virtual routers on the move: live router migration as a
TRANSCRIPT

Virtual Routers on the Move: Live Router Migrationas a Network-Management Primitive
Yi Wang∗ Eric Keller∗ Brian Biskeborn∗ Jacobus van der Merwe† Jennifer Rexford∗∗ Princeton University, Princeton, NJ, USA † AT&T Labs - Research, Florham Park, NJ, USA
{yiwang,jrex}@cs.princeton.edu {ekeller,bbiskebo}@princeton.edu [email protected]
ABSTRACTThe complexity of network management is widely recognizedas one of the biggest challenges facing the Internet today.Point solutions for individual problems further increase sys-tem complexity while not addressing the underlying causes.In this paper, we argue that many network-managementproblems stem from the same root cause—the need to main-tain consistency between the physical and logical configura-tion of the routers. Hence, we propose VROOM (VirtualROuters On the Move), a new network-management primi-tive that avoids unnecessary changes to the logical topologyby allowing (virtual) routers to freely move from one phys-ical node to another. In addition to simplifying existingnetwork-management tasks like planned maintenance andservice deployment, VROOM can also help tackle emergingchallenges such as reducing energy consumption. We presentthe design, implementation, and evaluation of novel migra-tion techniques for virtual routers with either hardware orsoftware data planes. Our evaluation shows that VROOMis transparent to routing protocols and results in no perfor-mance impact on the data traffic when a hardware-baseddata plane is used.
Categories and Subject DescriptorsC.2.6 [Computer Communication Networks]: Internet-working; C.2.1 [Computer Communication Networks]:Network Architecture and Design
General TermsDesign, Experimentation, Management, Measurement
KeywordsInternet, architecture, routing, virtual router, migration
1. INTRODUCTIONNetwork management is widely recognized as one of the
most important challenges facing the Internet. The cost ofthe people and systems that manage a network typically
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.SIGCOMM’08, August 17–22, 2008, Seattle, Washington, USA.Copyright 2008 ACM 978-1-60558-175-0/08/08 ...$5.00.
exceeds the cost of the underlying nodes and links; in ad-dition, most network outages are caused by operator errors,rather than equipment failures [21]. From routine tasks suchas planned maintenance to the less-frequent deployment ofnew protocols, network operators struggle to provide seam-less service in the face of changes to the underlying network.Handling change is difficult because each change to the phys-ical infrastructure requires a corresponding modification tothe logical configuration of the routers—such as reconfigur-ing the tunable parameters in the routing protocols.
Logical refers to IP packet-forwarding functions, while phys-ical refers to the physical router equipment (such as linecards and the CPU) that enables these functions. Any in-consistency between the logical and physical configurationscan lead to unexpected reachability or performance prob-lems. Furthermore, because of today’s tight coupling be-tween the physical and logical topologies, sometimes logical-layer changes are used purely as a tool to handle physicalchanges more gracefully. A classic example is increasing thelink weights in Interior Gateway Protocols to “cost out” arouter in advance of planned maintenance [30]. In this case,a change in the logical topology is not the goal, rather it isthe indirect tool available to achieve the task at hand, andit does so with potential negative side effects.
In this paper, we argue that breaking the tight couplingbetween physical and logical configurations can provide asingle, general abstraction that simplifies network manage-ment. Specifically, we propose VROOM (Virtual ROutersOn the Move), a new network-management primitive wherevirtual routers can move freely from one physical router toanother. In VROOM, physical routers merely serve as thecarrier substrate on which the actual virtual routers operate.VROOM can migrate a virtual router to a different physi-cal router without disrupting the flow of traffic or changingthe logical topology, obviating the need to reconfigure thevirtual routers while also avoiding routing-protocol conver-gence delays. For example, if a physical router must un-dergo planned maintenance, the virtual routers could move(in advance) to another physical router in the same Point-of-Presence (PoP). In addition, edge routers can move fromone location to another by virtually re-homing the links thatconnect to neighboring domains.
Realizing these objectives presents several challenges: (i)migratable routers: to make a (virtual) router migratable, its“router” functionality must be separable from the physicalequipment on which it runs; (ii) minimal outages: to avoiddisrupting user traffic or triggering routing protocol recon-vergence, the migration should cause no or minimal packetloss; (iii) migratable links: to keep the IP-layer topology in-

tact, the links attached to a migrating router must “follow”it to its new location. Fortunately, the third challenge isaddressed by recent advances in transport-layer technolo-gies, as discussed in Section 2. Our goal, then, is to migraterouter functionality from one piece of equipment to anotherwithout disrupting the IP-layer topology or the data trafficit carries, and without requiring router reconfiguration.
On the surface, virtual router migration might seem likea straight-forward extention to existing virtual machine mi-gration techniques. This would involve copying the virtualrouter image (including routing-protocol binaries, configu-ration files and data-plane state) to the new physical routerand freezing the running processes before copying them aswell. The processes and data-plane state would then be re-stored on the new physical router and associated with themigrated links. However, the delays in completing all ofthese steps would cause unacceptable disruptions for boththe data traffic and the routing protocols. For virtual routermigration to be viable in practice, packet forwarding shouldnot be interrupted, not even temporarily. In contrast, thecontrol plane can tolerate brief disruptions, since routingprotocols have their own retransmission mechansisms. Still,the control plane must restart quickly at the new location toavoid losing protocol adjacencies with other routers and tominimize delay in responding to unplanned network events.
In VROOM, we minimize disruption by leveraging theseparation of the control and data planes in modern routers.We introduce a data-plane hypervisor—a migration-awareinterface between the control and data planes. This unifiedinterface allows us to support migration between physicalrouters with different data-plane technologies. VROOM mi-grates only the control plane, while continuing to forwardtraffic through the old data plane. The control plane canstart running at the new location, and populate the new dataplane while updating the old data plane in parallel. Dur-ing the transition period, the old router redirects routing-protocol traffic to the new location. Once the data planeis fully populated at the new location, link migration canbegin. The two data planes operate simultaneously for aperiod of time to facilitate asynchronous migration of thelinks.
To demonstrate the generality of our data-plane hypervi-sor, we present two prototype VROOM routers—one witha software data plane (in the Linux kernel) and the otherwith a hardware data plane (using a NetFPGA card [23]).Each virtual router runs the Quagga routing suite [26] in anOpenVZ container [24]. Our software extensions consist ofthree main modules that (i) separate the forwarding tablesfrom the container contexts, (ii) push the forwarding-tableentries generated by Quagga into the separate data plane,and (iii) dynamically bind the virtual interfaces and forward-ing tables. Our system supports seamless live migration ofvirtual routers between the two data-plane platforms. Ourexperiments show that virtual router migration causes nopacket loss or delay when the hardware data plane is used,and at most a few seconds of delay in processing control-plane messages.
The remainder of the paper is structured as follows. Sec-tion 2 presents background on flexible transport networksand an overview of related work. Next, Section 3 discusseshow router migration would simplify existing network man-agement tasks, such as planned maintenance and servicedeployment, while also addressing emerging challenges like
Router A ProgrammableTransport Network
Router B
Router C
Optical transport switch
(a) Programmable transport network
Router A Packet-awareTransport Network
Router B
Router C
IP router
(b) Packet-aware transport network
Figure 1: Link migration in the transport networks
power management. We present the VROOM architecturein Section 4, followed by the implementation and evalua-tion in Sections 5 and 6, respectively. We briefly discussour on-going work on migration scheduling in Section 7 andconclude in Section 8.
2. BACKGROUNDOne of the fundamental requirements of VROOM is “link
migration”, i.e., the links of a virtual router should “fol-low” its migration from one physical node to another. Thisis made possible by emerging transport network technolo-gies. We briefly describe these technologies before giving anoverview of related work.
2.1 Flexible Link MigrationIn its most basic form, a link at the IP layer corresponds
to a direct physical link (e.g., a cable), making link migra-tion hard as it involves physically moving link end point(s).However, in practice, what appears as a direct link at theIP layer often corresponds to a series of connections throughdifferent network elements at the transport layer. For ex-ample, in today’s ISP backbones, “direct” physical links aretypically realized by optical transport networks, where anIP link corresponds to a circuit traversing multiple opticalswitches [9, 34]. Recent advances in programmable transportnetworks [9, 3] allow physical links between routers to bedynamically set up and torn down. For example, as shownin Figure 1(a), the link between physical routers A and Bis switched through a programmable transport network. Bysignaling the transport network, the same physical port onrouter A can be connected to router C after an optical pathswitch-over. Such path switch-over at the transport layercan be done efficiently, e.g., sub-nanosecond optical switch-ing time has been reported [27]. Furthermore, such switch-ing can be performed across a wide-area network of trans-port switches, which enables inter-POP link migration.

