big data workforce - purdue krannert · in the current era, for example, ... 1the use of big data...
TRANSCRIPT

Comments are appreciated: [email protected]. I am indebted to Monica Rogati and Daniel Tunkelang at LinkedIn for valuable feedback and assistance with data collection and analysis. I have also benefited from discussions with Frank Nagle, Foster Provost, and seminar participants at LinkedIn, New York University, and the University of Maryland. I am grateful to the Alfred P. Sloan Foundation for financial assistance.
HOW THE IT WORKFORCE AFFECTS RETURNS TO IT INNOVATION: EVIDENCE FROM BIG DATA ANALYTICS
Prasanna Tambe NYU Stern
DRAFT
Last Revised, December 2012
Abstract
This paper tests the hypothesis that a firms’ own investments in new IT innovations are a strategic complement to the investments of other firms in the same labor market when the supply of new technical skills and know-how is rapidly changing, fading over time as the supply of technical skills adjusts. The principal contribution of the paper is the use of a new data source—the LinkedIn skills database—to measure the emergence of technical know-how related to big data analytics within the US IT workforce, and its transmission among firms through worker mobility. From 2006 to 2012, firms’ employment of big data engineers was highly localized, and was associated with 4-5% faster productivity growth and 2% growth in sales share relative to other firms in the same four-digit industry, but only for employers with access to technical workers from other firms making big data investments. Evidence for these complementarities disappears for more mature IT innovations, including traditional database management systems. These findings suggest the importance of emerging technical know-how as a supply-side factor explaining the rate at which value is unlocked from new IT innovations. Implications are discussed for the big data skills gap and for a big data enabled digital divide.

2
1.0 Introduction
Early adopters face a number of obstacles when implementing new information
technologies. One in particular, a “shortage” of the expertise required to successfully
implement new technologies, tends to attract significant media and policy attention
during technology boom periods. This paper argues that during the early days of the
spread of IT innovations, firms’ investments in the new innovation exhibit strategic
complementarities passed through the labor market for skills and know-how
complementary to the new innovations, allowing employers in these labor markets to
more rapidly derive productivity advantages from the new technologies. The impact of
these complementarities is strongest during periods of rapid technological change when
complementary technical skills are a bottleneck for unlocking value, but lose importance
over time as the supply of these new skills adjusts to meet demand.
In the current era, for example, there has been policy concern about how
emerging skill gaps might harm prospects for “big data” related innovation and
productivity growth (Mckinsey 2011; Rooney 2012).1 In addition to contributing to the
academic literature on determinants of variation in IT-enabled productivity growth rates,
this paper has implications for understanding systematic differences in the returns to IT
innovation. For example, the current debates on the impact of the big data skills shortage
reflect a gap in the academic literature on IT-enabled productivity growth. Most work in
this area focuses on the effects of IT capital inputs and complementary organizational
factors on firm performance (e.g. see Melville, Gurbaxani and Kraemer 2004), with little
emphasis on how the development of skills complementary to new technical innovations
1The use of big data tools has been associated with the emergence of a new generation of technical skills. Examples of these emerging skills are Hadoop, Map/Reduce, Apache Pig, Hive, and Hbase.

3
affects the rate of technological change. This omission is noteworthy because recent work
finds evidence of significant differences in IT-enabled growth rates across geographic
regions during the dot-com boom, even though the hardware and software inputs required
for implementing Internet-enabled business practices are generally available at common
factor prices throughout the United States (Forman, Goldfarb, and Greenstein 2012). This
puzzle suggests the presence of a “missing” factor of production in some IT-intensive
labor markets that grows increasingly important during periods of rapid IT innovation.
Differences in the supply of skills required for implementing these new technological
innovations are a plausible, yet unexamined, explanation for these findings.
This investigation into the impact of the skill content of the IT labor pool requires
measuring the emergence of new technical know-how in US labor markets. Prior work in
this area uses data on the cross-firm flow of workers by occupation (Tambe and Hitt
2012), but this is the first paper to examine the emergence of new technical know-how
within the IT workforce. The main innovation in the paper is analysis of a new data set
describing, at a extremely fine-grained level of detail, technical skills for a large fraction
of the US IT workforce. These data are analyzed in partnership with LinkedIn, a popular
online professional network2 on which participants, in addition to listing employers and
occupations in their profiles, list professional technical skills such as Java, SQL, Apache
Pig, and Hadoop. The granularity in the skills data and the massive scale of its collection
enable measurement of the skill content of employers and labor markets. For this
analysis, this level of detail is necessary for identifying workers with emerging big data
skills, and distinguishing them from IT workers with skills complementary to mature IT
2 See http://www.linkedin.com. These data were collected while the author was in-residence at LinkedIn in Mountain View, California.

4
innovations. Although data from online databases such as these can raise sampling
concerns, potential issues arising from these sampling concerns are specifically addressed
later in the analysis. To the best of my knowledge, these types of skill data are not
available through any alternative data source, and data sets based on IT employment
levels or IT capital expenditures are not sufficiently detailed to conduct the types of
comparisons required in this analysis. Therefore, among its other contributions, this study
demonstrates how emerging sources of data on labor market activity enable insights
related to labor policy and employment strategy.3
The principal contribution of the paper is that the analysis of technical skill data
can generate insights into how differences in the skill content of labor markets can affect
firm performance. Although prior work examines spillovers from IT investments using
IT labor flow data at the occupational level (Tambe and Hitt 2012), these data cannot
produce insights into the reasons underlying superior performance for some groups of
firms (such as those in some geographic regions), because IT investment levels or IT
employment flows are generally not sufficient to differentiate firms investing in new IT
innovations from all other firms. The data analyzed in this paper have the notable
advantage that they enable measurement of differences in the accumulation of know-how
complementing new IT innovations, such as big data technologies, which rather than
overall IT employment levels or capital spending, has been argued to be a key factor
distinguishing high-tech labor markets from labor markets in other cities (Saxenian
1996). Measurement of these factors may explain why firms in some labor markets
3 For example, in comparison to the data collection approach used in this paper, a survey based approach would have significant shortcomings because it requires collecting data at a scale that would be prohibitive and at a level of detail that employers in general do not retain (e.g. employee outflows).

5
perform better than others, and why firms that invest in early stage IT innovations choose
to locate in these labor markets.
The results from the analysis are consistent with the hypothesis that labor market
spillovers are important for understanding differences in returns from investments in new
IT innovations, but not for investments in mature information technologies. Distributional
comparisons of the technical skills data indicate that emerging big data skills such as
Hadoop, Apache Pig, Hbase, and Map/Reduce are highly geographically concentrated—
over 30% of the big data workforce is employed in Silicon Valley, compared with 4% of
total US IT employment in that region. Furthermore, analysis of the geographic
distribution of all major technical skills provides support for the hypothesis that the short-
run supply of skills complementary to new IT innovations is geographically concentrated,
which is consistent with an economics literature on the how the spatial concentration of
productive activity changes with the age of technical innovation (Desmet and Rossi-
Hansberg 2009).
Second, productivity regressions provide evidence of complementarities between
a firm’s own big data investments and the investments of other firms in the same labor
market. Pooled OLS regressions suggest an output elasticity of 9% for big data
investment, but this falls to only 2% when using fixed-effects or first-differences
estimators, suggesting substantial unobserved heterogeneity between big data firms and
other firms. Importantly, these investments only produce significant returns for firms
hiring in labor markets in which other firms are making similar investments. Moreover,
evidence for complementarities for aggregate IT investments disappears when
investments in big data are directly included into the production function—in other

6
words, these strategic complementarities are primarily important during the early stages
of IT innovation, when the supply of new technical skills is constrained and there are few
institutions through which these skills can be acquired. The economic importance of
these spillovers for unlocking the value of new technological innovations, in combination
with the regional scope of labor markets, suggests why firms in some regions are more
rapidly able to capture value from new IT innovations, and experience faster productivity
growth during technology booms. These findings are robust to several specifications as
well as tests for robustness to measurement error in the skills data.
These findings make contributions to two academic literatures. First, it extends
the IT productivity literature towards an understanding of why some groups of firms,
such as those embedded in a common labor market, systematically outperform others
during periods of rapid technological innovation. This is important because there is
growing evidence that firms and workers in some regions have enjoyed greater benefits
from recent waves of IT innovation than others (Dewan and Kraemer 2000; Bloom,
Sadun, and Van Reenen 2012; Forman, Goldfarb, and Greenstein 2012) and there is
concern that the current wave of big data innovation will further widen an already
existing digital divide across regions (Freeland 2010; Dewan, Ganley, & Kraemer
forthcoming). The findings in this paper suggest that this separation will systematically
widen during periods characterized by rapid technical innovation and the emergence of
new skills. Finally, because these findings imply social returns from the investments of
other firms transmitted through the labor market, this paper contributes to a literature on
IT spillovers (Cheng and Nault 2007, 2011; Chang and Gurbaxani 2012; Tambe and Hitt
2012b) as well as to a literature on IT labor markets and the management of IT human

