a weighted version of free energy ribosomal algorithm using mg1655 e.coli genome
Post on 21-Dec-2015
213 views
TRANSCRIPT

A weighted Version of Free Energy Ribosomal Algorithm
Using MG1655 E.Coli Genome

Free Energy Ribosomal Algorithm
C1
C2
C3
C4
C(L-N)
S
.
.
.
Co
rrel
ato
r
E1
E2
E3
E4
EL-N
A sliding window is applied on the received noisy mRNA sequence to select sub-sequences (S) of length N and compare them with all (L-N) codewords in the codebook (L=13).
The codeword that results in the minimum distance metric is selected and the metric value is saved.
Biologically, the ribosome achieves this by means of the complementary principle. The energetics involved in the rRNA-mRNA interaction tell the ribosome when a signal is detected and, thus, when the start of the process of translation should take place.
The codeword yielding the minimum free energy, i.e. most complementary, will be the valid codeword. The minimum energies are stored and plotted in order to show the performance of the algorithm.

AGAGAAAUAAAAAGUGAAACAUCUGC … GCGUCCAUCAGUUUGA
For N = 5 (codeword length = window length)
In this model, the method of free energy doublets presented in [12] is adopted to calculate a free energy distance metric in kcal/mol instead of minimum distance (see Table).
[12] D. Rosnick, Free Energy Periodicity and Memory Model for Genetic Coding. PhD thesis, North Carolina State University, Raleigh, 2001.
5’ U A A G G A G G U G A U C ... 3’

U A A G G : Codeword # 1U A C G G : 5-bases string of mRNA
U A
U AMatch E = E – 1.1
A C
A AMismatch E = E
C G
A GMismatch E = E
G G
G GMatch E = E – 2.9
– 1.1
– 0
– 0
– 2.9
- 4
E = 0 (Initialization)
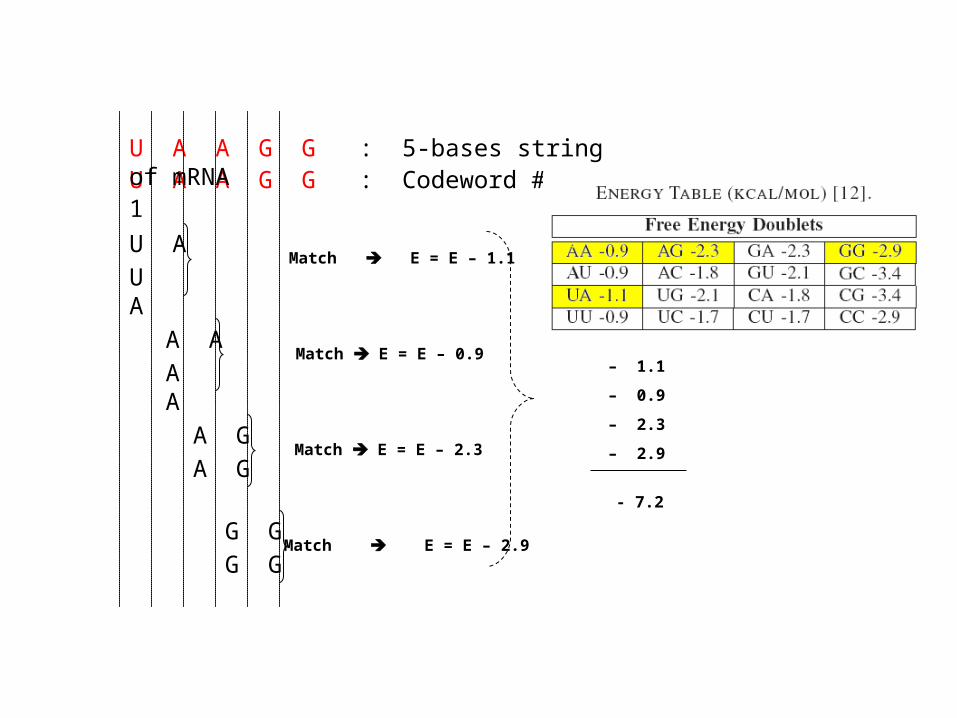
U A A G G : Codeword # 1U A A G G : 5-bases string of mRNA
U A
U AMatch E = E – 1.1
A A
A AMatch E = E – 0.9
A G
A GMatch E = E – 2.3
G G
G GMatch E = E – 2.9
– 1.1
– 0.9
– 2.3
– 2.9
- 7.2

