on the design of ip routers part 1: router architectureshungngo/classes/2010/589/reading... ·...
TRANSCRIPT

On the design of IP routersPart 1: Router architectures
James Aweya *
Systems Design Engineer, Nortel Networks, P.O. Box 3511, Station C, Ottawa, Canada K1Y 4H7
Received 12 February 1999; received in revised form 27 May 1999; accepted 19 July 1999
Abstract
Internet Protocol (IP) networks are currently undergoing transitions that mandate greater bandwidths and the need
to prepare the network infrastructures for converged tra�c (voice, video, and data). Thus, in the emerging environment
of high performance IP networks, it is expected that local and campus area backbones, enterprise networks, and In-
ternet Service Providers (ISPs) will use multigigabit and terabit networking technologies where IP routers will be used
not only to interconnect backbone segments but also to act as points of attachments to high performance wide area
links. Special attention must be given to new powerful architectures for routers in order to play that demanding role. In
this paper, we describe the evolution of IP router architectures and highlight some of the performance issues a�ecting IP
routers. We identify important trends in router design and outline some design issues facing the next generation of
routers. It is also observed that the achievement of high throughput IP routers is possible if the critical tasks are
identi®ed and special purpose modules are properly tailored to perform them. Ó 2000 Elsevier Science B.V. All rights
reserved.
Keywords: Internet Protocol networks; Routers; Performance; Design
1. Introduction
The rapid growth in the popularity of the In-ternet has caused the tra�c on the Internet togrow drastically every year for the last severalyears. It has also spurred the emergence of manyInternet Service Providers (ISPs). To sustaingrowth, ISPs need to provide new di�erentiatedservices, e.g., tiered service, support for multime-dia applications, etc. The routers in the ISPsÕ net-works play a critical role in providing these
services. Internet Protocol (IP) tra�c on privateenterprise networks has also been growing rapidlyfor some time. These networks face signi®cantbandwidth challenges as new application types,especially desktop applications uniting voice, vid-eo, and data tra�c need to be delivered on thenetwork infrastructure. This growth in IP tra�c isbeginning to stress the traditional processor-baseddesign of current-day routers and as a result hascreated new challenges for router design.
Routers have traditionally been implementedpurely in software. Because of the software im-plementation, the performance of a router waslimited by the performance of the processor exe-cuting the protocol code. To achieve wire-speedrouting, high-performance processors together
www.elsevier.com/locate/sysarc
Journal of Systems Architecture 46 (2000) 483±511
* Corresponding author. Tel.: +1-613-763-6491; fax: +1-613-
763-5692.
E-mail address: [email protected] (J. Aweya).
1383-7621/00/$ - see front matter Ó 2000 Elsevier Science B.V. All rights reserved.
PII: S 1 3 8 3 - 7 6 2 1 ( 9 9 ) 0 0 0 2 8 - 4

with large memories were required. This translatedinto higher cost. Thus, while software-based wire-speed routing was possible at low-speeds, for ex-ample, with 10 megabits per second (Mbps) ports,or with a relatively smaller number of 100 Mbpsports, the processing costs and architectural im-plications make it di�cult to achieve wire-speedrouting at higher speeds using software-basedprocessing.
Fortunately, many changes in technology (bothnetworking and silicon) have changed the land-scape for implementing high-speed routers. Siliconcapability has improved to the point where highlycomplex systems can be built on a single integratedcircuit (IC). The use of 0.35 lm and smaller silicongeometries enables application speci®c integratedcircuit (ASIC) implementations of millions of gate-equivalents. Embedded memory (SRAM, DRAM)and microprocessors are available in addition tohigh-density logic. This makes it possible to buildsingle-chip, low-cost routing solutions that incor-porate both hardware and software as needed forbest overall performance.
In this paper we investigate the evolution of IProuter designs and highlight the major perfor-mance issues a�ecting IP routers. The need tobuild fast IP routers is being addressed in a varietyof ways. We discuss these in various sections of thepaper. In particular, we examine the architecturalconstraints imposed by the various router designalternatives. The scope of the discussion presentedhere does not cover more recent label switchingrouting techniques such as IP Switching [1], theCell Switching Router (CSR) architecture [2], TagSwitching [3], and Multiprotocol Label Switching(MPLS), which is a standardization e�ort under-way at the Internet Engineering Task Force(IETF). The discussion is limited to routing tech-niques as described in RFC 1812 [4].
In Section 2, we brie¯y review the basic func-tionalities in IP routers. The IETFÕs Requirementsfor IP Version 4 Routers [4] describes in great detailthe set of protocol standards that Internet Proto-col version 4 (IPv4) routers need to conform to.Section 3 presents the design issues and trends thatarise in IP routers. In this section, we present anoverview of IP router designs and point out theirmajor innovations and limitations. The intercon-
nection unit (or switch fabric) is one of the maincomponents in a router. The switch fabric can beimplemented using many di�erent techniqueswhich are described in detail in a number of pub-lications (e.g., [5±7]). Section 4 presents an over-view of these switch fabric technologies. Theconcluding remarks of the paper are given inSection 5.
2. Basic functionalities in IP routers
Generally, routers consist of the following basiccomponents: several network interfaces to the at-tached networks, processing module(s), bu�eringmodule(s), and an internal interconnection unit (orswitch fabric). Typically, packets are received at aninbound network interface, processed by the pro-cessing module and, possibly, stored in the buf-fering module. Then, they are forwarded throughthe internal interconnection unit to the outboundinterface that transmits them on the next hop onthe journey to their ®nal destination. The aggre-gate packet rate of all attached network interfacesneeds to be processed, bu�ered and relayed.Therefore, the processing and memory modulesmay be replicated either fully or partially on thenetwork interfaces to allow for concurrent opera-tions.
A generic architecture of an IP router is given inFig. 1. Fig. 1(a) shows the basic architecture of atypical router: the controller card (which holds theCPU), the router backplane, and interface cards.The CPU in the router typically performs suchfunctions as path computations, routing tablemaintenance, and reachability propagation. Itruns which ever routing protocol is needed in therouter. The interface cards consist of adapters thatperform inbound and outbound packet forward-ing (and may even cache routing table entries orhave extensive packet processing capabilities). Therouter backplane is responsible for transferringpackets between the cards. The basic functional-ities in an IP router can be categorized as: routeprocessing, packet forwarding, and router specialservices. The two key functionalities for packetrouting are route processing (i.e., path computa-tion, routing table maintenance, and reachability
484 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

propagation) and packet forwarding (see Fig.1(b)). We discuss the three functionalities in moredetail below.
2.1. Route processing
Routing protocols are the means by whichrouters gain information about the network.Routing protocols map network topology andstore their view of that topology in the routingtable. Thus, route processing includes routing ta-ble construction and maintenance using routingprotocols such as the Routing Information Pro-tocol (RIP) and Open Shortest Path First (OSPF)[8±10]. The routing table consists of routing entriesthat specify the destination and the next-hoprouter through which the datagram should beforwarded to reach the destination. Route calcu-lation consists of determining a route to the des-tination: network, subnet, network pre®x, or host.
In static routing, the routing table entries arecreated by default when an interface is con®gured(for directly connected interfaces), added by, forexample, the route command (normally from asystem bootstrap ®le), or created by an InternetControl Message Protocol (ICMP) redirect (usu-ally when the wrong default is used) [11]. Oncecon®gured, the network paths will not change.
With static routing, a router may issue an alarmwhen it recognizes that a link has gone down, butwill not automatically recon®gure the routing ta-ble to reroute the tra�c around the disabled link.Static routing, used in LANs over limited dis-tances, requires basically the network manager tocon®gure the routing table. Thus, static routing is®ne if the network is small, there is a single con-nection point to other networks, and there are noredundant routes (where a backup route can beused if a primary route fails). Dynamic routing isnormally used if any of these three conditions donot hold true.
Dynamic routing, used in internetworkingacross wide area networks, automatically recon-®gures the routing table and recalculates the leastexpensive path. In this case, routers broadcastadvertisement packets (signifying their presence)to all network nodes and communicate with otherrouters about their network connections, the costof connections, and their load levels. Convergence,or recon®guration of the routing tables, must oc-cur quickly before routers with incorrect infor-mation misroute data packets into dead ends.Some dynamic routers can also rebalance thetra�c load.
The use of dynamic routing does not change theway an IP forwarding engine performs routing at
Fig. 1. Generic architecture of a router.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 485

