© 2007 ibm corporation gpfs, glamour and panache towards a global scalable file service renu tewari...
Post on 21-Dec-2015
215 views
TRANSCRIPT

© 2007 IBM Corporation
GPFS, Glamour and PanacheTowards a Global Scalable File Service
Renu Tewari
IBM Almaden

2 © 2006 IBM Corporation
IBM General Parallel File System
World-wide Sharing of Data
Example: grid computing workflows– Massive amounts of data gathered at
remote locations– Distributed compute resources process
input data and store their results– Results are analyzed or visualized by
people at many locations
Inge
stCompute
Visualize

3 © 2006 IBM Corporation
IBM General Parallel File System
What is the function of a Filesystem
Namespace Consistency Security and Access control Fault Tolerance Performance

4 © 2006 IBM Corporation
IBM General Parallel File System
How do we get to a Scalable Global FS
Scale Up– Enterprise class storage systems– Large parallel machines
Scale Out– Internet companies and “cloud computing” are clearly embracing scale-out HW
architectures– Large clusters of commodity servers connected by high-bandwidth Ethernet– For many applications, scale-out has proven to be cheaper than scale-up – Question of network bandwidth compared to disk bandwidth
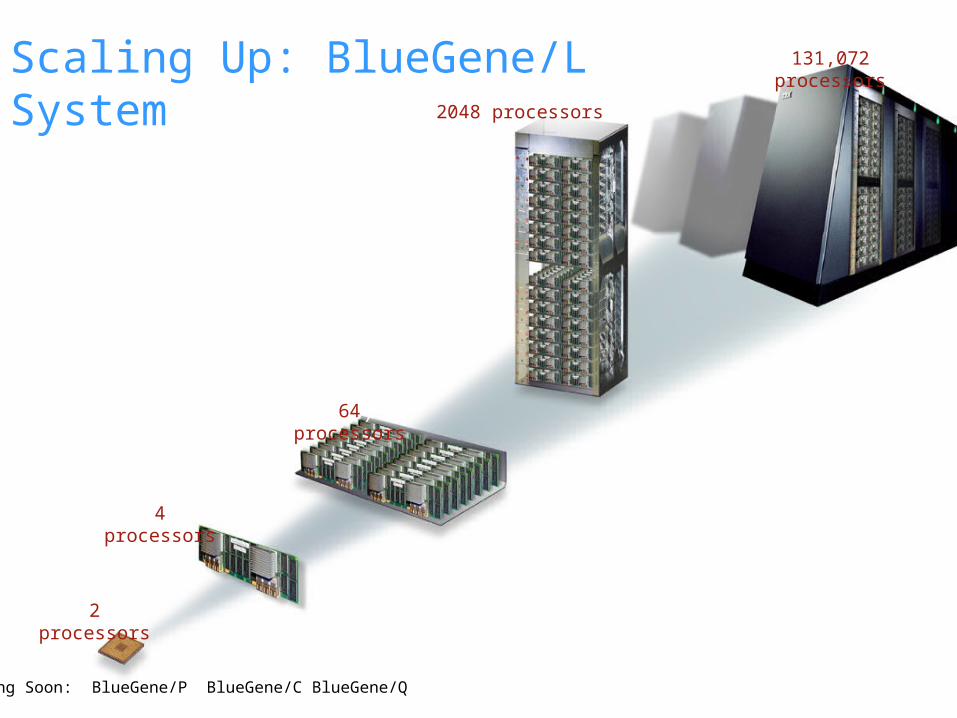
© 2007 IBM Corporation5.6 GF/s
4 MB
2 processors
2 chips
11.2 GF/s1.0 GB
16 compute cards (16 compute, 0-2 IO cards)
180 GF/s16 GB
32 Node Cards
5.6 TF/s512 GB
20 KWatts1 m2 footprint
64 Racks, 64x32x32
360 TF/s32 TB
1.3M Watts
Rack
System
Node Card
Compute Card
Chip
4 processors
64 processors
131,072 processors
2048 processors
Scaling Up: BlueGene/L System
Coming Soon: BlueGene/P BlueGene/C BlueGene/Q

6 © 2006 IBM Corporation
IBM General Parallel File System
Technology keeps growing …
Technology blurs distinction among SAN, LAN, and WAN– “Why can’t I use whatever fabric I have for storage?”
– “Why do I need to separate fabrics for storage and communication?”
– “Why can’t I share files across my entire SAN like I can with Ethernet?”
– “Why can’t I access storage over long distances?”

7 © 2006 IBM Corporation
IBM General Parallel File System
Outline
GPFS – Scaling the “local” filesystem for a large data store
pNFS– Scaling the pipe for remote data access
WAN Caching– Bringing data closer to where it is consumed
Federated filesystems – Separating the physical location from the logical namespace

