ml presentation
TRANSCRIPT

UnraveledMachine Learning

UnraveledMachine Learning
ravel [rav-uh l]verb, raveled, raveling.1. to disentangle or unravel the threads or fibers of (a woven or knitted fabric, rope, etc.).2. to tangle or entangle.

ravel

verb, raveled, raveling.1. to disentangle or unravel
the threads or fibers of (a woven or knitted fabric, rope, etc.).
2. to tangle or entangle.
ravel [rav-uh l]

Field of study that gives computers the ability to learn without being explicitly programmed.— Arthur Samuel (1959)
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
— Tom Mitchell (1998)
ML Definitions
39 Years

Field of study that gives computers the ability to learn without being explicitly programmed.
— Arthur Samuel (1959)


A solved game is a game whose outcome (win, lose, or draw) can be correctly predicted from any position, given that both players
play perfectly.

Heuristicsexperience-based techniques for problem solving
rule of thumb
educated guess
intuitive judgment
stereotyping
common sense

A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P,
improves with experience E.— Tom Mitchell (1998)

Cat?Dog!
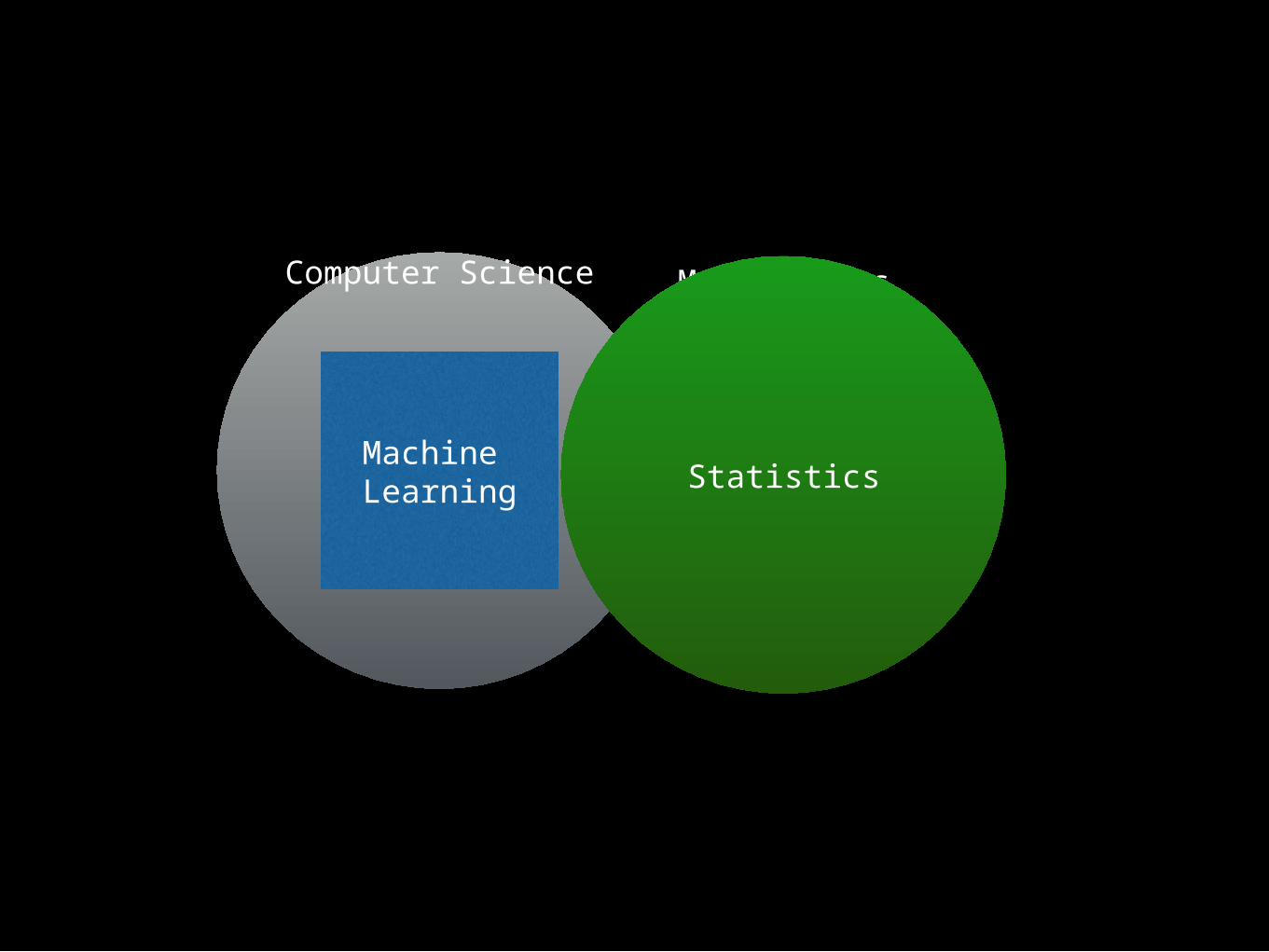
MathematicsComputer Science
Machine Learning Statistics