the IP layer. What changes is the informationplaced in the routing table ± instead of comingfrom the route commands in bootstrap ®les, theroutes are added and deleted dynamically by arouting protocol, as routes change over time. Therouting protocol adds a routing policy to the sys-tem, choosing which routes to place in the routingtable. If the protocol ®nds multiple routes to adestination, the protocol chooses which route isthe best, and which one to insert in the table. If theprotocol ®nds that a link has gone down, it candelete the a�ected routes or add alternate routesthat bypass the problem.
A network (including several networks admin-istered as a whole) can be de®ned as an autono-mous system. A network owned by a corporation,an ISP, or a university campus often de®nes anautonomous system. There are two principalrouting protocol types [8±11]: those that operatewithin an autonomous system, or the InteriorGateway Protocols (IGPs), and those that operatebetween autonomous systems, or Exterior Gate-way Protocols (EGPs). Within an autonomoussystem, any protocol may be used for route dis-covery, propagating, and validating routes. Eachautonomous system can be independently admin-istered and must make routing information avail-able to other autonomous systems. The majorIGPs include RIP, OSPF, and IS±IS (IntermediateSystem to Intermediate System). Some EGPs in-clude EGP and Border Gateway Protocol (BGP).Refs. [8±10] present detail discussions on routingprotocols.
2.2. Packet forwarding
2.2.1. Forwarding processIn this section, we brie¯y review the forwarding
process in IPv4 routers. More details of the for-warding requirements are given in Ref. [4]. Arouter receives an IP packet on one of its inter-faces and then forwards the packet out of anotherof its interfaces (or possibly more than one, if thepacket is a multicast packet), based on the con-tents of the IP header. As the packet is forwardedhop by hop, the packetÕs (original) network layerheader (IP header) remains relatively unchanged,containing the complete set of instructions on how
to forward the packet (IP tunneling may call forprepending the packet with other IP headers in thenetwork). However, the data-link headers andphysical-transmission schemes may change radi-cally at each hop in order to match the changingmedia types.
Suppose that the router receives a packet fromone of its attached network segments. The routerveri®es the contents of the IP header by checkingthe protocol version, header length, packet length,and header checksum ®elds. The protocol versionmust be equal to 4 for IPv4 which we assume inthis paper. The header length must be greater thanor equal to the minimum IP header size (20 bytes).The length of the IP packet, expressed in bytes,must also be larger than the minimum header size.In addition, the router checks that the entirepacket has been received, by checking the IPpacket length against the size of the receivedEthernet packet, for example, in the case where theinterface is attached to an Ethernet network. Toverify that none of the ®elds of the header havebeen corrupted, the 16-bit ones-complementchecksum of the entire IP header is calculated andveri®ed to be equal to 0x��. If any of these basicchecks fail, the packet is deemed to be malformedand is discarded without sending an error indica-tion back to the packetÕs originator.
Next, the router veri®es that the time-to-live(TTL) ®eld is greater than 1. The purpose of theTTL ®eld is to make sure that packets do notcirculate forever when there are routing loops. Thehost sets the packetÕs TTL ®eld to be greater thanor equal to the maximum number of router hopsexpected on the way to the destination. Eachrouter decrements the TTL ®eld by 1 when for-warding; when the TTL ®eld is decremented to 0,the packet is discarded, and an Internet ControlMessage Protocol (ICMP) TTL Exceeded messageis sent back to the host. On decrementing the TTL,the router must update the packetÕs headerchecksum. RFC 1141 [92] contains implementa-tion techniques for computing the IP checksum.Since a router often changes only the TTL ®eld(decrementing it by 1), a router can incrementallyupdate the checksum when it forwards a receivedpacket, instead of calculating the checksum overthe entire IP header again.
486 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

The router then looks at the destination IPaddress. The address indicates a single destinationhost (unicast), a group of destination hosts (mul-ticast), or all hosts on a given network segment(broadcast). Unicast packets are discarded if theywere received as data-link broadcasts or as multi-casts; otherwise, multiple routers may attempt toforward the packet, possibly contributing to abroadcast storm. In packet forwarding, the desti-nation IP address is used as a key for the routingtable lookup. The best-matching routing tableentry is returned, indicating whether to forwardthe packet and, if so, the interface to forward thepacket out of and the IP address of the next IProuter (if any) in the packetÕs path. The next-hopIP address is used at the output interface to de-termine the link address of the packet, in case thelink is shared by multiple parties (such as anEthernet, Token Ring or Fiber Distributed DataInterface (FDDI) network), and is consequentlynot needed if the output connects to a point-to-point link.
In addition to making forwarding decisions, theforwarding process is responsible for makingpacket classi®cations for quality of service (QoS)control and access ®ltering. Flows can be identi®edbased on source IP address, destination IP ad-dress, TCP/UDP port numbers as well as IP typeof service (TOS) ®eld. Classi®cation can even bebased on higher layer packet attributes.
If the packet is too large to be sent out of theoutgoing interface in one piece (that is, the packetlength is greater than the outgoing interfaceÕsMaximum Transmission Unit (MTU)), the routerattempts to split the packet into smaller fragments.Fragmentation, however, can a�ect performanceadversely [12]. Host may instead wish to preventfragmentation by setting the DonÕt Fragment (DF)bit in the Fragmentation ®eld. In this case, therouter does not fragment but instead drops thepacket and sends an ICMP Destination Unreach-able (subtype Fragmentation Needed and DF Set)message back to the host. The host uses thismessage to calculate the minimum MTU along thepacketÕs path [13], which is in turn used to sizefuture packets.
The router then prepends the appropriate data-link header for the outgoing interface. The IP
address of the next hop is converted to a data-linkaddress, usually using the Address ResolutionProtocol (ARP) [14] or a variant of ARP, such asInverse ARP [15] for Frame Relay subnets. Therouter then sends the packet to the next hop, wherethe process is repeated.
An application can also modify the handling ofits packets by extending the IP headers of itspackets with one or more IP options. IP optionsare used infrequently for regular data packets,because most internet routers are heavily opti-mized for forwarding packets having no options.Most IP options (such as the record-route andtimestamp options) are used to aid in statisticscollection but do not a�ect a packetÕs path.However, the strict-source route and the loose-source route options can be used by an applicationto control the path its packets take. The strict-source route option is used to specify the exactpath that the packet will take, router by router.The utility of strict-source route is limited by themaximum size of the IP header (60 bytes), whichlimits to 9 the number of hops speci®ed by thestrict-source route option. The loose-source routeis used to specify a set of intermediate routers(again, up to 9) through which the packet must goon the way to its destination. Loose-source routingis used mainly for diagnostic purposes, such as anaid to debugging internet routing problems.
2.2.2. Route lookupFor a long time, the major performance bot-
tleneck in IP routers has been the time it takes tolook up a route in the routing table. The problemis de®ned as that of searching through a database(routing table) of destination pre®xes and locatingthe longest pre®x that matches the destination IPaddress of a given packet. A routing table lookupreturns the best-matching routing table entry,which tells the router which interface to forwardthe packet out of and the IP address of the packetÕsnext hop. Pre®x matching was introduced in theearly 1990s, when it was foreseen that the numberof end users as well as the amount of routing in-formation on the Internet would grow enormous-ly. The address classes A, B, and C (allowing sitesto have 24, 16, and 8 bits respectively for ad-dressing) proved too in¯exible and wasteful of the
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 487

address space. To make better use of this scarceresource, especially the class B addresses, bundlesof class C networks were given out instead of classB addresses. This resulted in massive growthof routing table entries. Thus, Classless Inter-Domain Routing (CIDR) [16] introduced afundamental concept in route aggregation whichallows for contiguous blocks of address space to beaggregated and advertised as singular routes in-stead of individual entries in a routing table. Thishelps keep the size of the routing tables smallerthan if each address were advertised individually.
Many routers have a default route in theirrouting table. This is a routing table entry for thezero-length pre®x 0/0 (or 0.0.0.0). The defaultroute matches every destination, although it isoverridden by all more speci®c pre®xes. For ex-ample, suppose that an organizationÕs intranet hasone router attaching itself to the public Internet.All of the organizationÕs other routers can then usea default route pointing to the Internet connectionrather than knowing about all of the public In-ternetÕs routes.
The ®rst approaches for longest pre®x matchingused radix trees or modi®ed Patricia trees [17,18]combined with hash tables, (Patricia stands for``Practical Algorithm to Retrieve InformationCoded in Alphanumeric'' [19]). These trees arebinary trees, whereby the tree traversal depends ona sequence of single-bit comparisons in the key,the destination IP address. These lookup algo-rithms have complexity proportional to the num-ber of address bits which, for IPv4 is only 32. Inthe worst case it takes time proportional to thelength of the destination address to ®nd the longestpre®x match. Worse, the commonly used Patriciaalgorithm may need to backtrack to ®nd thelongest match, leading to poor worst-case perfor-mance. The performance of Patricia is somewhatdata dependent. With a particularly unfortunatecollection of pre®xes in the routing table, thelookup of certain addresses can take as many as 32bit comparisons, one for each bit of the destinationIP address.
Early implementations of routers, however,could not a�ord such expensive computations.Thus, one way to speed up the routing tablelookup is to try to avoid it entirely. The routing
table lookup provides the next hop for a given IPdestination. Some routers cache this IP destina-tion-to-next-hop association in a separate databasethat is consulted (as the front end to the routingtable) before the routing table lookup as shown inFig. 2. Finding a particular destination in thisdatabase of IP destination-to-next-hop associa-tion is easier because an exact match is done in-stead of the more expensive best-match operationof the routing table. So, most routers relied onroute caches [20,21]. The route caching techniquesrely on there being enough locality in the tra�c sothat the cache hit rate is su�ciently high and thecost of a routing lookup is amortized over severalpackets.
This front-end database might be organized as ahash table [22]. After the router has forwardedseveral packets, if the router sees any of thesedestinations again (a cache hit), their lookups willbe very quick. Packets to new destinations will beslower, however, because the cost of a failed hashlookup will have to be added to the normal routingtable lookup. Front-end caches to the routing ta-ble can work well at the edge of the Internet orwithin organizations. However, cache schemes donot seem to work well in the InternetÕs core. Thelarge number of packet destinations seen by thecore routers can cause caches to over¯ow or fortheir lookup to become slower than the routingtable lookup itself. Cache schemes are not reallye�ective when the hash bucket size (the number ofdestinations that hash to the same value) startsgetting large. Also, the frequent routing changesseen in the core routers can force them to invali-
Fig. 2. A route cache used as a front-end database to the
routing table.
488 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

