e-book social media voor kulturhusen
TRANSCRIPT

Universiteit van Amsterdam
Making Multi-core Computing Mainstream
Professor Chris JesshopeUniversity of Amsterdam

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Overview
i. Motivation and background - why multi-core?
ii. Introduction to the EU funded Apple-CORE project
iii. The SVP execution model
iv. Microgrid implementation and evaluation
v. Summary

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Moore’s law and its consequences
• If dimensions on silicon are reduced by l
• density increases by l2 and clock speed by l
• giving a performance increase of l3
• ... but power density also grows by l2
• Power proportional to frequency & Voltage2

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
The problem exponentials
• Power density increases exponentially over time• Chip area reachable in a clock decreases exponentially• We are now in an era where clock frequency is limited
by cooling constraints and it takes many cycles for a signal to cross a chip - distributed systems on a chip
130 nm
100 nm
70 nm
35 nm
20 mm chip edge

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
The resulting problems
• Power - without expensive cooling technology we have reached the limit if processor speed in CMOS the only
• ILP - executing multiple instructions in a single cycle by executing instructions out of order is power intensive and has limits difficult to achieve more than 4-way issue
• Memory gap - there is an increasing gap between processor and memory speed as a consequence of the signal propagation
• As we will see multi-core is a solution but it introduces another problem - how to program and manage explicit concurrency

Invited presentation INFOS 2010 (c) Chris Jesshope 28/3/2010
Multi-core - a Solution?
• Multi-core is the only way to increase chip performance
• Multi-core means simpler cores (in-order issue) and are more power efficient to implement
move from few complex cores to many simpler ones
• Applications are more power efficiently running on many rather cores than on a few cores... with some provisos
• applications must be scalable
• communications must be local
• programs probably need to be rewritten and concurrent programming which is difficult

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Shape of the future?• Intel recently announced its Single-chip Cloud Computer
a multicore comprising 48 IA architecture cores
• SCC is a research vehicle to investigate programming models and operating systems for the multi-core era
• It comprises:
• 48 P54C cores operating at 1GHz (FDIV bug fixed!)
• 24 node mesh network with 64GBytes/sec links
• Partitioned shared address space with no hardware coherency between cores
• Up to 64GBytes shared off-chip memory
• 256 KBytes L2 cache per core (not shared)
• 16KByte shared message passing buffer
• Supports FV scaling with 24 frequency domains and 6 voltage islands (N.b. Pd=kfv2)

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Making it Mainstream
• The changes required are fundamental and disruptive!
• Questions that need to be answered include:
• what programming model is required how is it supported in the architecture?
• do we need a full operating system on each core?
• how do we deal with locality and in its absence how to introduce asynchronous instruction execution
• Finally can we have generic concurrent programs
• i.e. source or even binary code compatibility across generations of multi-core processors

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Overview
i. Motivation and background - why multi-core?
ii. Introduction to the EU funded Apple-CORE project
iii. The SVP execution model
iv. Microgrid implementation and evaluation
v. Summary

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
• The goal of the EU Project Apple-CORE is indeed to make multi-core mainstream
• this means expressing and composing computations as concurrently as possible
• i.e. replace sequential with concurrent composition
• We uses an execution model designed for multi-cores
• The Self-adaptive Virtual Processor or SVP
• SVP implements both an OS kernel and a related programming model
• In Apple-CORE - SVP is implemented in the core’s binary instructions and it is the only OS required on most cores

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Overview
i. Motivation and background - why multi-core?
ii. Introduction to the EU funded Apple-CORE project
iii. The SVP execution model
iv. Microgrid implementation and evaluation
v. Summary

Invited presentation INFOS 2010 (c) Chris Jesshope 28/3/2010
The changing Landscape
• In the past, memory has been ubiquitous and cores were scarce - we therefore rationed processor cycles
• In the multi-core era, we consider both memory and cores to be ubiquitous
• Move from time sharing to space sharing, the cluster is the processor
• SVP introduces the concept of place (a cluster) allocated for exclusive use of a thread (space sharing)

