whoweda : warehouse of web data sanjay kumar madria department of computer science
DESCRIPTION
WHOWEDA : Warehouse of Web Data Sanjay Kumar Madria Department of Computer Science Purdue University, West Lafayette, IN 47907 [email protected]. www.is.a.mess. WWW. collection of multimedia documents in the form of web pages connected via hyperlinks. Characteristics of WWW. - PowerPoint PPT PresentationTRANSCRIPT

1
WHOWEDA : Warehouse of Web Data
Sanjay Kumar Madria
Department of Computer Science
Purdue University, West Lafayette, IN 47907

2

3
WWW
• collection of multimedia documents in the form of web pages connected via hyperlinks.

4
Characteristics of WWW
• WWW is a set of directed graphs
• data in the WWW has a heterogeneous nature
• unstructured versus structured information
• no central authority to manage information
• Dynamic verses static information
• Web information discoveries - search engines

5
As WWW grows, more chaotic it becomes
• Web is fast growing, distributed, non-administered global information resource
• WWW allows access to text, image, video, sound and graphic data
• more business organizations creating web servers
• more chaotic environment to locate information of interest
• lost in hyperspace syndrome

6
Does it affect the corporate world?• Lack of credibility of data
– Different sites with different data– Same site different data
• Historical information is not available– Previous versions of web data– How does web data change with time– Summarization over time
• Data to information• Reduction in productivity
– Analysis is manual

7
How users find web sites• Indexes and search engines 75• UseNet newsgroups 44• Cool lists 27• New lists 24• Listservers 23• Print ads 21• Word-of-mouth and e-mail 17• Linked web advertisement 4

8
Limitations of Search Engines
• Do not exploit hyperlinks
• search is limited to string matching
• Queries are evaluated on archived data rather than up-to-date data; no indexing on current data
• low accuracy
• replicated results
• no further manipulation possible

9
Limitations of Search Engines
• ERROR 404!
• No efficient document management
• Query results cannot be further manipulated
• No efficient means for knowledge discovery

10
Current Research Projects• Web Query System
– W3QS, WebSQL, AKIRA, NetQL, RAW,
WebLog
• Semistructured Data– LOREL, UnQL, WebOQL
• Website Management System– STRUDEL
• Web Warehouse
- WHOWEDA

11
WHOWEDA -Key Objectives
• Design a suitable data model to represent web information
• development of web algebra and query language
• Maintenance of Web data
• Development of knowledge discovery and web mining tools
• Web warehouse

12
WHOWEDA - What?
• WareHouse Of Web Data– Subject - oriented– Integrated– Temporal– Granularity - Lower, higher– Some summary– Not updatable– Alternative information sources

13
What is a Web Warehouse?
• Subject-oriented, integrated, time-variant, non-volatile repository of web data for direct querying and analysis for some sort of decision making
• A process whereby organizations or individuals extract value from their Web informational assets through the use of special stores called web warehouses
14
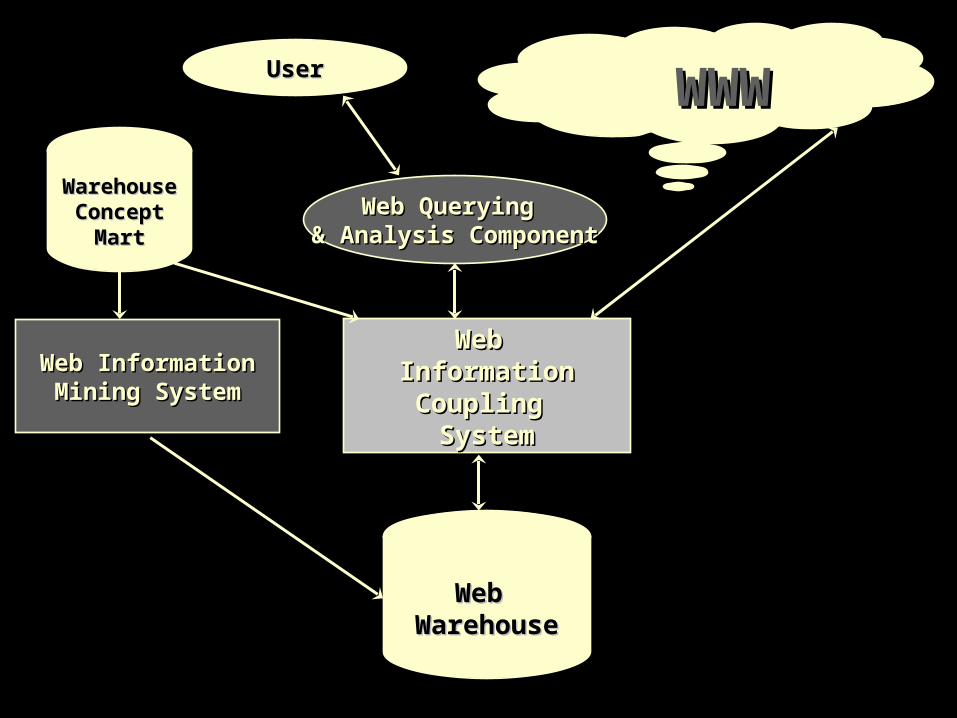
WHOWEDA! www.cais.ntu.edu.sg:8000/~whoweda
• A WareHouse Of WEb DAta
• Web Information Coupling Model (WICM)– Web Objects– Web Schema
• Web Information Coupling Algebra
• Web Information Maintenance
• Web Mining and Knowledge discovery
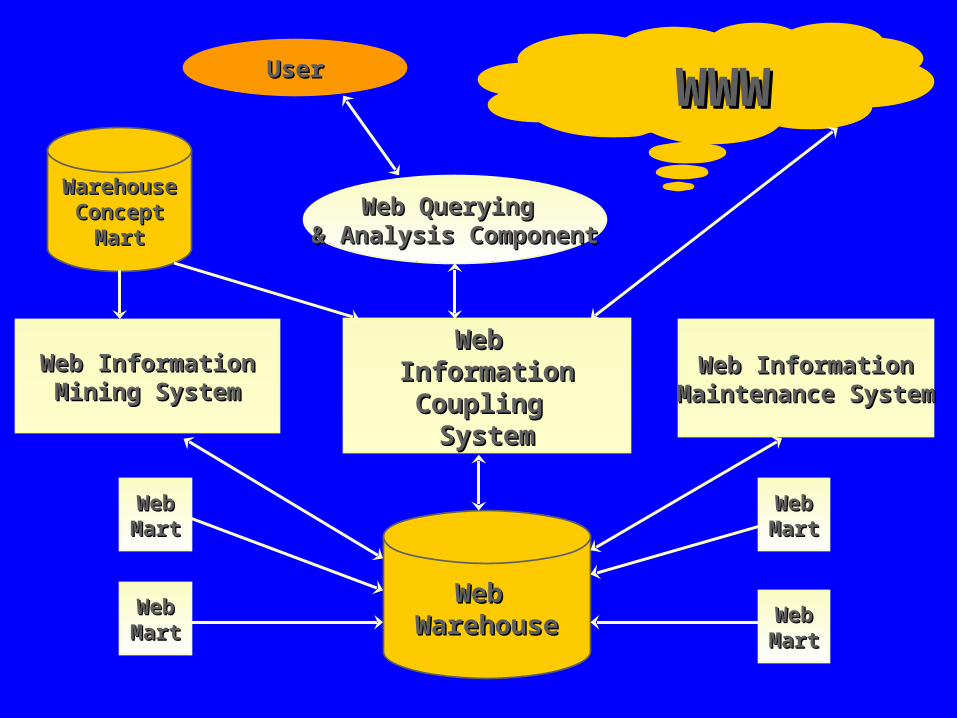
Web Web InformationInformationCoupling Coupling SystemSystem
Web InformationWeb InformationMaintenance SystemMaintenance System
Web InformationWeb InformationMining SystemMining System
WarehouseWarehouseConceptConcept
MartMart
WebWebMartMart
WWWWWW
Web Web WarehouseWarehouse
WebWebMartMart
WebWebMartMart
WebWebMartMart
Web Querying Web Querying & Analysis Component& Analysis Component
UserUser

