clustered indexing for conditional branch predictors veerle desmet ghent university belgium
TRANSCRIPT

Clustered Indexingfor Conditional Branch Predictors
Veerle DesmetGhent University
Belgium

Clustered Indexingfor Conditional Branch Predictors
Veerle DesmetGhent University
Belgium

3
Conditional Branches
if (i > 0)/* something */
else /* something else */
for (i=0; i<50; i++) {
/* a loop... */ }/* next statements */ How frequent do
conditional branches occur?
1/8

4
Program Execution
Fetch = take next instruction Decode = analyze type and
read operands Execute Write Back = write result
Fetch Decode Execute Write Back
R1=R2+R3
addition4 3
computation
R1 contains 7

5
Pipelined architectures
Parallel versus sequential:
Constant flow of instructions possible Faster applications Limitation due to conditional branches
Fetch Decode Execute Write Back
R1=R2+R3R1=R2+R3R5=R2+1 R1=R2+R3R5=R2+1R4=R3-1 R1=R2+R3R5=R2+1R4=R3-1R7=2*R1 R5=R2+1R4=R3-1R7=2*R1R5=R6 R4=R3-1R7=2*R1R5=R6R1>0
6
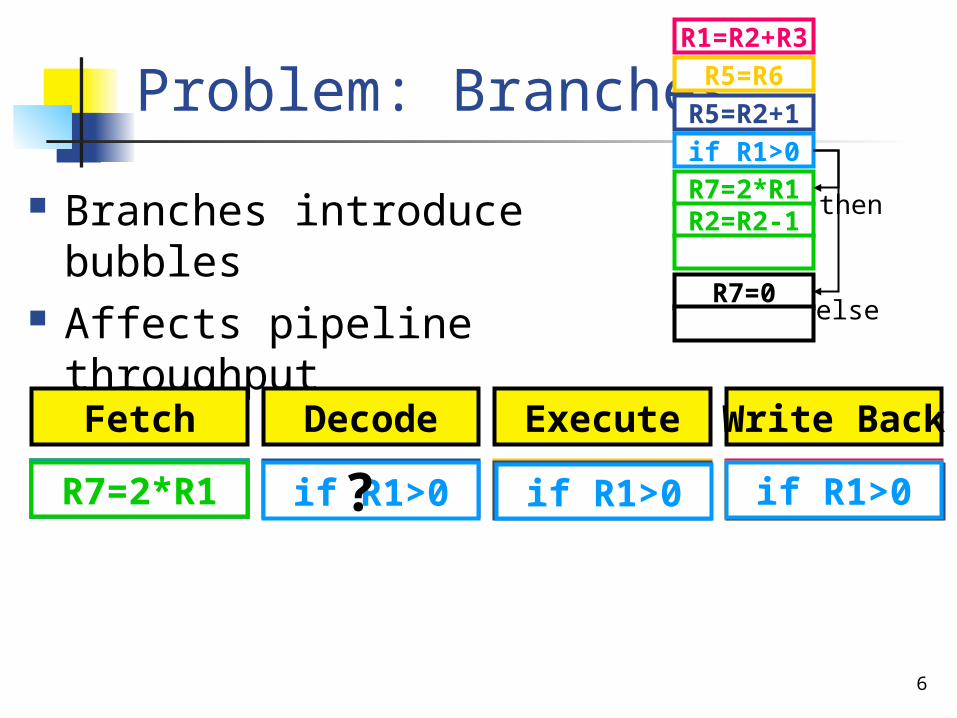
Problem: Branches
Branches introduce bubbles
Affects pipeline throughputFetch Decode Execute Write Back
R1=R2+R3 R1=R2+R3R5=R2+1 R5=R2+1R4=R3-1R7=2*R1R5=R6 R5=R6if R1>0 if R1>0 R5=R2+1 R5=R6? if R1>0 R5=R2+1?? if R1>0R7=2*R1
R1=R2+R3
R5=R2+1
R7=0
R7=2*R1
R5=R6
if R1>0
else
thenR2=R2-1