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Motivation for SVP
• Provide an execution model that supports binary-code compatibility across generations of processors 1 .. many cores
• Capture locality through implicit communication and support weakly-consistent memory systems
• shared, partitioned shared and distributed memories
• Provide explicit and dynamic resource management
• Support work migration and load balancing through the use of delegation - threads continually created and terminating
• Provide security to support the exclusive use of both Memory and Cores
Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
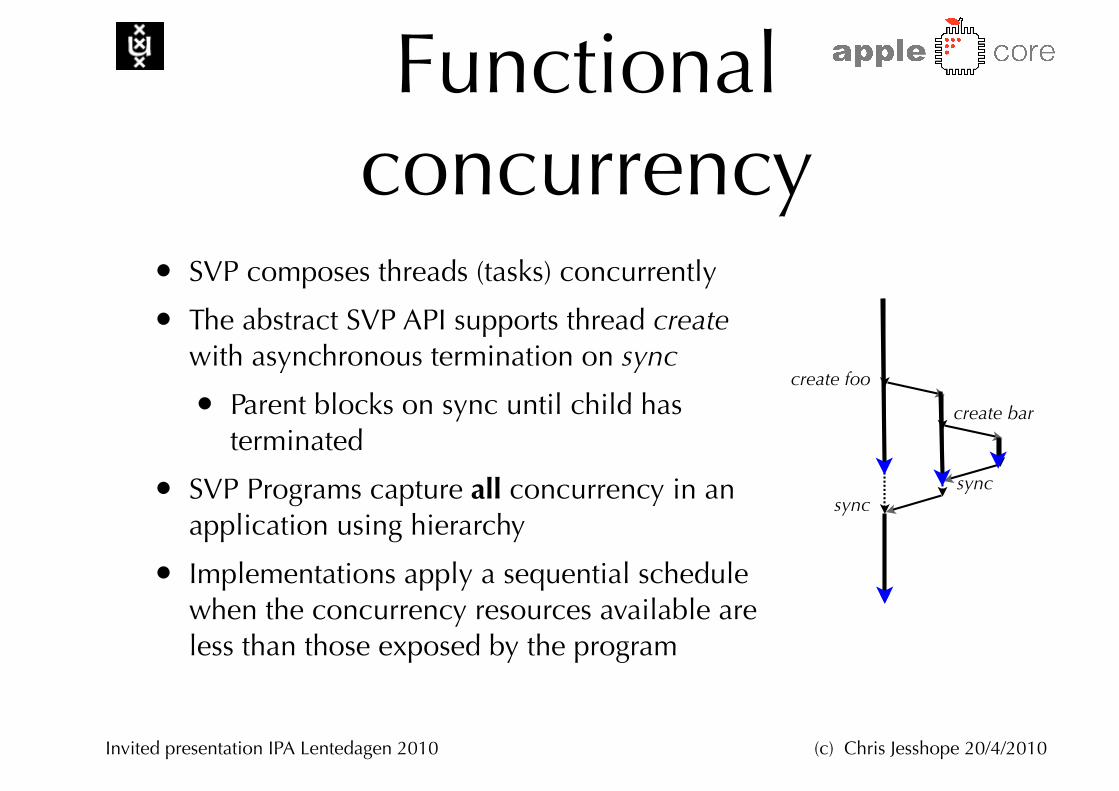
Functional concurrency
• SVP composes threads (tasks) concurrently
• The abstract SVP API supports thread create with asynchronous termination on sync
• Parent blocks on sync until child has terminated
• SVP Programs capture all concurrency in an application using hierarchy
• Implementations apply a sequential schedule when the concurrency resources available are less than those exposed by the program
create foo
create bar
syncsync

