developing streaming applications with apache apex (strata + hadoop world)
TRANSCRIPT

Developing Streaming Applications with Apache Apex
David Yan <[email protected]>PMC Member, Apache ApexSoftware Engineer, Google
Strata+Hadoop World, San Jose, CAMarch 16, 2017

Agenda● Technical Overview of Apache Apex as a streaming
platform● Developing an Application Pipeline● Developing an Operator, and the Operator Library● Event Time Windowing● Debugging, Scaling and Tuning● Q & A

What is Apache Apex? Why?● A platform for streaming applications● Written in Java● Uses YARN for resource management and HDFS for storage● Has a comprehensive operator library.● Scalable, fault tolerant, high throughput and low latency● Provides low-level control for performance tuning● Users include GE (Predix), Capital One, Royal Bank of Canada,
Pubmatic, SilverSpring Network, etc. ○ (more at https://apex.apache.org/powered-by-apex.html)

Technical Overview
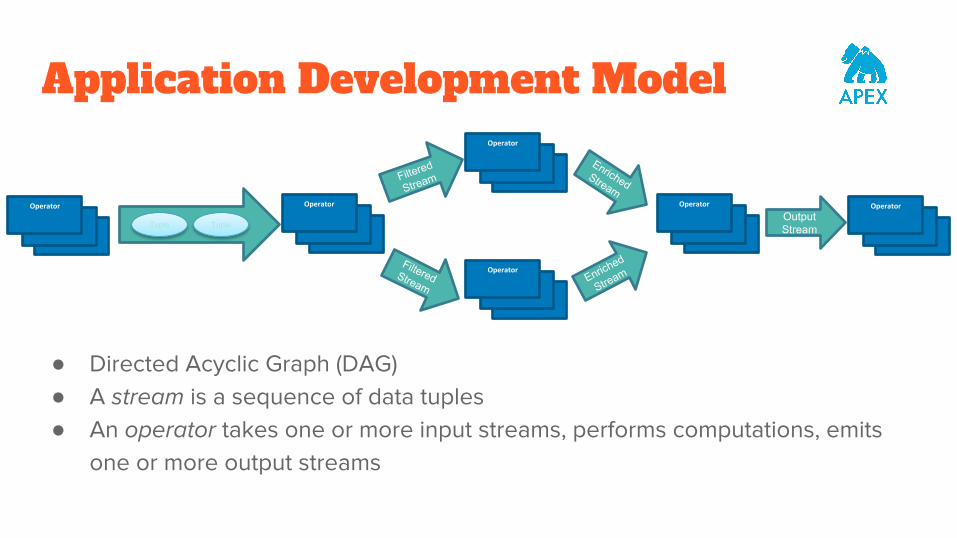
Application Development Model
● Directed Acyclic Graph (DAG)● A stream is a sequence of data tuples● An operator takes one or more input streams, performs computations, emits
one or more output streams
Filtered
Stream
Output StreamTuple Tuple