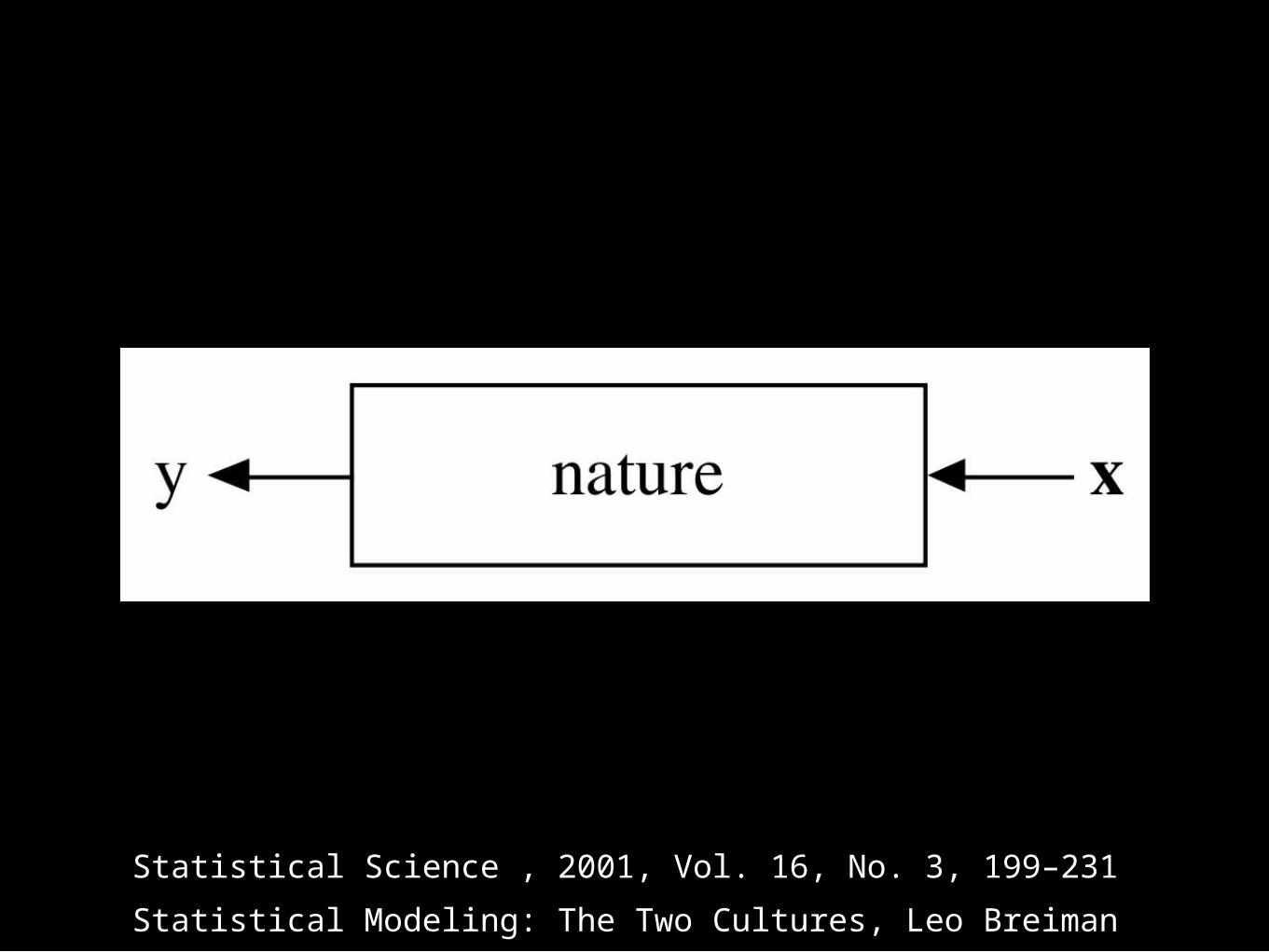
One [statistics] assumes that the data are generated by a given stochastic data model.The other uses algorithmic models and treats the data mechanism as unknown.The statistical community has been committed to the almost exclusive use of data models. This commitment has led to irrelevant theory,
questionable conclusions, and has kept statisticians from working on a large range of interesting current problems.— Leo Breiman, 2001

Kuhn, Max; Johnson, Kjell (2013-05-17). Applied Predictive Modeling (Page 20). Springer. Kindle Edition.
Statistical Science , 2001, Vol. 16, No. 3, 199–231
Statistical Modeling: The Two Cultures, Leo Breiman

Statistical Science , 2001, Vol. 16, No. 3, 199–231
Statistical Modeling: The Two Cultures, Leo Breiman

This enterprise has at its heart the belief that a statistician, by imagination and by looking at
the data, can invent a reasonably good parametric class of models for a complex
mechanism devised by nature.
Statistical Science , 2001, Vol. 16, No. 3, 199–231
Statistical Modeling: The Two Cultures, Leo Breiman

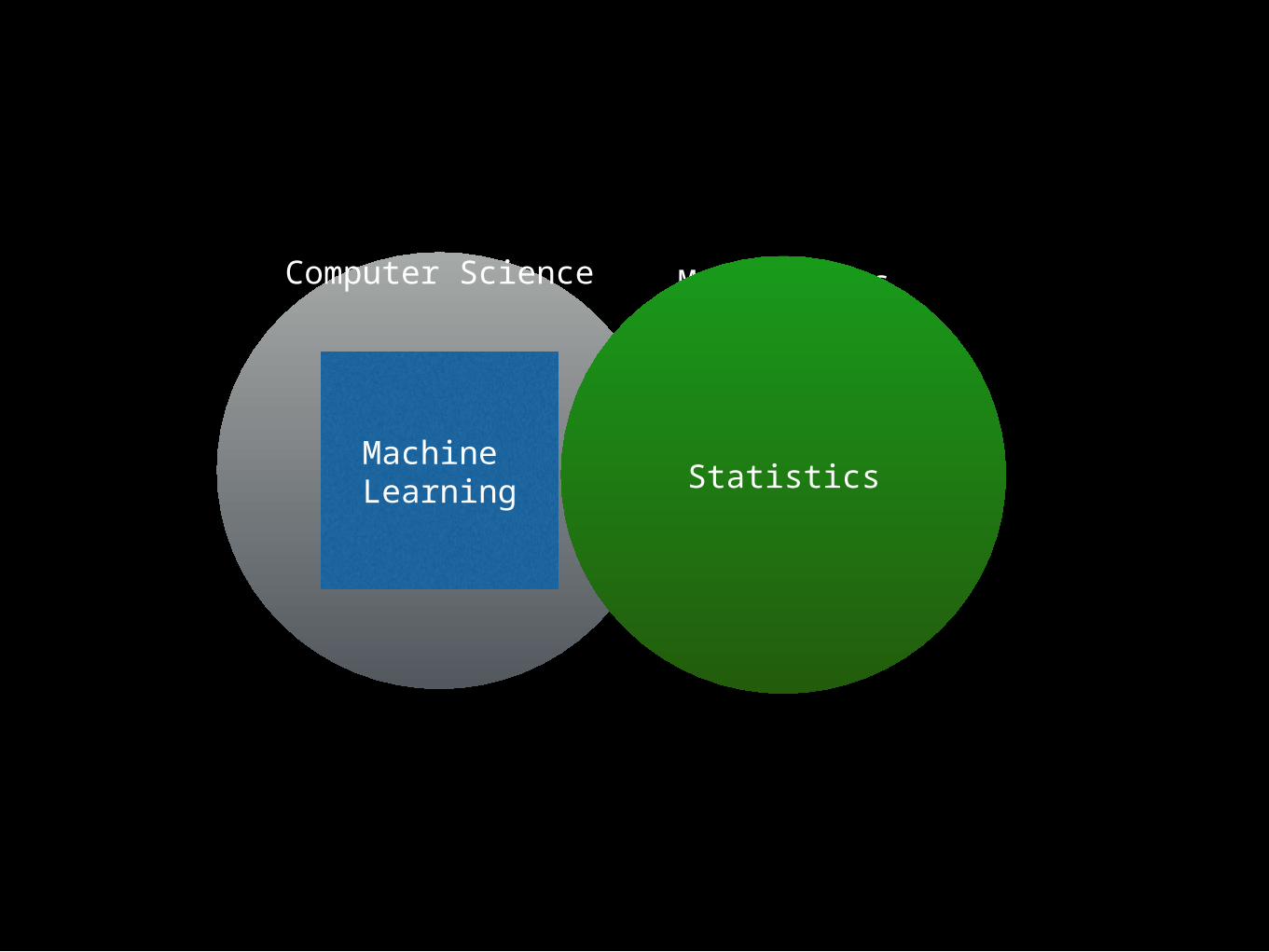
MathematicsComputer Science
Machine Learning Statistics

Mathematics
Computer Science
Machine Learning Statistics

Data Science
MathematicsComputer Science
Machine Learning
Statistics

Data Science

Mathematics
Computer Science
Hacking
Data Science


Mathematics
Computer Science
Hacking
Data Science

Mathematics
Computer Science
Hacking
Big Data

VolumeVelocityVariety

P(V__) = .649% = .00649
.00649 ^ 3 = 0.000000273359449
= 2.7 * 10^-7





StatisticsVastly Simplified
Too much stuff to measure everything.
What to do?