8 © 2006 IBM Corporation
IBM General Parallel File System
GPFS GPFS
9 © 2006 IBM Corporation
IBM General Parallel File System
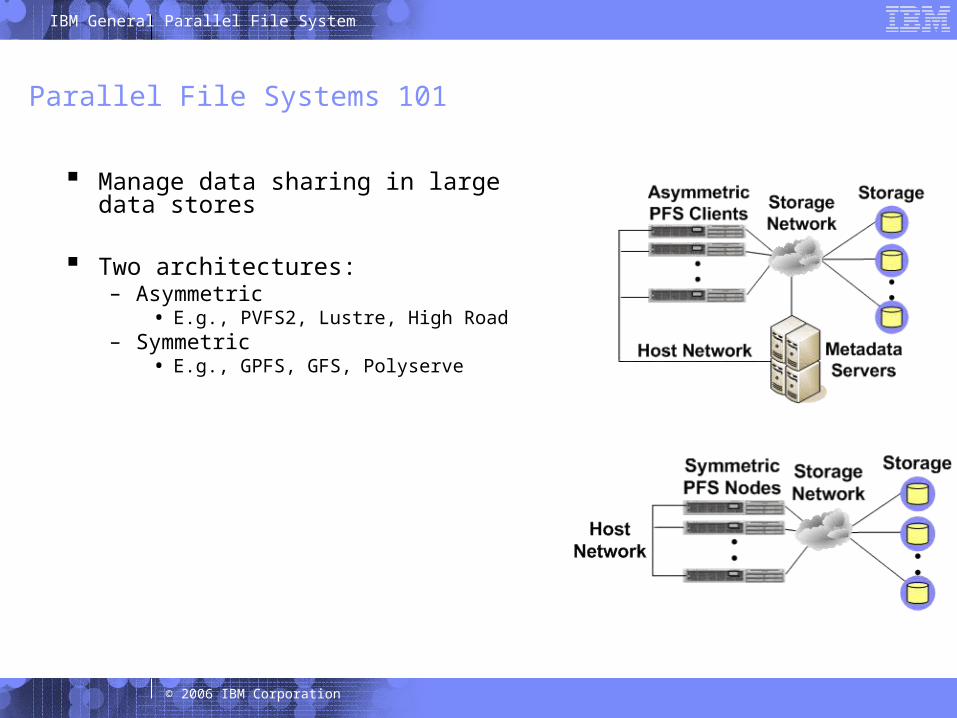
Parallel File Systems 101
Manage data sharing in large data stores
Two architectures:– Asymmetric
• E.g., PVFS2, Lustre, High Road– Symmetric
• E.g., GPFS, GFS, Polyserve
10 © 2006 IBM Corporation
IBM General Parallel File System
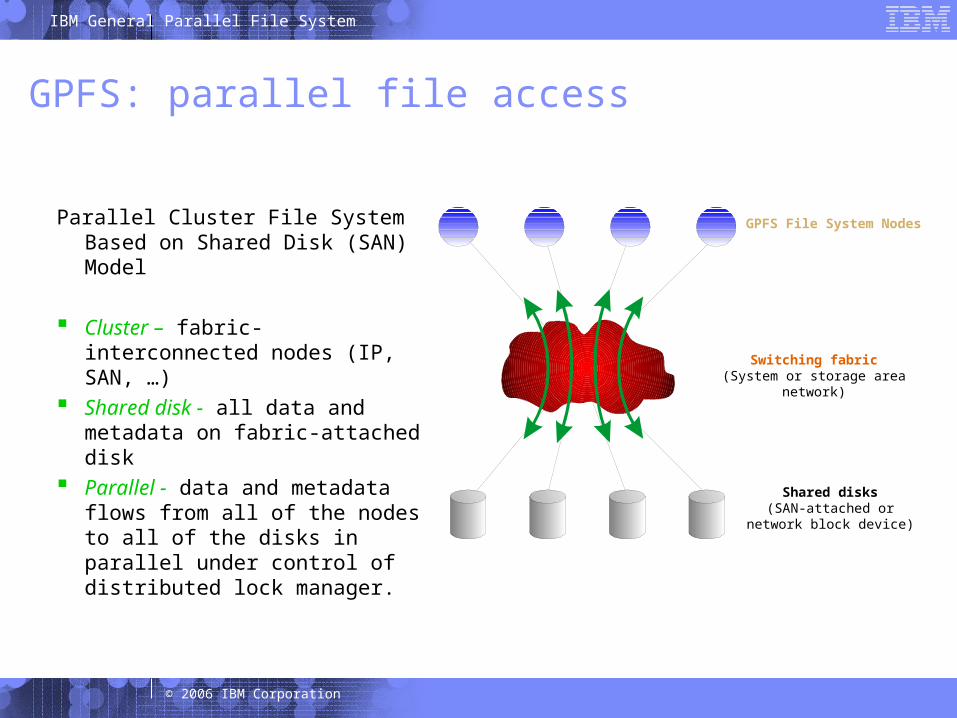
GPFS: parallel file access
Parallel Cluster File System Based on Shared Disk (SAN) Model
Cluster – fabric-interconnected nodes (IP, SAN, …)
Shared disk - all data and metadata on fabric-attached disk
Parallel - data and metadata flows from all of the nodes to all of the disks in parallel under control of distributed lock manager.
GPFS File System Nodes
Switching fabric(System or storage area
network)
Shared disks(SAN-attached or
network block device)

11 © 2006 IBM Corporation
IBM General Parallel File System
What GPFS is NOT
Not a client-server file system like NFS, DFS, or AFS: no single-server bottleneck, no protocol overhead for data transfer
Not like some SAN file systems (e.g. Veritas, CXFS): no distinct metadata server (which is a potential bottleneck)

12 © 2006 IBM Corporation
IBM General Parallel File System
GPFS FeaturesHigh capacity:
– Large number of disks in a single FSHigh BW access to single file
– Large block size, full-stride I/O to RAID– Wide striping – one file over all disks– Small files spread uniformly– Multiple nodes read/write in parallel
High availability– Nodes: log recovery restores
consistency after a node failure– Data: RAID or internal replication– On-line management (add/remove
disks or nodes without un-mounting)– Rolling software upgrade
Single-system image, standard POSIX interface– Distributed locking for read/write semantics
Advanced file system features– Memory mapped files– Direct I/O– Replication– Snapshots– Quotas– Extended attributes

13 © 2006 IBM Corporation
IBM General Parallel File System
Distributed Locking
GPFS architecture: – Clients share data data and metadata
– ... synchronized by means of distributed locking
Distributed locking essential to …– synchronize file system operations for POSIX semantics,
– synchronize updates to file system metadata on disk to prevent corruption,
– maintain cache consistency of data and metadata cached on different nodes.
Synchronization requires communication … – Problem: sending a lock message for every operation will not
scale.
– Solution: Token-based lock manager allows“lock caching”.

14 © 2006 IBM Corporation
IBM General Parallel File System
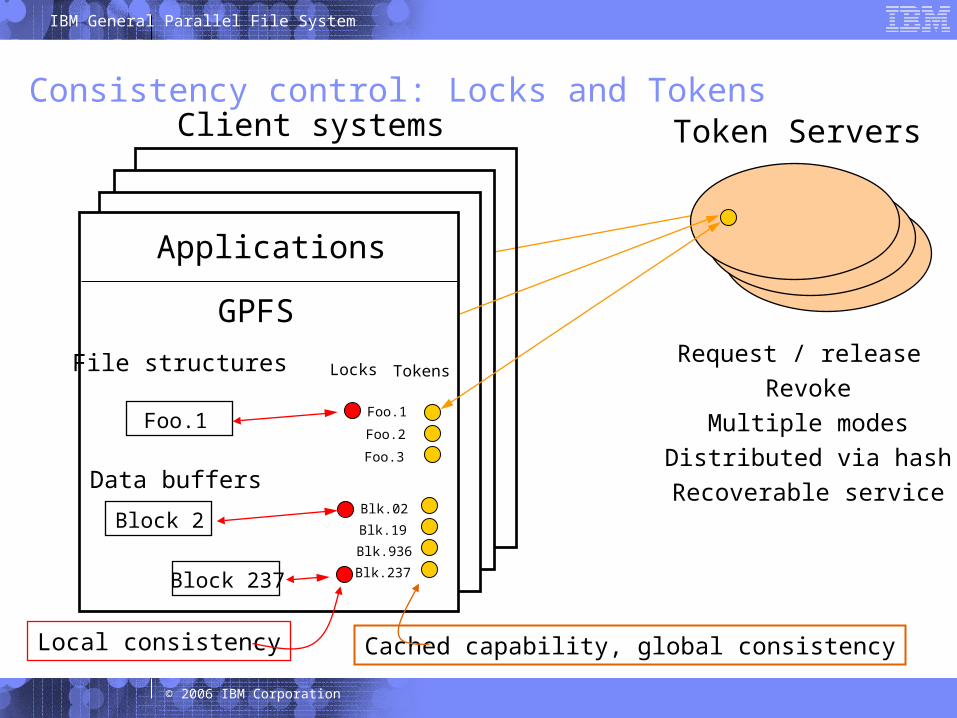
Token-based Lock Manager
Token server grants tokens. Token represents right to
read, cache, and/or updatea particular piece of dataor metadata.
Single message to tokenserver allows repeatedaccess to the same object.
Conflicting operation onanother node will revokethe token.
Force-on-steal: dirty data & metadata flushed to disk when token is stolen.
Numerous optimizations: – Large byte ranges– Lookup/open
15 © 2006 IBM Corporation
IBM General Parallel File System
Consistency control: Locks and TokensToken Servers
Applications
GPFS
TokensLocks
Foo.1
Foo.2
Foo.3
Foo.1
Blk.02
Blk.19
Blk.936
Blk.237
Data buffers
File structures
Block 237
Block 2
Local consistency Cached capability, global consistency
Client systems
Request / releaseRevoke
Multiple modesDistributed via hashRecoverable service

