prefixes are
sorted in alphabetical order.
Affix Vtot
(n1+V)
V N n1 P
(n1/N)
Q
(V/N)
Arch- 120 55 5464 65 0.012 0.010
Hyper- 342 154 2600 188 0.072 0.059
Mega- 209 73 1010 136 0.135 0.072
Mini- 517 171 35918 346 0.010 0.005
Over- 591 342 50308 249 0.005 0.007
Out- 2013 1054 50015 959 0.019 0.021
Semi- 752 294 6557 458 0.070 0.045
Super- 534 317 15691 217 0.014 0.020
Ultra- 280 111 1202 169 0.141 0.092
Under- 887 519 66337 368 0.006 0.008
Table 4.2. The results of ten prefixes, calculated with five different productivity measures.

18
Table 4.3 ranks the different prefixes for each productivity measure; 1 is signifying the
highest productivity rank, and 10 the lowest (the least productive prefix).
Productivity
ranking
Vtot
(n1+V)
V N n1 P
(n1/N)
Q
(V/N)
1. over- over- under- over- mega- ultra-
2. under- under- out- semi- ultra- mega-
3. semi- out- over- under- hyper- hyper-
4. out- super- mini- mini- semi- semi-
5. super- semi- super- out- over- over-
6. mini- mini- semi- super- super- super-
7. hyper- hyper- arch- hyper- arch- arch-
8. ultra- ultra- hyper- ultra- mini- under-
9. mega- mega- ultra- mega- under- out-
10. arch- arch- mega- arch- out- mini-
Table 4.3. Ranking of prefixes for each measure.
5. Discussion
5.1 Sizing up the productivity measures
To address the first research question, we can state quite clearly that the different
productivity measurements give different results and that the ten prefixes used in this study
are often ranked quite differently by the five measures/calculations. However, as can be
seen in the tables above, although the prefixes are ranked differently by the different
measurements, some patterns can nonetheless be detected (see explanation of this in the
next paragraph). The prefix super-, however, unlike most of the other prefixes, does show
consistency across the measurements, getting a mid-range ranking for all five measures.
An interesting case is mega-, whose P and Q values give a high productivity value, while
the token frequency (N), type frequency (V) and hapax frequency (n1) give a low
productivity score (that is, compared to the other prefixes). For under-, the opposite seems
to be the case, i.e. high values for V, N and n1 but low for P and Q. The implication of such
differences suggests that P and Q, on the one hand, and the type, token, and hapax counts,
on the other hand, reflect different aspects of productivity. By themselves, type, token and
hapax measures are often regarded as reflecting factual (past or contemporary)
productivity, while P is considered to reflect what Plag calls an affix's potential or,
probability, of occurring in new word-formations (Plag, 2006). Consequently, we might
conclude that while under- has been productive in the past (with high V and N values), the
P and Q value for mega- would imply that it is potentially productive, meaning
(presumably) that it is in some sense likely to be used to coin new words.

19
Plag et al. (1999) claim that for a large corpus, the total number of hapaxes will come to
about half of the number of types for the total corpus vocabulary (the LNRE distribution).
As seen in Table 5.1 below, this estimate also seems to apply to individual prefixes. The
hapax/type quotient for the investigated prefixes in this studdy ranges from 0.42 to 0.67 of
the number of types (with a mean of 0.534 and a standard deviation of 0.099). Since this
relationship seems to be fairly consistent across the ten prefixes, it is not suprising that the
P and Q measurements are highly correlated (r = 0.98) and seem to provide the same kind
of information. Considering this similarity of information in the type and hapax counts, one
thing that could be considered surprising is that several researchers seem to argue that
hapax counts give so much more information than simple type counts (Plag, 2003; Baayen
& Renouf, 1996; Fernandez-Dominguez et al., 2007; Plag et al., 1999; Plag, 2006).
Prefix n1 Vtot n1/Vtot
1. arch- 65 120 0.54
2. hyper- 188 342 0.55
3. mega- 136 209 0.65
4. mini- 346 517 0.67
5. out- 249 591 0.42
6. over- 959 2013 0.48
7. semi- 485 752 0.61
8. super- 217 534 0.41
9. ultra- 169 280 0.60
10. under- 368 887 0.41
Table 5.1. Hapax and total type counts and their quotients.
The high correlation values of hapaxes and types, on the one hand, and P (and Q) on the
other (see Table 4.1 above), would seem to support Plag's claim that different
measurements are to be viewed as reflecting different aspects of morphological
productivity (Plag, 2006).
One aspect of hapax legomena that has not been considered in this study is the proportion
of neologism. It is assumed that the larger the corpus, the larger the proportion of
neologisms (Plag, 2006). Given a set of hapaxes, we can assume that many, but probably
not all of the items, are neologisms in some sense of the term. In order to get a better
understanding of the value of hapaxes, a careful study of neologisms would seem to be
needed.
Concerning methodological problems, it seems that most of them concern the selection
criteria that are to be used for selecting types and tokens for inclusion in the productivity
counts. The relevant literature is often vague about specifying selection criteria, and the
criteria that have been applied in past studies are very seldom explicitly stated (see section
2.2.2 above).