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Scheduling by instructionnon-blocking thread
waits for all parameters then
creates
a, b, c
thread executes to completion
blocking threadcreates then sets
parameters
thread blocks on parameters using SVP shared objects (i-structures)
a
b
c
• Pairwise communication between threads uses shared objects - support blocking read & non-blocking write
• Blocking is used to schedule threads in the SVP kernel• The same mechanism can be used to decouple instruction
execution - e.g. memory accesses are a concurrent activity

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Replication• SVP’s create API also supports replication
• A family of statically defined homogeneous threads(dynamically heterogeneous) can be created by supplying an index range {start, step, limit}
• threads are automatically created with their index variable pre-defined - testing this index allows heterogeneity
• To create a family of threads requires at least one additional thread concurrent context
• one context executes one child thread at a time
• more contexts mean more concurrency in execution

Replication & Communication
main thread
create(f1;;0;7;1;;)
sync(f1)
Family of 8 homogeneous threadsthreadi i=0..7
create(f2;;0;5;1;;)
sync(f2)
subordinate family - 1 shown
blocking communication
• Shared communication is pairwise between adjacent threads• i.e. in linear chains between child threads
• This capture locality in the model and avoids communication deadlock deadlock communication is guaranteed to be acyclic
Communication from the parent to all children using global objects is also supported

Memory consistency• We define consistency domains over memory to
differentiate between shared and global memories
• Even within a consistency domain concurrent threads can not reliably read each other’s memory except:i. A family of threads created can see any memory written by its
parent before create
ii. A parent can see memory written by its children after its syncs
iii. Memory written in one thread prior to a shared write can be read by that thread’s successor and memory written by a parent thread prior to a global write can be seen by all its children
iv. Between consistency domains only the values explicitly communicated by the shared and global objects are visible

SVP resource model• Processing resources are introduced into the SVP
through by acquiring a place and specifying it as a parameter on create• threads are then created at that place - a delegation
• a place server SEP must be provided by the SVP run-time
• Place is an abstraction defined for each SVP implementation - its contains one or more of:• an address to access the place
• a security key to allow execution at a place
• virtualisation of the physical place
• mutual exclusion at a place
Together these allow
single-use keys and exclusive
use