16 © 2006 IBM Corporation
IBM General Parallel File System
Distributed locking: optimizations
Byte range locking– Opportunistic locking: small “required” range and large “requested” range– Minimizes lock traffic for piecewise sharing
Metadata token optimizations– During lookup, client speculatively acquires tokens to open the file– Inode reuse: node deleting a file caches its inode for subsequent create– Directory scans: readdir() “prefetches” inode tokens for subsequent stat()– “metanode” dynamically assigned to handle metadata updates when
write-sharing occurs Block allocation
– Segmented allocation map allows each node to allocate space on all disks for data striping
New optimizations for multi-cluster scaling– Token manager split across multiple nodes (hashed tokens)– Metanode dynamically migrated to minimize communication latency

17 © 2006 IBM Corporation
IBM General Parallel File System
Performance
130+ GB/s parallel read/write on achieved on ASCII Purple 12 GB/s parallel read/8 GB/s write on 40-node IA64 Linux cluster
with 120 TB SAN-attached FAStT 600 7.8GB/s streaming read, 7.3GB/s write to single file on p690
– 15.8 GB/s read/14.5 GB/s write aggregate to multiple files
1000+ files/sec/node (3051 files/sec on 3 Linux nodes, 50 drives on one FAStT controller (256M files in 24 hours 26 mins).
18 © 2006 IBM Corporation
IBM General Parallel File System
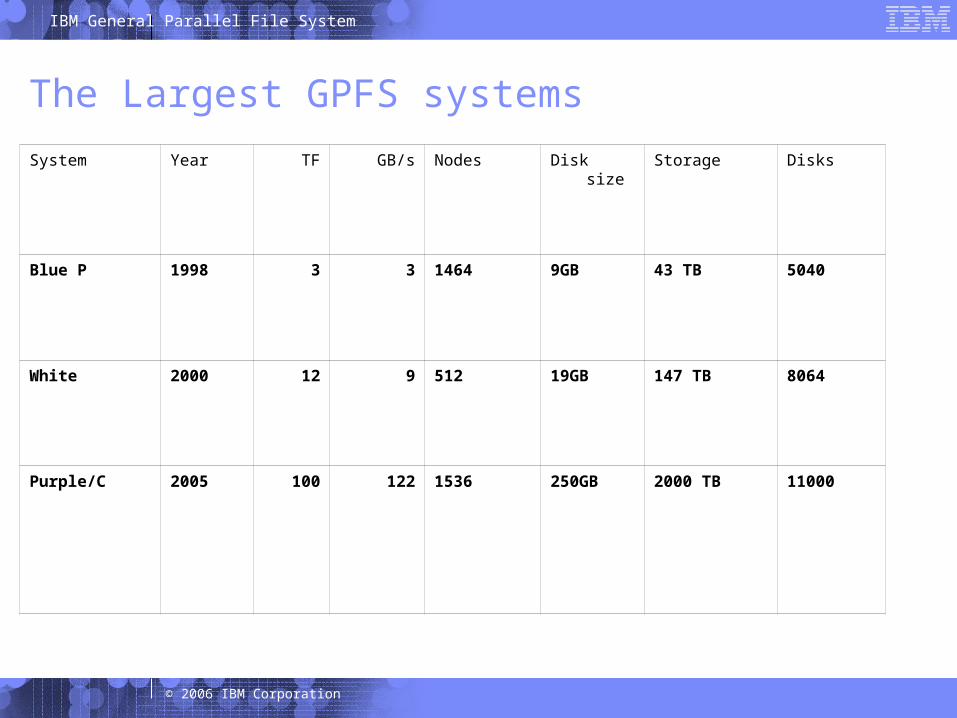
The Largest GPFS systems
System Year TF GB/s Nodes Disk size Storage Disks
Blue P 1998 3 3 1464 9GB 43 TB 5040
White 2000 12 9 512 19GB 147 TB 8064
Purple/C 2005 100 122 1536 250GB 2000 TB 11000
19 © 2006 IBM Corporation
IBM General Parallel File System
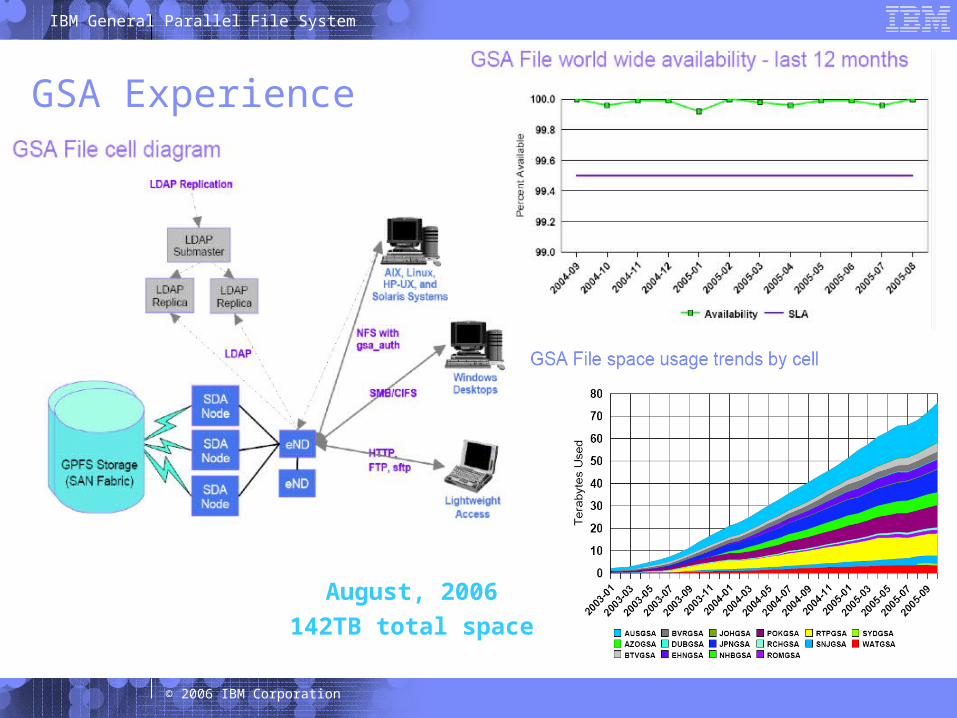
GSA Experience
August, 2006142TB total space