date their caches frequently, leading to a smallnumber of cache hits.
Typically, two types of packets arrive at arouter: packets to be forwarded to another net-work or packets destined to the router itself.Whether a packet to a router causes a routing ta-ble reference depends on the router implementa-tion. Some implementations may speed up routingtable lookups. One possibility is for the router toexplicitly check each incoming packet against atable of all of the routerÕs addresses to see if thereis a match. This explicit check means that therouting table is never consulted about packetsdestined to the router. Another possibility is to usethe routing table for all packets. Before the packetis sent, the router checks if the packet is to its ownaddress on the appropriate network. If the packetis for the router, then it is never transmitted. Theexplicit check after the routing table lookup re-quires checking a smaller number of router ad-dresses at the increased cost of a routing tablelookup. New routing table lookup algorithms arestill being developed in attempts to build evenfaster routers. Recent examples are found in Refs.[23±28].
The basic idea of one of the recent algorithms[23] is to create a small and compressed datastructure that represents large lookup tables usinga small amount of memory. The technique exploitsthe sparseness of actual entries in the space of allpossible routing table entries. This results in alower number of memory accesses (to a fastmemory) and hence faster lookups. The proposalreduces the routing table to very e�cient repre-sentation of a binary tree such that the majority ofthe table can reside in the primary cache of theprocessor, allowing route lookups at gigabitspeeds. In addition, the algorithm does not have tocalculate expensive perfect hash functions, al-though updates to the routing table are still noteasy. Ref. [24] proposes another approach forimplementing the compression and minimizing thecomplexity of updates.
The recent work of Waldvogel et al. [25] pre-sents an alternative approach which reduces thenumber of memory references rather than compactthe routing table. The main idea is to ®rst create aperfect hash table of pre®xes for each pre®x length.
A binary search among all pre®x lengths, using thehash tables for searches amongst pre®xes of aparticular length, can ®nd the longest pre®x matchfor an N bit address in O(log N) steps. Althoughthe algorithm has very fast execution times, cal-culating perfect hashes can be slow and can slowdown updates.
Hardware based techniques for route lookupare also actively being investigated both in re-search and commercial designs (e.g., [29±32]).Other designs of forwarding engine have concen-trated on IP packet header processing in hardware,to remove the dependence upon caching, and toavoid the cost of high-speed processor. Designsbased upon content-addressable memory havebeen investigated [29], but such memory is too farexpensive to be applied to a large routing table.Hardware route lookup and forwarding is alsounder active investigation in both research andcommercial designs [30,31]. The argument for asoftware-based implementation stresses ¯exibility.Hardware implementations can generally achieve ahigher performance at lower cost but are less¯exible.
2.3. Router special services
Besides dynamically ®nding the paths forpackets to take towards their destinations, routersalso implement other functions. Anything beyondcore routing functions falls into this category, forexample, authentication and access services suchas packet ®ltering for security/®rewall purposes.Companies often put a router between their com-pany network and the Internet and then con®gurethe router to prevent unauthorized access to thecompanyÕs resources from the Internet. This con-®guration may consist of certain patterns (for ex-ample, source and destination address and TCPport) whose matching packets should not be for-warded or of more complex rules to deal withprotocols that vary their port numbers over time,such as the File Transfer Protocol (FTP). Suchrouters are called ®rewalls. Similarly, internetservice providers (ISPs) often con®gure their rou-ters to verify the source address in all packets re-ceived from the ISPÕs customers. This foils certainsecurity attacks and makes other attacks easier to
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 489

trace back to their source. Similarly, ISPs provid-ing dial-in access to their routers typically useRemote Authentication Dial-In User Service(RADIUS) [33] to verify the identity of the persondialing in.
Often other functions, less directly related topacket forwarding, also get incorporated into IProuters. Examples of these non-forwarding func-tions include network management componentssuch as Simple Network Management Protocol(SNMP) and Management Information Bases(MIBs). Routers also play an important role inTCP/IP congestion control algorithms. When anIP network is congested, routers cannot forwardall the packets they receive. By simply discardingsome of their received packets, routers providefeedback to TCP congestion control algorithms,such as the TCP slow-start algorithm [34,35]. EarlyInternet routers simply discarded excess packetsinstead of queueing them onto already full trans-mit queues; these routers are termed drop-tailgateways. However, this discard behavior wasfound to be unfair, favoring applications that sendlarger and more bursty data streams. Modern In-ternet routers employ more sophisticated, andfairer, drop algorithms, such as Random EarlyDetection (RED) [36].
Algorithms also have been developed that allowrouters to organize their transmit queues so as togive resource guarantees to certain classes of tra�cor to speci®c applications. These queueing or linkscheduling algorithms include Weighted FairQueueing (WFQ) [37] and Class Based Queueing(CBQ) [38]. A protocol called RSVP [39] has beendeveloped that allows hosts to dynamically signalto routers which applications should get specialqueueing treatment. However, RSVP has not yetbeen deployed, with some people arguing thatqueueing preference could more simply be indi-cated by using the Type of Service (TOS) bits inthe IP header [40,41].
Some vendors allow the collection of tra�cstatistics on their routers, for example, how manypackets and bytes are forwarded per receiving andtransmitting interface on the router. These statis-tics are used for future capacity planning. Theycan also be used by ISPs to implement usage-basedcharging schemes for their customers.
3. IP router architectures
In this section, we review the main architecturesproposed for IP routers. Speci®cally, we examineimportant trends in IP router design and outlinesome design issues facing the next generation ofrouters. The aim is not to provide an exhaustivereview of existing architectures, but instead to givethe reader a perspective on the range of optionsavailable and the associated trade-o� betweenperformance, functionality, and complexity.
3.1. Bus-based router architectures with singleprocessor
The ®rst generation of IP router was based onsoftware implementations on a single general-purpose central processing unit (CPU). Theserouters consist of a general-purpose processor andmultiple interface cards interconnected through ashared bus as depicted in Fig. 3.
Packets arriving at the interfaces are forwardedto the CPU which determines the next hop addressand sends them back to the appropriate outgoinginterface(s). Data are usually bu�ered in a cen-tralized data memory [42,43], which leads to thedisadvantage of having the data cross the bustwice, making it the major system bottleneck.Packet processing and node management software(including routing protocol operation, routing ta-ble maintenance, routing table lookups, and othercontrol and management protocols such as ICMP,SNMP) are also implemented on the central pro-
Fig. 3. Traditional bus-based router architecture.
490 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

cessor. Unfortunately, this simple architectureyields low performance for the following reasons:· The central processor has to process all packets
¯owing through the router (as well as those des-tined to it). This represents a serious processingbottleneck.
· Some major packet processing tasks in a routerinvolve memory intensive operations (e.g., tablelookups) which limits the e�ectiveness of proces-sor power upgrades in boosting the router pack-et processing throughput. Routing tablelookups and data movements are the major con-sumer of overall packet processing cycles. Pack-et processing time does not decrease linearly iffaster processors are used because of the some-times dominating e�ect of memory access rate.
· Moving data from one interface to the other (ei-ther through main memory or not) is a time con-suming operation that often exceeds the packetheader processing time. In many cases, the com-puter input/output (I/O) bus quickly becomes asevere limiting factor to overall router through-put.
Since routing table lookup is a time-consumingprocess of packet forwarding, some traditionalsoftware-based routers cache the IP destination-to-next-hop association in a separate database that isconsulted as the front end to the routing table be-fore the routing table lookup. The justi®cation forroute caching is that packet arrivals are temporallycorrelated, so that if a packet belonging to a new¯ow arrives then more packets belonging to thesame ¯ow can be expected to arrive in the near fu-ture. Route caching of IP destination/next-hopaddress pairs will decrease the average processingtime per packet if locality exists for packet ad-dresses [20,21]. Still, the performance of the tradi-tional bus-based router depends heavily on thethroughput of the shared bus and on the forward-ing speed of the central processor. This architecturecannot scale to meet the increasing throughput re-quirements of multigigabit network interface cards.
3.2. Bus-based router architectures with multipleprocessors
For the second generation IP routers, im-provement in the shared-bus router architecture
was introduced by distributing the packet for-warding operations. In some architectures, dis-tributing fast processors and route caches, inaddition to receive and transmit bu�ers, over thenetwork interface cards reduces the load on thesystem bus. Other second generation routers rem-edy this problem by employing multiple forward-ing engines (dedicated solely for packet forwardingoperation) in parallel since a single CPU cannotkeep up with requests from high-speed input ports.An advantage of having multiple forwarding en-gines serving as one pool is the ease of balancingloads from the ports when they have di�erentspeeds and utilization levels. We review, in thissection, these second generation router architec-tures.
3.2.1. Architectures with route cachingThis architecture reduces the number of bus
copies and speeds up packet forwarding by using aroute cache of frequently seen addresses in thenetwork interface as shown in Fig. 4. Packets aretherefore transmitted only once over the sharedbus. Thus, this architecture allows the networkinterface cards to process packets locally some ofthe time.
In this architecture, a router keeps a centralmaster routing table and the satellite processors inthe network interfaces each keep only a modestcache of recently used routes. If a route is not in anetwork interface processorÕs cache, it would re-quest the relevant route from the central table. Theroute cache entries are tra�c-driven in that the®rst packet to a new destination is routed by themain CPU (or route processor) via the centralrouting table information and as part of that for-warding operation, a route cache entry for thatdestination is then added in the network interface.This allows subsequent packet ¯ows to the samedestination network to be switched based on ane�cient route cache match. These entries are pe-riodically aged out to keep the route cache currentand can be immediately invalidated if the networktopology changes. At high-speeds, the centralrouting table can easily become a bottleneck be-cause the cost of retrieving a route from the centraltable is many times more expensive than actually
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 491

