a quick introduction to some statistical concepts
TRANSCRIPT

A QUICK INTRODUCTION TO
SOME STATISTICAL CONCEPTS
Mean (average) page 2 Variance page 7 Standard deviation page 11 Bivariate data page 13 Covariance page 14 Correlation page 19 Linear regression page 21 Residuals page 24 Additional formulas page 25 Regression effect page 27
This document was prepared by Professor Gary Simon with the advice (and consent) of Professor William Silber, Stern School of Business. If you have comments or suggestions, please send them to either [email protected] or [email protected] Release date 15 JULY 2002
1

THE MEAN, OR AVERAGE This document will introduce a number of statistical concepts, and perhaps some of these may be very new to you. Statistical topics can be confusing because identical subject matter can be described in very different terms. The very same statistical concept can be described in several ways:
1. Data, as numbers. 2. Data, represented algebraically. 2m. Data, represented algebraically, allowing multiple values. 3. Conceptually as random variables with probabilities.
A list of data, as in points 1 through 3, might be described as a variable. Each column of a data spreadsheet could be called a variable. In item 3, we do not necessarily have data, and we conceptualize the idea as a random variable. Let’s illustrate the notions first for the concept of the average of a set of values. The average is also called the mean.
1. Consider the list of values 48, 46, 54, 51, 53. The average (or mean) of
this list is found as 48 46 54 51 535
� � � � = 2525
= 50.4.
2. Let n be the number of items in a list. Represent the list as x1, x2, … , xn.
The three dots simply indicate that we’re omitting some of the values.
Note that we’re using x as the symbol for the list items. You’ll frequently see xi as the generic ith element of the list. You can think of the symbol i as a counter or as an index. Some people will describe the list as { xi ; i = 1, …, n }. You can read this as “x-sub-i, as i runs from 1 to n.”
The average of this list is 1 2 ... nx x xn
� � � = � �1 21 ... nx x xn
� � � .
Since we’ll be adding lists of numbers rather frequently, it helps to create a simple notation for this concept. We use the summation
notation 1
n
ii
x�
� to represent the sum of the x’s, using the index i to
enumerate from the starting value i = 1 to the ending value i = n.
Then we have 1
n
ii
x�
� = x1 + x2 + … + xn and the average can be
2

written as 1
1 n
ii
xn
�
� = 1
n
ii
x
n�
�. The symbol i is nothing but a
counting convenience. You should note that 1
n
ii
x�
� =
1
n
jj
x�
� = 1
n
uu
x�
� .
ix�
1n � i in v i
i
n vn
��
In nearly every case you’ll encounter, the entire list of n values will be added, and it’s burdensome to keep the notation above and below the � sign. You can then use ix� as a simpler notation for x1 + x2 + … + xn . Again, the symbol i is a mere counting convenience, and so = jx� = ux� .
The symbol x , which we read as “x bar,” is the most common notation for
the average of the x’s. Thus x = 1ix
n �.
2m. It can happen that the list of value x1, x2, … , xn will involve duplications.
Suppose that there are k different values and that we name them as v1, v2, …, vk . Let’s say that v1 occurs n1 times, v2 occurs n2 times, and so on. The data could then be reorganized to look like this:
Value Multiplicity
v1 n1 v2 n2 v3 n3 . . . . vk nk
TOTAL n
Now x = . You will also see this as x = i .
The formulas in item 2 above are still correct, even if the list involves duplications.
3. There are times in which we consider problems hypothetically, rather than
with numbers (as in item 1) or with algebra symbols (as in items 2 and 2m). In the hypothetical form, we’ll consider X as the phenomenon under discussion, and we’ll give X the technical name random variable. In this style of thinking, X is endowed with randomness. We should write
3

X in upper case. We may have no data yet, but we can still discuss the possible values for X. Let’s suppose that xi is a possible value, and that its associated probability is pi . In such a case, the average of X is i ip x� . When dealing with random variables (rather than with numbers or with algebra symbols), the mean is generally denoted � or perhaps �X . We also say that � is the expected value of X.
The table below concerns the numbers of employees of an office calling in sick on any particular morning.
x : 0 1 2 3 4 p : 0.40 0.30 0.20 0.08 0.02
The probabilities are likely based on past observations, but they could as well be someone’s hypothetical conjectures. We can apply these probabilities to tomorrow’s sick calls, for which we certainly do not yet have data. We can use X to represent the phenomenon, and in this case we’d calculate the expected value of X as
� = 0.40 � 0 + 0.30 � 1 + 0.20 � 2 + 0.08 � 3 + 0.02 � 4 = 0 + 0.30 + 0.40 + 0.24 + 0.08 = 1.02
That is, we expect 1.02 employees to call in sick tomorrow.
Below, bordered by ***, is a technical note which you can skip at first reading.
************************************************************************ This description works perfectly for random variables whose possible values can be identified and isolated; such random variables are called discrete. Other random variables are obtained by measurement processes and have uncountably many values. These random variables are called continuous and a special mathematical framework is needed to deal with them. ************************************************************************
We will not discuss every single idea in all four forms noted above. However you should be aware that it’s possible to describe statistical notions in different styles.
4