20 © 2006 IBM Corporation
IBM General Parallel File System
GPFS on ASC Purple/C Supercomputer
1536-node, 100 TF pSeries cluster at Lawrence Livermore National Laboratory 2 PB GPFS file system (one mount point) 500 RAID controller pairs, 11000 disk drives 130 GB/s parallel I/O measured to a single file (135GB/s to multiple files)

21 © 2006 IBM Corporation
IBM General Parallel File System
GPFS Directions
Petascale computing work (HPCS)– File systems to a trillion files– Space to exabytes– Clusters to 50K nodes– Improved robustness with increasing numbers of components
Data Integrity– Fixing more than 2 failures– Covering the entire data path (disks, controllers, interconnect)
Storage management– Extensions for content managers, intelligent data store facilities
File Serving– pNFS (Parallel NFSv4)– Metadata intensive workload improvements– Large cache exploitation
Distributed file systems– Disk-based caching at remote sites– Independent, disconnected operation (even writes)
• Multi-update reconciliation– Multi-site replication for availability
Automated operations improvements– Improved installation process– Automatic setting of most performance control knobs– GUI for management overview
22 © 2006 IBM Corporation
IBM General Parallel File System
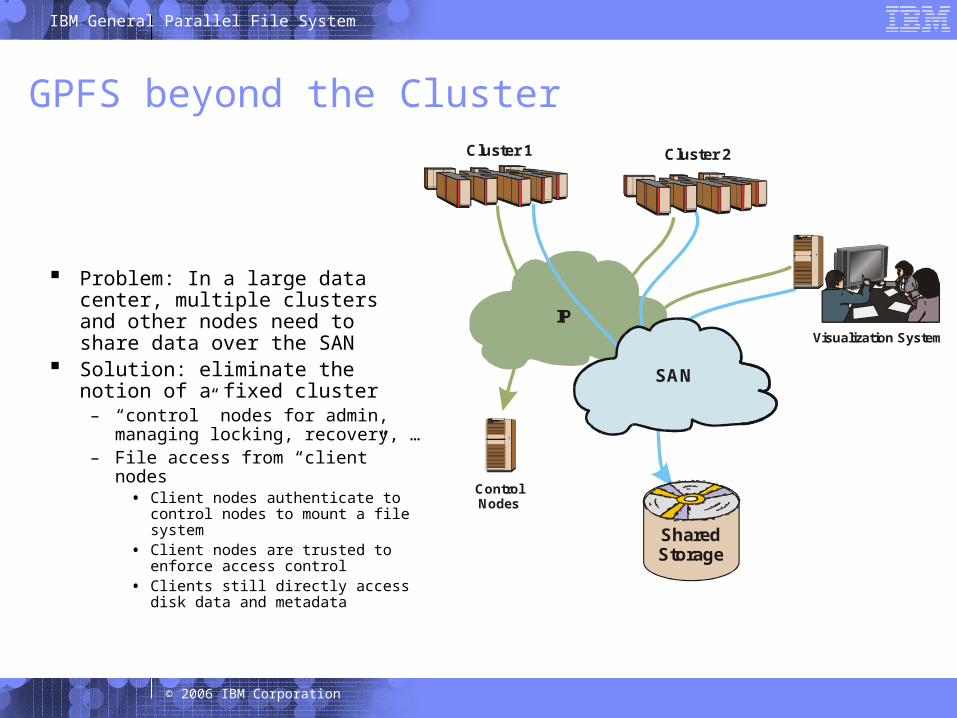
GPFS beyond the Cluster
Problem: In a large data center, multiple clusters and other nodes need to share data over the SAN
Solution: eliminate the notion of a fixed cluster
– “control” nodes for admin, managing locking, recovery, …
– File access from “client” nodes• Client nodes authenticate to control
nodes to mount a file system• Client nodes are trusted to enforce
access control• Clients still directly access disk data
and metadata
Cluster 1 Cluster 2
Visualization System
SharedStorage
SAN
IP
ControlNodes

23 © 2006 IBM Corporation
IBM General Parallel File System
Multi-cluster GPFS and Grid Storage
Multi-cluster supported in GPFS – Nodes of one cluster mount file system(s) of another cluster– Tight consistency identical to that of a single cluster– User ID’s mapped across clusters
• Server and remote client clusters can have different userid spaces• File userids on disk may not match credentials on remote cluster• Pluggable infrastructure allows userids to be mapped across clusters
Multi-cluster works within a site or across a WAN– Lawrence Berkeley Labs (NERSC)
• multiple supercomputer clusters share large GPFS file systems
– DEISA (European computing grid)• RZG, CINECA, IDRIS, CSC, CSCS, UPC, IBM• pSeries and other clusters interconnected with multi-gigabit WAN• Multi-cluster GPFS in “friendly-user” production 4/2005
– Teragrid• SDSC, NCSA, ANL, PSC, CalTech, IU, UT, …..• Sites linked via 30 Gb/sec dedicated WAN• 500TB GPFS file system at SDSC shared across sites, 1500 nodes• Multi-cluster GPFS in production 10/2005
24 © 2006 IBM Corporation
IBM General Parallel File System
Remote Data Access Problem:Gap Between Users and Parallel File Systems
Q: Use an existing parallel file system?A: Not likely
Q: Build “yet another” parallel file system?A: See above
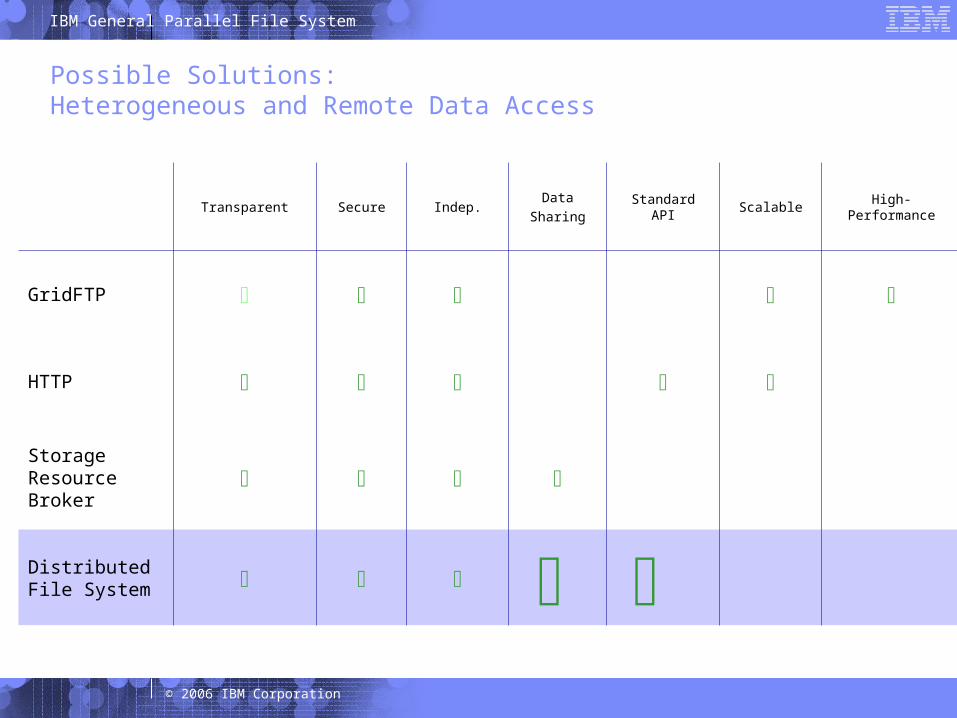
25 © 2006 IBM Corporation
IBM General Parallel File System
Possible Solutions:Heterogeneous and Remote Data Access
Transparent Secure Indep.Data
SharingStandard API Scalable High-Performance
GridFTP
HTTP
Storage Resource Broker
Distributed File System