Free Energy Ribosome Decoding Algorithm

L = length(c);
N = length(c{1});
E1(1:L) = 0; % Initialization
E2(1:L) = 0; % Initialization
for k = 1:L
match = 0;
for n = 1:N-1
if isequal({c{k}(n:n+1)},{s{1}(n:n+1)})
match = match + 1;
FED = c{k}(n:n+1);
E1(k) = E1(k) + uniform_energy(FED);
if match == 1, factor = 1; end
if match == 2, factor = 2; end
if match == 3, factor = 5; end
if match == 4, factor = 10; end
E2(k) = E2(k) + factor * uniform_energy(FED);
else
E1(k) = E1(k);
E2(k) = E2(k);
end
end
end
E_min1 = min(E1);
E_min2 = min(E2);
Remarks:
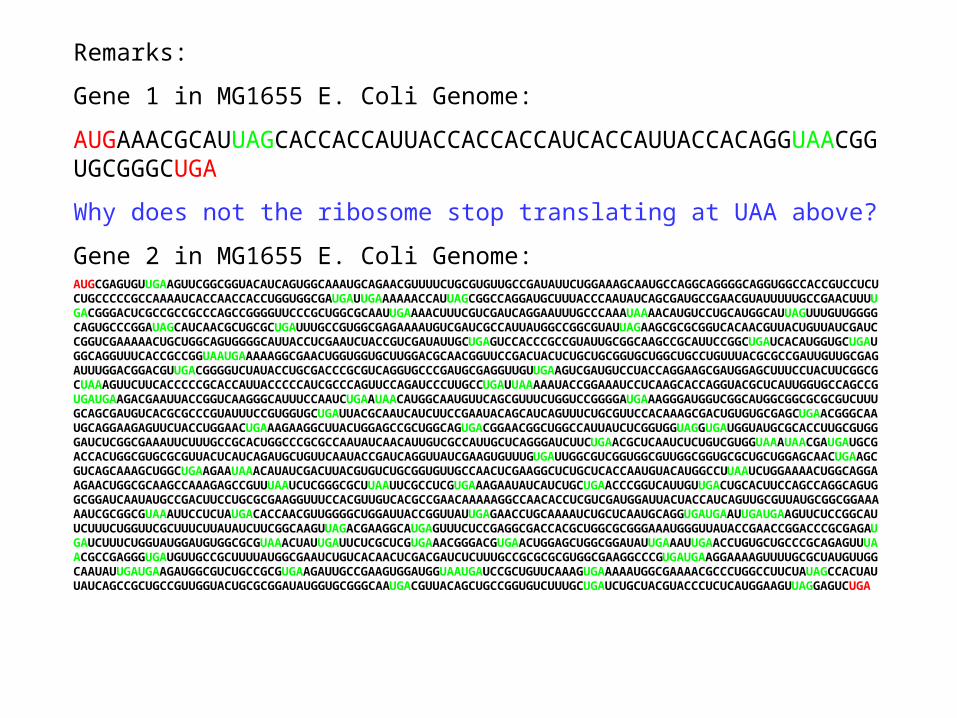
Gene 1 in MG1655 E. Coli Genome:
AUGAAACGCAUUAGCACCACCAUUACCACCACCAUCACCAUUACCACAGGUAACGGUGCGGGCUGA
Why does not the ribosome stop translating at UAA above?
Gene 2 in MG1655 E. Coli Genome:AUGCGAGUGUUGAAGUUCGGCGGUACAUCAGUGGCAAAUGCAGAACGUUUUCUGCGUGUUGCCGAUAUUCUGGAAAGCAAUGCCAGGCAGGGGCAGGUGGCCACCGUCCUCUCUGCCCCCGCCAAAAUCACCAACCACCUGGUGGCGAUGAUUGAAAAAACCAUUAGCGGCCAGGAUGCUUUACCCAAUAUCAGCGAUGCCGAACGUAUUUUUGCCGAACUUUUGACGGGACUCGCCGCCGCCCAGCCGGGGUUCCCGCUGGCGCAAUUGAAAACUUUCGUCGAUCAGGAAUUUGCCCAAAUAAAACAUGUCCUGCAUGGCAUUAGUUUGUUGGGGCAGUGCCCGGAUAGCAUCAACGCUGCGCUGAUUUGCCGUGGCGAGAAAAUGUCGAUCGCCAUUAUGGCCGGCGUAUUAGAAGCGCGCGGUCACAACGUUACUGUUAUCGAUCCGGUCGAAAAACUGCUGGCAGUGGGGCAUUACCUCGAAUCUACCGUCGAUAUUGCUGAGUCCACCCGCCGUAUUGCGGCAAGCCGCAUUCCGGCUGAUCACAUGGUGCUGAUGGCAGGUUUCACCGCCGGUAAUGAAAAAGGCGAACUGGUGGUGCUUGGACGCAACGGUUCCGACUACUCUGCUGCGGUGCUGGCUGCCUGUUUACGCGCCGAUUGUUGCGAGAUUUGGACGGACGUUGACGGGGUCUAUACCUGCGACCCGCGUCAGGUGCCCGAUGCGAGGUUGUUGAAGUCGAUGUCCUACCAGGAAGCGAUGGAGCUUUCCUACUUCGGCGCUAAAGUUCUUCACCCCCGCACCAUUACCCCCAUCGCCCAGUUCCAGAUCCCUUGCCUGAUUAAAAAUACCGGAAAUCCUCAAGCACCAGGUACGCUCAUUGGUGCCAGCCGUGAUGAAGACGAAUUACCGGUCAAGGGCAUUUCCAAUCUGAAUAACAUGGCAAUGUUCAGCGUUUCUGGUCCGGGGAUGAAAGGGAUGGUCGGCAUGGCGGCGCGCGUCUUUGCAGCGAUGUCACGCGCCCGUAUUUCCGUGGUGCUGAUUACGCAAUCAUCUUCCGAAUACAGCAUCAGUUUCUGCGUUCCACAAAGCGACUGUGUGCGAGCUGAACGGGCAAUGCAGGAAGAGUUCUACCUGGAACUGAAAGAAGGCUUACUGGAGCCGCUGGCAGUGACGGAACGGCUGGCCAUUAUCUCGGUGGUAGGUGAUGGUAUGCGCACCUUGCGUGGGAUCUCGGCGAAAUUCUUUGCCGCACUGGCCCGCGCCAAUAUCAACAUUGUCGCCAUUGCUCAGGGAUCUUCUGAACGCUCAAUCUCUGUCGUGGUAAAUAACGAUGAUGCGACCACUGGCGUGCGCGUUACUCAUCAGAUGCUGUUCAAUACCGAUCAGGUUAUCGAAGUGUUUGUGAUUGGCGUCGGUGGCGUUGGCGGUGCGCUGCUGGAGCAACUGAAGCGUCAGCAAAGCUGGCUGAAGAAUAAACAUAUCGACUUACGUGUCUGCGGUGUUGCCAACUCGAAGGCUCUGCUCACCAAUGUACAUGGCCUUAAUCUGGAAAACUGGCAGGAAGAACUGGCGCAAGCCAAAGAGCCGUUUAAUCUCGGGCGCUUAAUUCGCCUCGUGAAAGAAUAUCAUCUGCUGAACCCGGUCAUUGUUGACUGCACUUCCAGCCAGGCAGUGGCGGAUCAAUAUGCCGACUUCCUGCGCGAAGGUUUCCACGUUGUCACGCCGAACAAAAAGGCCAACACCUCGUCGAUGGAUUACUACCAUCAGUUGCGUUAUGCGGCGGAAAAAUCGCGGCGUAAAUUCCUCUAUGACACCAACGUUGGGGCUGGAUUACCGGUUAUUGAGAACCUGCAAAAUCUGCUCAAUGCAGGUGAUGAAUUGAUGAAGUUCUCCGGCAUUCUUUCUGGUUCGCUUUCUUAUAUCUUCGGCAAGUUAGACGAAGGCAUGAGUUUCUCCGAGGCGACCACGCUGGCGCGGGAAAUGGGUUAUACCGAACCGGACCCGCGAGAUGAUCUUUCUGGUAUGGAUGUGGCGCGUAAACUAUUGAUUCUCGCUCGUGAAACGGGACGUGAACUGGAGCUGGCGGAUAUUGAAAUUGAACCUGUGCUGCCCGCAGAGUUUAACGCCGAGGGUGAUGUUGCCGCUUUUAUGGCGAAUCUGUCACAACUCGACGAUCUCUUUGCCGCGCGCGUGGCGAAGGCCCGUGAUGAAGGAAAAGUUUUGCGCUAUGUUGGCAAUAUUGAUGAAGAUGGCGUCUGCCGCGUGAAGAUUGCCGAAGUGGAUGGUAAUGAUCCGCUGUUCAAAGUGAAAAAUGGCGAAAACGCCCUGGCCUUCUAUAGCCACUAUUAUCAGCCGCUGCCGUUGGUACUGCGCGGAUAUGGUGCGGGCAAUGACGUUACAGCUGCCGGUGUCUUUGCUGAUCUGCUACGUACCCUCUCAUGGAAGUUAGGAGUCUGA

