hw09 map reduce over tahoe a least authority encrypted distributed filesystem
TRANSCRIPT

Hadoop World NYC 20091
Hadoop World 2009
New YorkOct 1, 2009
MapReduce over Tahoe
.Booz Allen Hamilton Inc.134 National Business ParkwayAnnapolis Junction, MD 20701
Aaron CordovaAssociate

Hadoop World NYC 20092
MapReduce over Tahoe
Impact of data security requirements on large scale analysis
Introduction to Tahoe
Integrating Tahoe with Hadoop’s MapReduce
Deployment scenarios, considerations
Test results

Hadoop World NYC 2009
Features of Large Scale Analysis
As data grows, it becomes harder, more expensive to move– “Massive” data
The more data sets are located together, the more valuable each is– Network Effect
Bring computation to the data
3
Hadoop World NYC 20094
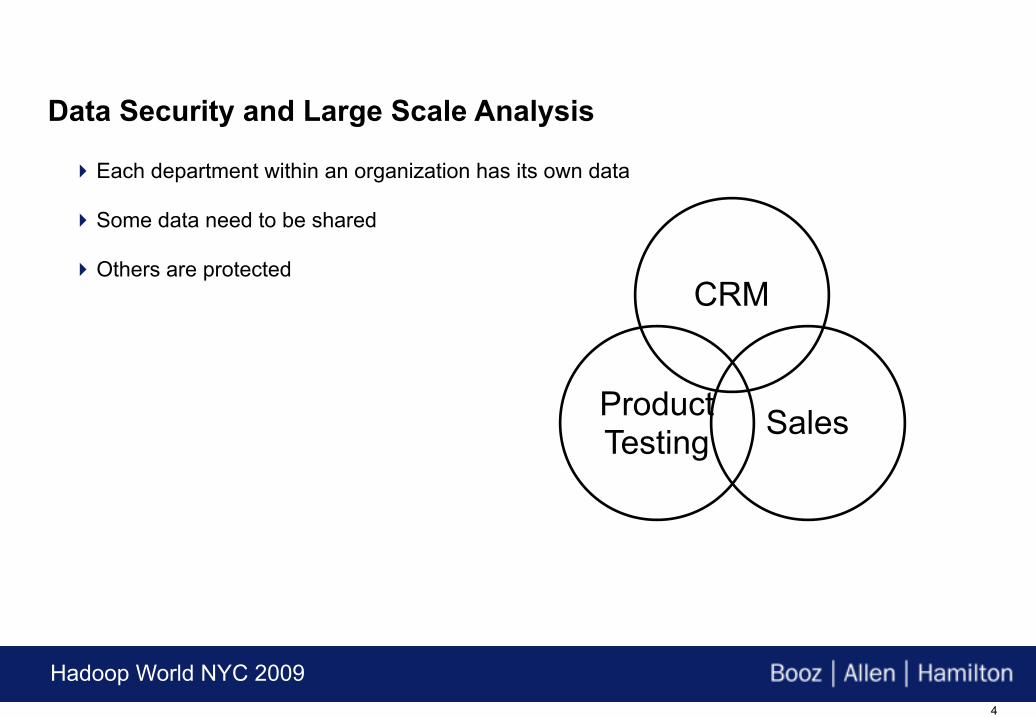
Data Security and Large Scale Analysis
CRM
SalesProductTesting