26 © 2006 IBM Corporation
IBM General Parallel File System
pNFS, NFSv4.1pNFS, NFSv4.1

27 © 2006 IBM Corporation
IBM General Parallel File System
Why not vanilla NFS NFS is a frequently used for remote data access
– Pros• Simple, reliable, easy to manage• Practically every OS comes with a free NFS client• Lots of vendors make NFS servers
– Cons• NFS “loose consistency” not suitable for some applications• Capacity and bandwidth don’t scale• Attempts to make NFS scale make it unreliable and difficult to manage
– Single-server bottleneck (capacity and throughput limitations)– To overcome bottleneck, user has to explicitly partition namespace across servers
» Partitioning and re-partitioning is tedious and hard to get right
Various attempts to scale conventional NFS, each with limitations– Clustered NFS servers (NFS on top of a cluster file system)
• Each server handles all data, but each client only mounts from one server

28 © 2006 IBM Corporation
IBM General Parallel File System
NFSv4 Optimized for WAN
Compound ops Redirection support Delegations
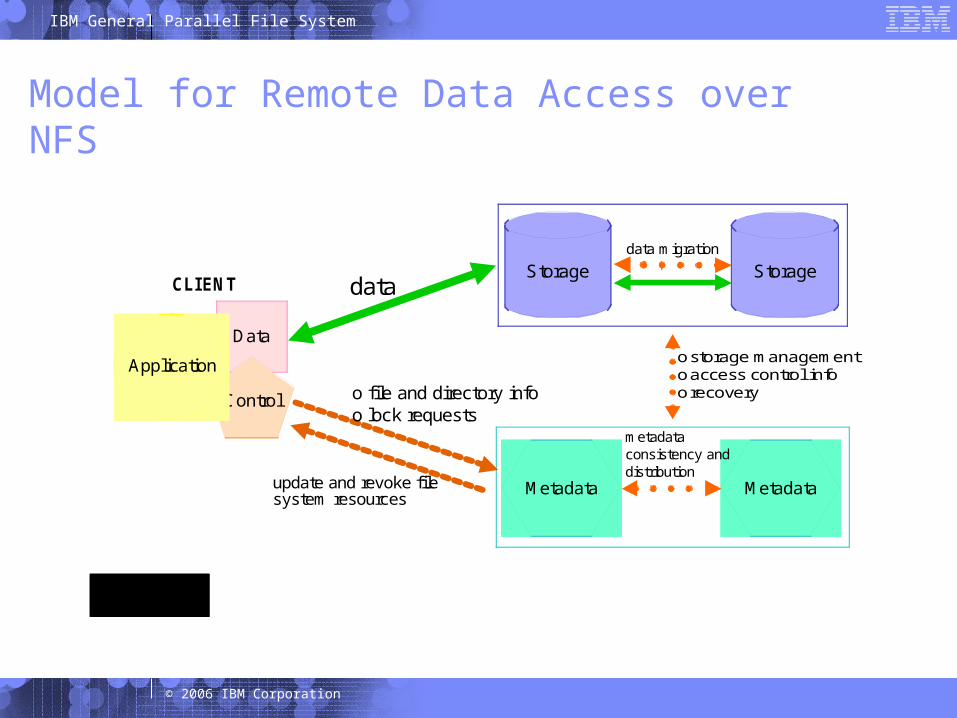
29 © 2006 IBM Corporation
IBM General Parallel File System
Model for Remote Data Access over NFS
ostorage managementoaccess control infoo recovery
datacontrol
CLIENT
Data
Control
Application
Metadata Metadata
metadata consistency and distribution
update and revoke file system resources
o file and directory infoo lock requests
data migration
Storage Storagedata