In addition to core links within an ISP, we also want tomigrate access links connecting customer edge (CE) routersand provider edge (PE) routers, where only the PE end ofthe links are under the ISP’s control. Historically, accesslinks correspond to a path in the underlying access network,such as a T1 circuit in a time-division multiplexing (TDM)access network. In such cases, the migration of an access linkcan be accomplished in similar fashion to the mechanismshown in Figure 1(a), by switching to a new circuit at theswitch directly connected to the CE router. However, in tra-ditional circuit-switched access networks, a dedicated phys-ical port on a PE router is required to terminate each TDMcircuit. Therefore, if all ports on a physical PE router are inuse, it will not be able to accommodate more virtual routers.Fortunately, as Ethernet emerges as an economical and flex-ible alternative to legacy TDM services, access networks areevolving to packet-aware transport networks [2]. This trendoffers important benefits for VROOM by eliminating theneed for per-customer physical ports on PE routers. In apacket-aware access network (e.g., a virtual private LANservice access network), each customer access port is associ-ated with a label, or a “pseudo wire” [6], which allows a PErouter to support multiple logical access links on the samephysical port. The migration of a pseudo-wire access linkinvolves establishing a new pseudo wire and switching to itat the multi-service switch [2] adjacent to the CE.
Unlike conventional ISP networks, some networks are re-alized as overlays on top of other ISPs’ networks. Examplesinclude commercial “Carrier Supporting Carrier (CSC)”net-works [10], and VINI, a research virtual network infrastruc-ture overlaid on top of National Lambda Rail and Inter-net2 [32]. In such cases, a single-hop link in the overlaynetwork is actually a multi-hop path in the underlying net-work, which can be an MPLS VPN (e.g., CSC) or an IPnetwork (e.g., VINI). Link migration in an MPLS transportnetwork involves switching over to a newly established labelswitched path (LSP). Link migration in an IP network canbe done by changing the IP address of the tunnel end point.
2.2 Related WorkVROOM’s motivation is similar, in part, to that of the
RouterFarm work [3], namely, to reduce the impact of plannedmaintenance by migrating router functionality from one placein the network to another. However, RouterFarm essen-tially performs a “cold restart”, compared to VROOM’s live(“hot”) migration. Specifically, in RouterFarm router migra-tion is realized by re-instantiating a router instance at thenew location, which not only requires router reconfiguration,but also introduces inevitable downtime in both the controland data planes. In VROOM, on the other hand, we performlive router migration without reconfiguration or discernibledisruption. In our earlier prototype of VROOM [33], routermigration was realized by directly using the standard virtualmachine migration capability provided by Xen [4], whichlacked the control and data plane separation presented inthis paper. As a result, it involved data-plane downtimeduring the migration process.
Recent advances in virtual machine technologies and theirlive migration capabilities [12, 24] have been leveraged inserver-management tools, primarily in data centers. For ex-ample, Sandpiper [35] automatically migrates virtual serversacross a pool of physical servers to alleviate hotspots. Usher [22]allows administrators to express a variety of policies for
managing clusters of virtual servers. Remus [13] uses asyn-chronous virtual machine replication to provide high avail-ability to server in the face of hardware failures. In contrast,VROOM focuses on leveraging live migration techniques tosimplify management in the networking domain.
Network virtualization has been proposed in various con-texts. Early work includes the“switchlets” concept, in whichATM switches are partitioned to enable dynamic creationof virtual networks [31]. More recently, the CABO archi-tecture proposes to use virtualization as a means to enablemultiple service providers to share the same physical infras-tructure [16]. Outside the research community, router vir-tualization has already become available in several forms incommercial routers [11, 20]. In VROOM, we take an ad-ditional step not only to virtualize the router functionality,but also to decouple the virtualized router from its physicalhost and enable it to migrate.
VROOM also relates to recent work on minimizing tran-sient routing disruptions during planned maintenance. Ameasurement study of a large ISP showed that more thanhalf of routing changes were planned in advance [19]. Net-work operators can limit the disruption by reconfiguring therouting protocols to direct traffic away from the equipmentundergoing maintenance [30, 17]. In addition, extensionsto the routing protocols can allow a router to continue for-warding packets in the data plane while reinstalling or re-booting the control-plane software [29, 8]. However, thesetechniques require changes to the logical configuration or therouting software, respectively. In contrast, VROOM hidesthe effects of physical topology changes in the first place,obviating the need for point solutions that increase systemcomplexity while enabling new network-management capa-bilities, as discussed in the next section.
3. NETWORK MANAGEMENT TASKSIn this section, we present three case studies of the ap-
plications of VROOM. We show that the separation be-tween physical and logical, and the router migration ca-pability enabled by VROOM, can greatly simplify existingnetwork-management tasks. It can also provide network-management solutions to other emerging challenges. We ex-plain why the existing solutions (in the first two examples)are not satisfactory and outline the VROOM approach toaddressing the same problems.
3.1 Planned MaintenancePlanned maintenance is a hidden fact of life in every net-
work. However, the state-of-the-art practices are still unsat-isfactory. For example, software upgrades today still requirerebooting the router and re-synchronizing routing protocolstates from neighbors (e.g., BGP routes), which can leadto outages of 10-15 minutes [3]. Different solutions havebeen proposed to reduce the impact of planned maintenanceon network traffic, such as “costing out” the equipment inadvance. Another example is the RouterFarm approach ofremoving the static binding between customers and accessrouters to reduce service disruption time while performingmaintenance on access routers [3]. However, we argue thatneither solution is satisfactory, since maintenance of physicalrouters still requires changes to the logical network topology,and requires (often human interactive) reconfigurations androuting protocol reconvergence. This usually implies moreconfiguration errors [21] and increased network instability.

We performed an analysis of planned-maintenance eventsconducted in a Tier-1 ISP backbone over a one-week period.Due to space limitations, we only mention the high-levelresults that are pertinent to VROOM here. Our analysisindicates that, among all the planned-maintenance eventsthat have undesirable network impact today (e.g., routingprotocol reconvergence or data-plane disruption), 70% couldbe conducted without any network impact if VROOM wereused. (This number assumes migration between routerswith control planes of like kind. With more sophisticatedmigration strategies, e.g., where a “control-plane hypervi-sor” allows migration between routers with different con-trol plane implementations, the number increases to 90%.)These promising numbers result from the fact that mostplanned-maintenance events were hardware related and, assuch, did not intend to make any longer-term changes to thelogical-layer configurations.
To perform planned maintenance tasks in a VROOM-enabled network, network administrators can simply migrateall the virtual routers running on a physical router to otherphysical routers before doing maintenance and migrate themback afterwards as needed, without ever needing to reconfig-ure any routing protocols or worry about traffic disruptionor protocol reconvergence.
3.2 Service Deployment and EvolutionDeploying new services, like IPv6 or IPTV, is the life-
blood of any ISP. Yet, ISPs must exercise caution when de-ploying these new services. First, they must ensure thatthe new services do not adversely impact existing services.Second, the necessary support systems need to be in placebefore services can be properly supported. (Support sys-tems include configuration management, service monitoring,provisioning, and billing.) Hence, ISPs usually start with asmall trial running in a controlled environment on dedicatedequipment, supporting a few early-adopter customers. How-ever, this leads to a “success disaster” when the service war-rants wider deployment. The ISP wants to offer seamlessservice to its existing customers, and yet also restructuretheir test network, or move the service onto a larger net-work to serve a larger set of customers. This “trial systemsuccess” dilemma is hard to resolve if the logical notion of a“network node” remains bound to a specific physical router.
VROOM provides a simple solution by enabling networkoperators to freely migrate virtual routers from the trialsystem to the operational backbone. Rather than shuttingdown the trial service, the ISP can continue supporting theearly-adopter customers while continuously growing the trialsystem, attracting new customers, and eventually seamlesslymigrating the entire service to the operational network.
ISPs usually deploy such service-oriented routers as closeto their customers as possible, in order to avoid backhaultraffic. However, as the services grow, the geographical dis-tribution of customers may change over time. With VROOM,ISPs can easily reallocate the routers to adapt to new cus-tomer demands.
