word/doc2vec for sentiment analysis michael czerny dc natural language processing 4/8/2015
TRANSCRIPT

Word/Doc2Vec for Sentiment Analysis
Michael Czerny DC Natural Language Processing
4/8/2015

Who am I?
• MSc Cosmology and Particle Physics• Data Scientist at L-3 Data Tactics• Interested in applying forefront research in NLP and ML
to industry problems• Email: [email protected]• @m0_z

Outline:1. What is sentiment analysis?2. Previous (i.e. pre-W/D2V) approaches to SA3. Word2Vec explained• How it can be used for SA• Example/App(?)
4. Doc2Vec explained• “ “
5. Conclusions

What is sentiment analysis?

What is sentiment analysis?In a nutshell: extracting attitudes toward something from
human language
=> Positive (?)
=> Negative (?)(Or something else entirely?)
SA aims to map qualitative data to a quantitative output(s)

What is sentiment analysis?
Easy (relatively) for humans1, hard for machines!
1mashable.com/2010/04/19/sentiment-analysis/
How do we convert human language to a machine-readable form?

Previous approaches to SA

Previous approaches to SA
Keyword lookup:• Assign sentiment score to words
(“hate”: -1, “love”: +1)• Aggregate scores of all words in
text• Overall + / - determines sentiment
http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#lexicon

Previous approaches to SADrawbacks:
• Need to label words• Can’t implicitly capture negation (“Not good” =
0 ??)• Ignores word context

Previous approaches to SASlap a classifier on it!
• One-hot encode text so that each word is a column (“bag of words”)
“John likes to watch movies. Mary likes movies too.” => [1 2 1 1 2 0 0 0 1 1]“John also likes to watch football games.” => [1 1 1 1 0 1 1 1 0 0]
• Use these vectors as input features to some classifier with labeled data

Previous approaches to SADrawbacks:
• Feature space grows linearly with vocab size• Ignores word context• Input features contain no information on words
themselves (“bad” is just as similar to “good” as “great” is)

Previous approaches to SASentiment Treebank (actually came after W2V)
• Fine-grained sentiment labels for 215,154 phrases of 11,855 sentences
• Train a recurrent ANN “bottom-up” by using previous children vectors to predict parent-phrase sentiment
• Does very well (85% test-set accuracy) on Treebank sentences2
• Good at finding negation
2 Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank, R. Socher et al. 2013. http://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf

Previous approaches to SADrawbacks:
• Probably does not generalize well to all tasks (phrase score for “#YOLO swag” = ??)
• Good in theory, hard in practice (good luck implementing it!)

What can:• Give continuous vector rep.’s of words?• Capture context?• Require minimal feature creation?

Answer:

Or… Word2Vec!3
3 Efficient Implementation of Word Representations in Vector Space, T. Mikolov, K. Chen, G. Corrado, and J. Dean, 2013.http://arxiv.org/pdf/1301.3781.pdf
• Maps words to continuous vector representations (i.e. points in an N-dimensional space)
• Learns vectors from training data (generalizable!)• Minimal feature creation!

Word2Vec
3 Efficient Implementation of Word Representations in Vector Space, T. Mikolov, K. Chen, G. Corrado, and J. Dean, 2013.http://arxiv.org/pdf/1301.3781.pdf
Two methods: Skip-gram and CBOW
How does it work?

CBOW
4 word2vec Parameter Learning Explained, X. Rong, 2014 http://arxiv.org/pdf/1411.2738v1.pdf
• Randomly initialize input/output weight matrices of sizes VxN and NxV where V: vocab size, N: vector size (parameter)
• Predict target word (one-hot encoded) from input of context word vectors (average) using single-layer NN
• Update weight matrices using SGD, backprop. and cross entropy over corpus
• Hidden layer size corresponds to word vector dim.

