ml pipelines talk from datafest 3 (in russian)
TRANSCRIPT


Содержание
• Что такое Pipelines на примере Scikit-Learn
• Pipelines в Spark
• Практика использования Spark ML

Процесс построения модели
• Подготовка данных (очистка, нормализация, заполнение пропусков)
• Отбор признаков, генерация новых признаков (например, обработка текста)
• Построение модели классификации/регрессии
• Настройка гиперпараметров модели
• Стекинг моделей

ML pipelines
• Позволяют описать весь процесс построения модели c помощью 2-х типов “строительных блоков”
• Transformer: fit + transform
• Estimator: fit + predict
• “Composite” software design pattern
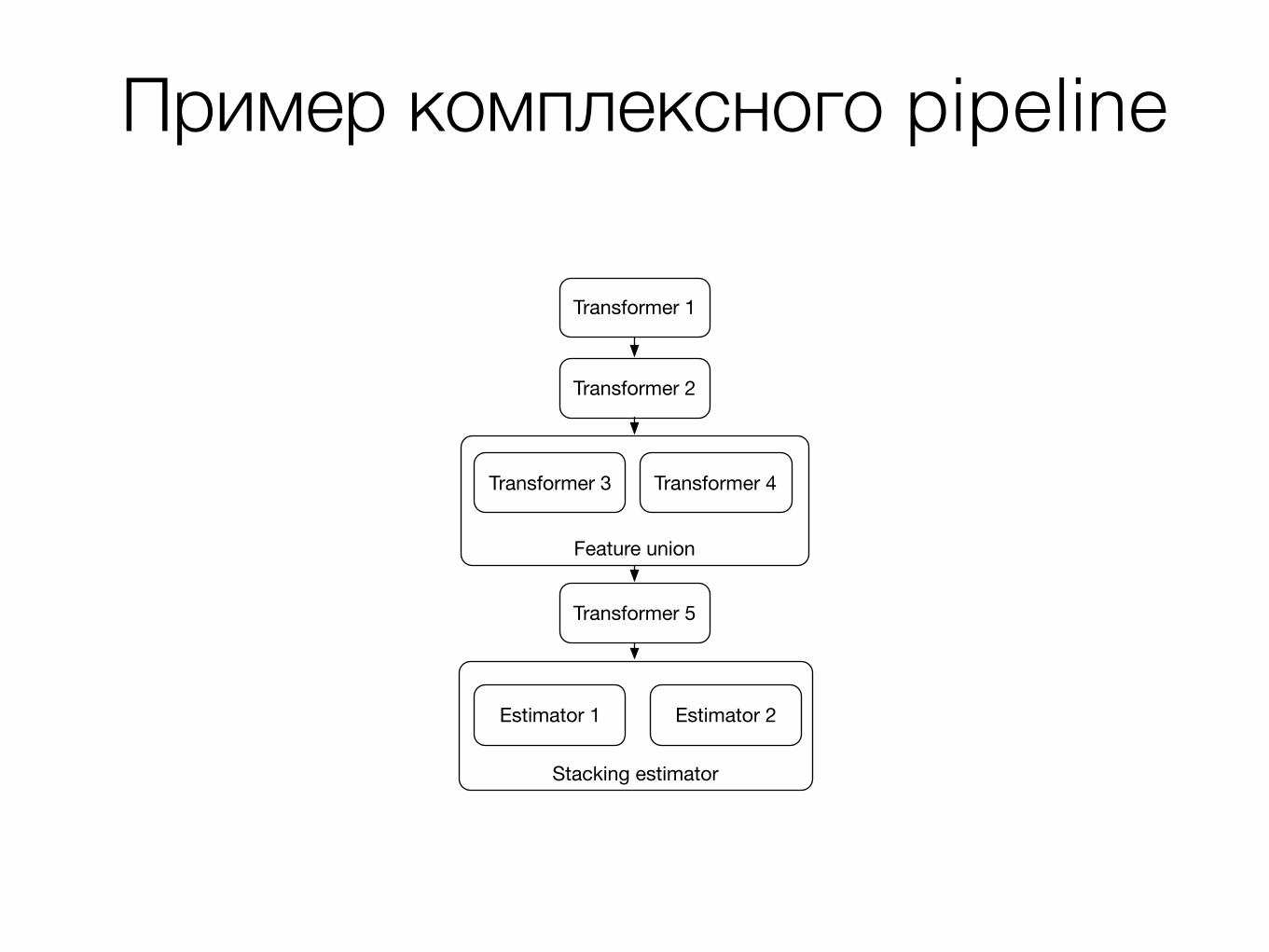
Пример комплексного pipeline
Transformer 5
Transformer 2
Transformer 1
Stacking estimator
Feature union
Transformer 3 Transformer 4
Estimator 1 Estimator 2

Зачем нужны pipelines
• Обученный pipeline - составная модель, которую легко сохранить и использовать в production
• Абстракция pipeline позволяет единообразно описывать, обучать и применять совершенно разные комплексные модели