processing the packet local in the network inter-face.
A major limitation of this architecture is thatit has a tra�c dependent throughput and alsothe shared bus is still a bottleneck. The per-formance of this architecture can be improvedby enhancing each of the distributed networkinterface cards with larger memories and com-plete forwarding tables. The decreasing cost ofhigh bandwidth memories makes this possible.However, the shared bus and the general pur-pose CPU can neither scale to high capacitylinks nor provide tra�c pattern independentthroughput.
3.2.2. Architectures with multiple parallel forward-ing engines
Another bus-based multiple processor routerarchitecture is described in [44]. Multiple for-warding engines are connected in parallel toachieve high packet processing rates as shown inFig. 5. The network interface modules transmitand receive data from the links at the requiredrates. As a packet comes into a network interface,the IP header is stripped by a control circuitry,augmented with an identifying tag, and sent to aforwarding engine for validation and routing.While the forwarding engine is performing therouting function, the remainder of the packet isdeposited in an input bu�er (in the network in-
terface) in parallel. The forwarding engine deter-mines which outgoing link the packet should betransmitted on, and sends the updated header®elds to the appropriate destination interfacemodule along with the tag information. Thepacket is then moved from the bu�er in the sourceinterface module to a bu�er in the destination in-terface module and eventually transmitted on theoutgoing link.
The forwarding engines can each work on dif-ferent headers in parallel. The circuitry in the in-terface modules peels the header o� of each packetand assigns the headers to the forwarding enginesin a round-robin fashion. Since in some (real time)applications packet order maintenance is an issue,the output control circuitry also goes round-robin,guaranteeing that packets will then be sent out inthe same order as they were received. Better load-balancing may be achieved by having a more in-telligent input interface which assigns each headerto the lightest loaded forwarding engine [44]. Theoutput control circuitry would then have to selectthe next forwarding engine to obtain a processedheader from by following the demultiplexing orderfollowed at the input, so that order preservation ofpackets is ensured. The forwarding engine returnsa new header (or multiple headers, if the packet isto be fragmented), along with routing information(i.e., the immediate destination of the packet). Aroute processor runs the routing protocols and
Fig. 4. Reducing the number of bus copies using a route cache in the network interface.
492 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

creates a forwarding table that is used by the for-warding engines.
The choice of this architecture was premised onthe observation that it is highly unlikely that allinterfaces will be bottlenecked at the same time.Hence sharing of the forwarding engines can in-crease the port density of the router. The for-warding engines are only responsible for resolvingnext-hop addresses. Forwarding only IP headersto the forwarding engines eliminates an unneces-sary packet payload transfer over the bus. Packetpayloads are always directly transferred betweenthe interface modules and they never go to eitherthe forwarding engines or the route processorunless they are speci®cally destined to them.
3.3. Switch-based router architectures with multipleprocessors
To alleviate the bottlenecks of the second gen-eration of IP routers, the third generation of rou-ters were designed with the shared bus replaced bya switch fabric. This provides su�cient bandwidthfor transmitting packets between interface cards
and allows throughput to be increased by severalorders of magnitude. With the interconnectionunit between interface cards not the bottleneck,the new bottleneck is packet processing.
The multigigabit router (MGR) is an exampleof this architecture [45]. The design has dedicatedIP packet forwarding engines with route caches inthem. The MGR consists of multiple line cards(each supporting one or more network interfaces)and forwarding engine cards, all connected to ahigh-speed (crossbar) switch as shown in Fig. 6.The design places forwarding engines on boardsdistinct from line cards. When a packet arrives at aline card, its header is removed and passedthrough the switch to a forwarding engine. Theremainder of the packet remains on the inboundline card. The forwarding engine reads the headerto determine how to forward the packet and thenupdates the header and sends the updated headerand its forwarding instructions back to the in-bound line card. The inbound line card integratesthe new header with the rest of the packet andsends the entire packet to the outbound line cardfor transmission. The MGR, like most routers,
Fig. 5. Bus-based router architecture with multiple parallel forwarding engines.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 493

also has a control (and route) processor that pro-vides basic management functions such as gener-ation of routing tables for the forwarding enginesand link (up/down) management. Each forwardingengine has a set of the forwarding tables (whichare a summary of the routing table data).
Similar to other cache-driven architectures, theforwarding engine checks to see if the cached routematches the destination of the packet (a cache hit).If not, the forwarding engine carries out an ex-tended lookup of the forwarding table associatedwith it. In this case, the engine searches the routingtable for the correct route, and generates a versionof the route for the route cache. Since the for-warding table contains pre®x routes and the routecache is a cache of routes for particular destina-tion, the processor has to convert the forwardingtable entry into an appropriate destination-speci®ccache entry.
3.4. Limitation of IP packet forwarding based onroute caching
Regardless of the type of interconnection unitused (bus, shared memory, crossbar, etc.), a routecache can be used in conjunction with a (central-ized) processing unit for IP packet forwarding[20,21,45]. In this section, we examine the limita-tions of route caching techniques before we pro-ceed with the discussion on other routerarchitectures.
The route cache model creates the potential forcache misses which occur with ``demand-caching''schemes as described above. That is, if a route isnot found in the forwarding cache, the ®rstpacket(s) then looks to the routing table main-tained by the CPU to determine the outboundinterface and then a cache entry is added for thatdestination. This means when addresses are notfound in the cache, the packet forwarding de-faults to a classical software-based route lookup(sometimes described as a ``slow-path''). Since thecache information is derived from the routingtable, routing changes cause existing cache entriesto be invalidated and reestablished to re¯ect anytopology changes. In networking environmentswhich frequently experience signi®cant routingactivity (such as in the Internet) this can causetra�c to be forwarded via the main CPU (theslow path), as opposed to via the route cache (thefast path).
In enterprise backbones or public networks, thecombination of highly random tra�c patterns andfrequent topology changes tends to eliminate anybene®ts from the route cache, and performance isbounded by the speed of the software slow pathwhich can be many orders of magnitude lowerthan the caching fast path.
This demand-caching scheme, maintaining avery fast access subnet of the routing topologyinformation, is optimized for scenarios wherebythe majority of the tra�c ¯ows are associatedwith a subnet of destinations. However, giventhat tra�c pro®les at the core of the Internet(and potentially within some large enterprisenetworks) do not follow closely this model, anew forwarding paradigm is required that wouldeliminate the increasing cache maintenance re-sulting from growing numbers of topologicallydispersed destinations and dynamic networkchanges.
The performance of a product using the routecache technique is in¯uenced by the followingfactors:· how big the cache is,· how the cache is maintained (the three most
popular cache maintenance strategies are ran-dom replacement, ®rst-in-®rst-out (FIFO), andleast recently used (LRU)), and
Fig. 6. Switch-based router architecture with multiple for-
warding engines.
494 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

· what the performance of the slow path is, sinceat least some percentage of the tra�c will takethe slow path in any application.
The main argument in favor of cache-basedschemes is that a cache hit is at least less expensivethan a full route lookup (so a cache is valuableprovided it achieves a modest hit rate). Even withan increasing number of ¯ows, it appears thatpacket bursts and temporal correlation in thepacket arrivals will continue to ensure that there isa strong chance that two datagrams arriving closetogether will be headed for the same destination.
In current backbone routers, the number of¯ows that are active at a given interface can beextremely high. Studies have shown that an OC-3interface might have an average of 256,000 ¯owsactive concurrently [46]. It is observed in [47] that,for this many ¯ows, use of hardware caches isextremely di�cult, especially if we consider thefact that a fully associative hardware cache is re-quired. So caches of such size are most likely to beimplemented as hash tables since only hash tablescan be scaled to these sizes. However, the O(1)lookup time of a hash table is an average caseresult, and the worst-case performance of a hashtable can be poor since multiple headers mighthash into the same location. Due to the largenumber of ¯ows that are simultaneously active in arouter and due to the fact that hash tables gener-ally cannot guarantee good hashing under all ar-rival patterns, the performance of cache-basedschemes is heavily tra�c dependent. If a largenumber of new ¯ows arrive at the same time, theslow path of the router can be overloaded, and it ispossible that packet loss can occur due to the (slowpath) processing overload and not due to outputlink congestion.
Some architectures have been proposed thatavoid the potential overload of continuous cachechurn (which results in a performance bottleneck).These designs use instead a forwarding database ineach network interface which mirrors the entirecontent of the IP routing table maintained by theCPU (route processor). That is, there is a one-to-one correspondence between the forwarding dat-abase entries and routing table pre®xes; thereforeno need to maintain a route cache [48±50]. Byeliminating the route cache, the architecture fully
eliminates the slow path. This o�ers signi®cantbene®ts in terms of performance, scalability, net-work resilience and functionality, particularly inlarge complex networks with dynamic ¯ows. Thesearchitectures can best accommodate the changingnetwork dynamics and tra�c characteristics re-sulting from increasing numbers of short ¯owstypically associated with Web-based applicationsand interactive type sessions.
3.5. Switch-based router architectures with fullydistributed processors
From the discussion in the preceding sections,we ®nd that the three main bottlenecks in a routerare processing power, memory bandwidth, andinternal bus bandwidth. These three bottleneckscan be avoided by using a distributed switch-basedarchitecture with properly designed network in-terfaces. Since routers are mostly dedicated sys-tems not running any speci®c application tasks,o�-loading processing to the network interfacesre¯ects a proper approach to increase the overallrouter performance. A successful step towardsbuilding high performance routers is to add someprocessing power to each network interface in or-der to reduce the processing and memory bottle-necks. General-purpose processors and/ordedicated very large scale integrated (VLSI) com-ponents can be applied. The third bottleneck (in-ternal bus bandwidth) can be solved by usingspecial mechanisms where the internal bus is ine�ect a switch (e.g., shared memory, crossbar, etc.)thus allowing simultaneous packet transfers be-tween di�erent pairs of network interfaces. Thisarrangement must also allow for e�cient multicastcapabilities.
We review in this section, decentralized routerarchitectures where each network interface isequipped with appropriate processing power andbu�er space. Our focus is on high performancepacket processing subsystems that form an integralpart of multiport routers for high-speed networks.The routers have to cope with extremely high ag-gregate packet rates ¯owing through the systemand, thus, require e�cient processing and memorycomponents. A generic modular switch-basedrouter architecture is shown in Fig. 7.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 495

