lecture 02: technology trends and quantitative design and ... · •system software –compiler:...
TRANSCRIPT

Lecture02:TechnologyTrendsandQuantitativeDesignandAnalysisfor
Performance
CSCE513ComputerArchitectureDepartmentofComputerScienceandEngineering
Yonghong [email protected]
http://cse.sc.edu/~yanyh
1

Contents
• Computercomponents• Computerarchitecturesandgreatideasincomputerarchitectures
• TrendsandPerformance
2

ComputerArchitecture
• Coversthreeaspectsofcomputerdesign– Instructionsetarchitecture
• Softwareandhardwareinterfaces– Organizationormicroarchitecture
• CPU,memory,cachearchitecture– Hardware
• Computersystems,e.g.I/Odevices
3

LevelsofProgramCode
• High-levellanguage– Levelofabstractionclosertoproblemdomain
– Providesforproductivityandportability
• Assemblylanguage– Textualrepresentationofinstructions
• Hardwarerepresentation– Binarydigits(bits)– Encodedinstructionsanddata
4
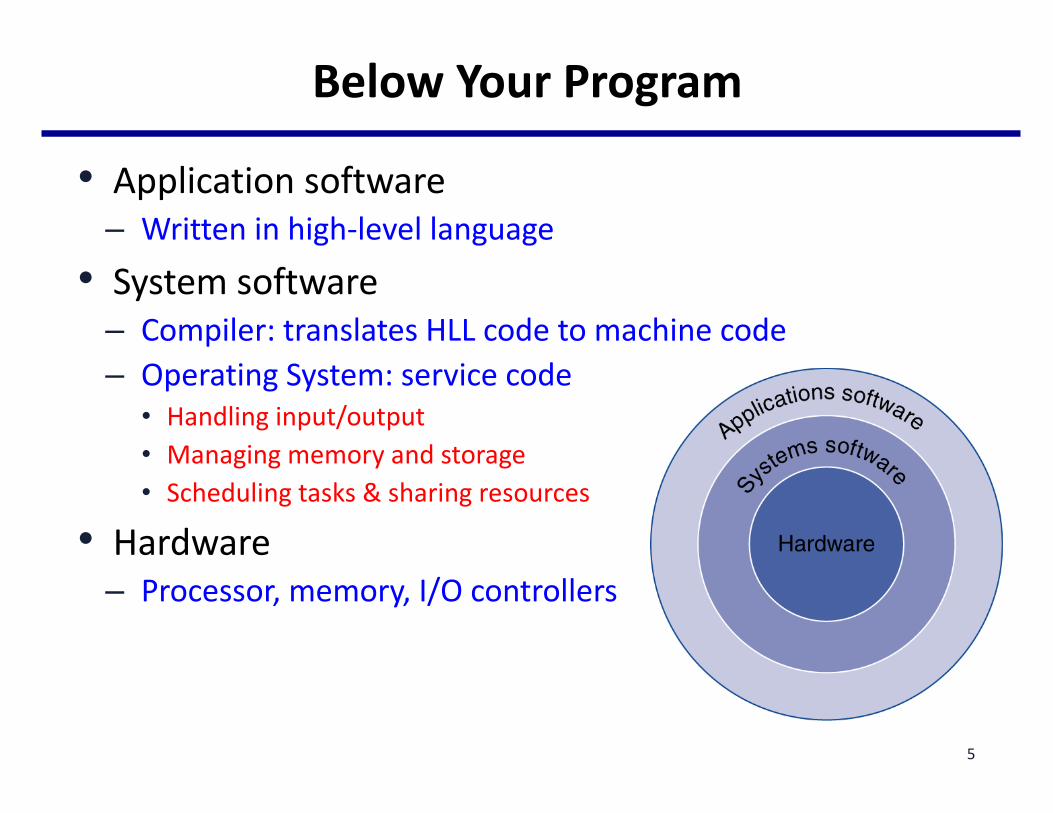
BelowYourProgram
• Applicationsoftware– Writteninhigh-levellanguage