Gene 19 in MG1655 E.Coli Genome:
CUCGUUGUGGAGAAUAACAAAAAUGGUCAUCUGGAGCUUACAGGUGGCCAUUCGUGGGACAGUAUCCCUGACAGCCUACAAAACGCAAUUGAAGAACGCGAGGCAUCGUCUUAACGAGGCACCGAGGCGUCGCAUUCUUCAGAUGGUUCAACCCUUAAGUUAGCGCUUAUGGGAUCACUCCCCGCCGUUGCUCUUACUCGGAUUCGUAAGCCGUGAAAACAGCAACCUCCGUCUGGCCAGUUCGGAUGUGAACCUCACAGAGGUCUUUUCUCGUUACCAGCGCCGCCACUACGGCGGUGAUACAGAUGACGAUCAGGGCGACAAUCAUCGCCUUAUGCUGCUUCAUUGCUCUCUUCUCCUUGACCUUACGGUCAGUAAGAGGCACUCUACAUGUGUUCAGCAUAUAGGAGGCCUCGGGUUGAUGGUAAAAUAUCACUCGGGGCUUUUCUCUAUCUGCCGUUCAGCUAAUGCCUGAGACAGACAGCCUCAAGCACCCGCCGCUAUUAUAUCGCUCUCUUUAACCCAUUUUGUUUUAUCGAUUCUAAUCCUGAAGACGCCUCGCAUUUUUGUGGCGUAAUUUUUUAAUGAUUUAAUUAUUUAACUUUAAUUUAUCUCUUCAUCGCAAUUAUUGACGACAAGCUGGAUUAUUUUUGAAAUAUUGGCCUAACAAGCAUCGCCGACUGACAACAAAUUAAUUAUUACUUUUCCUAAUUAAUCCCUCAGGAAUCCUCACCUUAAGCUAUGAUUAUCUAGGCUUAGGGUCACUCGUGAGCGCUUACAGCCGUCAAAAACGCAUCUCACCGCUGAUGGCGCAAAUUCUUCAAUAGCUCGUAAAAAACGAAUUAUUCCUACACUAUAAUCUGAUUUUAACGAUGAUUCGUGCGGGGUAAAAUAGUAAAAACGAUCUAUUCACCUGAAAGAGAAAUAAAAAGUGAAACAUCUGCAUCGAUUCUUUAGCAGUGAUGCCUCGGGAGGCAUUAUUCUUAUCAUUGCCGCUAUCCUGGCGAUGAUUAUGGCCAACAGCGGCGCAACCAGUGGAUGGUAUCACGACUUUCUGGAGACGCCGGUUCAGCUCCGGGUUGGUUCACUCGAAAUCAACAAAAACAUGCUGUUAUGGAUAAAUGACGCGCUGAUGGCGGUAUUUUUCCUGUUAGUCGGUCUGGAAGUUAAACGUGAACUGAUGCAAGGAUCGCUAGCCAGCUUACGCCAGGCCGCAUUUCCAGUUAUCGCCGCUAUUGGUGGGAUGAUUGUGCCGGCAUUACUCUAUCUGGCUUUUAACUAUGCCGAUCCGAUUACCCGCGAAGGGUGGGCGAUCCCGGCGGCUACUGACAUUGCUUUUGCACUUGGUGUACUGGCGCUGUUGGGAAGUCGUGUUCCGUUAGCGCUGAAGAUCUUUUUGAUGGCUCUGGCUAUUAUCGACGAUCUUGGGGCCAUCAUUAUCAUCGCAUUGUUCUACACUAAUGACUUAUCGAUGGCCUCUCUUGGCGUCGCGGCUGUAGCAAUUGCGGUACUCGCGGUAUUGAAUCUGUGUGGUGCACGCCGCACGGGCGUCUAUAUUCUUGUUGGCGUGGUGUUGUGGACUGCGGUGUUGAAAUCGGGGGUUCACGCAACUCUGGCGGGGGUAAUUGUCGGCUUCUUUAUUCCUUUGAAAGAGAAGCAUGGGCGUUCUCCAGCGAAGCGACUGGAGCAUGUGUUGCACCCGUGGGUGGCGUAUCUGAUUUUGCCGCUGUUUGCAUUUGCUAAUGCUGGCGUUUCACUGCAAGGCGUCACGCUGGAUGGCUUGACCUCCAUUCUGCCAUUGGGGAUCAUCGCUGGCUUGCUGAUUGGCAAACCGCUGGGGAUUAGUCUGUUCUGCUGGUUGGCGCUGCGUUUGAAACUGGCGCAUCUGCCUGAGGGAACGACUUAUCAGCAAAUUAUGGUGGUGGGGAUCCUGUGCGGUAUCGGUUUUACUAUGUCUAUCUUUAUUGCCAGCCUGGCCUUUGGUAGCGUAGAUCCAGAACUGAUUAACUGGGCGAAACUCGGUAUCCUGGUCGGUUCUAUCUCUUCGGCGGUAAUUGGAUACAGCUGGUUACGCGUUCGUUUGCGUCCAUCAGUUUGACAGGACGGUUUACCGGGGAGCCAUAAACGGCUCCCUUUUCAUUGUUAUCAGGGAGAGAA
SD = 16963 IC = 17489 TC = 18655 This sequence starts at 16558 and ends at 18714