EXAMPLE: Over ten business days, the number of shares traded of Miraco were these:
400 200 500 300 800 400 700 200 600 200 Miraco is, of course, a very small company. The average number of shares per day is x = 430. This uses 400 + 200 + … + 200 = 4,300.
There are some duplications of values in this list. The value 200 occurs three times an 400 occurs twice. You can use these duplications to rearrange your computation if you wish. This rearranged form would be
3 � 200 + 300 + 2 � 400 + 500 + 600 + 700 + 800 = 4,300 For this situation, it’s simple enough to add the original list of ten values without searching for duplicates.
EXAMPLE: The number of medical emergency calls coming per day to the Eastside Ambulance Service is random, and we know (either from past experience or as a hypothetical suggestion) that
The probability of 0 calls is 0.10. The probability of 1 call is 0.15. The probability of 2 calls is 0.25. The probability of 3 calls is 0.35. The probability of 4 calls is 0.10. The probability of 5 calls is 0.05.
The mean number of calls per day is
0.10 � 0 + 0.15 � 1 + 0.25 � 2 + 0.35 � 3 + 0.10 � 4 + 0.05 � 5 = 0.00 + 0.15 + 0.50 + 1.05 + 0.40 + 0.25 = 2.35
We can conceptualize the number of calls on any single day as a random variable X. This calculation shows that �X = 2.35.
5

EXAMPLE: A sample was taken of 20 suburban families, and each sampled family was asked how many cars it owned. The data were these:
2 2 1 2 3 2 2 1 2 2 2 1 2 2 1 0 2 2 1 2 You can get x by simply adding these numbers and then dividing by 20. However, the work is easier if you organize it like so:
1 family owned no cars. 5 families owned one car. 13 families owned two cars. 1 family owned three cars.
The total value is then
1 � 0 + 5 � 1 + 13 � 2 + 1 � 3 = 0 + 5 + 26 + 3 = 34
Then x = 3420
= 1.7.
6

THE VARIANCE Another useful statistical summary is the variance. We will use the variance as an intermediary to get to the calculation known as the standard deviation.
The standard deviation is simply the square root of the variance, so the connection between the variance and the standard deviation is very simple. If you are dealing with the variance concept for the first time, you’ll be distressed by the fact that there are several different formulas that lead to the same result. If you are using a computer to do your arithmetic, you will not generally be concerned about the details. We strongly recommend the use of a computer, because arithmetic with a calculator is error-prone. On the other hand, just to make sure the computer is doing it right, as well as to make sure you understand the formula, you should do a sample calculation by hand. With a modest amount of data, the variance can be calculated without a computer. However, the choice of formula requires a judgment call based on the appearance of the information. A good choice will lead to the answer more quickly, and with lower probability of error, than a bad computational choice.
In formula terms, we can describe the process of finding the variance of the list x1, x2, … , xn .
1. Start by finding x , the average. 2. Find the n differences x1 - x , x2 - x , x3 - x , … , xn - x . The
differences are also called deviations. As a computational check, this list must sum to zero.
3. Square these n differences to produce the values (x1 - x )2 , (x2 - x )2, (x3 - x )2, … , (xn - x )2 .
4. Sum these values to get (x1 - x )2 + (x2 - x )2 + (x3 - x )2 + … + (xn - x )2. 5. Divide this sum by n - 1, the sample size, less 1.
The usual symbol for the variance is s2 when the computation starts from data. (When we work from random variables, the symbol is �2.) The variance can be done through the formula which summarizes the steps above.
s2 = � �21
1 ix xn
�
�
�
It’s a little puzzling that this is divided by n - 1, rather than by n. There is a perfectly good explanation for this choice, but we’re not yet ready for it.
7