3.3 Power SavingsVROOM not only provides simple solutions to conven-
tional network-management tasks, but also enables new so-lutions to emerging challenges such as power management.It was reported that in 2000 the total power consumption ofthe estimated 3.26 million routers in the U.S. was about 1.1
TWh (Tera-Watt hours) [28]. This number was expected togrow to 1.9 to 2.4TWh in the year 2005 [28], which translatesinto an annual cost of about 178-225 million dollars [25].These numbers do not include the power consumption ofthe required cooling systems.
Although designing energy-efficient equipment is clearlyan important part of the solution [18], we believe that net-work operators can also manage a network in a more power-efficient manner. Previous studies have reported that Inter-net traffic has a consistent diurnal pattern caused by humaninteractive network activities. However, today’s routers aresurprisingly power-insensitive to the traffic loads they arehandling—an idle router consumes over 90% of the powerit requires when working at maximum capacity [7]. We ar-gue that, with VROOM, the variations in daily traffic vol-ume can be exploited to reduce power consumption. Specif-ically, the size of the physical network can be expanded andshrunk according to traffic demand, by hibernating or pow-ering down the routers that are not needed. The best wayto do this today would be to use the “cost-out/cost-in” ap-proach, which inevitably introduces configuration overheadand performance disruptions due to protocol reconvergence.
VROOM provides a cleaner solution: as the network traf-fic volume decreases at night, virtual routers can be mi-grated to a smaller set of physical routers and the unneededphysical routers can be shut down or put into hibernationto save power. When the traffic starts to increase, phys-ical routers can be brought up again and virtual routerscan be migrated back accordingly. With VROOM, the IP-layer topology stays intact during the migrations, so thatpower savings do not come at the price of user traffic dis-ruption, reconfiguration overhead or protocol reconvergence.Our analysis of data traffic volumes in a Tier-1 ISP back-bone suggests that, even if only migrating virtual routerswithin the same POP while keeping the same link utiliza-tion rate, applying the above VROOM power managementapproach could save 18%-25% of the power required to runthe routers in the network. As discussed in Section 7, al-lowing migration across different POPs could result in moresubstantial power savings.
4. VROOM ARCHITECTUREIn this section, we present the VROOM architecture. We
first describe the three building-blocks that make virtualrouter migration possible—router virtualization, control anddata plane separation, and dynamic interface binding. Wethen present the VROOM router migration process. Un-like regular servers, modern routers typically have physicallyseparate control and data planes. Leveraging this uniqueproperty, we introduce a data-plane hypervisor between thecontrol and data planes that enables virtual routers to mi-grate across different data-plane platforms. We describe indetail the three migration techniques that minimize control-plane downtime and eliminate data-plane disruption—data-plane cloning, remote control plane, and double data planes.
4.1 Making Virtual Routers MigratableFigure 2 shows the architecture of a VROOM router that
supports virtual router migration. It has three importantfeatures that make migration possible: router virtualization,control and data plane separation, and dynamic interfacebinding, all of which already exist in some form in today’shigh-end commercial routers.

VR1
Physical Router A
Physical Router B
VR1
Physical Router A Physical Router A
data traffic (flow 1)
Physical Router A
routing messages
(a) Tunnel setup for redirecting routing messages
( t0 - t1 )
(b) Remote control plane withredirection of routing messages
( t4 - t5 )
(c) Double data planes duringasynchronous link migration
( t5 - t6 )
(d) Remove old data plane and redirection tunnels
( t6 )
data traffic (flow 2)
Physical Router B
VR1
Physical Router B
VR1
Physical Router B
redirection of routing messages
Figure 3: VROOM’s novel router migration mechanisms (the times at the bottom of the subfigures correspondto those in Figure 4)
Physical Router
Substrate
Dynamic interface binding
Physical interface
(2)
(2)
Data Plane
Control Plane
Virtual Router
Control Plane
Virtual Router
Control Plane
Virtual Router
Data Plane
Data Plane
(1)
Data-plane hypervisor(1)
Tunnel interface
Figure 2: The architecture of a VROOM router
Router Virtualization: A VROOM router partitions theresources of a physical router to support multiple virtualrouter instances. Each virtual router runs independentlywith its own control plane (e.g., applications, configura-tions, routing protocol instances and routing informationbase (RIB)) and data plane (e.g., interfaces and forwardinginformation base (FIB)). Such router virtualization supportis already available in some commercial routers [11, 20]. Theisolation between virtual routers makes it possible to migrateone virtual router without affecting the others.Control and Data Plane Separation: In a VROOMrouter, the control and data planes run in separate environ-ments. As shown in Figure 2, the control planes of virtualrouters are hosted in separate “containers” (or “virtual envi-ronments”), while their data planes reside in the substrate,where each data plane is kept in separate data structureswith its own state information, such as FIB entries and ac-cess control lists (ACLs). Similar separation of control anddata planes already exists in today’s commercial routers,with control plane running on the CPU(s) and main memory,while the data plane runs on line cards that have their owncomputing power (for packet forwarding) and memory (tohold the FIBs). This separation allows VROOM to migratethe control and data planes of a virtual router separately (asdiscussed in Section 4.2.1 and 4.2.2).Dynamic Interface Binding: To enable router migrationand link migration, a VROOM router should be able to dy-
router-image copy
memory copy
asynchronous link migration
data-plane cloning
stall-and-copy (control plane downtime)
t2 timet0 t1 t3 t5 t6
old nodecontrol plane
data plane
new node
old node
new node
remote control plane
double data
planes2
1 2 3 4 5
1 tunnel setup
3
4
5pre-copy
3-1 3-2
3-1:3-2:
t4
steps
Figure 4: VROOM’s router migration process
namically set up and change the binding between a virtualrouter’s FIB and its substrate interfaces (which can be phys-ical or tunnel interfaces), as shown in Figure 2. Given theexisting interface binding mechanism in today’s routers thatmaps interfaces with virtual routers, VROOM only requirestwo simple extensions. First, after a virtual router is mi-grated, this binding needs to be re-established dynamicallyon the new physical router. This is essentially the same asif this virtual router were just instantiated on the physicalrouter. Second, link migration in a packet-aware transportnetwork involves changing tunnel interfaces in the router, asshown in Figure 1. In this case, the router substrate needsto switch the binding from the old tunnel interface to thenew one on-the-fly1.
4.2 Virtual Router Migration ProcessFigures 3 and 4 illustrate the VROOM virtual router mi-
gration process. The first step in the process involves es-tablishing tunnels between the source physical router A anddestination physical router B of the migration (Figure 3(a)).These tunnels allow the control plane to send and receiverouting messages after it is migrated (steps 2 and 3) but be-fore link migration (step 5) completes. They also allow themigrated control plane to keep its data plane on A up-to-date (Figure 3(b)). Although the control plane will experi-
1In the case of a programmable transport network, link mi-gration happens inside the transport network and is trans-parent to the routers.

ence a short period of downtime at the end of step 3 (memorycopy), the data plane continues working during the entiremigration process. In fact, after step 4 (data-plane cloning),the data planes on both A and B can forward traffic si-multaneously (Figure 3(c)). With these double data planes,links can be migrated from A to B in an asynchronous fash-ion (Figure 3(c) and (d)), after which the data plane on Acan be disabled (Figure 4). We now describe the migrationmechanisms in greater detail.
4.2.1 Control-Plane MigrationTwo things need to be taken care of when migrating the
control plane: the router image, such as routing-protocolbinaries and network configuration files, and the memory,which includes the states of all the running processes. Whencopying the router image and memory, it is desirable to min-imize the total migration time, and more importantly, tominimize the control-plane downtime (i.e., the time betweenwhen the control plane is check-pointed on the source nodeand when it is restored on the destination node). This is be-cause, although routing protocols can usually tolerate a briefnetwork glitch using retransmission (e.g., BGP uses TCPretransmission, while OSPF uses its own reliable retrans-mission mechanism), a long control-plane outage can breakprotocol adjacencies and cause protocols to reconverge.
We now describe how VROOM leverages virtual machine(VM) migration techniques to migrate the control plane insteps 2 (router-image copy) and 3 (memory copy) of its mi-gration process, as shown in Figure 4.
Unlike general-purpose VMs that can potentially be run-ning completely different programs, virtual routers from thesame vendor run the same (usually small) set of programs(e.g., routing protocol suites). VROOM assumes that thesame set of binaries are already available on every physi-cal router. Before a virtual router is migrated, the bina-ries are locally copied to its file system on the destinationnode. Therefore, only the router configuration files need tobe copied over the network, reducing the total migrationtime (as local-copy is usually faster than network-copy).
