hw09 cross data center logs processing
TRANSCRIPT

Rackspace Hosting
Hadoop World 2009
Stu Hood – Search Team Technical Lead
Date: October 2, 2009
Cross Datacenter Logs Processing

Overview
• Use case• Background
• Log Types
• Querying
• Previous Solutions
• The Hadoop Solution
• Implementation• Collection
• Index time
• Query time
• Advantages of Hadoop• Storage
• Analysis
• Scalability
• Community

Use Case: Background
• “Rackapps” - Email and Apps Division• Founded 1999, merged with Rackspace 2007
• Hybrid Mail Hosting
• 40% of accounts have a mix of Exchange and Rackspace Email
• Fantastic Control Panel to juggle accounts
• Webmail client with calendar/contact/note sharing
• More Apps to come
• Environment
• 1K+ servers at 3 of 6 Rackspace datacenters
• Breakdown - 80% Linux, 20% Windows• “Rackspace Email” - custom email and application platform• Microsoft Exchange

Use Case: Log Types
• MTA (mail delivery) logs• Postfix
• Exchange
• Momentum
• Spam and virus logs• Amavis
• Access logs• Dovecot
• Exchange
• httpd logs

Use Case: Querying
• Support Team• Needs to answer basic questions:
• Mail Transfer – Was it delivered?
• Spam – Why was this (not) marked as spam?
• Access – Who (checked | failed to check) mail?
• Engineering• More advanced questions:
• Which delivery routes have the highest latency?
• Which are the spammiest IPs?
• Where in the world do customers log in from?
• Elsewhere• Cloud teams use Hadoop for even more mission critical statistics

Previous Solutions
• V1 – Query at the Source• Founding – 2006
• No processing: flat log files on each source machine
• To query, support escalates a ticket to Engineering
• Queries take hours
• 14 days available, single datacenter
• V2 – Bulk load to MySQL• 2006 – 2007
• Process logs, bulk load into denormalized schema
• Add merge tables for common query time ranges
• SQL self joins to find log entries for a path
• Queries take minutes
• 1 day available, single datacenter

The Hadoop Solution
• V3 – Lucene Indexes in Hadoop• 2007 – Present
• Raw logs collected and processed in Hadoop
• Lucene indexes as intermediate format
• “Realtime” queries via Solr
• Indexes merged to Solr nodes with15 minute turnaround
• 7 days stored uncompressed
• Queries take seconds
• Long term querying via MapReduce, high level languages
• Hadoop InputFormat for Lucene indexes
• 6 months available for MR queries
• Queries take minutes
• Multiple datacenters

The Hadoop Solution: Alternatives
• Splunk• Great for realtime querying, but weak for long term analysis
• Archived data is not easily queryable
• Data warehouse package• Weak for realtime querying, great for long term analysis
• Partitioned MySQL• Mediocre solution to either goal
• Needed something similar to MapReduce for sharded MySQL

Implementation: Collection
• Software– Transport
– Syslog-ng,
– SSH tunnel between datacenters
– Considering Scribe/rsyslog/?
– Storage
– App to deposit to Hadoop using Java API
• Hardware– Per Datacenter
– 2-4 collector machines
– hundreds of source machines
– Single Datacenter
– 30 node Hadoop cluster
– 20 Solr nodes