7
resources (Agarwal and Ferratt 2001; Ang, Slaughter, and Ng 2002; Levina and Xin
2007; Bapna et al 2012).
Second, this study presents the first large-scale statistical evidence of returns to
big data investment, and therefore contributes to the IT value literature (Brynjolfsson and
Hitt 1996, 2003; Dewan and Min 1997) as well as to an emerging literature on the value
of data analytics (Brynjolfsson, Hitt, and Kim 2011; Barua, Mani, and Mukherjee 2012).
Existing empirical work on the value of data analytics finds evidence of significant
returns to data driven decision-making practices, but does not distinguish between big
data technologies and traditional database management systems. Given the media
attention that has been focused on the former, it is important to understand whether
higher returns can be attributed specifically to big data technologies, or alternatively, to
growing demand for data practices more generally. Moreover, due to the reliance of big
data technologies on open source software and commodity hardware, it may be
particularly difficult to measure the impact of these technologies using data collected on
hardware or software expenditures.4 Therefore, the empirical approach in this paper,
using data on the employment of workers with big data skills, may be among the most
reliable ways to measure firms’ big data usage as well as its impact.
2.0 Technology Background and Key Hypotheses
2.1. Technology Definitions
By many accounts, US firms are at the cusp of a data-driven revolution in
management. Modern businesses capture enormous amounts of fine-grained data related,
for example, to social media activity, RFID tags, clickstream activity, consumer
4 See Greenstein and Nagle (2012) for a discussion of the difficulties associated with measuring open source software use and value.

8
sentiment, and mobile phone usage, and the analysis of these types of data promises to
produce insights that will revolutionize managerial decision-making. The massive scale
of this data collection has, in many cases, outpaced firms’ abilities to create new insights
using existing technologies. Therefore, over the last few years, there has been growing
interest in the potential economic impact of emerging “big data” technologies, which
facilitate data analysis at a scale that exceeds the capabilities of existing database
management systems, and which many academic and industry observers believe will
drive a new wave of innovation and productivity growth (Mckinsey 2011; Brynjolfsson
and Mcafee 2011).
The term “big data” is used to describe technologies enabling the collection,
management, and analysis of datasets that are too large for conventional database
management systems (Dumbill 2012). As a solution to the limitations of existing
database management systems, these technologies use massively parallel computing
approaches for data analysis. Although distributed data processing has a longer history
(e.g. Provost and Kolluri 1999 survey a literature in this area over a decade ago), the
scale and rate of data collection in recent years has significantly raised the returns to
innovation in these technologies.
The origins of big data technologies can be traced to employees at Google who, in
2004, began using big data algorithms to support distributed processing. Apache Hadoop,
the most widely used software platform for big data analytics, is derived from the
Map/Reduce framework, implemented in the Java programming language, and freely
distributed under an open source license. This open source project has a number of
subprojects such as Cassandra, Pig, Hive, and HDFS, that handle different parts of the

9
Hadoop cluster interface, communication, and processing flow. Big data infrastructure
requires the implementation of this software and data environment on clusters of
computers. Because both the hardware and software required to support big data are
readily available to firms, the primary expense that firms face when implementing big
data technological solutions is the acquisition of expertise required to install, maintain,
and facilitate these clusters to support data analysis.
2.2. Key Hypotheses
This paper argues that the short-run supply of technical skills complementary to new IT
innovations governs the pace of technical change associated with these innovations. In
particular, firms derive benefits from spillovers of the human capital generated through
the IT investments of other firms when the supply of these skills is constrained. The
hypothesized importance of the geographic concentration of new technical skills for
regional variation in IT-enabled growth is closely related to work on how R&D spillovers
impact economic geography and firm performance. The literature on R&D spillovers
demonstrates that firms derive significant benefits from the R&D activities of their
technological neighbors (Jaffe 1986), that limits to the geographic range of mechanisms
through which these R&D spillovers are transmitted explain the geographic concentration
of firms conducting similar R&D (Jaffe, Trajtenberg, and Henderson 1993; Audretsch
and Feldman 1996), and that firms make strategic decisions based on access to these
spillovers (Alcacer and Chung 2007).
In a recent literature, scholars argue that firms’ IT investments also generate
productivity spillovers (Dedrick, Gurbaxani, and Kraemer 2003; Cheng and Nault 2007,
2011; Chang and Gurbaxani 2012; Tambe and Hitt 2012b). Like R&D investments, IT

10
investments generate technical know-how, embodied in the skill content of the IT
workforce. For early IT innovations, when there is a limited supply of technical skills
complementary to the new innovation, the investments of early adopters are important for
the accumulation of this technical know-how in labor markets. As the intermediate-run
supply of these skills adjusts to meet rising demand for the new technological innovation
through the emergence of institutions such as university degree programs through which
this technical human capital can be acquired, the importance of the investments of initial
adopters becomes less important for producing these skills. Therefore, this paper argues
that in the early stages of IT innovation, geographically concentrated early adopters
capture social benefits from the investments of other firms, transmitted through thicker
labor markets for skills complementary to emerging IT innovations. For the recent wave
of big data innovation, this generates two testable hypotheses:
H1: Skills complementary to new IT innovations are more geographically concentrated
than mature technical skills.
H2: Investments in new IT innovation by other firms in the same labor market are
complementary to a firm’s own investments in the innovation.
A further distinction between IT and R&D know-how is that as a “general-purpose”
technology, IT innovations impact firms in all industries. While returns to R&D
spillovers depend on the firm’s technological position (Jaffe 1986), benefits from IT
spillovers are more closely related to organizational factors governing returns to the
adoption of technological innovations, rather than industry or technological position.
Therefore, rather than clustering by industry, firms will geographically concentrate nearer
sources of new technical know-how if justified by their expected returns to early IT

11
adoption, regardless of industry position. Because the presence of these spillovers implies
that IT-intensive regions will attract firms with the highest returns to investing in early IT
innovations, productivity and wage growth related to new IT innovations can be expected
to be systematically faster in these labor markets.
3.0 Data and Key Measures
3.1 Primary Data Source
The primary data source for this analysis is the LinkedIn database. LinkedIn is a
professional networking site with over 175 million users worldwide.5 Web site
participants typically list professional information on their user profiles, including
employment histories with employers and job titles, education, geographic information,
accomplishments, and interest groups. In addition, LinkedIn asks participants to list
individual skills (e.g. C++, Java, Hadoop). To the best of my knowledge, this is the
largest database ever assembled on firms, workers, and skills in the US, and this paper is
the first to use this entire database for social science research.6
No prior work has examined the IT workforce at a level of analysis permitting
skill-based comparisons over large samples of firms and regions. However, this level of
detail is required for this analysis because it enables measurement of the emergence of
big data related skills within particular firms and regions, in a sample large enough to
support large-scale statistical inference. The data sources on IT employment levels or IT
capital spending that inform most existing research on IT productivity are not sufficient
for understanding skill-based geographic differences in IT-enabled productivity growth
rates. For instance, the descriptive statistics reported below illustrate that while the big
5 See http://www.linkedin.com. 6 These data were collected while the author was in-residence at LinkedIn in Mountain View, California.

12
data workforce is highly concentrated in a few regions, more common technical skills
such as SQL or Java are evenly distributed across major metropolitan regions, and are
therefore unlikely to have much explanatory power for differences in productivity growth
across labor markets.
Firm-level measures of investment in big data innovation were created using the
number of IT employees at the firm who report having a single emerging technical skill:
Hadoop. Although there are a number of emerging technical skills complementary to big
data innovation, there is no existing, standardized taxonomy of technical skills and
importantly, Hadoop has been identified by many industry observers as the technical skill
most closely associated with the current wave of big data innovation (Dumbill 2012,
Bertolucci 2012). Therefore, the employment of engineers listing Hadoop as a skill is
likely to be highly correlated with a firm’s big data activities. Although it is possible a)
that firms who employ workers with these skills are not investing in big data or b) that
firms that are investing in big data technologies do not employ any workers who list
Hadoop on LinkedIn profiles, both types of measurement error lead to an attenuation
(downward) bias on the main effect estimates of big data use. Nonetheless, the potential
impact of this type of measurement error on the key estimates of the paper is addressed in
several robustness checks at the end of the analysis.
Because the LinkedIn data include geographic information for workers, these big
data measures can also be created at the regional level as well as the firm-region level,
where a region in the LinkedIn database corresponds to a metropolitan area. Although the
firm-region level of analysis is less precise than the establishment level comparisons used
in some IT adoption research (e.g. Forman 2005), it provides useful variation beyond the