20
5.2 Measurement correlations
To address the second research question concerning the extent the measures correlate with
each other, we can notice, as mentioned above, that type frequency (V) and hapax
frequency (n1) correlate very highly (r=0.93). A similarly high correlation value applies to
P and Q (r=0.98). The other correlations seem to be moderate, ranging from -0.18 to 0.7.
The high correlation between hapaxes and types could be regarded as surprising given that
some types have a quite high token frequency and could thus be considered to be
lexicalized to a greater or lesser extent. However, the value seems to suggest that types and
hapaxes on the one hand, and the P and Q calculations on the other, are closely related
kinds of information.
5.3 Hapaxes´ importance concerning productivity
Plag (2006) considers P (the 'Productivity in the narrow sense') to calculate potential
productivity, or, the probability of meeting a newly produced word type with a specific
affix. It is difficult, however, to see how the notion of probability should be interpreted
here. P is calculated as the number of hapaxes divided by the total token frequency for a
particular affix. In the case of a process (or affix) in a given corpus that has only a few
types, perhaps with most of them having high token frequencies, and only a few hapaxes, it
does seem that such a case would be of low productivity (the high token frequency might
indicate some degree of lexicalization, leaving few items on which to base an analogy for
production). On the other hand, if the token frequency equals the hapax count for some
affix (i.e. all occurrences of the affix are hapaxes, but not necessarily neologisms), then P
necessarily equal 1 (certainty), which seems rather counter-intuitive but should perhaps be
considered simply a minor glitch in the calculation.
In addressing the third research question concerning the extent to which hapax legomena
provide useful productivity information, we can now argue, since the P and Q calculations
correlate so highly (r=0,98), and that the hapax counts for the different prefixes do
approximate half the type counts for any particular prefix, that the hapax counts are not
actually providing much more information that the type counts.
5.4 Conclusion
Clearly, there is no single method for measuring the productivity of affixes, and no single
method is acknowledged by the majority of word-formation scholars as being superior to
all the others (Bauer, 2005). Rather, the different models should be viewed as reflecting
different aspects of morphological productivity (Plag, 2006) where type and hapax
frequency (and to some extent even token frequency), measures similar aspects of
productivity ('factual' productivity); while P and Q, on the other hand, considers another
kind of information and thus another view of productivity (potential productivity). By
investigating several of the methods, comparing and analyzing the different results and the
information they give, one can hopefully come to a more nuanced view of just what the
general notion of productivity is supposed to mean and measure.

21
This study of productivity measurements of ten prefixes in the BNC was based on random
samples of types of each of the ten prefixes. In order to get a more reliable view of the
measurements, a study that scrutinizes each token of each type for each prefix would need
to be done. While such a study was outside the scope of this project, it could be considered
for future work. In addition to more reliable numbers, such a study would probably also
provide data for more rigorous selection criteria. Such a study could also calculate variation
of results based on varying sets of selection criteria. Such a study would also contribute
towards lifting the general study of morphological productivity up from what Bauer calls "a
rather poor state" (Bauer 2001: 25).