Implementation: Indexing/Querying
• Indexing– Unique processing code for schema’d, unschema’d logs
– SolrOutputFormat generates compressed Lucene indexes
• Querying– “Realtime”
– Sharded Lucene/Solr instances merge index chunks from Hadoop
– Using Solr API– Plugin to optimize sharding: queries are distributed to relevant nodes– Solr merges esults
– Raw Logs
– Using Hadoop Streaming and unix grep
– MapReduce
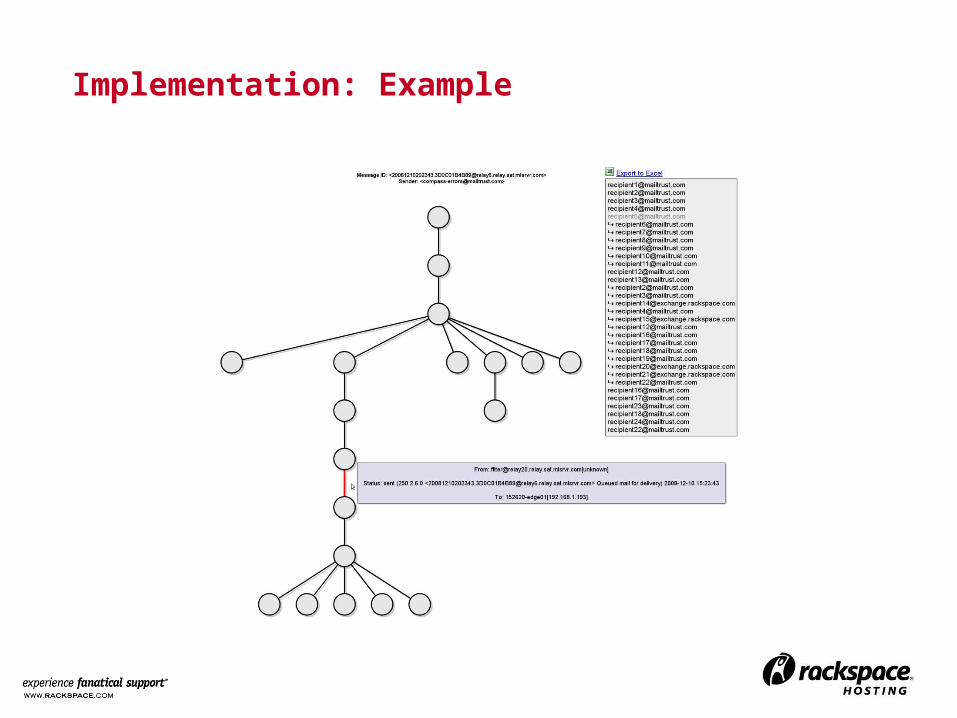
Implementation: Example

Implementation: Timeframe
• Development• Developed by a team of 1.5 in 3 months
• Indexing, Statistics
• Deployment• Developers acted as operations team
• Cloudera deployment resolved this problem
• Roadblocks• Bumped into job-size limitations
• Resolved now

Advantages: Storage
• Raw Logs– 3 days
– For debugging purposes, use by engineering
– In HDFS
• Indexes– 7 days
– Queryable via Solr API
– On local disk
• Archived Indexes– 6+ months
– Queryable via Hadoop, or use API to ask for old data to be made accessible in Solr
– In HDFS

Advantages: Analysis
• Java MapReduce API– For optimal performance of frequently run jobs
• Apache Pig– Ideal for one off queries
– Interactive development
– No need to understand MapReduce (SQL replacement)
– Extensible via UDFs
–Hadoop Streaming– For users comfortable with MapReduce, in a hurry
– Use any language (frequently Python)

Pig Example
records = LOAD 'amavis' USING us.webmail.pig.io.SolrSlicer('sender,timestamp,rip,recips', '1251777901', '1252447501');
flat = FOREACH records GENERATE FLATTEN(sender), FLATTEN(timestamp), FLATTEN(rip), FLATTEN(recips);
filtered = FILTER flat BY sender IS NOT NULL AND sender MATCHES '.*whitehouse\\.gov$';
cleantimes = FOREACH filtered GENERATE sender,(us.webmail.pig.udf.FromSolrLong(timestamp) / 3600 * 3600) as timestamp,rip,recips;
grouped = GROUP cleantimes BY (sender, rip, timestamp);
counts = FOREACH grouped GENERATE group, COUNT(*);
hostcounts = FOREACH counts GENERATE group.sender, us.webmail.pig.udf.ReverseDNS(group.rip) as host, group.timestamp, $1;
dump hostcounts;

Advantages: Scalability, Cost, Community
• Scalability• Add or remove nodes at any time
• Linearly increase processing and storage capacity
• No code changes
• Cost• Only expansion cost is hardware
• No licensing
• Community• Constant development and improvements
• Stream of patches adding capability and performance
• Companies like Cloudera exist to:
• Abstract away patch selection
• Trivialize deployment
• Provide emergency support

Fin!
Questions?