13
firm level when examining how the labor pool impacts returns to investment. Moreover,
much of the economics literature has treated the metro region as the key observational
unit for labor market analysis (e.g. see Card 1990; Borjas, Freeman, and Katz 1996), so
this level of analysis may be the most appropriate one when considering skill-based labor
market differences. Similar methods to the ones described above are used to create firm
and firm-region measures of other skills, including SQL, Java, and SAP.
The LinkedIn database was also used to create measures of total IT employment
at the firm as well as to identify other firms in the focal firm’s IT labor pool. Firm level
IT employment measures are created by summing the number of US-based IT workers in
the database who report working for an employer in a given year. This method of creating
IT employment measures is similar to prior work in the IT economics literature that uses
employment history databases (citation blinded), but due to the fraction of the US
technical workforce represented in the LinkedIn database, requires fewer sampling
corrections. Other firms in the labor pool are identified using data on the firm-to-firm
transitions of IT workers between firms as reported on their employment histories. This
approach is also similar to that used in prior work (citation blinded).
3.2 Sources of Measurement Error
The most significant limitation associated with using this data source is uneven sampling
across firms and regions and response biases related to which website users choose to
post skills information into the database. Measurement error is a problem common to all
data sets that have been used in prior IT research and the error variance for even the most
widely used IT measures has been estimated to be as high as 30-50% of the variance of
the total IT measure (Brynjolfsson and Hitt 2003). Therefore, it is useful to characterize

14
the error in these data sources to understand the potential direction and magnitude of
biases produced by these errors.
Because the measures used in this paper are principally constructed at the firm
level, errors in the skill-based measures are generated when there are selection concerns
related to a) how many of a firm’s IT workers participate on LinkedIn or b) if
participating employees misreport or omit skills in a way that is correlated with the error
term. In general, the large size of the sample mitigates most concerns related to
participation. LinkedIn includes much of the white-collar workforce, and within IT
occupations, the size of the US-based LinkedIn sample is over 80% of the size of the total
IT workforce reported by the Bureau of Labor Statistics. Correlations with external data
sources indicate that the LinkedIn IT employment data are a good measure of the size of
the firm’s IT labor force. In logs, the correlation between the measures generated using
LinkedIn data and the IT employment measures developed using similar methods in
recent work is 0.61 (Tambe and Hitt 2012a). Firm-level correlations with the IT
employment figures from the survey data used in Brynjolfsson, Hitt, and Kim is 0.70.
Finally, the correlation with total employment in the packaged software industry (SIC
7372), where most employees are likely to be IT employees, is 0.81.
More significant concerns relate to which workers choose to report skills, and
which skills they choose to report, and whether this reporting rate systematically varies
across labor markets.7 Spearman rank correlations reject the hypothesis that there are
systematic differences between the distribution of IT employees across regions and the
distribution of IT employees who report skills across regions (ρ=0.998). The same is true 7 There has been recent concern about the possibility of fake profiles on social networks (Thier 2012). However, fake profiles will not bias the coefficient estimates unless big data skills are over or under represented in fake profiles, so are relatively unlikely to directly impact the estimates.

15
of Spearman rank correlations between the distribution of IT employees across firms and
the distribution of IT employees who report skills across firms (ρ=0.983).
The most problematic biases occur when errors in the firm-level skills based
measures are correlated with productivity—for example, if employees in productive firms
are more likely to report skills complementary to big data than employees at other firms,
and indeed, it is plausible that employees at more productive firms are more likely to be
engaged with LinkedIn, and therefore more likely to report skills information on
LinkedIn. Although this is somewhat difficult to directly address due to the novelty of the
data source and the lack of data available about skills through any other channel, there are
a number of statistical robustness tests that can bound the potential effects of these types
of measurement error on the main estimates. These tests are described in the main
analysis.
3.3 Supplementary data sources
The Compustat database was used to create measures of capital, total employment, and
value added (output less materials), and to construct dummy variables for industry and
year. Industry dummy variables were constructed at the four-digit SIC level, which is a
more precise level of industry controls than most prior IT research, enabled by the large
sample size.8 Value added was chosen as a dependent variable to maintain consistency
with prior research on the productivity of IT investments and has the benefit that it is
somewhat less subject than measures of total output to biases from unobserved variables
that affect demand as well as technology employment. Measures of capital and value-
added were adjusted using methods from the micro-productivity literature and deflated to
8 Most existing IT productivity studies at the firm level of analysis use 1 or 2 digit industry controls due to sample size limitations.

16
a common base year using industry-level deflators posted at the Bureau of Economic
Analysis. Industry sales share measures were created by computing the share of total
industry output at the four-digit SIC level accounted for by each firm in each year.
4.0 Empirical Framework
Like much of the existing research on IT productivity, this paper estimates the
contribution of various production inputs to a measure of output, using micro-data on the
production activities of a large panel of firms. The most common functional form used to
estimate these relationships has historically been the Cobb-Douglas specification, which
is among the simplest functional forms, and forms the basis for productivity measurement
of the US economy as a whole. Like prior studies in the IT productivity literature, this
analysis assumes that firms produce output via a Cobb-Douglas production function with
capital (K), labor (L), and IT inputs (IT). This model can be extended to include measures
of individual technologies on the right-hand side, similar to the models used to estimate
the returns to data practices in Brynjolfsson, Hitt, and Kim (2011) or returns to ERP
adoption in Hitt, Wu, and Zhou (2002). An estimable model of a production function that
separates the contribution of big data investments from a firm’s aggregate IT investments
can be written:
(1) ln!" = ∝! ln! +∝! ln ! +∝!" ln !" +∝!" ln!" + !
where K is capital, L is non-IT labor, IT is IT labor, BD is big data labor, and where the
indices for firm and year in (1) are dropped for notational convenience. The use of labor
based measures for IT investment has been common in the literature (e.g. see Lichtenberg
1995).

17
This model can be estimated using standard regression techniques such as
ordinary least squares (with suitable standard error corrections for panel data) or panel
methods such as fixed effects or differences. The coefficient estimate on the big data
input (αBD) is the output elasticity of a firm’s investments in big data, which is the
percentage increase in output generated by a one percent increase in the big data input.
To extend this model to incorporate labor market spillovers produced by the
investments of other firms, this production function can be augmented with measures of
the IT activities of labor market neighbors. The principal contribution of this paper is the
analysis of data on firm’s investments in big data innovations at the firm and regional
levels, as well as labor flow data enabling direct measurement of the big data and
aggregate IT investments of the firm’s labor pool. Together these data can be used to
create measures of the skill content of IT labor that being acquired by firms. A measure
of the pool of external labor market investment in big data can be created as follows:
(2) !!"! = !!!"!!
(3) !!"! = !!!"!!
where wj is the share of incoming IT labor that firm i has acquired from firm j in each
year and BD and IT are the big data employment and IT employment of firm j,
respectively, in that year. An alternative measure used in some regressions substitutes wjr,
the share of IT labor hired from firm j in a particular metropolitan area r, for wj and
substitutes BDjr, the big data employment levels for firm j in that metropolitan area, for
BDj.
This method of creating a measure of the “pool” of external investment is similar
to that used in an extensive literature on R&D spillovers as well as in an emerging

18
literature on IT spillovers (Chang and Gurbaxani 2012; Tambe and Hitt 2012b). The
spillover-augmented form of the productivity regression in (1) can be written:
(4) ln!" = ∝! ln! +∝! ln ! +∝!" ln !" +∝!" ln !" +∝!!!" ln !!" +∝!!!" ln !!" + !
All of these measures of investment by labor market neighbors can be included in (1) in
main effects as well as in interactions with firms’ own investments to test for
complementarities. Biases related to endogeneity and measurement error are discussed
further below.
5.0 Descriptive Statistics
5.1 Industrial and Geographic Distributions of Emerging Big Data Skills
The industries employing the largest numbers of workers with big data skills are reported
in Table 1. Most big data workers are employed in IT industries, but over 30% are
employed in other IT-using industries, such as finance, transportation, utilities, and retail.
Figure 1 indicates that the geographic distribution of big data workers is skewed. The
measures of the big data workforce in Figure 1 are normalized by the size of the IT labor
force in each metropolitan region, so they represent the intensity of big data skills within
the local IT workforce. Even after controlling for size of the total IT labor force, the
intensity of Hadoop skills is much greater in the San Francisco Bay area than in any other
region. For comparison, Table 2 shows the rate of decline in the concentration of
Hadoop across metropolitan regions along-side the decline in concentration of other
major technical skills, where the fraction in each cell is the intensity of the skill in that
metro region relative to the intensity in the metro region with the highest concentration of
that skill. Hadoop is very highly geographically concentrated, with the skill intensity in
the San Francisco Bay area being more than double that of any other city, and four to five