7
Solution: Prediction
Fetch those instructions that are likely to be executed
Fetch Decode Execute Write Back
R1=R2+R3
R5=R2+1
R7=0
R7=2*R1
R5=R6
if R1>0
else
thenR2=R2-1
R1=R2+R3 R1=R2+R3R5=R2+1 R5=R2+1R4=R3-1R7=2*R1R5=R6 R5=R6if R1>0 if R1>0 R5=R2+1 R5=R6R7=2*R1 if R1>0 R5=R2+1R7=2*R1R2=R2-1
correct prediction = gainmisprediction = penalty

8
Nowaday’s Architecturein
stru
ctio
n c
ach
e
fetc
h
deco
de
reg
iste
r re
nam
e
dis
patc
h
inst
ruct
ion
w
ind
ow
re-orderlogic
functionalunit
register file
IPC
functionalunit
functionalunit
functionalunit
Branchpredictor

Clustered Indexingfor Conditional Branch Predictors
Veerle DesmetGhent University
Belgium

10
Bimodal Branch Predictor
Predict outcome of condition e.g. if or else based on unique branch
address
Update prediction table
k
Branch address
predictiontable

11
Global History Branch Predictor
k
Global history
predictiontable
Predict outcome of condition e.g. for loop based on global history 111101111011110
Update prediction table and global history

