meetup paris data classesfiles.meetup.com/18216091/meetup paris big data... · framework de...
TRANSCRIPT

Meetup Paris Data Classes
REX Spark/Cassandra
Add Intelligence to Data
21/10/2015

Qui somme nous ?
CIM by AID
Qu’est ce qu’il y a sous le capot
Apache Spark - Petit rappel
Quelques bonnes pratiques
Retours d’expérience
Conclusion
01
02
03
04
05
06
07.
11-11-15 Copyright 2015 2
AGENDA

Add intelligence to data
11-11-15 Copyright 2015 3

Chaîne de valeur complète autour de l’analyse, du traitement,
de l’exploitation, de la transformation et de la visualisation des données.
CRMGestion de base de données marketing
(B2B, B2C) clients, prospects,
Référentiel client unique,
Sirétisation, Pacitel
Data ScienceWebmining,
Segmentation, Scoring,
NLP, Plans Tests,
Migration outil
Customer Interaction
ManagementParcours-clients cross canal, DMP
Saas, Big et Smart Data, Tag
Management
Data QualityNormalisation, Enrichissement,
Géolocalisation, Data
Cleaning, Déduplication
Business IntelligenceData Visualisation,
Reporting
ConseilMarketing & Fidélisation,
Conseil Technologique, P.O.C.,
Gestion de projet