30 © 2006 IBM Corporation
IBM General Parallel File System
Parallel NFS (pNFS) – extending NFS to HPC
Include pNFS in NFSv4.1 to support parallel access– Minor version extension of NFSv4 protocol
– NFSv4 client mounts from pNFS-enabled NFSv4 metadata servermetadata server• Non-pNFS-enabled client gets data directly from metadata server
• pNFS-enabled client is redirected to (multiple) data servers that store the file
Benefits:– Individual high-performance client can benefit from striping across multiple
data servers, e.g. 10g client with 1g data servers (or servers with few disks)
– Multiple clients can use data servers like a parallel file system• Still NFS semantics, vs. most parallel file systems which support Posix
Three variants of protocol– File: data servers are NFSv4 file servers
– Object: data servers are ANSI T10 OSD servers
– Block: data servers are block devices (Fibrechannel FCP, iSCSI)
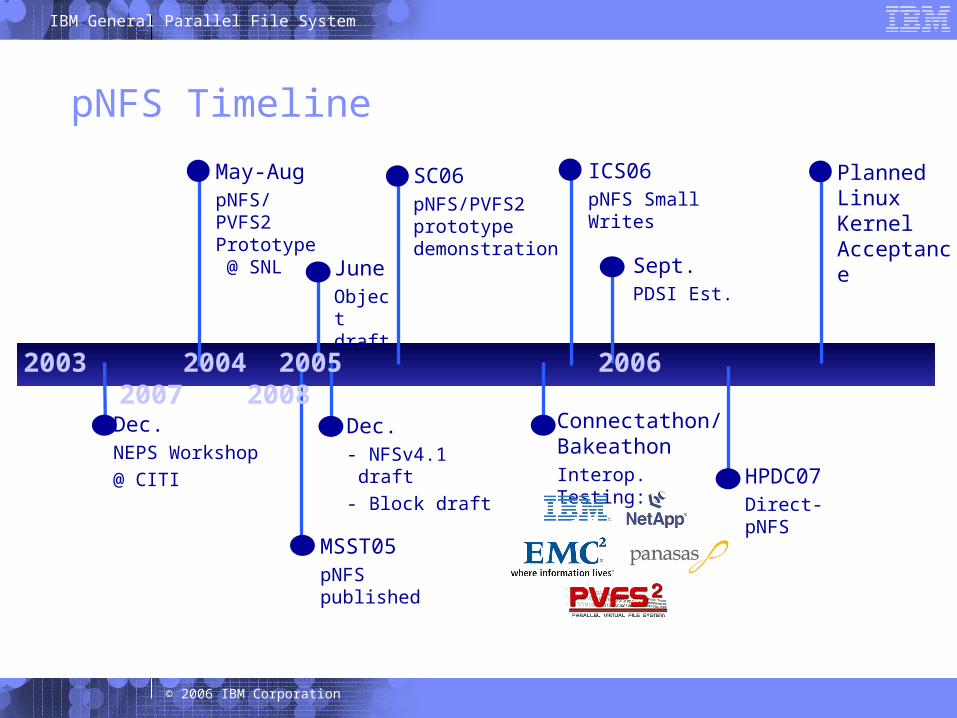
31 © 2006 IBM Corporation
IBM General Parallel File System
pNFS Timeline
Dec.NEPS Workshop@ CITI
May-AugpNFS/PVFS2 Prototype @ SNL
MSST05pNFS published
JuneObject draft
Dec.- NFSv4.1 draft
- Block draft
ICS06pNFS Small Writes
Connectathon/ BakeathonInterop. Testing:
Sept.PDSI Est.
HPDC07Direct-pNFS
Planned Linux Kernel Acceptance
2003 2004 2005 2006 2007 2008
SC06pNFS/PVFS2 prototype demonstration

32 © 2006 IBM Corporation
IBM General Parallel File System
pNFS protocol extensions to NFSv4.1 The basic pNFS architecture:
– Clients call metadata server to create/delete/open/close– Clients get layout (map of data) from metadata server– Layout directs clients to data servers for read/write operations
pNFS protocol operations:– GETDEVICELIST,
• retrieve device list
– GETDEVICEINFO – • retrieve information for a single device
• get data server identities and attributes– LAYOUTGET(file_handle, type, byte_range) – asks server for “layout” that tells client how to map file byte
ranges to data servers• Retrieves data layout information• Layout valid until returned or recalled by server
– LAYOUTRETURN(file_handle, byte_range) – tells server that client is no longer accessing byte range; server can release state
– LAYOUTCOMMIT(file_handle, byte_range, attributes, layout) – tells server to update metadata to make data visible to other clients
• update eof and block status
– CB_LAYOUTRECALL – server tells client to stop using a layout– CB_RECALLABLE_OBJ_AVAIL – tells client that delegation is now available for a file for which it was not
previously available
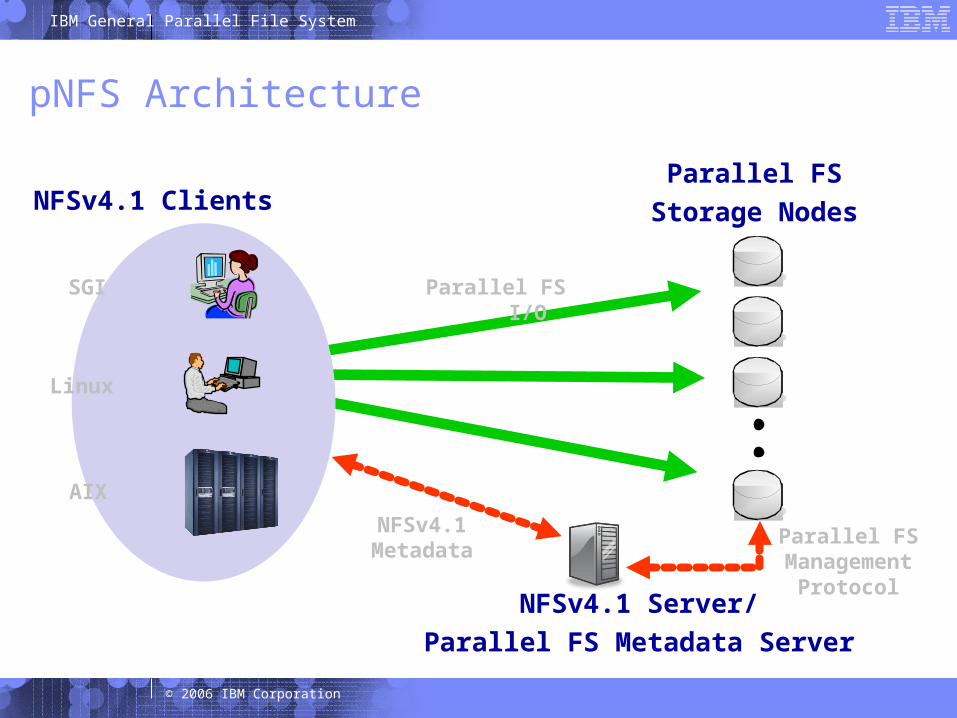
33 © 2006 IBM Corporation
IBM General Parallel File System
pNFS Architecture
NFSv4.1 Server/Parallel FS Metadata Server
SGI
Linux
AIX
Parallel FS I/O
NFSv4.1Metadata
Parallel FSStorage NodesNFSv4.1 Clients
Parallel FSManagementProtocol
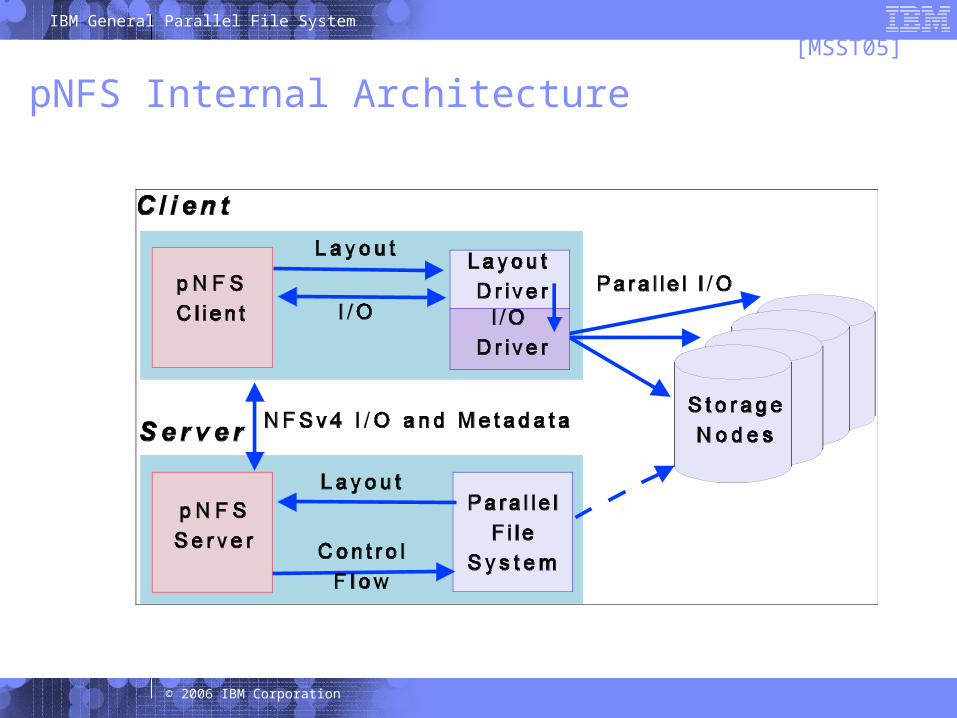
34 © 2006 IBM Corporation
IBM General Parallel File System
pNFS Internal Architecture[MSST05]