Each department within an organization has its own data
Some data need to be shared
Others are protected
Hadoop World NYC 2009
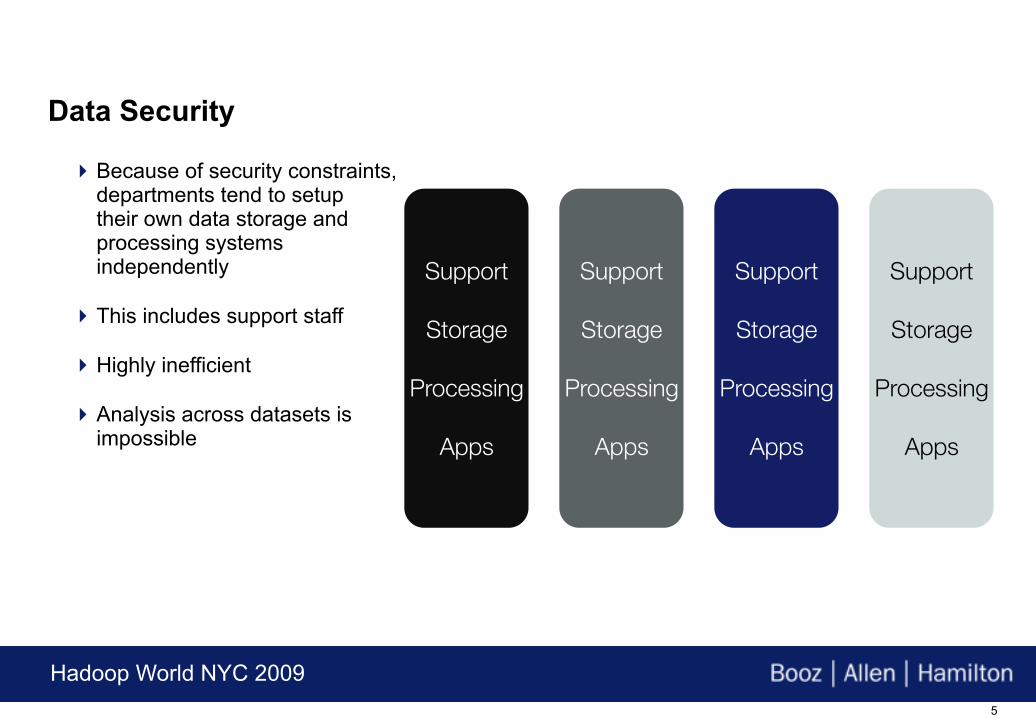
Data Security
5
Support
Storage
Processing
Apps
Support
Storage
Processing
Apps
Support
Storage
Processing
Apps
Support
Storage
Processing
Apps
Because of security constraints,departments tend to setuptheir own data storage andprocessing systems independently
This includes support staff
Highly inefficient
Analysis across datasets isimpossible

Hadoop World NYC 20096
“Stovepipe Effect”

Hadoop World NYC 2009
Tahoe - A Least Authority File System
Release 1.5
AllMyData.com
Included in Ubuntu Karmic Koala
Open Source
7
Hadoop World NYC 2009
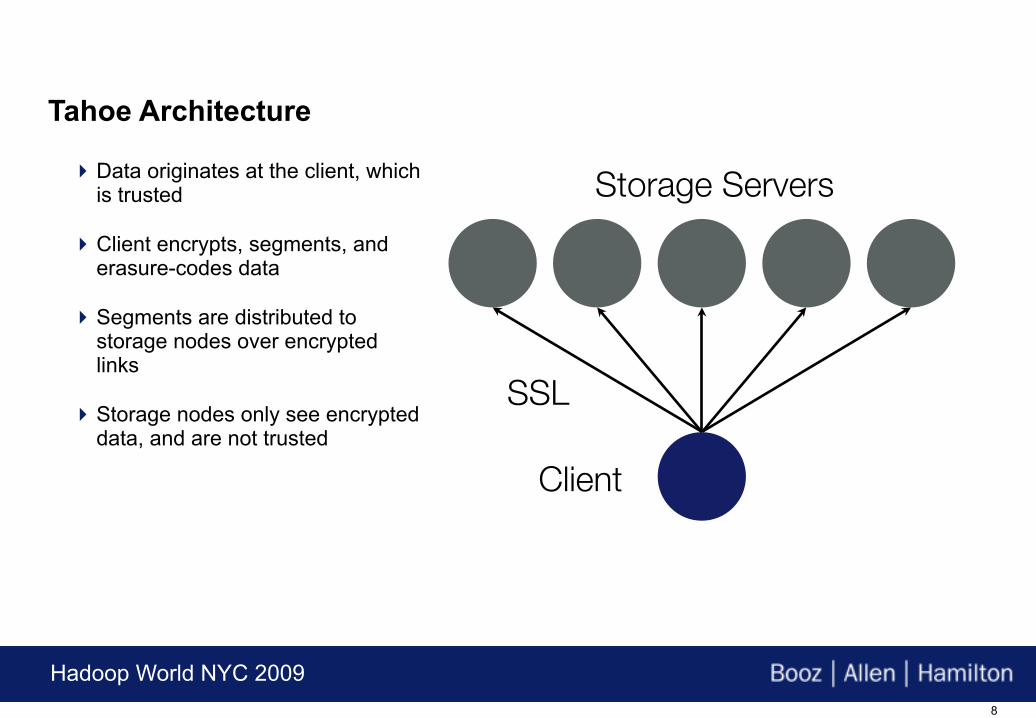
Tahoe Architecture
8
Storage Servers
Client
SSL
Data originates at the client, which is trusted
Client encrypts, segments, and erasure-codes data