Global WebGlobal WebManipulationManipulation
WarehouseWarehouseConceptConcept
MartMart
WWWWWW
Web Web WarehouseWarehouse
Web Web WarehouseWarehouse
Web Query & DisplayWeb Query & Display
UserUser
Pre processingPre processing
Local WebLocal WebManipulationManipulation
Global Web Global Web CouplingCoupling
Global RankingGlobal RankingData VisualizationData Visualization
Web SelectWeb Select
Local Web CouplingLocal Web CouplingWeb ProjectWeb Project
Local RankingLocal RankingWeb JoinWeb Join
Web UnionWeb UnionWeb IntersectionWeb Intersection
Schema TightnessSchema Tightness
Schema SearchSchema SearchSchema MatchSchema Match
Schema TightnessSchema Tightness
Data VisualizationData Visualization

17
Web Objects
• Node - url, title, format, size, date, text
• Link - source-url, target-url, label, link-type
• Web tuple
• Web table
• Web schema
• Web database

18
Web Schema• Metadata in the warehouse
• Structural ‘summary’ of web table
• Information Coupling using a Query graph
• Query graph ->Web schema
• directed graph represented by Ordered 4-tuple:– Set of node variables– Set of link variables– Connectivities– Predicates
19

20
Information Square's homepage
Headline article 1
Headline article n
News@TCS
News specialsAirport info
(List of video files)
List of links tolocal news
List of links toworld news
Local news 1
Local news kWorld news 1
World news t
Brief Organization of Information Space's Web Site

21
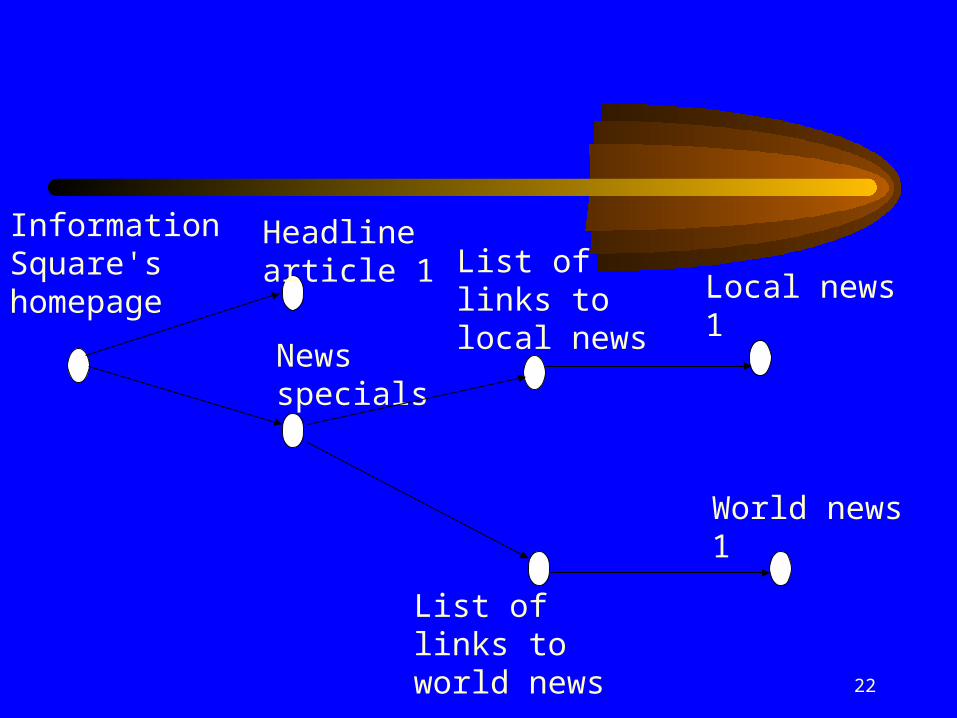
x ye
x ye
ggf
label CONTAINS"Local News"
target_URL CONTAINS"newshub/specials"
z
url CONTAINS"local"
label CONTAINS"World News"
w
url CONTAINS"world"
target_url CONTAINS"article”
h
url contains “headlines”
22
Information Square's homepage
Headline article 1
News specials
List of links tolocal news
List of links toworld news
Local news 1
World news 1

23
Schema- example
• Node variables: Xn = { x, y, z, w }
• Link variable: Xl = { e, f, g }
• Connectivities: C = { x<e>y and x<fg->z and x<fh->w }– The symbol represents an anonymous node
variable, a node variable not restricted by any predicate.