• Systemsoftware– Compiler:translatesHLLcodetomachinecode– OperatingSystem:servicecode
• Handlinginput/output• Managingmemoryandstorage• Schedulingtasks&sharingresources
• Hardware– Processor,memory,I/Ocontrollers
5
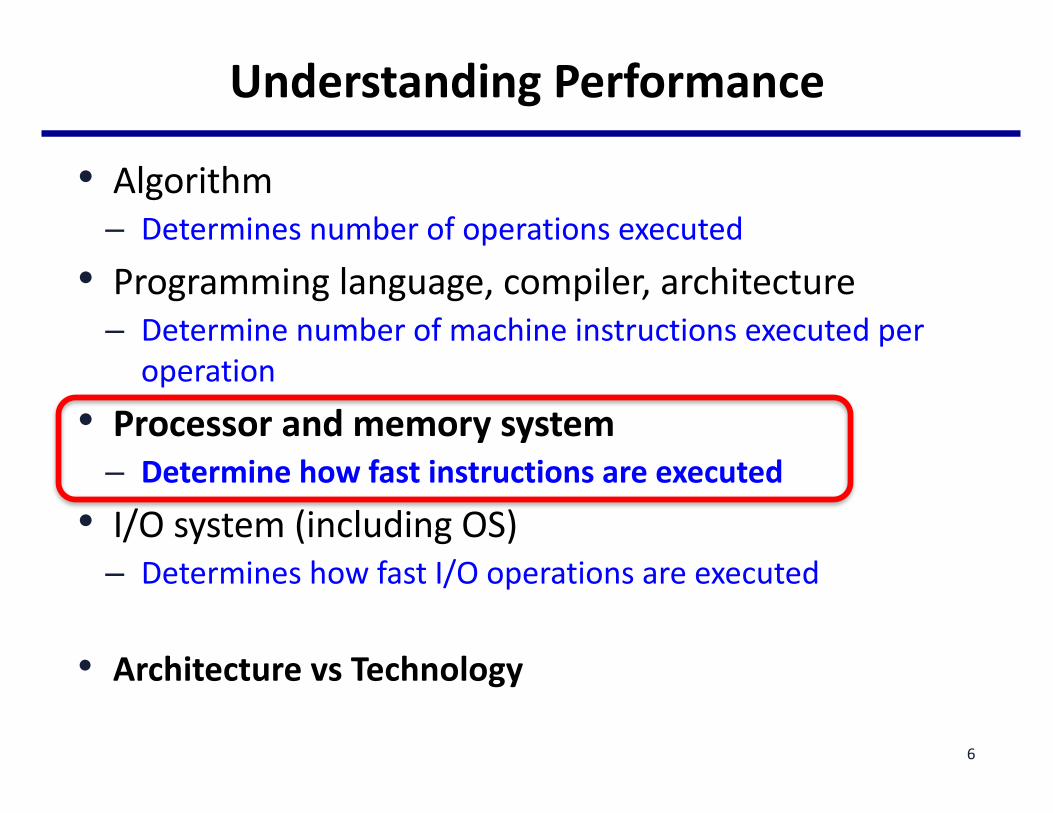
UnderstandingPerformance
• Algorithm– Determinesnumberofoperationsexecuted
• Programminglanguage,compiler,architecture– Determinenumberofmachineinstructionsexecutedper
operation• Processorandmemorysystem
– Determinehowfastinstructionsareexecuted• I/Osystem(includingOS)
– DetermineshowfastI/Ooperationsareexecuted
• ArchitecturevsTechnology
6
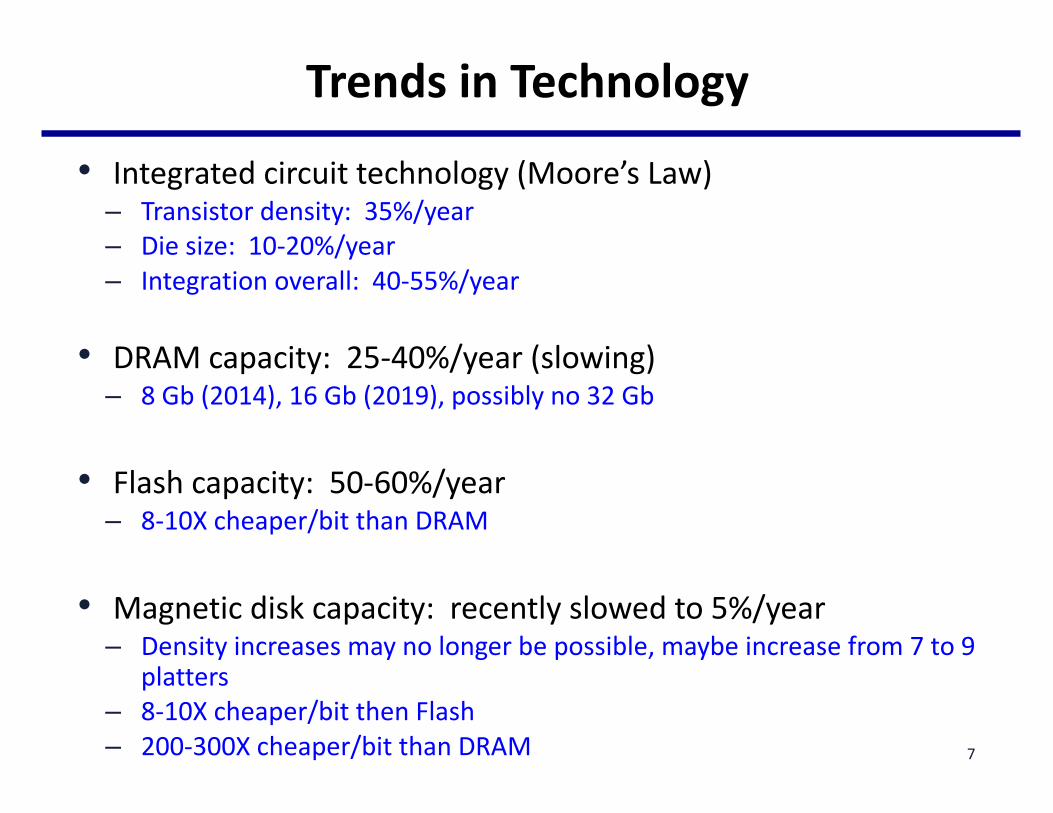
TrendsinTechnology
• Integratedcircuittechnology(Moore’sLaw)– Transistordensity:35%/year– Diesize:10-20%/year– Integrationoverall:40-55%/year
• DRAMcapacity:25-40%/year(slowing)– 8Gb(2014),16Gb(2019),possiblyno32Gb
• Flashcapacity:50-60%/year– 8-10Xcheaper/bitthanDRAM
• Magneticdiskcapacity:recentlyslowedto5%/year– Densityincreasesmaynolongerbepossible,maybeincreasefrom7to9
platters– 8-10Xcheaper/bitthenFlash– 200-300Xcheaper/bitthanDRAM 7