Filtered Stream
Enriched Stream
Enriched
Stream
er
Operator
er
Operator
er
Operator
er
Operator
er
Operator
er
Operator
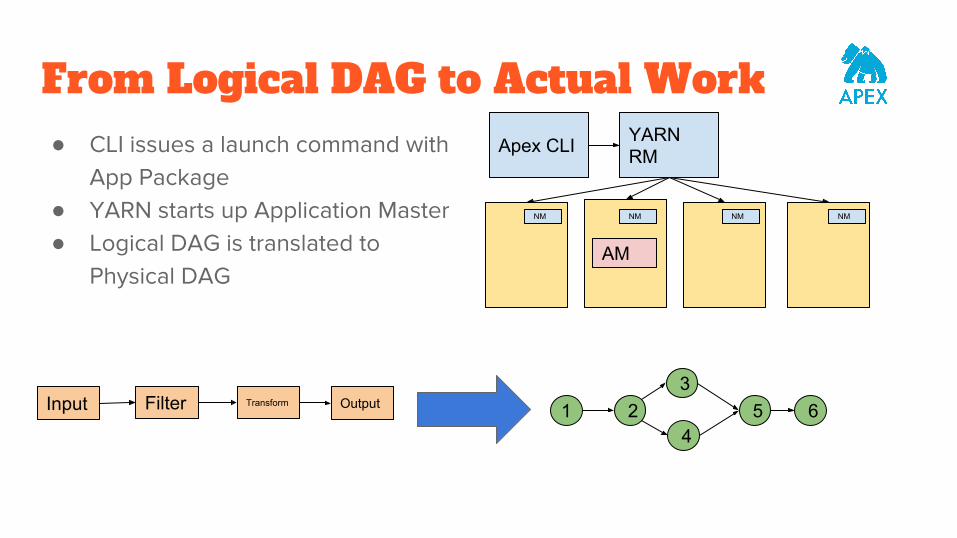
From Logical DAG to Actual Work ● CLI issues a launch command with
App Package● YARN starts up Application Master● Logical DAG is translated to
Physical DAG
Apex CLI YARN RM
NM NM NM NM
AM
1 23
45 6Input Filter Transform Output
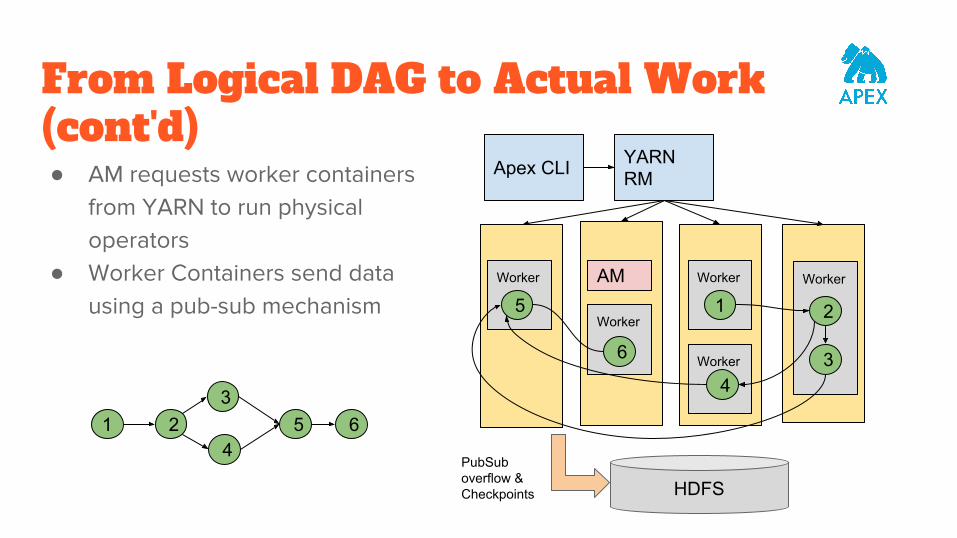
From Logical DAG to Actual Work(cont'd)● AM requests worker containers
from YARN to run physical operators
● Worker Containers send data using a pub-sub mechanism
Apex CLI YARN RM
AM Worker WorkerWorker
Worker
Worker6
4
1
3
25
1 23
45 6
HDFSPubSub overflow & Checkpoints
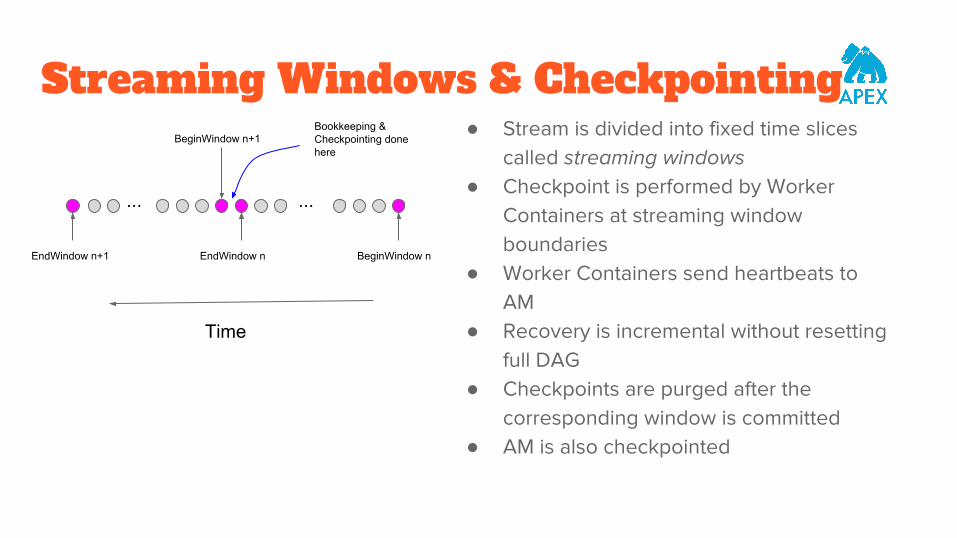
Streaming Windows & Checkpointing● Stream is divided into fixed time slices
called streaming windows● Checkpoint is performed by Worker
Containers at streaming window boundaries
● Worker Containers send heartbeats to AM
● Recovery is incremental without resetting full DAG
● Checkpoints are purged after the corresponding window is committed
● AM is also checkpointed
BeginWindow nEndWindow n
BeginWindow n+1
EndWindow n+1
Time
......
Bookkeeping & Checkpointing done here