24
• Predicates
• P={x.url=”http://www.mediacity.com.sg/i-square”,
• y.url CONTAINS “headlines”
• e.target_url CONTAINS "article",
• f.target.url CONTAINS "newshub/specials",
• g.label CONTAINS "Local News",
• z.url CONTAINS "local",
• h.label CONTAINS "World News",
• w.url CONTAINS "world" }

25
Query Graph - Example 1• Query graph - same as schema except that it
has one more parameter to control the results returned.
• Informally, it is directed connected graph consists of nodes, links and keywords imposed on them.
• Produce a list of diseases with their symptoms, evaluation procedures and treatment starting from the web site at http://www.panacea.org/
• Web table Diseases
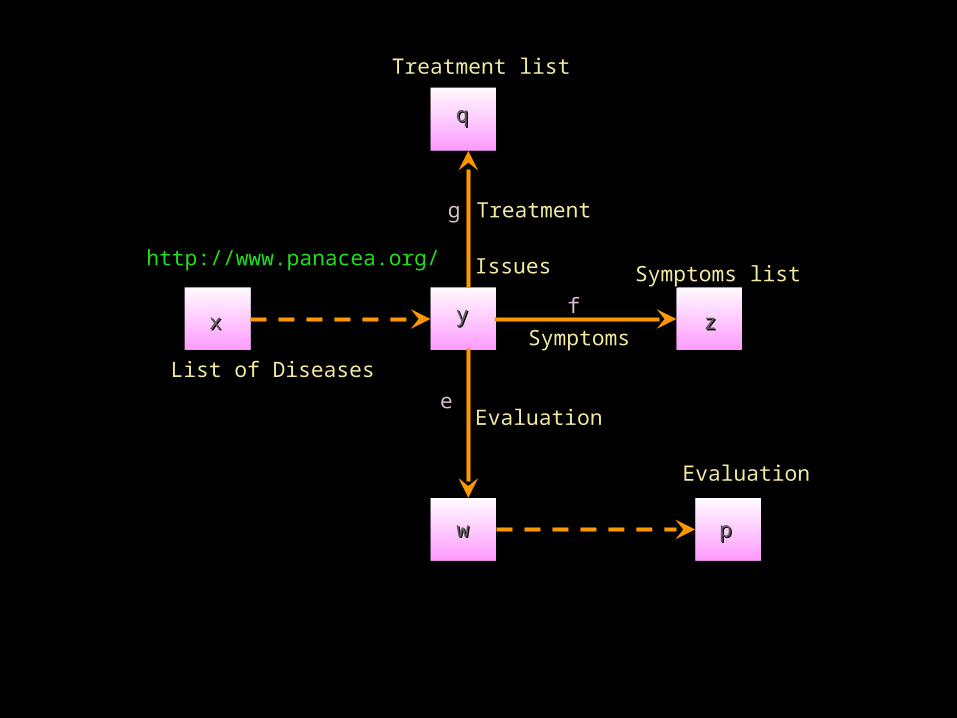
List of DiseasesList of Diseases
http://www.panacea.org/http://www.panacea.org/
xx
Treatment listTreatment list
TreatmentTreatmentgg
Symptoms listSymptoms list
zzSymptomsSymptoms
ff
IssuesIssues
yy
eeEvaluationEvaluation
ww pp
EvaluationEvaluation
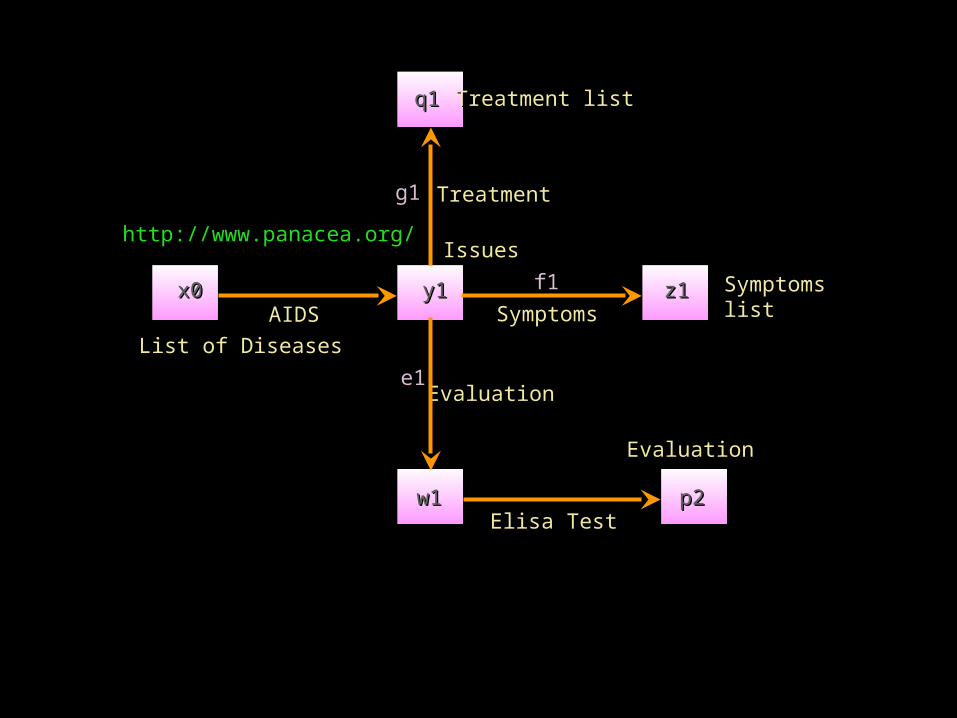
List of DiseasesList of Diseases
http://www.panacea.org/http://www.panacea.org/
x0x0
Treatment listTreatment listq1q1
TreatmentTreatmentg1g1
Symptoms Symptoms listlist
z1z1SymptomsSymptoms
f1f1
IssuesIssues
y1y1
e1e1EvaluationEvaluation
w1w1 p2p2Elisa TestElisa Test
AIDSAIDS
EvaluationEvaluation

28
Example 2
• Produce a list of drugs, and their uses and side effects starting from the web site at http://www.panacea.org/
• Web table Drugs

List of DiseasesList of Diseases
http://www.panacea.org/http://www.panacea.org/ Drug Drug listlist IssuesIssues
UsesUses
UseUse
Side effectsSide effectsaa bb cc dd
rr
ss
kk
SideSideeffectseffects

List ofList ofDiseasesDiseases
http://www.panacea.org/http://www.panacea.org/ DrugDrug listlist IssuesIssues
Uses of Uses of IndavirIndavir
UseUse
Side effectsSide effectsa0a0 b1b1 c1c1 d1d1
r1r1
s1s1
k1k1
AIDSAIDS
IndavirIndavir
Side effects Side effects of Indavirof Indavir

31
Query Language
• Starting from the CS deptt home page at NTU, find all documents that are linked through paths of length less than two containing only local links, and have in their text “database”.