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Mutual exclusion
• As SVP’s weakly consistent memory cannot be used for locks SVP introduces the concept of a mutex place that is shared between threads and which serialises all requests to create tasks
• This provides the necessary support to implement processor and memory allocation which require exclusive access to data structures identifying usage
• Memory reads and writes at exclusive places provide consistency between otherwise unrelated threads
• Similar to Dijkstra’s secretary concept
Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
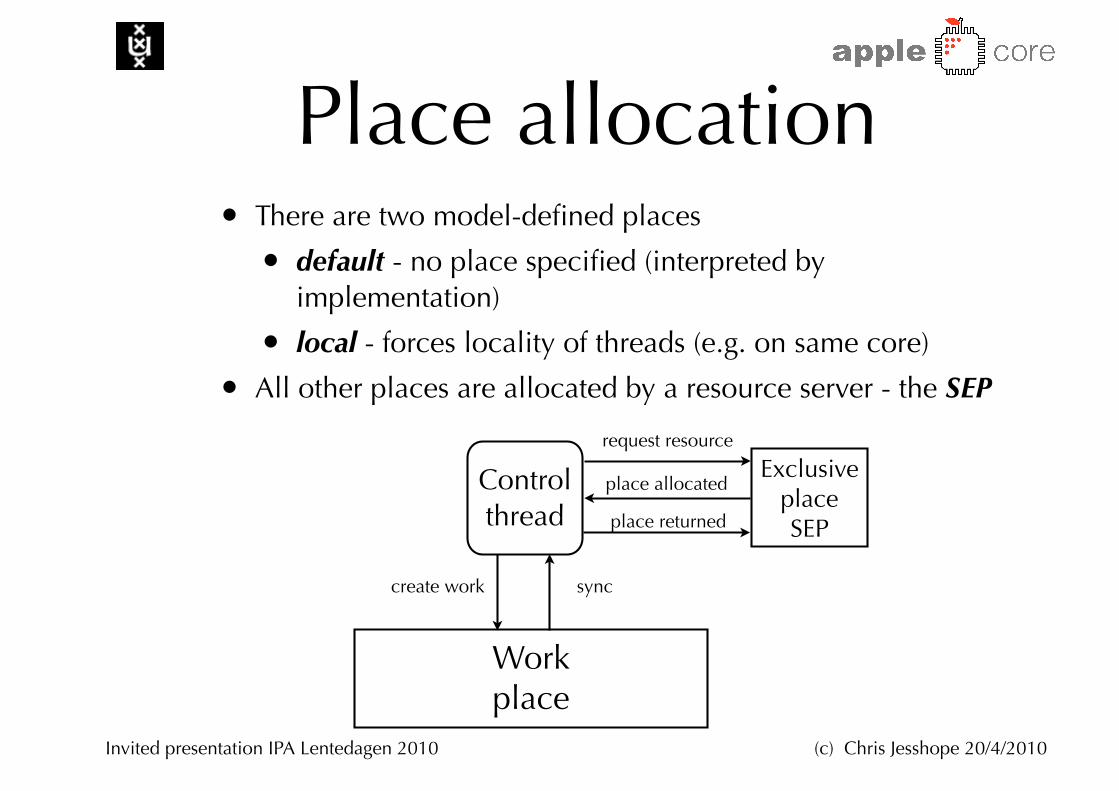
Place allocation• There are two model-defined places
• default - no place specified (interpreted by implementation)
• local - forces locality of threads (e.g. on same core)
• All other places are allocated by a resource server - the SEP
Control thread
Exclusive placeSEP
request resource
place allocated
Workplace
create work
place returned
sync

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Overview
i. Motivation and background - why multi-core
ii. Introduction to the EU funded Apple-CORE project
iii. The SVP execution model
iv. Microgrid implementation and evaluation
v. Summary

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Implementations
• In Apple-CORE we have implemented SVP in the ISA of a many-core processor
• we have Alpha and SPARC software emulation
• we have FPGA SPARC implementation (one core)
• We also have a software implementation of the SVP built over pthreads
• we plan to re-implement this on SCC to achieve a an efficient software kernel (granularity = small functions)

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Compilers
• Have defined a core language µTC (micro-threaded C) it captures all of the SVP concepts
• Have µTC to Alpha & SPARC compilers based on GCC
• Have parallelising C and SaC compilers that target the core SVP language
• SaC is a data-parallel functional language

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
The chip architecture
Distributed on-chip memory (COMA)
64 cores32
cores32
cores16
4 1
64 cores
Work distribution network
4
1
The cluster is the processor - binary code executes on a cluster of cores i.e. same code on one or more cores
External interfaces

