big data. what is it? massive volumes of rapidly growing data: – smartphones broadcasting location...
TRANSCRIPT

Big Data

What is it?
• Massive volumes of rapidly growing data:– Smartphones broadcasting location (few secs)– Chips in cars diagnostic tests (1000s per sec)– Cameras recording public/private spaces– RFID tags read at as travel through supply-chain

Characteristics of Big Data
• Grows at a fast pace• Diverse• not formally modeled • Unstructured• Heterogeneous• Data is valuable• Standard DBs and DWs cannot capture diversity
and heterogeneity• Cannot achieve satisfactory performance

How to deal with such data
• NoSQL – do not use a relational structure• MapReduce – from Google• Store data in columns rather than rows – great
for aggregates

NoSQL DBs

NoSQL DBs
• Not Only SQL• Not based on RDBMS technologies• Data organized into key-value pairs– <k, v>– v can be a simple word or number, or an arbitrarily
complex structure with its own semantics– Values processed by applications outside DBMS
and not by DBMS itself

NoSQL DBs
• NoSQL DBs– Flexible and extensible data model– No fixed schema– Development of queries is more complex– Distributed and horizontally scalable
• Run on large number of inexpensive (commodity) servers – add more servers as needed
• Differs from vertical scalability of RDBs where add more power to a central server
– Limits to operations (no join ...), but suited to simple tasks, e.g. storage and retrieval of text files such as tweets
– More processing simpler and more affordable– No standard or uniform query language such as SQL

BASE properties instead of ACID
• BASE: Basically Available Soft state Eventual Consistency• BASE differs from ACID – trades consistency for availability
– ACID pessimistic – forces consistency at end of every operation– BASE optimistic – accepts DB consistency will be in a state of
flux– Leads to levels of scalability that cannot be obtains with ACID– Supports partial failures without total system failure– Uses Partitioning!!!
• Design partitions so a failure impacts only 20% of users on a host• Decompose data into functional groups, partition busiest groups
across multiple DBs

BASE properties
– Where to relax consistency?• Analyze logical transactions• Temporal inconsistency cannot be hidden, so pick
opportunities to relax consistency, e.g.– Running totals of the amount sold and bought– Consistency across functional groups is easier to relax than
within groups» Counters for buyer and seller updated, BUT
• Running balances do not have to reflect result of transaction immediately• Acceptable in ATM withdrawals and cellphone
calls» Decouple updates to seller and buyer in transaction» Can have problems with 2PC

BASE properties
– Effect of soft state and eventual consistency on application design• Using BASE doesn’t change predictability of systems as
a closed loop– E.g. lag between moving asset from one user to another may
not be relevant (may take a few seconds) even though relying on a soft state and eventual consistency
– For more info about this: BASE paper – Pritchett from ebay

MongoDB
• One example of a NoSQL DB is MongoDB – document oriented organized around collections of documents– Collections are similar corresponds to tables in
RDBS– Document corresponds to rows in RDBS– Collections can be created at run-time– Documents’ structure not required to be the
same, although cases it may be

MongoDB
• Can built incrementally without modifying schema (since no schema)
• Example of hotel info:h1 = {name: "Metro Blu", address: "Chicago, IL", rating: 3.5}db.hotels.save(h1) h2 = {name: "Experiential", address: "New York, NY", rating: 4}db.hotels.save(h2) h3 = {name: "Zazu Hotel", address: "San Francisco, CA", rating: 4.5}db.hotels.save(h3)

MongoDB
• DB contains collection called ‘hotels’ with 3 documents
• To list all hotels:db.hotels.find()
• Did not have to declare or define the collection
• To add a new hotel with unknown rating:h4 = {name: "Solace", address: "Los Angeles, CA"}db.hotels.save(h4)

MongoDB
• To query all hotels in CA:db.hotels.find( { address : { $regex : "CA" } } );
• To update hotels:db.hotels.update( { name:"Zazu Hotel" }, { $set : {wifi: "free"} } )db.hotels.update( { name:"Zazu Hotel" }, { $set : {parking: 45} } )
• Operations in queries are limited – must implement in a programming language (javascript for MongoDB)
• Any performance optimizations, such as indexing, physical layout of documents must be implemented by developer

MapReduce
Based on J. Lin and C. Dyer bookData-Intensive Text Processing with
MapReduce

MapReduce
• Programming model for distributed computations on massive amounts of data
• Execution framework for large-scale data processing on clusters of commodity servers
• Developed by Google – built on old, principles of parallel and distributed processing
• Hadoop – adoption of open-source implementation by Yahoo (now Apache project)

Big Data
• Big data – issue to grapple with• Web-scale synonymous with data-intensive
processing• Public, private repositories of vast data• Behavior data important - BI