A 500-bases long sequence with the SD being set at position 90, the initiation codon at position 101, and the termination codon at position 398:
GGCGACAAUCAUCGCCUUAUGCUGCUUCAUUGCUCUCUUCUCCUUGACCUUACGGUCAGUAAGAGGCACUCUACAUGUGUUCAGCAUAUAGGAGGFCCUCGGUGAAACAUCUGCAUCGAUUCUUUAGCAGUGAUGCCUCGGGAGGCAUUAUUCUUAUCAUUGCCGCUAUCCUGGCGAUGAUUAUGGCCAACAGCGGCGCAACCAGUGGAUGGUAUCACGACUUUCUGGAGACGCCGGUUCAGCUCCGGGUUGGUUCACUCGAAAUCAACAAAAACAUGCUGUUAUGGAUAAAUGACGCGCUGAUGGCGGUAUUUUUCCUGUUAGUCGGUCUGGAAGUUAAACGUGAACUGAUGCAAGGAUCGCUAGCCAGCUUACGCCAGGCCGCAUUUCCAGCAGUUUGACAGGACGGUUUACCGGGGAGCCAUAAACGGCUCCCUUUUCAUUGUUAUCAGGGAGAGAAAUGAGCAUGUCUCAUAUCAAUUACAACCACUUGUAUUACUUCUGG
SD IC TC
16558 16963 17489 18655 18714
0 406 932 2098 2157
SD IC TC
0 90 101 398 500