Population = 1024Confidence = 99%
N = 256Red = 42%
CI = 6.935.1 - 48.9

Population = 16384Confidence = 99%
CI = 1%N = 8256


N = ALLBig
BigN = ALL





Cat Cat Cat Cat
Cat Cat Cat Cat
Dog Dog Dog Dog
Dog Dog Dog Dog
Cat Cat Cat Cat
Cat Cat Cat Cat
Dog Dog Dog Dog
Dog Dog Dog Dog
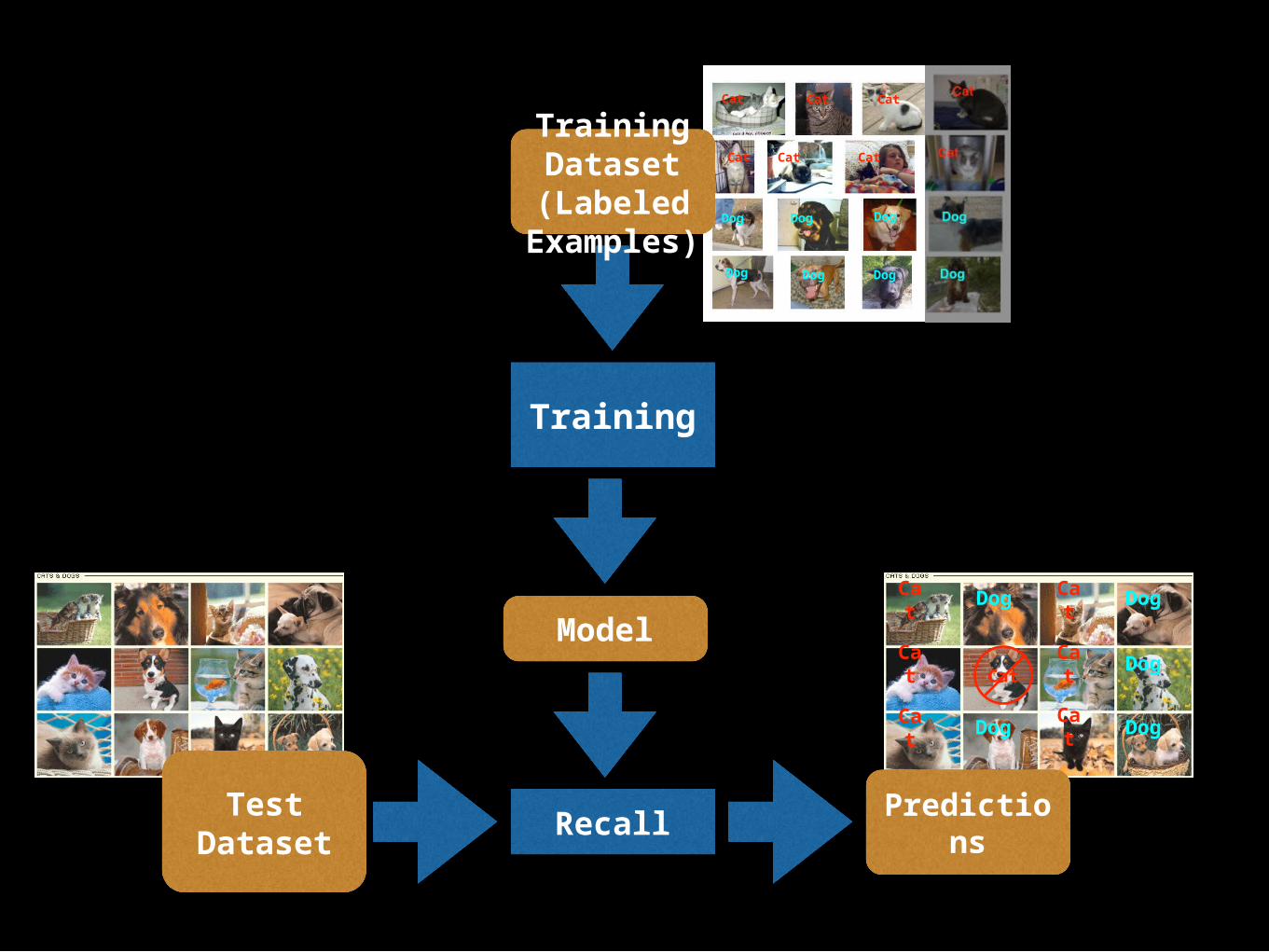
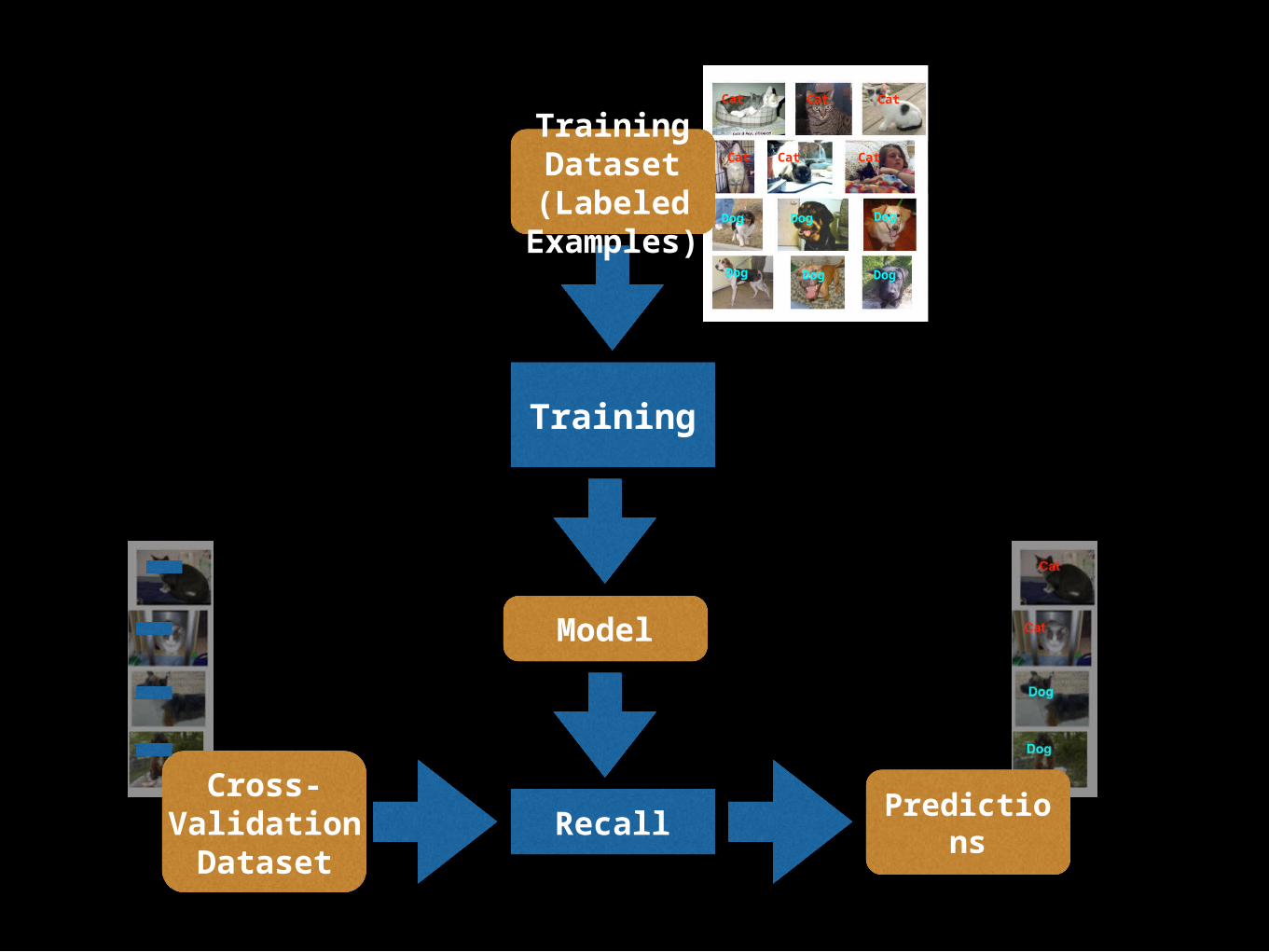
Training
Model
Recall
Cat Cat
Cat
CatCat
Cat
Dog Dog
Dog
DogDog
Cat
Predictions
TrainingDataset(Labeled
Examples)
TestDataset
Training
Model
Recall Predictions
Cat Cat
Cat
Dog
Cat Cat
Cat Cat Cat
Dog Dog Dog
Dog Dog Dog Dog
Cross-Validation
Dataset
Cat Cat Cat Cat
Cat Cat Cat Cat
Dog Dog Dog Dog
Dog Dog Dog Dog
TrainingDataset(Labeled