AID : DOMAINES D’EXPERTISES
11-11-15 Copyright 2015 4

Plus de 60 clients, tous secteurs confondus
ILS NOUS FONT CONFIANCE
11-11-15 Copyright 2015 5

Customer Interaction Management
by AID
11-11-15 Copyright 2015 6
MON CLIENT EST PASSÉ PAR ICI, IL REPASSERA PAR LÀ…
11-11-15 Copyright 2015 7
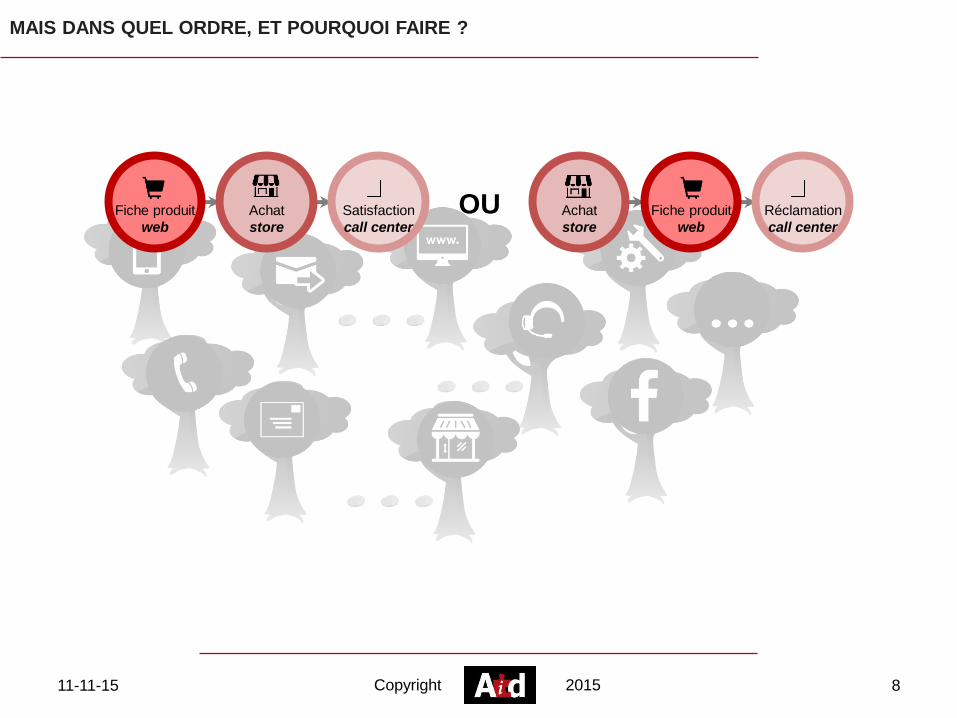
MAIS DANS QUEL ORDRE, ET POURQUOI FAIRE ?
Fiche produit
web
Achat
store
Satisfaction
call center
Achat
store
Fiche produit
web
Réclamation
call center
OU
11-11-15 Copyright 2015 8
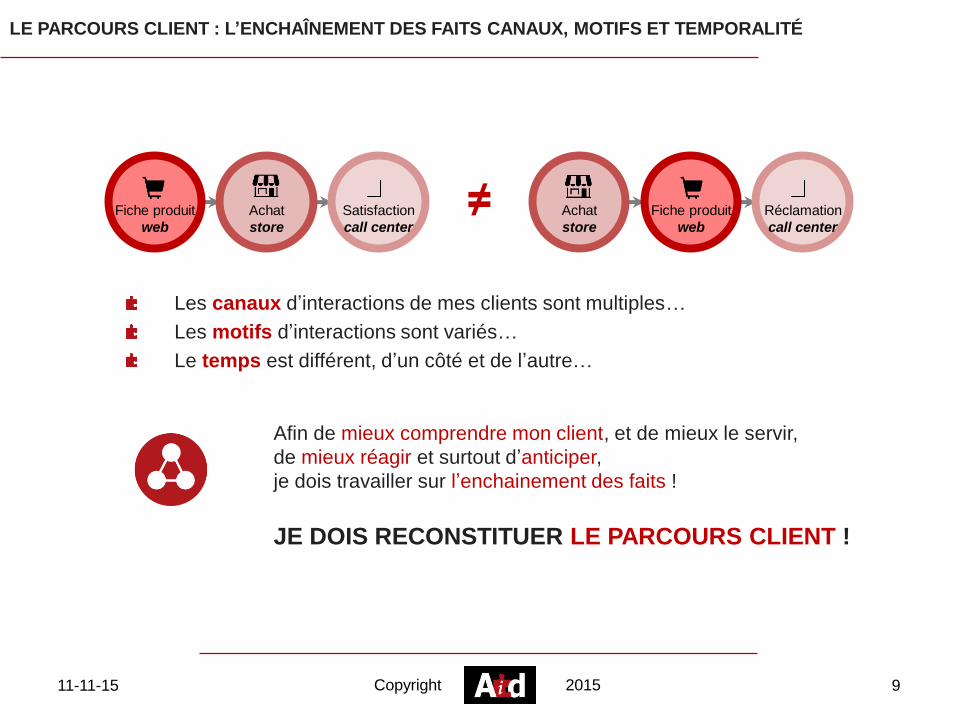
LE PARCOURS CLIENT : L’ENCHAÎNEMENT DES FAITS CANAUX, MOTIFS ET TEMPORALITÉ
Les canaux d’interactions de mes clients sont multiples…
Les motifs d’interactions sont variés…
Le temps est différent, d’un côté et de l’autre…
Afin de mieux comprendre mon client, et de mieux le servir,
de mieux réagir et surtout d’anticiper,
je dois travailler sur l’enchainement des faits !
JE DOIS RECONSTITUER LE PARCOURS CLIENT !
Fiche produit
web
Achat
store
Satisfaction
call center
Achat
store
Fiche produit
web
Réclamation
call center
≠
11-11-15 Copyright 2015 9