EXAMPLE: Consider the list of values 48, 46, 54, 51, 53. This was considered previously, and we found the average x = 50.4. The list of differences from the average is this:
-2.4, -4.4, 3.6, 0.6, 2.6 The value -2.4 was obtained as 48 - 50.4. This list of five values sums to zero, as it must. Next we square the values to produce the following:
5.76, 19.36, 12.96, 0.36, 6.76 The value 5.76 was obtained as (-2.4)2 = (-2.4) � (-2.4).
Next we sum the list of squares to get the total 45.20. Finally, we compute s2 = 45.205 1�
=
45.204
= 11.30.
You might find it easier to lay out the arithmetic in a table.
Values xi
Deviations xi -
Squares of Deviations
48 -2.4 5.76 46 -4.4 19.63 54 3.6 12.96 51 0.6 0.36 53 2.6 6.76
TOTAL 0.0 45.20
x
This example should make it clear why we recommend that variances be calculated with a computer! There are other computational formulas for the variance, but the technique given here will suffice for hand calculations with short lists. Variances can also be found for random variables with probabilities. For example, if the value xi has associated probability pi , then the expected value is i ip x� , and it is usually denoted by �. This was discussed above. The variance would then be defined as
�2 = � = � �
2i ip x � �
2 2i ip x � ��
8

You might note that a different symbol, �2 rather than s2, is used for this situation. Also, the forms � and �
2i ip x � �� 22
i ip x � �� represent two different computational strategies. As an example of the variance of a random variable, consider this situation regarding values for the price at which a certain home will sell. The prices are in thousands of dollars.
Price Probability 200 0.20 225 0.40 250 0.30 275 0.10
The expected value here is
� = 0.20 � 200 + 0.40 � 225 + 0.30 � 250 + 0.10 � 275 = 40 + 90 + 75 + 27.5 = 232.5
This example illustrates well what we mean by a random variable. There is no data (yet). The home will sell only one time, and the entire process will come down to a single number. Before the home sells, however, we conceptualize the random process which creates the price. This has been done by suggesting possible prices and corresponding probabilities. (This is of course a hypothetical probability mechanism, perhaps based on a suggestion from a real estate expert.) The random variable will get some symbol, likely X, and we making statements of the form “the probability that X will take the value 200 is 0.20.” The mean of this random variable is � = 232.5. This is not among the listed possible values (200, 225, 250, 275), but the statistical analyst is not concerned. We can next find the variance of the random variable X though this calculation:
�2 = 0.20 � (200-232.5)2 + 0.40 � (225-232.5)2
+ 0.30 � (250-232.5)2 + 0.10 � (275-232.5)2 = 211.25 + 22.5 + 91.875 + 180.625 = 506.25
9

We could also work through 2i ip x� , finding
2
i ip x� = 0.20 � 2002 + 0.40 � 2252 + 0.30 � 2502 + 0.10 � 2752
= 8,000 + 20,250 + 18,750 + 7,562.50
= 54,562.50 This would allow us to compute
�2 = 2
i ip x �2
�� = 54,562.50 - 232.52 = 54,562.50 - 54,056.25 = 506.25 The formulas � and �
2i ip x � �� 22
i ip x � �� will produce the same answer.
10

THE STANDARD DEVIATION If the data values have units of measurements, perhaps dollars, then the variance will have units that are the squares of the units of the data. Thus, if x1, x2, … , xn gives a list of values in dollars, then the variance s2 will have units of dollars2. This would be read as “dollars, squared” or as “square dollars.” This is all very reasonable from a mathematical or physical point of view, but most users are not comfortable with the concept of square dollars. Accordingly, it is common to take the square root to convert back to the original units. The standard deviation is the square root of the variance, and it will have the same units of measurements as the original values. Thus, the standard deviation of a list of dollar values will also be in dollar units. If you’ve calculated a variance, then you get the standard deviation simply as the square root. There are no other added computational complexities associated with the standard deviation. For data the standard deviation is usually written as s, and for random variables the standard deviation is usually written as �. It’s fairly easy to make quick judgments about standard deviations because of the following empirical rule that frequently applied to observed data. We’ll state it twice, once for data and once for random variables.
If x1, x2, … , xn is a set of data values (such as annual rates of return on n mutual funds), and if x is the average and s the standard deviation, then
About 23 of the values are in the interval from x - s to x + s.
About 95% of the values are in the interval from x - 2s to x + 2s. If X denotes a random variable with mean � and with standard deviation �, then
The probability is about 2
3 that X will take a value in the interval from � - � to � + �.
The probability is about 0.95 that X will take a value in the interval from � - 2� to � + 2�.
11

