basic statistical concepts
DESCRIPTION
Basic statistical concepts. [email protected] http://dambe.bio.uottawa.ca. Simpson’s paradox. C. R. Charig et al. 1986. Br Med J ( Clin Res Ed) 292 (6524): 879–882 Treatment A: all open procedures Treatment B: percutaneous nephrolithotomy Question: which treatment is better ?. - PowerPoint PPT PresentationTRANSCRIPT


Simpson’s paradox
Treatment A Treatment B
Small Stones 93% (81/87) 87% (234/270)
Large Stones 73% (192/263) 69% (55/80)
Pooled 78% (273/350) 83% (289/350)
C. R. Charig et al. 1986. Br Med J (Clin Res Ed) 292 (6524): 879–882
Treatment A: all open procedures
Treatment B: percutaneous nephrolithotomy
Question: which treatment is better?

Applied Biostatistics• What is biostatistics: Biostatistics is for collecting,
organizing, summarizing, presenting and analyzing data of biological importance, with the objective of drawing conclusions and facilitating decision-making.
• Statistical estimation/description– point estimation (e.g., mean X = 3.4, slope = 0.37)– interval estimation (e.g., 0.5 < mean X < 8.5)
• Significance tests– Statistic, e.g. t, F, 2 which are indices measuring the
difference between the observed value and the expected value derived from the null hypothesis
– Significance level and p value (e.g., p < 0.01)– Distribution of the statistic (We cannot obtain p value with
the distribution)

• Normal distribution:– Central tendency– dispersion– skewness– kurtosis.
• Confidence Limits.• Degree of freedom, e.g., N, (N-1):
– Use a random number generator to get 40 variables from standard normal distribution and compute variance by dividing SS/N and SS/(N-1)
Descriptive Statistics
-6 -4 -2 0 2 4 6
Confidence Limits: Mean ± t,df SE
1 1
2 2
2 21 1
;
( ) ( )
;1 1
N N
i i ii i
N N
i i ii i
x
x f x
x xN N
x x f x x
s sN N
ss
N