Tag Web
Achats magasins
Call center
SAV
Réseaux sociaux
Mobiles/beacon
Gestion de campagnes
NOTRE PLATEFORME DE VISUALISATION ET D’ANALYSE DES PARCOURS CLIENTS
Canaux d’interactions
Repositories
Data Warehouse Client (RCU, …)
DMP
Site Web
Call out
Réseaux sociaux
Notifications Mobiles
Canaux d’activation
Campagnes
Gestion de campagnes
RTBCIM by AID
connexions à vos environnements, par canal ou
réconciliés
11-11-15 Copyright 2015 10

1 2 4
Identifier les pain
points des parcours de
vos clients
Mettre en œuvre les
données nécessaires
dans l’outil
Mesurer les résultats
dans l’outil
3
Analyser et actionner
les parcours gagnants
CIM by AID : Notre démarche itérative de création de valeur
11-11-15 Copyright 2015 11

03. Qu’est ce qu’il y a sous le capot
11-11-15 Copyright 2015 12

Modularité : Capacité à découpler les modules de traitement pour
profiter pleinement des évolutions technologiques
Temps réel : Valeur d’une données fortement liée son « age »
Scalabilité : Capacité à monter en puissance
Open Source : Pour ne pas être dépendant des modèles de licence
STACK TECHNIQUE : CRITÈRES DE CHOIX
11-11-15 Copyright 2015 13
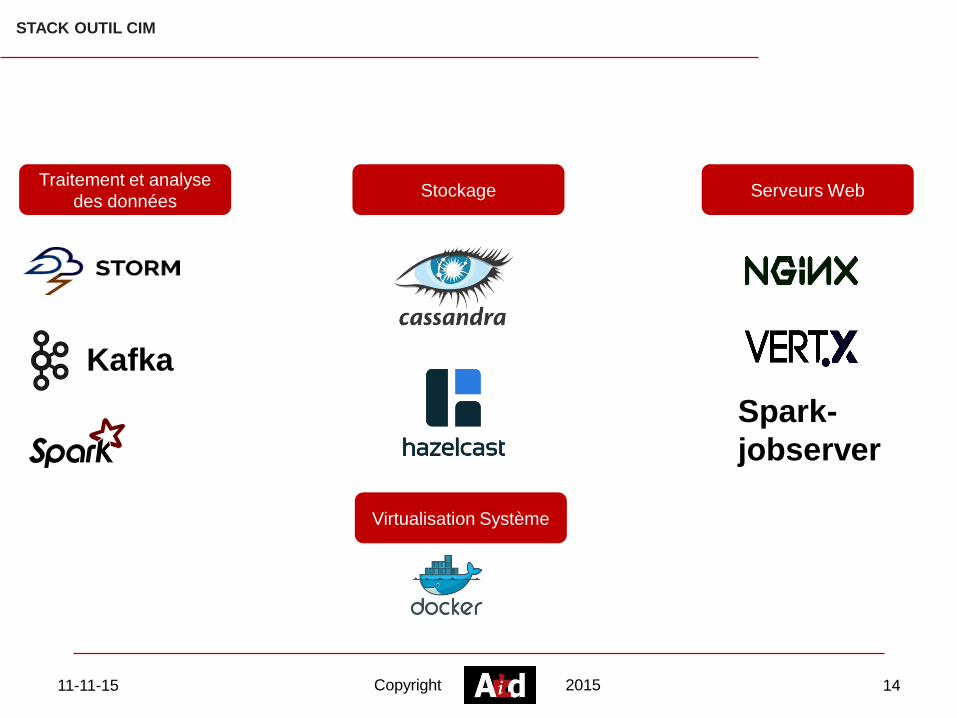
STACK OUTIL CIM
Traitement et analyse
des données Stockage Serveurs Web
Virtualisation Système
Kafka
11-11-15 Copyright 2015 14
Spark-
jobserver

STACK PRODUCTION
Intégration continue
Automatisation des déploiement
Virtualisation Logicielle
Surveillance
11-11-15 Copyright 2015 15