EXAMPLE:
Consider all American males between the ages of 21 and 30. What would be the standard deviation of their weights? We certainly cannot answer this question precisely without data, but it’s easy to make a plausible guess at the standard deviation s. Perhaps these men have an average weight of 165 pounds. It would be believable that about 2
3 of these men have weights between 165 - 25 = 140 pounds and 165 + 25 = 190 pounds, so that 25 pounds is a plausible guess at the standard deviation. We’d also be reasonably happy with the statement that about 95% have weights between 165 - 50 = 115 pounds and 165 + 50 = 215 pounds. EXAMPLE:
Consider data on daily orders for bagged refined flour from Carlborg Mills in Brainerd, Minnesota. What would be a reasonable value for the standard deviation of the daily amounts ordered? The ability to guess standard deviations depends on some familiarity with the concept. It’s easy to formulate a guess for the weights of American males. Since we have no information about this flour mill and no experience with flour data, we should probably not make a guess here.
12

BIVARIATE DATA The mean (or average) and the standard deviation are very common statistical summaries. These two simple quantities can tell us quite a lot about a set of data or about a random variable. The notions get even more interesting when we describe two sets of data (or two random variables) at the same time. The word bivariate suggests that we are dealing with two variables. Consider this set of data on ten recently-sold homes:
Area Price 1800 182400 1362 172800 1819 190000 1594 167600 1605 192500 2741 243800 2190 184400 2393 230500 1654 171600 2209 223100
All homes were located in the same suburban subdivision. The first column gives the indoor area in square feet, and the second column gives the price in dollars. Spreadsheets are now the preferred way to exhibit data like this. You might however also see this in coordinate form:
(1800, 182400) , (1362, 172800) , (1819, 190000) , (1594, 167600) , (1605, 192500) , (2741, 243800) , (2190, 184400) , (2393, 230500) , (1654, 171600) , (2209, 223100)
We can find the following information:
Variable Average Standard deviation
Area 1,937 430 Price 195,870 26,910
This small table gives us quite a good impression about the data. We might, however, like to see something that tells us how the variables act together. Do the larger homes have higher prices?
13

A simple first step consists of making a scatterplot:
This picture has ten points, one for each of the homes. Yes, there is definitely the impression that the larger homes have higher prices. COVARIANCE There are several quantities that quantify the relationship between the two variables. Let’s use y as a symbol for Price and let’s use x as a symbol for Area. The quantity known as the sample covariance between x and y is given as
sxy = � � � �1
11
n
i ii
x x y yn
�
� �
�
�
For the data on home prices and floor areas, this calculation is structured as
� � �
� � �
� ��
1 { 1,800 1,937 182, 400 195,87010 1
1,362 1,937 172,800 195,870...2, 209 1,937 223,100 195,870 }
xys � � �
�
� � �
�
� � �
�
�
�
14