Gene 129 in MG1655 E.Coli Genome:
GGCUAUUUCCUCUCCUCUGGAUUUGGGGGAGAGGAGUUUUGACGGCUAUCACCCUUUAUCAACAAUGGUCAGGGUAGACUGAUUUUCGGCUAAGGAGGAAGGCGAUGUUAGGUUGGGUAAUUACCUGUCACGAUGACCGGGCGCAAGAGAUACUGGAUGCGCUGGAGAAAAAACAUGGGGCACUUCUUCAGUGCCGGGCCGUGAAUUUCUGGCGCGGAUUAAGCUCUAAUAUGCUCAGCCGCAUGAUGUGCGAUGCUCUGCAUGAAGCGGACUCUGGUGAGGGUGUCAUCUUCUUAACCGAUAUAGCCGGAGCGCCACCGUAUCGCGUGGCUUCAUUAUUAAGCCACAAACACUCCCGUUGCGAAGUGAUUUCUGGUGUCACGUUACCGUUAAUUGAACAGAUGAUGGCUUGCCGUGAAACCAUGACCAGUUCAGAGUUUCGCGAGCGUAUUGUCGAACUGGGUGCGCCGGAGGUGAGUAGUCUUUGGCACCAACAACAAAAAAAUCCGCCUUUCGUCCUCAAACAUAAUUUGUAUGAGUAUUAACCCGCGAUUCUGAUGGCGCUUUUGCUACAAUAAAAGCGUUGUUUCACCCUCGGUUAUUUUUUCA
SD = 144565
IC = 144577
TC = 145017
This sequence starts at 144473 and ends at 145081