32
• COUPLE WEBTABLE W FROM WWW
SUCH THAT NODE I, j IN WWW and LINK e,f,g IN WWW AND I<e|f,g>j WHERE I.url EQUALS “http://www.ntu.edu.sg” AND j.text CONTAINS “database” AND f.link-type EQUALS local AND g.link-type EQUALS local;

33
Web Algebra
• Formal foundation of data representation and manipulation in a web warehouse
• Web operators:– Information access operator– Information manipulation operators– Web schema operators– Data visualization operators

34
Information access operator
• Global Web Coupling

35
Information Manipulation
- Web select– Web project– Local web coupling– Web join– Web cartesian product– Web union– Web intersect– Local Web coupling

36
Web Select
• Extracts web tuples from web tables satisfying certain conditions on node and link variables and on connectivities
• Input is select Schema
• Output is a web table satisfying the select schema

37
• select W1 tuples that contain world news about Indonesia since May 1 1998.
• MsW1 where
Ms = < Xsn, Xsl, Cs, Ps >,
Xsn = { x, w }, Xsl = { },
Cs = { },
Ps = { x.date > "1May1998", w.text CONTAINS “Indonesia”}

38
• Xn’ = { x, y, z, w },Xl’ = { e, f, g }• C’ = { x<e>y and x<fg->z and x<fh->w }• P’={x.url=”http://www.mediacity.com.sg/i-
square”, x.date > "1May1998",• e.target_url CONTAINS "article",
f.target.url CONTAINS "newshub/specials",• g.label CONTAINS "Local News",• z.url CONTAINS "local",• h.label CONTAINS "World News",• w.url CONTAINS "world",• w.text CONTAINS “Indonesia” }

39
Web Information Coupling System
• A database system to couple related web information
• Global web Coupling and Local Web Coupling

40
Global Coupling - Information Access
• To integrate data from the Web
• To create historical data
• To couple related information from the WWW satisfying a query graph
• Operator to create web tables
• From web with no schema to web table with web schema

41
Why local web coupling?
• Directly querying the WWW to gather these information is an expensive and repetitive affair
• Web documents containing similar information can reside in different web tables in a web warehouse
• A mechanism to gather these similar information by additional manipulation of the materialized web tables

42
Local Web Couple operator
• Two web tuples and can be coupled if there exist atleast one pair of nodes from and which contains similar information.
iw
iw
jw
jw

43
Local Web Couple operator
• The web couple operator is basically a web cartesian product followed by web select:
• We denote web couple by the symbol:
WW
WWW ji
ji WWW
44
Web Coupling

45
• M2 = < Xn”, Xl”, C”,P” > for W2• Xn” = { s, t, u}, Xl” = { k, l, m, n },• C” ={ s<kl>t and s<mn>u },• P”{s.url=
“http://www.asia1.com.sg/straitstimes/”,• k.label = “REGION”, • l.target_url=
“http://www.asia1.com.sg/straitstimes/pages/sea*.html”, m.label = “WORLD”,
• n.target_url=“http://www.asia1.com.sg/straitstimes/pages/wrld*.html”}

46
• W1 q W2 where
• q = (x.date=s.date) & (w.text CONTAINS “Indonesia”) & (t.text CONTAINS “Indonesia”)

47
• Xn* = { x, y, z, w, s, t, u }, Xl* = { e, f, g, k, l, m, n }, C*= { x<e>y and x<fg->z and x<fh->w and s<kl>t and s<mn>u }
• P* = { x.url=”http://www.mediacity.com.sg/i-square”, e.target_url CONTAINS "article",
• f.target.url CONTAINS "newshub/specials",
• g.label CONTAINS "Local News",
• z.url CONTAINS "local",
• h.label CONTAINS "World News",
• w.url CONTAINS "world",
• s.url = “http://www.asia1.com.sg/straitstimes/”,

48
• k.label = “REGION”, l.target_url = “http://www.asia1.com.sg/straitstimes/pages/sea*.html”,
• m.label = “WORLD”,
• n.target_url = “http://www.asia1.com.sg/straitstimes/pages/wrld*.html”,
• x.date = s.date,
• w.text CONTAINS “Indonesia”,
• t.text CONTAINS “Indonesia"}

49
Local Web Coupling
• Initiated explicitly by the user
• User provides the pair of node variables and the keyword set based on which coupling is to be performed
• Coupling nodes in each pair of web tuples in the input web tables must satisfy one of the coupling conditions

50
Construction of coupled table
• First perform a web cartesian product on the two web tables
• For each web tuple in the resultant web table– the specified instances of node variables are
inspected to determine whether the web tuple satisfy coupling compatibility condition(s)

51
Construction of coupled table
– If a pair of nodes satisfy none of the conditions, the corresponding web tuple is rejected
– Otherwise, the web tuple is stored in a separate web table

52
Types of web coupling
• System driven web coupling: In this case the system to decide which are the node variables to be coupled (coupling nodes). If atleast a pair of coupling nodes cannot be identified then the web tables cannot be coupled.

53
Types of web coupling
• User driven web coupling: In this case the user decides which are the node variables to be coupled (coupling nodes).
• Coupling is performed only on those user specified node variable(s).

54
Types of web coupling
• Attribute driven web coupling: In this case the user specifies the coupling attributes.
• Coupling is performed only on those user specified coupling attribute(s).

55
Attribute driven web coupling
COUPLE TABLE3
FROM TABLE1 AND TABLE 2
ON ATTRIBUTE “TEXT”
AT SCHEMA/TUPLE(optional)

56
Types of web coupling
• Value driven web coupling: In this case the user specifies the values of the attributes of the nodes on which coupling should be performed.
• Coupling is performed only on those user specified attribute values.

57
Value driven web coupling
COUPLE TABLE3
FROM TABLE1 AND TABLE 2
ON VALUE “Software Agents”
AT SCHEMA/TUPLE(optional)

58
Schema level web coupling• We inspect the schemas to decide whether
the two web tables can be coupled.• If coupling conditions cannot be identified
then the two web tables cannot be coupled.
• We do not inspect the web tuples in the web table.
• Number of web tuples coupled will be n*m.

59
Tuple level web coupling
• We inspect the web tuples of the two input web tables to identify nodes with similar information.
• The number of web tuples in the coupled web table <=n*m

60
Why two levels?
• A schema does not capture all the information of the web documents in a web table; not always possible to identify coupling condition by inspecting the schemas.
• possible to find existence of coupling nodes which are not defined in the schemas.

61
Why two levels?
• Tuple level coupling gives us a mean to correlate web documents containing similar information from the web tables (that cannot be identified from their schemas) at the expense of additional processing.

