1 recpu:a parallel and pipelined architecture for regular expression matching department of computer...
Post on 20-Dec-2015
218 views
TRANSCRIPT

1
ReCPU:a Parallel and Pipelined Architecture for Regular Expression M
atching
Department of Computer Science and Information Engineering National Cheng Kung University, Taiwan R.O.C.
Authors: Marco Paolieri, Ivano Bonesana, Marco D. Santambrogio
Publisher: Very Large Scale Integration, 2007. VLSI - SoC 2007. IFIP International
Present: Yu-Tso Chen
Date: April, 29, 2008

2
Outline
1. Introduction 2. Proposed Approach 3. Architecture Description 4. Performance Evaluation

3
Introduction
Some approaches require a new generation of the HDL whenever a new RE needs to be processed.
We require to update the instruction memory with the new RE.

4
Introduction
Advantages :• On average it compares more than one chara
cter per clock cycle• As well as it requires less memory occupation
• Easily possible to change the pattern at run-time just updating the content of the instruction memory.• Without modifying the underlying hardware

5
Proposed Approach
Some example to clarify mapping of complex RE operators into the programming language.• * and + correspond to loop in instructions
• The loop terminates whenever the pattern matching fails.
• Nested parentheses [e.g. (((ab)*(c|d))|(abc)) ]
• We mapped this to the function call
• Open parenthesis – all the control path internal registers is saved in a stack
• Close parenthesis – found a stack-pop operation and the validity of the RE is checked combining the current operator

6
Instruction Structure

7
Instruction Structure
MSB – the use of a parenthesis (i.e. a function call)
Internal operands – (i.e. and or or used to match the characters present in the current instruction)
External operands – loops and close parenthesis (i.e. a return after a function call)
A RE is completely matched whenever a NOP instruction is fetched from the instruction memory.

8
A Complete List of Opcodes Don’t care values are expressed as “-”

9
Example
(( (ab)*(c|d))| (abc) )
1 -- --- 1 -- --- 1 -- --- a 0 01 --- b 0 -- 001 1 -- --- c 0 10 --- d 0 -- 1– 0 -- 011 1 -- --- a 0 01 --- b 0 01 --- c 0 -- 1-- 0 -- 1-- 0 00 000
1 -- --- 1 -- --- 1 -- --- 0 01 --- ab 0 -- 001 1 -- --- 0 10 --- cd 0 -- 1– 0 -- 011 1 -- --- 0 01 --- abc 0 -- 1-- 0 -- 1-- 0 00 000

10
Data Path
In order to process more than one character per clock cycle, we applied some tech. to increase the parallelism of ReCPU :• Pipelining
• Data and instructions prefetching
• Parallel memory ports

11
Pipeline
Two stages Fetch/Decode and Execute The control path spends one cycle to pre
charge the pipeline and then it starts performing the prefetching mechanism.
In each stage we introduced duplicated buffers to avoid stalls.• One buffer is used to prefetch the next instruc
tion.
• The other is used as backup of the first one.

12
First Stage – Fetch/Decode
Just one set of pipeline register values are forwarded to the Execution stage.
Multiplexer is controlled by the control unit
The decode process extracts from the instruction• Reference string
• Length – (indicated as valid_ref)• Because the number of char. composing the sub-R
E can be lower than the width of the cluster.
• operators