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
synchronous operations
The SVP Core
Thread aware I-cache
threadQ
thread/instruction
select
I-structureRegister
file
asynchronous operations e.g. FPU/load
Instructions tagged with thread and family index Data tagged with RF address
Active thread queue contains threads that are guaranteed to execute at least one instruction
Communication to neighbouring core
Communication from neighbouring core
Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
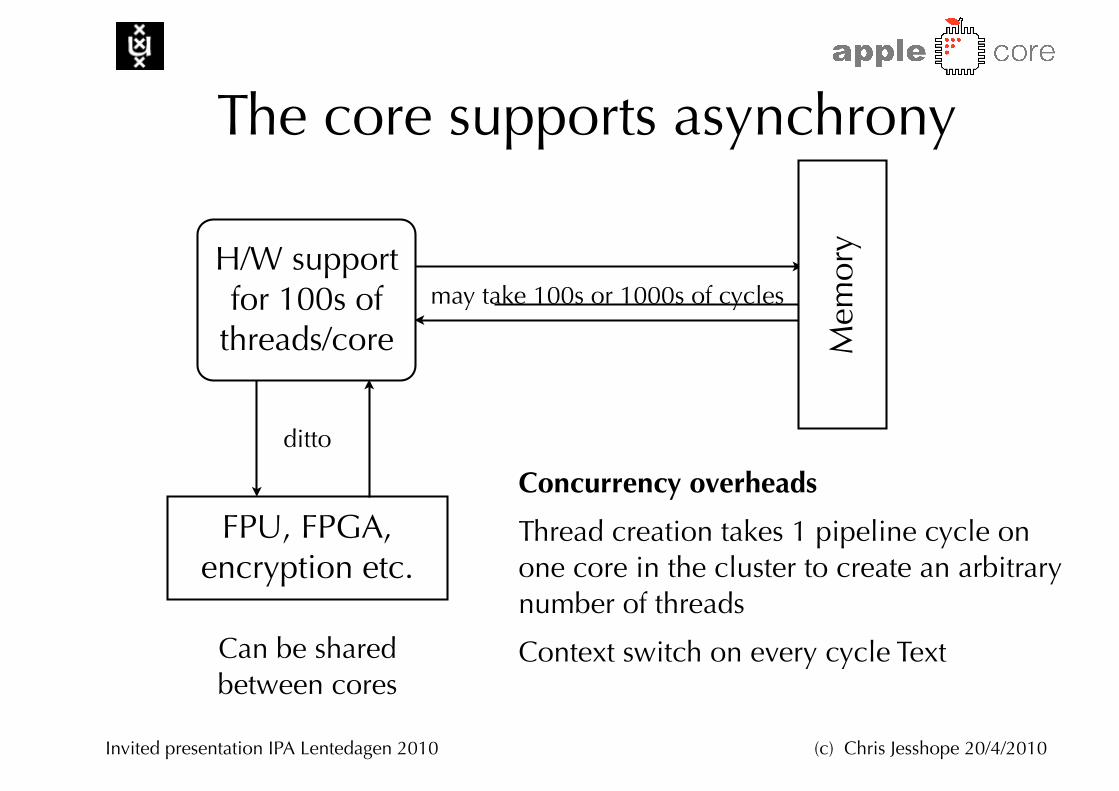
The core supports asynchrony
Mem
ory
may take 100s or 1000s of cyclesH/W support for 100s of
threads/core
FPU, FPGA, encryption etc.
ditto
Can be shared between cores
Concurrency overheads
Thread creation takes 1 pipeline cycle on one core in the cluster to create an arbitrary number of threads
Context switch on every cycle Text

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Chip Parametersfor evaluation
• Results presented execute code on a microgrid of 128 cores on a cycle-accurate software emulation
• Alpha ISA with 1024 int & 512 float register file
• 256 thread table entries 16 family tables entries
• 1K L1 I-cache and 1K L1 D-cache
• 32K L2 cache shared between 4 cores
• 2 DDR3 standard memory channels
• In all experiments the same binary code was executed on clusters of bare cores of arbitrary size with cold caches

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
128-core MicrogridCluster
ring
1 FPU +
2 cores
L2 cache
COMA
directory
COMA
ringRoot directory Root directory
DDR Channel DDR Channel
I/O interface
DMA
2-level COMA memory, I/O cores, DDR external memory interfaces