19
times that of cities towards the bottom of the list. By comparison, the decline in
concentration of SQL and Java, the two most popular IT skills in the database, is slower,
with relatively little variation across labor markets, indicating that the supply of these
skills is much more even across labor markets.
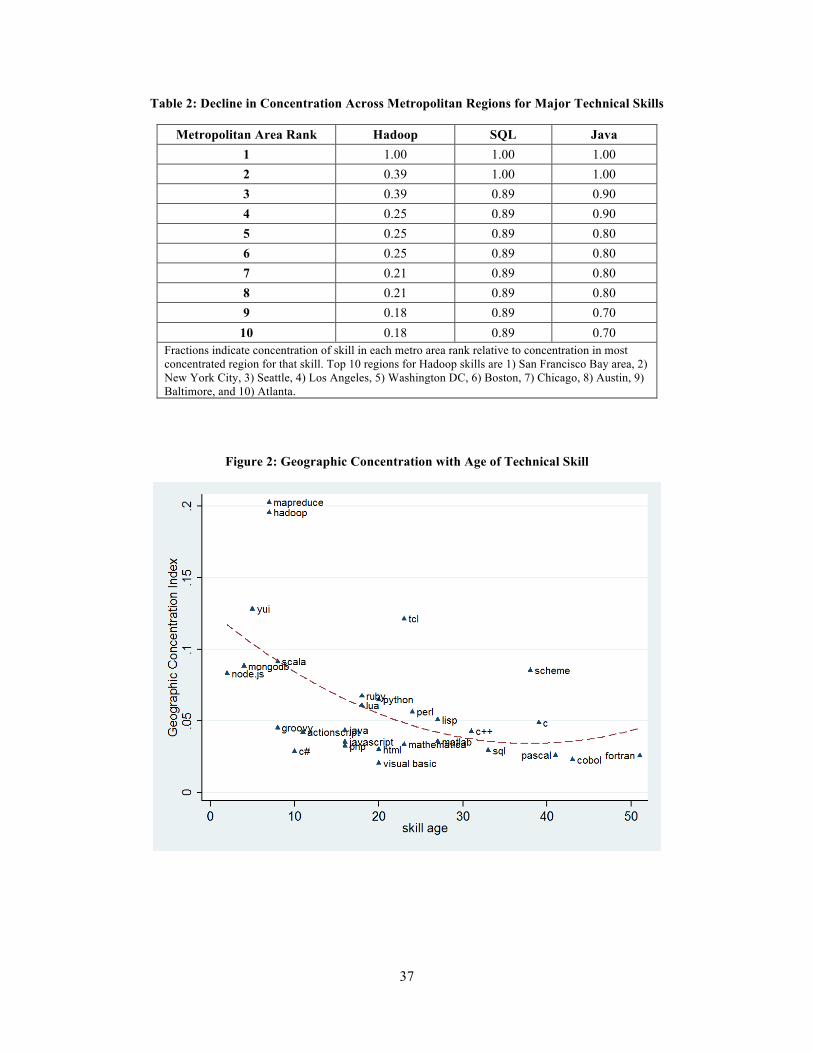
Figure 2 plots the age of common technical skills against this geographic
concentration measure, where the age of technical skills was collected using Internet data
sources.9 The most highly concentrated skills are associated with the recent big data
innovation boom, such as Hadoop and Map/Reduce, and the least concentrated are older
technical skills such as Cobol and Fortran. Figure 3 plots the geographic concentration of
all major technical skills in the database,10 where the concentration of each skill is
computed by summing the squared fraction of the skill in each metro area across all
metro areas, such that a value of one would correspond to all employees with a particular
technical skill being located in a single metropolitan region. The plot demonstrates
significant variation in geographic concentration across technical skills, and suggests that
among all major technical skills, skills associated with the rising importance of big data
technologies are amongst the most geographically concentrated. Although the trends
illustrated in Figures 1 through 3 are not conclusive, they are consistent with the
hypothesis that in the short-run, skills complementary to new IT innovations tend to be
highly geographically concentrated.
The regression analyses use the employment of IT workers with Hadoop skills as
a marker of firm-level differences in big-data related human capital. Figure 4 illustrates
differences in the skill distribution of the IT labor force in firms that employ workers
9 For example, see http://en.wikipedia.org/wiki/History_of_programming_languages 10Major technical skills are defined as those with at least 1,000 people in the database reporting having that skill.

20
with Hadoop skills. The vertical axis is the fraction of each skill located in firms that are
employing workers with Hadoop skills (i.e. “big data” firms). The distributional
comparison indicates that the skill content of the IT labor force in these firms is
significantly different from that in other US firms, more heavily weighted towards
emerging skills such as “apache pig” and “map/reduce”.11 A Kolmogorov-Smirnov test
rejects the hypothesis that the distributions are the same across the two groups of firms
(D=0.964). Figure 5 shows a similar comparison between the skill distribution of the San
Francisco Bay area, the region with the largest concentration of Hadoop employment, and
the rest of the US IT labor force. This comparison also indicates greater concentration of
skills required for intensive large-scale data analytics, such as “apache pig”, “hadoop”,
“distributed algorithms”, “recommender systems”, and “hbase”. A Kolmogorov-Smirnov
test rejects the hypothesis that the distribution in the San Francisco-based IT labor force
is the same as the IT labor market in the rest of the US (D=0.676).
Finally, while Figure 1 illustrates cross-market differences in the intensity of big
data skills within the IT labor force, Figure 6 illustrates the distribution of the labor-
weighted share of external investment in big data for firms in a region, one of the key
measures used in the regression analyses. The figure indicates that these external
investment measures available to firms in San Francisco and Seattle are substantially
larger than in any other US cities.
5.2 Statistics for Key Measures Used in the Regression Analyses
Table 3 summarizes the key measures used in the regression analysis, and Table 4 reports
means and standard deviations for these measures, and tests for statistically significant
11Because big-data firms are identified using the employment of workers with Hadoop skills, Hadoop is excluded from this list of skills.

21
differences in means between firms employing big data engineers and all other firms in
the sample. In general, big data firms have significantly higher employment levels than
other firms (t=10.21), and are more IT-intensive than other firms (t=23.52), at least in
part due to the fraction of big data firms in IT industries. Measures of the pool of total IT
employment by labor market neighbors as well as the pool of big data employment are
greater for big data using firms. Table 5 reports simple correlations among 2011 values
for the key measures. The most notable of these is between the external pool of aggregate
IT employment and the external pool of big data employment. The high correlation
between the two measures suggests the importance of the large sample for producing
estimates relying on independent variation between these two values and the dependent
variable.
6.0 Regression Analyses
6.1 Main Results
Table 6 reports baseline productivity results. The pooled OLS results in (1) imply an
elasticity of IT labor comparable to that produced by prior studies using similar
specifications (t=15.5) (e.g. see Lichtenberg 1995). The higher coefficient produced when
using IT employment instead of IT capital stock is mostly attributable to the use of
employment rather than labor expense as the labor measure. In the absence of direct
measures of labor expenses, higher wages paid to educated workers in IT-intensive
firms12 are reflected in the IT input, rather than the labor input. The coefficient estimate
on IT labor falls considerably in (2) after applying a fixed-effect estimator (t=5.88). In
general, these regressions demonstrate that the measures of aggregate IT employment
12 Bresnahan, Brynjolfsson, and Hitt (2002) provide evidence that IT use is associated with greater demand for educated workers.

22
used in the analysis behave similarly in productivity regressions to other studies that use
IT labor as a measure of a firm’s IT investments (Tambe and Hitt 2012).
Column (3) introduces big data employment measures into the baseline
regression. The coefficient estimate on big data employment can be interpreted as the
excess return to IT employment produced by employing IT workers with big data skills.
The estimates suggest a significant association between the employment of big data
workers and productivity (t=4.5), and columns (4) and (5) suggest that the magnitude of
this estimate is similar for both IT (t=3.38) and non-IT industries (t=2.54). However, the
output elasticity on the big data measure falls significantly, from.09 to.02 (t=2.0), after
applying a fixed effects estimator in (6), indicating that much of the estimate in (3) can be
attributed to unobserved heterogeneity correlated with big data usage. The first-
differences estimate in (7) is similar in magnitude to the fixed-effects estimate and
implies an output elasticity of about 2% for changes in big data employment (t=2.13).
The results in (8) are from a cross-sectional regression using 2011 measures that also
include measures of SQL employment, which tests the alternative hypothesis that the
estimated returns are from returns to data assets in general, rather than big data
technologies specifically. However, including a measure of SQL skills has little effect on
the coefficient estimate on the measure of big data employment, and the coefficient
estimate on SQL is insignificant. Overall, the estimates suggest that the output elasticity
of big data employment is 40%-100% higher than the output elasticity of other types of
IT employment.
The estimates in Table 7 introduce measures of the big data employment of labor
market neighbors to the baseline productivity regression. All measures of external

