lab: introduction to weka
TRANSCRIPT

Introduction to WEKA
Tommaso Fornaciari1
1University of Trento, Center for Mind/Brain Sciences
Philosophy 2-year MasterIntroduction to Artificial Intelligence

Outline
IntroductionWhat is WEKA?What is this lab?References
Getting startedMain windowSteps of a WEKA processExplorer section Tabs
Loading dataInputWhat an .arff file looks like?Type of attributesSparse dataSomething wrong?
Dataset managementChecking attributesEditing datasetFiltering
Attributes’ selectionWhyHow
Visualizing attributesThe scatter plot matrixParamenters

What is WEKA?
I Weka - Waikato Environment for Knowledge Analysis - is asoftware which implements several machine learning algorithmsand data preprocessing tools.
I It is produced by the University of Waikato in New Zealand anddistributed under the terms of the GNU General Public License.

What is this lab?
This lab is a tutorial of four lectures...
Schedule March 6th, 13th, 20th and 27th from 10.00am to12.00am.
Approach Pragmatic. More practice than theory (Olga will provideyou with the theoretical foundations).
Goal To learn enough WEKA to find out by yourself how touse it to solve your own problems.
Contact [email protected]

References
Bouckaert, R. R., Frank, E., Hall, M., Kirkby, R., Reutemann, P.,Seewald, A., and Scuse, D. (2009).Weka manual (3.7.1).
Witten, I. H., Frank, E., and Hall, M. A. (2011).Data Mining: Practical Machine Learning Tools and Techniques.Morgan Kaufmann, Burlington, MA, 3 edition.

Main window
Explorer Graphical User Interface -GUI which gives theeasiest access to every toolfor machine learningexperiments.
Experimenter Which algorithm works best? Experimenter allows tocompare a variety of learning techniques automatically.
KnowledgeFlow It allows to design configurations for streamed dataprocessing. Useful to save memory.
Simple CLI Command Line Interface. Useful to save memory andto launch processes from scripts.

Steps of a WEKA process
I Loading a dataset;I Preprocessing;I Attribute selection;
I Choosing an algorithm;I Set training and test set;I Set parameters;
I Running the process;I View the results;I Save them.
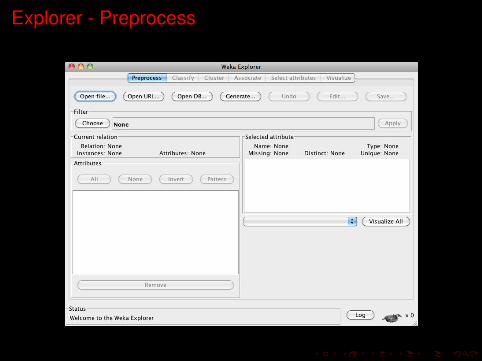
Explorer - Preprocess

Explorer section Tabs
Preprocess Choose and modify the data being acted on.Classify Train and test learning schemes that classify or perform
regression.Cluster Learn clusters for the data.
Associate Learn association rules for the data.Select attributes Select the most relevant attributes in the data.
Visualize View an interactive 2D plot of the data.

Input
It is possible to provide WEKA with data in several ways:Open file.... Brings up a dialog box allowing you to browse for the
data file on the local file system.Open URL.... Asks for a Uniform Resource Locator address for
where the data is stored.Open DB.... Reads data from a database.Generate.... Enables you to generate artificial data from a variety of
DataGenerators.However, Weka’s native data storage method is ARFF format.You can easily convert from a spreadsheet to ARFF.

What an .arff file looks like?
@relation mydataset % dataset’s name% empty row for readability
@attribute length numeric % list and type of attributes@attribute nopunct numeric % ‘numeric’ = numbers... % omissis@attribute ART_NOUN numeric@attribute class {0,1} % {x,y,...} factors
% in this case, the class@data % data incipit7,6,4,1,2,4,5,6,7,1,1,2,4,5,6,7,1,1,2...16,14,5,6,1,4,1,3,3,4,0,1,4,1,3,3,4,0...13,12,7,1,2,2,1,3,2,2,5,2,2,1,3,2,2,5...14,13,5,3,2,2,1,3,9,1,9,2,2,1,3,9,1,9...5,4,12,22,5,6,1,8,2,1,1,5,6,1,8,2,1,1......

Type of attributes
I numericI {factor,that,is,nominal,specification}I string (the data have to be close in ’)I date "yyyy-MM-dd HH:mm:ss" (or the format you prefer)
Values can include spaces; if so, they must be placed within quotationmarks.The class attribute is not distinguished in any way in the data file.