Example of data analysis
30 32 34 36 38 40 42 44 46 48 500
200
400
600
800
1000
1200
Number E(N)
Chest
Num
ber
Chest Number (X-meanX)^2 E(P_cumul) E(P) E(N) E(N) Chi-sq33 3 46.6738 0.0010 0.0010 5.7513 5.7513 1.316234 18 34.0102 0.0046 0.0036 20.8698 20.8698 0.394635 81 23.3465 0.0173 0.0126 72.4853 72.4853 1.000236 185 14.6829 0.0520 0.0347 199.2925 199.2925 1.025037 420 8.0192 0.1276 0.0756 433.7970 433.7970 0.438838 749 3.3556 0.2579 0.1303 747.6065 747.6065 0.002639 1073 0.6919 0.4357 0.1778 1020.1789 1020.1789 2.734940 1079 0.0283 0.6278 0.1921 1102.3292 1102.3292 0.493741 934 1.3646 0.7922 0.1644 943.1520 943.1520 0.088842 658 4.7010 0.9035 0.1114 638.9692 638.9692 0.566843 370 10.0373 0.9633 0.0597 342.7579 342.7579 2.165244 92 17.3737 0.9886 0.0254 145.5710 145.5710 19.714445 50 26.7101 0.9972 0.0085 48.9444 48.9444 0.022846 21 38.0464 0.9994 0.0023 13.0264 16.2278 1.403447 4 51.3828 0.9999 0.0005 2.744048 1 66.7191 1.0000 0.0001 0.4574
Sum 5738 1 5737.9328 31.3675Mean 39.8318 p = 0.0010Var 4.2002Std 2.0494
Probability density function (PDF)Cumulative distribution function (CDF)Grouped dataNull hypothesisSignificance test and p value
𝑝 (𝑥 ,𝜇 ,𝜎 )= 1𝜎 √2𝜋
𝑒−
(𝑥−𝜇 )2
2𝜎2
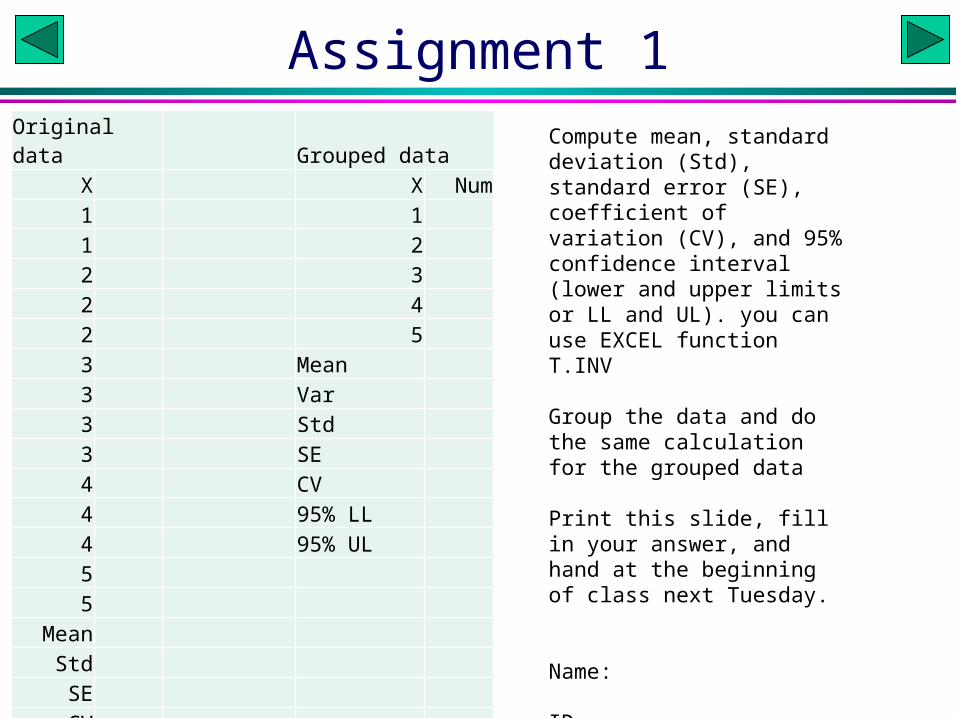
Assignment 1Original data Grouped data
X X Num1 11 22 32 42 53 Mean3 Var3 Std3 SE4 CV4 95% LL4 95% UL55
MeanStdSECV
95% LL95% UL
Compute mean, standard deviation (Std), standard error (SE), coefficient of variation (CV), and 95% confidence interval (lower and upper limits or LL and UL). you can use EXCEL function T.INV
Group the data and do the same calculation for the grouped data
Print this slide, fill in your answer, and hand at the beginning of class next Tuesday.
Name:
ID

Data: same pattern but smaller N
Assignment 3:
Do the same test of normality as the previous slide with comparable N.
No need to hand in, but get ready to discuss the result
Grade Number400 24750 74
1250 381750 212250 112750 83250 113750 54250 24750 15250 35750 16250 06750 07250 07750 1
0 1000 2000 3000 4000 5000 6000 7000 80000
10
20
30
40
50
60
70
80
Grade
Num
ber

R and distributions• Discrete variable: poisson, binomial, geometric, …• Continuous variable: normal, t, F, 2, …• Functions:
– CDF: add p, e.g., pnorm, pt, pf, pchisq– PDF: add d, e.g., dnorm, dt, df, dchisq– Random numbers: add r, e.g., rnorm, rt, rf, rchisq– Quantile (inverse of CDF): add q, e.g., qnorm, qt, qf,qchisq
– Empirical cumulative distribution function: ecdf(x)– Empirical density: density(x)
• Graphic functions– qqnorm(x)– hist(x,n), truehist(x,n) in MASS