Segments are distributed to storage nodes over encrypted links
Storage nodes only see encrypted data, and are not trusted
Hadoop World NYC 2009
Tahoe Architecture Features
AES Encryption
Segmentation
Erasure-coding
Distributed
Flexible Access Control
9

Hadoop World NYC 2009
Erasure Coding Overview
10
N
KOnly k of n segments are needed to recover the file
Up to n-k machines can fail, be compromised, or malicious without data loss
n and k are configurable, and can be chosen to achieve desired availability
Expansion factor of data is k/n (default is 3/10, or 3.3)

Hadoop World NYC 2009
Flexible Access Control
11
FileReadCapWriteCap
DirReadCapWriteCap
Each file has a Read Capability and a Write Capability
These are decryption keys
Directories have capabilities too
Hadoop World NYC 2009
Flexible Access Control
12
File
Dir
Dir
File File
ReadCap
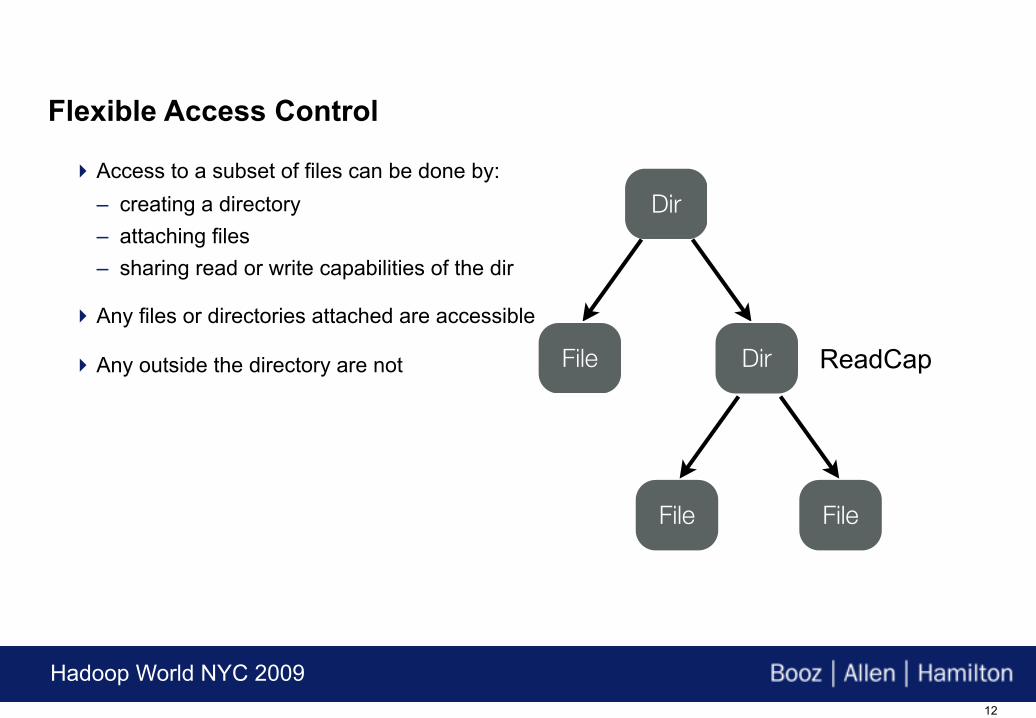