90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signalsN = 5
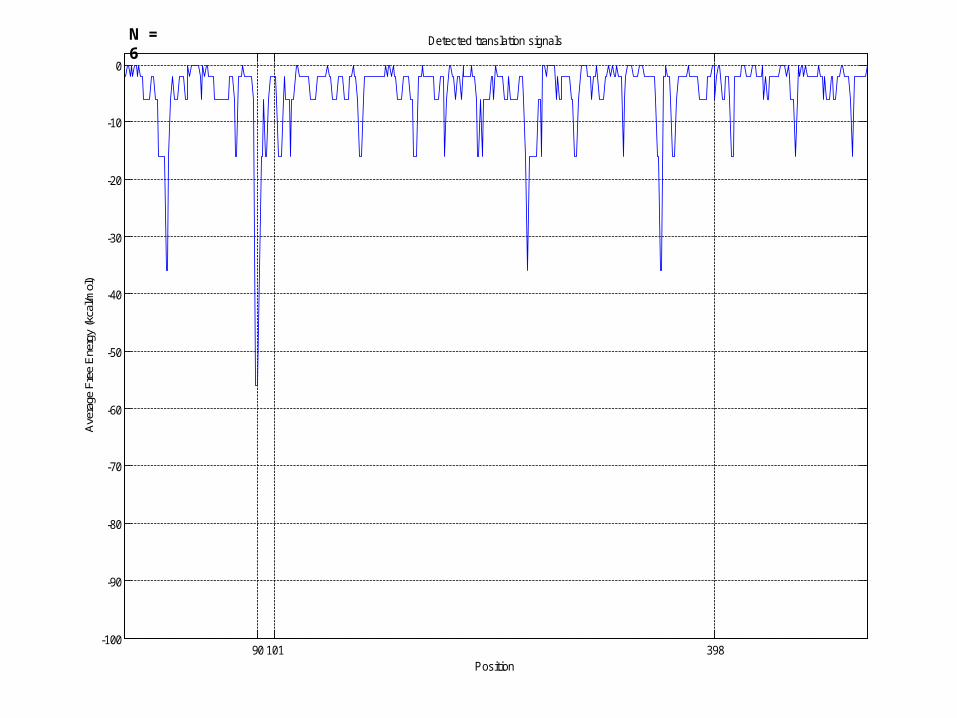
90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signalsN = 6
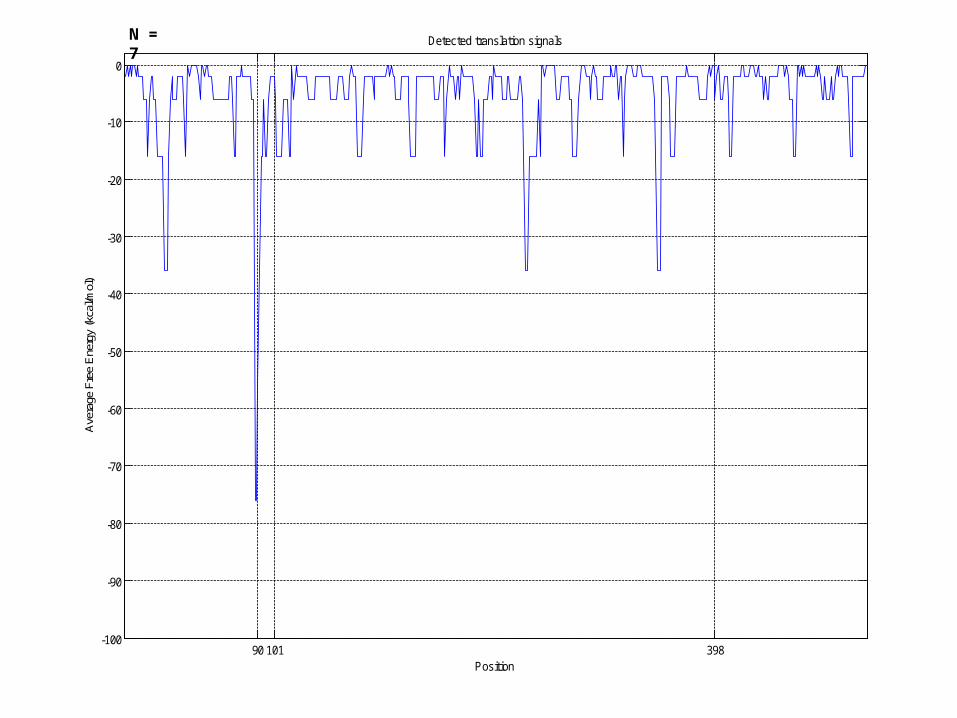
90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signalsN = 7

90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signalsN = 8

90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signalsN = 9

90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signalsN = 10

90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signalsN = 11

90 101 398
-100
-90
-80
-70
-60
-50
-40
-30
-20
-10
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected translation signals