Writing an Apex Application
Pipeline

Writing an Apex Application Pipeline ● Creating a project: Maven archetype● Two APIs to specify an Apex pipeline
○ Compositional○ Declarative

Compositional APIInput Parser Counter Output
CountsWordsLines
Kafka Database
FilterFiltered

Declarative API
StreamFactory.fromKafka09(brokers, topic)
.flatMap(input -> Arrays.asList(input.split("\\s+")))
.filter(input -> filterWords.contains(input))
.window(new WindowOption.GlobalWindow(),
new TriggerOption().accumulatingFiredPanes().withEarlyFiringsAtEvery(1))
.sumByKey(input -> new Tuple.PlainTuple<>(new KeyValPair<>(input, 1L)))
.map(input -> input.getValue())
.endWith(new JdbcOutput())
.populateDag(dag);
Input Parser Counter OutputCountsWordsLines
Kafka Database
FilterFiltered

Operators
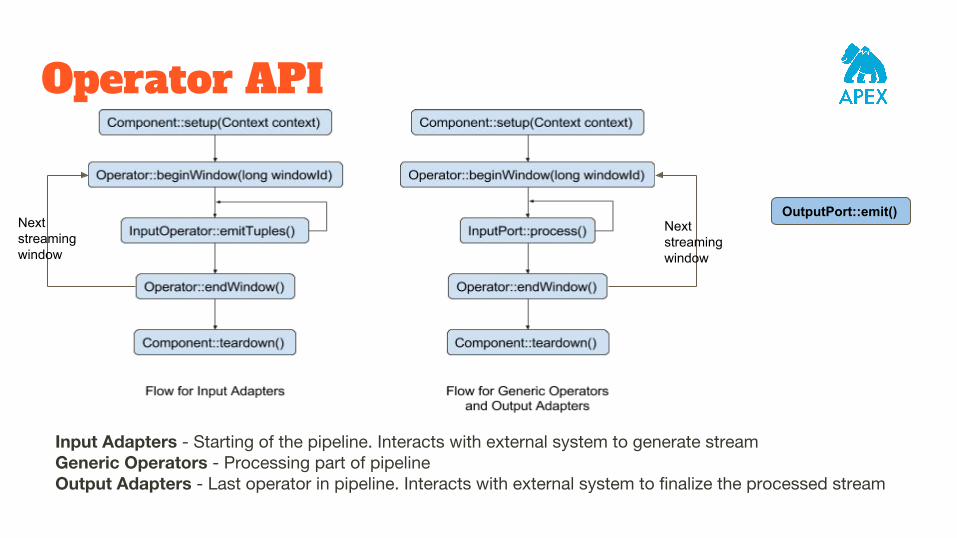
Operator API
Next streamingwindow
Next streaming window
Input Adapters - Starting of the pipeline. Interacts with external system to generate streamGeneric Operators - Processing part of pipelineOutput Adapters - Last operator in pipeline. Interacts with external system to finalize the processed stream
OutputPort::emit()