22
References
Aronoff, M. (1976). Word Formation in Generative Grammar. Cambridge, USA: MIT
Press.
Baayen, H. (2012). homepage of R. Harald Baayen. Retrieved from
http://www.ualberta.ca/~baayen/.
Baayen, R. H. & Renouf, A. (1996) Chronicling the times: Productive lexical innovations
in an English newspaper. Language, 72(1), 69-96.
Bauer, L. (1983). English word-formation. Cambridge: Cambridge Univ. Press.
Bauer, L. (2001). Morphological productivity. Cambridge: Cambridge Univ. Press.
Bauer, L. (2005). Productivity: Theories. In P. tekauer & R. Lieber (Eds.), Handbook of
word-formation (pp. 315-34). Dordrecht, The Netherlands: Springer.
Fernández-Domínguez, J., Díaz-Negrillo, A., tekauer, P. (2007). How is low
morphological productivity measured? ATLANTIS, 29(1), 29-54.
Hay, J. & Baayen, H. (2001). Parsing and Productivity. In G. E. Booji & J. van Marle
(Eds.), Yearbook of Morphology 2001 (pp. 203-235). Dordrecht, The Netherlands: Kluwer
Academic Publishers.
Lehrer, A. (1995). Prefixes in English word formation. Folia Linguistica 29(1), 133-148.
Ljung, M. (2003). Making words in English. Lund: Studentlitteratur.
Plag, I., Dalton-Puffer, C., Baayen, H. (1999). Morphological productivity across speech
and writing. English Language and Linguistics 3(2), 209-228.
Plag, I. (2003). Word-formation in English. Cambridge: Cambridge University Press.
Plag, I. (2006). Productivity. In B. Arts & A. McMahon (Eds.), The Handbook of English
Linguistics (pp. 121-128). Malden, USA: Blackwell Publishing Ltd.
Plag, I. (2007). Introduction to English Linguistics. Berlin: Mouton de Gruyter.
van Marle, J. (1992) The relationship between morphological productivity and frequency: a
comment on Baayen´s performance-oriented conception of morphological productivity. In
G. E. Booij & J. van Marle (Eds.), Yearbook of Morphology 1991 (pp. 151-163).
Dorodrecht, The Netherlands: Kluwer Academic Publishers.

23
The British National Corpus, version 3 (BNC XML Edition). 2007. Distributed by Oxford
University Computing Services on behalf of the BNC Consortium. URL:
http://www.natcorp.ox.ac.uk/

24
Appendix A
"A" equals accepted, that the lemma under consideration has been approved. "X", on the
other hand, means that the lemma has been rejected, not considered as valid.
Random sample of
the prefix arch- Headword Frequency
A = accepted
X = rejected
1 arch-appeaser 1 A
2 arch-boss 1 A
3 arch-cynic 1 A
4 arch-gallic 1 A
5 arch-introspective 1 A
6 arch-priestess 1 A
7 arch-thatcherite 1 A
8 archadian 1 X
9 archaeoentomology 1 X
10 archaeopterix 1 X
11 archambaud 1 X
12 archangetica 1 X
13 archdeadon 1 X
14 archenfield 1 X
15 archetypology 1 A
16 archias 1 X
17 archidonate 1 A
18 archilocho 1 X
19 archipiélago 1 X
20 architect-owner 1 X
21 architecto 1 X
22
architecture-
independent
1 X
23 architype 1 A
24 archi 1 X
25 archon-list 1 X
26 archterrorist 1 A
27 archimede 2 X
28 arch-opponent 2 A
29 archaeogastropod 2 X
30 archd 2 X
31 architectura 2 X
32 archmage 2 A
33 arch-priest 3 A
34 archaistic 3 X
35 archdruid 3 A
36 archipelagoe 3 X

25
37 arch-conservative 4 A
38 archilochean 4 X
39 archelaus 5 X
40 archao 6 X
41 architectonic 8 X
42 archy 9 X
43 archived 11 X
44 archimandrite 14 A
45 archeologist 24 X
46 archdiocese 39 A
47 archangel 56 A
48 archivist 149 X
49 archway 261 A
50 archaeologist 537 X
Random sample of
the prefix hyper- Headword Frequency
A = accepted
X = rejected
1 hyper-awareness 1 A
2 hyper-edge 1 A
3 hyper-flex 1 A
4 hyper-knee 1 A
5 hyper-passionate 1 A
6 hyper-smart 1 A
7 hyperaccumulation 1 A
8 hyperaesthetic 1 A
9 hyperbolae 1 X
10 hypercarbon 1 A
11 hypercompetitive 1 A
12 hyperdensity 1 A
13 hyperechoic 1 A
14 hypergames 1 A
15 hypergastinaemia 1 A
16 hypergraphics 1 A
17 hyperinsulinemia 1 A
18 hyperlipaemic 1 A
19 hypermetabolic 1 A
20 hypernormal 1 A
21 hyperparasitic 1 A
22 hyperpigment 1 A
23 hypersaline 1 A
24 hypersnow 1 A
25 hyperstriatum 1 A
26 hypertext-style 1 A
27 hypertonicity 1 A
28 hyperventilate 1 A