“Show me the code”ds = pd.read_csv('titanic.csv')features = ds.drop(['survived', 'alive'], axis=1)
empty_space = FunctionTransformer( lambda x: x.replace(r'\s+', np.nan, regex=True), validate=False)df2dict = FunctionTransformer( lambda x: x.to_dict(orient='records'), validate=False)
pl = Pipeline([ ('empty_space', empty_space), ('to_dict', df2dict), ('dv', DictVectorizer(sparse=False)), ('na', Imputer(strategy='most_frequent')), ('gbt', GradientBoostingRegressor( n_estimators=100, learning_rate=0.02, random_state=1, max_depth=3))])
cv = cross_val_score(pl, features, ds.survived, cv=3, scoring='roc_auc')cv.mean(), cv.std()

Spark ML
• 2 версии API, новая версия с поддержкой pipelines появилась в Spark 1.6
• Реализации алгоритмов базируются на Spark RDD поэтому для обучения используются все узлы кластера
• например, в случае
• минимизации функции потерь
• расчета качества разбиения для вариантов ветвления в дереве

Spark ML pipelines
• Основаны на Spark DataFrames, вход и выход - колонка DataFrame
• Основные компоненты - Transfromer и Estimator аналогично sklearn
• Поддержка сохранения готовой модели в файл
• реализована для большинства моделей в Spark 2.0

Titanic Spark ML pipelineidxCols = [col+'Idx' for col in categoricalCols]
assembler = VectorAssembler( inputCols=idxCols + numCols, outputCol="features")
cl = GBTClassifier( labelCol="survived", maxIter=100, maxDepth=3, stepSize=0.02)
pl = Pipeline(stages=indexers + [assembler, cl])
sdf_fna = sdf.fillna(0).replace('', 'NA')train_df, test_df = sdf_fna.randomSplit([0.7, 0.3])
m = pl.fit(train_df)
predictions = m.transform(test_df)
evaluator = BinaryClassificationEvaluator( labelCol="survived", rawPredictionCol="prediction", metricName="areaUnderROC")
evaluator.evaluate(predictions)
ss = SparkSession.builder.getOrCreate()sdf = ss.read.csv('titanic.csv', header=True)
numCols = [ 'pclass', 'age', 'sibsp', 'parch', 'fare', 'alone']
for col in numCols: sdf = sdf.withColumn( col, sdf[col].astype('decimal'))
sdf = sdf.withColumn( 'survived', sdf['survived'].astype('int'))
categoricalCols =[ 'sex', 'embarked', 'class', 'deck', 'who', 'embark_town']
indexers = [ StringIndexer( inputCol=col, outputCol=col+'Idx', handleInvalid='skip') for col in categoricalCols]

Особенности Spark ML pipelines
• Estimators и Transformers возвращают {estimator}Model класс обученной модели после обучения
• StringIndexer достаточно для подготовки категориальных признаков для деревьев
• категориальные колонки помечаются специальным атрибутом
• в случае линейной модели необходим еще OneHotEncoder

Результат преобразования со StringIndexersi = StringIndexer(inputCol='in', outputCol='out')
rows = [ {'in': 'm'}, {'in': 'm'}, {'in': 'f'}, {'in': 'f'}, {'in': 'm'},]
df = ss.createDataFrame(rows)
si.fit(df).transform(df).toPandas()
in out
m 0.0
m 0.0
f 1.0
f 1.0
m 0.0

Практика использования Spark ML
• Not “Big Data” but “Big Computations”
• Выбор полиномиальных признаков c помощью линейной модели
• Выбор признаков с помощью Boruta в случае большого числа признаков
• Автоматический подбор параметров модели
• реализован только поиск по сетке

Выбор полиномиальных признаков c помощью линейной модели
• Много признаков - большой объем вычислений при обучении модели
• Обучение происходит параллельно с использованием всех узлов кластера (в отличие от sklearn, где обучение происходит в 1 поток)
• Spark сохраняет в памяти все варианты взаимодействий признаков, это нужно учесть при планировании потребления памяти

Создание полиномиальных признаков
pe = PolynomialExpansion(degree=2, inputCol='in', outputCol='out')
rows = [ {'in': Vectors.dense([2, 10, 20])},]
df = ss.createDataFrame(rows)
pe.transform(df).collect()[0].out.toArray()
array([ 2., 4., 10., 20., 100., 20., 40., 200., 400.])

Модель с полиномиальными признаками# only 2-category features can be used without binarizationcategoricalCols =['sex'] #,'embarked', 'class', 'deck', 'who', 'embark_town']
indexers = [ StringIndexer(inputCol=col, outputCol=col+'Idx', handleInvalid='skip') for col in categoricalCols]
idxCols = [col+'Idx' for col in categoricalCols]
numCols = ['pclass', 'age', 'sibsp', 'parch', 'fare', 'alone']
assembler = VectorAssembler( inputCols=idxCols + numCols, outputCol="features")
pe = PolynomialExpansion(degree=2, inputCol='features', outputCol='features_p')
cl = LogisticRegression(featuresCol='features_p', labelCol="survived", maxIter=10, regParam=0.1)
pl = Pipeline(stages=indexers + [assembler, pe, cl])
m = pl.fit(sdf.fillna(0).replace('', 'NA'))