Descriptive stats in R• Built-in: mean, sd, var, …• R package: fBasics with skewness, kurtosis, etc.
• Test of normality– Univariate
• Significance test (Shapiro-Wilk-test): shapiro.test(xVec)• Graphic: qqnorm(xVec), plot(density(xVec))
– Multivariate energy test in library "energy"): mvnorm.etest(xMatrix)
• Custom-made:– Describe in Describe.R– StatsGroupedData in StatsGroupData.R

Decision making and risks
1. Type I error is also called Producer’s risk (rejecting a good product). To limit the chance of committing a Type I error, we typically set its rate () small. is referred to as significance level in significance test.
2. Type II error is often referred to as consumer’s risk (accepting an inferior product), and its rate is typically represented by . One can avoid making Type II errors by making no decision until we have a sample size large enough to give us sufficient power to reject the null hypothesis.
3. The power of a test is 1- which depends on sample size and effect size.
Decision
Accept Reject
H0 (e.g., ) True Correct Type I error (false positive)
False Type II error (false negative) Correct

Inference: Population and Sample
ID Weight Length (in kg) (in m)
1 2.3 0.32 2.5 0.33 2.5 0.54 2.4 0.45 2.4 0.46 2.3 0.5
Mean 2.4 0.4
Population Sample SampleIndividual
Statistic Observation
Variable Variate

Essential definitions• Statistic: any one of many computed or estimated statistical
quantities, such as the mean, the standard variation, the correlation coefficient between two variables, the t statistic for two-sample t-test.
• Parameter: a numerical descriptive measure (attribute) of a population.
• Population: a specified set of individuals (or individual observations) about which inferences are to be made.– Idealized population– Operationally defined population.
• Sample: a subset of individuals (or individual observations), generally used to make inference about the population from which the sample is taken from.

Optional materials• Central tendency
– Arithmetic mean– Geometric mean– Harmonic mean
• Dispersion– Moments– Skewness– Kurtosis
• Basic probability theory– Events and event space– Independent events– Mutually exclusive events– Joint events– Empirical probability– Conditional probability

Elementary Probability Theory• Empirical probability of an event is taken as the relative
frequency of occurrence of the event when the number of observations is very large.
• A coin is tossed 10000 times, and we observed head 5136 times. The empirical probability of observing a head when a coin is tossed is then5136/10000 = 0.5136.
• A die is tossed 10000 times and we observed number 2 up 1703 times. What is the empirical probability of getting a 2 when the die is tossed?
• If the coin and the die are even, what is the expected probabilities for getting a head or a number 2?

Mutually Exclusive Events• Two or more events are mutually exclusive if the
occurrence of one of them exclude the occurrence of others.
• Example: – observing a head and observing a tail in a single coin
tossing experiment– events represented by null hypothesis and the alternative
hypothesis– being a faithful husband and having extramarital affairs.
• Binomial distribution

If I ask someone to toss a coin 6 times and record the number of heads, and he comes back to tell me that the number of heads is exactly 3. If I ask him repeat the tossing experiment three more times, and he always comes back to say that the number of heads in each experiment is exactly 3. What would you think?
Experiment Outcome (Number of Heads out of 6 Coin-tossing)1 32 33 34 3
The probability of getting 3 heads out of 6 coin-tossing is 0.3125 for a fair coin following the binomial distribution (0.5 + 0.5)6, and the probability of getting this result 4 times in a roll is 0.0095.
Coin-Tossing Expt.
The person might not have done the experiment at all!