04. Apache Spark
11-11-15 Copyright 2015 16

Framework de développement pour traiter de gros volumes
de données de manière distribuée.
• Open Source : Produit du laboratoire AMPLab de
l’université de Berkeley
• En développement depuis 2009 :
• 06/2013 : Projet prioritaire APACHE
• 04/2014 : Version 1.0
• 10/2015 : Version 1.5
11-11-15 Copyright 2015 17
APACHE SPARK – QUÈSACO ?
Qu’est ce que c’est ?
Interfaces Développé en SCALA
API : Scala, Python, Java et R
In-Memory : Les données restent mémoire, permettant une exécution plus rapide
des calculs
Plan d’exécution : permet d’optimiser les calculs itératifs (particulièrement utile pour
les algorithmes de machine learning)
11-11-15 Copyright 2015 18
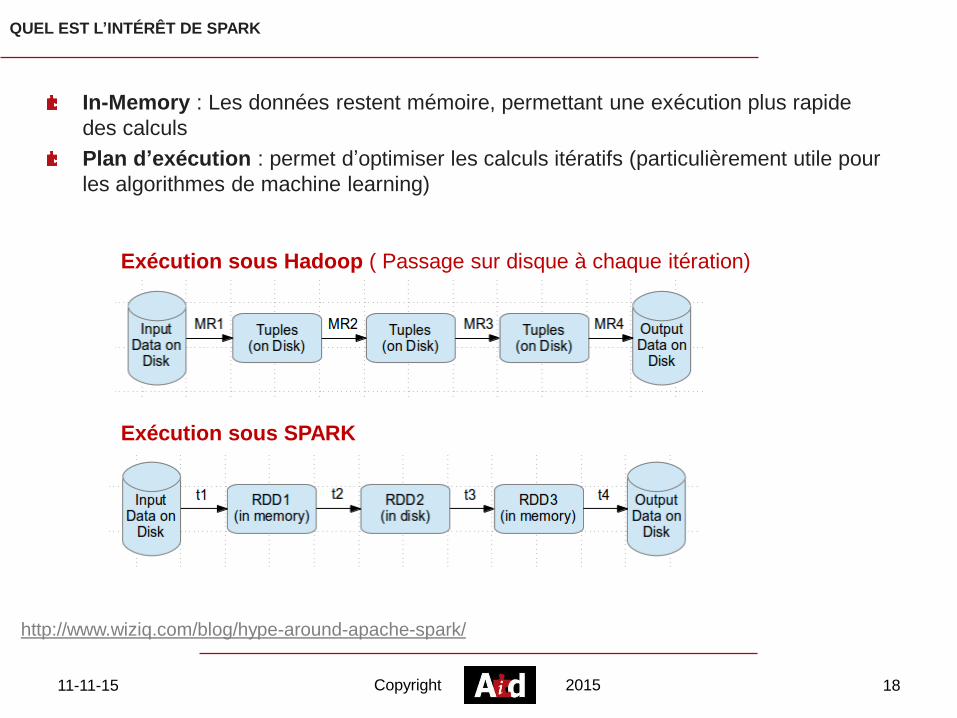
QUEL EST L’INTÉRÊT DE SPARK
http://www.wiziq.com/blog/hype-around-apache-spark/
Exécution sous Hadoop ( Passage sur disque à chaque itération)
Exécution sous SPARK
11-11-15 Copyright 2015 19
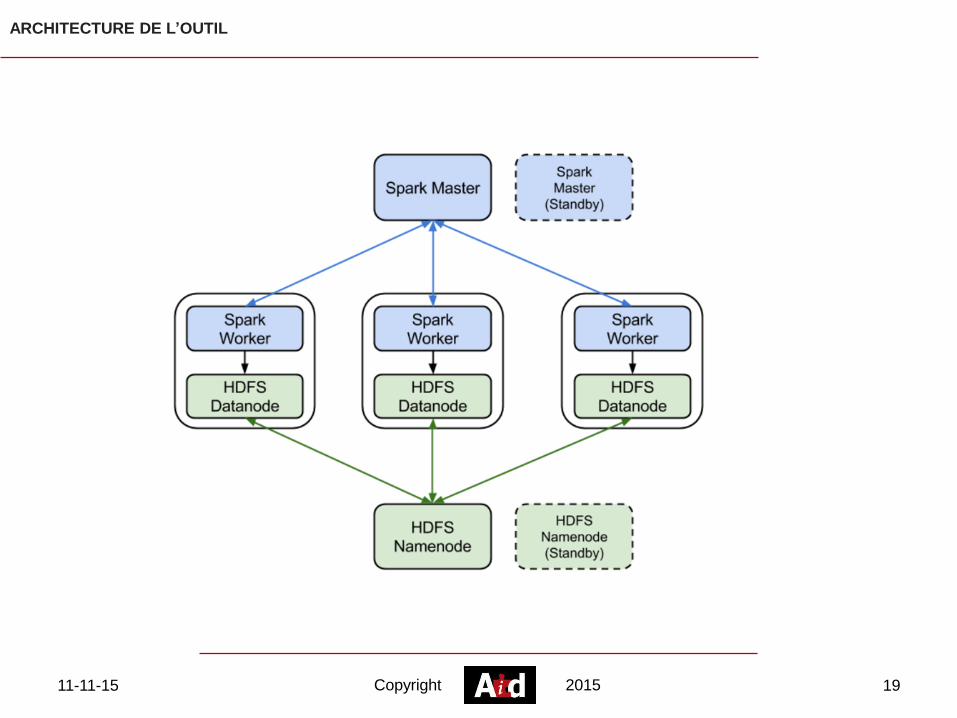
ARCHITECTURE DE L’OUTIL

11-11-15 Copyright 2015 20
2 CAS D’USAGES
Spark-Shell Spark Application
• Interface interactive
• Utile pour l’exploration analyse de
données
• Disponible en Python, Scala et R
(beta)
• Traitement industriel des données
• Jar compilés
• Disponible en Scala, Java et Python

Resilient Distributed Dataset (RDD)
• Immutable
• Distribué
• Tolérant aux pannes
• Persiste les résultats intermédiaires en mémoire.
Data Frames
• Distribué
• Organisé en colonnes/avec un schéma
• Permet d’exécuter des requêtes SQL
11-11-15 Copyright 2015 21
SPARK – STRUCTURE DE DONNÉES 1/2