The simplest way to migrate the memory of a virtualrouter is to check-point the router, copy the memory pagesto the destination, and restore the router, a.k.a. stall-and-copy [24]. This approach leads to downtime that is propor-tional to the memory size of the router. A better approachis to add an iterative pre-copy phase before the final stall-and-copy [12], as shown in Figure 4. All pages are trans-ferred in the first round of the pre-copy phase, and in thefollowing rounds, only pages that were modified during theprevious round are transferred. This pre-copy technique re-duces the number of pages that need to be transfered in thestall-and-copy phase, reducing the control plane downtimeof the virtual router (i.e., the control plane is only “frozen”between t3 and t4 in Figure 4).
4.2.2 Data-Plane CloningThe control-plane migration described above could be ex-
tended to migrate the data plane, i.e., copy all data-planestates over to the new physical node. However, this approachhas two drawbacks. First, copying the data-plane states(e.g., FIB and ACLs) is unnecessary and wasteful, becausethe information that is used to generate these states (e.g.,RIB and configuration files) is already available in the con-trol plane. Second, copying the data-plane state directly can
be difficult if the source and destination routers use differentdata-plane technologies. For example, some routers may useTCAM (ternary content-addressable memory) in their dataplanes, while others may use regular SRAM. As a result, thedata structures that hold the state may be different.
VROOM formalizes the interface between the control anddata planes by introducing a data-plane hypervisor, whichallows a migrated control plane to re-instantiate the dataplane on the new platform, a process we call data-planecloning. That is, only the control plane of the router isactually migrated. Once the control plane is migrated tothe new physical router, it clones its original data plane byrepopulating the FIB using its RIB and reinstalling ACLsand other data-plane states2 through the data-plane hyper-visor (as shown in Figure 2). The data-plane hypervisorprovides a unified interface to the control plane that hidesthe heterogeneity of the underlying data-plane implementa-tions, enabling virtual routers to migrate between differenttypes of data planes.
4.2.3 Remote Control PlaneAs shown in Figure 3(b), after VR1’s control plane is mi-
grated from A to B, the natural next steps are to repopu-late (clone) the data plane on B and then migrate the linksfrom A to B. Unfortunately, the creation of the new dataplane can not be done instantaneously, primarily due to thetime it takes to install FIB entries. Installing one FIB en-try typically takes between one hundred and a few hundredmicroseconds [5]; therefore, installing the full Internet BGProuting table (about 250k routes) could take over 20 sec-onds. During this period of time, although data traffic canstill be forwarded by the old data plane on A, all the rout-ing instances in VR1’s control plane can no longer send orreceive routing messages. The longer the control plane re-mains unreachable, the more likely it will lose its protocoladjacencies with its neighbors.
To overcome this dilemma, A’s substrate starts redirect-ing all the routing messages destined to VR1 to B at theend of the control-plane migration (time t4 in Figure 4).This is done by establishing a tunnel between A and B foreach of VR1’s substrate interfaces. To avoid introducing anyadditional downtime in the control plane, these tunnels areestablished before the control-plane migration, as shown inFigure 3(a). With this redirection mechanism, VR1’s con-trol plane not only can exchange routing messages with itsneighbors, it can also act as the remote control plane forits old data plane on A and continue to update the old FIBwhen routing changes happen.
4.2.4 Double Data PlanesIn theory, at the end of the data-plane cloning step, VR1
can switch from the old data plane on A to the new oneon B by migrating all its links from A to B simultaneously.However, performing accurate synchronous link migrationacross all the links is challenging, and could significantlyincrease the complexity of the system (because of the needto implement a synchronization mechanism).
Fortunately, because VR1 has two data planes ready to
2Data dynamically collected in the old data plane (suchas NetFlow) can be copied and merged with the new one.Other path-specific statistics (such as queue length) will bereset as the previous results are no longer meaningful oncethe physical path changes.

zebra
Quagga
kernel routing table
iproute2
bgpd ospfd shadowd
VE1
shadowd
VE2
shadowd
VE3
virtd
Control plane
Data plane
table1 table2 table3
VE0(the root context)
bindd
Linuxor
NetFPGA
Figure 5: The design of the VROOM prototyperouters (with two types of data planes)
forward traffic at the end of the data-plane cloning step (Fig-ure 4), the migration of its links does not need to happenall at once. Instead, each link can be migrated independentof the others, in an asynchronous fashion, as shown in Fig-ure 3(c) and (d). First, router B creates a new outgoing linkto each of VR1’s neighbors, while all data traffic continuesto flow through router A. Then, the incoming links can besafely migrated asynchronously, with some traffic starting toflow through router B while the remaining traffic still flowsthrough router A. Finally, once all of VR1’s links are mi-grated to router B, the old data plane and outgoing links onA, as well as the temporary tunnels, can be safely removed.
5. PROTOTYPE IMPLEMENTATIONIn this section, we present the implementation of two
VROOM prototype routers. The first is built on commod-ity PC hardware and the Linux-based virtualization solutionOpenVZ [24]. The second is built using the same softwarebut utilizing the NetFPGA platform [23] as the hardwaredata plane. We believe the design presented here is readilyapplicable to commercial routers, which typically have thesame clean separation between the control and data planes.
Our prototype implementation consists of three new pro-grams, as shown in Figure 5. These include virtd, to enablepacket forwarding outside of the virtual environment (con-trol and data plane separation); shadowd, to enable eachVE to install routes into the FIB; and bindd (data planecloning), to provide the bindings between the physical inter-faces and the virtual interfaces and FIB of each VE (data-plane hypervisor). We first discuss the mechanisms thatenable virtual router migration in our prototypes and thenpresent the additional mechanisms we implemented that re-alize the migration.
5.1 Enabling Virtual Router MigrationWe chose to use OpenVZ [24], a Linux-based OS-level vir-
tualization solution, as the virtualization environment forour prototypes. As running multiple operating systems fordifferent virtual routers is unnecessary, the lighter-weightOS-level virtualization is better suited to our need thanother virtualization techniques, such as full virtualizationand para-virtualization. In OpenVZ, multiple virtual envi-ronments (VEs) running on the same host share the same
kernel, but have separate virtualized resources such as namespaces, process trees, devices, and network stacks. OpenVZalso provides live migration capability for running VEs3.
In the rest of this subsection, we describe in a top-downorder the three components of our two prototypes that en-able virtual router migration. We first present the mecha-nism that separates the control and data planes, and thendescribe the data-plane hypervisor that allows the controlplanes to update the FIBs in the shared data plane. Finally,we describe the mechanisms that dynamically bind the in-terfaces with the FIBs and set up the data path.
5.1.1 Control and Data Plane SeparationTo mimic the control and data plane separation provided
in commercial routers, we move the FIBs out of the VEs andplace them in a shared but virtualized data plane, as shownin Figure 5. This means that packet forwarding no longerhappens within the context of each VE, so it is unaffectedwhen the VE is migrated.
As previously mentioned, we have implemented two proto-types with different types of data planes—a software-baseddata plane (SD) and a hardware-based data plane (HD). Inthe SD prototype router, the data plane resides in the rootcontext (or “VE0”) of the system and uses the Linux kernelfor packet forwarding. Since the Linux kernel (2.6.18) sup-ports 256 separate routing tables, the SD router virtualizesits data plane by associating each VE with a different kernelrouting table as its FIB.
In the HD router implementation, we use the NetFPGAplatform configured with the reference router provided byStanford [23]. The NetFPGA card is a 4-port gigabit eth-ernet PCI card with a Virtex 2-Pro FPGA on it. With theNetFPGA as the data plane, packet forwarding in the HDrouter does not use the host CPU, thus more closely resem-bling commercial router architectures. The NetFPGA ref-erence router does not currently support virtualization. Asa result, our HD router implementation is currently limitedto only one virtual router per physical node.
5.1.2 Data-Plane HypervisorAs explained in Section 4, VROOM extends the stan-
dard control plane/data plane interface to a migration-awaredata-plane hypervisor. Our prototype presents a rudimen-tary data-plane hypervisor implementation which only sup-ports FIB updates. (A full-fledged data-plane hypervisorwould also allow the configuration of other data plane states.)We implemented the virtd program as the data-plane hy-pervisor. virtd runs in the VE0 and provides an interfacefor virtual routers to install/remove routes in the shareddata plane, as shown in Figure 5. We also implemented theshadowd program that runs inside each VE and pushes routeupdates from the control plane to the FIB through virtd.