62
Join Processing in Web Databases

63
Web Join• Concatenate tuples based on identical nodes
or documents
• Input are two web tables and their schemas
• Output is a joined table
• Types – Pi-web join, theta-web join, outer joins, web
composition, semi web join

64
Web Join• Used for combining related data from
various web tables
• Mechanism to detect changes
• Mechanism to find alternative web document in case of “Document Not Found” error

65
Web Join Operator
• Information manipulation operator
• Manipulate information residing in a web database to derive additional information
• Harness useful, composite information from two web tables
• Capitalize on the reuse of retrieved data from the WWW in order to reduce execution time of queries

66
Joinable Nodes
• Node variables participating in the web join process
• Expressed as a pair
• Each node in the pair should have identical URLs

67
Web Join
• Combine two web tables by concatenating a web tuple of one web table with a web tuple of other web table whenever there exist joinable nodes
• Joinable nodes are identified from the schemas of the two web tables
• URLs of the joinable nodes are identical

List of List of DiseasesDiseases
http://www.panacea.org/http://www.panacea.org/
xx
Treatment listTreatment list
TreatmentTreatmentgg
Symptoms listSymptoms list
zzSymptomsSymptoms
ffIssuesIssues
yy
eeEvaluationEvaluation
ww pp
EvaluationEvaluationDrug Drug listlist
UsesUses
UseUse
Side effectsSide effects
bb cc ddrr
ss
kk
SideSideeffectseffects
IssuesIssues
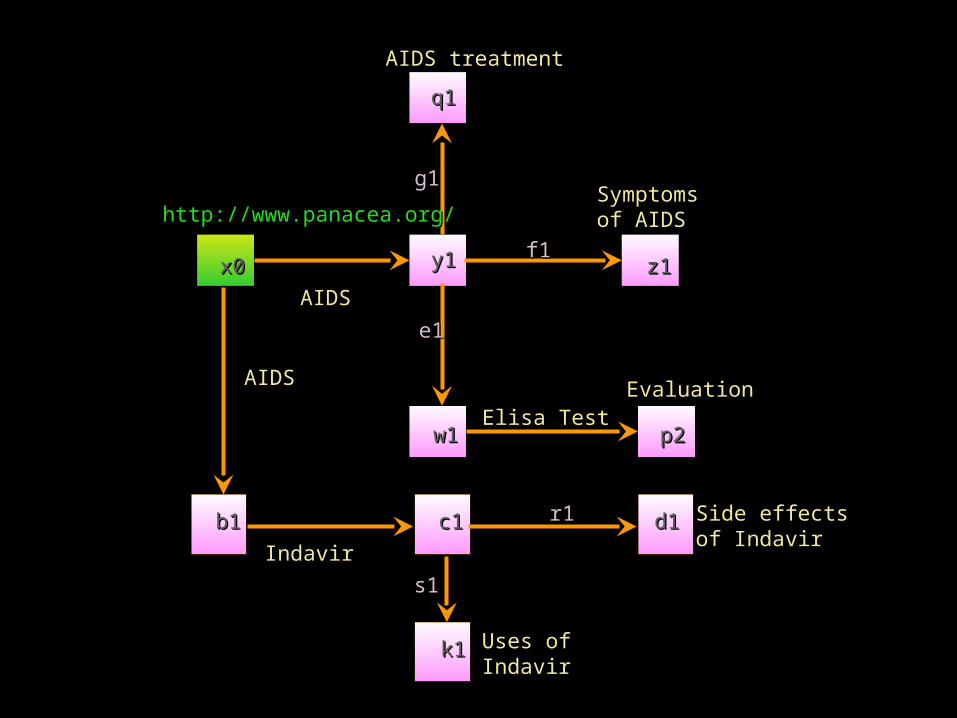
http://www.panacea.org/http://www.panacea.org/
x0x0
AIDS treatmentAIDS treatment
q1q1
g1g1Symptoms Symptoms of AIDSof AIDS
z1z1f1f1y1y1
e1e1
ww11
p2p2
EvaluationEvaluation
b1b1 c1c1 d1d1r1r1
s1s1
k1k1
Side effects Side effects of Indavirof Indavir
AIDSAIDS
AIDSAIDS
Elisa TestElisa Test
IndavirIndavir
Uses ofUses ofIndavirIndavir

70
Join Existence
• Given two web tables, we determine if these two web tables are joinable
• Inspect the schemas of the web tables
• Satisfy joinability conditions based on:– node predicates– link predicates– node and link predicates– locus of a node relative to a joinable node

71
Join Construction
• To construct a joined schema, we construct:– node set– link set– connectivity set– predicate set
• Construction of joined table– Concatenating the web tuples of the two input
tables over the joinable nodes

72
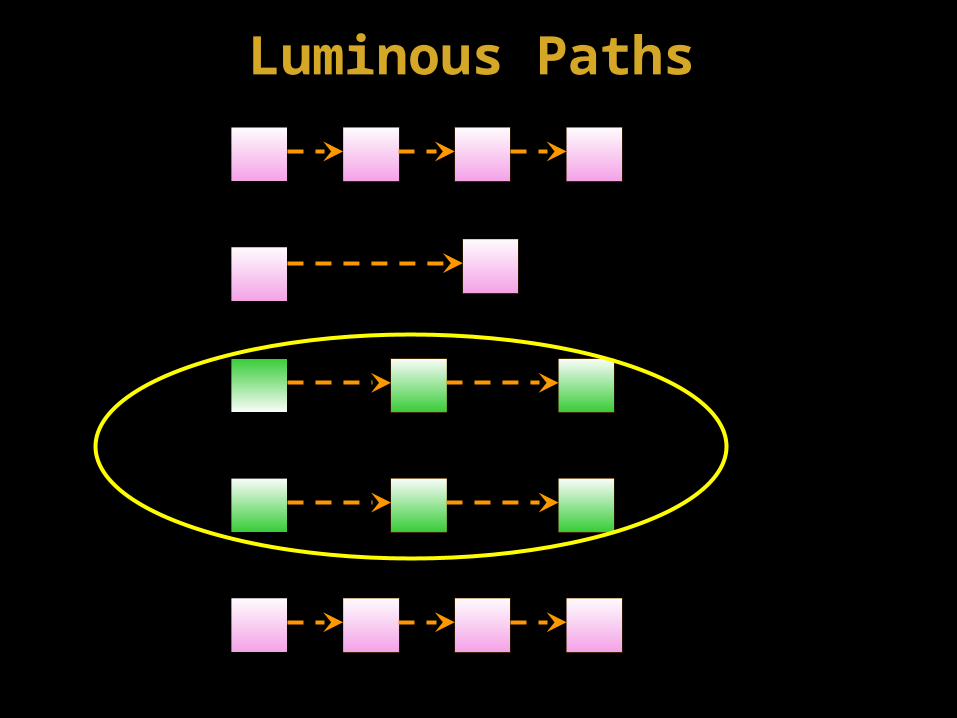
Web Bags
• Existence of identical web tuples.
• Created due to web project operation.
• Structure based mining
• Used for discovering– Visible nodes– Luminous nodes– Luminous paths