11-11-15 Copyright 2015 22
SPARK – STRUCTURE DE DONNÉES 2/2
RDD
Data frame
11-11-15 Copyright 2015 23
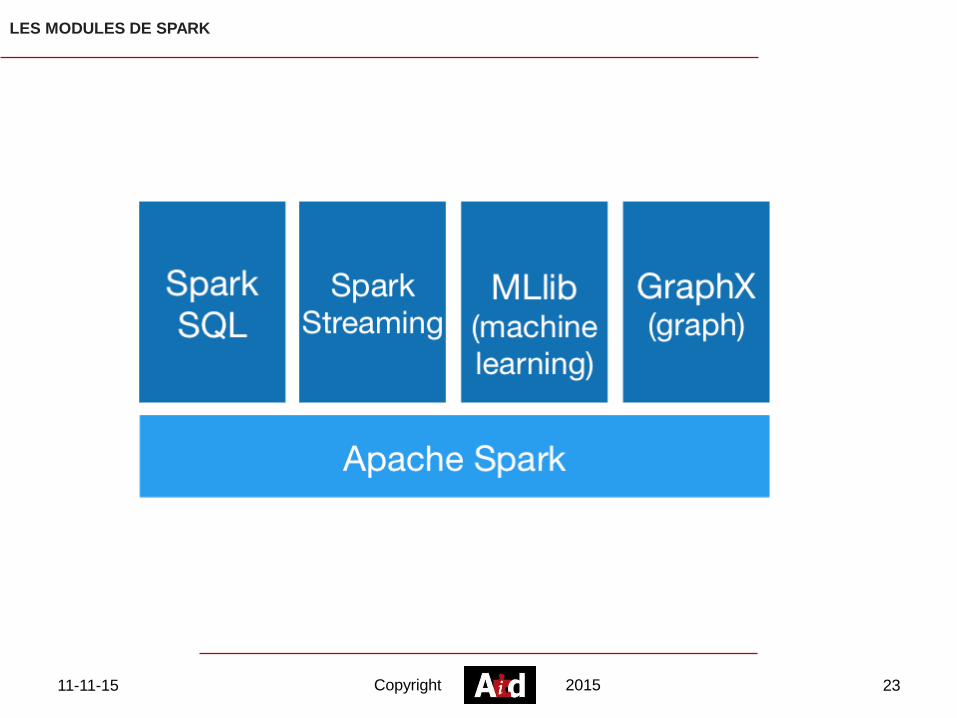
LES MODULES DE SPARK
11-11-15 Copyright 2015 24
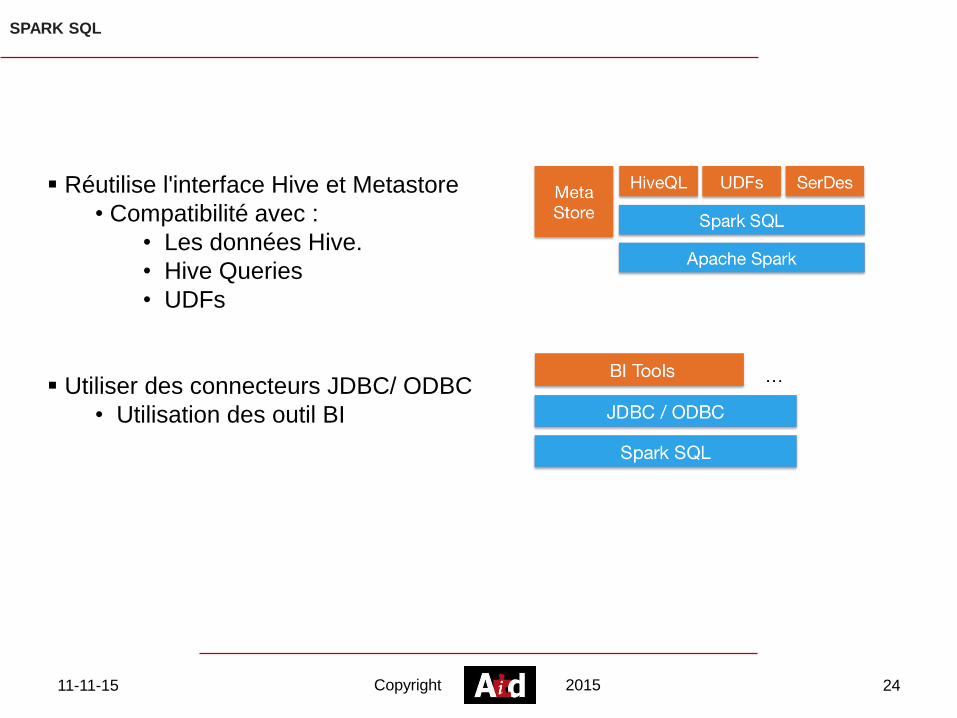
SPARK SQL
Réutilise l'interface Hive et Metastore
• Compatibilité avec :
• Les données Hive.
• Hive Queries
• UDFs
Utiliser des connecteurs JDBC/ ODBC
• Utilisation des outil BI