35 © 2006 IBM Corporation
IBM General Parallel File System
pNFS Discussion
Heterogeneity – High layout driver development cost– Reduce costs with standard storage protocols
Transparency– File system semantics
• Mix of NFSv4 and underlying file system
• E.g., pNFS/PVFS2 prototype caches only metadata
Security– Storage protocol dependent– Restrict WAN capability
Validation of opaque layout design– Negligible layout retrieval overhead– Maintains file system independence
• pNFS client utilize multiple storage protocols simultaneously • Underlying file system must manage layout information
Layout driver enables scalability and performance– Avoid indirection penalty and single server bottleneck– Escape NFSv4 block size restrictions

36 © 2006 IBM Corporation
IBM General Parallel File System
pNFS Small Write Performance
Scientific I/O workloads– 90% of requests transfer 10% of data– Gap between small and large I/O requests
File system characteristics– Distributed file systems
• Asynchronous client requests• Client write back cache• Server write gathering
– Parallel file systems• Large transfer buffers limits asynchrony• Write-through or no cache
Use mixture of distributed and parallel storage protocols– Increase overall write performance
[ICS06]
37 © 2006 IBM Corporation
IBM General Parallel File System
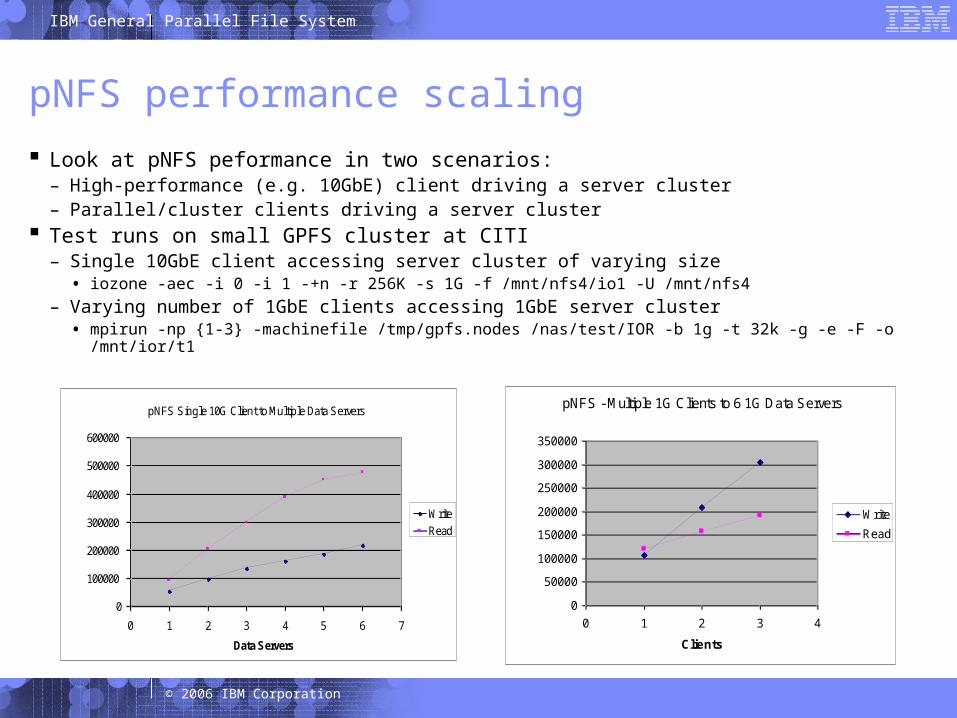
pNFS performance scaling
Look at pNFS peformance in two scenarios:– High-performance (e.g. 10GbE) client driving a server cluster– Parallel/cluster clients driving a server cluster
Test runs on small GPFS cluster at CITI– Single 10GbE client accessing server cluster of varying size
• iozone -aec -i 0 -i 1 -+n -r 256K -s 1G -f /mnt/nfs4/io1 -U /mnt/nfs4
– Varying number of 1GbE clients accessing 1GbE server cluster• mpirun -np {1-3} -machinefile /tmp/gpfs.nodes /nas/test/IOR -b 1g -t 32k -g -e -F -o /mnt/ior/t1
pNFS Single 10G Client to Multiple Data Servers
0
100000
200000
300000
400000
500000
600000
0 1 2 3 4 5 6 7
Data Servers
KB/s
Write
Read
pNFS - Multiple 1G Clients to 6 1G Data Servers
0
50000
100000
150000
200000
250000
300000
350000
0 1 2 3 4
Clients
KB/s
Write
Read

38 © 2006 IBM Corporation
IBM General Parallel File System
Accessing Remote Data: Approaches
Admin controlled Replication– Requires grouping data apriori and then triggering replication– Replicas need to be kept in sync with master copy – Replica update done periodically or admin driven
Explicit file transfer, e.g., Grid FTP– Requires keeping track of multiple copies of the data– Requires planning ahead (all data must be copied in advance)– New data has to get migrated back
File access over the WAN, e.g., GPFS Multicluster over Teragrid– True shared file system– One copy of the data– Updates propagated and visible instantly– Requires high-bandwidth, low-latency WAN– Requires constant connection between sites, e.g., for the duration of a parallel job
39 © 2006 IBM Corporation
IBM General Parallel File System
WAN CachingWAN Caching