Sparse data
It can be impractical to represent each element of a sparse matrixexplicitly, as follows:
0,26,0,0,0,0,63,0,0,0,"class A"0,0,0,42,0,0,0,0,0,0,"class B"
Nonzero attributes can be explicitly identified by attribute number andtheir value stated:
{1 26, 6 63, 10 "class A"}{3 42, 10 "class B"}

Something wrong?
If you try to load a dataset and receive an error message:
I Try to understand the meaning of the error message :-)
Check some common mistakes:
I Attribute names with ‘strange’ characters such as spaces innames not included in quotes, commas, % and so on;
I No correspondence between number of attributes and data;I No correspondence between type of attributes and data;I ...
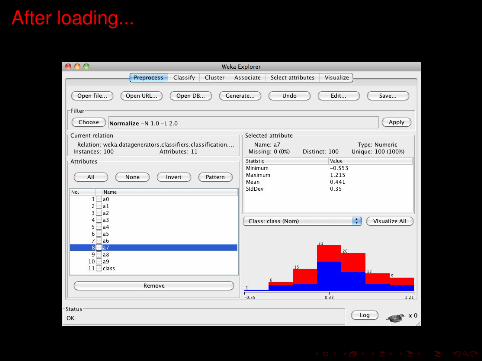
After loading...

Checking attributes
Name The name of the attribute, the same as that given in the attributelist.
Type The type of attribute.Missing The number (and percentage) of instances in the data for which
this attribute is missing (unspecified).Distinct The number of different values that the data contains for this
attribute.Unique The number (and percentage) of instances in the data having a
value for this attribute that no other instances have.
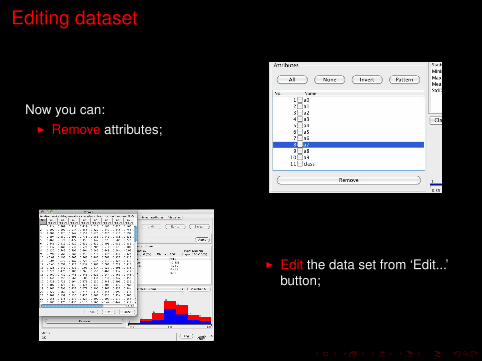
Editing dataset
Now you can:I Remove attributes;
I Edit the data set from ‘Edit...’button;

Filtering
You can also...I Apply filters to entities or
attributes.All filters transform the inputdataset in some way.
I After the choice, clic on thename of the filter to edit it.What appears in the line is thecommand-line version of thefilter, and the parameters arespecified with minus signs.
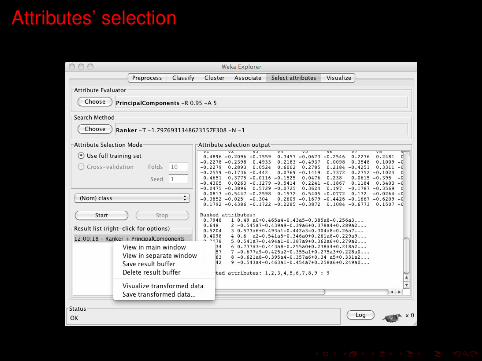
Attributes’ selection

Why
I You may want to evaluate the effectiveness of your attributes inyour machine learning tasks.
I You also could decide to select your attribute not manually, butaccording this effectiveness.
I For these purposes there is the Select attributes panel.

How
This process involves these steps:1. Choosing an attributes’ evaluator, which determines what
method is used to assign a worth to each attribute;
2. Choosing a search method, which traverse the attribute space tofind a good subset. Quality is measured by the chosen attributesubset evaluator;
3. Choosing if consider the attributes of the whole dataset ratherthan a subset identified through a process of cross-validation;
4. Running the process;
5. Lastly, if you want to perform a machine learning experimentusign only the selected subset of attributes, with right clic on theresult list you can choose to save the reduced/transformed datain .arff format.
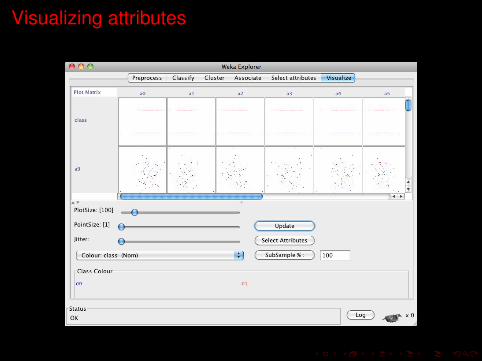
Visualizing attributes

The scatter plot matrix
I The Visualize panel helps you visualize a dataset - not the resultof a classification or clustering model, but the dataset itself.
I It displays a matrix of two-dimensional scatter plots of every pairof attributes.

Paramenters
PlotSize Size of the plot;PointSize Size of the points;
Jitter Random displacement applied to X and Y values toseparate points that lie on top of one another;
Colour Attribute which determines the colour of the points:normally the class;
Select Attributes The size of the matrix of plots can be reduced byselecting certain attributes;
SubSample % It is also possible to consider only subsample of thedata;
Update It makes to come into effect the paramenters’configuration.

Thanks for attention!
Jacopo de’ Barbari, Ritratto di Luca Pacioli, 1495