Now suppose Mendel obtained the following results:
Breeding Experiment Number of Round Seeds Number of Wrinkled Seeds1 21 72 24 83 18 6
Based on (0.75+0.25)n: P1 = 0.171883; P2 = 0.161041; P3 = 0.185257; P = 0.0051Edwards, A. W. F. 1986. Are Mendel’s results really too close? Biol. Rev. 61:295-312.
Thinking Critically

Compound Event• A compound event, denoted by E1E2 or E1E2…EN, refers to the
event when two or more events occurring together.• For independent events, Pr{E1E2} = Pr{E1}Pr{E2}
• For dependent events, Pr{E1E2} = Pr{E1}Pr{E2|E1}

Probability of joined events
Criteria Prob.
Between 25 and 45 1/2Very bright 1/25Liberal 1/3Relatively nonreligious 2/3Self-supporting 1/2No kids 1/3Funny, sense of humor 1/3Warm, considerate 1/2Sexually assertive 1/2Attractive 1/2Doesn’t drink or smoke 1/2Is not presently attached 1/2Would fall in love quickly 1/5
The probability of meeting such a person satisfying all criteria is 1/648,000, i.e., if you meet one new candidate per day, it will take you, on the average, 1775 years to find your partner.
Fortunately, many criteria are correlated, e.g., a very bright adult is almost always self-supporting.

Conditional Probability
• Let E1 be the probability of observing number 2 when a die is tossed, and E2 be the probability of observing even numbers. The conditional probability, denoted by Pr{E1|E2} is called the conditional probability of E1 when E2 has occurred.
• What is the expected value for the conditional probability of P{E1|E2} with a fair die?
• What is the expected value for the conditional probability of P{E2|E1}?

Independent Events
• Two events (E1 and E2) are independent if the occurrence or non-occurrence of E1 does not affect the probability of occurrence of E2, so that Pr{E2|E1} = Pr{E2}.
• When one person throw a coin in Hong Kong, and another person throw a die in US, the event of observing a head and the event of getting a number 2 can be assumed to be independent.
• The event of grading students unfairly and the event of students making an appeal can be assumed to be dependent.

Various Kinds of Means• Arithmetic mean• Geometric mean• Harmonic mean• Quadratic mean (or root mean square)

Geometric Mean
• The geometric mean (Gx) is expressed as:
• where is called the product operator (and you know that is called the summation operator.
n
n
ii
nnx xxxxG
1
21 ...

When to Use Geometric Mean• The geometric mean is frequently used with rates of change
over time, e.g., the rate of increase in population size, the rate of increase in wealth.
• Suppose we have a population of 1000 mice in the 1st year (x1 = 1000), 2000 mice the 2nd year (x2 = 2000), 8000 mice the 3rd year (x3 = 8000), and 8000 mice the 4th year (x4 = 8000). This scenario is summarized in the following table:
Year Population size(t)
Population size(t+1)
Rate of increasePSt+1 / PSt
1 1000 2000 2 (population size doubled)
2 2000 8000 4 (population size quadrupled)
3 8000 8000 1 (population size stable)
What is the mean rate of increase? (2+4+1) / 3 ?

Wrong Use of Arithmetic Mean• The arithmetic mean is (2+4+1) / 3 = 7/3, which
might lead us to conclude that the population is increasing with an average rate of 7/3.
• This is a wrong conclusion because
1000 * 7/3 * 7/3 * 7/3 8000
• The arithmetic mean is not good for ratio variables.

Using Geometric Mean• The geometric mean is:
• This is the correct average rate of increase. On average, the population size has doubled every year over the last three years, so that x4 = 1000 222 = 8000 mice.
• Alternative: 1000*r3 = 8000
.28142 33 xG

The Ratio Variable• Example:
– Year 1:
– Year 2:
• The arithmetic mean ratio is r1 = 2.5
• What is the mean ratio of bread price to milk price?– Ratio r1 = 1/3; Ratio r2 = 1/2
– Arithmetic mean ratio is r2 = (1/3 + 1/2) / 2 = 5/12 = 0.4167.
• But r1 1/r2. What’s wrong?
• Conclusion: Arithmetic mean is no good for ratios
3loafperpriceBread
quartperpriceMilk
2loafperpriceBread
quartperpriceMilk