40 © 2006 IBM Corporation
IBM General Parallel File System
WAN Caching: The Wish List
Scalable cache for high performance applications Single namespace (not absolutely necessary but convenient) Files moved transparently upon access (or pre-staged, e.g. with “touch”)
– Files can be stored on disk at cache site for as long as they are needed
– Files automatically moved back as they age out of cache or are needed elsewhere
– Possible (and desirable) to support disconnected operation
Cache “browsable” by client– Local ‘ls’ should show the list of files as the remote
Cache consistent both locally across nodes and with remote system

41 © 2006 IBM Corporation
IBM General Parallel File System
Panache: Key Design Points
A clustered cache embedded in GPFS caches data from a remote cluster Applications
–Grid computing - allowing data to move transparently during grid workflows
–Facilitates content distribution for global enterprises
–“Follow-the-sun” engineering teams
Key features–Cluster-wide cache designed for scalability and performance
•Integrated with GPFS for consistent and concurrent data access from all nodes of the cluster
–No special WAN protocol or hardware •Uses soon to be industry standard pNFS (NFSv4.1) protocol for parallel access
•No additional hardware at both ends as required by WAFS vendors

42 © 2006 IBM Corporation
IBM General Parallel File System
Panache Architecture Completely transparent to GPFS clients and
applications– Application can run on local cache with
same view as if it was running on remote cluster
– Any client can browse the cache as a traditional filesystem
– Cache presents a POSIX compliant view of the cached data
– Cache data can be re-exported over NFS
pNFS for parallel data transfer over WAN
Cache consistency is “tunable” – NFSv4 file/dir delegations for across
the WAN consistency Supports disconnected operations
– Resync after reconnect with policy for conflict resolution
– Supports policy for pre-fetching and pre-populating the cache along with on-demand access
– Supports whole-file or partial file caching
Plan for P2P style sharing across caches
pNFS Data Servers
pNFS over WAN
pNFS
Clients
Remote cluster
Metadata Server
Application
Nodes
Local GPFS cache site

43 © 2006 IBM Corporation
IBM General Parallel File System
Federated Filesystems Federated Filesystems

44 © 2006 IBM Corporation
IBM General Parallel File System
Project Glamour
An architecture for filesystem virtualization– Decouple the file from the physical fileserver/filesystem
Unified “file-based” view of storage across an enterprise– Consolidate the “fragmented view” of heterogeneous independent
fileservers
– Could be distributed across multiple geographical locations
Simplify management– Single point of access for setting policies, control, capacity management

45 © 2006 IBM Corporation
IBM General Parallel File System
Approaches to Filesystem Virtualization
Layer-7 gateway/proxy appliance • In the data path can limit scalability
• Uses standard protocols (including NFSv3)
• Works with existing file servers and NAS appliances
• E.g., NeoPath, Acopia
Server redirection– Requests forwarded among backend servers using proprietary protocols
• Vendor lockin
• Does not work with existing/heterogeneous systems
• Can be optimized for performance
• E.g., Spinnaker, Panasas
Client redirection– Redirect clients to the server with required data
• Needs protocol support (CIFS/NFS v4 only)
• Does not work with v3 clients
• Works with standard v4, CIFS clients
• Works well for distributed clients and servers
• Can be very scalable
• E.g., MS-Dfs, Glamour, NuView

46 © 2006 IBM Corporation
IBM General Parallel File System
Glamour: Common Namespace exports local /home/alice as /users/home/alice
exports local /home/bob as /users/home/bob
export local /usr/local/glamor as /storage/proj/latest/glamor
ToolsToolsusersusers
SVNSVN homehome genericgeneric
storagestorage
projproj
backupbackup latestlatest
CMVCCMVC
WatsonAlmaden
//
src bin
Almaden
glamorglamor
Watson
src bin
glamorglamor
Watson
src tmp
alicealice
Haifa
talk papers
bobbob
Replicates: Almaden:/usr/local/glamor as/storage/proj/backup/glamor
Haifa

47 © 2006 IBM Corporation
IBM General Parallel File System
Architecture
Namespace DB
Admin Tools
(CLI,GUI, etc)
Client Interface
Data Server Interface
LDB
Command Central
LDB_LDAP
Glamour admin
Local glamour agent
Glamor-enabled NFSv4 server
Glamour Schema
NFSv3 Client
Namespace LDAP Server
Slapd (Open LDAP)
Glamor LDAP Plugin
NIS Map Schema RNFS Schema
autofsautofs
GPFS Client
RNFS
NFSv4 Server

48 © 2006 IBM Corporation
IBM General Parallel File System
Namespace Features Multi protocol support
– v3 ClientLdap option in /etc/auto.* with nismap schema
dn: cn=dir1,nisMapName=/foo,dc=company,dc=comcn:dir1nisMapEntry: -fstype=autofs ldap://server,nisMapName=/foo/dir1,dc=…objectclass:nisObject
– Linux v4 Server Ldap option in /etc/exports with rnfs schema
dn: cn=dir1,ou=locations,dc=company,dc=comcn:dir1fslocations: server1:/path/at/server1fslocations: server2:/path/at/server2referral: TRUEobjectclass:rnfs
– CIFS in progress Multi system support
– AIX, Linux, … Nested mounts
– Only supported for v4 currently– No cycles
Common Glamour schema – Convert to desired schema for v3 or v4 or GPFS clients– Understood by agent in a Glamour-enabled fileserver
Locations LDIF entry
dn: DmLocation=server:/path/at/server, ou=locations,dc=company,dc=comobjectclass: DmLocationDmLocation: server:/path/at/serverDmdir: /fileset11DmParent: /dir1DmNamespace: /DmSite: usDmNfsType: 3DmHost:DmDomain:DmPath:DmVersion:DmStatus:
Glamour Schema Fileset LDIF Entry
dn: DmDir=/dir1,DmNamespace=/, ou=locations,dc=company,dc=comobjectclass: DmDirDmDir: /fileset11DmParent: /dir1DmNamespace: /DmType: Leaf

49 © 2006 IBM Corporation
IBM General Parallel File System
Towards a Federated Filesystems Standard
IBM continuing the Glamour effort to incorporate NFSv4, NFSv3, CIFS, and even local file systems such as GPFS
Prototype on Linux as reference implementation
Collaboration with NetApp and the extended NFS community for an IETF standard on administering federated filesystems
50 © 2006 IBM Corporation
IBM General Parallel File System
Questionswww.almaden.ibm.com/StorageSystems/areas/filesys
tewarir at us ibm com