We run the Quagga routing software suite [26] as the con-trol plane inside each VE. Quagga supports many routingprotocols, including BGP and OSPF. In addition to the in-cluded protocols, Quagga provides an interface in zebra,its routing manager, to allow the addition of new protocoldaemons. We made use of this interface to implement shad-owd as a client of zebra. zebra provides clients with both
3The current OpenVZ migration function uses the simple“stall-and-copy” mechanism for memory migration. Includ-ing a “pre-copy” stage [12] in the process will reduce themigration downtime.

the ability to notify zebra of route changes and to be noti-fied of route changes. As shadowd is not a routing protocolbut simply a shadowing daemon, it uses only the route re-distribution capability. Through this interface, shadowd isnotified of any changes in the RIB and immediately mirrorsthem to virtd using remote procedure calls (RPCs). Eachshadowd instance is configured with a unique ID (e.g., theID of the virtual router), which is included in every messageit sends to virtd. Based on this ID, virtd can correctlyinstall/remove routes in the corresponding FIB upon receiv-ing updates from a shadowd instance. In the SD prototype,this involves using the Linux iproute2 utility to set a rout-ing table entry. In the HD prototype, this involves using thedevice driver to write to registers in the NetFPGA.
5.1.3 Dynamic Interface BindingWith the separation of control and data planes, and the
sharing of the same data plane among multiple virtual routers,the data path of each virtual router must be set up properlyto ensure that (i) data packets can be forwarded accordingto the right FIB, and (ii) routing messages can be deliveredto the right control plane.
We implemented the bindd program that meets these re-quirements by providing two main functions. The first isto set up the mapping between a virtual router’s substrateinterfaces and its FIB after the virtual router is instantiatedor migrated, to ensure correct packet forwarding. (Note thata virtual router’s substrate interface could be either a ded-icated physical interface or a tunnel interface that sharesthe same physical interface with other tunnels.) In the SDprototype, bindd establishes this binding by using the rout-ing policy management function (i.e., “ip rule”) provided bythe Linux iproute2 utility. As previously mentioned, theHD prototype is currently limited to a single table. OnceNetFPGA supports virtualization, a mechanism similar tothe “ip rule” function can be used to bind the interfaces withthe FIBs.
The second function of bindd is to bind the substrate in-terfaces with the virtual interfaces of the control plane. Inboth prototypes, this binding is achieved by connecting eachpair of substrate and virtual interfaces to a different bridgeusing the Linux brctl utility. In the HD prototype, eachof the four physical ports on the NetFPGA is presented toLinux as a separate physical interface, so packets destinedto the control plane of a local VE are passed from the NetF-PGA to Linux through the corresponding interface.
5.2 Realizing Virtual Router MigrationThe above mechanisms set the foundation for VROOM
virtual router migration in the OpenVZ environment. Wenow describe the implementations of data-plane cloning, re-mote control plane, and double data planes.
Although migration is transparent to the routing pro-cesses running in the VE, shadowd needs to be notified at theend of the control plane migration in order to start the“dataplane cloning”. We implemented a function in shadowd that,when called, triggers shadowd to request zebra to resend allthe routes and then push them down to virtd to repopu-late the FIB. Note that virtd runs on a fixed (private) IPaddress and a fixed port on each physical node. Therefore,after a virtual router is migrated to a new physical node, theroute updates sent by its shadowd can be seamlessly routedto the local virtd instance on the new node.
To enable a migrated control plane to continue updatingthe old FIB (i.e., to act as a “remote control plane”), weimplemented in virtd the ability to forward route updatesto another virtd instance using the same RPC mechanismthat is used by shadowd. As soon as virtual router VR1 ismigrated from node A to node B, the migration script no-tifies the virtd instance on B of A’s IP address and VR1’sID. B’s virtd, besides updating the new FIB, starts for-warding the route updates from VR1’s control plane to A,whose virtd then updates VR1’s old FIB. After all of VR1’slinks are migrated, the old data plane is no longer used, soB’s virtd is notified to stop forwarding updates. With B’svirtd updating both the old and new FIBs of VR1 (i.e.,the “double data planes”), the two data planes can forwardpackets during the asynchronous link migration process.
Note that the data-plane hypervisor implementation makesthe the control planes unaware of the details of a particularunderlying data plane. As as result, migration can occurbetween any combination of our HD and SD prototypes (i.e.SD to SD, HD to HD, SD to HD, and HD to SD).
6. EVALUATIONIn this section, we evaluate the performance of VROOM
using our SD and HD prototype routers. We first measurethe performance of the basic functions of the migration pro-cess individually, and then place a VROOM router in a net-work and evaluate the effect its migration has on the dataand control planes. Specifically, we answer the following twoquestions:
1. What is the impact of virtual router migration on dataforwarding? Our evaluation shows that it is important tohave bandwidth isolation between migration traffic and datatraffic. With separate bandwidth, migration based on anHD router has no performance impact on data forwarding.Migration based on a SD router introduces minimal delayincrease and no packet loss to data traffic.
2. What is the impact of virtual router migration on rout-ing protocols? Our evaluation shows that a virtual routerrunning only OSPF in an Abilene-topology network can sup-port 1-second OSPF hello-interval without losing protocoladjacencies during migration. The same router loaded withan additional full Internet BGP routing table can supporta minimal OSPF hello-interval of 2 seconds without losingOSPF or BGP adjacencies.
6.1 MethodologyOur evaluation involved experiments conducted in the Em-
ulab tesbed [15]. We primarily used PC3000 machines as thephysical nodes in our experiments. The PC3000 is an IntelXeon 3.0 GHz 64-bit platform with 2GB RAM and five Gi-gabit Ethernet NICs. For the HD prototype, each physicalnode was additionally equipped with a NetFPGA card. Allnodes in our experiments were running an OpenVZ patchedLinux kernel 2.6.18-ovz028stab049.1. For a few experimentswe also used the lower performance PC850 physical nodes,built on an Intel Pentium III 850MHz platform with 512MBRAM and five 100Mbps Ethernet NICs.
We used three different testbed topologies in our experi-ments:The diamond testbed: We use the 4-node diamond-topologytestbed (Figure 6) to evaluate the performance of individualmigration functions and the impact of migration on the dataplane. The testbed has two different configurations, which
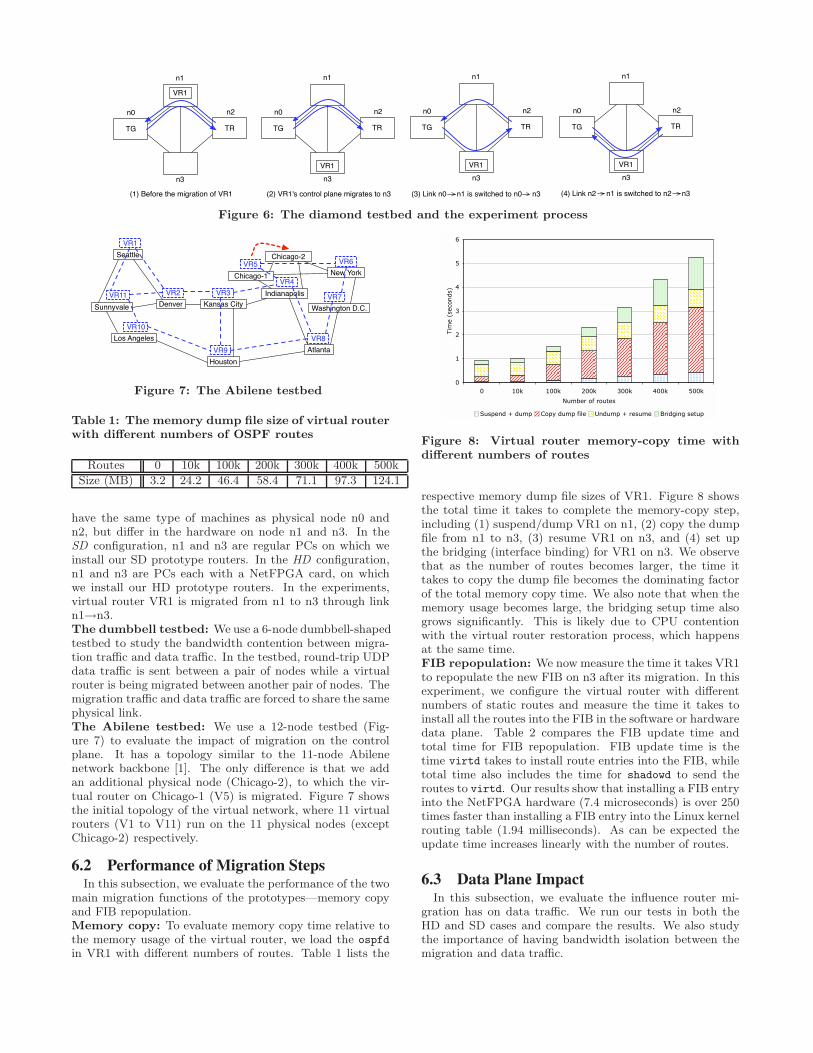
TG TR
n0
n1
n2
n3
VR1
TG TR
n0
n1
n2
n3
VR1
TG TR
n0
n1
n2
n3
VR1
TG TR
n0
n1
n2
n3
VR1
(1) Before the migration of VR1 (2) VR1's control plane migrates to n3 (3) Link n0 n1 is switched to n0 n3 (4) Link n2 n1 is switched to n2 n3
Figure 6: The diamond testbed and the experiment process
Seattle
Sunnyvale
Los Angeles
Kansas CityDenver
Houston
Chicago-1
Indianapolis
Chicago-2
New York
Washington D.C.