23
investment patterns are zero-centered, so the main effect on own investments in big data
should be interpreted as the performance impact of big data in firms embedded in a labor
market with average levels of big data employment. Column (1) includes a measure of
the aggregate IT employment levels of other firms weighted by incoming IT labor share.
The estimate on this measure is positive and significant (t=2.4) and indicates that an
overall level of IT employment in the labor market one standard deviation higher than the
mean is associated with an output elasticity of about 2%. This result is consistent with
prior work that attempts to estimate the impact of IT spillovers on productivity.
Column (3) includes a measure of big data employment levels within the labor
market. Interestingly, after including the new measure, the estimate on the IT investment
of other firms in the labor market is no longer significantly different than zero, indicating
that labor market spillovers from IT investment are produced by investment in recent
waves of IT innovation. The output elasticity on the big data pool is similar to the
estimate on the pool of IT investment in (1) (t=3.25). Column (4) reports estimates from a
cross-sectional regression using only 2011 values, for which measurement error in the
skills data is likely to be smallest. Restricting the sample to 2011 values doubles the
estimated output elasticity of big data investments by labor market neighbors (t=1.81).
The application of fixed-effects and differences estimators in (5) and (6) produces
estimates consistent with the OLS regressions, suggesting that changes in the levels of
big data employment in the labor market, rather than changes in IT employment levels,
are associated with higher productivity levels for firms. The estimates restricted to the
2011 cross-section have a larger coefficient on the big data pool (t=1.81), as well as on
own big data investment. In general, the estimates in Table 7 imply that IT-related

24
productivity spillovers are primarily generated by investments in new IT innovations. For
a big data pool that is one standard deviation larger than the mean, the OLS estimates
suggest an output elasticity of about 7% and the panel estimates suggest an output
elasticity of about 4%. Column (7) of Table 7 provides tests for complementarities
between the firms’ own use of big data and the external big data pool. There is a
significant and positive association with productivity for big data firms with larger
investment levels in big data in the same labor market. A big data pool one standard
deviation higher than the mean is associated with an output elasticity of about 8%.
6.2 Using Sales Share as a Dependent Variable
Table 8 uses changes in four-digit SIC sales share from 2005 to 2011 as a
dependent variable rather than value added. The use of this dependent variable has two
advantages. First, changes in sales share are less subject to the productivity measurement
difficulties associated with the 2008 financial crash. Second, changes in sales share
indicate changes in industry concentration, which have been attracting renewed attention
in the IT economics literature (Brynjolfsson et al 2009).
Column (1) provides evidence of correlations between IT intensity and growth in
sales share (t=1.62), consistent with recent work in this area (Brynjolfsson et al 2009).
Column (2) includes measures of big data investment and demonstrates that associations
between IT use and changes in sales share are due primarily to investments in new IT
innovations (t=1.67), rather than overall IT intensity—firms with growing industry sales
share are those investing in early stage IT innovations. After including direct measures of
big data investment, the estimate on IT labor is no longer significantly different than zero.
Columns (3) through (5) provide evidence that these short-run performance advantages

25
are most closely associated with the interaction term between own big data investment
and big data investment in the labor pool.
Figure 8 provides a visual representation of these effects on sales share–it plots
measures of the firms’ big data pool against changes in sales share from 2005 to 2011,
where firms are divided into adopters and non-adopters of big data. The scatter plot
indicates that for firms making investments in big data technologies, changes in sales
share are increasing in the external pool of big data investment, suggesting a greater
performance impact from firms’ investments in these technologies when embedded in
labor markets in which other employers are concurrently making investments in big data
technologies. On the other hand, there is no clear trend for firms not making their own
investments in big data.
Figure 9 shows a similar plot, where SQL investment is substituted for big data
investment as the variable on the horizontal axis. Unlike with investment in big data
technologies, there is no apparent benefit for being in SQL-intensive labor markets when
making investments in SQL based database technologies. Overall, these analyses
indicate that changes in industry concentration documented in prior work are associated
with investments in new IT innovations, and that the labor pool is a complementary
factor of production for investments in new IT innovations. This complementarity
implies that firms that are in a position to use new IT innovations to achieve higher
performance relative to industry competitors will tend to cluster in the same labor
markets, producing greater overall performance levels in these regions.
6.3 Regional Measures

26
Estimates using regional measures are reported in Table 9. Column (1) uses measures of
investment in the labor market constructed using the investments of other firms in the
regional pool. This measure is more precise than the measure used above because human
capital formation is likely to be more highly correlated with establishment level
investments, rather than firm level investments—for example, a firm’s big data
investments in Atlanta are a more precise measure of the technical human capital of IT
workers located at the Atlanta offices than the firm’s overall investment levels. After
reconstructing the measures using data on regional labor flows and skills employment
(t=2.44), the effect of the original measure of the big data pool is no longer significant,
which supports the interpretation that the productivity results are driven by spillovers of
technical know-how rather than unobservable firm-level characteristics in the labor
network.
Because these data are available at the metropolitan area, measures can also be
constructed that isolate the contributions of specific metropolitan regions. The regression
in (2) separates spillover measures into the regional pools in San Francisco and Seattle
and those in all other US metropolitan areas. The results indicate that statistical
associations between the pool measures and productivity are restricted to San Francisco
or Seattle (t=4.5). There are no significant correlations with productivity for external
pools of big data investments in the combined measure of all other US regions, and these
findings are robust to restricting the sample to IT firms only or to non IT firms only.
Column (5) reports results using the regional measure of the big data investment pool in
(1) but with the sample limited to firms that do not hire any IT workers in Seattle or San
Francisco, and the results from this regression also indicate no statistical associations

27
between the spillover pool measure and productivity. Finally, the regression results from
(6) are from a specification that includes measures of the big data pool at the firm level,
the regional level, and the regional level separated into San Francisco and Seattle and all
other regions. After including all of these measures into the same regression, the only
significant estimate is on the pool measure in San Francisco and Seattle (t=2.8). Finally,
the results in (7) indicate that the regional measures also produce more precise results
than the aggregate measure in a complementarities-based specification (t=2.09).
6.4 Endogeneity Tests
The primary concern with interpreting the estimates presented above relates to
omitted variables that exert an upward bias on both the measure of own big data
investment or the big data pool. Some of these concerns are mitigated by the consistency
of the estimates across fixed-effects and differences estimators, which remove the effects
of time-invariant omitted variables.
The nature of the statistical evidence on complementarities also supports the key
hypotheses. It is noteworthy that the evidence indicates that firms’ big data investments,
in the absence of investment by other firms in the same labor market, are not associated
with higher productivity levels. Unobservables associated with big data adoption can be
expected to produce an upward bias on the main effect big data term, regardless of the
characteristics of the firm’s local labor market. This complementarities also act in the
reverse direction—if the results are driven by unobservables correlated with the firm’s
ability to attract workers from firms investing in big data, this omitted variable should
exert an upward bias on the main effect for the labor market measure. Instead, any
sources of endogeneity must act at the confluence of these two factors.

28
A statistical test for this argument is shown in Tables 10 and 11 which implement
complementarities tests proposed by Brynjolfsson and Milgrom (2009) that contrast the
productivity of firms with varying combinations of investment in big data and external
pools of big data investment. Each of the variables is dichotomized, where a 1 represents
a high level of investment, and a 0 represents a low level of investment, split at the
median level of each of these groups. The highest productivity group is that in which
firms have high-levels of both factors (1, 1), where values are productivity levels relative
to the (0, 0) group. F-tests indicate that the productivity differences between the (1, 1)
group and groups with any other combination of factors are significant at the 5% level.
This pattern of results is what would be predicted by the complementarities story. Table
11 presents the results of similar tests using SQL rather than big data as the focal
technology. Evidence for complementarities disappears, which is consistent with the
argument that there are no labor market spillovers produced by investments in older
information technologies.
The regional results are, in general, also supportive of a causal explanation.
Specifically, hiring IT labor from other firms making big data investments is not
sufficient. Firms must hire these technical workers from the locations in which firms are
making these big data investments. Therefore, the estimates on the complementarities
tests as well as the regional results are more consistent with the story that the production
estimates reported in this study reflect human capital spillovers, rather than omitted
variables.
An additional source of endogeneity is measurement error in the key independent
variable. Table 12 presents results from regressions testing the sensitivity of the results to