Examples)
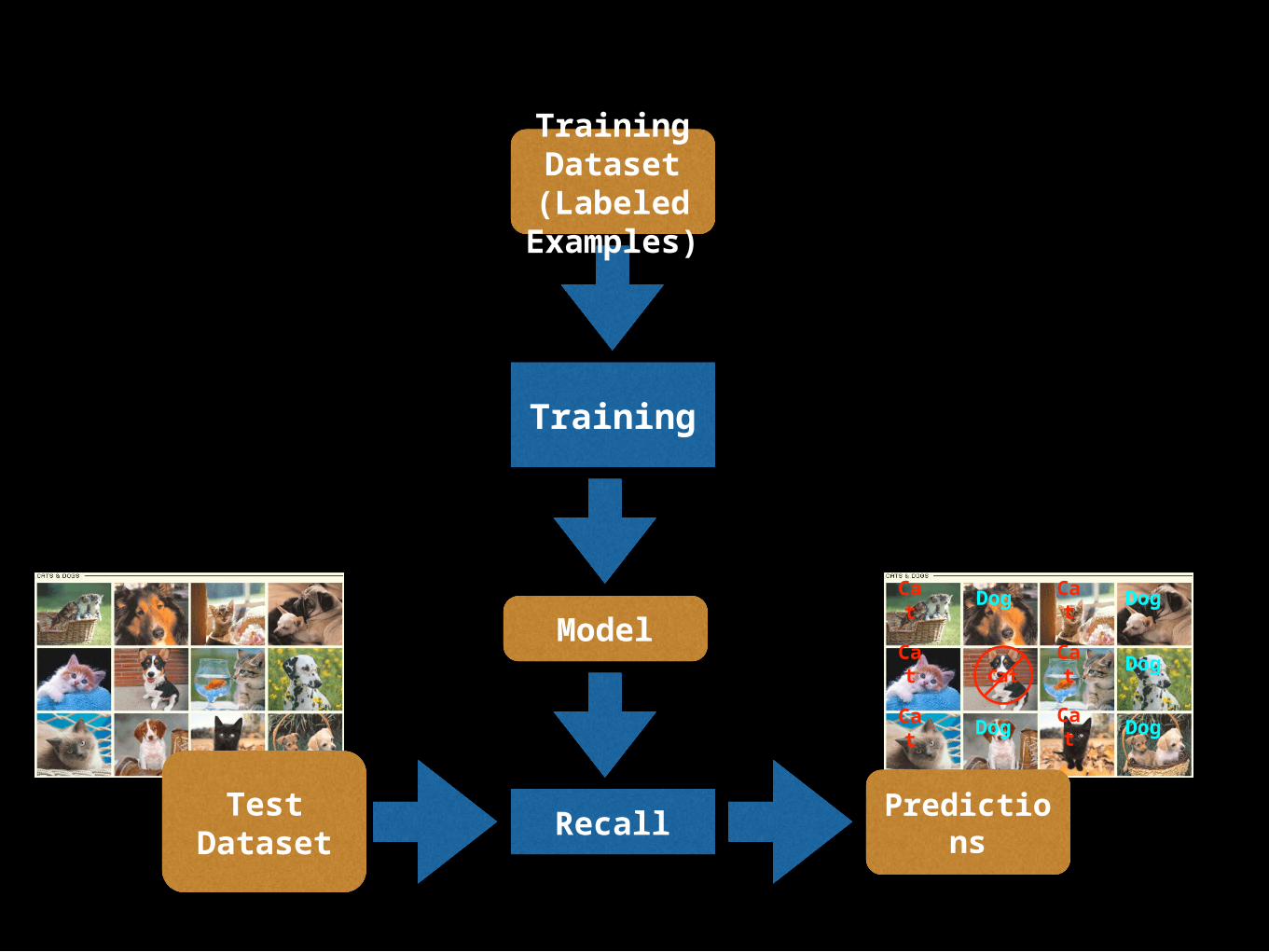
Training
Model
Recall
Cat Cat
Cat
CatCat
Cat
Dog Dog
Dog
DogDog
Cat
Predictions
TrainingDataset(Labeled
Examples)
TestDataset






Prediction
The alternative would be to think backwards . . . and that’s just remembering.
— Sheldon on The Big Bang Theory


Accuracy

Predictive modeling:
The process of developing a mathematical tool or model that generates an accurate prediction
— Kuhn, Max; Johnson, Kjell (2013-05-17). Applied Predictive Modeling. Springer.
Predictions do not have to be accurate to score big value.
— Siegel, Eric. Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die. Wiley.
more

PredictNot Explain

Splork?