Atlanta
VR1
VR2 VR3
VR4
VR5 VR6
VR7
VR8
VR9
VR10
VR11
Figure 7: The Abilene testbed
Table 1: The memory dump file size of virtual routerwith different numbers of OSPF routes
Routes 0 10k 100k 200k 300k 400k 500k
Size (MB) 3.2 24.2 46.4 58.4 71.1 97.3 124.1
have the same type of machines as physical node n0 andn2, but differ in the hardware on node n1 and n3. In theSD configuration, n1 and n3 are regular PCs on which weinstall our SD prototype routers. In the HD configuration,n1 and n3 are PCs each with a NetFPGA card, on whichwe install our HD prototype routers. In the experiments,virtual router VR1 is migrated from n1 to n3 through linkn1→n3.The dumbbell testbed: We use a 6-node dumbbell-shapedtestbed to study the bandwidth contention between migra-tion traffic and data traffic. In the testbed, round-trip UDPdata traffic is sent between a pair of nodes while a virtualrouter is being migrated between another pair of nodes. Themigration traffic and data traffic are forced to share the samephysical link.The Abilene testbed: We use a 12-node testbed (Fig-ure 7) to evaluate the impact of migration on the controlplane. It has a topology similar to the 11-node Abilenenetwork backbone [1]. The only difference is that we addan additional physical node (Chicago-2), to which the vir-tual router on Chicago-1 (V5) is migrated. Figure 7 showsthe initial topology of the virtual network, where 11 virtualrouters (V1 to V11) run on the 11 physical nodes (exceptChicago-2) respectively.
6.2 Performance of Migration StepsIn this subsection, we evaluate the performance of the two
main migration functions of the prototypes—memory copyand FIB repopulation.Memory copy: To evaluate memory copy time relative tothe memory usage of the virtual router, we load the ospfd
in VR1 with different numbers of routes. Table 1 lists the
0
1
2
3
4
5
6
0 10k 100k 200k 300k 400k 500k
Number of routes
Tim
e (
seconds)
Suspend + dump Copy dump file Undump + resume Bridging setup
Figure 8: Virtual router memory-copy time withdifferent numbers of routes
respective memory dump file sizes of VR1. Figure 8 showsthe total time it takes to complete the memory-copy step,including (1) suspend/dump VR1 on n1, (2) copy the dumpfile from n1 to n3, (3) resume VR1 on n3, and (4) set upthe bridging (interface binding) for VR1 on n3. We observethat as the number of routes becomes larger, the time ittakes to copy the dump file becomes the dominating factorof the total memory copy time. We also note that when thememory usage becomes large, the bridging setup time alsogrows significantly. This is likely due to CPU contentionwith the virtual router restoration process, which happensat the same time.FIB repopulation: We now measure the time it takes VR1to repopulate the new FIB on n3 after its migration. In thisexperiment, we configure the virtual router with differentnumbers of static routes and measure the time it takes toinstall all the routes into the FIB in the software or hardwaredata plane. Table 2 compares the FIB update time andtotal time for FIB repopulation. FIB update time is thetime virtd takes to install route entries into the FIB, whiletotal time also includes the time for shadowd to send theroutes to virtd. Our results show that installing a FIB entryinto the NetFPGA hardware (7.4 microseconds) is over 250times faster than installing a FIB entry into the Linux kernelrouting table (1.94 milliseconds). As can be expected theupdate time increases linearly with the number of routes.
6.3 Data Plane ImpactIn this subsection, we evaluate the influence router mi-
gration has on data traffic. We run our tests in both theHD and SD cases and compare the results. We also studythe importance of having bandwidth isolation between themigration and data traffic.
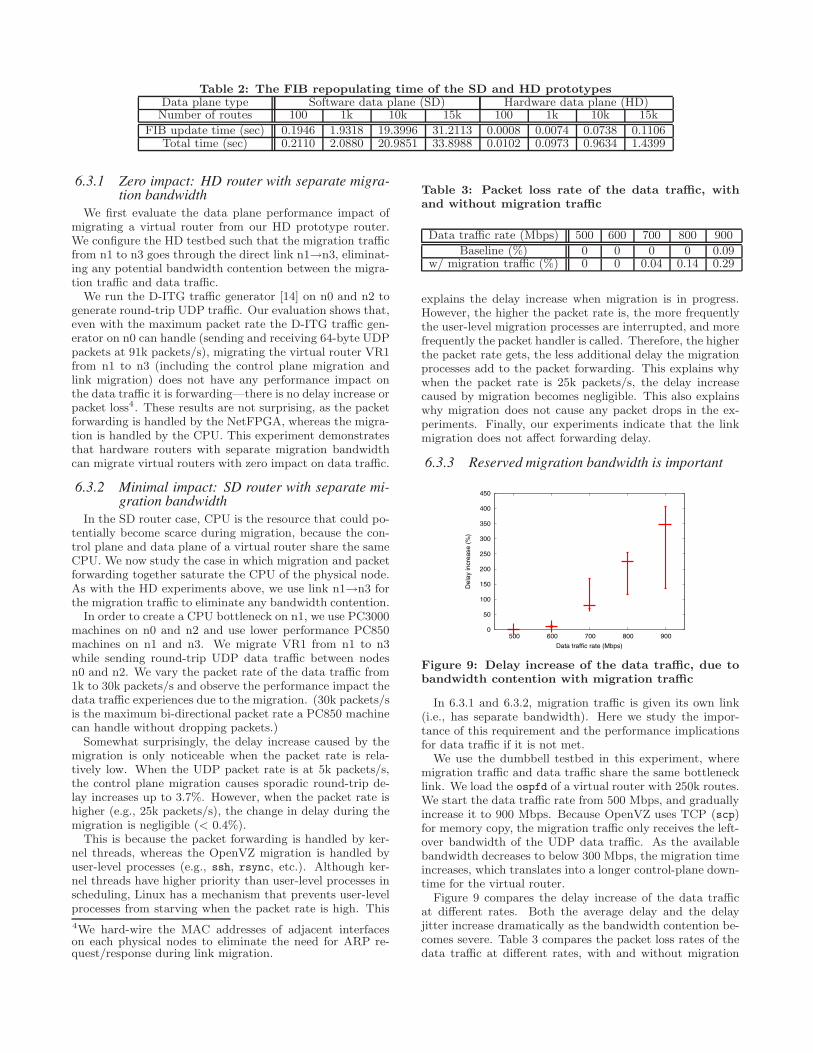
Table 2: The FIB repopulating time of the SD and HD prototypesData plane type Software data plane (SD) Hardware data plane (HD)Number of routes 100 1k 10k 15k 100 1k 10k 15k
FIB update time (sec) 0.1946 1.9318 19.3996 31.2113 0.0008 0.0074 0.0738 0.1106Total time (sec) 0.2110 2.0880 20.9851 33.8988 0.0102 0.0973 0.9634 1.4399
6.3.1 Zero impact: HD router with separate migra-tion bandwidth
We first evaluate the data plane performance impact ofmigrating a virtual router from our HD prototype router.We configure the HD testbed such that the migration trafficfrom n1 to n3 goes through the direct link n1→n3, eliminat-ing any potential bandwidth contention between the migra-tion traffic and data traffic.