11-11-15 Copyright 2015 25
MLLIB
Une bibliothèque d’algorithme de machine Learning distribué
régression logistique et linéaire machine à vecteurs de support (SVM)
classification
Arbre de décision, forêt aléatoire et arbres de gradient boosté
recommandation par alternance moindres carrés (SLA)
… etc
11-11-15 Copyright 2015 26
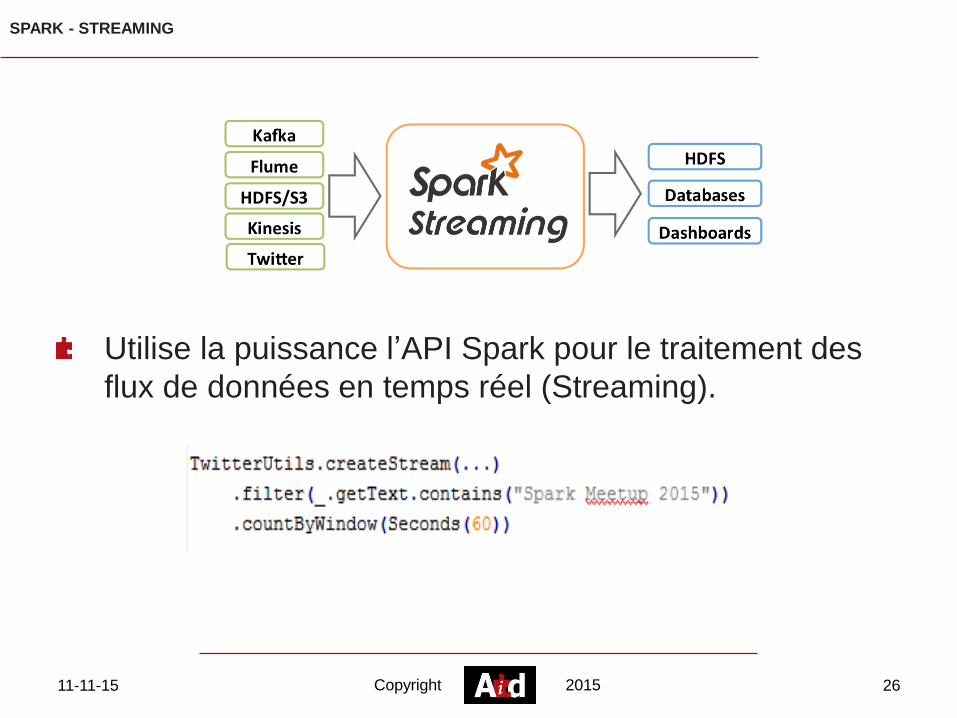
SPARK - STREAMING
Utilise la puissance l’API Spark pour le traitement des
flux de données en temps réel (Streaming).

11-11-15 Copyright 2015 27
GRAPHX
Un API de Spark qui permet de manipuler les Graphes

11-11-15 Copyright 2015 28
CONNECTEURS
Spark fonctionne dans un environnement :
- Hadoop
- Mesos
- Standalone
Spark peut se connecter à :
- Cassandra
- HDFS
- Hbase
- Hive
- …etc
11-11-15 Copyright 2015 29
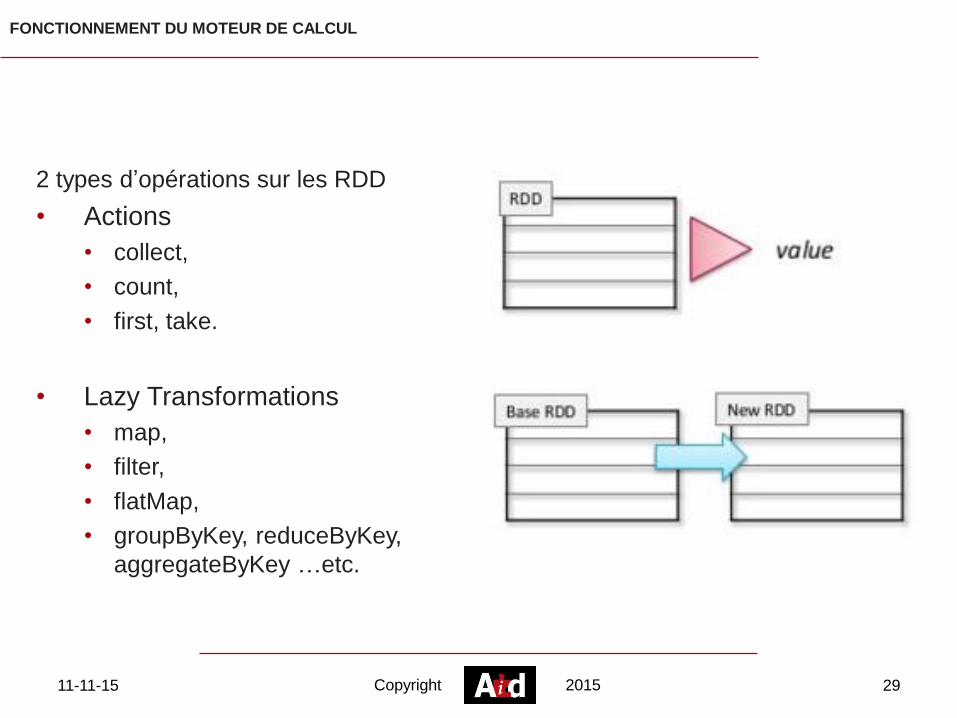
FONCTIONNEMENT DU MOTEUR DE CALCUL
2 types d’opérations sur les RDD
• Actions
• collect,
• count,
• first, take.
• Lazy Transformations
• map,
• filter,
• flatMap,
• groupByKey, reduceByKey,
aggregateByKey …etc.