Operator Example (Stateless)

Operator Example (Stateful)

RDBMS• JDBC• MySQL• Oracle• MemSQL
NoSQL
• Cassandra, HBase• Aerospike, Accumulo• Couchbase/ CouchDB• Redis, MongoDB• Geode
Messaging• Kafka• JMS (ActiveMQ etc.)• Kinesis, SQS • Flume, NiFi• MQTT
File Systems• HDFS/ Hive• Local File• S3
Parsers• XML • JSON• CSV• Avro• Parquet
Transformations• Filters, Expression, Enrich• Windowing, Aggregation• Join• Dedup
Analytics• Dimensional Aggregations
(with state management for historical data + query)
Protocols• HTTP• FTP• WebSocket• SMTP
Other• Elastic Search• Script (JavaScript, Python, R)• Solr• Twitter
Apex "Malhar" Operator Library
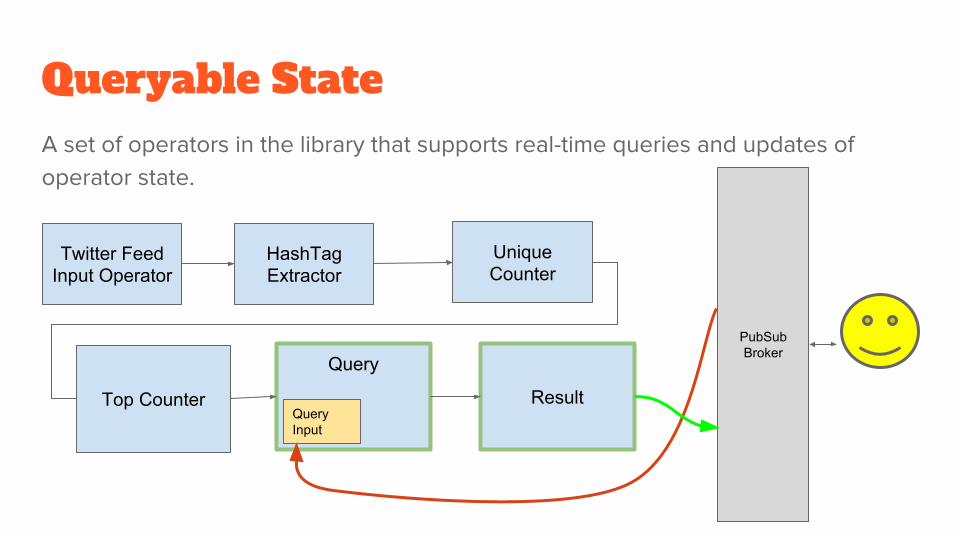
Queryable StateA set of operators in the library that supports real-time queries and updates of operator state.
HashTag Extractor
Top Counter
Twitter Feed Input Operator
Unique Counter
Query
Result
PubSub Broker
Query Input
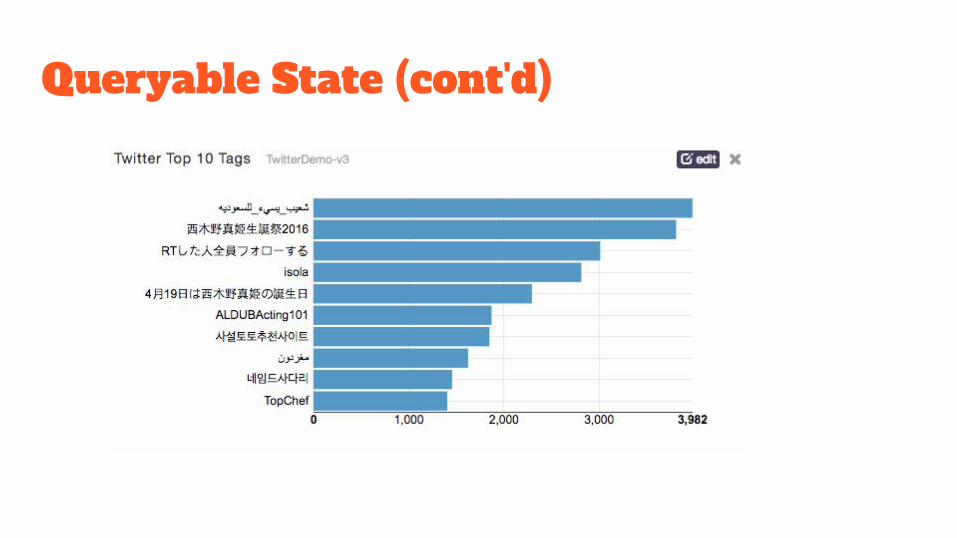
Queryable State (cont'd)