We run the D-ITG traffic generator [14] on n0 and n2 togenerate round-trip UDP traffic. Our evaluation shows that,even with the maximum packet rate the D-ITG traffic gen-erator on n0 can handle (sending and receiving 64-byte UDPpackets at 91k packets/s), migrating the virtual router VR1from n1 to n3 (including the control plane migration andlink migration) does not have any performance impact onthe data traffic it is forwarding—there is no delay increase orpacket loss4. These results are not surprising, as the packetforwarding is handled by the NetFPGA, whereas the migra-tion is handled by the CPU. This experiment demonstratesthat hardware routers with separate migration bandwidthcan migrate virtual routers with zero impact on data traffic.
6.3.2 Minimal impact: SD router with separate mi-gration bandwidth
In the SD router case, CPU is the resource that could po-tentially become scarce during migration, because the con-trol plane and data plane of a virtual router share the sameCPU. We now study the case in which migration and packetforwarding together saturate the CPU of the physical node.As with the HD experiments above, we use link n1→n3 forthe migration traffic to eliminate any bandwidth contention.
In order to create a CPU bottleneck on n1, we use PC3000machines on n0 and n2 and use lower performance PC850machines on n1 and n3. We migrate VR1 from n1 to n3while sending round-trip UDP data traffic between nodesn0 and n2. We vary the packet rate of the data traffic from1k to 30k packets/s and observe the performance impact thedata traffic experiences due to the migration. (30k packets/sis the maximum bi-directional packet rate a PC850 machinecan handle without dropping packets.)
Somewhat surprisingly, the delay increase caused by themigration is only noticeable when the packet rate is rela-tively low. When the UDP packet rate is at 5k packets/s,the control plane migration causes sporadic round-trip de-lay increases up to 3.7%. However, when the packet rate ishigher (e.g., 25k packets/s), the change in delay during themigration is negligible (< 0.4%).
This is because the packet forwarding is handled by ker-nel threads, whereas the OpenVZ migration is handled byuser-level processes (e.g., ssh, rsync, etc.). Although ker-nel threads have higher priority than user-level processes inscheduling, Linux has a mechanism that prevents user-levelprocesses from starving when the packet rate is high. This
4We hard-wire the MAC addresses of adjacent interfaceson each physical nodes to eliminate the need for ARP re-quest/response during link migration.
Table 3: Packet loss rate of the data traffic, withand without migration traffic
Data traffic rate (Mbps) 500 600 700 800 900
Baseline (%) 0 0 0 0 0.09w/ migration traffic (%) 0 0 0.04 0.14 0.29
explains the delay increase when migration is in progress.However, the higher the packet rate is, the more frequentlythe user-level migration processes are interrupted, and morefrequently the packet handler is called. Therefore, the higherthe packet rate gets, the less additional delay the migrationprocesses add to the packet forwarding. This explains whywhen the packet rate is 25k packets/s, the delay increasecaused by migration becomes negligible. This also explainswhy migration does not cause any packet drops in the ex-periments. Finally, our experiments indicate that the linkmigration does not affect forwarding delay.
6.3.3 Reserved migration bandwidth is important
0
50
100
150
200
250
300
350
400
450
500 600 700 800 900
Del
ay in
crea
se (
%)
Data traffic rate (Mbps)
Figure 9: Delay increase of the data traffic, due tobandwidth contention with migration traffic
In 6.3.1 and 6.3.2, migration traffic is given its own link(i.e., has separate bandwidth). Here we study the impor-tance of this requirement and the performance implicationsfor data traffic if it is not met.
We use the dumbbell testbed in this experiment, wheremigration traffic and data traffic share the same bottlenecklink. We load the ospfd of a virtual router with 250k routes.We start the data traffic rate from 500 Mbps, and graduallyincrease it to 900 Mbps. Because OpenVZ uses TCP (scp)for memory copy, the migration traffic only receives the left-over bandwidth of the UDP data traffic. As the availablebandwidth decreases to below 300 Mbps, the migration timeincreases, which translates into a longer control-plane down-time for the virtual router.
Figure 9 compares the delay increase of the data trafficat different rates. Both the average delay and the delayjitter increase dramatically as the bandwidth contention be-comes severe. Table 3 compares the packet loss rates of thedata traffic at different rates, with and without migration

traffic. Not surprisingly, bandwidth contention (i.e., datatraffic rate ≥ 700 Mbps) causes data packet loss. The aboveresults indicate that in order to minimize the control-planedowntime of the virtual router, and to eliminate the per-formance impact to data traffic, operators should provideseparate bandwidth for the migration traffic.
6.4 Control Plane ImpactIn this subsection, we investigate the control plane dynam-
ics introduced by router migration, especially how migrationaffects the protocol adjacencies. We assume a backbone net-work running MPLS, in which its edge routers run OSPFand BGP, while its core routers run only OSPF. Our resultsshow that, with default timers, protocol adjacencies of bothOSPF and BGP are kept intact, and at most one OSPF LSAretransmission is needed in the worst case.
6.4.1 Core Router MigrationWe configure virtual routers VR1, VR6, VR8 and VR10
on the Abilene testbed (Figure 7) as edge routers, and theremaining virtual routers as core routers. By migrating VR5from physical node Chicago-1 to Chicago-2, we observe theimpact of migrating a core router on OSPF dynamics.No events during migration: We first look at the case inwhich there are no network events during the migration. Ourexperiment results show that the control-plane downtime ofVR5 is between 0.924 and 1.008 seconds, with an average of0.972 seconds over 10 runs.
We start with the default OSPF timers of Cisco routers:hello-interval of 10 seconds and dead-interval of 40 seconds.We then reduce the hello-interval to 5, 2, and 1 second insubsequent runs, while keeping the dead-interval equal tofour times the hello-interval. We find that the OSPF adja-cencies between the migrating VR5 and its neighbors (VR4and VR6) stay up in all cases. Even in the most restrictive1-second hello-interval case, at most one OSPF hello mes-sage is lost and VR5 comes back up on Chicago-2 before itsneighbors’ dead timers expire.Events happen during migration: We then investigatethe case in which there are events during the migration andthe migrating router VR5 misses the LSAs triggered by theevents. We trigger new LSAs by flapping the link betweenVR2 and VR3. We observe that VR5 misses an LSA whenthe LSA is generated during VR5’s 1-second downtime. Insuch a case, VR5 gets a retransmission of the missing LSA 5seconds later, which is the default LSA retransmit-interval.
We then reduce the LSA retransmit-interval from 5 sec-onds to 1 second, in order to reduce the time that VR5 mayhave a stale view of the network. This change brings downthe maximum interval between the occurrence of a link flapand VR5’s reception of the resulting LSA to 2 seconds (i.e.,the 1 second control plane downtime plus the 1 second LSAretransmit-interval).
6.4.2 Edge Router MigrationHere we configure VR5 as the fifth edge router in the
network that runs BGP in addition to OSPF. VR5 receivesa full Internet BGP routing table with 255k routes (obtainedfrom RouteViewson Dec 12, 2007) from an eBGP peer thatis not included in Figure 7, and it forms an iBGP full meshwith the other four edge routers.
With the addition of a full BGP table, the memory dumpfile size grows from 3.2 MB to 76.0 MB. As a result, it takes
longer to suspend/dump the virtual router, copy over itsdump file, and resume it. The average downtime of the con-trol plane during migration increases to between 3.484 and3.594 seconds, with an average of 3.560 seconds over 10 runs.We observe that all of VR5’s BGP sessions stay intact dur-ing its migration. The minimal integer hello-interval VR5can support without breaking its OSPF adjacencies duringmigration is 2 seconds (with dead-interval set to 8 seconds).In practice, ISPs are unlikely to set the timers much lowerthan the default values, in order to shield themselves fromfaulty links or equipment.
7. MIGRATION SCHEDULINGThis paper primarily discusses the question of migration
mechanisms (“how to migrate”) for VROOM. Another im-portant question is the migration scheduling (“where to mi-grate”). Here we briefly discuss the constraints that needto be considered when scheduling migration and several op-timization problems that are part of our ongoing work onVROOM migration scheduling.
When deciding where to migrate a virtual router, sev-eral physical constraints need to be taken into considera-tion. First of all, an “eligible” destination physical routerfor migration must use a software platform compatible withthe original physical router, and have similar (or greater)capabilities (such as the number of access control lists sup-ported). In addition, the destination physical router musthave sufficient resources available, including processing power(whether the physical router is already hosting the max-imum number of virtual routers it can support) and linkcapacity (whether the links connected to the physical routerhave enough unused bandwidth to handle the migrating vir-tual router’s traffic load). Furthermore, the redundancy re-quirement of the virtual router also needs to be considered—today a router is usually connected to two different routers(one as primary and the other as backup) for redundancy.If the primary and backup are migrated to the same node,physical redundancy will be lost.