12
Gshare Branch Predictor
k
Global history
Branch address
Original index
predictiontable
[McFarling]
XOR

13
Misprediction rate: gshare
0
5
10
15
20
25
10 100 1000 10000 100000 1000000
predictor size (bytes)
mis
pred
ictio
n ra
te
SPEC INT 2000
better
14
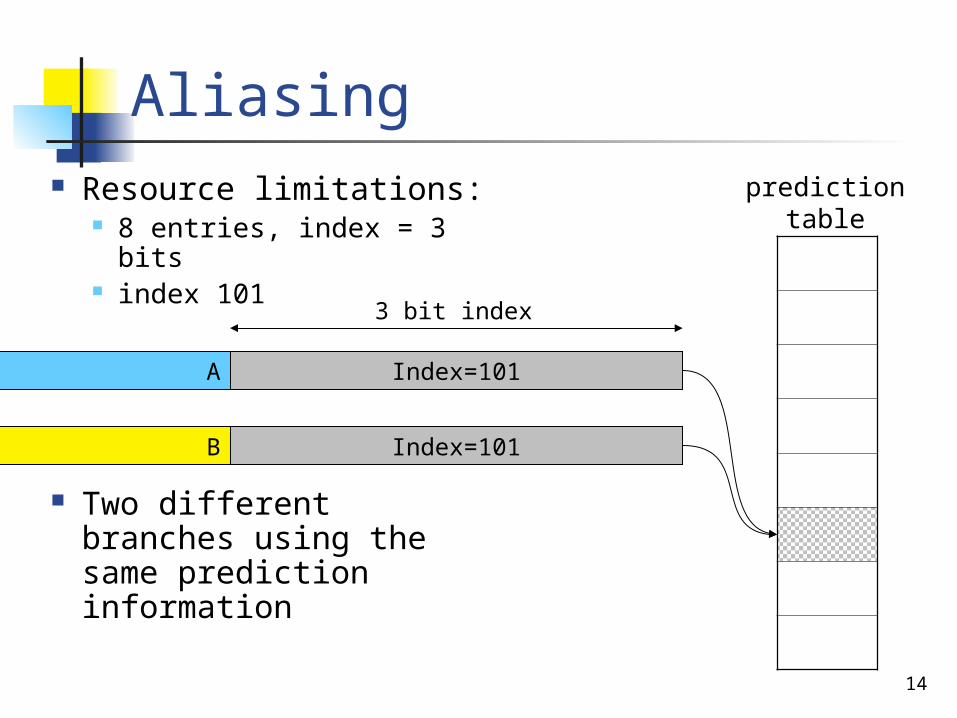
Aliasing Resource limitations:
8 entries, index = 3 bits index 101
Two different branches using the same prediction information
3 bit index
Index=101
Index=101B
A
predictiontable
15
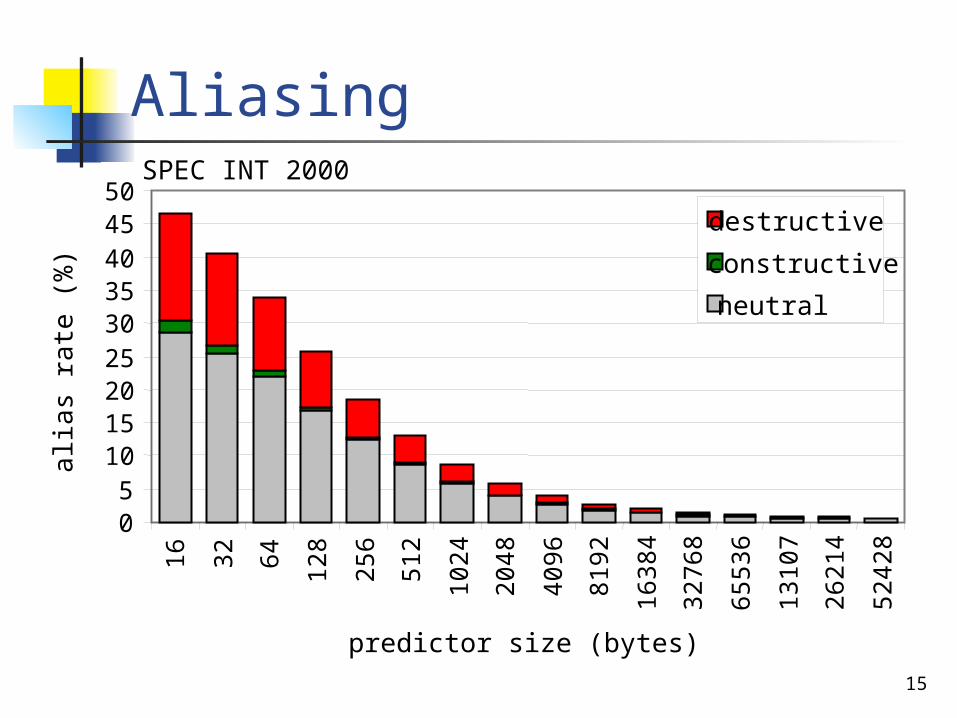
Aliasing
05
101520253035404550
16 32 64 128
256
512
1024
2048
4096
8192
1638
4
3276
8
6553
6
1310
7
2621
4
5242
8
predictor size (bytes)
alia
s ra
te (
%)
destructive
constructive
neutral
SPEC INT 2000

Clustered Indexingfor Conditional Branch Predictors
Veerle DesmetGhent University
Belgium

17
Basic Observations
Branches with similar behavior can share prediction information 1 1 1 1 0 0 0 0 1 1 1 1 0 1 0 1 1 1 1 1 0 0 0 0 1 1 1 1 0 1 0 1
Branches can use same table entry, e.g. 1 1 1 1 0 0 0 0 1 1 1 1 0 1 0
time

18
Time Varying Behavior
1 1 1 1 0 0 0 0 1 1 1 1 0 1 0 1
1 1 1 1 0 0 0 0 1 1 1 1 0 1 0 1 1 1 1 1 0 0 1 0 0
1 1 1 1 0 1 0
100% 0% 100% 50%
100% 0% 100% 60%
100% 25% 0% NE
NE NE 100% 33%
A:B:C:D:
A:B:C:D:
phase
NE = not executed
phase phase phase