� � � �
� � � �
� � � �
1{ 137 -13,4709
575 23,070...272 27,230 }
� � �
� � � �
�
� �
Although you should do a sample calculation by hand to reinforce your understanding of the concept, actual calculations of this type should certainly be done by computer! The value above is 10,257,646. This calculation has the form
sxy = � ��1 -difference from mean -difference from mean
sample size -1x y� �
so that the units must come from the products. Since x is measured in ft2 (square feet) and y is measured in dollars, the covariance will have units of ft2-$. We cannot even provide good advice about how to pronounce such a thing, but you could try “square-foot dollars” or “dollars-square-foot” or maybe “foot-foot-dollars.” The units are annoying, and fortunately there is something we will do about this – soon. Each summand of the covariance sxy is a product of two factors. Either or both of the factors can be negative, so some of the summands are positive, and some are negative. A picture can show what this means.
15
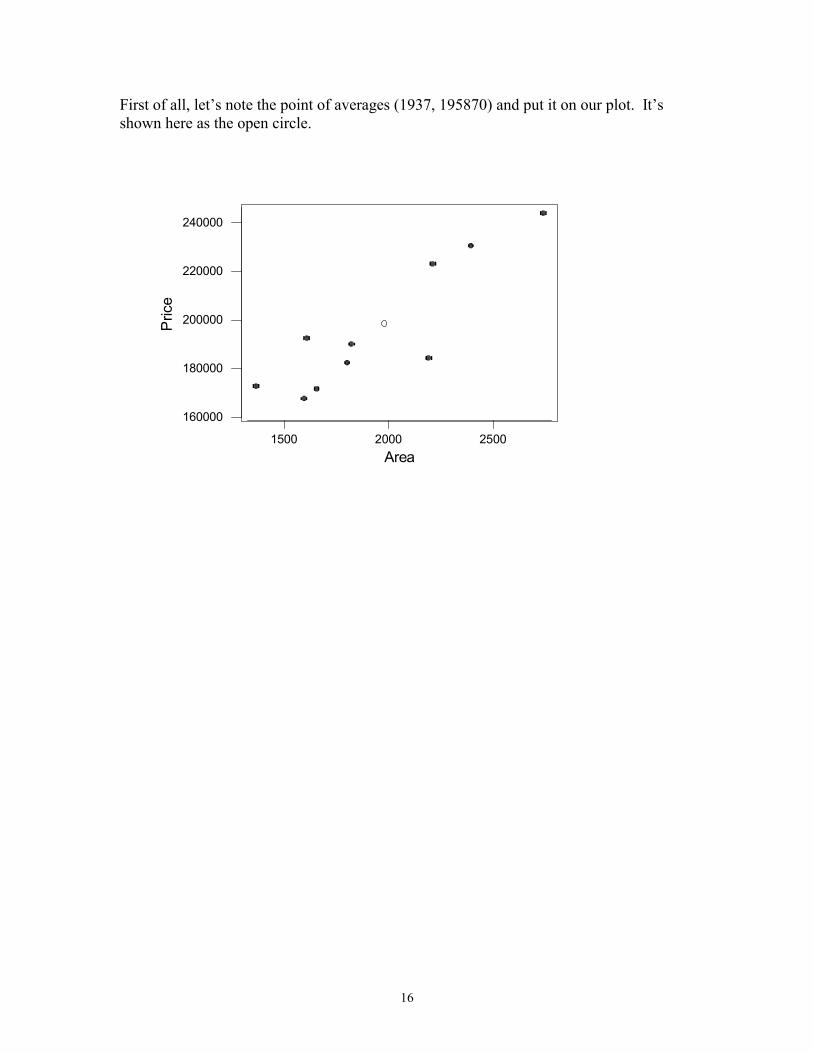
First of all, let’s note the point of averages (1937, 195870) and put it on our plot. It’s shown here as the open circle.
250020001500
240000
220000
200000
180000
160000
Area
Pric
e
16

The contribution to the covariance of any single data point is the area of a rectangle with one corner at the point of averages and the diagonally opposite corner at the data point. The illustration here is of a positive contribution to the covariance, as both the area and the price are above average.
250020001500
240000
220000
200000
180000
160000
Area
Pric
e
17