73
Definitions • Visibility of a web document or node D in a
web table W measures the number of different web documents in W that have links to D
• Luminosity - Reverse of visibility, the number of other distinct documents that are linked from D
• Luminous paths - a set of inter-linked nodes which occurs number of times in a web table

74
Steps to find visible nodes
• Input: Web table W, node variable x, visibility threshold v
• Output: Set of visible nodes • Create a web table from W where each web
tuple contains distinct instances of node x and the preceeding node which is linked to x
• Eliminate the nodes linked to x in each tuple of the web table using web project

75
Steps to find visible nodes
• Input: Web table W, node variable x, visibility threshold v
• Output: Set of visible nodes
• Create a web table from W where each web tuple contains distinct instances of node x and the preceeding node which is linked to x
• Eliminate the nodes linked to x in each tuple of the web table using web project

76
Steps to find visible nodes • Check if the collection of web tuples of node x
thus created is a web bag by comparing their URLs
• Create multiplets for each collection of identical nodes
• For each multiplet calculate the node visibility• Determine the multiplets with node visibility
greater than the threshold• Create the visible node set

77
Steps to find luminous nodes
• Input: Web table W, node variable x, luminosity threshold l
• Output: Set of luminous nodes
• Steps are similar to that of visible node discovery
• We consider the nodes linked from x in place of nodes linked to x

78
Steps to find luminous nodes
• Input: Web table W, node variable x, luminosity threshold l
• Output: Set of luminous nodes
• Steps are similar to that of visible node discovery
• We consider the nodes linked from x in place of nodes linked to x

79
Steps to find luminous paths
• Create the collection of multiplets
• Compute path luminosity for each multiplet
• If the path luminosity value of a multiplet is greater than or equal to threshold then a path in the multiplet is a luminous path
• Otherwise, we create a collection of linear web tuples from the above collection of web tuples

80
Steps to find luminous paths
• This is to identify if there exist a subset of inter-linked nodes between x and y that are luminous paths
• We repeat the procedure to compute path luminosity for these set of inter-linked nodes
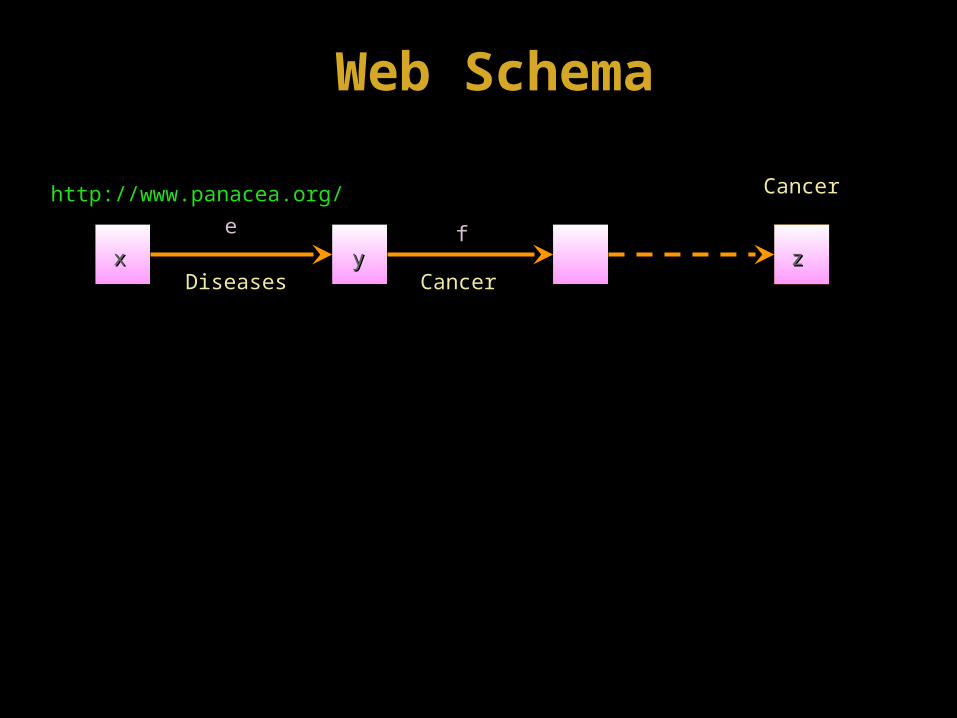
http://www.panacea.org/http://www.panacea.org/
xx yy zz
CancerCancer
CancerCancerDiseasesDiseases
ee ff
Web SchemaWeb Schema
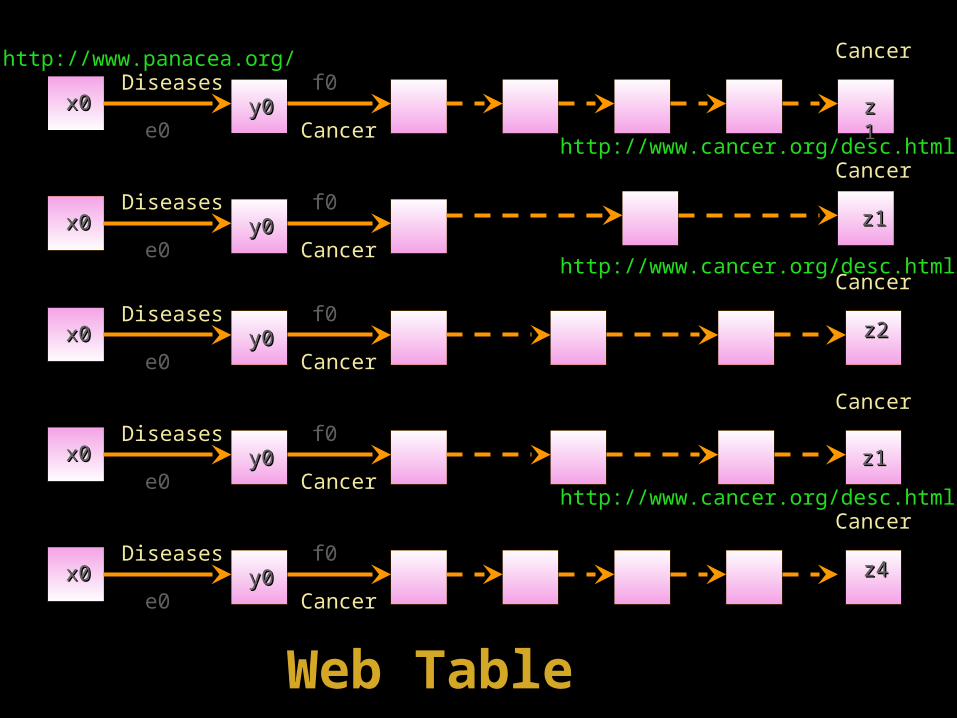
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0DiseasesDiseases
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.htmlCancerCancere0e0
f0f0zz11
CancerCancer
x0x0 y0y0DiseasesDiseases
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.htmlCancerCancere0e0
f0f0z1z1
CancerCancer
x0x0 y0y0DiseasesDiseases
CancerCancere0e0
f0f0z2z2
CancerCancer
x0x0 y0y0DiseasesDiseases
CancerCancere0e0
f0f0z4z4
CancerCancer
x0x0 y0y0DiseasesDiseases
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.htmlCancerCancere0e0
f0f0z1z1
Web TableWeb Table