Access to a subset of files can be done by:– creating a directory– attaching files– sharing read or write capabilities of the dir
Any files or directories attached are accessible
Any outside the directory are not
Hadoop World NYC 2009
Access Control Example
13
Files
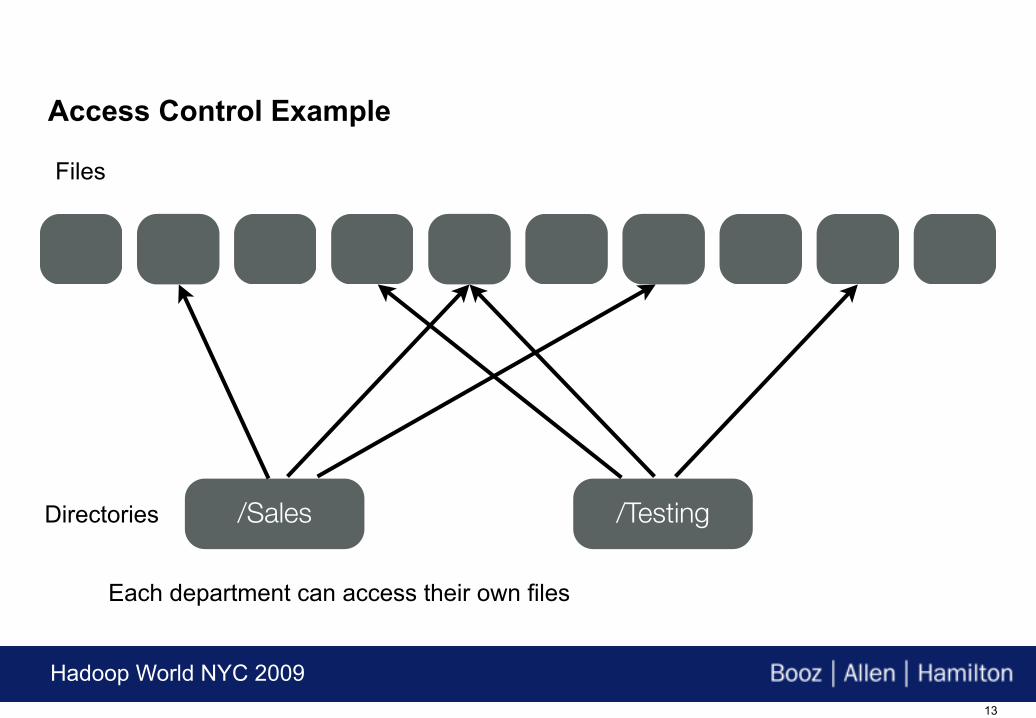
/Sales /TestingDirectories
Each department can access their own files
Hadoop World NYC 2009
Access Control Example
14
Files
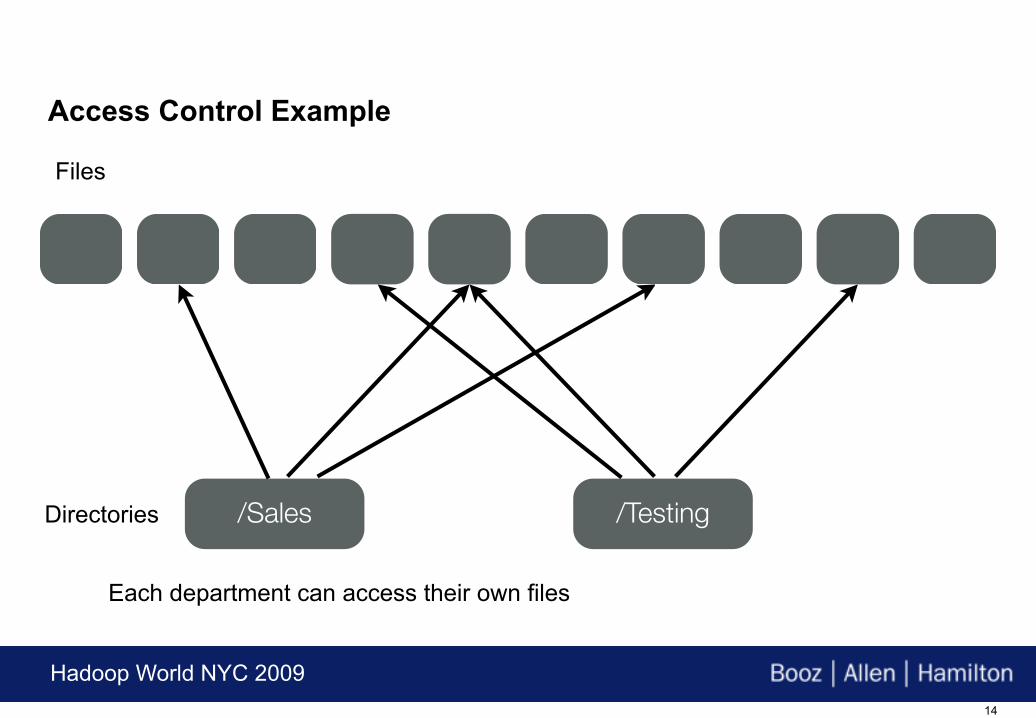
/Sales /TestingDirectories
Each department can access their own files
Hadoop World NYC 2009
Access Control Example
15
Files
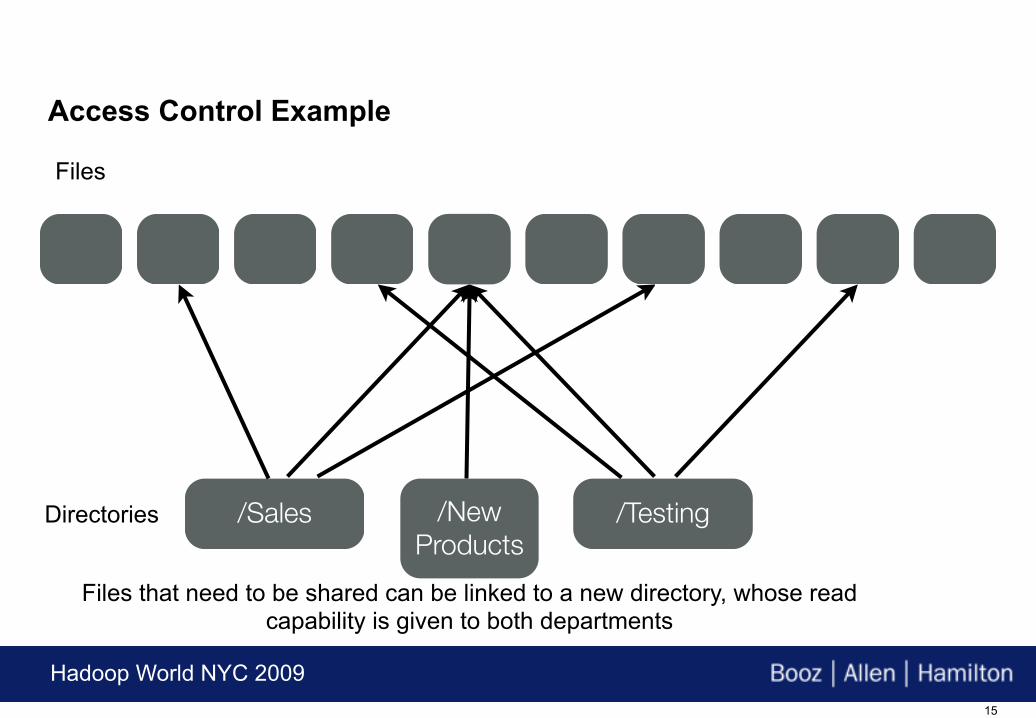
/Sales /TestingDirectories /New Products
Files that need to be shared can be linked to a new directory, whose read capability is given to both departments

Hadoop World NYC 2009
Hadoop Can Use The Following File Systems
HDFS
Cloud Store (KFS)
Amazon S3
FTP
Read only HTTP
Now, Tahoe!