26
29 hyper-media 2 A
30 hyperarc 2 A
31 hyperconsciousness 2 A
32 hyperintelligent 2 A
33 hypermanic 2 A
34 hyperpolarisation 2 A
35 hypersexuality 2 A
36 hypertext-to-text 2 A
37 hyper-real 3 A
38 hyperextension 3 A
39 hypersomnia 3 A
40 hyperchannel 4 A
41 hyperpnoea 4 A
42 hyperparasite 5 A
43 hyperfine 6 A
44 hyperinsulinaemia 7 A
45 hyper-base 9 A
46 hyperglycaemic 15 A
47 hypertensive 21 A
48 hyperdesk 26 A
49 hypermedia 38 A
50 hyperion 62 X
Random sample of
the prefix mega- Headword Frequency
A = accepted
X = rejected
1 mega-cash 1 A
2 mega-city 1 A
3 mega-death 1 A
4 mega-diverse 1 A
5 mega-firm 1 A
6 mega-gloss 1 A
7 mega-high 1 A
8 mega-interesting 1 A
9 mega-massive 1 A
10 mega-microscope 1 A
11 mega-moan 1 A
12 mega-profitable 1 A
13 mega-skrag 1 A
14 mega-stonking 1 A
15 mega-ton 1 A
16 mega-volume 1 A
17 mega-whopper 1 A
18 megabecquerel 1 A
19 megabuck 1 A
20 megaceros 1 A

27
21 megacounty 1 A
22 megafabulously 1 A
23 megaglob 1 A
24 megaira 1 X
25 megalencephaly 1 A
26 megali 1 X
27 megalomedia 1 A
28 megamillion 1 A
29 megamuseum 1 A
30 megaphone-wielding 1 A
31 megapixel 1 A
32 megaprogram 1 A
33 megaship 1 A
34 megasthenes 1 X
35 megaterium 1 X
36 megatooth 1 A
37 megavessel 1 A
38 megazone 1 A
39 megaproject 2 A
40 mega-expensive 2 A
41 mega-store 2 A
42 megadrives 2 A
43 megamerger 2 A
44 megate 2 X
45 mega-buck 3 A
46 megabase 3 A
47 megagame 3 A
48 megatek 3 X
49 megalosaurus 4 A
50 megastardom 4 A
Random sample of
the prefix mini- Headword Frequency
A = accepted
X = rejected
1 mini-aileron 1 A
2 mini-bead 1 A
3 mini-captain 1 A
4 mini-classic 1 A
5 mini-conference 1 A
6 mini-debate 1 A
7 mini-earthquake 1 A
8 mini-fad 1 A
9 mini-forest 1 A
10 mini-grinder 1 A
11 mini-hypermarket 1 A
12 mini-launch 1 A

28
13 mini-micro 1 A
14 mini-parade 1 A
15 mini-proof 1 A
16 mini-retrieval 1 A
17 mini-section 1 A
18 mini-slab 1 A
19 mini-studio 1 A
20 mini-thesis 1 A
21 mini-twelfth 1 A
22 mini-wurlitzer 1 A
23 minichrom 1 A
24 minidisk 1 A
25 minilink 1 A
26 minimissile 1 A
27
mining-to-
manufacturing
1 A
28 minipuls 1 A
29 miniskirted 1 A
30 minister-it 1 X
31 ministers 1 X
32 minitanker 1 A
33 mini-tunnel 2 A
34 mini-cinema 2 A
35 mini-jmc 2 A
36 mini-season 2 A
37 mini-uzi 2 A
38 minifundium 2 A
39 minis-type 2 X
40 minit 2 X
41 miniato 3 X
42 minitex 3 X
43 miniclub 4 A
44 mini-version 5 A
45 mini-golf 6 A
46 mini-van 7 A
47 mini-cab 9 A
48 mini-golf 13 A
49 minimization 18 X
50 mini-enterprise 28 A
Random sample of
the prefix out- Headword Frequency
A = accepted
X = rejected
1 out-act 1 A
2 out-cross 1 A
3 out-fish 1 A