BandwidthandLatency
• Bandwidthorthroughput– Totalworkdoneinagiventime– 10,000-25,000Ximprovementfor
processors– 300-1200Ximprovementfor
memoryanddisks
• Latencyorresponsetime– Timebetweenstartandcompletionofanevent– 30-80Ximprovementforprocessors– 6-8Ximprovementformemoryanddisks
8

MeasuringPerformance
• Typicalperformancemetrics:– Responsetime– Throughput
• SpeedupofXrelativetoY:ExecutiontimeY /ExecutiontimeX– Example:timetakentorunaprogram,10sonX,15sonY– Speedup:15s/10s=1.5,à Xis1.5fasterthanY
• Executiontime– Wallclocktime:includesallsystemoverheads(I/O,swapping,etc)– CPUtime:onlycomputationtime
• Benchmarks– Kernels(e.g.matrixmultiply)– Toyprograms(e.g.sorting)– Syntheticbenchmarks(e.g.Dhrystone)– Benchmarksuites(e.g.SPEC06fp,TPC-C)
9

MeasuringExecutionTime1/2
• Elapsedtime– Totalresponsetime,includingallaspects
• Processing,I/O,OSoverhead,idletime– Determinessystemperformance
• CPUtime
10
https://passlab.github.io/CSCE513/exercises/sum/sum_full.c