Each network interface provides the processingpower and the bu�er space needed for packetprocessing tasks related to all the packets ¯owingthrough it. Functional components (inbound,outbound, and local processing elements) processthe inbound, outbound tra�c and time-criticalport processing tasks. They perform the process-ing of all protocol functions (in addition toquality of service (QoS) processing functions) thatlie in the critical path of data ¯ow. In order toprovide QoS guarantees, a port may need toclassify packets into prede®ned service classes.Depending on router implementation, a port mayalso need to run data-link level protocols such asSerial Line Internet Protocol (SLIP), Point-to-Point Protocol (PPP) and IEEE 802.1Q VLAN(Virtual LAN), or network-level protocols such asPoint-to-Point Tunneling Protocol (PPTP). Theexact features of the processing components de-pend on the functional partitioning and imple-mentation details. Concurrent operation amongthese components can be provided. The networkinterfaces are interconnected via a high perfor-mance switch that enables them to exchange dataand control messages. In addition, a CPU is usedto perform some centralized tasks. As a result, theoverall processing and bu�ering capacity is dis-tributed over the available interfaces and theCPU.
The Media-Speci®c Interface (MSI) performsall the functions of the physical layer and theMedia Access Control (MAC) sublayer (in thecase of the IEEE 802 protocol model). The SwitchFabric Interface (SFI) is responsible for preparingthe packet for its journey across the switch fabric.The SFI may prepend an internal routing tagcontaining port of exit, the QoS priority, and droppriority, onto the packet.
In order to decrease latency and increasethroughput, more concurrency has to be achievedamong the various packet handling operations(mainly header processing and data movement).This can be achieved by using parallel or multi-processor platforms in each high performancenetwork interface. Obviously, there is a price forthat (cost and space) which has to be considered inthe router design.
To analyze the processing capabilities and todetermine potential performance bottlenecks, thefunctions and components of a router and, espe-cially, of all its processing subsystems have to beidenti®ed. Therefore, all protocols related to thetask of a router need to be considered. In an IProuter, the IP protocol itself as well as additionalprotocols, such as ICMP, ARP, RARP (ReverseARP), BGP, etc., are required.
A distinction can be made between the pro-cessing tasks directly related to packets being for-
Fig. 7. A generic switch-based distributed router architecture.
496 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

warded through the router and those related topackets destined to the router, such as mainte-nance, management or error protocol data. Bestperformance can be achieved when packets arehandled by multiple heterogeneous processing el-ements, where each element specializes in a speci®coperation. In such a con®guration, special purposemodules perform the time critical tasks in order toachieve high throughput and low latency. Timecritical tasks are the ones related to the regulardata ¯ow. The non-time critical tasks are per-formed in general purpose processors (CPU). Anumber of commercial routers follow this designapproach (e.g., [47,51±62]).
3.5.1. Critical data path processing (fast path)The processing tasks directly related to packets
being forwarded through the router can be re-ferred to as the time critical processing tasks. Theyform the critical path (sometimes called the fastpath) through a router and need to be highly op-timized in order to achieve multigigabit rates.These processing tasks comprise all protocols in-volved in the critical path (e.g., Logical LinkControl, (LLC) Subnetwork Access Protocol(SNAP) and IP) as well as ARP which can beprocessed in the network interface because it needsdirect access to the network, even though it is nottime critical. The time critical tasks mainly consistof header checking, and forwarding (and may in-clude segmentation) functions. These protocolsdirectly a�ect the performance of an IP router interms of the number of packets that can be pro-cessed per second.
Most high-speed routers implement the fastpath functions in hardware. Generally, the fastpath of IP routing requires the following func-tions: IP packet validation, destination addressparsing and table lookup, packet lifetime control(TTL update), and checksum calculation. The fastpath may also be responsible for making packetclassi®cations for QoS control and access ®ltering.The vast majority of packets ¯owing through anIP router need to have only these operations per-formed on them. While they are not trivial, it ispossible to implement them in hardware, therebyproviding performance suitable for high-speedrouting.
3.5.2. Non-critical data path processing (slow path)Packets destined to a router, such as mainte-
nance, management or error protocol data areusually not time critical. However, they have to beintegrated in an e�cient way that does not inter-fere with the packet processing and, thus, does notslow down the time-critical path. Typical examplesof these non-time critical processing tasks are errorprotocols (e.g., ICMP), routing protocols (e.g.,RIP, OSPF, BGP), and network managementprotocols (e.g., SNMP). These processing tasksneed to be centralized in a router node and typi-cally reside above the network or transport pro-tocols.
As shown in Fig. 8, only protocols in the for-warding path of a packet through the IP router areimplemented on the network interface itself. Otherprotocols such as routing and network manage-ment protocols are implemented on the CPU. Thisway, the CPU does not adversely a�ect perfor-mance because it is located out of the data path,where it maintains route tables and determines thepolicies and resources used by the network inter-faces. As an example, the CPU subsystem can beattached to the switch fabric in the same way as aregular network interface. In this case, the CPUsubsystem is viewed by the switch fabric as a reg-ular network interface. It has, however, a com-
Fig. 8. Example IEEE 802 protocol entities in an IP router
[Adapted from 48].
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 497

pletely di�erent internal architecture and function.This subsystem receives all non-critical protocoldata units and requests to process certain relatedprotocol entities (ICMP, SNMP, RIP, OSPF,BGP, etc.). Any protocol data unit that needs to besent on any network by these protocol entities issent to the proper network interface, as if it wasjust another IP datagram relayed from anothernetwork.
The CPU subsystem can communicate with allother network interfaces through the exchange ofcoded messages across the switch fabric (or on aseparate control bus [44,47]). IP datagrams gen-erated by the CPU protocol entities are also codedin the same format. They carry the IP address ofthe next hop. For that, the CPU needs to access itsindividual routing table. This routing table can bethe master table of the entire router. All otherrouting tables in the network interfaces will beexact replicas (or summaries in compressed tableformat) of the master table. Routing table updatesin the network interfaces can then be done bybroadcasting (if the switch fabric is capable ofthat) or any other suitable data push technique.Any update information (e.g., QoS policies, accesscontrol policies, packet drop policies, etc.) origi-nated in the CPU has to be broadcast to all net-work interfaces. Such special data segments arereceived by the network interfaces which take careof the actual write operation in their forwardingtables. Updates to the routing table in the CPU aredone either by the various routing protocol entitiesor by management action. This centralization isreasonable since routing changes are assumed tohappen infrequently and not particularly timecritical. The CPU can also be con®gured to handleany packet whose destination address cannot befound in the forwarding table in the network in-terface card.
3.5.3. Fast path or slow path?It is not always obvious which router functions
are to be implemented in the fast path or slowpath. Some router designers may choose to includethe ARP processing in the fast path instead of inthe slow path of a router for performance reasons,and because ARP needs direct access to thephysical network. Other may argue for ARP im-
plementation in the slow path instead of the fastpath. For example, in the ARP used for Ethernet[14], if a router gets a datagram to an IP addresswhose Ethernet address it does not know, it issupposed to send an ARP message and hold thedatagram until it gets an ARP reply with thenecessary Ethernet address. When the ARP isimplemented in the slow path, datagrams forwhich the destination link layer address is un-known are passed to the CPU, which does theARP and, once it gets the ARP reply, forwards thedatagram and incorporates the link-layer addressinto future forwarding tables in the network in-terfaces.
There are other functions which router design-ers may argue to be not critical and are more ap-propriate to be implemented in the slow path. IPpacket fragmentation and reassembly, sourcerouting option, route recording option, timestampoption, and ICMP message generation are exam-ples of such functions. It can be argued thatpackets requiring these functions are rare and canbe handled in the slow path: a practical productdoes not need to be able to perform ``wire-speed''routing when infrequently used options are presentin the packet. Since such packets having such op-tions comprise a small fraction of the total tra�c,they can be handled as exception conditions. As aresult, such packets can be handled by the CPU,i.e., the slow path. For IP packet headers witherror, generally, the CPU can instruct the inboundnetwork interface to discard the errored datagram[48]. In some cases, the CPU will generate anICMP message. Alternatively, in the cache-basedscheme [45], templates of some common ICMPmessages such as the TimeExceeded message arekept in the forwarding engine and these can becombined with the IP header to generate a validICMP message.
An IP packet can be fragmented by a router,that is, a single packet can be segmented intomultiple, smaller packets and transmitted onto theoutput ports. This capability allows a router toforward packets between ports where the output isincapable of carrying a packet of the desiredlength; that is, the MTU of the output port is lessthan that of the input port. Fragmentation is goodin the sense that it allows communication between
498 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