Data Frame (depuis 1.3)
Spark R (depuis 1.4)
Machine Learning
11-11-15 Copyright 2015 30
NOUVEAUTÉS NOTABLE DEPUIS LE DÉBUT DE L’ANNÉE
=> Manipulation des données via SQL
API pour exploiter les fonctionnalités de
calcul distribué directement depuis R
Fort enrichissement de la bibliothèques
d’ Algorithmes
Ex : Apparition d’algo d’analyse de
séquences (PrefixSpan)

05. Bonnes Pratiques
11-11-15 Copyright 2015 31

=> Utiliser les fonctions natives du connecteur
• repartitionByCassandraReplica()
• joinWithCassandraTable()
=> Cache
• MEMORY_ONLY
• MEMORY_AND_DISK
• MEMORY_ONLY …etc
=> gestion de la mémoire
• spark.executor.memory
• spark.shuffle.memoryFraction: default of 0.2
• spark.storage.memoryFraction
11-11-15 Copyright 2015 32
BONNES PRATIQUES
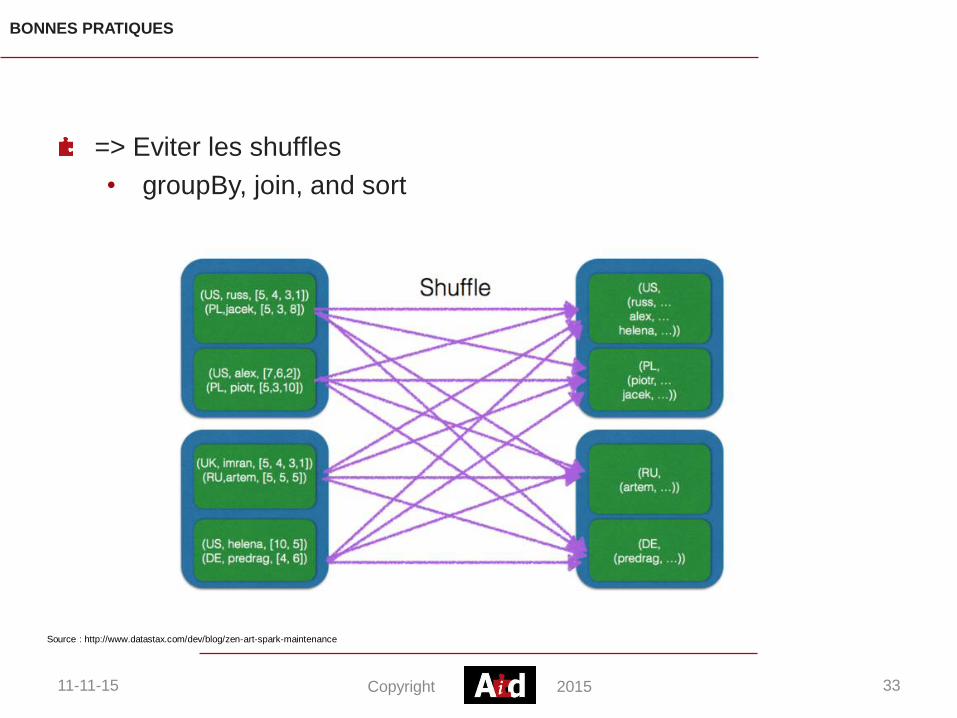
=> Eviter les shuffles
• groupBy, join, and sort
11-11-15 Copyright 2015 33
BONNES PRATIQUES
Source : http://www.datastax.com/dev/blog/zen-art-spark-maintenance

=> Thread Safe !!!
• Joda Time Vs Java util Date
=> Prb - Sérialisation
• Serialisateur par defaut de Spark VS
• org.apache.spark.serializer.KryoSerializer
=> Gestion des valeurs nulles
• Option[]
11-11-15 Copyright 2015 34
BONNES PRATIQUES

06. Retour d’expérience
11-11-15 Copyright 2015 35

Ex : Choix des outils pour l’exécution de l’analyse du parcours client
Phase 1 : Hbase + Hadoop => Distrib Cloudera
Phase 2 : Hbase + Hadoop => Distrib HortonWork
Phase 3 : Hbase + SPARK - pas de distrib
Phase 4 : Cassandra + SPARK - pas de distrib
CHOIX DES OUTILS
Beaucoup de nouveaux outils et pleins de nouvelles promesses
Mais qui ont leurs limites
Processus itératif composé de nombreux essais
11-11-15 Copyright 2015 36