Splork?




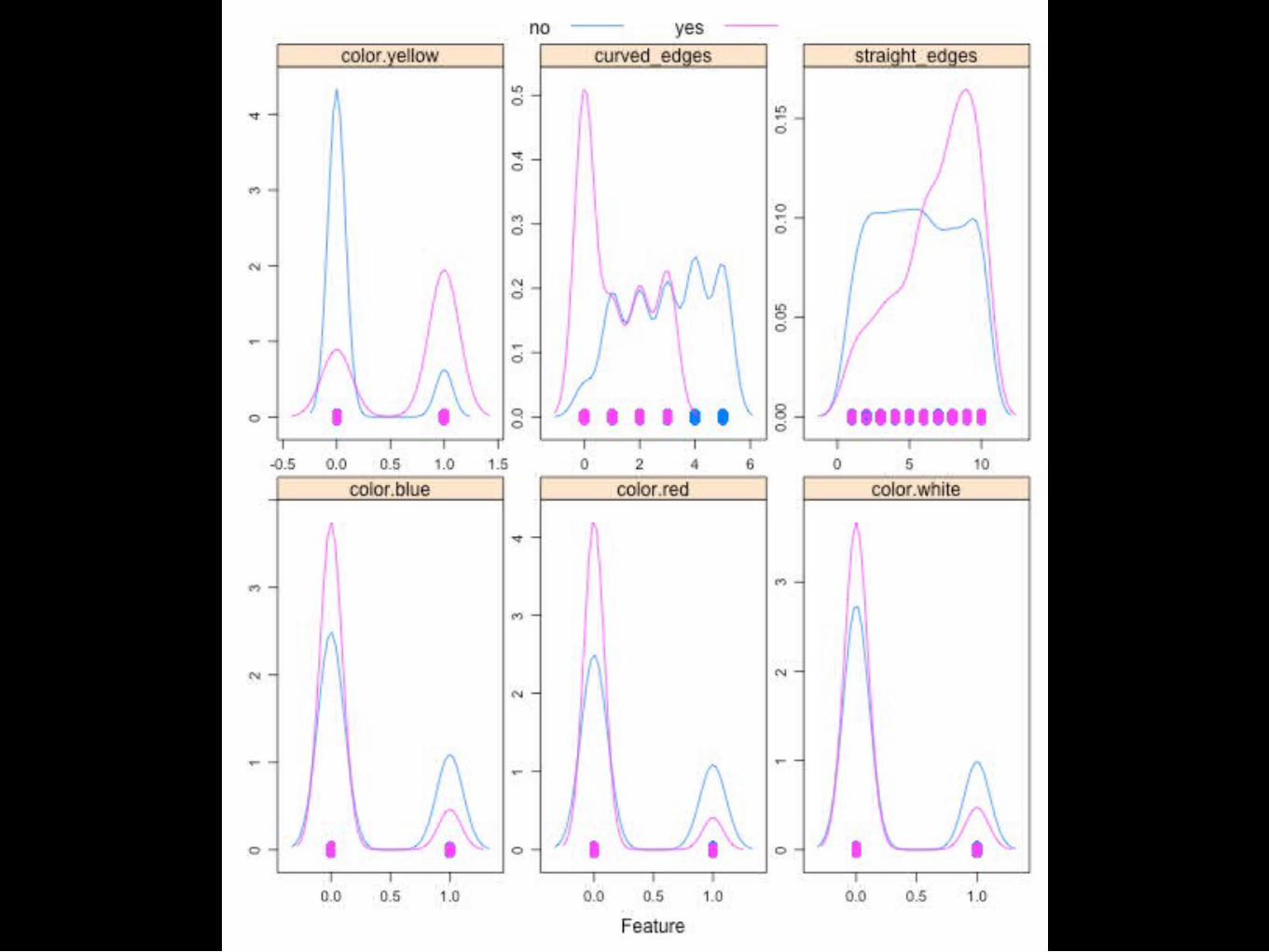
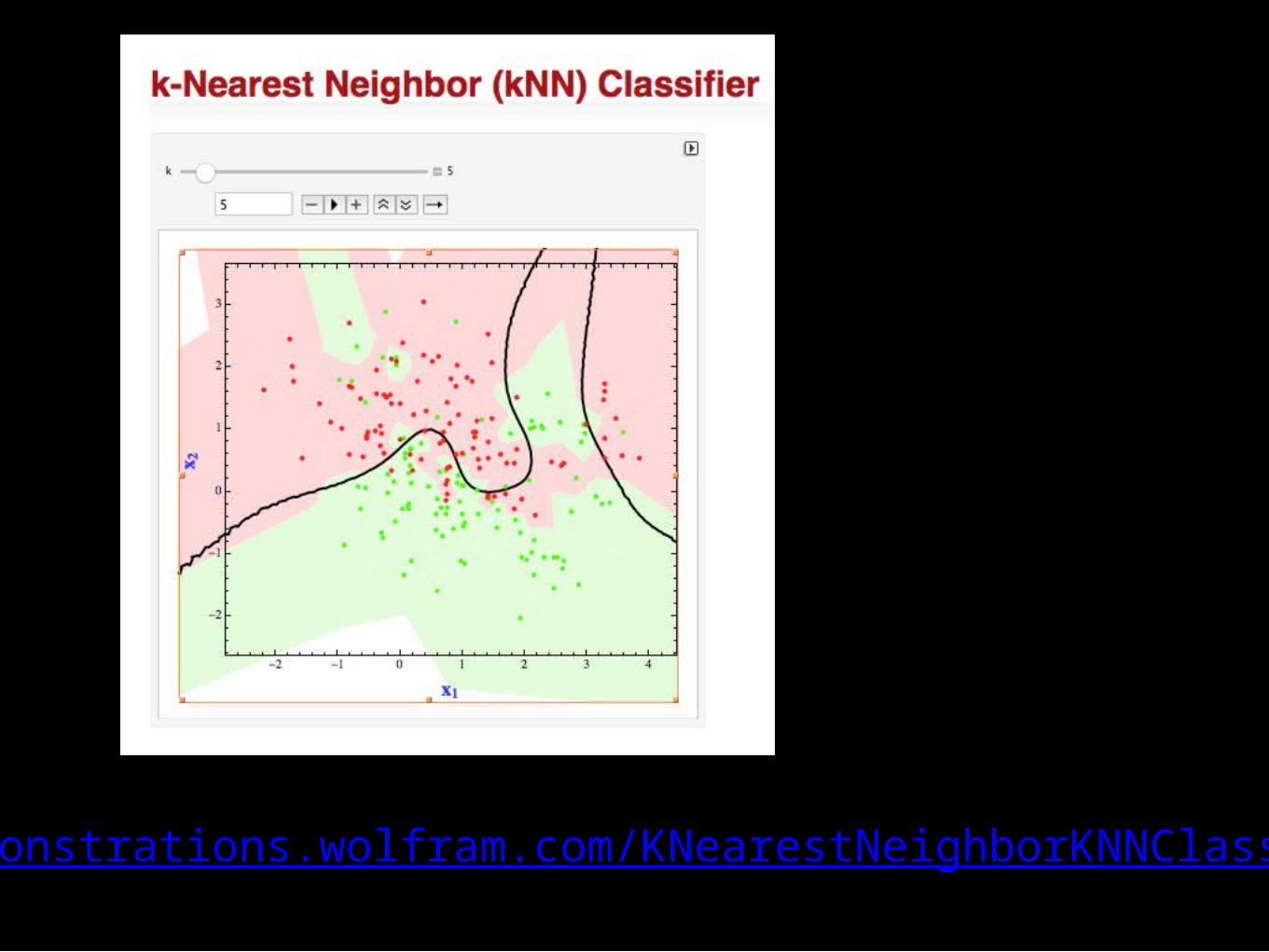
http://demonstrations.wolfram.com/KNearestNeighborKNNClassifier/