Распечатка весов признаков
fnames = idxCols + numColspnames = [ n+'*'+n2 for i, n in zip(range(len(fnames)), fnames) for n2 in (['1']+fnames)[:i+2]]
weights = m.stages[-1].coefficients.array
pd.DataFrame( {'weights': weights, 'importance': np.abs(weights), 'names': pnames}).sort_values('importance', ascending=False)[:10]
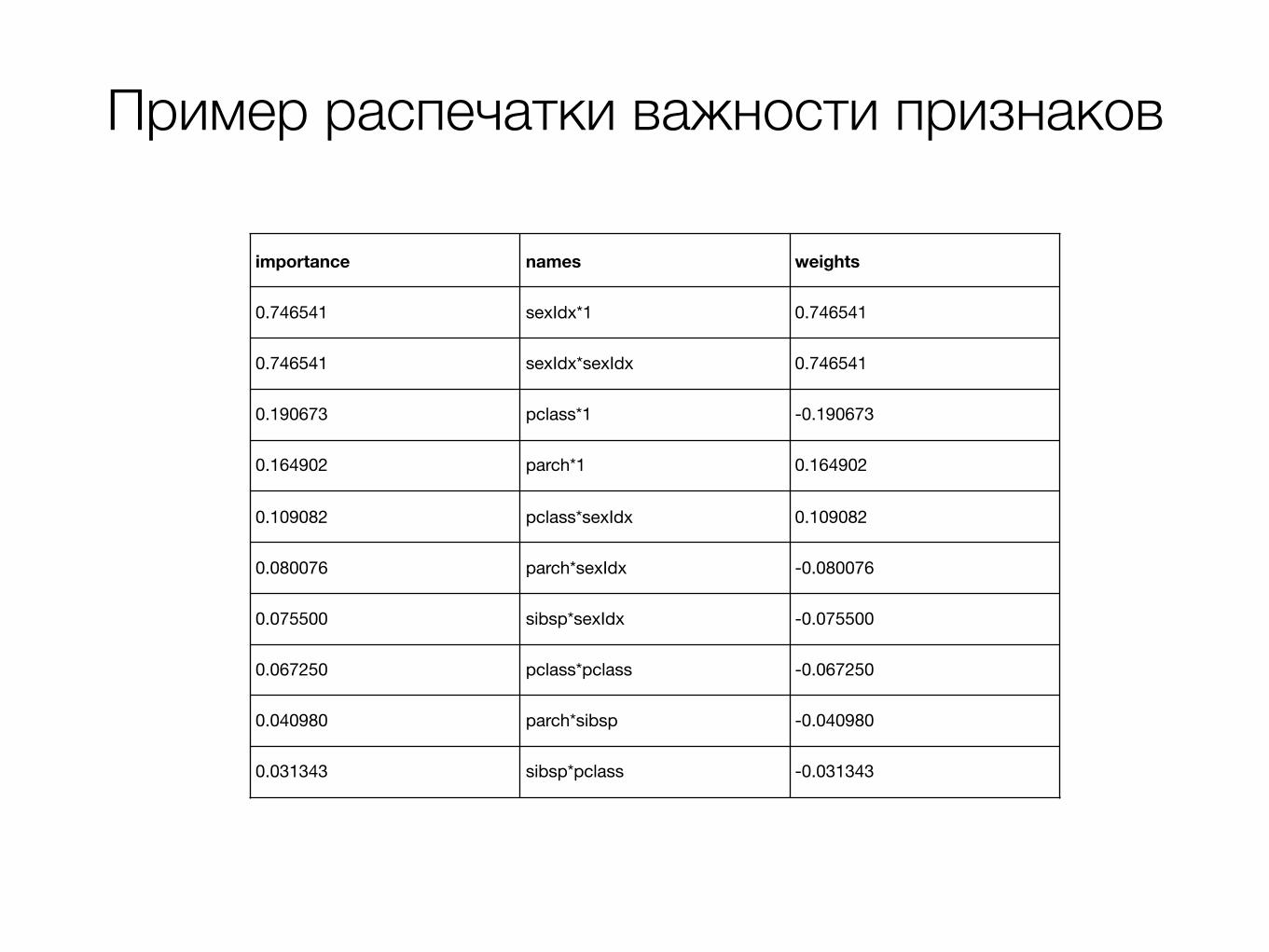
Пример распечатки важности признаков
importance names weights
0.746541 sexIdx*1 0.746541
0.746541 sexIdx*sexIdx 0.746541
0.190673 pclass*1 -0.190673
0.164902 parch*1 0.164902
0.109082 pclass*sexIdx 0.109082
0.080076 parch*sexIdx -0.080076
0.075500 sibsp*sexIdx -0.075500
0.067250 pclass*pclass -0.067250
0.040980 parch*sibsp -0.040980
0.031343 sibsp*pclass -0.031343

Автоматический подбор параметров модели
• Поиск по сетке
• Случайный поиск по сетке
• Tree-structured Parzen Estimator (Hyperopt)
• Gaussian process regression (Spearmint)
• Random forest regression (SMAC)