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Delegation granularity• Results plot GFLOPS & GIPS for
a 1 GHz core using a shared FPU (1 FPU per 2 cores)
• Efficiency is the the average IPC of all cores N.b. this is from a cold start on bare cores
• n=4K on 64 cores - we create & execute 64 threads/core in 3.5µsec
• n=8K on 64 cores we create & executes 128 threads/core in 6.5 µsec
• These include place allocation
!"
!#$"
!#%"
!#&"
!#'"
!#("
!#)"
!#*"
!#+"
!#,"
$"
!"
("
$!"
$("
%!"
%("
&!"
&("
'!"
'("
!" $!" %!" &!" '!" (!" )!" *!"
!"#$%&#'(
)*+,-./)
0-.(1%2(3)45(#67#8(
9:;<%2(7=(#72%>(
?!@9!+(A((((((!BCDE0,9(,*(.EDE!(
*@D)F!9E(
-./0123+45"
-6123+45"
-./0123'45"
-6123'45"
789:;<9=3+45"
789:;<9=3'45"

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Latency tolerance
• Generally L1 D-cache consumes a large fraction of core area
• We show that with latency tolerant cores the size of the L1 D-cache can be reduced to little more than a buffer
• Evaluated using FFT on with L1 cache sizes from 1 to 64K Bytes using from 1 to 64 cores in steps of 1

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
L1 D-cache size evaluation
!"
#"
$!"
$#"
%!"
%#"
&!"
&#"
'!"
'#"
!" $!" %!" &!" '!" #!" (!"
!"##$%"&
'%()#*&+,&-+*#.&"#*&-/%.0#*&
!"##$%"&,+*&123&445&6&7612&38&96-:-;#&
)*+,-."/0"1/.-2"3-."14*25-."$"67"891:1;-"
)*+,-."/0"1/.-2"3-."14*25-."'"67"891:1;-"
)*+,-."/0"1/.-2"3-."14*25-."$("67"891:1;-"
)*+,-."/0"1/.-2"3-."14*25-."('"67"891:1;-"

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
I/O bound kernel
10 100
1000 10000
100000
10 20
30 40
50 60
0 1 2 3 4 5 6 7
LMK7: Eqn. of state frag. - Performance (GFLOP/s)(cold caches)
#psize
#coresper SVP place
0 1 2 3 4 5 6 7
DDR3 memory saturation

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Compute bound kernel
10
100
1000
10000 0 10
20 30
40 50
60 70
0 1 2 3 4 5 6 7 8 9
LMK21: Matrix-Matrix productPerformance (GFLOP/s)
#psize#cores
0
1
2
3
4
5
6
7
8
9
Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
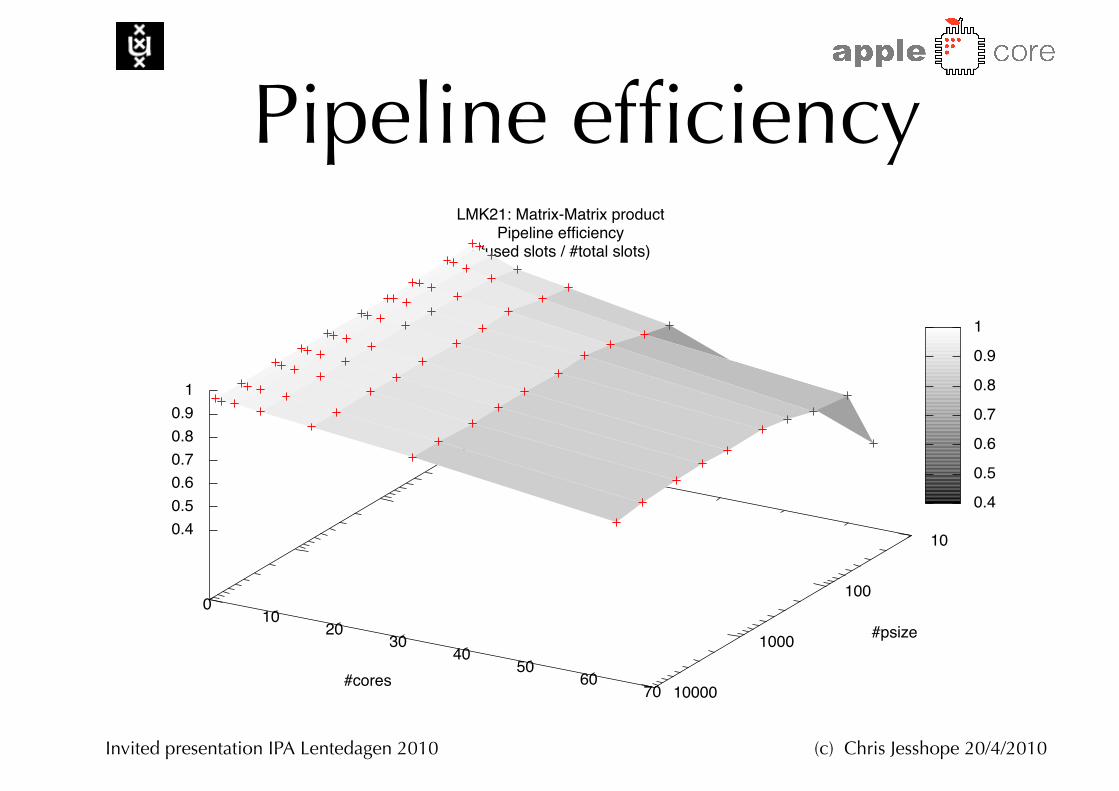
Pipeline efficiency
10
100
1000
10000
0 10
20 30
40 50
60 70
0.4
0.5
0.6
0.7
0.8
0.9
1
LMK21: Matrix-Matrix productPipeline efficiency
(#used slots / #total slots)
#psize
#cores
0.4
0.5
0.6
0.7
0.8
0.9
1