> k1<-knn3(splorkData[samp,-c(3,4)],splorkData$splork[samp], k=3)> k13-nearest neighbor classification model
Call:knn3.data.frame(x = splorkData[samp, -c(3, 4)], y = splorkData$splork[samp], k = 3)
Training set class distribution:
no yes 386 114
> pred<-predict(k1,newdata=splorkData[-samp,-c(3,4)],type="class")> str(pred) Factor w/ 2 levels "no","yes": 1 1 1 2 1 1 1 1 1 1 ...> table(pred,splorkData$splork[-samp]) pred no yes no 332 5 yes 0 117

> rf <- randomForest(splork ~ ., data=splorkData[1:500,])
Call: randomForest(formula = splork ~ ., data = splorkData[1:500, ]) Type of random forest: classification Number of trees: 500No. of variables tried at each split: 1
OOB estimate of error rate: 0%Confusion matrix: no yes class.errorno 462 0 0yes 0 38 0>
> table(pred,splorkData$splork[501:954]) pred no yes no 418 0 yes 0 36

1
32
4
> getTree(rf) left daughter right daughter split var split point status prediction
0: 1 2 3 7 0.5 1 01 :2 4 5 6 0.5 1 02 :3 0 0 0 0.0 -1 23 :4 6 7 3 1.0 1 0 4 :5 0 0 0 0.0 -1 15 :6 0 0 0 0.0 -1 16 :7 0 0 0 0.0 -1 1
6 7
5
w=0 w=1

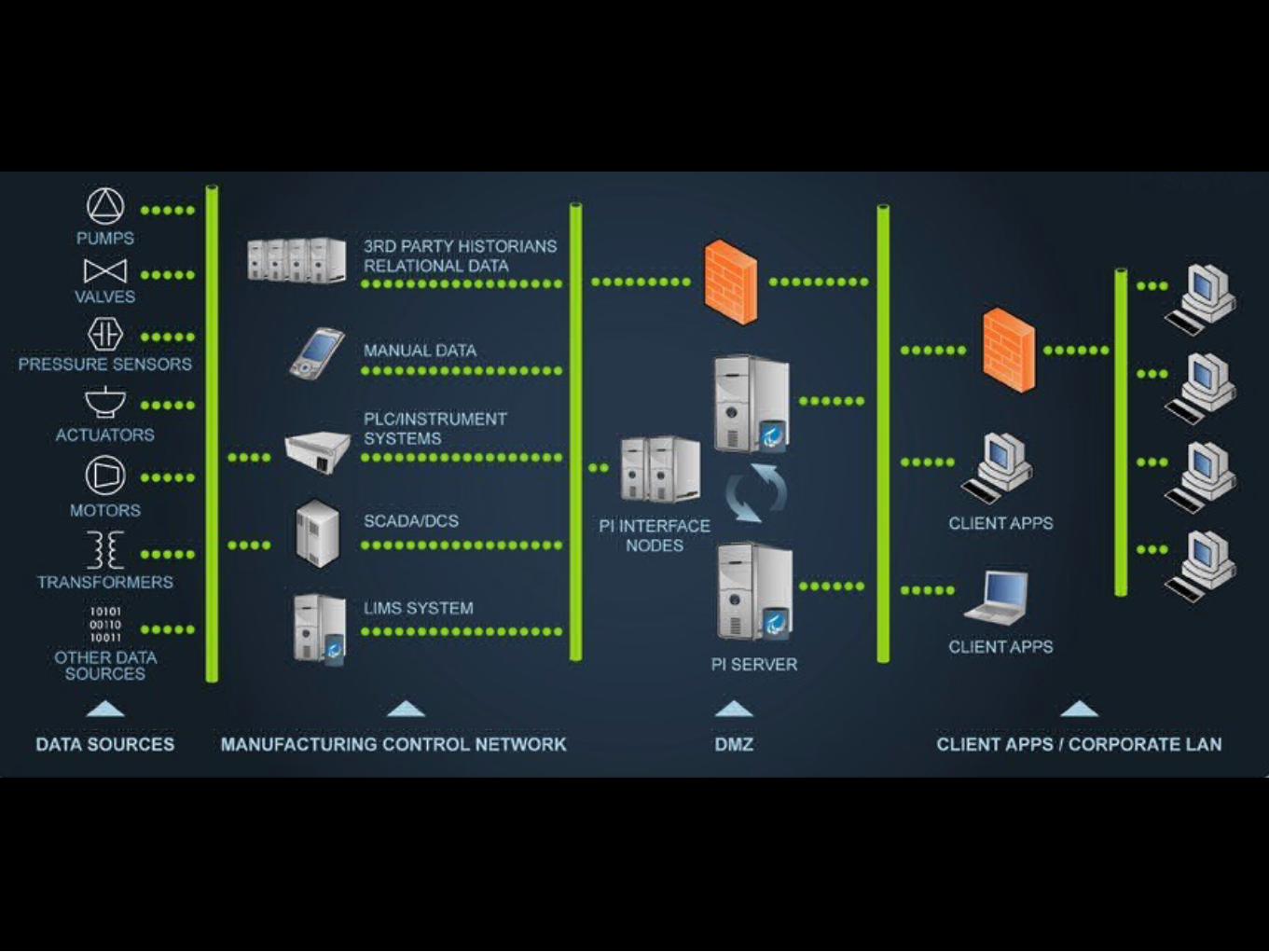
Title: SECOM Data SetAbstract: Data from a semi-conductor manufacturing process
-----------------------------------------------------
Data Set Characteristics: MultivariateNumber of Instances: 1567Area: ComputerAttribute Characteristics: RealNumber of Attributes: 591Date Donated: 2008-11-19Associated Tasks: Classification, Causal-DiscoveryMissing Values? Yes