MeasuringExecutionTime2/2
• Elapsedtime• CPUtime
– Timespentprocessingagivenjob• DiscountsI/Otime,otherjobs’shares
– ComprisesuserCPUtimeandsystemCPUtime– DifferentprogramsareaffecteddifferentlybyCPUandsystem– “time”commandinLinux
11
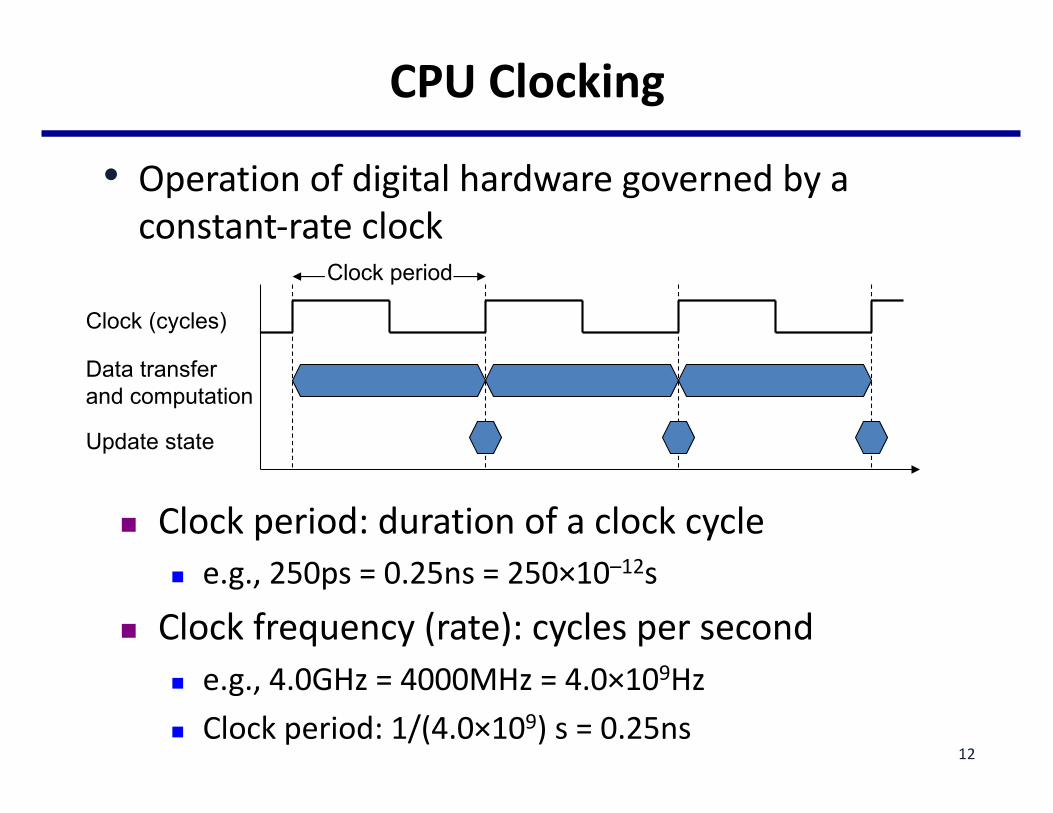
CPUClocking
• Operationofdigitalhardwaregovernedbyaconstant-rateclock
Clock (cycles)
Data transferand computation
Update state
Clock period
n Clockperiod:durationofaclockcyclen e.g.,250ps=0.25ns=250×10–12s
n Clockfrequency(rate):cyclespersecondn e.g.,4.0GHz=4000MHz=4.0×109Hzn Clockperiod:1/(4.0×109)s=0.25ns
12
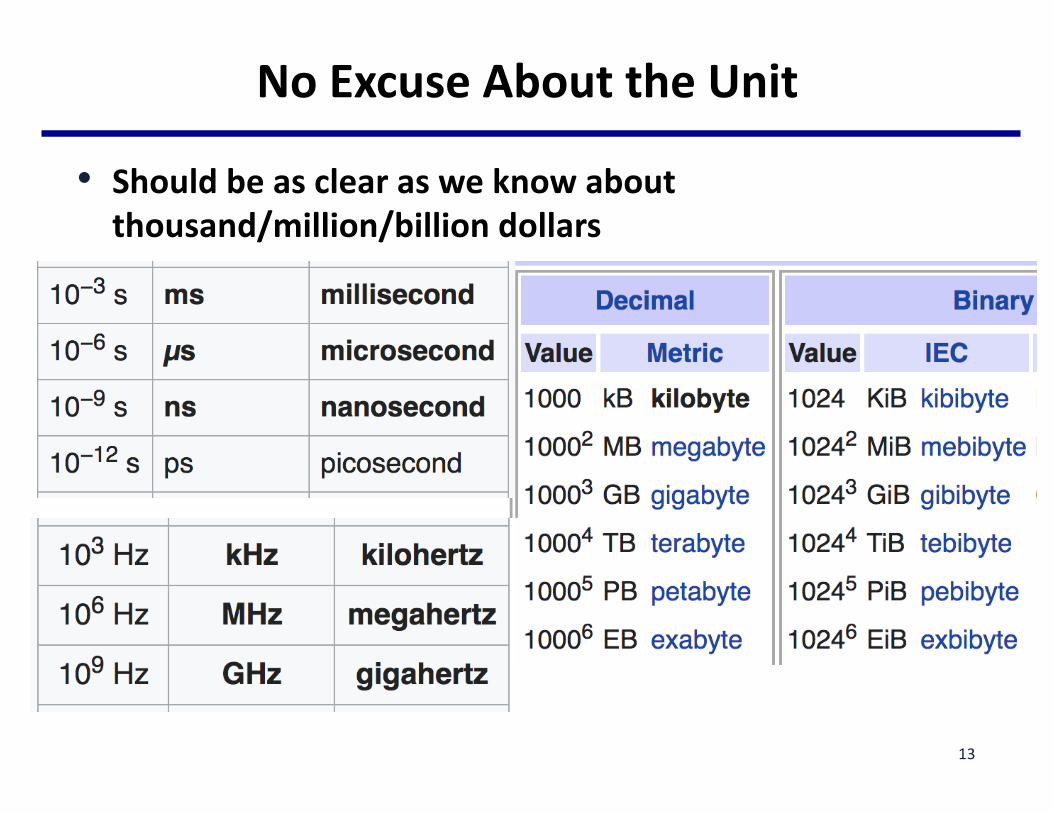
NoExcuseAbouttheUnit
• Shouldbeasclearasweknowaboutthousand/million/billiondollars
13
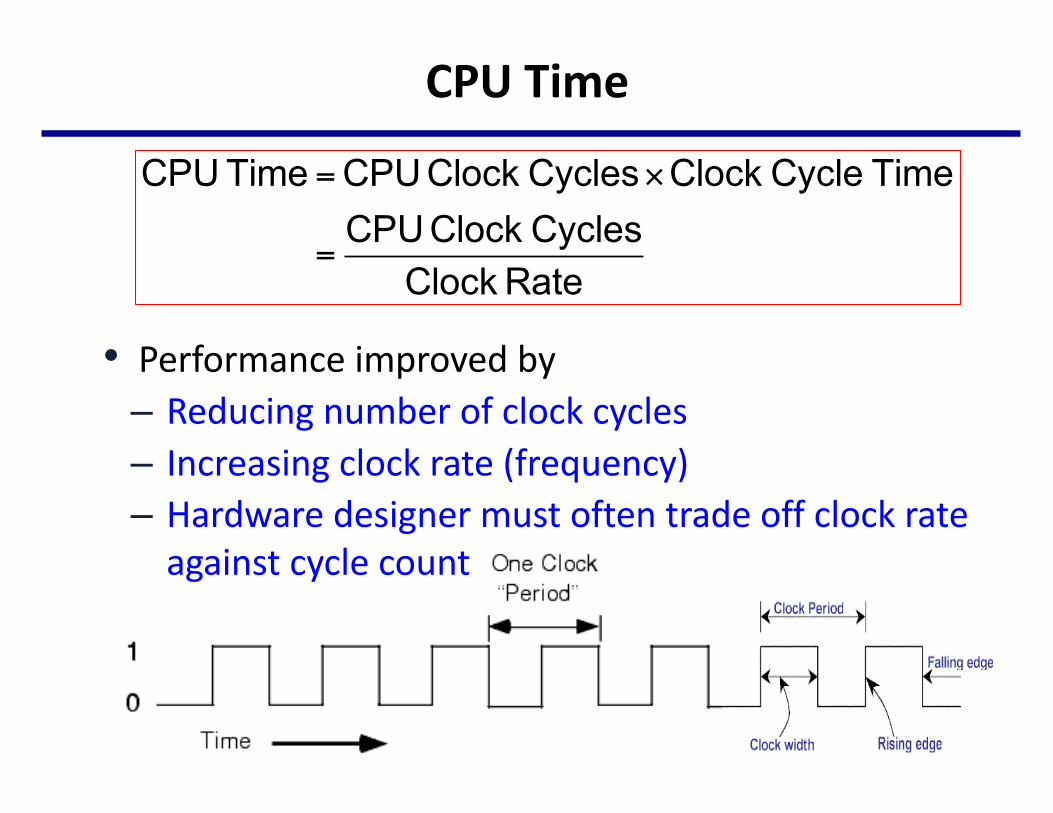
CPUTime
• Performanceimprovedby– Reducingnumberofclockcycles– Increasingclockrate(frequency)– Hardwaredesignermustoftentradeoffclockrateagainstcyclecount
CPU Time =CPU Clock Cycles×Clock Cycle Time
=CPU Clock Cycles
Clock Rate
14