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
SL Quicksort - Sort rate
!"!#$!!%
&"!#$!'%
("!#$!)%
("&#$!)%
*"!#$!)%
*"&#$!)%
+"!#$!)%
+"&#$!)%
,"!#$!)%
!% (!% *!% +!% ,!% &!% '!%
!"#$%$&'#()%*('%$(+&")%
,&%&-%+&'($%.$()%
/.0+1%$&'#%2%3&'#%'4#(%567#($8$(+9%
-./0%/102%340-"5-26%789:%
-./0%/102%340-"5-26%7('9:%
-./0%/102%340-"5-26%7+*9:%
-./0%/102%340-"5-26%7',9:%
*";<=>%6./2%?@.%7(!9:%

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Overview
i. Motivation and background - why multi-core
ii. Introduction to the EU funded Apple-CORE project
iii. The SVP execution model
iv. Microgrid implementation and evaluation
v. Summary

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Summary - models and software-engineering issues
• SVP provides a deterministic concurrency model with weakly consistent memory
• it composes without deadlock
• it has a well defined sequential schedule giving implementations of generic code at many levels of granularity
• resource deadlock problems are solvable
• For generality we add mutual exclusion as a place - to support OS services

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Summary architecture
• The microgrid is the finest possible SVP implementation
• We have demonstrated that it provides high efficiency execution across a range of applications
• The approach however is disruptive, it requires:
• new architectures, compilers and operating systems
• Cores can be tuned for depth or breadth of concurrency
• Core area optimised using very small L1 caches and by sharing large-area operations, e.g. FPUs, dividers
• 1st version of the FPGA prototype demonstrated in February this year in the 2nd Apple-CORE review