#make training and test subsets>train<-secom[1:1000,]>test<-secom[1001:1567,]
#get rid of near-zero-variance variables>train<-train[,-nearZeroVar(train)]>test<-test[,-nearZeroVar(test)]
#impute missing values>train<-na.roughfix(train)>test<-na.roughfix(test)
#scale and center>tr1<-preProcess(train, method = c("center", "scale"))>tr2<-preProcess(test, method = c("center", "scale"))>traincs<-predict(tr1,train)>testcs<-predict(tr2,test)
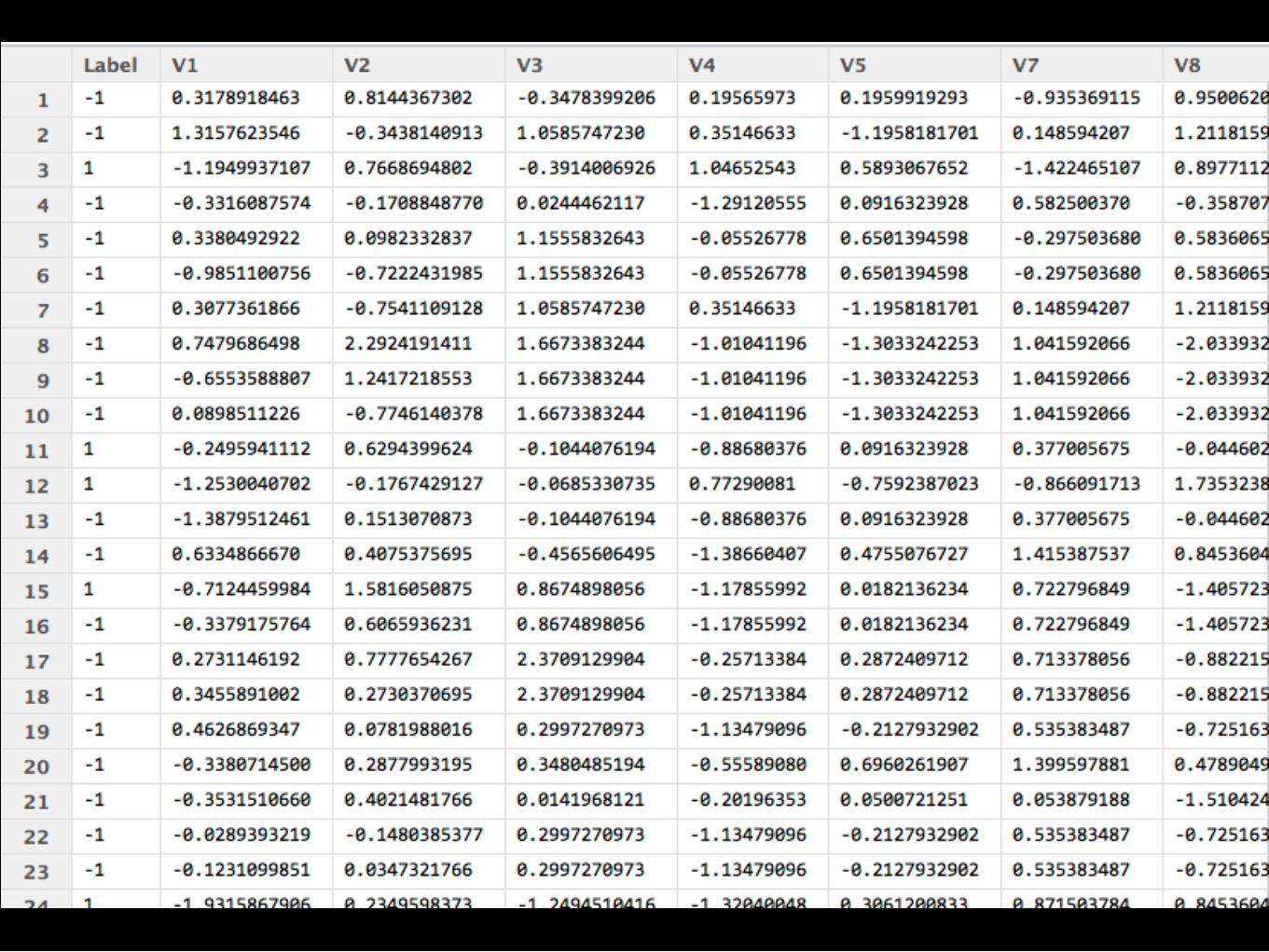
> fit <- glm(secResp ~ .,data=data.frame(sec[train,],secResp=secResp[train]), family=binomial(logit))Warning messages:1: glm.fit: algorithm did not converge 2: glm.fit: fitted probabilities numerically 0 or 1 occurred >
For the background to warning messages about ‘fitted probabilities numerically 0 or 1 occurred’ for binomial GLMs, see Venables & Ripley (2002, pp. 197–8).
There is one fairly common circumstance in which both convergence problems and the Hauck-Donner phenomenon can occur. This is when the fitted probabilities are extremely close to zero or one. Consider a medical diagnosis problem with thousands of cases and around 50 binary explanatory variable (which may arise from coding fewer categorical variables); one of these indicators is rarely true but always indicates that the disease is present.
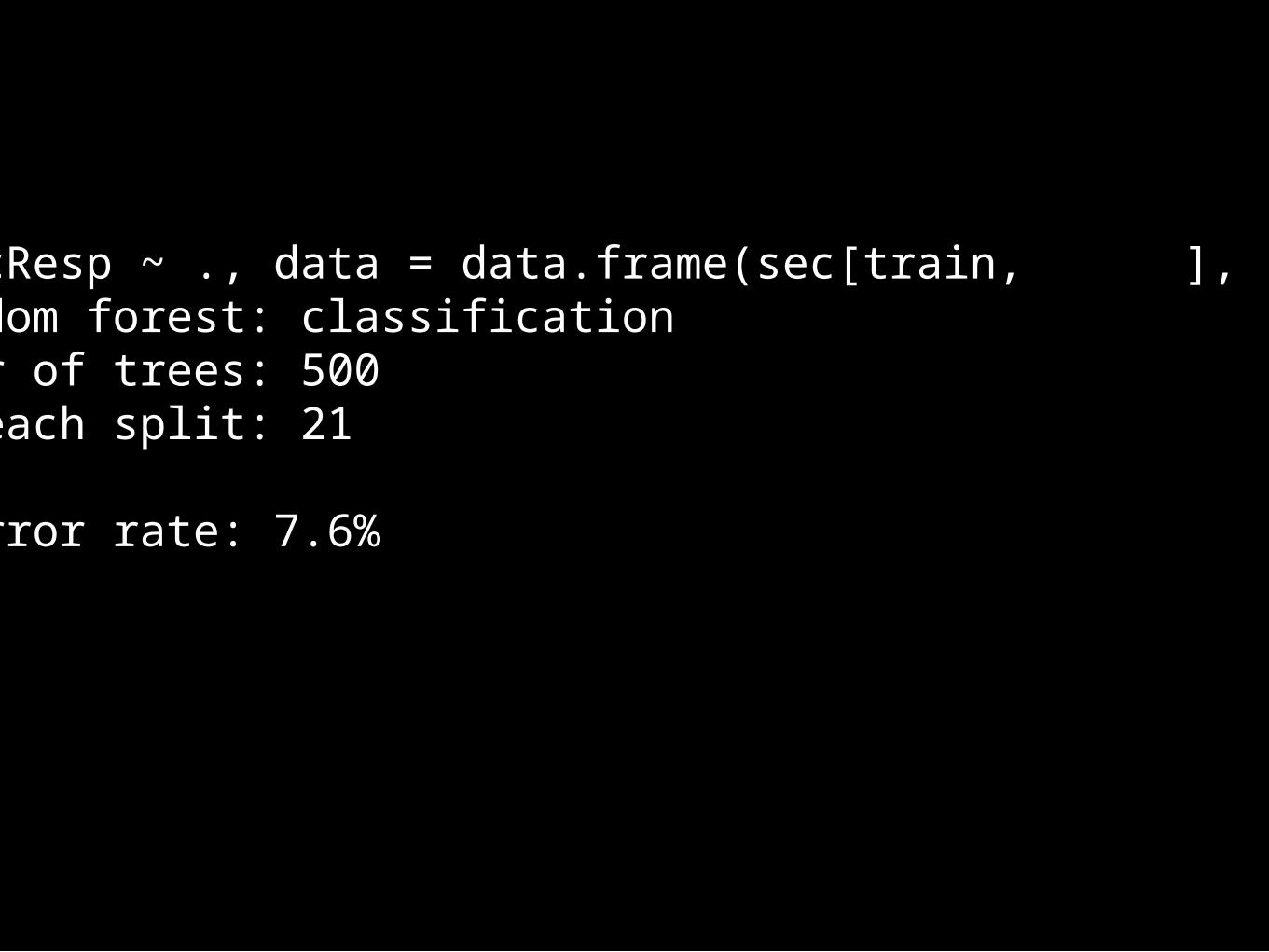
>Call: randomForest(formula = secResp ~ ., data = data.frame(sec[train, ], secResp = secResp[train])) Type of random forest: classification Number of trees: 500No. of variables tried at each split: 21
OOB estimate of error rate: 7.6%Confusion matrix: 0 1 class.error0 924 0 01 76 0 1