end systems connected through links with dis-similar MTUs. It is bad in that it imposes a sig-ni®cant processing burden on the router, whichmust perform more work to generate the resultingmultiple output datagrams from the single inputIP datagram. It is also bad from a data through-put point of view because, when one fragment islost, the entire IP datagram must be retransmitted.The main arguments for implementing fragmen-tation in the slow path is that IP packet frag-mentation can be considered an ``exceptioncondition'', outside of the fast path. Now that IPMTU discovery [13] is prevalent, fragmentationshould be rare.
Reassembly of fragments may be necessary forpackets destined for entities within the router it-self. These fragments may have been generatedeither by other routers in the path between thesender and the router in question or by the originalsending end system itself. Although fragment re-assembly can be a resource-intensive process (bothin CPU cycles and memory), the number ofpackets sent to the router is normally quite lowrelative to the number of packets being routedthrough. The number of fragmented packets des-tined for the router is a small percentage of thetotal router tra�c. Thus, the performance of therouter for packet reassembly is not critical and canbe implemented in the slow path.
The fast path and slow path functions aresummarized in Fig. 9. Fig. 9 further categorizes theslow path router functions into two: those per-formed on a packet-by-packet basis (that is, op-tional or exception conditions) and thoseperformed as background tasks.
3.5.4. Protocol entities and IP processing in thedistributed router architecture
The IP protocol is the most extensive entity inthe packet processing path of an IP router and,thus, IP processing typically determines theachievable performance of a router. Therefore, adecomposition of IP that enables e�cient multi-processing is needed in the distributed router ar-chitecture. An example of a typical functionalpartitioning in the distributed router architectureis shown in Fig. 10.
This distributed multiprocessing architecture,means that the various processing elements canwork in parallel on their own tasks with little de-pendence on the other processors in the system.This architecture decouples the tasks associatedwith determining routes through the network fromthe time-critical tasks associated with IP process-ing. The results of this is an architecture with highlevels of aggregate system performance and theability to scale to increasingly higher performancelevels.
Network interface cards built with general-purpose processors and complex communicationprotocols tend to be more expensive than thosebuilt using ASICs and simple communicationprotocols. Choosing between ASICs and general-purpose processors for an interface card is notstraightforward. General-purpose processors tendto be more expensive, but allow extensive portfunctionality. They are also available o�-the-shelf, and their price/performance ratio improvesyearly [63]. ASICs are not only cheaper, but canalso provide operations that are speci®c torouting, such as traversing a Patricia tree.
Fig. 9. Typical IP router fast-path and slow-path functions.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 499

Moreover, the lack of ¯exibility with ASICs canbe overcome by implementing functionality in theroute processor (e.g., ARP, fragmentation andreassemby, IP options, etc.).
Some router designers often observe that theIPv4 speci®cation is very stable and say that itwould be more cost e�ective to implement theforwarding engine in an ASIC. It is argued thatASIC can reduce the complexity on each systemboard by combining a number of functions intoindividual chips that are designed to perform athigh speeds. It may also be argued that the Inter-net is constantly evolving in a subtle way that re-quire programmability and as such a fastprocessor is appropriate for the forwarding engine.
The forwarding database in a network interfaceconsists of several cross-linked tables as illustratedin Fig. 11. This database can include IP routes(unicast and multicast), ARP tables, and packet®ltering information for QoS and security/accesscontrol.
Now, let us take a generic shared memoryrouter architecture and then trace the path of anIP packet as it goes through an ingress port andout of an egress port. The IP packet processingsteps are shown in Fig. 12.
The IP packet processing steps are as followswith the step numbers corresponding to those inFig. 12:
1. IP header validation. As a packet enters an in-gress port, the forwarding logic veri®es all Lay-er 3 information (header length, packet length,protocol version, checksum, etc.).
2. Route lookup and header processing. The routerthen performs an IP address lookup using thepacketÕs destination address to determine theegress (or outbound) port, and performs all IPforwarding operations (TTL decrement, headerchecksum, etc.).
3. Packet classi®cation. In addition to examining theLayer 3 information, the forwarding engine ex-amines Layer 4 and higher layer packet attributesrelative to any QoS and access control policies.
4. With the Layer 3 and higher layer attributes inhand, the forwarding engine performs one ormore parallel functions:� associates the packet with the appropriatepriority and the appropriate egress port(s)(an internal routing tag provides the switchfabric with the appropriate egress port infor-mation, the QoS priority queue the packet isto be stored in, and the drop priority for con-gestion control),� redirects the packet to a di�erent (overrid-den) destination (ICMP redirect),� drops the packet according to a congestioncontrol policy (e.g., RED [36]), or a securitypolicy, and
Fig. 10. An example functional partitioning in the distributed router architecture.
500 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511
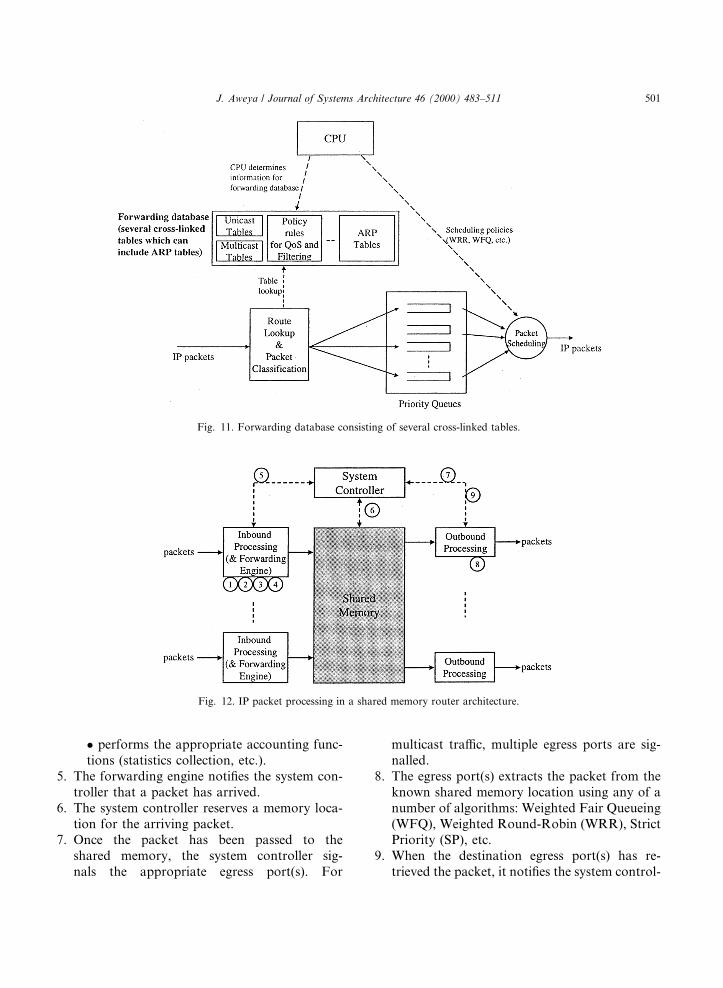
� performs the appropriate accounting func-tions (statistics collection, etc.).
5. The forwarding engine noti®es the system con-troller that a packet has arrived.
6. The system controller reserves a memory loca-tion for the arriving packet.
7. Once the packet has been passed to theshared memory, the system controller sig-nals the appropriate egress port(s). For
multicast tra�c, multiple egress ports are sig-nalled.
8. The egress port(s) extracts the packet from theknown shared memory location using any of anumber of algorithms: Weighted Fair Queueing(WFQ), Weighted Round-Robin (WRR), StrictPriority (SP), etc.
9. When the destination egress port(s) has re-trieved the packet, it noti®es the system control-
Fig. 11. Forwarding database consisting of several cross-linked tables.
Fig. 12. IP packet processing in a shared memory router architecture.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 501

ler, and the memory location is made availablefor new tra�c.
Section 3 does not attempt an exhaustive review ofall possible router architectures. Instead, its aim isto identify the basic approaches that have beenproposed and classify them according to the designtrade-o�s they represent. In particular, it is im-portant to understand how di�erent architecturesfare in terms of performance, implementationcomplexity, and scalability to higher link speeds.In Section 4, we present an overview of the mostcommon switch fabrics used in routers.
4. Typical switch fabrics of routers
Switch fabric design is a very well studied area,especially in the context of Asychronous TransferMode (ATM) switches [5±7], so in this section, weexamine brie¯y the most common fabrics used inrouter design. The switch fabric in a router is re-sponsible for transferring packets between theother functional blocks. In particular, it routesuser packets from the input modules to the ap-propriate output modules. The design of theswitch fabric is complicated by other requirementssuch as multicasting, fault tolerance, and loss anddelay priorities. When these requirements areconsidered, it becomes apparent that the switchfabric should have additional functions, e.g., con-centration, packet duplication for multicasting ifrequired, packet scheduling, packet discarding,and congestion monitoring and control.
Virtually all IP router designs are based onvariations or combinations of the following basicapproaches: shared memory; shared medium; dis-tributed output bu�ered; space division (e.g.,crossbar). Some important considerations for theswitch fabric design are: throughput, packet loss,packet delays, amount of bu�ering, and complex-ity of implementation. For given input tra�c, theswitch fabric designs aim to maximize throughputand minimize packet delays and losses. In addi-tion, the total amount of bu�ering should beminimal (to sustain the desired throughput with-out incurring excessive delays) and implementa-tion should be simple.
4.1. Shared medium switch fabric
In a router, packets may be routed by means ofa shared medium e.g., bus, ring, or dual bus. Thesimplest switch fabric is the bus. Bus-based routersimplement a monolithic backplane comprising asingle medium over which all inter-module tra�cmust ¯ow. Data are transmitted across the bususing Time Division Multiplexing (TDM), inwhich each module is allocated a time slot in acontinuously repeating transmission. However, abus is limited in capacity and by the arbitrationoverhead for sharing this critical resource. Thechallenge is that it is almost impossible to build abus arbitration scheme fast enough to providenon-blocking performance at multigigabit speeds.
An example of a fabric using a time-divisionmultiplexed (TDM) bus is shown in Fig. 13. In-coming packets are sequentially broadcast on thebus (in a round-robin fashion). At each output,address ®lters examine the internal routing tag oneach packet to determine if the packet is destinedfor that output. The address ®lters passes the ap-propriate packets through to the output bu�ers.
It is apparent that the bus must be capable ofhandling the total throughput. For discussion, weassume a router with N input ports and N outputports, with all port speeds equal to S (®xed size)packets per second. In this case, a packet time isde®ned as the time required to receive or transmitan entire packet at the port speed, i.e., 1/S s. If thebus operates at a su�ciently high speed, at leastNS packets/s, then there are no con¯icts forbandwidth and all queueing occurs at the outputs.
Fig. 13. Shared medium switch fabric: a TDM bus.
502 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