29
4 out-i 1 X
5 out-nursing 1 A
6 out-of-keeping 1 X
7 out-of-stock 1 X
8 out-patient 1 A
9 out-quarterback 1 A
10 out-spoke 1 A
11 out-turn 1 A
12 outbluffed 1 A
13 outcross 1 A
14 outer-ring 1 X
15 outflood 1 A
16 outlandos 1 X
17 outof-the-way 1 X
18 output-setting 1 A
19 outsang 1 A
20 outside-the-scope 1 A
21 outswel 1 A
22 outwardness 1 A
23 outreaching 2 A
24 out-hit 2 A
25 out-of-time 2 X
26 out-standing 2 A
27 outerhead 2 A
28 outlawing 2 A
29 outshining 2 A
30 out-and-back 3 X
31 out-placement 3 A
32 outflanking 3 A
33 outr 3 X
34 out-of-competition 4 X
35 outbr 4 X
36 outward-pointing 4 A
37 outbound 5 A
38 outsourcing 5 A
39 out-of-contract 7 X
40 outsized 8 A
41 outflung 12 A
42 out-manoeuvr 15 A
43 outrigger 19 A
44 outsource 25 A
45 out-of-work 39 X
46 outplay 58 A
47 outbound 100 A
48 outpost 164 A

30
49 outpatient 368 A
50 outbreak 1173 A
Random sample of
the prefix over-
Headword Frequency A = accepted
X = rejected
1 over-abundant 1 A
2 over-bleach 1 A
3 over-chill 1 A
4 over-declamatory 1 A
5 over-embellishment 1 A
6 over-florid 1 A
7 over-ideologisation 1 A
8 over-lean 1 A
9 over-modulate 1 A
10 over-possessive 1 A
11 over-rarefy 1 A
12 over-sample 1 A
13 over-solicitousness 1 A
14 over-sweet-anemone 1 A
15 over-upholstered 1 A
16 overattentive 1 A
17 overcoat-clad 1 A
18 overdiscuss 1 A
19 overfrow 1 A
20 overinsterpretation 1 A
21 overmonolithic 1 A
22 overproducing 1 A
23 oversight 1 A
24 overtrading 1 A
25 over-spiritualizing 2 A
26 over-control 2 A
27 over-furnished 2 A
28 over-police 2 A
29 over-strong 2 A
30 overcoated 2 A
31 overjacket 2 A
32 overstrained 2 A
33 over-doing 3 A
34 over-solicitous 3 A
35 overman 3 A
36 over-breeding 4 A
37 over-sentimental 4 A
38 overshirt 4 A
39 overmighty 5 A
40 over-spending 6 A

31
41 over-stretched 7 A
42 overindulgence 8 A
43 over-state 10 A
44 overeating 12 A
45 oversize 15 A
46 overwritten 19 A
47 overreach 27 A
48 overrated 40 A
49 oversimplification 66 A
50 overload 212 A
Random sample of
the prefix semi- Headword Frequency
A = accepted
X = rejected
1 semi-accidentally 1 A
2 semi-architectural 1 A
3 semi-bachelor 1 A
4 semi-bureaucrat 1 A
5 semi-collapse 1 A
6 semi-consciously 1 A
7 semi-customer 1 A
8 semi-destroy 1 A
9 semi-dwarf 1 A
10 semi-existence 1 A
11 semi-flat 1 A
12 semi-gothic 1 A
13 semi-illiterate 1 A
14 semi-intensive 1 A
15 semi-liberated 1 A
16 semi-market 1 A
17 semi-national 1 A
18 semi-palmated 1 A
19 semi-pluralism 1 A
20 semi-pureed 1 A
21 semi-refined 1 A
22 semi-rs 1 A
23 semi-seriously 1 A
24 semi-slavery 1 A
25 semi-stable 1 A
26 semi-strangled 1 A
27 semi-train 1 A
28 semi-wet 1 A
29 semiconductor-based 1 A
30 semilla 1 X
31 seminis 1 X
32 semirecumbent 1 A