29
error in the big data employment measures. Big data employment is likely to be measured
with error if a) employees report having big data skills but are not using them at the firm
or inaccurately report having acquired skills or b) no employees at big data using firms
report having these skills. To test the sensitivity of the key estimates to these sources of
measurement error, alternative measures of big data employment with different error
characteristics are substituted into the baseline regressions.
Column (1) uses a binary adoption variable that takes a value of one when at least
one of a firm’s employees lists Hadoop as a technical skill. Columns (2) and (3) use
similar measures of big data, based on having at least two employees reporting Hadoop
skills in (2) and on having at least five workers reporting Hadoop skills in (3). Using
these measures suggests that the most robust correlations arise with the binary variable
based on having at least two employees with big data skills (t=3.39). The estimates in (4)
and (5) are produced by using this binary measure with the two employee threshold in
fixed-effects and differences. The fixed-effects estimator indicates an output elasticity of
about 4% (t=2.05), and this estimate very is similar in magnitude to the first-differences
estimate (t=2.87). These estimates are about twice as large as the fixed-effects and first-
differences estimates reported in columns (5) and (6) of the main results in Table 5,
which is not surprising given that the interpretation of the coefficient estimate on the
binary variable is the mean productivity difference between big data using firms and all
other firms in the sample.
Column (6) uses a measure of big data employment normalized by the total
number of employees in the firm who report SQL skills. This normalization provides
several measurement advantages. It removes firm-specific sources of error that are

30
common across workers who report SQL and big data skills. The coefficient estimate
produced by the use of this normalized measure is consistent with results from other
measures (t=2.93). Finally, column (7) presents regression results when limiting the
sample only to firms that use big data. The variation in this regression comes from
differences in quantities of big data workers for firms who have at least one employee
who lists big data skills. Estimates from this regression indicate that correlations between
the big data measure and productivity measures observed in earlier regressions come not
only from productivity differences between big data using firms and other firms, but also
from productivity differences that are systematically associated with big data investment
within big data using firms (t=3.98).
7.0 Summary and Conclusions
The principal contribution of this paper is the collection of data enabling the
measurement of emerging technical know-how within the IT workforce and analysis of
the complementarities arising between the skill content of the labor pool and firms’ own
investments in new IT innovations.
For managers, this analysis also provides the first statistical evidence of the
business impact of big data technologies. The estimates indicate that these technologies
are currently associated with performance returns that measurably exceed the returns
from traditional database management systems alone. Firms in both IT industries and
non-IT industries appear to be capturing these returns. However, the analysis
demonstrates the importance of the emerging big data workforce as a strategic
complement to a firm’s own initiatives.

31
These findings have implications for innovation and labor policy. Although prior
work provides evidence for IT labor market spillovers, the findings produced in this
analysis indicate that these spillovers are primarily important for investments in new IT
innovations, rather than aggregate IT investments. Therefore, policy efforts aimed at
encouraging IT spillovers should be focused on firms’ investments in new IT
innovations. These findings also have implications for a potential big data divide. This
paper suggests that growing divisions in wealth across labor markets are created by an
“invisible” factor of production that separates regions during technology booms. During
the current wave of big data innovation, we should expect IT-intensive cities to continue
to experience faster productivity growth than other regions until the skills complementary
to big data innovation become more widely available.
This analysis suggests several areas interesting for future research such as those
related to the strategic decisions that firms make to acquire IT labor. It would be of
significant interest to examine how firms balance the benefits of acquiring these skilled
workers against the difficulties of retaining these workers, as well as how investments in
culture and process impact the acquisition and retention of these workers at different
stages of the technology cycle. It will also be important to achieve a better understanding
of how the productivity gains documented in this paper are divided between firms and
their workers.
References Agarwal, R., T. Ferratt. 2001. Crafting an HR Strategy to Meet the Need for IT Workers.
Communications of the ACM. (44:7), pp. 58-64. Agarwal, R., D. Audretsch, M. Sarkar. 2007. The process of creative construction: knowledge
spillovers, entrepreneurship, and economic growth. Strategic Entrepreneurship Journal (1:3-4), pp. 263-286.

32
Alcacer, J., W. Chung. 2007. Location Strategies and Knowledge Spillovers. Management Science (53:5), pp. 760-776.
Ang, S., S. Slaughter, and K. Ng. 2002. Human Capital and Institutional Determinants of
Information Technology Compensation: Modeling Multilevel and Cross-Level Interactions. Management Science, 48(11), 1427-1445.
Audretsch, D. and M. Feldman. R&D Spillovers and the Geography of Innovation and
Production. American Economic Review. 86(3), 1996, pp. 630-640. Bertolucci, J. 2012. Data Scientists: Meet Big Data’s Top Guns. InformationWeek. Bertolucci, J. 2012. Big Data’s Wild West Period Stars Hadoop. InformationWeek. (Accessed
online at http://www.informationweek.com/big-data/news/big-data-analytics/240006652/big-datas-wild-west-period-stars-hadoop)
Bapna, R., N. Langer, A. Mehra, and A. Gupta. Human Capital Investments and Employee
Performance: An Analysis of IT Services Industry. Management Science, forthcoming. Barua, A., D. Mani, and R. Mukherjee. Measuring the Business Impacts of Effective Data. Report
accessed at http://www.sybase.com/files/White_Papers on Sep 15, 2012. Bloom, N., Sadun, R., and J. Van Reenen. “Americans Do I.T. Better: US Multinationals and the
Productivity Miracle”, American Economic Review, 2012. Borjas, G., R. Freeman, and L. Katz. Searching for the Effect of Immigration on the Labor Market.
American Economic Review, 1996, pp. 246-251. Breschi, S. and Lissoni, F. “Knowledge spillovers and local innovation systems: a critical survey”,
Industrial and Corporate Change (10:4), 2001, pp. 975-1005. Bresnahan, T., A. Gambardella, and A. Saxenian. ‘Old Economy’ Inputs for ‘New Economy’
Outcomes: Cluster Formation in the New Silicon Valleys. Bresnahan, T. and S. Greenstein. 1996. Technical Progress and Co-invention in Computing and in
the Uses of Computers. Brookings Papers: Microeconomics. Brynjolfsson, E. and L. Hitt. 1996. Paradox Lost? Firm-Level Evidence on the Returns to
Information Systems Spending. Management Science. 42:4, 541-558. Brynjolfsson, E., L. Hitt, and H. Kim. 2011. Strength in Numbers: How Does Data-Driven
Decision Making Affect Firm Performance? Working Paper. Brynjolfsson, E. and A. Mcafee. 2011. The Big Data Boom is the Innovation Story of Our Time.
The Atlantic. Nov 21, 2011. Accessed at http://www.theatlantic.com/business/archive/2011/11/the-big-data-boom-is-the-innovation-story-of-our-time/248215/ on Sept 15, 2012.
Brynjolfsson, E., A. Mcafee, M. Sorrell, and F. Zhu. 2009. Scale Without Mass: Business Process
Replicaton and Industry Dynamics. Working Paper.

33
Brynjolfsson, E. and P. Milgrom. 2009. Complementarities in Organizations. Working Paper. Campbell, B., M. Ganco, A. Franco, R. Agarwal. Who leaves, where to, and why worry?
employee mobility, entrepreneurship and effects on source firm performance. Strategic Management Journal, (33:1), 65-87.
Card, D. 1990. The Impact of the Mariel Boatlift on the Miami Labor Market. Industrial and
Labor Relations Review 43(2), 245-257. Chang, Y. and V. Gurbaxani. The Impact of IT-Related Spillovers on Long-Run Productivity: An
Empirical Analysis. Information Systems Research, forthcoming. Cheng, Z. and B. Nault. 2007. Industry Level Supplier-Driven IT Spillovers. Management
Science 53(8), 1199-1216. Cheng, Z. and B. Nault. Relative Industry Concentration and Customer-Driven IT Spillovers.
Information Systems Research, forthcoming. Desmet, K. and Rossi-Hansberg, E. 2009. “Spatial Growth and Industry Age”, Journal of
Economic Theory. 144, 2477-2502. Dedrick, J., V. Gurbaxani, and K. Kraemer. Information Technology and Economic Performance:
A Critical Review of the Empirical Evidence. ACM Computing Surveys, 35(1), pp. 1-28. Dewan, S. and K. Kraemer. “Information Technology and Productivity: Evidence from Country-
Level Data”, Management Science (46:4), 2000, pp. 548-562. Dewan, S., D. Ganley, and K. Kraemer. “Complementarities in the Diffusion of Personal
Computers and the Internet: Implications for the Global Digital Divide”, Information Systems Research, forthcoming.
Dewan, S. and C. Min. “The Substitution of Information Technology for Other Factors of
Production: A Firm-Level Analysis”, Management Science (43:12), 1997, pp. 1660-1675. Draca, M., R. Sadun, and J. Van Reenen. 2006. Productivity and ICT: A Review of the Evidence.
CEP Discussion Paper No. 749. Dumbill, E. 2012. What is Apache Hadoop? (Accessed online at
http://strata.oreilly.com/2012/02/what-is-apache-hadoop.html on September 10th, 2012) Elias, H. 2011. Do Americans have 21st century job skills? Forbes. 12/12/2011.
http://www.forbes.com/sites/ciocentral/2011/12/12/do-americans-have-21st-century-job-skills/. Accessed on April 7th, 2012.
Fallick, B., Fleischman, C., Rebitzer, J. “Job-Hopping in Silicon Valley: Some Evidence
Concerning the Microfoundations of a High-Technology Cluster”, The Review of Economics and Statistics (88:3), 2006, pp. 472-481.