Event Time Windowing

What, Why, and How?● Event Time Windows not to be confused with "streaming windows"● Time of the event vs processing time and ingression time● Data often arrives late and out of order● Concepts outlined by Google's Millwheel and Apache Beam: Watermarks,
Allowed Lateness, Accumulation Modes, and Triggers

ExampleStreamFactory.fromFolder("/tmp")
.flatMap(input -> Arrays.asList(input.split( "\\s+")))
.map(input -> new TimestampedTuple<>(System.currentTimeMillis(), input))
.window(new TimeWindows(Duration.standardMinutes(5)), TriggerOption.AtWatermark() .accumulatingFiredPanes() .withEarlyFiringsAtEvery(Duration.standardSeconds(1)), Duration.standardSeconds(15)) .sumByKey(input -> new TimestampedTuple<>(input.getTimestamp(), new KeyValPair<>(input.getValue(),
1L ))))
.map(new FormatAsTableRowFn()) // format for printing
.print()
.populateDag(dag);

Debugging, Scaling & Tuning Your
Application

Debugging● Logs● Local Mode● Remote JVM Attachment● Tuple Recording
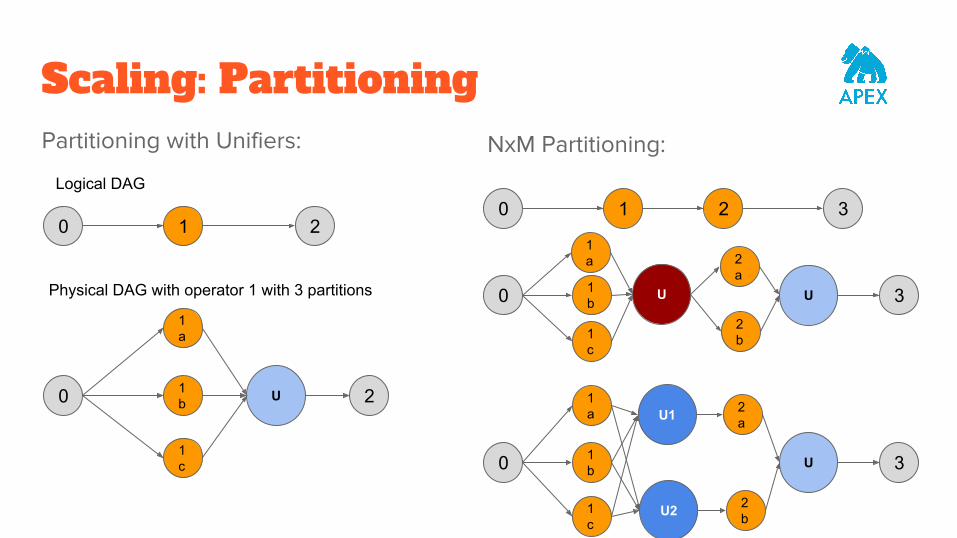
Scaling: PartitioningPartitioning with Unifiers: NxM Partitioning:
0 1 2
0
1a
1b
1c
U 2
Logical DAG
Physical DAG with operator 1 with 3 partitions
0 21 3
0
2a
1b 3
1a
1c
2b
U U
0
2a
1b 3
1a
1c
2b
U1
U
U2
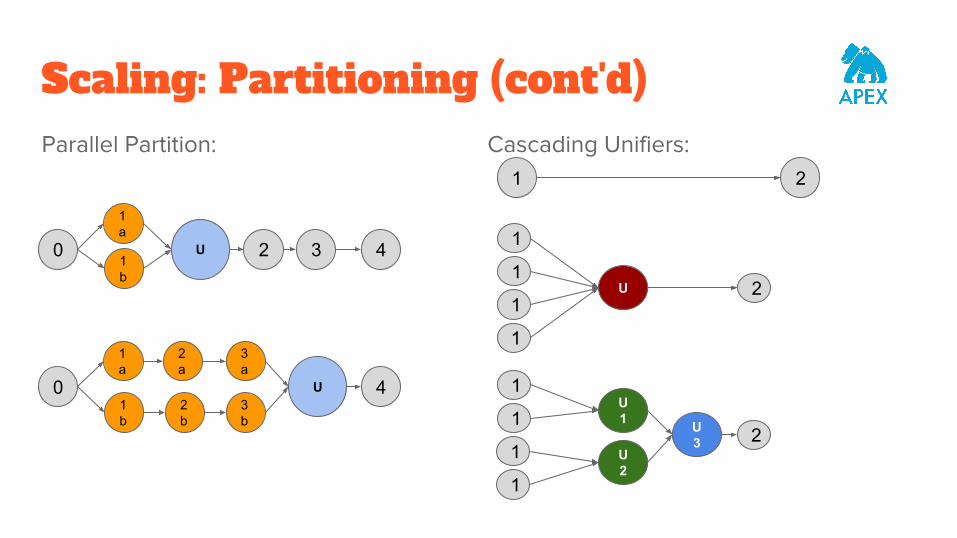
Scaling: Partitioning (cont'd)Parallel Partition: Cascading Unifiers:
0
1a
1b
U 2 3 4
0
1a
1b
U 4
2a
3a
2b
3b
1 2
1
1
1
1
U 2
1
1
1
1
U1
2U2
U3

Dynamic Partitioning● Partitioning change while
application is running○ Change number of partitions at
runtime based on stats○ Supports re-distribution of state when