19
Branch Clustering
Each branch represents a point in N-dim space
Clusters formed by k-means algorithm
A:B:C:D:
100% 0% 100% 50%
100% 0% 100% 60%
100% 25% 0% NE
NE NE 100% 33%

20
k-Means Cluster Algorithm
X
X
1. initial centers 2. calculate nearest center
X
X
4. Restart with new centers
XX
3. redefine centers
X
X
XX

21
k-Means Cluster Algorithm
XX
1. initial centers
Stable solution
X X X X
X X
2. calculate nearest centers
3. redefine centers

22
Determining k of k-Means
k is chosen by BIC-score (Bayesian Information Criterion) Tradeoff between k and goodness of a clustering
Stable solution with k=2
X X
Stable solution with k=3
X
XX
best?

23
Branch Clustering
SPEC INT 2000 from 8 to 33 clusters mcf: 8 gcc, parser: 33
Each branch belongs to exactly one cluster
100% 0% 100% 50%
100% 0% 100% 60%
100% 25% 0% NE
NE NE 100% 33%
A:B:C:D:
Cluster
Cluster
Cluster
Cluster

Clustered Indexingfor Conditional Branch Predictors
Veerle DesmetGhent University
Belgium

25
Subtables Example
8 entries, index = 3 bits
4 clusters, 2 bits Original index 101
3
Index = 1Cluster
predictiontable

26
Subtables Example
8 entries, index = 3 bits
4 clusters, 2 bits Original index 101
3
Index = 1Cluster
predictiontable

27
Subtables Example
8 entries, index = 3 bits
4 clusters, 2 bits Original index 101
3 to 6 bits for cluster [SPECint2000]
can be used in every predictor scheme
3
Index = 1Cluster
predictiontable

28
Subtables for Bimodal
Cluster Branch addr
predictiontable
0
5
10
15
20
25
10 100 1000 10000 100000 1000000
predictor size (bytes)
mis
pre
dic
tion
rat
e
bimodal original
bimodal clustered

29
Subtables for Gshare
Cluster Branch addrprediction
table
Global history
0
5
10
15
20
25
10 100 1000 10000 100000 1000000
mis
pre
dic
tion
rat
e
gshare original
gshare clustered
predictor size (bytes)
19% better for SMALL predictors

30
Why Clustered Indexing Works
05
101520253035404550
16 32 64 128
256
512
1024
2048
4096
8192
1638
4
3276
8
6553
6
1310
7
2621
4
5242
8
predictor size (bytes)
alia
s ra
te (
%)
destructive
constructive
neutral
05
101520253035404550
16 32 64 128
256
512
1024
2048
4096
8192
1638
4
3276
8
6553
6
1310
7
2621
4
5242
8
predictor size (bytes)
alia
s ra
te (
%)
destructive
constructive
neutral
Subtabling Uses smaller predictors More aliasing expected… but
More constructive aliasing

31
Hashing: Alternative to Subtables
Keeps original global history length
Global history
Gshare ix index
Branch addr Cluster
predictiontable

32
Hashing for Gshare
0
5
10
15
20
25
10 100 1000 10000 100000 1000000
predictor size (bytes)
mis
pre
dic
tion
ra
te
gshare original
gshare clustered: subtables
gshare clustered: hashed
3,5
4
4,5
5
5,5
6
6,5
7
7,5
1000 10000 100000 1000000
predictor size (bytes)
mis
pre
dic
tion
ra
te
gshare original
gshare clustered: subtables
gshare clustered: hashed
5% better for LARGE predictors