Fortunately, ISPs typically leave enough “head room” inlink capacities to absorb increased traffic volume. Addition-ally, most ISPs use routers from one or two vendors, witha small number of models, which leaves a large number ofeligible physical routers to be chosen for the migration.
Given a physical router that requires maintenance, thequestion of where to migrate the virtual routers it currentlyhosts can be formulated as an optimization problem, subjectto all the above constraints. Depending on the preferenceof the operator, different objectives can be used to pick thebest destination router, such as minimizing the overall CPUload of the physical router, minimizing the maximum loadof physical links in the network, minimizing the stretch (i.e.,latency increase) of virtual links introduced by the migra-tion, or maximizing the reliability of the network (e.g., theability to survive the failure of any physical node or link).However, finding optimal solutions to these problems maybe computationally intractable. Fortunately, simple local-search algorithms should perform reasonably well, since thenumber of physical routers to consider is limited (e.g., tohundreds or small thousands, even for large ISPs) and find-ing a “good” solution (rather than an optimal one) is accept-able in practice.
Besides migration scheduling for planned maintenance, weare also working on the scheduling problems of power sav-

ings and traffic engineering. In the case of power savings,we take the power prices in different geographic locationsinto account and try to minimize power consumption witha certain migration granularity (e.g., once every hour, ac-cording to the hourly traffic matrices). In the case of trafficengineering, we migrate virtual routers to shift load awayfrom congested physical links.
8. CONCLUSIONSVROOM is a new network-management primitive that
supports live migration of virtual routers from one physicalrouter to another. To minimize disruptions, VROOM allowsthe migrated control plane to clone the data-plane state atthe new location while continuing to update the state at theold location. VROOM temporarily forwards packets usingboth data planes to support asynchronous migration of thelinks. These designs are readily applicable to commercialrouter platforms. Experiments with our prototype systemdemonstrate that VROOM does not disrupt the data planeand only briefly freezes the control plane. In the unlikelyscenario that a control-plane event occurs during the freeze,the effects are largely hidden by existing mechanisms forretransmitting routing-protocol messages.
Our research on VROOM raises several broader questionsabout the design of future routers and the relationship withthe underlying transport network. Recent innovations intransport networks support rapid set-up and tear-down oflinks, enabling the network topology to change underneaththe IP routers. Dynamic topologies coupled with VROOM’smigration of the control plane and cloning of the data planemake the router an increasingly ephemeral concept, not tiedto a particular location or piece of hardware. Future workon router hypervisors could take this idea one step further.Just as today’s commercial routers have a clear separationbetween the control and data planes, future routers coulddecouple the control-plane software from the control-planestate (e.g., routing information bases). Such a“control-planehypervisor” would make it easier to upgrade router softwareand for virtual routers to migrate between physical routersthat run different code bases.
9. REFERENCES[1] The Internet2 Network. http://www.internet2.edu/.[2] T. Afferton, R. Doverspike, C. Kalmanek, and K. K.
Ramakrishnan. Packet-aware transport for metro networks.IEEE Communication Magazine, March 2004.
[3] M. Agrawal, S. Bailey, A. Greenberg, J. Pastor, P. Sebos,S. Seshan, J. van der Merwe, and J. Yates. RouterFarm:Towards a dynamic, manageable network edge. In Proc.ACM SIGCOMM Workshop on Internet NetworkManagement (INM), September 2006.
[4] P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris,A. Ho, R. Neugebar, I. Pratt, and A. Warfield. Xen and theArt of Virtualization. In Proc. SOSP, October 2003.
[5] O. Bonaventure, C. Filsfils, and P. Francois. Achievingsub-50 milliseconds recovery upon BGP peering linkfailures. IEEE/ACM Trans. Networking, October 2007.
[6] S. Bryant and P. Pate. Pseudo wire emulation edge-to-edge(PWE3) architecture. RFC 3985, March 2005.
[7] J. Chabarek, J. Sommers, P. Barford, C. Estan, D. Tsiang,and S. Wright. Power awareness in network design androuting. In Proc. IEEE INFOCOM, 2008.
[8] E. Chen, R. Fernando, J. Scudder, and Y. Rekhter.Graceful Restart Mechanism for BGP. RFC 4724, January2007.
[9] Ciena CoreDirector Switch. http://www.ciena.com.
[10] MPLS VPN Carrier Supporting Carrier.http://www.cisco.com/en/US/docs/ios/12_0st/12_0st14/feature/guide/csc.html.
[11] Cisco Logical Routers.http://www.cisco.com/en/US/docs/ios_xr_sw/iosxr_r3.2/interfaces/command/reference/hr32lr.html.
[12] C. Clark, K. Fraser, S. Hand, J. G. Hansen, E. Jul,C. Limpach, I. Pratt, and A. Warfield. Live Migration ofVirtual Machines. In Proc. NSDI, May 2005.
[13] B. Cully, G. Lefebvre, D. Meyer, M. Feeley, N. Hutchinson,and A. Warfield. Remus: High availability via asynchronousvirtual machine replication. In Proc. NSDI, April 2008.
[14] D-ITG. http://www.grid.unina.it/software/ITG/.[15] Emulab. http://www.emulab.net.[16] N. Feamster, L. Gao, and J. Rexford. How to lease the
Internet in your spare time. ACM SIGCOMM ComputerCommunications Review, Jan 2007.
[17] P. Francois, M. Shand, and O. Bonaventure.Disruption-free topology reconfiguration in OSPF networks.In Proc. IEEE INFOCOM, May 2007.
[18] M. Gupta and S. Singh. Greening of the Internet. In Proc.ACM SIGCOMM, August 2003.
[19] G. Iannaccone, C.-N. Chuah, S. Bhattacharyya, andC. Diot. Feasibility of IP restoration in a tier-1 backbone.IEEE Network Magazine, Mar 2004.
[20] Juniper Logical Routers.http://www.juniper.net/techpubs/software/junos/junos85/feature-guide-85/id-11139212.html.
[21] Z. Kerravala. Configuration Management Delivers BusinessResiliency. The Yankee Group, November 2002.
[22] M. McNett, D. Gupta, A. Vahdat, and G. M. Voelker.Usher: An extensible framework for managing clusters ofvirtual machines. In Proc. USENIX LISA Conference,November 2007.
[23] NetFPGA. http://yuba.stanford.edu/NetFPGA/.[24] OpenVZ. http://openvz.org.[25] Average retail price of electricity. http://www.eia.doe.
gov/cneaf/electricity/epm/table5_6_a.html.[26] Quagga Routing Suite. http://www.quagga.net.[27] A. Rostami and E. Sargent. An optical integrated system
for implementation of NxM optical cross-connect, beamsplitter, mux/demux and combiner. IJCSNS InternationalJournal of Computer Science and Network Security, July2006.
[28] K. Roth, F. Goldstein, and J. Kleinman. EnergyConsumption by Office and TelecommunicationsEquipment in commercial buildings Volume I: EnergyConsumption Baseline. National Technical InformationService (NTIS), U.S. Department of Commerce, Springfield,VA 22161, NTIS Number: PB2002-101438, 2002.
[29] A. Shaikh, R. Dube, and A. Varma. Avoiding instabilityduring graceful shutdown of multiple OSPF routers.IEEE/ACM Trans. Networking, 14(3):532–542, June 2006.
[30] R. Teixeira, A. Shaikh, T. Griffin, and J. Rexford.Dynamics of hot-potato routing in IP networks. In Proc.ACM SIGMETRICS, June 2004.
[31] J. van der Merwe and I. Leslie. Switchlets and dynamicvirtual ATM networks. In Proc. IFIP/IEEE InternationalSymposium on Integrated Network Management, May 1997.
[32] VINI. http://www.vini-veritas.net/.[33] Y. Wang, J. van der Merwe, and J. Rexford. VROOM:
Virtual ROuters On the Move. In Proc. ACM SIGCOMMWorkshop on Hot Topics in Networking, Nov 2007.
[34] J. Wei, K. Ramakrishnan, R. Doverspike, and J. Pastor.Convergence through packet-aware transport. Journal ofOptical Networking, 5(4), April 2006.
[35] T. Wood, P. Shenoy, A. Venkataramani, and M. Yousif.Black-box and Gray-box Strategies for Virtual MachineMigration. In Proc. NSDI, April 2007.