16

Hadoop World NYC 2009
Hadoop File System Integration HowTo
Step 1. – Locate your favorite file system’s API
Step 2.– subclass FileSystem– found in /src/core/org/apache/hadoop/fs/FileSystem.java
Step 3.– Add lines to core-site.xml:
<name> fs.lafs.impl </name><value> your.class </value>
Step 4.– Test using your favorite Infrastructure Service Provider
17
Hadoop World NYC 2009
Hadoop Integration : MapReduce
18
Storage Servers
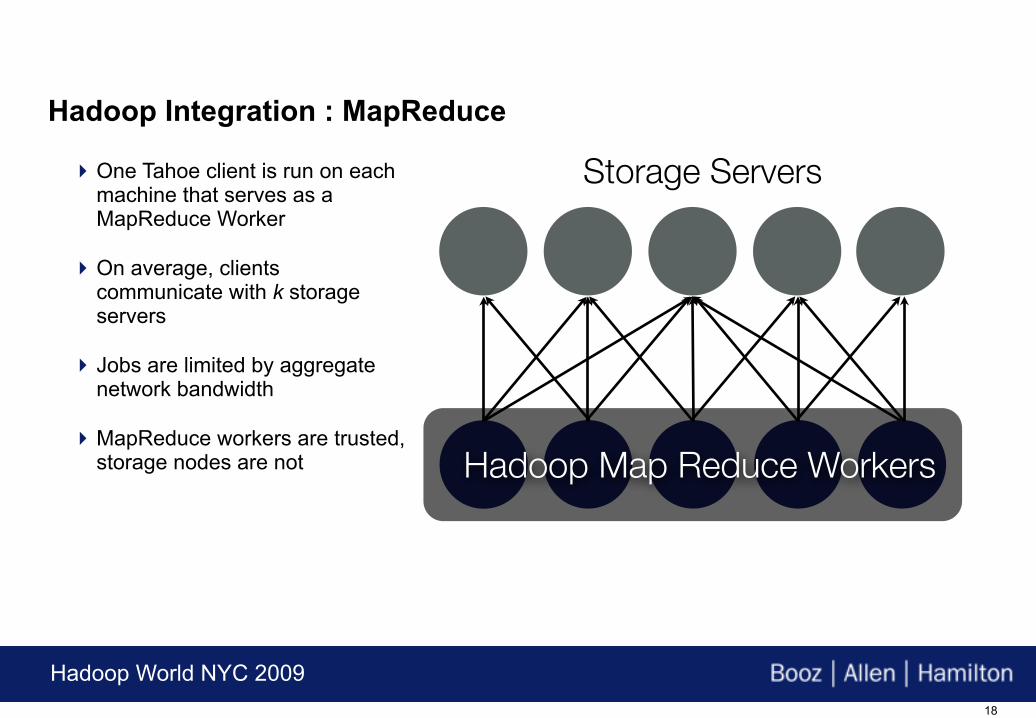
Hadoop Map Reduce Workers
One Tahoe client is run on each machine that serves as a MapReduce Worker
On average, clients communicate with k storage servers
Jobs are limited by aggregate network bandwidth
MapReduce workers are trusted, storage nodes are not

Hadoop World NYC 2009
Hadoop-Tahoe Configuration
Step 1. Start Tahoe
Step 2. Create a new directory in Tahoe, note the WriteCap
Step 3. Configure core-site.xml thus:– fs.lafs.impl: org.apache.hadoop.fs.lafs.LAFS– lafs.rootcap: $WRITE_CAP– fs.default.name: lafs://localhost