4th paradigm
• Manipulate, explore, mine massive data – 4th paradigm of science (theory, experiments, simulations)
• In CS, systems must be able to scale
• Increases in capacity > improvements in bandwidth

MapReduce (MR)
• MapReduce – level of abstraction and beneficial division of labor– Programming model – powerful abstraction
separates what from how of data intensive processing

Big Ideas behind MapReduce
• Scale out not up– Purchasing symmetric multi-processing machines
(SMP) with large number of processor sockets (100s), large shared memory (GBs) not cost effective• Why? Machine with 2x processors > 2x cost
– Barroso & Holzle analysis using TPC benchmarks• SMP – communication order magnitude faster
– Cluster of low end approach 4x more cost effective than high end
– However, even low end only 10-50% utilization – not energy efficient

Big Ideas behind MapReduce
• Assume failures are common– Assume cluster machines mean-time failure 1000
days– 10,000 server cluster, 10 failures a day– MR copes with failure
• Move processing to the data– MR assume architecture where
processors/storage co-located– Run code on processor attached to data

Big Ideas behind MapReduce
• Process data sequentially not random– If 1TB DB with 1010, 100B records– If update 1%, take 1 month– If read entire DB and rewrites all records with
updates, takes < 1 work day on single machine– Solid state won’t help– MR – designed for batch processing, trade latency
for throughput

Big Ideas behind MapReduce
• Hide system-level details from application developer– Writing distributed programs difficult• Details across threads, processes, machines• Code runs concurrently is unpredictable– Deadlocks, race conditions, etc.
– MR isolates develop from system-level details• No locking, starvation, etc.• Well-defined interfaces• Separates what (programmer) from how (responsibility
of execution framework)• Framework designed once and verified for correctness

Big Ideas behind MapReduce
• Seamless scalability– Given 2x data, algorithms takes at most 2x to run– Given cluster 2x large, take ½ time to run– The above is unobtainable for algorithms• 9 women can’t have a baby in 1 month• E.g. 2x programs takes longer• Degree of parallelization increases communication
– MR small step toward attaining• Algorithm fixed, framework executes algorithm• If use 10 machines 10 hours, 100 machines 1 hour

Motivation for MapReduce
• Still waiting for parallel processing to replace sequential• Progress of Moore’s law - most problems could be solved by
single computer, so ignore parallel, etc.• Around 2005, no longer true– Semiconductor industry ran out of opportunities to
improve• Faster clocks cheaper pipelines, superscalar
architecture– Then came multi-core• Not matched by advances in software

Motivation
• Parallel processing only way forward• MapReduce to the rescue– Anyone can download open source Hadoop
implementation of MapReduce– Rent a cluster from a utility cloud– Process TB within the week
• Multiple cores in a chip, multiple machines in a cluster

Motivation
• MapReduce: effective data analysis tool– First widely-adopted step away from von
Neumann model• Can’t treat multi-core processor, cluster as
conglomeration of many von Neumann machine image that communicates over network• Wrong abstraction• MR – organize computations not over individual
machines, but over clusters• Datacenter is the computer

Motivation
• Previous models of parallel computation– PRAM• Arbitrary number of processors, share unbounded large
memory, operate synchronously on shared input– LogP, BSP
• MR most successful abstraction for large-scale resources– Manages complexity, hides details, presents well-defined
behavior– Makes certain tasks easier, others harder
• MapReduce first in new class of programming models

MAP REDUCE BASICS CHAPTER 2

Basics• Divide and conquer– Partition large problem into smaller subproblems– Worker work on subproblems in parallel• Threads in a core, cores in multi-core processor,
multiple processor in a machine, machines in a cluster– Combine intermediate results from worker to final result– Issues• How break up into smaller tasks• Assign tasks to workers• Workers get data needed• Coordinate synchronization among workers• Share partial results• Do all if SE errors and HW faults?

Basics
• MR – abstraction that hides system-level details from programmer
• Move code to data– Spread data across disks– DFS manages storage

Topics
• Functional programming• MapReduce• Distributed file system

Functional Programming Roots
• MapReduce = functional programming plus distributed processing on steroids – Not a new idea… dates back to the 50’s (or even 30’s)
• What is functional programming?– Computation as application of functions– Computation is evaluation of mathematical functions– Avoids state and mutable data– Emphasizes application of functions instead of changes in
state

Functional Programming Roots
• How is it different?– Traditional notions of “data” and “instructions” are not
applicable– Data flows are implicit in program– Different orders of execution are possible– Theoretical foundation provided by lambda calculus
• a formal system for function definition
• Exemplified by LISP, Scheme

Overview of Lisp
• Functions written in prefix notation
(+ 1 2) 3 (* 3 4) 12(sqrt ( + (* 3 3) (* 4 4))) 5(define x 3) x(* x 5) 15