Naturally, if the bus speed is less than NS packets/s, some input queueing will probably be necessary.
In this architecture, the outputs are modularfrom each other, which has advantages in imple-mentation and reliability. The address ®lters andoutput bu�ers are straightforward to implement.Also, the broadcast-and-select nature of this ap-proach makes multicasting and broadcasting nat-ural. For these reasons, the bus type switch fabrichas found a lot of implementation in routers.However, the address ®lters and output bu�ersmust operate at the speed of the shared medium,which could be up to N times faster than the portspeed. There is a physical limit to the speed of thebus, address ®lters, and output bu�ers; these limitthe scalability of this approach to large sizes andhigh speeds. Either the size N or speed S can belarge, but there is a physical limitation on theproduct NS. As with the shared memory approach(to be discussed next), this approach involvesoutput queueing, which is capable of the optimalthroughput (compared to simple ®rst-in ®rst-out(FIFO) input queueing). However, the outputbu�ers are not shared, and hence this approachrequires more total amount of bu�ers than theshared memory fabric for the same packet lossrate.
4.2. Shared memory switch fabric
A typical architecture of a shared memoryfabric is shown in Fig. 14. Incoming packets aretypically converted from a serial to parallel form
which are then written sequentially into a (dualport) random access memory. Their packet head-ers with internal routing tags are typically deliv-ered to a memory controller, which decides theorder in which packets are read out of the mem-ory. The outgoing packets are demultiplexed to theoutputs, where they are converted from parallel toserial form. Functionally, this is an outputqueueing approach, where the output bu�ers allphysically belong to a common bu�er pool. Theoutput bu�ered approach is attractive because itcan achieve a normalized throughput of one undera full load [64,65]. Sharing a common bu�er poolhas the advantage of minimizing the amounts ofbu�ers required to achieve a speci®ed packet lossrate. The main idea is that a central bu�er is mostcapable of taking advantage of statistical sharing.If the rate of tra�c to one output port is high, itcan draw upon more bu�er space until the com-mon bu�er pool is (partially or) completely ®lled.For these reasons it is a popular approach forrouter design (e.g., [51±53,56,58±60]).
Unfortunately, the approach has its disadvan-tages. As the packets must be written into and readout from the memory one at a time, the sharedmemory must operate at the total throughput rate.It must be capable of reading and writing a packet(assuming ®xed size packets) in every 1/NS s, thatis, N times faster than the port speed. As the accesstime of random access memories is physicallylimited, this speed-up factor N limits the ability ofthis approach to scale up to large sizes and fastspeeds. Either the size N or speed S can be large,but the memory access time imposes a limit on theproduct NS, which is the total throughput.Moreover, the (centralized) memory controllermust process (the routing tags of) packets at thesame rate as the memory. This might be di�cult if,for instance, the controller must handle multiplepriority classes and complicated packet schedul-ing. Multicasting and broadcasting in this ap-proach will also increase the complexity of thecontroller. Multicasting is not natural to theshared memory approach but can be implementedwith additional control circuitry. A multicastpacket may be duplicated before the memory orread multiple times from the memory. The ®rstapproach obviously requires more memory be-Fig. 14. A shared memory switch fabric.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 503

cause multiple copies of the same packet aremaintained in the memory. In the second ap-proach, a packet is read multiple times from thesame memory location [78±80]. The control cir-cuitry must keep the packet in memory until it hasbeen read to all the output ports in the multicastgroup.
A single point of failure is invariably introducedin the shared memory-based design because add-ing a redundant switch fabric to this design is socomplex and expensive. As a result, shared mem-ory switch fabrics are best suited for small capacitysystems.
4.3. Distributed output bu�ered switch fabric
The distributed output bu�ered approach isshown in Fig. 15. Independent paths exist betweenall N 2 possible pairs of inputs and outputs. In thisdesign, arriving packets are broadcast on separatebuses to all outputs. Address ®lters at each outputdetermine if the packets are destined for thatoutput. Appropriate packets are passed throughthe address ®lters to the output queues.
This approach o�ers many attractive features.Naturally there is no con¯ict among the N 2 inde-pendent paths between inputs and outputs, andhence all queueing occurs at the outputs. As statedearlier, output queueing achieves the optimalnormalized throughput compared to simple FIFOinput queueing [64,65]. Like the shared mediumapproach, it is also broadcast-and-select in nature
and, therefore, multicasting is natural. For multi-casting, an address ®lter can recognize a set ofmulticast addresses as well as output port ad-dresses. The address ®lters and output bu�ers aresimple to implement. Unlike the shared mediumapproach, the address ®lters and bu�ers need tooperate only at the port speed. All of the hardwarecan operate at the same speed. There is no speed-up factor to limit scalability in this approach. Forthese reasons, this approach has been taken insome commercial router designs (e.g., [57]).
Unfortunately, the quadratic N 2 growth ofbu�ers means that the size N must be limited forpractical reasons. However, in principle, there isno severe limitation on S. The port speed S can beincreased to the physical limits of the address ®l-ters and output bu�ers. Hence, this approachmight realize a high total throughput NS packetsper second by scaling up the port speed S. TheKnockout switch was an early prototype thatsuggested a trade-o� to reduce the amount ofbu�ers at the cost of higher packet loss [66]. In-stead of N bu�ers at each output, it was proposedto use only a ®xed number L bu�ers at each output(for a total of NL bu�ers which is linear in N),based on the observation that the simultaneousarrival of more than L packets (cells) to any out-put was improbable. It was argued that L� 8 issu�cient under uniform random tra�c conditionsto achieve a cell loss rate of 10ÿ6 for large N.
4.4. Space division switch fabric: the crossbar switch
Optimal throughput and delay performance isobtained using output bu�ered switches. More-over, since upon arrival, the packets are immedi-ately placed in the output bu�ers, it is possible tobetter control the latency of the packet. This helpsin providing QoS guarantees. While this architec-ture appears to be especially convenient for pro-viding QoS guarantees, it has serious limitations:the output bu�ered switch memory speed must beequal to at least the aggregate input speed acrossthe switch. To achieve this, the switch fabric mustoperate at a rate at least equal to the aggregate ofall the input links connected to the switch. How-ever, increasing line rate (S) and increasing switchsize (N) make it extremely di�cult to signi®cantlyFig. 15. A distributed output bu�ered switch fabric.
504 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

speedup the switch fabric, and also build memorieswith a bandwidth of order O(NS).
At multigigabit and terabit speeds it becomesdi�cult to build output bu�ered switches. As aresult some high-speed implementations are basedon the input bu�ered switch architecture. One ofthe most popular interconnection networks usedfor building input bu�ered switches is the crossbarbecause of its (i) low cost, (ii) good scalability and(iii) non-blocking properties. Crossbar switcheshave an architecture that, depending on the im-plementation, can scale to very high bandwidths.Considerations of cost and complexity are theprimary constraints on the capacity of switches ofthis type. The crossbar switch (see Fig. 16) is asimple example of a space division fabric whichcan physically connect any of the N inputs to anyof the N outputs. An input bu�ered crossbarswitch has the crossbar fabric running at the linkrate. In this architecture bu�ering occurs at theinputs, and the speed of the memory does not needto exceed the speed of a single port. Given thecurrent state of technology, this architecture iswidely considered to be substantially more scalablethan output bu�ered or shared memory switches.However, the crossbar architecture presents manytechnical challenges that need to be overcome inorder to provide bandwidth and delay guarantees.Examples of commercial routers that use crossbarswitch fabrics are [54,55,61].
We start with the issue of providing bandwidthguarantees in the crossbar architecture. For thecase where there is a single FIFO queue at each
input, it has long been known that a seriousproblem referred to as head-of-line (HOL) block-ing [64] can substantially reduce achievablethroughput. In particular, the well-known resultsof [64] is that for uniform random distribution ofinput tra�c, the achievable throughput is only58.6%. Moreover, Li [67] has shown that themaximum throughput of the switch decreasesmonotonically with increasing burst size. Consid-erable amount of work has been done in recentyears to build input bu�ered switches that matchthe performance of an output bu�ered switch. Oneway of reducing the e�ect of HOL blocking is toincrease the speed of the input/output channel (i.e.,the speedup of the switch fabric). Speedup is de-®ned as the ratio of the switch fabric bandwidthand the bandwidth of the input links. There havebeen a number of studies such as [68,69] whichshowed that an input bu�ered crossbar switch witha single FIFO at the input can achieve about 99%throughput under certain assumptions on the in-put tra�c statistics for speedup in the range of 4±5. A more recent simulation study [70] suggestedthat speedup as low as 2 may be su�cient to ob-tain performance comparable to that of outputbu�ered switches.
Another way of eliminating the HOL blockingis by changing the queueing structure at the in-put. Instead of maintaining a single FIFO at theinput, a separate queue per each output can bemaintained at each input (virtual output queues(VOQs)). However, since there could be conten-tion at the inputs and outputs, there is a necessityfor an arbitration algorithm to schedule packetsbetween various inputs and outputs (equivalentto the matching problem for bipartite graphs). Ithas been shown that an input bu�ered switchwith VOQs can provide asymptotic 100%throughput using a maximum matching algo-rithm [71]. However, the complexity of the bestknown maximum match algorithm is too high forhigh-speed implementation. Moreover, undercertain tra�c conditions, maximum matching canlead to starvation. Over the years, a number ofmaximal matching algorithms have been pro-posed [72±75].
As stated above, increasing the speedup ofthe switch fabric can improve the performanceFig. 16. A crossbar switch.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 505