CPUTimeExample
• ComputerA:2GHzclock,10sCPUtime• DesigningComputerB
– Aimfor6sCPUtime– Candofasterclock,butcauses1.2× clockcyclesofA
• HowfastmustComputerBclockbe?
Clock RateB =Clock CyclesB
CPU TimeB
=1.2×Clock CyclesA
6sClock CyclesA =CPU TimeA ×Clock RateA
=10s×2GHz = 20×109
Clock RateB =1.2×20×109
6s=
24×109
6s= 4GHz
15

InstructionCountandCPI
• InstructionCountforaprogram– Determinedbyprogram,ISAandcompiler
• Averagecyclesperinstruction– DeterminedbyCPUhardware– IfdifferentinstructionshavedifferentCPI
• AverageCPIaffectedbyinstructionmix
Rate ClockCPICount nInstructio
Time Cycle ClockCPICount nInstructioTime CPU
nInstructio per CyclesCount nInstructioCycles Clock
´=
´´=
´=
16

CPIExample
• ComputerA:CycleTime=250ps,CPI=2.0• ComputerB:CycleTime=500ps,CPI=1.2• SameISA• Whichisfaster,andbyhowmuch?
1.2500psI600psI
ATime CPUBTime CPU
600psI500ps1.2IBTime CycleBCPICount nInstructioBTime CPU
500psI250ps2.0IATime CycleACPICount nInstructioATime CPU
=´´
=
´=´´=
´´=
´=´´=
´´=
Aisfaster…
…bythismuch
17

CPIinMoreDetail
• Ifdifferentinstructionclassestakedifferentnumbersofcycles
• WeightedaverageCPI
å=
´=n
1iii )Count nInstructio(CPICycles Clock
å=
÷øö
çèæ ´==
n
1i
ii Count nInstructio
Count nInstructioCPICount nInstructio
Cycles ClockCPI
Relative frequency
18

CPIExample
• AlternativecompiledcodesequencesusinginstructionsinclassesA,B,C
Class A B CCPI for class 1 2 3
IC in sequence #1 2 1 2IC in sequence #2 4 1 1
n Sequence#1:IC=5n ClockCycles=2×1+1×2+2×3=10
n Avg.CPI=10/5=2.0
n Sequence#2:IC=6n ClockCycles=4×1+1×2+1×3=9
n Avg.CPI=9/6=1.5
19
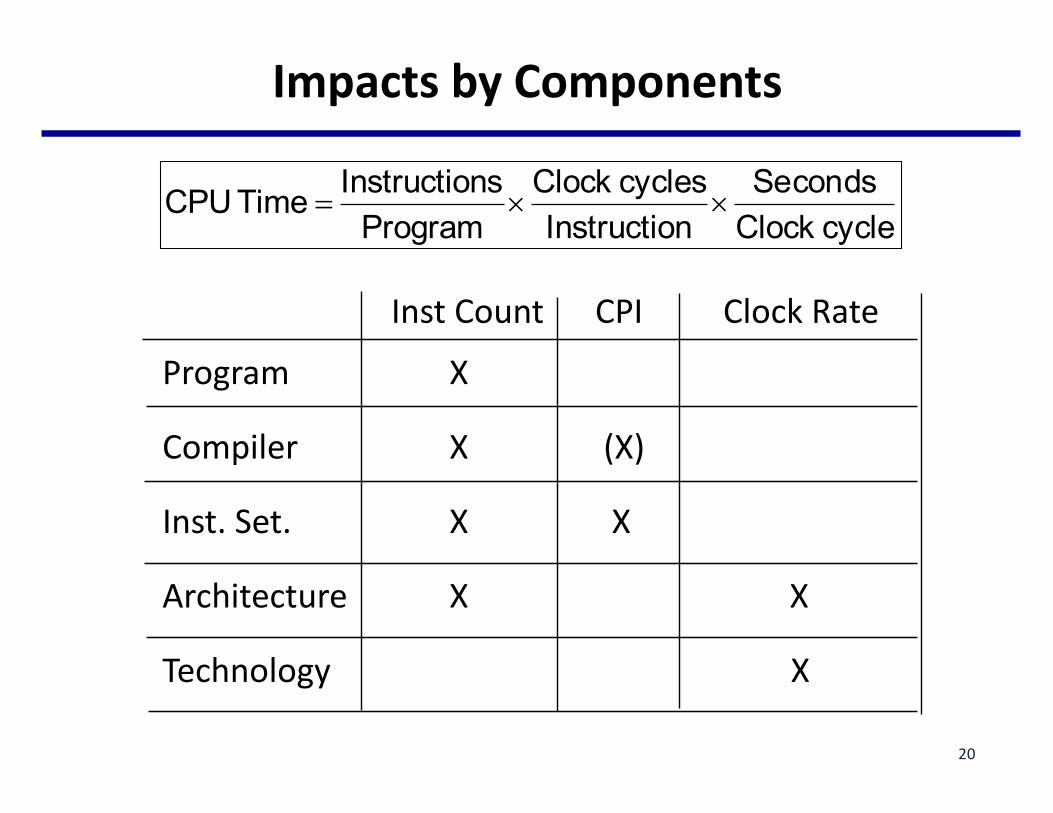
ImpactsbyComponents
Inst Count CPI ClockRate
Program X
Compiler X (X)
Inst.Set. X X
Architecture X X
Technology X
20
cycle ClockSeconds
nInstructiocycles Clock
ProgramnsInstructioTime CPU ´´=