Skip-gram
4 word2vec Parameter Learning Explained, X. Rong, 2014 http://arxiv.org/pdf/1411.2738v1.pdf
• Method very similar, except now we predict window of words given single word vector
• Boils down to maximizing dot-product similarity of context words and target word5
• Skip-gram typically outperforms CBOW on semantic and syntactic accuracy (Mikolov et al.)
5 word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method, Y. Goldberg & O. Levy, 2014

What does Word2Vec give us?
Vectors!
More importantly, stuff like:
vector(“king”) – vector(“man”) + vector(“woman”) ≈ vector(“queen”)

Simple vector operations give usInteresting relationships:
3 Efficient Implementation of Word Representations in Vector Space, T. Mikolov, K. Chen, G. Corrado, and J. Dean, 2013.http://arxiv.org/pdf/1301.3781.pdf

Word2Vec for Sentiment Analysis

Word2Vec for SA
Learned W2V features
Sentiment classifier
Bonus: Word2Vec has implementations in python (gensim), Java, C++, and Spark MLlib

Example: TweetsMethodology:
• Collect tweets using emoticons and as fuzzy labels for positive and negative sentiment (can quickly & easily collect many this way!)
• Preprocess tweets• Split into train-test• Train word2vec on train set• Average word vectors for each tweet as input to classifier• Validate model• All using python!

Example: TweetsTutorial at: http://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis
Word2Vec trained on ~400,000 tweets gives us 73% classification accuracy• Gensim word2vec implementation• Sklearn Logit SGD classifier• Improves to 77% using ANN classifier
ROC curve

Example: Tweets
Negative tweets: Positive tweets:

Example: TweetsExtend with neutral class (“#news” is our fuzzy label)
• ~83% test accuracy with ANN classifier
• Seems to do impossibly well for neutral…

Example: Tweets
Neutral tweets:

Example: TweetsWhy does averaging tweets work?

Example: TweetsWords in 2D space

Example: TweetsWords in 2D space

Example: TweetsWords in 2D space

Example: Convolutional Nets
Window of word vecs => convolve => classify
6 Convolutional Neural Networks for Sentence Classification, Y. Kim, 2014.http://arxiv.org/pdf/1408.5882v2.pdf
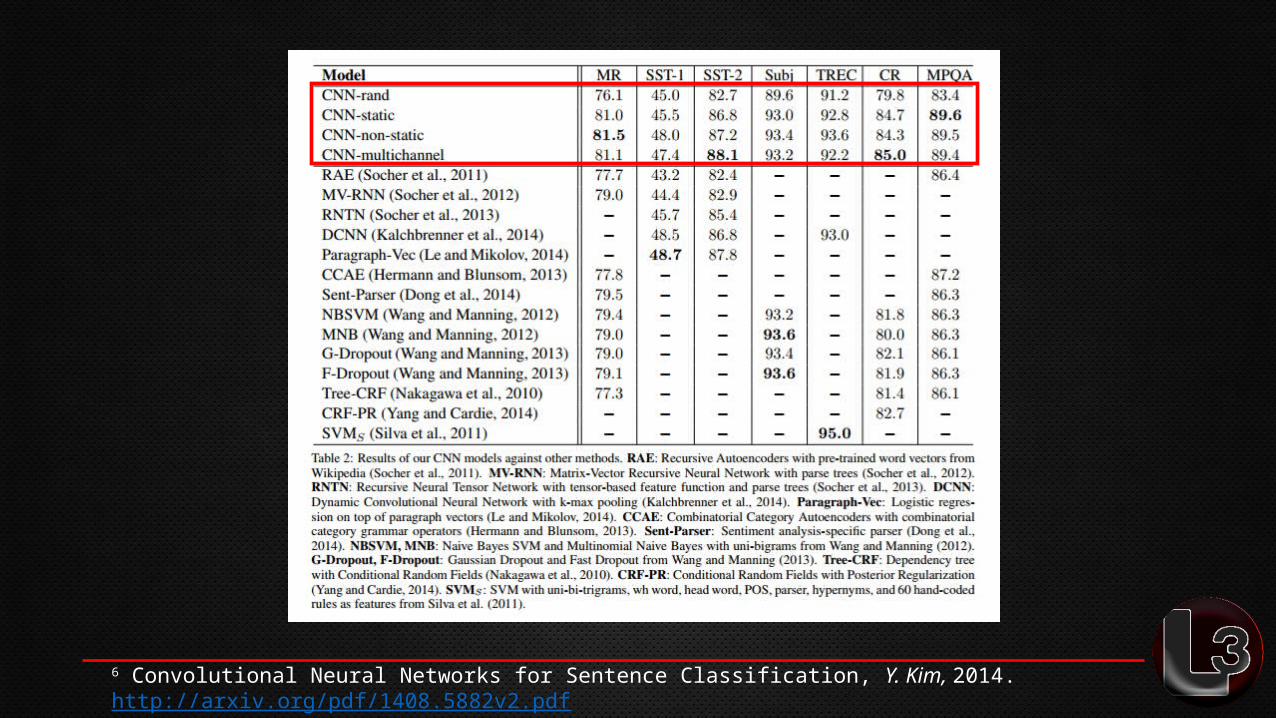
6 Convolutional Neural Networks for Sentence Classification, Y. Kim, 2014.http://arxiv.org/pdf/1408.5882v2.pdf