Ex : Soumission de Job Spark depuis une application WEB
INTÉGRATION
Individuellement les outils sont relativement faciles à prendre en main
Les difficultés commencent quand on veut les faire marcher entre eux
11-11-15 Copyright 2015 37
11-11-15 Copyright 2015 38
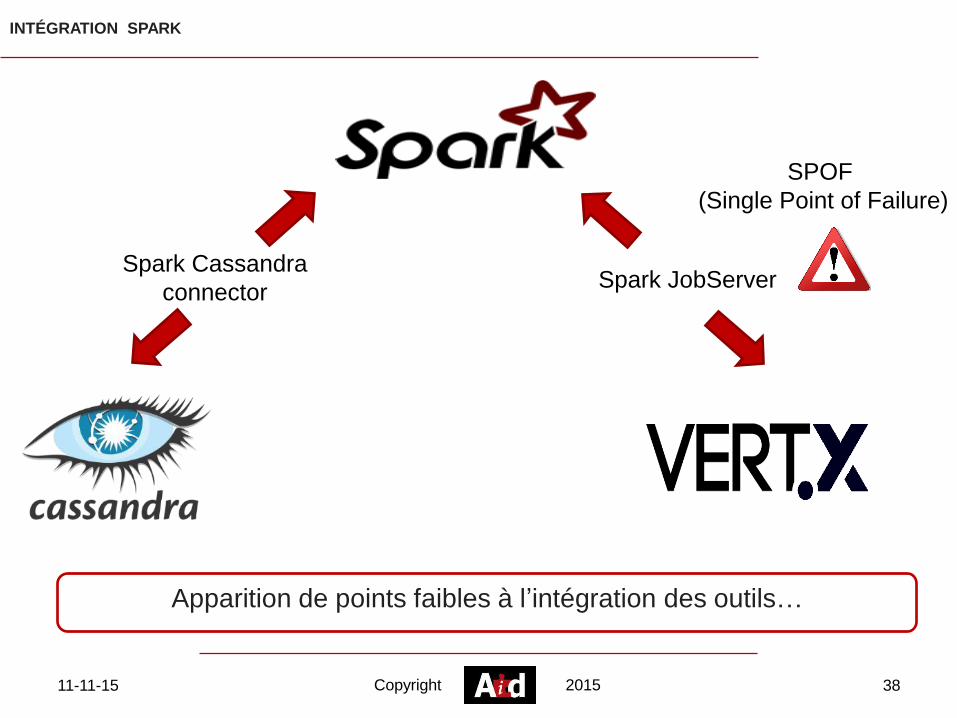
INTÉGRATION SPARK
Spark Cassandra
connectorSpark JobServer
SPOF
(Single Point of Failure)
Apparition de points faibles à l’intégration des outils…

Outils « Big Data » encore jeunes => Evolution Fréquentes
=> Compétences rares
=> Documentation parfois un peu faible
Nécessitant une montée en => Maitrise du fonctionnement interne requise pour
compétence être pleinement exploité.
(Paramétrage par défaut insuffisant)
Montée de version à surveiller => Pas toujours rétro compatible
MISE EN PRODUCTION
Plus complexe qu’il n’y parait
11-11-15 Copyright 2015 39
RH
Equipe pluri-disciplinaire
Dev JAVA Data Scientist
Ingénieur
Système

07. Conclusion
11-11-15 Copyright 2015 41

11-11-15 Copyright 2015 42
SPARK - PRISE EN MAIN FACILE …. MAIS
- Un outil puisant et plein de promesse
- Traitement des données
- Machine Learning
- Analyse
- Relativement facile à prendre en main
=> notamment grâce à Spark Shell
- Optimisation parfois complexe
Besoin de rentrer dans le détail du fonctionnement de l’outil
- Attention à la gestion de la mémoire
- Gestion de la volumétrie : travail / optim par palier
ex : V1 – OK jusqu’à 1=100 M lignes
V2 – OK jusqu’à 1=150 M lignes
Actuellement travail sur V3 pour dépasser 300 M lignes
Mais…

Merci de votre attention !
en direct4 rue Henri Le Sidaner
78 000 Versailles, France
01 39 23 93 00
chez nouswww.aid.fr
Cim.aid.fr
Twitter : @aid_agency
@arnaudcontival
Linkedin : AID
sur nos réseauxMatthieu Lamairesse Resp.
Technique
Yoran de Gouvello Directeur
big data et CIM
Pour nous contacter

Université de Berkeley :
• https://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
http://spark.apache.org/docs
Learning Spark: Lightning-Fast Big Data Analytics, O'Reilly.
Modules complémentaires SPARK : http://spark-packages.org/
SOURCES