zz
CancerCancer
Projected schemaProjected schema
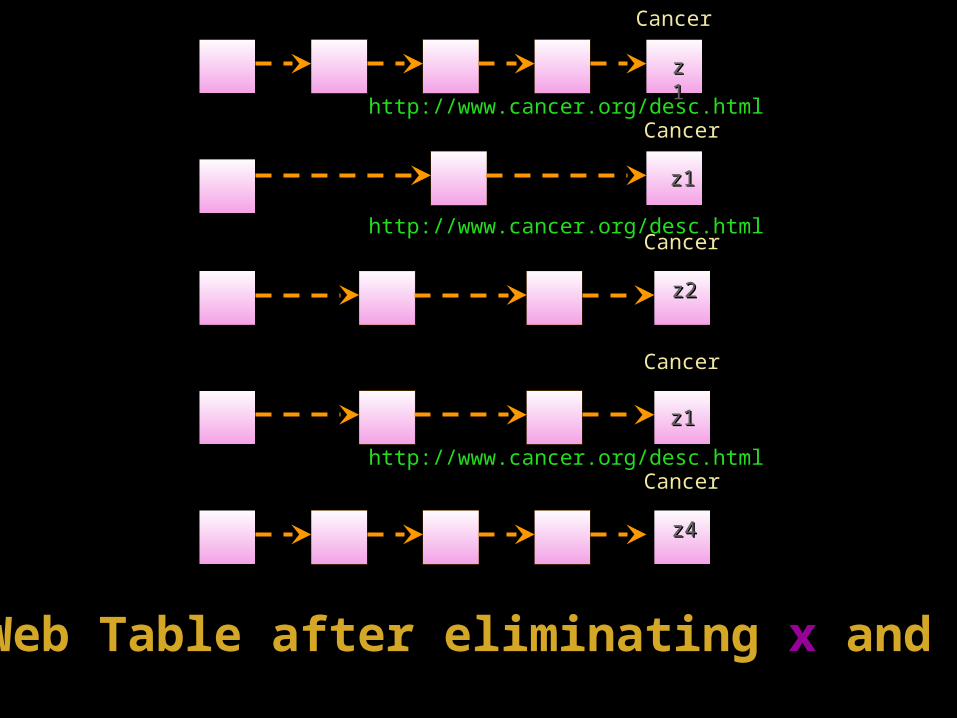
CancerCancer
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
zz11
CancerCancer
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
z1z1
CancerCancer
z2z2
CancerCancer
z4z4
CancerCancer
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
z1z1
Web Table after eliminating Web Table after eliminating xx and and yy

http://www.panacea.org/http://www.panacea.org/
xx yy zz
CancerCancer
DiseasesDiseases
ee
Projected schemaProjected schema
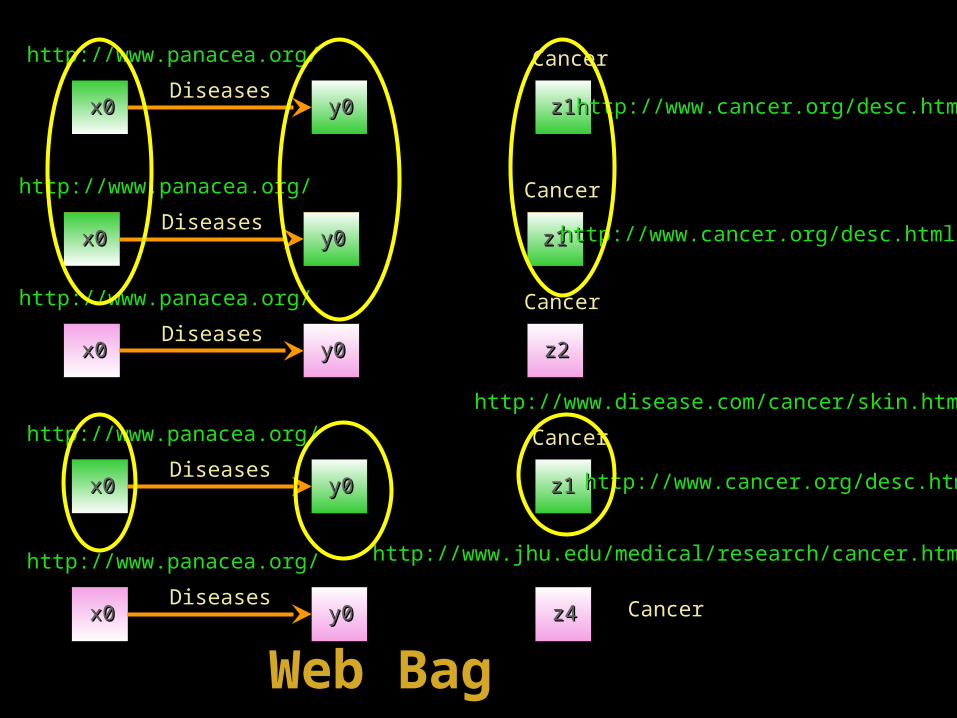
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0 z1z1DiseasesDiseases
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0 z1z1DiseasesDiseases
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0 z1z1DiseasesDiseases
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0 z2z2DiseasesDiseases
http://www.disease.com/cancer/skin.htmhttp://www.disease.com/cancer/skin.htm
http://www.jhu.edu/medical/research/cancer.htmhttp://www.jhu.edu/medical/research/cancer.htm
Web BagWeb Bag
http://www.panacea.org/http://www.panacea.org/
CancerCancerx0x0 y0y0 z4z4DiseasesDiseases

http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0 z1z1DiseasesDiseases
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0 z2z2DiseasesDiseases
http://www.disease.com/cancer/skin.htmhttp://www.disease.com/cancer/skin.htm
http://www.panacea.org/http://www.panacea.org/ CancerCancer
x0x0 y0y0 z4z4DiseasesDiseases
http://www.jhu.edu/medical/research/cancer.htmhttp://www.jhu.edu/medical/research/cancer.htm
After removal of identical tuplesAfter removal of identical tuples