Here is another positive contribution to the covariance, as both the area and the price are below average:
250020001500
240000
220000
200000
180000
160000
Area
Pric
e
18
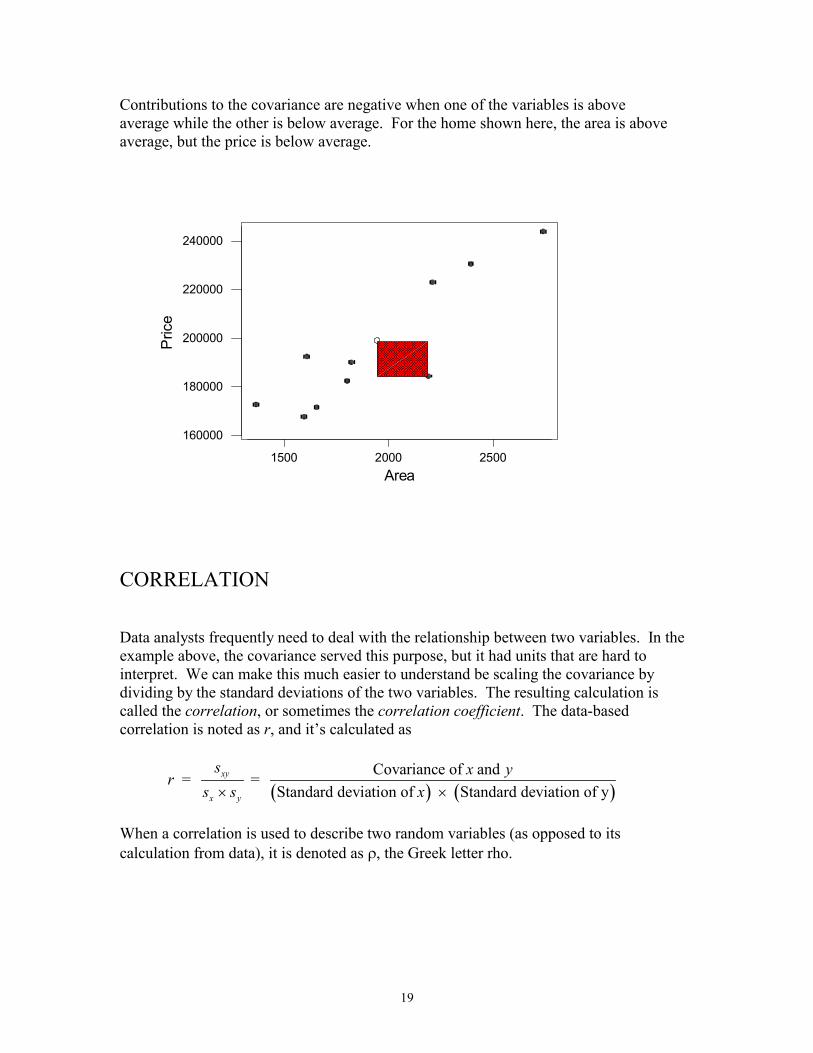
Contributions to the covariance are negative when one of the variables is above average while the other is below average. For the home shown here, the area is above average, but the price is below average.
250020001500
240000
220000
200000
180000
160000
Area
Pric
e
CORRELATION Data analysts frequently need to deal with the relationship between two variables. In the example above, the covariance served this purpose, but it had units that are hard to interpret. We can make this much easier to understand be scaling the covariance by dividing by the standard deviations of the two variables. The resulting calculation is called the correlation, or sometimes the correlation coefficient. The data-based correlation is noted as r, and it’s calculated as
r = xy
x y
ss s�
= � � � �
Covariance of andStandard deviation of Standard deviation of y
x yx �
When a correlation is used to describe two random variables (as opposed to its calculation from data), it is denoted as �, the Greek letter rho.
19

For our data on house sizes and prices, this is
r = 10,257,64626,910 430�
� 0.8865
The calculation of r must produce a value between -1 and +1; values outside this interval are arithmetic errors. ************************************************************************With some algebraic work, we can show that
r = 11 x y
x x y yn s s
� �� �� �� �� �� �� � �� �
�
so that r is (almost) an average of the product of scaled differences from the means. These correspond to the scaled areas of the rectangles associated with the covariances. ************************************************************************ Correlations that are close to +1 represent strong positive relationships. The correlation found above as 0.8865 tells us that large homes tend to have high prices, and small homes tend to have low prices.
A correlation will be +1 exactly if and only if the data points all lie on a line with positive slope. Positive slope refers to a line that rises from the left end of the scatter plot to the right end. This can happen only with a perfect accounting relationship between x and y, and it thus rarely encountered with real data.
Correlations that are close to -1 represent strong negative relationships. For instance, the prices of used 1998 Toyota Corollas have a strong negative relationship with the mileage on the odometer. That is, high prices are generally found on cars with low mileage, and low prices are found on cars with high mileage.
A correlation will be -1 exactly if and only if the data points all lie on a line with negative slope, referring to a line that drops from the left end of the scatter plot to the right end. This requires a perfect accounting relationship between x and y.
Correlations that are close to zero represent weak relationships. We’ve used the words “close to,” “strong,” and “weak” very loosely. Our feelings about correlations will vary according to the problem. Sometimes we work with real estate prices, sometimes with bond interest rates, and sometimes with corporate profits.
20