Using Geometric Mean• Geometric mean of the milk/bread ratios:
• Geometric mean of the bread/milk ratios:
1 (3 2) 6 2.4495r
2 (1/ 3) (1/ 2) 1/ 6 0.4082r
21
10.4082r
r

Moments and distribution• The moment (mr)
• The central moment (r)
• The first moment is the arithmetic mean• The second central moment
– is the population variance when N is equal to population size (typically assumed to be infinitely large)
– is the sample variance when N = n-1 where n is sample size
• Standardized moment (r) = the moment of the standardized x.– 1 = 0– 2 = 1– 3 is population skewness; the sample skewness with
sample size (n) is
1
( )N
ri
ir
X X
N
1 2 1...
Nrir r r
N ir
XX X X
mN N
r
i ri r
r r r
X XX X
N N
3( 1)
2
n n
n
2 = u2/n

Skewness
-6 -4 -2 0 2 4 6
Right-Skewed (+) Left-Skewed (-)

KurtosisLeptokurtic(Kurtosis < 0)
Normally distributed
Platykurtic (Kurtosis > 0)
-6 -4 -2 0 2 4 6
44 2
1
1
( 1) 3( 1)3
( 1)( 2)( 3) ( 2)( 3)
n
ini i
i
zx xn n n
n n n s n n n

Empirical frequency distributions• Chest Number of Men
(inches)33 334 1835 8136 18537 42038 74939 107340 107941 93442 65843 37044 9245 5046 2147 448 1
• Marks Number of (mid-point) candidates
400 24750 741250 381750 212250 112750 83250 113750 54250 24750 15250 35750 16250 06750 07250 07750 1

data chest;input chest number;cards;33 334 1835 8136 18537 42038 74939 107340 107941 93442 65843 37044 9245 5046 2147 448 1;proc univariate normal plot; freq number; var chest;run;
Univariate Procedure
Variable=CHEST
N 5738 Sum Wgts 5738Mean 39.83182 Sum 228555Std Dev 2.049616 Variance 4.200925Skewness 0.03333 Kurtosis 0.06109USS 9127863 CSS 24100.71CV 5.145674 Std Mean 0.027058T:Mean=0 1472.102 Pr>|T| 0.0001Num ^= 0 5738 Num > 0 5738M(Sign) 2869 Pr>=|M| 0.0001Sgn Rank 8232596 Pr>=|S| 0.0001D:Normal 0.098317 Pr>D <.01
USS = Sum(xi2)
CSS = Sum(xi – MeanX)2
SAS Program and Output

data Grade;input marks number;cards;400 24 750 74 1250 38 1750 21 2250 11 2750 8 3250 11 3750 5 4250 2 4750 1 5250 3 5750 1 6250 0 6750 0 7250 0 7750 1;proc univariate normal plot; freq number; var marks;run;
Univariate Procedure
Variable= marks
N 200 Sum Wgts 200Mean 1465.5 Sum 293100Std Dev 1179.392 Variance 1390965Skewness 2.031081 Kurtosis 5.180086USS 7.0634E8 CSS 2.768E8CV 80.47708 Std Mean 83.39558T:Mean=0 17.57287 Pr>|T| 0.0001Num ^= 0 200 Num > 0 200M(Sign) 100 Pr>=|M| 0.0001Sgn Rank 10050 Pr>=|S| 0.0001W:Normal 0.767621 Pr<W 0.0001
SAS Program and Output

SAS Graph
DATA; DO X=-5 TO 5 BY 0.25; DO Y=-5 TO 5 BY 0.25; DO Z=SIN(SQRT(X*X+Y*Y)); OUTPUT;
END;END;
END;PROC G3D; PLOT Y*X=Z/CAXIS=BLACK CTEXT=BLACK; TITLE 'Hat plot'; FOOTNOTE 'Fig. 1, Xia';RUN;