Word2VecDrawbacks:
• Quality depends on input data, number of samples, and size of vectors (possibly long computation time!)
But Google released 3 million word vecs trained on 100 billion words!
• Averaging vec’s does not work well (in my experience) on large text (> tweet level)
• W2V cannot provide fixed-length feature vectors for variable-length text (pretty much everything!)
3 Efficient Implementation of Word Representations in Vector Space, T. Mikolov, K. Chen, G. Corrado, and J. Dean, 2013.http://arxiv.org/pdf/1301.3781.pdf

Doc2Vec

Doc2Vec7
• Generalizes W2V to whole documents (phrases, sentences, etc.)
• Provides fixed-length vector
• Distributed Memory (DM) and Distributed Bag of Words (DBOW)
7Distributed Representations of Sentences and Documents, Q. V. Lee & T. Mikolov, 2014http://arxiv.org/abs/1405.4053

Distributed Memory (DM)
• Assign and randomly initialize paragraph vector for each doc
• Predict next work using context words + paragraph vec
• Slide context window across doc but keep paragraph vec fixed (hence distributed memory)
• Updating done via SGD and backprop.
7Distributed Representations of Sentences and Documents, Q. V. Lee & T. Mikolov, 2014http://arxiv.org/abs/1405.4053

Distributed Bag of Words (DBOW)
• ONLY use paragraph vec (no word vecs!)
• Take window of words in paragraph and randomly sample which one to predict using paragraph vec (ignores word ordering)
• Simpler, more memory efficient• DM typically outperforms DBOW
(but DM + DBOW is even better!)
7Distributed Representations of Sentences and Documents, Q. V. Lee & T. Mikolov, 2014http://arxiv.org/abs/1405.4053

How does it perform?Outperforms sentiment Treebank RNN (and everything else) on its own
dataset on both coarse and fine-grained sentiment classification
7Distributed Representations of Sentences and Documents, Q. V. Lee & T. Mikolov, 2014http://arxiv.org/abs/1405.4053
• Paragraph vec + 7 words to predict 8th word• Concatenates 400 dim. DBOW and DM vecs
as input• Predicts test-set paragraph vec’s from frozen
train-set word vec’s

How does it perform?Outperforms everything on Stanford IMDB movie review
data set
7Distributed Representations of Sentences and Documents, Q. V. Lee & T. Mikolov, 2014http://arxiv.org/abs/1405.4053
• Paragraph vec + 9 words to predict 10th word
• Concatenates 400 dim. DBOW and DM vecs as input
• Predicts test-set paragraph vec’s from frozen train-set word vec’s