34
Forman, C. 2005. The Corporate Digital Divide: Determinants of Internet Adoption. Management Science. 51:4, 641-654.
Forman, C., Golfarb, A., and Greenstein, S. “The Internet and Local Wages: Convergence or
Divergence?” American Economic Review, 2012. Franco, A. and Filson. D. Spin-outs: knowledge diffusion through employee mobility. Rand
Journal of Economics (37:4), 2006, pp. 841-860. Freedman, M. “Job hopping, earnings dynamics, and industrial agglomeration in the software
publishing industry”, Journal of Urban Economics, (64:3), 2008, 590-600. Freeland, C. In Big Data, Potential for Big Division. New York Times. January 12, 2012.
Accessed at http://www.nytimes.com/2012/01/13/us/13iht-letter13.html on September 14, 2012.
Greenwood, B. and A. Gopal. 2010. Ending the Mending Wall: Exploring Entrepreneur-Venture
Capitalist Co-Location in New IT Ventures. Proceedings of the International Conference on Information Systems.
Griliches, Z. “The Search for R&D Spillovers”, Scandanavian Journal of Economics (94), 1992,
pp. 29-47. Jaffe, A. “Technological Opportunity and Spillovers of R&D: Evidence from Firms' Patents,
Profits, and Market Value”, American Economic Review (76:5), 1986, pp. 984-1001. Jaffe, A., Trajtenberg, M., Henderson, R. “Geographic Localization of Knowledge Spillovers as
Evidenced by Patent Citations”, Quarterly Journal of Economics, (108:3), 1993, 577-598.
Levina, N. and M. Xin. “Comparing IT Workers’ Compensation Across Country Contexts:
Demographic and Institutional Factors”, Information Systems Research (18:2), 2007, pp. 193-210.
Lichtenberg, F. “The Output Contributions of Computer Equipment and Personnel. A firm-level
analysis”, Economics of Innovation and New Technology (3:3-4), 1995, pp. 201-218. McElheran, K. Do Market Leaders Lead in Business Process Innovation? The Case(s) of E-
Business Adoption. HBS TOM Unit Working Paper 10-104. 2011 Mckinsey Global Institute. 2011. Big Data: The Next Frontier for innovation, competition, and
productivity. Melville, N., K. Kraemer, and V. Gurbaxani. 2004. Review: Information Technology and
Organizational Performance: An Integrative Model of IT Business Value. MIS Quarterly. 28(2): 283-322.
Mendelson, H. 2000. Organizational Architecture and Success in the Information Technology
Industry. Management Science. 46(4): 513-529.

35
Greenstein, S. and F. Nagle, Digital Dark Matter and the Economics of Apache. Working Paper. 2012.
Provost, F. and V. Kolluri. 1999. A Survey of Methods for Scaling Up Inductive Algorithms.
Data Mining and Knowledge Discovery, (3:2), 131-169. Rooney, B. 2012. “Big Data’s Big Problem: Little Talent.” Wall Street Journal. April 29, 2012. Saxenian, A. 1996. Regional Advantage: Culture and Competition in Silicon Valley and Route
128, Harvard University Press, Cambridge, USA. Swan, A. and S. Brown. 2008. The Skills, Role, and Career Structure of Data Scientists and
Curators: An Assessment of Current Practice and Future Needs. Available at http://www.jisc.ac.uk/media/documents/programmes/digitalrepositories/dataskillscareersfinalreport.pdf. Accessed on August 28, 2012.
Tambe, P. and L. Hitt. 2012a. The Productivity of New Information Technology Investments:
New Evidence from IT Labor Data. Information Systems Research, forthcoming. Tambe, P. and L. Hitt. 2012b. Job Hopping, Information Technology Spillovers, and Productivity
Growth. Working Paper. Thier, D. 2012. An Estimated 83 Million Facebook Profiles are Fake. Acccessed at
http://www.forbes.com/sites/davidthier/2012/08/02/83-million-estimated-facebook-profiles-are-fake/ on December 3, 2012.

36
Table 1: 6-Digit NAICS Industries by Employment of Workers with Big Data Skills*
6-Digit NAICS Industry % of Big Data Workers Software Publishers 20.4 Internet Publishing and Broadcasting 13.0 Computer Systems Design 5.2 Radio and Television Broadcasting 5.0 Internet Shopping 4.4 Computer Peripheral Manufacturing 4.3 Computer Services 3.9 Commercial Banking 3.1 Computer Storage Manufacturing 2.5 Wired Telecommunication 2.2 Computer Programming Services 2.1 Computer Manufacturing 2.0 General Merchandising 1.8 All Industries 100 *Only includes 6-digit NAICS industries with at least ten firms. Based on big data employment in public firms only.
Figure 1: Top Metro Regions by Intensity of Big Data Skills Within the IT Labor Force
37
Table 2: Decline in Concentration Across Metropolitan Regions for Major Technical Skills
Metropolitan Area Rank Hadoop SQL Java 1 1.00 1.00 1.00 2 0.39 1.00 1.00 3 0.39 0.89 0.90 4 0.25 0.89 0.90 5 0.25 0.89 0.80 6 0.25 0.89 0.80 7 0.21 0.89 0.80 8 0.21 0.89 0.80 9 0.18 0.89 0.70
10 0.18 0.89 0.70 Fractions indicate concentration of skill in each metro area rank relative to concentration in most concentrated region for that skill. Top 10 regions for Hadoop skills are 1) San Francisco Bay area, 2) New York City, 3) Seattle, 4) Los Angeles, 5) Washington DC, 6) Boston, 7) Chicago, 8) Austin, 9) Baltimore, and 10) Atlanta.
Figure 2: Geographic Concentration with Age of Technical Skill

38
Figure 2: Geographic Concentrations of Major Technical Skills
Figure 3: Technical Skill Distance Between Big Data Firms and Other US Firms

39
Figure 4: Technical Skill Distance Between San Francisco Bay Area and Other US Regions
Figure 5: Labor-Share Weighted Big Data Employment Measure Across Metropolitan Areas

40
Table 3: Summary of Key Measures
Variable Data Source Description Value Added Compustat Sales minus materials deflated to a base year. Capital Compustat Computed from PP&E measures and deflated to a base year. Non-IT Labor Compustat Total employment minus IT employment Industry Compustat 4 digit SIC classification IT Employment LinkedIn IT workers employed by the firm Big Data Employment LinkedIn Employees with big data skills at firm IT Pool LinkedIn External IT employment weighted by incoming IT labor share Big Data Pool LinkedIn External big data employment weighted by incoming IT labor share IT Skills LinkedIn Self-reported technical skills Geographic Location LinkedIn Metropolitan area self-reported by employees
Table 4: Summary Statistics and Mean Comparisons for Regression Variables
(1) (2) (3) (4) (5) Mean Std. Dev. Big Data Other T-test Log(Capital) 5.51 2.39 6.65 5.72 5.61** Log(Employment) 1.38 1.88 2.65 1.36 10.21** Log(IT Employment) 3.96 1.73 5.67 3.26 23.52** Log(IT Pool) 0 1.52 .248 -.719 10.05** Log(Big Data Pool) 0 2.66 2.49 .605 12.16** Log(Value Added/Employee) 4.74 1.01 5.03 4.81 3.11** Log(SQL)+ 1.45 2.60 4.08 1.09 17.34** Log(Java)+ .462 2.99 3.85 -.008 19.92** N 13,380 211 1,484 Economic figures are from 2011 Compustat data. **p<.05. A significant value in column (4) rejects the hypothesis that the means in (2) and (3) are equal. +2011 values only. Means and standard deviations in (1) and (2) are reported for all observations. Mean comparison statistics in (3) through (5) are for 2011 values.
Table 5: Correlations Among Key Regression Variables
1 2 3 4 5 1. Capital 1.00 2. Non-IT Employment 0.76 1.00 3. Big Data Employment 0.16 0.22 1.00 4. IT Employment 0.42 0.59 0.48 1.00 5. IT Pool 0.11 0.20 0.21 0.44 1.00 6. Big Data Pool 0.11 0.22 0.26 0.49 0.84 All variables are in logs. Correlations are shown for 2011 values of variables. N=1,692.

