informatics i101 february 25, 2003 john c. paolillo, instructor
TRANSCRIPT

Informatics I101
February 25, 2003
John C. Paolillo, Instructor

Electronic Text
• ASCII — American Standard Code for Information Interchange
• EBCDIC (IBM Mainframes, not standard)• Extended ASCII (8-bit, not standard)
– DOS Extended ASCII– Windows Extended ASCII– Macintosh Extended ASCII
• UNICODE (16-bit, standard-in-progress)

ASCII
01000001
Alphabet letter "A"
means
Screen Representation
A A A
is displayed as
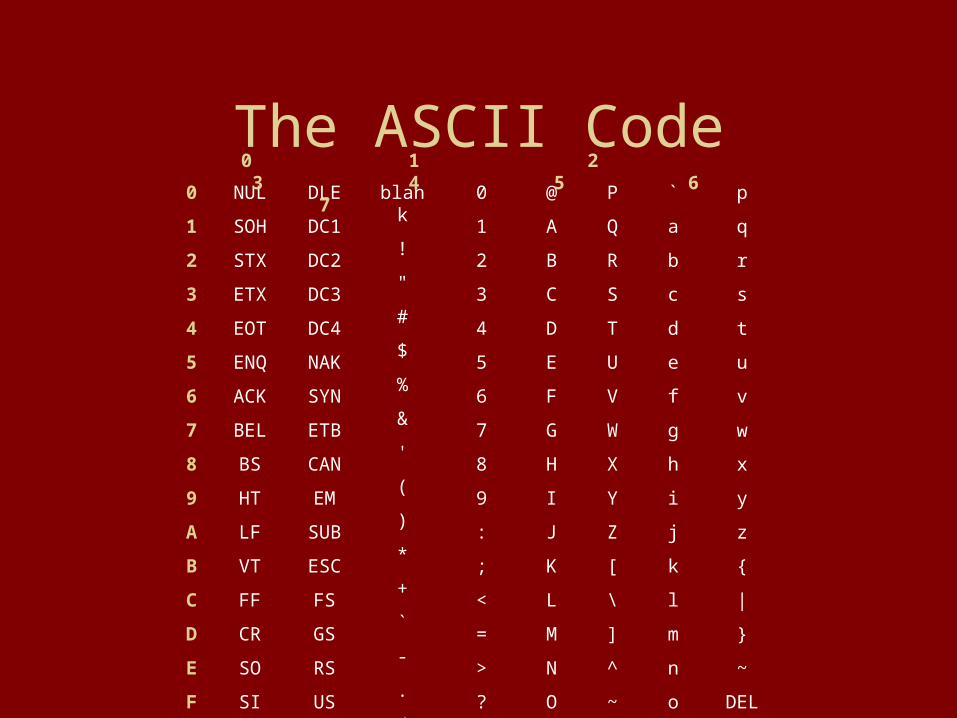
The ASCII CodeNUL
SOH
STX
ETX
EOT
ENQ
ACK
BEL
BS
HT
LF
VT
FF
CR
SO
SI
0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
blank
!
"
#
$
%
&
'
(
)
*
+
`
-
.
/
@
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
`
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
DLE
DC1
DC2
DC3
DC4
NAK
SYN
ETB
CAN
EM
SUB
ESC
FS
GS
RS
US
0
1
2
3
4
5
6
7
8
9
:
;
<
=
>
?
P
Q
R
S
T
U
V
W
X
Y
Z
[
\
]
^
~
p
q
r
s
t
u
v
w
x
y
z
{
|
}
~
DEL
0 1 2 3 4 5 6 7

An Example Text
T h i s i s a n e x a m p l e
84 104 105 115 32 105 115 32 97 110 32 101 120 97 109 112 108 101
Note that each ASCII character corresponds to a number, including spaces, carriage returns, etc. Everything must be represented somehow, otherwise the computer couldn’t do anything with it.

Representation in Memory32
101108112109
97120101
32110
97
_el
pmaxe_na
0110101001101001011010000110011101100110011001010110010001100011011000100110000101100000

Features of ASCII
• 7 bit fixed-length code – all codes have same number of bits
• Sorting: A precedes B, B precedes C, etc.• Caps + 32 = Lower case (A + space = a)• Word divisions, etc. must be parsed
ASCII is very widespread and almost universally supported.

Variable-Length Codes
• Some symbols (e.g. letters) have shorter codes than others– E.g. Morse code:
e = dot, j = dot-dash-dash-dash
– Use frequency of symbols to assign code lentgths
• Why? Space efficiency – compression tools such as gzip and zip use variable-
length codes (based on words)

Requirements
Starting and ending points of symbols must be clear(simplistic) example: four symbols must be encoded:
0 10 110 1110
All symbols end with a zeroAny zero ends a symbolAny one continues a symbolAverage number of bits per symbol = 2

Example
• 12 symbols– digits 0-9
– decimal point and space (end of number)
0 1 2 3 4 5 6 7 8 9 _ .
00
00
0 11
11
10 1
0
0 00
01
11
11
0 001 0102 01103 011104 0111105 0111116 107 1108 11109 11110_ 111110. 111111

Efficient Coding
Huffman coding (gzip)1. count the number of times each symbol occurs
2. start with the two least frequent symbola) combine them using a tree
b) put 0 on one branch, 1 on the other
c) combine counts and treat as a single symbol
3. continue combining in the same way until every symbol is assigned a place in the tree
4. read the codes from the top of the tree down to each symbol

Information Theory
• Mathematical theory of communication– How many bits in an efficient variable-length
encoding?– How much information is in a chunk of data?– How can the capacity of an information medium be
measured?
• Probabilistic model of information– “Noisy channel” model– less frequent ≈ more surprising ≈ more informative
• Measures information using the notion entropy

Noisy Channel
1
0
1
0
Source Destination
We measure the probability of each possible path (correct reception and errors)

Entropy
• Entropy of a symbol is calculated from its probability of occurrenceNumber of bits required hs = log2 ps
Average entropy: H(p) = – sum( pi log pi )
• Related to variance
• Measured in bits (log2)

Base 2 Logarithms
2log2x = x ; e.g. log22 = 1, log24 = 2, log28 = 3,
etc.
Often we round up to the nearest power of two (= min number of bits)

Unicode
• Administered by the Unicode Consortium
• Assigns unique code to every written symbol (21 bits: 2,097,152 codes)– UTF-32: four-byte fixed-length code– UTF-16: two to four-byte variable-length code– UTF-8: one to 4-byte variable length code
• ASCII Block (one byte) + basic multilingual plane (2-3 bytes) + supplementary (4 bytes)