Remarks
• Number of genes in MG1655 E. Coli Strain having the Shine-Dalgarno in the 5’ to 3’ direction (out of 2094 genes):
- “AGGAGG” : 90 positions ( 4.30 % ) - “AGGAG” : 454 positions ( 21.68 %) - “GGAGG” : 335 positions ( 16.00 %) - “GAGG” : 1313 positions ( 62.70 %) - “GGAG” : 1518 positions ( 72.49 %) - “AGGA” : 1836 positions ( 87.68 %)
0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 480 500
A
U
G
C
The Corresponding Gene String
0 90 101 398 500-1200
-1000
-800
-600
-400
-200
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
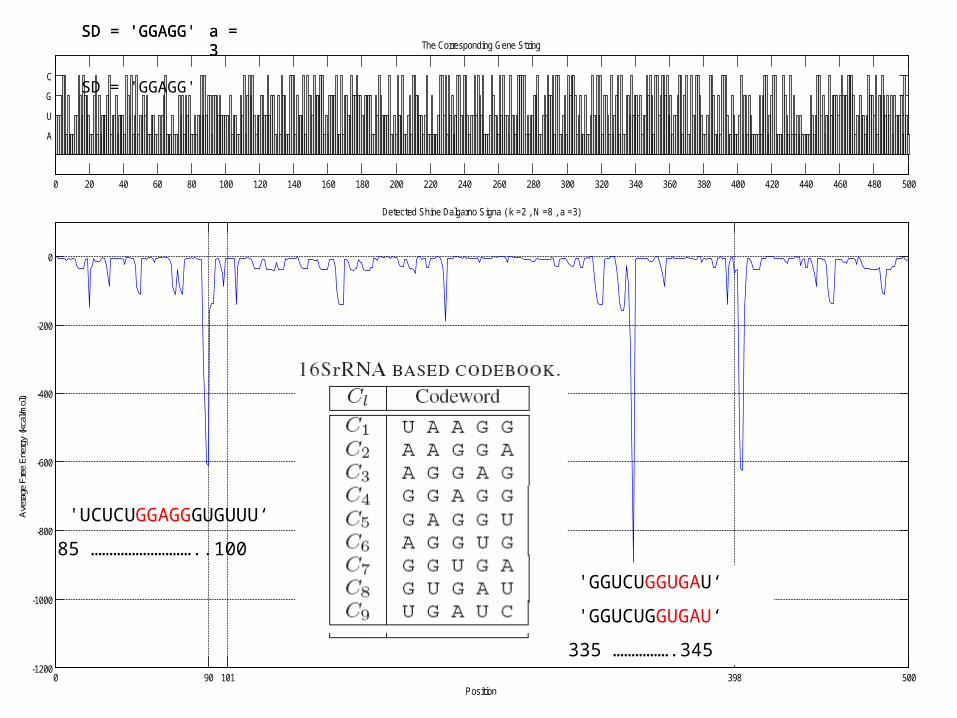
Detected Shine Dalgarno Signa ( k =2 , N =8 , a =3)
SD = 'GGAGG'
'UCUCUGGAGGGUGUUU‘
85 ………………………..100
'GGUCUGGUGAU‘
'GGUCUGGUGAU‘
335 …………….345
a = 3SD = 'GGAGG' a = 3
'GGUCUGGUGAU‘
'GGUCUGGUGAU‘
335 …………….345
SD = 'GGAGG'

0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 480 500
A
U
G
C
The Corresponding Gene String
0 90 101 398 500-1200
-1000
-800
-600
-400
-200
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected Shine Dalgarno Signa ( k =2 , N =8 , a =2)
'GGUCUGGUGAU‘
'GGUCUGGUGAU‘
335 …………….345
'UCUCUGGAGGGUGUUU‘
85 ………………………..100
SD = 'GGAGG' a = 2

0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 480 500
A
U
G
C
The Corresponding Gene String
0 90 101 398 500-1200
-1000
-800
-600
-400
-200
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected Shine Dalgarno Signa ( k =1 , N =8 , a =2.5)
'GAAAAAGGAGAAAUUC ‘
85 ……………………….100
'CUGGGAUGGAGGUCAC ‘
'CUGGGAUGGAGGUCAC ‘
235 ……………………….250
SD = ‘AGGAG' a = 2.5
'GAAAAAGGAGAAAUUC ‘
85 ……………………….100
'CUGGGAUGGAGGUCAC ‘
'CUGGGAUGGAGGUCAC ‘
235 ……………………….250
SD = ‘AGGAG' a = 2.5
'GAAAAAGGAGAAAUUC ‘
85 ……………………….100
'CUGGGAUGGAGGUCAC ‘
'CUGGGAUGGAGGUCAC ‘
235 ……………………….250
SD = ‘AGGAG' a = 2.5

0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 480 500
A
U
G
C
The Corresponding Gene String
0 90 101 398 500-1200
-1000
-800
-600
-400
-200
0
X: 42Y: -29.13
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected Shine Dalgarno Signa ( k =9 , N =10 , a =2.5)
'CUCACAGGAGC ‘
40 ………………50
'GAGCGAGGAGAACCGU ‘
85 ……………………….100
SD = ‘AGGAG' a = 2.5SD = ‘AGGAG' a = 2.5
'CUCACAGGAGC ‘
40 ………………50
SD = ‘AGGAG' a = 2.5
'GAGCGAGGAGAACCGU ‘
85 ……………………….100
'CUCACAGGAGC ‘
40 ………………50
SD = ‘AGGAG' a = 2.5
'GAGCGAGGAGAACCGU ‘
85 ……………………….100
'CUCACAGGAGC ‘
40 ………………50
SD = ‘AGGAG' a = 2.5