CancerCancer
z1z1 http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
CancerCancer
z1z1 http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
CancerCancer
z2z2
http://www.disease.com/cancer/skin.htmhttp://www.disease.com/cancer/skin.htm
http://www.jhu.edu/medical/research/cancer.htmhttp://www.jhu.edu/medical/research/cancer.htm
CancerCancer
z1z1
CancerCancer
z4z4

http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
CancerCancer
z1z1 http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
CancerCancer
z2z2
http://www.disease.com/cancer/skin.htmhttp://www.disease.com/cancer/skin.htm
http://www.jhu.edu/medical/research/cancer.htmhttp://www.jhu.edu/medical/research/cancer.htm
CancerCancer
z1z1
CancerCancer
z4z4

http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
CancerCancer
z1z1 http://www.cancer.org/desc.htmlhttp://www.cancer.org/desc.html
CancerCancer
z2z2
http://www.disease.com/cancer/skin.htmhttp://www.disease.com/cancer/skin.htm
http://www.jhu.edu/medical/research/cancer.htmhttp://www.jhu.edu/medical/research/cancer.htm
CancerCancer
z1z1
CancerCancer
z4z4
Visible NodesVisible Nodes
Luminous PathsLuminous Paths

92
More Operators . . .
• Web schema operators:– Schema tightness operator, Schema match
operator, Schema search operator
• Data visualization operators:– Ranking operators (Global & Local), Web
Nest, Web Un-nest, Web Coalesce, Web Expand, Web Pack, Web Unpack, Web Sort

93
Partitioning of web tables
• Partitioning web tables– restructured easily– indexed easily– monitored easily– reorganized easily
• By– time
• schema tree structure
• keywords

94
Warehouse Concept Mart (WCMart)
• Subject oriented
• Concept generation.
• Manually -> Autonomous.
• Used for:– Ranking tuples– Global web coupling– Content based mining

95
Mining in Web Warehouse
• Web Structure Mining
• Web Content Mining
• Web usage Mining

96
Web Data Refinement
• Improve web schema - schema tightness operator
• Partition web tables based on content and structure

97
Partitioning of web tables
• Partitioning web tables– restructured easily– indexed easily– monitored easily– reorganized easily
• By– time
• schema tree structure
• keywords

WarehouseWarehouseConceptConcept
MartMart
WarehouseWarehouseConceptConcept
MartMart
WWWWWW
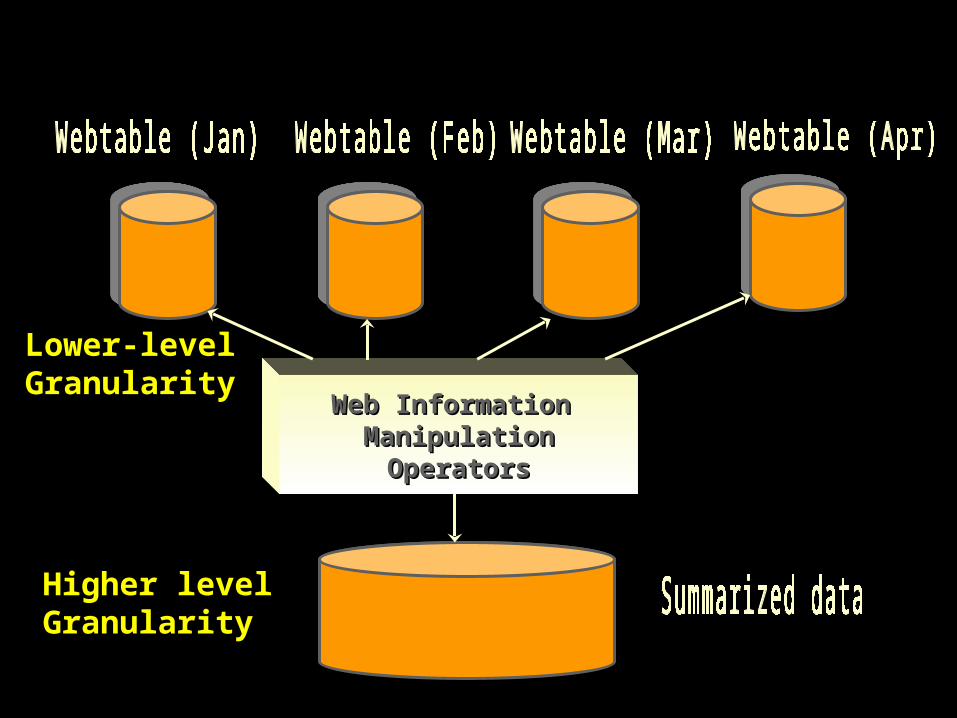
Web Information Web Information ManipulationManipulation
OperatorsOperators
Lower-levelLower-levelGranularityGranularity
Higher levelHigher levelGranularityGranularity
Web Web InformationInformation
Coupling Coupling SystemSystem
Web InformationWeb InformationMining SystemMining System
WarehouseWarehouseConceptConcept
MartMart
WWWWWW
Web Web WarehouseWarehouse
Web Querying Web Querying & Analysis Component& Analysis Component
UserUser

101
• Structural
• Content-based– time-variant analysis– snapshot analysis– compare one period with another– trend analysis
What type of information can be summarized?

102
• Most volatile documents– Sites which change frequently– Rate of change over time– a pointer to directly access documents which change
rapidly
• Most visible nodes, luminous nodes, luminous paths– Change with time– Decrease or increase - Analyze the reason
Structural Summarization

103
• What can be aggregrated in a web page?– Number of links with identical labels– Number of keywords
• Changes in content with time– Comparing the changes
• Open question• XML will improve the ability of analysis of
web data
Content Summarization

104
Summary• Current status:
– Mechanism for accessing and manipulating web information in WHOWEDA
– Implementing various web operators and query language
• Future research– What types of information can be summarized?– What types of knowledge can be mined?– Refine web warehouse architecture
• www.cais.ntu.edu.sg:8000/~whoweda