ProcessorPerformanceEquationSummary
21

PrinciplesofComputerDesign
• TakeAdvantageofParallelism– e.g.multipleprocessors,disks,memorybanks,pipelining,
multiplefunctionalunits
• PrincipleofLocality– Reuseofdataandinstructions
• FocusontheCommonCase– Amdahl’sLaw
22

Amdahl’sLaw
23
( )enhanced
enhancedenhanced
new
oldoverall
SpeedupFraction Fraction
1 ExTimeExTime Speedup
+-==1
Best you could ever hope to do:
( )enhancedmaximum Fraction - 1
1 Speedup =
( ) úû
ùêë
é+-´=
enhanced
enhancedenhancedoldnew Speedup
FractionFraction ExTime ExTime 1

UsingAmdahl’sLaw
24

Amdahl’sLawforParallelism
• TheenhancedfractionFisthroughparallelism,perfectparallelismwithlinearspeedup– ThespeedupforFisNforNprocessors
• Overallspeedup
• Speedupupperbound(whenNà∞):– 1-F:thesequentialportionofaprogram
25
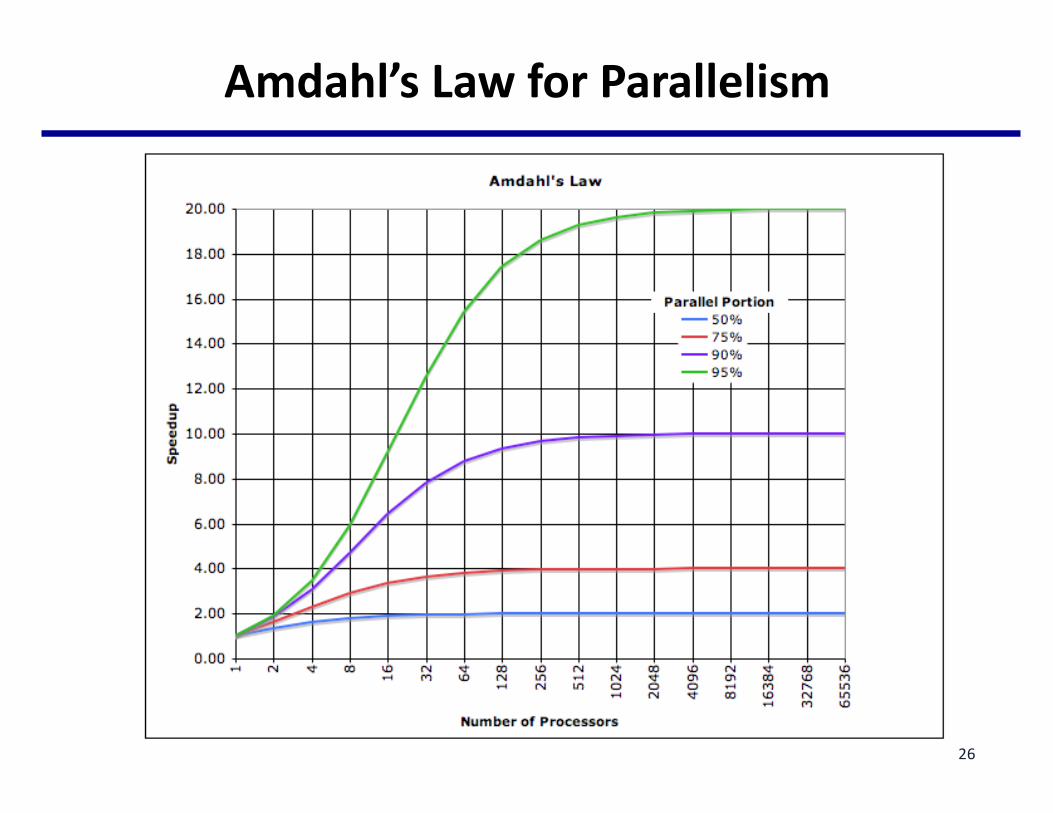
Amdahl’sLawforParallelism
26

Exercise#1:Amdahl’sLaw
27

Exercise#1:Amdahl’sLawSolution
28

GeneralAmdahl’sLaw
• F030%,nospeedup;F140%,speedupby4;F230%speedupby3,whatistheoverallspeedup
• =1/(0.3+0.4/4+0.3/3)=1/0.5=2
29