number of partitions change○ API for custom scaler or partitioner
StatelessThroughputBasedPartitioner<MyOperator> partitioner = new StatelessThroughputBasedPartitioner<>(); partitioner.setCooldownMillis(45000);partitioner.setMaximumEvents(30000);partitioner.setMinimumEvents(10000);
dag.setAttribute(op, OperatorContext.STATS_LISTENERS, Arrays.asList(new StatsListener[]{partitioner}));
dag.setAttribute(op, OperatorContext.PARTITIONER, partitioner);

Locality● Node-Local: The two operators should be placed in the same node● Container-Local: Same worker container (saves serialization)● Thread-Local: Same thread (simple function call)
// setting locality between op1 and op2 to be NODE_LOCALdag.addStream("streamName", op1.output, op2.input) .setLocality(DAG.Locality.NODE_LOCAL);

Recent Additions and Roadmap● Apex runner in Apache Beam● Iterative processing● Integrated with Apache Samoa, opens up ML● Integrated with Apache Calcite, allows SQL
---------------------------------------------
● Enhanced support for Batch Processing● Support for Mesos and Kubernetes● Encrypted Streams● Python API

Q & A

Resources● http://apex.apache.org/● Learn more: http://apex.apache.org/docs.html ● GitHub Repositories
○ http://github.com/apache/apex-core○ http://github.com/apache/apex-malhar
● Subscribe - http://apex.apache.org/community.html● Download - http://apex.apache.org/downloads.html● Follow @ApacheApex - https://twitter.com/apacheapex● Meetups – http://www.meetup.com/topics/apache-apex/● Slideshare: http://www.slideshare.net/ApacheApex/presentations● https://www.youtube.com/results?search_query=apache+apex