32
33 semivoluminous 1 A
34 semi-audible 2 A
35 semi-democratic 2 A
36 semi-government 2 A
37 semi-peripheral 2 A
38 semi-ruin 2 A
39 semiautomated 2 A
40 semiprofessional 2 A
41 semi-flexible 3 A
42 semi-proletariat 3 A
43 semi-annually 4 A
44
semi-
proletarianisation
4 A
45 semi-aquatic 5 A
46 semitonal 5 A
47 semi-abstract 7 A
48 semi-nude 8 A
49 semi-autobiographical 12 A
50 semi-rural 19 A
Random sample of
the prefix super- Headword Frequency
A = accepted
X = rejected
1 super-absorbency A
2 super-bush 1 A
3 super-deluxe 1 A
4 super-fitness 1 A
5 super-heroe 1 A
6 super-liner 1 A
7 super-mini 1 A
8 super-pit 1 A
9 super-rocket 1 A
10 super-sexy 1 A
11 super-spy 1 A
12 super-treble 1 A
13 superactivate 1 A
14 superbly-located 1 X
15 supercalendered 1 A
16 superchrome 1 A
17 supercut 1 A
18 superfirm 1 A
19 supergrass 1 A
20 superimposer 1 A
21 superlativeness 1 X
22 supermax 1 X

33
23
supernaturally-
flavoured
1 A
24 superpatriot 1 A
25 superquinn 1 X
26 supersmart 1 A
27 superstress 1 A
28 supertinta 1 X
29 super-loud 2 A
30 super-hyped 2 A
31 super-stadium 2 A
32 superbly-judged 2 X
33 superfecundity 2 A
34 superlunary 2 A
35 superpruf 2 X
36 supertintas 2 X
37 super-saver 3 A
38 supernaturalism 3 A
39 super-delegate 4 A
40 supermarioland 4 X
41 superbike 5 A
42 superstation 5 A
43 superphosphate 6 A
44 superspec 7 X
45 supermac 9 X
46 super-fit 12 A
47 supermini 15 A
48 superscript 22 A
49 super-power 41 A
50 superposition 70 A
Random sample of
the prefix ultra- Headword Frequency
A = accepted
X = rejected
1 ultra-absorbent 1 A
2 ultra-avantgarde 1 A
3 ultra-centralised 1 A
4 ultra-current 1 A
5 ultra-defensive 1 A
6 ultra-drawing 1 A
7 ultra-fast 1 A
8 ultra-free 1 A
9 ultra-happy 1 A
10 ultra-hip 1 A
11 ultra-keen 1 A
12 ultra-low 1 A
13 ultra-model 1 A