REGRESSION In most statistical work with two variables, we move beyond the correlation concept to explore the related notion of regression. In the regression context we think of one of the variables as a possible influence on the other. The correlation concept treats the two variables symmetrically, but regression does not. In the regression context, the variable that is doing the (potential) influencing is called the independent variable. The variable that is (potentially) influenced is the dependent variable. Thus, the independent variable is a (potential) influence on the dependent variable. We are being very, very careful with the word “potential.” Consider a data base of manufacturing firms in which we are concerned with year 2000 R&D (research and development) spending and year 2001 profits. Certainly we will consider year 2000 R&D as the independent variable and year 2001 profits as the dependent variable, as we expect that year 2000 R&D will influence year 2001 profits. The data, however, might not support our expectations. This is exactly why we will think of year 2000 R&D as a potential influence. We have many reasons for doing the regression. We will certainly ask whether the potential influence turns out to be an actual influence. We will want to quantify the strength of the relationship. A very important use of regression will be in prediction. If we decide that the relationship between year 2000 R&D and year 2001 profits is strong, we would use that relationship in predicting future profits based on prior R&D spending. The word cause has been scrupulously avoided. We can describe something as a cause only if the data has been collected as part of a controlled randomized experiment. Economic and financial data are observational and not collected in an experimental framework. As much as we might like to say that spending on R&D causes future profit, we simply do not have the logical basis for such a claim. In the scatterplot that accompanies regression work, it is customary to place the dependent variable on the vertical axis and the independent variable on the horizontal axis. In the pictures above regarding home price and floor area, the price was the vertical axis. We certainly want to think that area is a potential influence on price. If the variable labels are x and y, it is customary to use y for the dependent variable and place it on the vertical axis.
21

There’s an interesting exception to this, and you should be aware of it. Economists frequently use P versus Q (price versus quantity) graphs, and they place P on the vertical axis. This layout would agree with custom perhaps for things like agricultural commodities, where Q precedes, and is a potential influence on, P. In other contexts, economists consider suppliers who set P, so that price is a potential influence on Q, the quantity that sells; in such a case they have the dependent variable on the horizontal axis.
In its simplest form, regression is executed as a straight-line relationship, and we call the process linear regression. If the dependent variable is y and the independent variable is x, then the fitted regression line will have the form
y = b0 + b1 x In this form b0 (the intercept) and b1 (the slope) will be numbers computed from the data. In our exploration of the real estate prices, the fitted line will be
Price = b0 + b1 Area The numeric version, obtained with the help of a computer, is
Price = 88,397.5 + 55.4926 Area You might feel that the precision is a bit pretentious, and perhaps you’d like to report
Price = 88,400 + 55.49 Area
22

Here is the scatterplot, this time with the fitted regression line superimposed:
250020001500
240000
220000
200000
180000
160000
Area
Pric
ePrice = 88397.5 + 55.4926 Area
We have a strong interest in the estimated regression slope, 55.49. This represents the average movement in price per unit movement in area. Specifically, this is to be interpreted as $55.49 per square foot of area. This is the estimated marginal effect on price of one additional square foot of area. The estimated intercept, here 88,400, can be interpreted in some problems, but probably not here. Some might try to say that this is “the value of a house with no area,” meaning perhaps an empty building lot. However, the data base included no building lots, and we should refrain from such a speculation. An immediate use of this regression is for prediction. If a home with 2,500 square feet of area comes onto this market, we would predict that it would sell for
88,400 + 55.49 � 2,500 = 88,400 + 138,725 = 227,125 The home might sell for more than $227,125 or it might sell for less. We are, after all, just making a prediction.
23

RESIDUALS Suppose that we use this prediction method for a home that was part of our original data set. The home listed as the first data point had an area of 1,800 square feet. The fitted price would be
88,400 + 55.49 � 1,800 = 88,400 + 99,882 = 188,282 We are going to call this a “fitted price” rather than a “predicted price” because this home is in our data set and we know the price at which it sold. Indeed, this price was $182,400. The difference between the actual observed price (here $182,400) and the fitted price ($188,282) is called the residual. For this home the residual is
182,400 - 188,282 = -5,882 Relative to this regression, this particular home sold for $5,882 less than it should have. This is not a mistake, it is not an error, it is not the result of ineffective negotiation. The data points do not lie neatly on a perfect line, so that some homes will have positive residuals and some will have negative residuals. The table below lists the residuals for all the homes in the data set. The values were obtained by computer; the difference between our -5,882 and the computer’s -5,884.2 is related only to round-off issues.
Area Price Residual 1800 182400 -5884.2 1362 172800 8821.6 1819 190000 661.5 1594 167600 -9252.7 1605 192500 15036.9 2741 243800 3297.3 2190 184400 -25526.3 2393 230500 9308.7 1654 171600 -8582.2 2209 223100 12119.4
The residuals will sum to zero; this is a consequence of the formulas used to calculate the regression. We can see that the fifth home sold for about $15,000 more than the fitted line would suggest. The seventh home sold for about $25,000 less than the fitted line would suggest. The residuals are non-zero simply because the points do not all fall on a straight line. It is tempting to say that the fifth home was over-valued by the purchasers, but we should
24