Step 4. Start MapReduce, but not HDFS
19
Hadoop World NYC 2009
Deployment Scenario - Large Organization
20
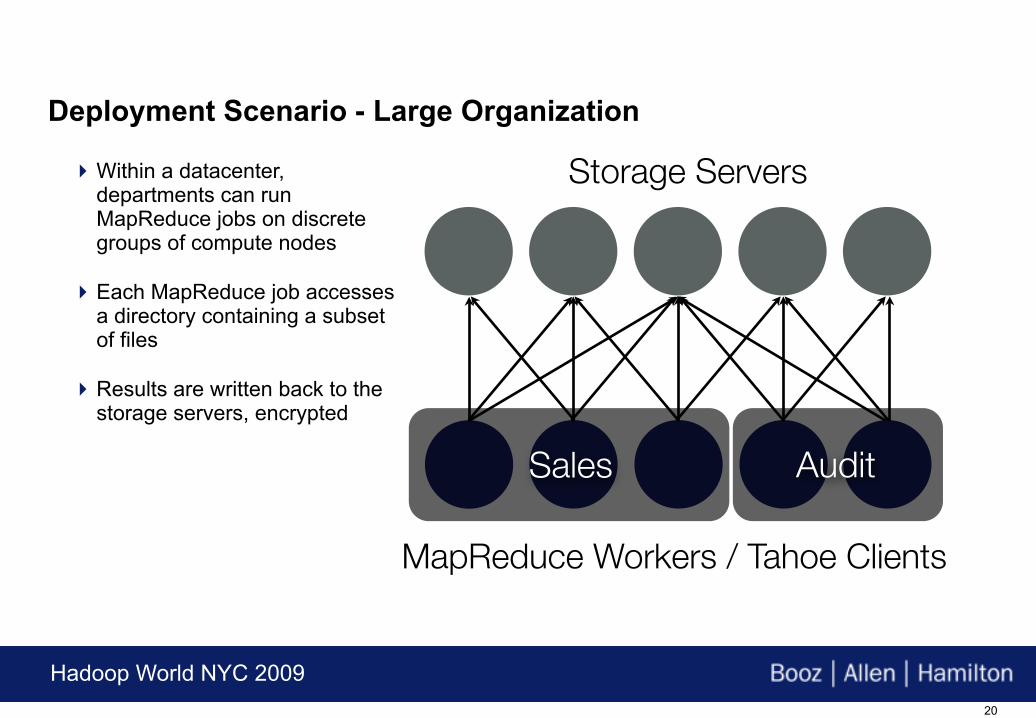
Storage Servers
MapReduce Workers / Tahoe Clients
Sales Audit
Within a datacenter, departments can run MapReduce jobs on discrete groups of compute nodes
Each MapReduce job accesses a directory containing a subset of files
Results are written back to the storage servers, encrypted
Hadoop World NYC 2009
Deployment Scenario - Community
21
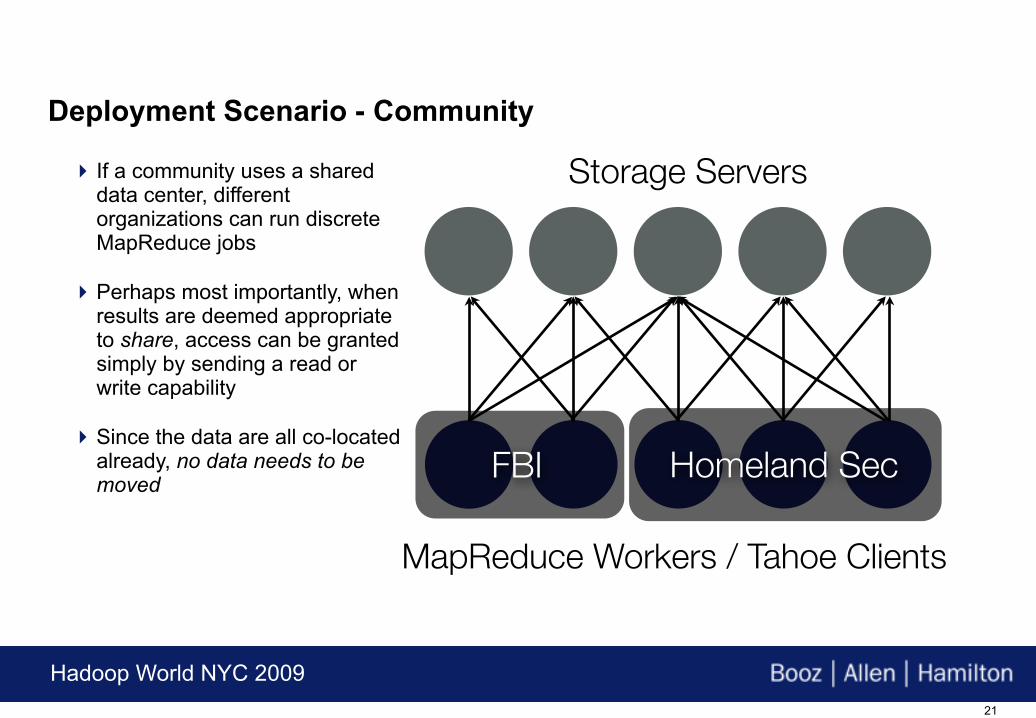
Storage Servers
FBI Homeland Sec
MapReduce Workers / Tahoe Clients
If a community uses a shared data center, different organizations can run discrete MapReduce jobs
Perhaps most importantly, when results are deemed appropriate to share, access can be granted simply by sending a read or write capability
Since the data are all co-located already, no data needs to be moved
Hadoop World NYC 2009
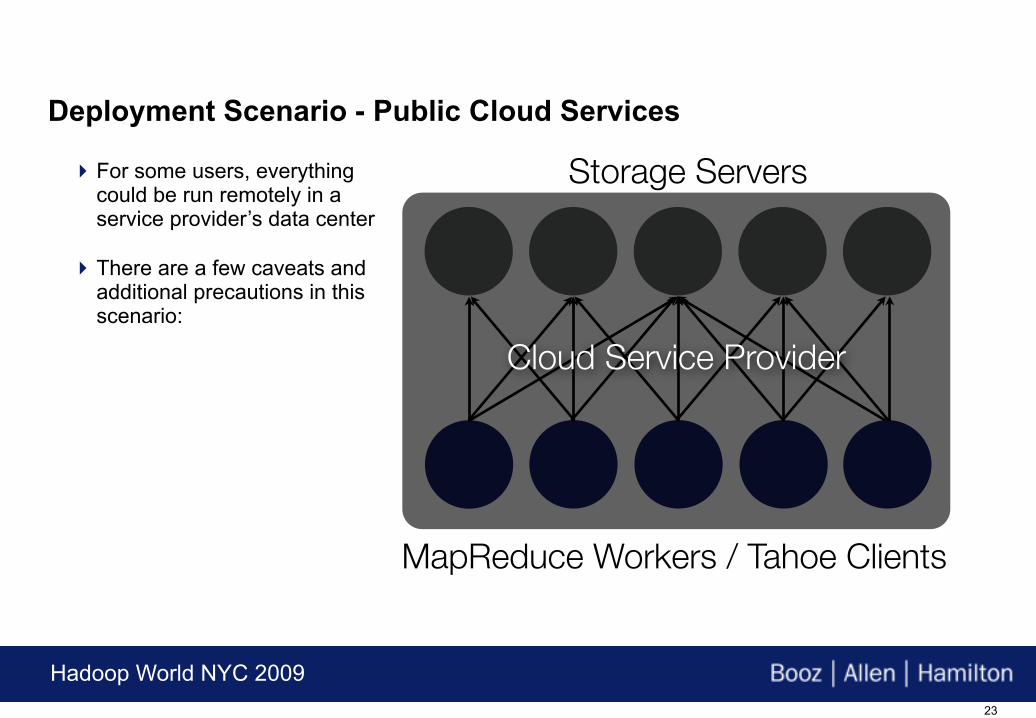