Exercise#2:CPUtimeandSpeedup
30

Exercise#2:Solution,TextbookPage54
31

PowerandEnergy
• Problem:– Getpowerinanddistributearound– getpowerout:dissipateheat
• Threeprimaryconcerns:– Maxpowerrequirementforaprocessor– ThermalDesignPower(TDP)
• Characterizessustainedpowerconsumption• Usedastargetforpowersupplyandcoolingsystem• Lowerthanpeakpower,higherthanaveragepowerconsumption
– Energyandenergyefficiency
• Clockratecanbereduceddynamicallytolimitpowerconsumption
32

EnergyandEnergyEfficiency
• Power:energyperunittime– 1watt=1joulepersecond– Energypertaskisoftenabettermeasurement
• ProcessorAhas20%higheraveragepowerconsumptionthanprocessorB.Aexecutestaskinonly70%ofthetimeneededbyB.– SoenergyconsumptionofAwillbe1.2*0.7=0.84ofB
33
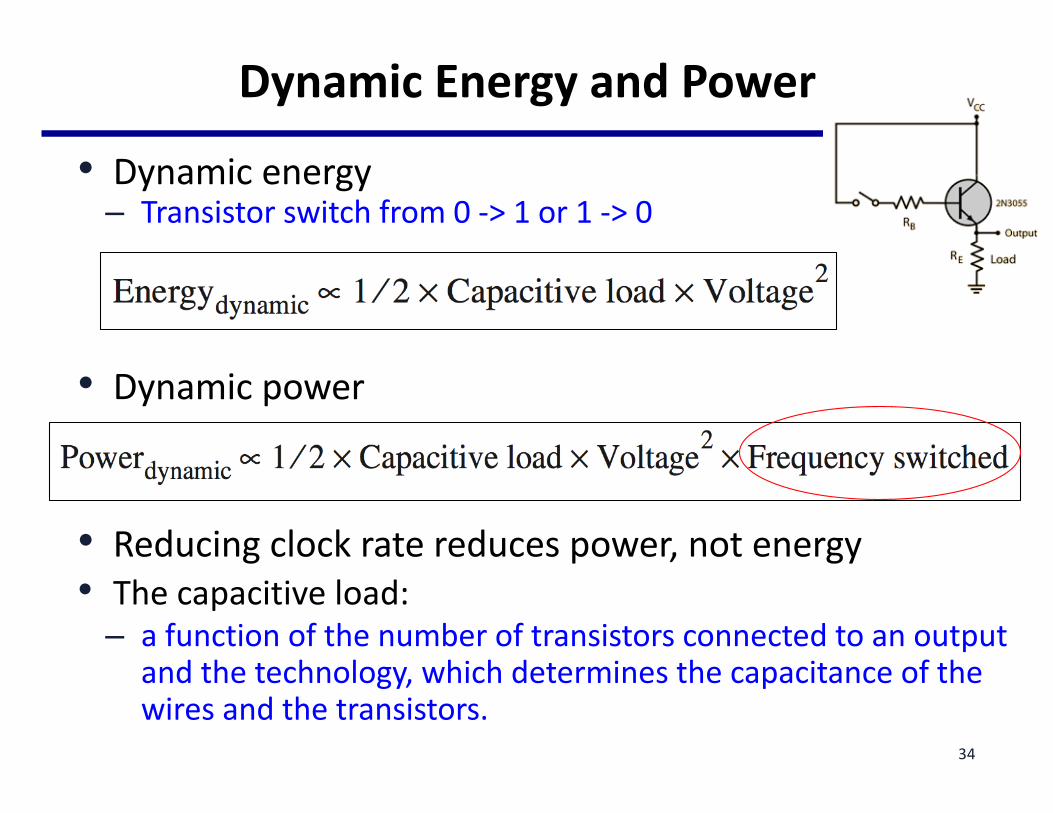
DynamicEnergyandPower
• Dynamicenergy– Transistorswitchfrom0->1or1->0
• Dynamicpower
• Reducingclockratereducespower,notenergy• Thecapacitiveload:
– afunctionofthenumberoftransistorsconnectedtoanoutputandthetechnology,whichdeterminesthecapacitanceofthewiresandthetransistors.
34