34
14 ultra-naughty 1 A
15 ultra-portability 1 A
16 ultra-quiet 1 A
17 ultra-reformist 1 A
18 ultra-right-wing 1 A
19 ultra-slow 1 A
20 ultra-sophisticate 1 A
21 ultra-structure 1 A
22 ultra-tog 1 X
23 ultra-yah 1 A
24 ultracentrifuge 1 A
25 ultradextral 1 A
26 ultramagnetic 1 A
27 ultrarunner 1 A
28 ultrasonographically 1 A
29 ultratherm 1 A
30 ultra-lightweight 2 A
31 ultra-compact 2 A
32 ultra-fit 2 A
33 ultra-powerful 2 A
34 ultra-rightwing 2 A
35 ultra-vivid 2 A
36 ultramafic 2 A
37 ultraviolet-coloured 2 A
38 ultra-leftism 3 A
39 ultra-tight 3 A
40 ultrafiltration 3 A
41 ultrasonically 3 A
42 ultra-low 4 A
43 ultralight 4 A
44 ultra-leftist 5 A
45 ultrasparc-iii 6 X
46 ultrasparc-i 8 X
47 ultra-nationalist 11 A
48 ultramarine 45 A
49 ultra-modern 30 A
50 ultrasound 164 A
Random sample of
the prefix under- Headword Frequency
A = accepted
X = rejected
1 under-active 1 A
2 under-challenge 1 A
3 under-demanding 1 A
4 under-fda 1 X
5 under-indeed 1 A
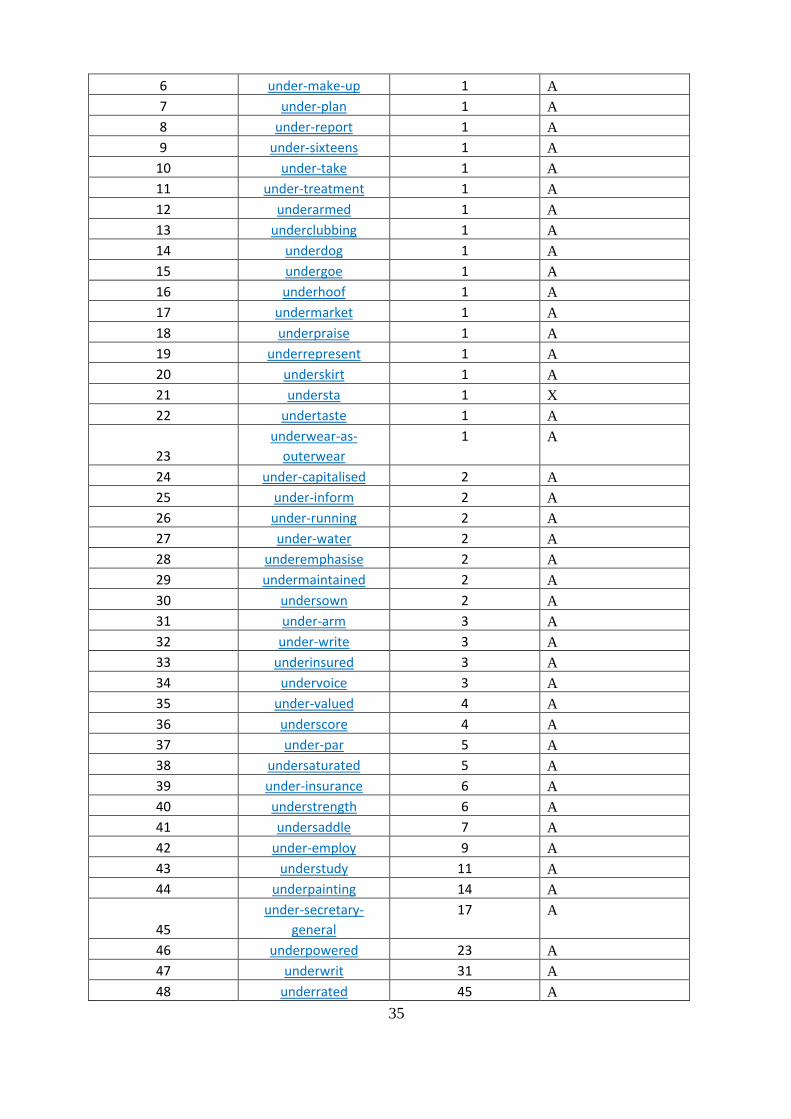
35
6 under-make-up 1 A
7 under-plan 1 A
8 under-report 1 A
9 under-sixteens 1 A
10 under-take 1 A
11 under-treatment 1 A
12 underarmed 1 A
13 underclubbing 1 A
14 underdog 1 A
15 undergoe 1 A
16 underhoof 1 A
17 undermarket 1 A
18 underpraise 1 A
19 underrepresent 1 A
20 underskirt 1 A
21 understa 1 X
22 undertaste 1 A
23
underwear-as-
outerwear
1 A
24 under-capitalised 2 A
25 under-inform 2 A
26 under-running 2 A
27 under-water 2 A
28 underemphasise 2 A
29 undermaintained 2 A
30 undersown 2 A
31 under-arm 3 A
32 under-write 3 A
33 underinsured 3 A
34 undervoice 3 A
35 under-valued 4 A
36 underscore 4 A
37 under-par 5 A
38 undersaturated 5 A
39 under-insurance 6 A
40 understrength 6 A
41 undersaddle 7 A
42 under-employ 9 A
43 understudy 11 A
44 underpainting 14 A
45
under-secretary-
general
17 A
46 underpowered 23 A
47 underwrit 31 A
48 underrated 45 A

36
49 underfunding 66 A
50 undergravel 149 A

37
Stockholms universitet
106 91 Stockholm
Telefon: 08–16 20 00
www.su.se