33
Self Profile-Based Clustering
Limit study Identified clusters optimal for given
execution
100% 0% 100% 50%
100% 0% 100% 60%
100% 25% 0% NE
NE NE 100% 33%
A:B:C:D:
Cluster
Cluster
Cluster
Cluster
34
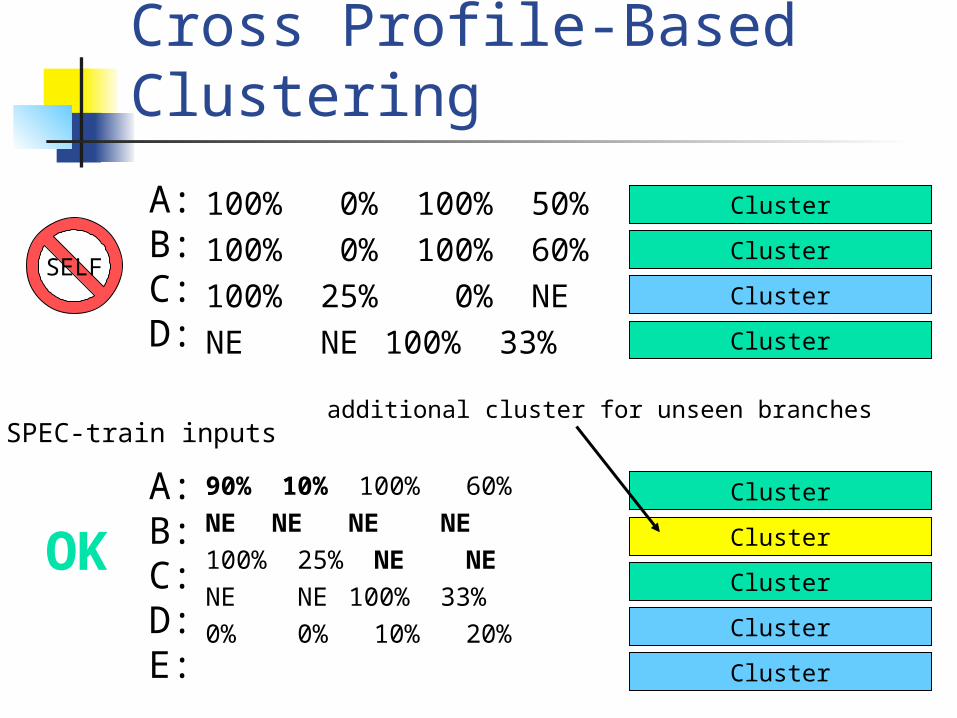
Cross Profile-Based Clustering
100% 0% 100% 50%
100% 0% 100% 60%
100% 25% 0% NE
NE NE 100% 33%
A:B:C:D:
Cluster
Cluster
Cluster
Cluster
SELF
90% 10% 100% 60%
NE NE NE NE
100% 25% NE NE
NE NE 100% 33%
0% 0% 10% 20%
A:B:C:D:E:
Cluster
Cluster
Cluster
SPEC-train inputs
OK Cluster
additional cluster for unseen branches
Cluster

35
Cross Profile-Based Clustering
0
5
10
15
20
25
10 100 1000 10000 100000 1000000
predictor size (bytes)
mis
pred
ictio
n ra
te
bimodal originalbimodal self clusteredbimodal cross clustered
0
5
10
15
20
25
10 100 1000 10000 100000 1000000
predictor size (bytes)
mis
pred
ictio
n ra
te
gshare originalgshare self clusteredgshare cross clustered
3,5
4
4,5
5
5,5
6
6,5
7
7,5
1000 10000 100000 1000000
predictor size (bytes)
mis
pred
ictio
n ra
te
gshare originalgshare self clustered: subtablesgshare self clustered: hashedgshare cross clustered: subtablesgshare cross clustered: hashed
cross clustered still good
GSHARE @ small budgets: subtables
12.3% less mispredictions(19% self clustered)
@ large budgets: hashing3% better(5% self clustered)

36
Conclusion
Small branch predictors suffer from aliasing frequently destructive
Exploit constructive aliasing by clustering branches
Implementation subtables (can be used in all branch prediction
schemes) hashing (specific for gshare)
Gshare misprediction rate @ 1KiB: reduced by 19% (self), 12.3% (cross)@ 256KiB: reduced by 5% (self), 3% (cross)

Questions?

The End