AnExamplefromTextbookpage#25
35

AnExamplefromTextbook
• Suppose a new CPU has– 85% of capacitive load of old CPU– 15% voltage and 15% frequency reduction
0.520.85FVC
0.85F0.85)(V0.85CPP 4
old2
oldold
old2
oldold
old
new ==´´
´´´´´=
36
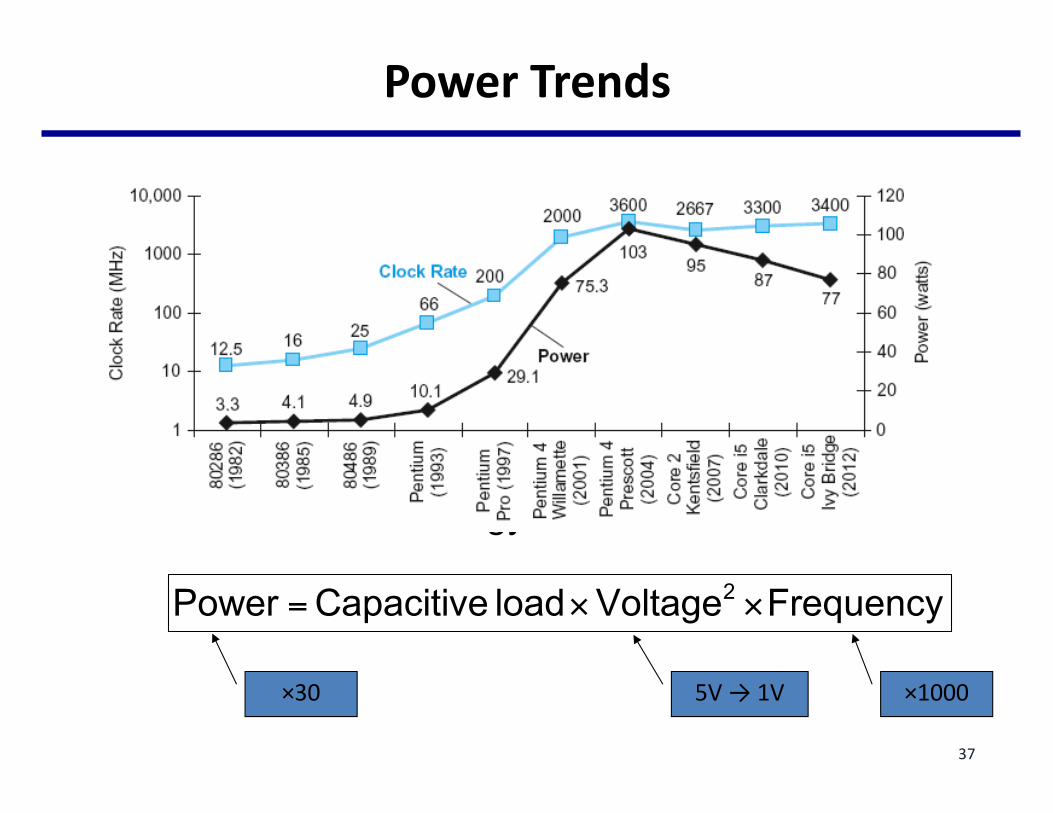
PowerTrends
• In CMOS IC technology
Power =Capacitive load×Voltage2 ×Frequency
×1000×30 5V→1V
37

ReducingPower
• Techniquesforreducingpower:– Donothingwell– DynamicVoltage-FrequencyScaling
– LowpowerstateforDRAM,disks– Overclocking,turningoffcores
38
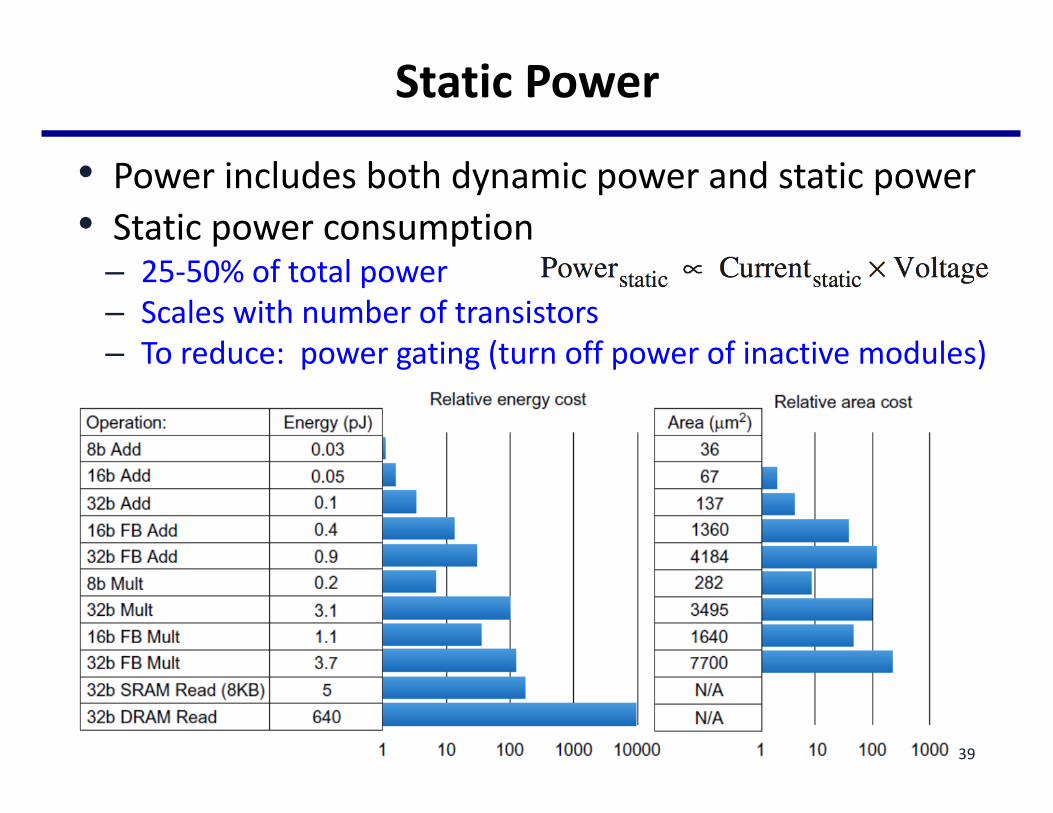
StaticPower
• Powerincludesbothdynamicpowerandstaticpower• Staticpowerconsumption
– 25-50%oftotalpower– Scaleswithnumberoftransistors– Toreduce:powergating(turnoffpowerofinactivemodules)
39