resist this interpretation. After all, the regression work utilized only floor area, and there are many other factors determining price. It will not surprise you to learn that regression models are used to relate stock prices to sets of independent variables. Companies with negative residuals might be described as undervalued, and therefore attractive purchases, but we have to be very careful about such judgments. After all, the regression work might be missing variables that are relevant to the values of the companies. Of course, these companies might really be undervalued, and certainly any company that produces a large negative residual should be examined closely! The work above has been described as a fitted regression line, based on data. There is also a true regression line, involving a model equation with random variables and a number of assumptions. We will not here go into the formalism of the model equation, but it’s important to realize that our work with data produces a fitted (or estimated) line and not the guaranteed truth. Suppose, hypothetically, that all the residuals turned out to be zero. This would indicate that the dependent variable y could be predicted perfectly from the independent variable x. This means, of course, that there is a perfect accounting relationship between x and y and further that the correlation between x and y would be +1 or -1 (depending on the slope); see the indented comments on page XX. Indeed, the residuals are related to the correlation coefficient. This is a complicated story, as this is the equation which relates them:
r2 = � �
� � � �
2residual1 Variancen y
��
�1
The tells us that a set of large residuals produces a correlation coefficient close to zero. ADDITIONAL FORMULAS The calculations to produce a fitted regression line are intense, and we recommend that computer software be used, although, once again, a sample hand calculation might improve your understanding of what is going on. There are nonetheless some interesting quantitative relationships that we can explore. Here’s one:
b1 = estimated regression slope = Sample covariance of and Sample variance of
x yx
= 2xy
x
ss
25

= � �� �
� �2
11
11
i i
i
x x y yn
x xn
� �
�
�
�
�
� = y
x
sr
s
= Standard deviation of CorrelationStandard deviation of
xy
�
There is a little bit of algebra work behind this. Since r = xy
x y
ss s
, it
must happen that sxy = r sx sy . If we substitute this into b1 = 2xy
x
ss
,
we get b1 = 2x y
x
r s ss
= y
x
sr
s.
b0 = estimated regression intercept = y - b1 x
There’s one further additional interesting way to present a regression line. The fitted line is
y = b0 + b1 x
We can make the substitutions b0 = y - b1 x and b1 = y
x
sr
s to get this:
y
y ys� =
x
x xrs�
In this expression, x and y represent the variables (meaning the names of the horizontal and vertical axes), while the remaining items ( x , sx , y , sy , r) are quantities computed from the data.
26

THE REGRESSION EFFECT Let’s consider the above form of the fitted regression equation with regard to a prediction. We showed previously that a home of 2,500 square feet would be predicted to sell for $227,125. We obtained this value as
88,400 + 55.49 � 2,500 = 88,400 + 138,725 = 227,125 but we could also obtain it by solving for y in
195,87026,910
y � = 2,500 1,9370.8865430�
�
Observe that on the right side the fraction 2,500 1,937430� � 1.31 shows that this home is
1.31 standard deviations above average in size. One would think that the predicted price would then be 1.31 standard deviation above average. However, the predicted price is
only 227,125 195,87026,910
� � 1.16 standard deviations above average in price. Indeed, we
see that within rounding 1.16 � 0.8865 � 1.31. The correlation coefficient in this last result makes the predicted price relatively closer to average than was the floor area used to make the prediction! The floor area is somewhat high, and we predict the price to be high, but not quite as high as the floor area. This particular phenomenon is known as the regression effect. It is a fact of statistical life, and it tends to turn up over and over. It is not always recognized. Suppose that a man is 6� 9�� tall, and suppose that he has a son. What height would you predict that this son would grow to? Most people would predict that he would be tall, but it would be quite unusual for him to be as tall as his father. Perhaps a reasonable prediction is 6� 5��. We are expecting the son to “regress” back to mediocrity, meaning that we expect him to revert to average values. This is of course a prediction on average. The son could well be even taller than his father, but this is unlikely. This regression effect applies also at the other end of the height scale. If the father is 5� 1��, then his son is likely to be short also, but the son will probably be taller than his father. The regression effect is strongest when far away from the center. For fathers of average height, the probability is about 50% that the sons will be taller and about 50% that the sons will be shorter.
27

The regression effect is everywhere.
People found to have high blood pressure at a mass screening (say at an employer’s health fair) will have, on average, lower blood pressures the next time a reading is taken. Mutual fund managers who have exceptionally good performances in year T will be found to have not-so-great performances, on average, in year T + 1. Professional athletes who have great performances in year T will have less great performances, on average, in year T + 1.
28