Universiteit van Amsterdam
Additional slides
Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
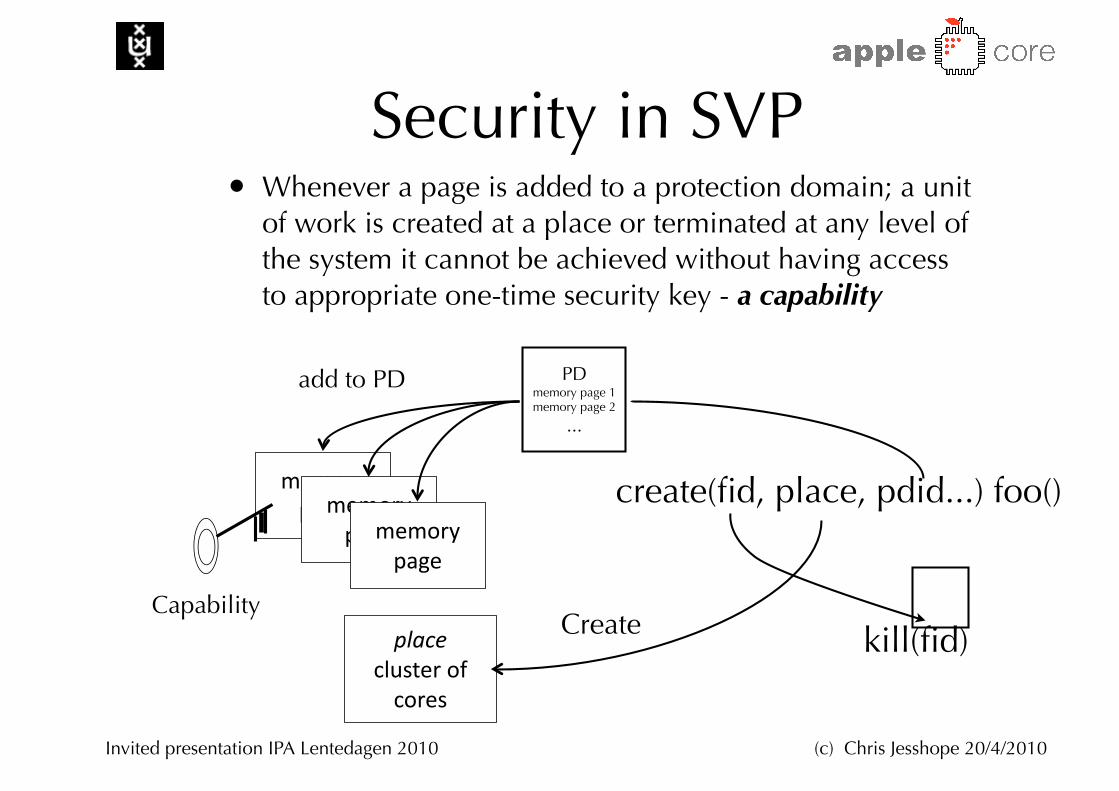
Security in SVP• Whenever a page is added to a protection domain; a unit
of work is created at a place or terminated at any level of the system it cannot be achieved without having access to appropriate one-time security key - a capability
memory pagememory
pagememory page
create(fid, place, pdid...) foo()
Capability
add to PD PDmemory page 1memory page 2
...
placecluster of cores
kill(fid)Create

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Resource allocation granularity
• The process of delegation and work creation is extremely efficient function delegation can be effective up to MHz rates
• 4K threads created executed and synchronised in 3.5K cycles in LMK7 benchmark - includes resource allocation
• This does not allow much time for analysis and hence we use JIT placeallocation
• At higher levels of the concurrency tree we have scope for analysis and resource partitioning

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
On-chip COMA memory
Microgrid resources
SEP
Unused core
SVP microgrid Comprises
Single virtual address space on chip with distributed shared memory
A grid of DRISC cores where clusters fixed or configured dynamically
SEP = resource manager
Families are delegated to clusters using a place
named place = clusterlocal = same processordefault = same cluster
Request
delegate
Configure e.g set capability
Return place
complete
Release

Invited presentation IPA Lentedagen 2010 (c) Chris Jesshope 20/4/2010
Multi-rooted allocation
main
static pipeline
dynamic sub-trees pipelineallocated by local SEP
Application concurrency treeSEP1 SEP2
SEP3 SEP4
dynamic adjustment
• For relatively static components resources (and allocators) can be partitioned with dynamic migration between partitions
Resource partitioning + dynamic allocation