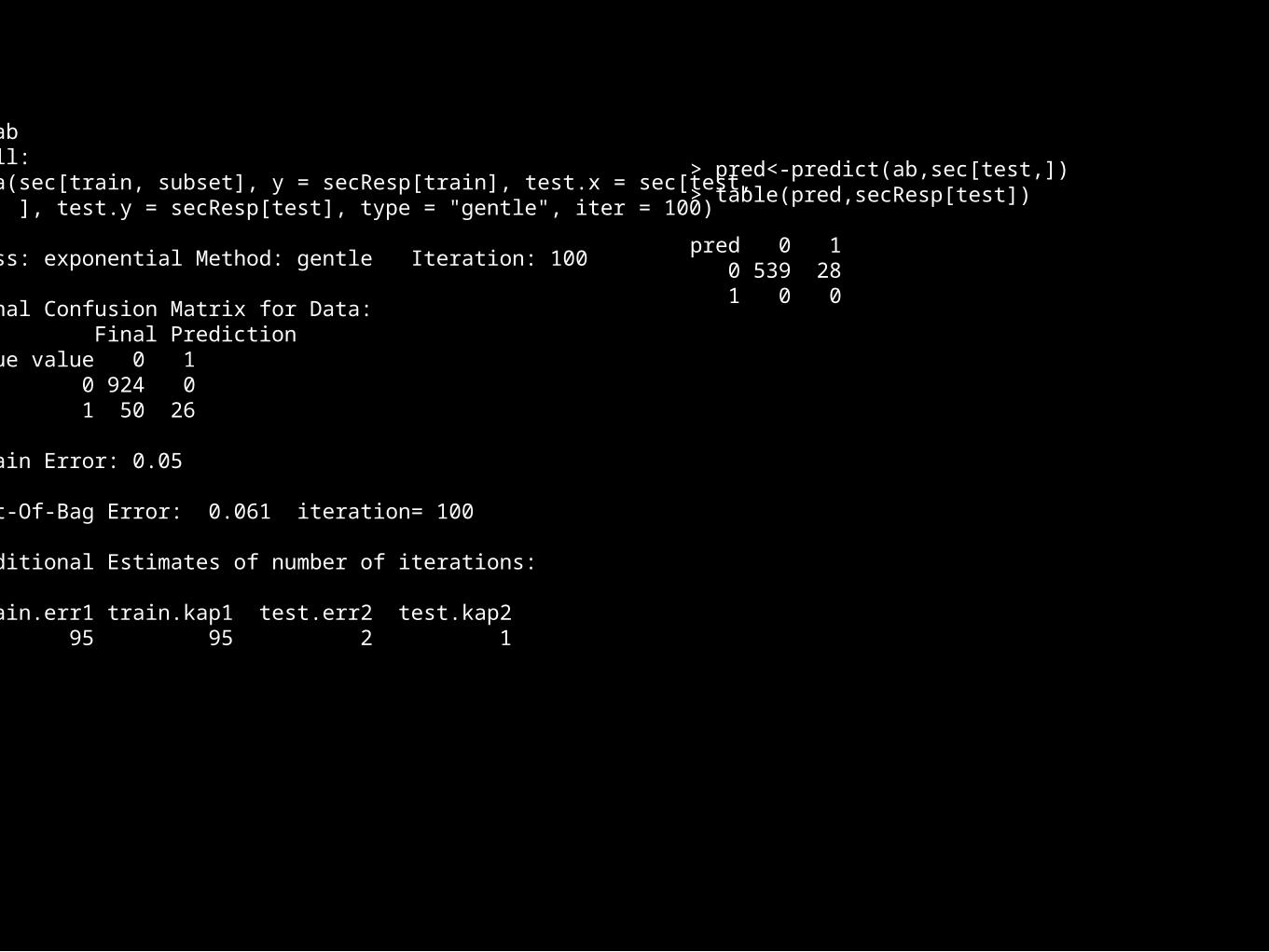
> abCall:ada(sec[train, subset], y = secResp[train], test.x = sec[test, ], test.y = secResp[test], type = "gentle", iter = 100)
Loss: exponential Method: gentle Iteration: 100
Final Confusion Matrix for Data: Final PredictionTrue value 0 1 0 924 0 1 50 26
Train Error: 0.05
Out-Of-Bag Error: 0.061 iteration= 100
Additional Estimates of number of iterations:
train.err1 train.kap1 test.err2 test.kap2 95 95 2 1
> pred<-predict(ab,sec[test,])> table(pred,secResp[test]) pred 0 1 0 539 28 1 0 0



People . . . operate with beliefs and biases. To the extent you can eliminate both and replace them with data,
you gain a clear advantage.
— Michael Lewis, Moneyball: The Art of Winning an Unfair Game