13
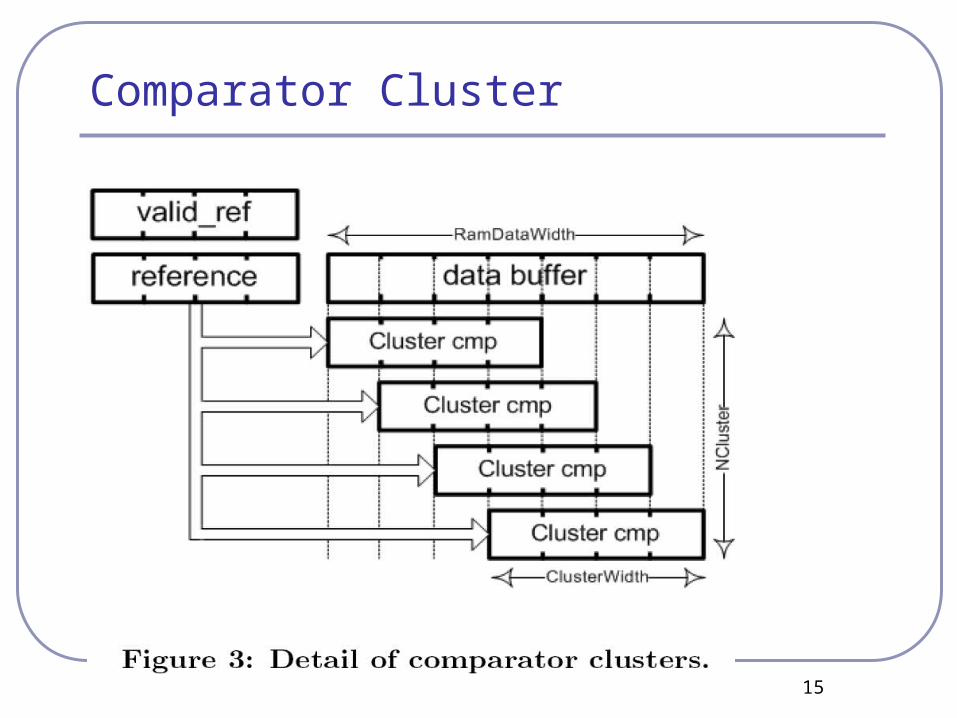
Second Stage - Execute
It is a fully combinatorial circuit. The reference coming from the previous
stage is compared with the data read from the RAM and previously stored in one of the two parallel buffers.
Each cluster is shifter of one character from the previous in order to cover a wider set of data in a single clock cycle.

14
Block Diagram of ReCPU (4 Clusters)
15
Comparator Cluster

16
Comparator Cluster

17
Control Path
The execution of an RE requires two input address : RE start address (instruction memory) and text start address (data memory)
Two execution cases can occur :• An RE does not match the text, the FSM loop
s in the EX_NM state.
• As soon as a match is detected the FSM goes into the EX_M state.

18
Control Path (cont.)
If no match is detected the data memory address is incremented by the number of clusters.
When an RE starts matching, the FSM goes into EX_M state and the ReCPU switches to the matching mode by using a single cluster comparator to perform pattern matching task on the data memory.

19
Control Path (cont.)
When the FSM is in EX_M state and one of the instructions composing the RE fails.• The whole process has to be restarted from
the RE started to match.
Whenever a NOP instruction is detected the RE is considered complete.

20
FSM of The Control Path
EX_NM
EX_MNOP
FD

21
Experimental Results
Setting Ncluster and ClusterWidth equal to 4

22
Experimental Results

23
Thanks for you attention

24
Example
(( (ab)*(c|d))| (abc) )
1 -- --- 1 -- --- 1 -- --- a 0 01 --- b 0 -- 001 1 -- --- c 0 10 --- d 0 -- 1– 0 -- 011 1 -- --- a 0 01 --- b 0 01 --- c 0 -- 1-- 0 -- 1-- 0 00 000
1 -- --- 1 -- --- 1 -- --- 0 01 --- ab 0 -- 001 1 -- --- 0 10 --- cd 0 -- 1– 0 -- 011 1 -- --- 0 01 --- abc 0 -- 1-- 0 -- 1-- 0 00 000

25
Experimental Results
Whenever the input text is not matching the current instruction and the opcode represents :• ‧operator
• │operator• Tcp =>critical path delay
• NCluster => Number of clusters
• ClusterWidth => Width of the clusters

26
Experimental Results (cont.)
Input text is matching the current instruction then the performance depends on the width of one cluster.
Achievable performance• Bx represents the number of bits processed in
one second
• Tx represents one of the quantities resulting