0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 480 500
A
U
G
C
The Corresponding Gene String
0 90 101 398 500-1200
-1000
-800
-600
-400
-200
0
X: 68Y: -29.13
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected Shine Dalgarno Signa ( k =5 , N =7 , a =2.5)
X: 72Y: -27.38
'GGGAAGAGGUAGGGGG ‘
85 ……………………….100
'UUCAUAAGGAU ‘
65 …………..…75
SD = ‘GAGG' a = 2.5SD = ‘GAGG' a = 2.5
'UUCAUAAGGAU ‘
65 …………..…75
SD = ‘GAGG' a = 2.5
'GGGAAGAGGUAGGGGG ‘
85 ……………………….100
'UUCAUAAGGAU ‘
65 …………..…75
SD = ‘GAGG' a = 2.5
'GGGAAGAGGUAGGGGG ‘
85 ……………………….100
'UUCAUAAGGAU ‘
65 …………..…75
SD = ‘GAGG' a = 2.5

0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 480 500
A
U
G
C
The Corresponding Gene String
0 90 101 398 500-1200
-1000
-800
-600
-400
-200
0
Position
Ave
rage
Fre
e E
nerg
y (k
cal/m
ol)
Detected Shine Dalgarno Signa ( k =1 , N =8 , a =2.5)
'AUUAUGGAGAAAAAUG ‘
85 ……………………….100
‘CUGGGAUGGAGGUCAC’
‘CUGGGAUGGAGGUCAC’
235………………………250
SD = ‘GGAG' a = 2.5

Shine-Dalgarno Sequence
• The Shine-Dalgarno Sequence (AGGAGGU) is the signal for initiation of protein biosynthesis in bacterial mRNA. It is located 5' of the first coding AUG, and consists primarily, but not exclusively, of purines.
• The complementary sequence (ACCUCCU), rich in pyrimidines, is called the Anti-Shine-Dalgarno Sequence and is located at the 3' end of the 16S rRNA in the ribosome.
• Mutations in the Shine-Dalgarno Sequence can reduce translation. This reduction is due to a reduced mRNA-ribosome pairing efficiency, as evidenced by the fact that complementary mutations in the Anti-Shine-Dalgarno Sequence can restore translation.
• The role of this sequence was first proposed by Australian scientists John Shine and Lynn Dalgarno.

Shine-Dalgarno sequence vs. ribosomal S1 protein
• In Gram-negative bacteria, however, Shine-Dalgarno sequence presence is not obligatory for ribosome to locate initiator codon, since deletion of Anti-Shine-Dalgarno sequence from 16S rRNA doesn't lead to translation initiation at non-authentic sites.
• Moreover, numerous prokaryotic mRNAs don't possess Shine-Dalgarno sequences at all.
• What principally attracts ribosome to mRNA initiation region is apparently ribosomal protein S1, which binds to AU-rich sequences found in many prokaryotic mRNAs 15-30 nucleotides upstream of start-codon.
• It should be noted, that S1 is only present in Gram-negative bacteria, being absent from Gram-positive species.

Hi, Mohammad,
As for the initiation of E.Coli translation, the small subunit of the ribosome binds to a site "upstream" (on the 5' side) of the start of the message. It proceeds downstream (5' -> 3') until it encounters the start codon AUG. (The region between the cap and the AUG is known as the 5'-untranslated region [5'-UTR].) Here it is joined by the large subunit and a special initiator tRNA. The initiator tRNA binds to the P site (shown in pink) on the ribosome.
There's a book called "Gene function : E. coli and its heritable elements", written by Robert E. Glass. It's an old book, but some fundamental ideas from it are rather illuminating. As for new information, I suggest you turn to papers (especially reviews) instead of books.
Maybe we can schedule a meeting sometime, if you like.
Siyun

I also find another target you might be interested:
Expression of the pyrC gene in Escherichia coli K-12 is regulated by a translational control mechanism. The pyrC ribosome binding site is unusual in that it contains two potential SD sequences, designated SD1 and SD2, which are located 11 and 4 nucleotides upstream of the translational initiation codon, respectively. Mutations that inactivate either SD1 or SD2 were constructed and incorporated separately into a pyrC::lacZ protein fusion. The effects of the mutations on pyrC::lacZ expression, regulation, and transcript levels were determined. The results indicate that SD1 is the only functional pyrC SD sequence. The SD2 mutation did cause a small reduction in expression, but this effect appeared to be due to a decrease in transcript stability.
Below is the nucleotide sequence of the translational initiation region.The ATG translational initiation codon is enclosed in a box. SD1 and SD2 are underlined.