41
Table 6: Productivity Effects of Big Data Employment
(1) (2) (3) (4) (5) (6) (7) (8) DV: Log(VA) OLS FE OLS OLS OLS FE Diffs OLS All All All Non-IT IT All All All
Log(Capital) .287** (.016)
.137** (.008)
.286** (.016)
.238** (.021)
.362** (.021)
.137** (.008)
.115** (.017)
.441** (.014)
Log(Non-IT Labor) .543** (.019)
.590** (.012)
.542** (.019)
.610** (.027)
.441** (.026)
.589** (.012)
.411** (.033)
.448** (.016)
Log(IT Labor) .155** (.010)
.047** (.008)
.148** (.010)
.139** (.013)
.150** (.015)
.047** (.008)
.019* (.010)
.089** (.014)
Log(BD Labor) .090** (.020)
.089** (.035)
.081** (.024)
.020** (.010)
.017** (.008)
.089** (.028)
Log(SQL Labor) .009 (.009)
Controls Year SIC4
Year SIC4
Year SIC4
Year SIC4
Year SIC4
Year SIC4 Year SIC4
N 18,639 18,639 18,639 12,081 6,558 18,639 10,866 4,696 R2 0.89 0.79 0.86 0.88 0.89 0.79 0.13 0.86 **p<.05. Standard errors are robust and clustered on firm. Industry controls are included at the four digit SIC level. All variables are in logs. Regressions in (1) through (7) are from 2006 to 2011. Regression in (8) only uses 2011 values.
Table 7: Productivity Effects of Big Data Employment Within Labor Market
(1) (2) (3) (4) (5) (6) (7) (8) DV: Log(VA) OLS OLS OLS Diff OLS OLS OLS Diffs
Log(Capital) .308** (.016)
.308** (.016)
.384** (.025)
.068 (.023)
.381** (.025)
.309** (.016)
.307** (.016)
.093** (.019)
Log(Non-IT Labor) .478** (.021)
.478** (.021)
.405** (.029)
.463 (.038)
.407** (.029)
.480** (.021)
.481** (.021)
.418** (.034)
Log(IT Labor) .164** (.011)
.162** (.011)
.094** (.025)
.047 (.026)
.112** (.024)
.168** (.011)
.167** (.011)
.056** (.019)
Log(BD Labor) .097** (.019)
.093** (.019)
.110** (.030)
.008 (.017)
.112** (.030)
Log(IT Pool) .014** (.005)
.003 (.007)
-.060 (.058)
-.003 (.005)
-.041 (.053)
.001 (.007) -.001
(.003)
Log(BD Pool) .013** (.004)
.029* (.016)
.005* (.003)
.033** (.016)
.014** (.004) .001
(.003)
Log(SQL Labor) .016 (.044)
BD Firm .089** (.031)
-.071 (.064)
-.036 (.041)
BD Firm*Log(BD Pool) .078** (.029)
.017* (.010)
BD Firm*Log(IT Pool) -.065 (.041)
-.001 (.025)
Controls Year SIC4
Year SIC4
Year SIC4 Year SIC4 SIC4
Year SIC4 Year
SIC4 Year
Observations 12,677 12,677 1,692 6,083 1,692 12,677 12,677 8,968 R2 0.89 0.89 0.90 0.12 0.91 0.89 0.89 0.16 **p<.05. Standard errors are clustered on firm. Industry controls are included at the four-digit SIC level. All variables are in logs. Measures of the IT pool, Big Data pool, and SQL pool are zero centered. Regressions in (1) through (6) are from the years 2006 to 2011. Regression in (7) only uses observations from 2011.

42
Table 8: Change in Sales Share from 2005-2011
(1) (2) (3) (4) (5) DV: Change in Sales Share OLS OLS OLS OLS OLS
Log(IT Labor) .005* (.003)
.002 (.003)
-.001 (.003)
-.001 (.003)
-.001 (.003)
Log(BD Labor) .013* (.008)
.012 (.008)
-.019 (.014)
-.019 (.014)
Log(IT Pool) .002 (.003)
.005 (.005)
.005 (.005)
Log(BD Pool) .003** (.001)
.009** (.003)
.009 (.003)
Log(IT)*Log(IT Pool) -.001 (.001)
Log(BD)*Log(BD Pool) .009** (.005)
Controls Size Year
Size Year
Size Year
Size Year
Size Year
N 1,797 1,797 1,797 1,797 1,797 R2 0.20 0.21 0.21 0.21 0.21 *p>.10; **p<.05. Dependent variable is sales share, computed as the firm’s output divided by total output in the four-digit SIC industry. Standard errors are clustered on firm. All variables are in logs. Measures of all pool variables are zero centered.
Figure 6: Changes in Sales Share Plotted Against Labor-Weighted Pool of Big Data
Employment

43
Figure 7: Changes in Sales Share Plotted Against Labor-Weighted Pool of SQL Employment

44
Table 9: Regional Comparisons of Productivity Effects from Big Data Labor Market Spillovers
(1) (2) (3) (4) (5) (6) (7) DV: Log(VA) OLS OLS OLS OLS OLS OLS OLS All All IT Non-IT All All All
Log(Capital) .380** (.025)
.377** (.024)
.391** (.026)
.358** (.041)
.364** (.034)
.378** (.025)
.380** (.021)
Log(Non-IT Labor) .412** (.030)
.419** (.029)
.337** (.034)
.495** (.045)
.444** (.039)
.408** (.030)
.372** (.025)
Log(IT) .133** (.020)
.126** (.020)
.145** (.029)
.088** (.027)
.109** (.025)
.129** (.020)
.168** (.018)
Log(Big Data) .102** (.030)
.087** (.030)
.111** (.038)
.041 (.049)
.104 (.078)
.082** (.031)
Log(IT Pool) -.027 (.028)
.004 (.005)
.000 (.023)
-.006 (.022)
.006 (.019)
-.025 (.027)
-.018 (.024)
Log(Big Data) .024 (.016) .025
(.017) .017
(.015)
Log(Big Data-Regional) .022** (.009) .009
(.015) -.029 (.022)
.030** (.009)
In San Francisco and Seattle .027** (.006)
.039** (.019)
.018** (.009) .042**
(.015)
Other Metro Areas .011 (.009)
.019 (.014)
.019 (.011) .025
(.015)
Big Data Firm .051 (.076)
BD Firm*Log(BD Pool) -.061 (.079)
BD Firm*Log(IT Pool) .414 (.401)
BD Firm*Log(BD-Region Pool) .048** (.023)
Controls SIC4 SIC4 SIC4 SIC4 SIC4 SIC4 SIC4 Year
N 1,692 1,694 609 1,085 1,135 1,692 1,692 R2 0.87 0.91 0.88 0.88 0.89 0.91 0.91 **p<.05. Standard errors are robust and clustered on firm. Industry controls are included at the four digit SIC level. All variables are in logs. All regressions only use 2011 values. All pool variables are zero-centered.

45
Table 8: Productivity Matched and Mismatched on Complements (Big Data)
Big Data \
Pool
1
0
1
.194*** (.077) N=198
.064 (.051) N=717
0
.147 (.128) N=25
0 (N/A) N=888
Huber-White robust standard errors are shown in parentheses and clustered on firm. ***p<.01.
Table 9: Productivity Matched and Mismatched on Complements (SQL)
SQL \
Pool
1
0
1
.129 (.075) N=737
-.011 (.083) N=268
0
.042 (.062) N=236
0 (N/A) N=705
Huber-White robust standard errors are shown in parentheses and clustered on firm.

46
Table 10: Tests of Sensitivity to Measurement Error in the Skills Data
(1) (2) (3) (4) (5) (6) (7) DV: Log(VA) OLS OLS OLS FE Diffs OLS OLS
Log(Capital) .308** (.016)
.308** (.016)
.308** (.016)
.077 (.014)
.109** (.017)
.373** (.024)
.345** (.043)
Log(Non-IT Labor) .479** (.021)
.479 (.021)
.479** (.021)
.321 (.020)
.400** (.033)
.416** (.031)
.351** (.055)
Log(IT Labor) .174** (.011)
.171** (.011)
.171** (.011)
-.011 (.012)
.015 (.010)
.160** (.022)
.221** (.050)
Big Data 1 .098** (.030)
-.002 (.036)
-.001 ** (.036)
Big Data 2 .219** (.053)
.183** (.054)
.043** (.021)
.043** (.015)
Big Data 5 .092 (.078)
Log(Big Data/SQL) .044** (.015)
Log(Big Data) .167** (.042)
Controls SIC4 Year
SIC4 Year
SIC4 Year
SIC4 Year
SIC4 Year
SIC4 Year
SIC4 Year
N 12,677 12,677 12,677 10,866 10,866 1,504 1,335 R2 0.89 0.89 0.89 0.12 0.15 0.90 0.93 **p<.05. Standard errors are robust and clustered on firm. Industry controls are included at the four-digit SIC level. All variables are in logs. All pool variables used for main effects and interactions are zero-centered. Regressions (1) through (5) are from 2006 to 2011. Regressions (6) and (7) use 2011 values only. Big data 1, 2, and 5 are binary variables indicating whether the firm has at least 1, 2, and 5 workers who list having Hadoop as a skill, respectively.