Functions
• Functions = lambda expressions bound to variablesExample expressed with lambda:(+ 1 2) 3 λxλy.x+y
• Above expression is equivalent to:
• Once defined, function can be applied:
(define (foo x y) (sqrt (+ (* x x) (* y y))))
(define foo (lambda (x y) (sqrt (+ (* x x) (* y y)))))
(foo 3 4) 5

Functional Programming Roots
• Two important concepts in functional programming– Map: do something to everything in a list– Fold: combine results of a list in some way

Functional Programming Map
• Higher order functions – accept other functions as arguments– Map• Takes a function f and its argument, which is a list• applies to all elements in list• Returns a list as result
• Lists are primitive data types – [1 2 3 4 5]– [[a 1] [b 2] [c 3]]

Map/Fold in Action• Simple map example:
(map (lambda (x) (* x x)) [1 2 3 4 5]) [1 4 9 16 25]

Functional Programming Reduce
– Fold• Takes function g, which has 2 arguments: an initial
value and a list. • The g applied to initial value and 1st item in list• Result stored in intermediate variable• Intermediate variable and next item in list 2nd
application of g, etc.• Fold returns final value of intermediate variable

Map/Fold in Action• Simple map example:
• Fold examples:
• Sum of squares:
(map (lambda (x) (* x x)) [1 2 3 4 5]) [1 4 9 16 25]
(fold + 0 [1 2 3 4 5]) 15(fold * 1 [1 2 3 4 5]) 120
(define (sum-of-squares v) // where v is a list (fold + 0 (map (lambda (x) (* x x)) v)))
(sum-of-squares [1 2 3 4 5]) 55
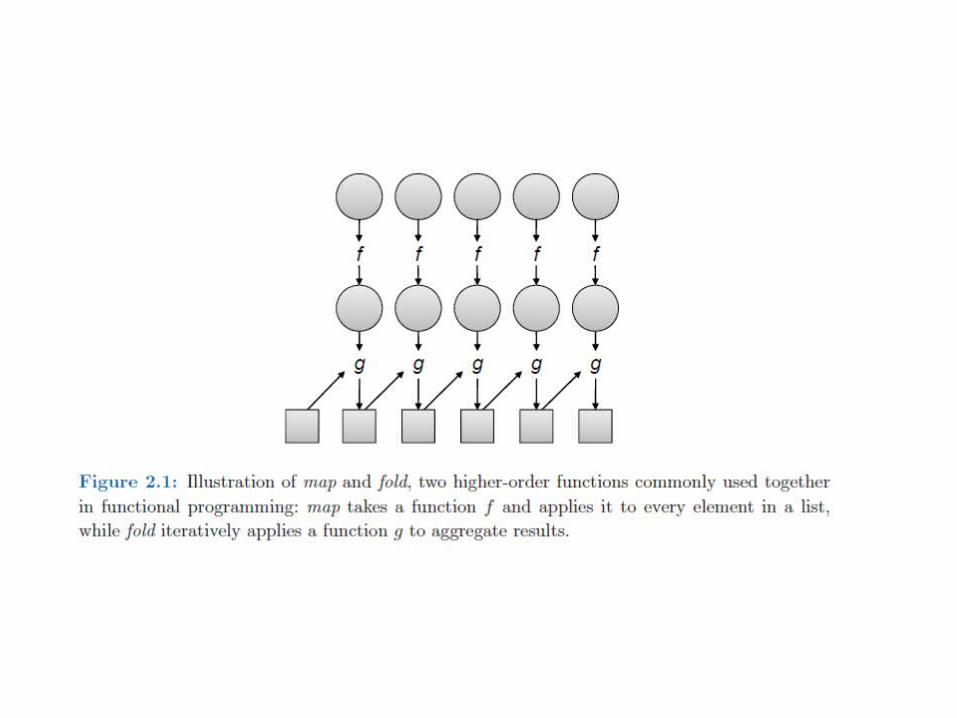

Functional Programming Roots
• Use map/fold in combination• Map – transformation of dataset• Fold- aggregation operation• Can apply map in parallel• Fold – more restrictions, elements must be
brought together– Many applications do not require g be applied to
all elements of list, fold aggregations in parallel

Functional Programming Roots
• Map in MapReduce is same as in functional programming
• Reduce corresponds to fold• 2 stages:– User specified computation applied over all input,
can occur in parallel, return intermediate output– Output aggregated by another user-specified
computation

Mappers/Reducers
• Key-value pair (k,v) – basic data structure in MR
• Keys, values – int, strings, etc., user defined– e.g. keys – URLs, values – HTML content– e.g. keys – node ids, values – adjacency lists of
nodesMap: (k1, v1) -> [(k2, v2)]Reduce: (k2, [v2]) -> [(k3, v2)]
Where […] denotes a list

General Flow• Apply mapper to every input key-value pair stored in
DFS• Generate arbitrary number of intermediate (k,v)• Distributed group by operation (shuffle) on intermediate
keys• Sort intermediate results by key (not across reducers)• Aggregate intermediate results• Generate final output to DFS – one file per reducer
Map
Reduce

What function is implemented?