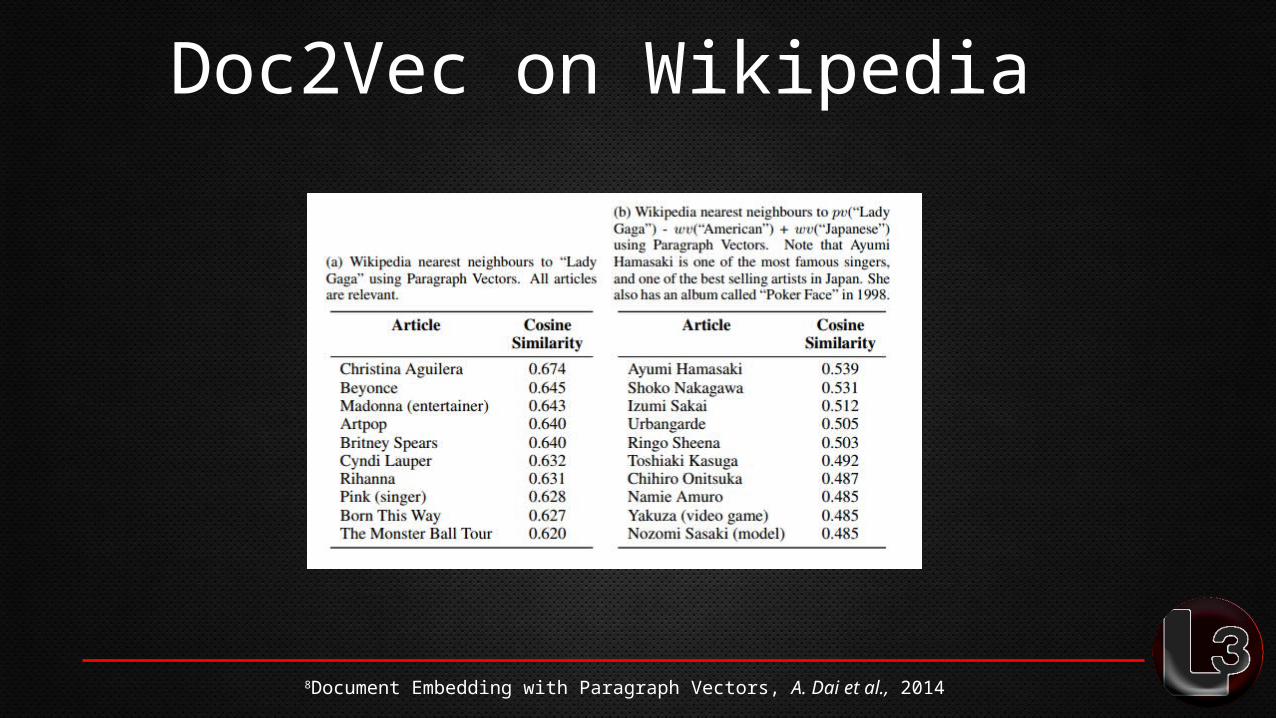
Doc2Vec on Wikipedia8
8Document Embedding with Paragraph Vectors, A. Dai et al., 2014

Doc2Vec on Wikipedia
8Document Embedding with Paragraph Vectors, A. Dai et al., 2014
LDA vs. Doc2Vec for nearest neighbors to “Machine learning” (bold = unrelated to ML)
Doc2Vec on Wikipedia
8Document Embedding with Paragraph Vectors, A. Dai et al., 2014

Using Doc2Vec
Gensim has an implementation already!Let’s try it on the Stanford IMDB set…

Using Doc2Vec
Only see ~13% test error (compared to reported 7.42%)See my blog post for full details: http://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis
Others have had similar issues (can get to 10% error)Code used in paper coming in the near future! (?)
Gensim cannot infer new doc vecs, but that is also coming!

Conclusion

Will Word/Doc2Vec solve all my problems?!
No, but maybe!

“No Free Lunch Theorem9”
Applying machine learning is an art! Test many tools and pick the right one.
9The Lack of A Priori Distinctions Between Learning Algorithms, D.H. Wolpert, 1996

W/D2V find contextual-based continuous vector representations of text
Many applications!• Information retrieval• Document classification• Recommendation algorithms• …

Thank you!