Deployment Scenario - Public Cloud Services
22
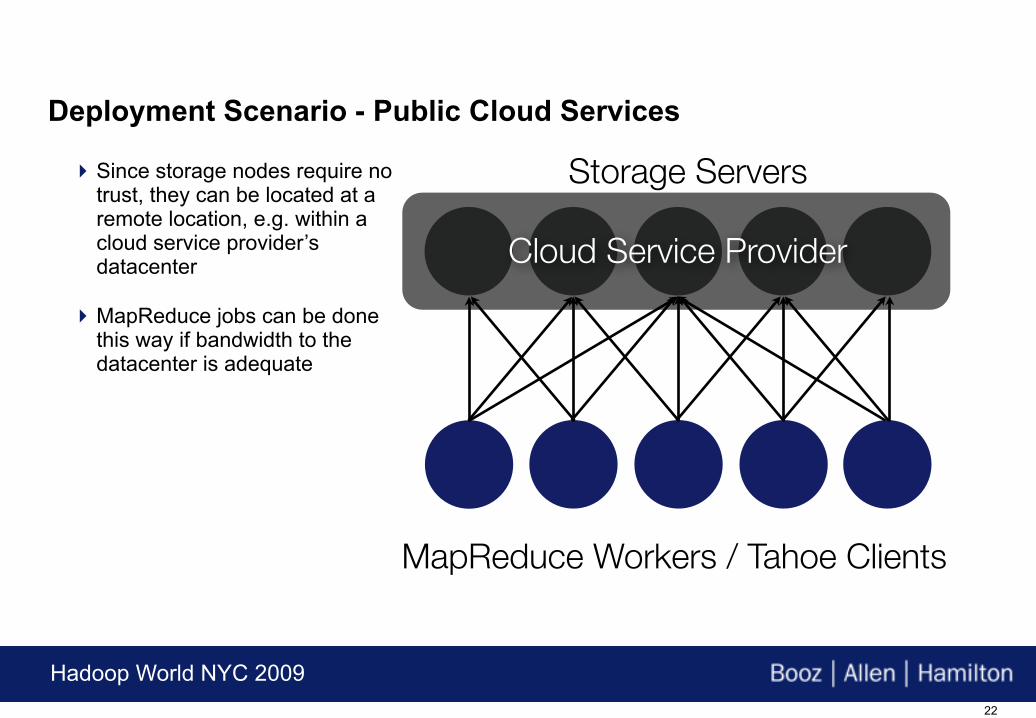
Storage Servers
Cloud Service Provider
MapReduce Workers / Tahoe Clients
Since storage nodes require no trust, they can be located at a remote location, e.g. within a cloud service provider’s datacenter
MapReduce jobs can be done this way if bandwidth to the datacenter is adequate
Hadoop World NYC 2009
Deployment Scenario - Public Cloud Services
23
Storage Servers
Cloud Service Provider
MapReduce Workers / Tahoe Clients
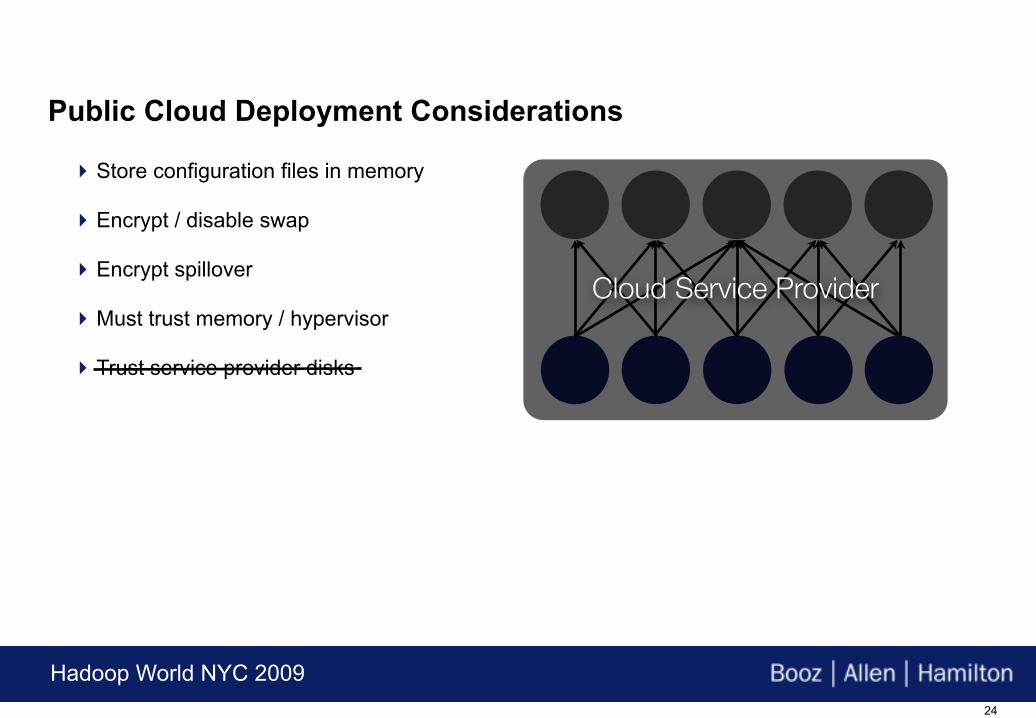
For some users, everything could be run remotely in a service provider’s data center
There are a few caveats and additional precautions in this scenario:
Hadoop World NYC 2009
Public Cloud Deployment Considerations
Store configuration files in memory
Encrypt / disable swap
Encrypt spillover
Must trust memory / hypervisor
Trust service provider disks
24
Cloud Service Provider

Hadoop World NYC 2009
HDFS and Linux Disk Encryption Drawbacks
At most one key per node - no support for flexible access control
Decryption done at the storage node rather than at the client - still have to trust storage nodes
25

Hadoop World NYC 2009
Tahoe and HDFS - Comparison
26
Feature HDFS Tahoe
Confidentiality File Permissions AES Encryption
Integrity Checksum Merkel Hash Tree
Availability Replication Erasure Coding
Expansion Factor 3x 3.3x (k/n)
Self-Healing Automatic Automatic
Load-balancing Automatic Planned
Mutable Files No Yes

Hadoop World NYC 2009
Performance
27
0
50
100
150
200
Random Write Word Count
HDFS Tahoe
Tests run on ten nodes
RandomWrite writes 1 GB per node
WordCount done over randomly generated text
Tahoe write speed is 10x slower
Read-intensive jobs are about the same
Not so bad since the most common data use case is write-once, read-many

Hadoop World NYC 2009
Code
Tahoe available from http://allmydata.org– Licensed under GPL 2 or TGPPL
Integration code available at http://hadoop-lafs.googlecode.com– Licensed under Apache 2
28