Example: unigram (word count)
• (docid, doc) on DFS, doc is text• Mapper tokenizes (docid, doc), emits (k,v) for
every word – (word, 1)• Execution framework all same keys brought
together in reducer• Reducer – sums all counts (of 1) for word• Each reduce writes to one file• Words within file sorted, file same # words• Can use output as input to another MR

Execution Framework
• Data/code co-location– Execute near data– It not possible must stream data• Try to keep within same rack

Execution Framework
• Synchronization– Concurrently running processes join up– Intermediate (k,v) grouped by key, copy intermediate data over network, shuffle/sort
• Number of copy operations? Worst case:–M X R copy operations
• Each mapper may send intermediate results to every reducer
– Reduce computation cannot start until all mappers finished, (k,v) shuffled/sorted• Differs from functional programming
– Can copy intermediate (k,v) over network to reducer when mapper finishes

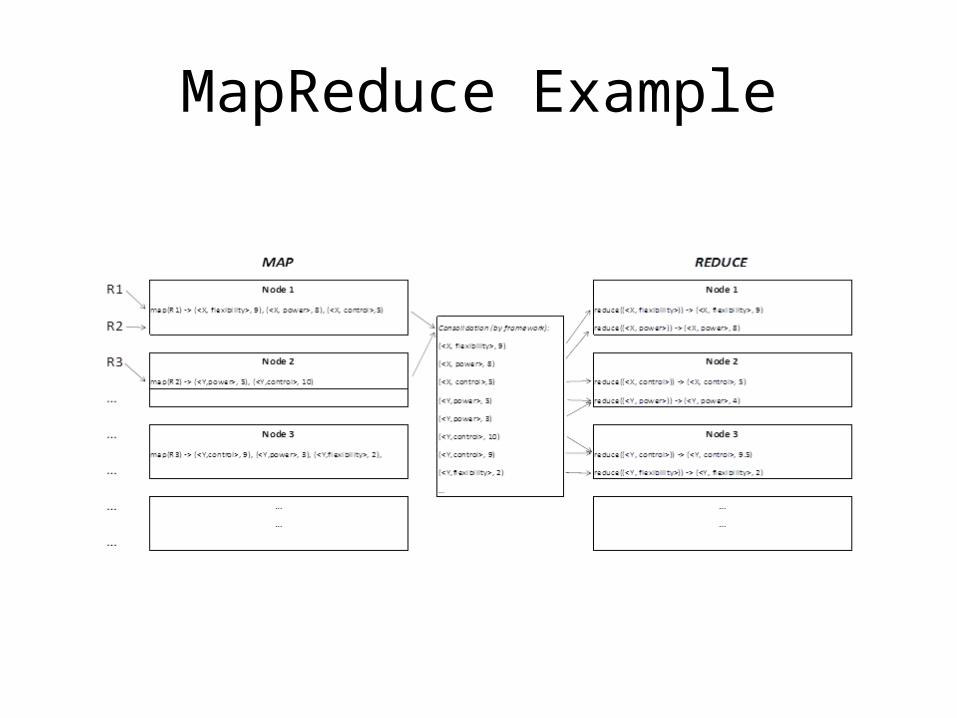
MapReduce Example
Convert the set of written tennis racket reviews to quantitative ratings of certain features. The output is the average of all numeric ratings of the tennis racket feature.– Review 1: The X tennis racket is very flexible, with ample
power, but provides average control.– Review 2: The Y tennis stick provides medium power and
outstanding control.– Review 3: Using the Y racket gives you great control, but
you have to generate most of your power. The frame is not very flexible.

MapReduce Example
• Map Function parses the text and outputs:– map(R1) -> (<X, flexibility>, 9), (<X, power>, 8),
(<X, control>, 5)– map(R2) -> (<Y, power>, 5), (<Y, control>, 10)– map(R3) -> (<Y, control>, 9), (<Y, power>, 3), (<Y,
flexibility>, 2)

MapReduce Example
• Reduce Function result:– reduce((<X, flexibility>)) -> (<X, flexibility>, 9)– reduce((<X, power>)) -> (<X, power>, 8)– reduce((<X, control>)) -> (<X, control>, 5)– reduce((<Y, power>)) -> (<Y, power>, 4)– reduce((<Y, control>)) -> (<Y, control>, 9.5)– reduce((<Y, flexibility>)) -> (<Y, flexibility>, 2)
MapReduce Example

MapReduce Example