of an input bu�ered switch. However, when theswitch fabric has a higher bandwidth than thelinks, bu�ering is required at the outputs too.Thus a combination of input bu�ered and out-put bu�ered switch is required, i.e., CombinedInput and Output Bu�ered (CIOB). The goal ofmost designs then is to ®nd the minimumspeedup required to match the performance ofan output bu�ered switch using a CIOB andVOQs. McKeown et al. [76] shown that a CIOBswitch with VOQs is always work conserving ifspeedup is greater than N/2. In a recent work,Prabhakar et al. [77] showed that a speed of 4is su�cient to emulate an output bu�ered switch(with an output FIFO) using a CIOB switchwith VOQs.
Multicast in the space division fabrics is simpleto implement but has some consequences. Forexample, a crossbar switch (with input bu�ering) isnaturally capable of broadcasting one incomingpacket to multiple outputs. However, this wouldaggravate the HOL blocking at the input bu�ers.Approaches to alleviate the HOL blocking e�ectwould increase the complexity of bu�er control.Other ine�cient approaches in crossbar switchesrequire an input port to write out multiple copiesof the packet to di�erent output ports one at atime. This does not support the one-to-manytransfers required for multicasting as in the sharedbus architecture and the fully distributed outputbu�ered architectures. The usual concern aboutmaking multiple copies is that it reduces e�ectiveswitch throughput. Several approaches for han-dling multicasting in crossbar switches have beenproposed, e.g., [81]. Generally, multicasting in-creases the complexity of space division fabrics.
4.5. Other issues in router switch fabric design
We have described above four typical designapproaches for router switch fabrics. Needless tosay, endless variations of these designs can beimagined but the above are the most commonfabrics found in routers. There are other issuesapplicable to understanding the trade-o�s involvedin any new design. We discuss some of these issuesnext.
4.5.1. Construction of large router switch fabricsWith regard to the construction of large switch
fabrics, most of the four basic switch fabric designapproaches are capable of realizing routers oflimited throughput. The shared memory andshared medium approaches can achieve athroughput limited by memory access time. Thespace division approach has no special constraintson throughput or size, only physical factors dolimit the maximum size in practice [82]. There arephysical limits to the circuit density and number ofinput/output (I/O) pins. Interconnection com-plexity and power dissipation become more di�-cult issues with fabric size [83]. In addition,reliability and repairability become di�cult withsize. Modi®cations to maximize the throughput ofspace division fabrics to address HOL blockingincreases the implementation complexity.
It is generally accepted that large router switchfabrics of 1 terabits per second (Tbps) throughputor more cannot be realized simply by scaling up afabric design in size and speed. Instead, largefabrics must be constructed by interconnection ofswitch modules of limited throughput. The smallmodules may be designed following any approach,and there are various ways to interconnect them[84±86].
4.5.2. Fault tolerance and reliabilityWith the rapid growth of the Internet and the
emergence of growing competition between Inter-net Service Providers (ISPs), reliability has becomean important issue for IP routers. In addition,multigigabit routers will be deployed in the core ofenterprise networks and the Internet. Tra�c fromthousands of individual ¯ows pass through theswitch fabric at any given time [46]. Thus, the ro-bustness and overall availability of the switchfabric becomes a critically important design pa-rameter. As in any communication system, faulttolerance is achieved by adding redundancy to thecrucial components. In a router, one of the mostcrucial components is the packet routing andbu�ering fabric. Redundancy may be added in twoways: by duplicating copies of the switch fabric orby adding redundancy within the fabric [87±90].In addition to redundancy, other considerations
506 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

include detection of faults and isolation and re-covery.
4.5.3. Bu�er management and quality of serviceThe prioritization of mission critical applica-
tions and the support of IP telephony and videoconferencing create the requirement for supportingQoS enforcement with the switch fabric. Theseapplications are sensitive to both absolute latencyand latency variations.
Beyond best-e�ort service, routers are begin-ning to o�er a number of QoS or priority classes.Priorities are used to indicate the preferentialtreatment of one tra�c class over another. Theswitch fabrics must handle these classes of tra�cdi�erently according to their QoS requirements. Inthe output bu�ered switch fabric, for example,typically the fabric will have multiple bu�ers ateach output port and one bu�er for each QoStra�c class. The bu�ers may be physically separateor a physical bu�er may be divided logically intoseparate bu�ers.
Bu�er management here refers to the discardingpolicy for the input of packets into the bu�ers(e.g., Random Early Detection (RED)), and thescheduling policy for the output of packets fromthe bu�ers (e.g., strict priority, weighted round-robin (WRR), weighted fair queueing (WFQ),etc.). Bu�er management in the IP router involvesboth dimensions of time (packet scheduling) andbu�er space (packet discarding). The IP tra�cclasses are distinguished in the time and space di-mensions by their packet delay and packet losspriorities. We therefore see that bu�er manage-ment and QoS support is an integral part of theswitch fabric design.
5. Conclusions and open problems
IP provides a high degree of ¯exibility inbuilding large and arbitrary complex networks.Interworking routers capable of forwarding ag-gregate data rates in the multigigabit and terabitper second range are required in emerging highperformance networking environments. This paperhas presented an evaluation of typical approachesproposed for designing high-speed routers. We
have focused primarily on the architectural over-view and the design of the components that havethe highest e�ect on performance.
First, we have observed that high-speed routersneed to have enough internal bandwidth to movepackets between its interfaces at multigigabit andterabit rates. The router design should use aswitched backplane. Until very recently, the stan-dard router used a shared bus rather than a swit-ched backplane. While bus-based routers mayhave satis®ed the early needs of IP networks,emerging demands for high bandwidth, QoS de-livery, multicast, and high availability place thebus architecture at a signi®cant disadvantage. Forhigh speeds, one really needs the parallelism of aswitch with superior QoS, multicast, scalability,and robustness properties. Second, routers needenough packet processing power to forward sev-eral million packets per second (Mpps). Routingtable lookups and data movements are the majorconsumers of processing cycles. The processingtime of these tasks does not decrease linearly iffaster processors are used. This is because of thesometimes dominating e�ect of memory accessrate.
It is observed that while an IP router must, ingeneral, perform a myriad of functions, in prac-tice the vast majority of packets need only a fewoperations performed in real-time. Thus, theperformance critical functions can be implement-ed in hardware (the fast path) and the remaining(necessary, but less time-critical) functions insoftware (the slow path). IP contains many fea-tures and functions that are either rarely used orthat can be performed in the background of high-speed data forwarding (for example, routingprotocol operation and network management).The router architecture should be optimized forthose functions that must be performed in real-time, on a packet-by-packet basis, for the ma-jority of the packets. This creates an optimizedrouting solution that route packets at high speedat a reasonable cost.
It has been observed in [63] that the cost of arouter port depends on, (1) the amount and kindof memory it uses, (2) its processing power, and (3)the complexity of the protocol used for commu-nication between the port and the route processor.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 507

This means the design of a router involve trade-o�s between performance, complexity, and cost.
Router ports built with general-purpose pro-cessors and complex communication protocolstend to be more expensive than those built usingASICs and simple communication protocols.Choosing between ASICs and general-purposeprocessors for an interface card is not straight-forward. General-purpose processors are costlier,but allow extensive port functionality, are avail-able o�-the-shelf, and their price/performance ra-tio improves rapidly with time [63]. ASICs are notonly cheaper, but can also provide operations thatare speci®c to routing, such as traversing a Patriciatree. Moreover, the lack of ¯exibility with ASICscan be overcome by implementing functionality inthe route processor.
The cost of a router port is also proportional tothe type and size of memory on the port. SRAMso�er faster access times, but are more expensivethan DRAMs. Bu�er memory is another param-eter that is di�cult to size. In general, the rule ofthumb is that a port should have enough bu�ers tosupport at least one bandwidth-delay productworth of packets, where the delay is the mean end-to-end delay and the bandwidth is the largestbandwidth available to TCP connections travers-ing that router. This sizing allows TCP to increasetheir transmission windows without excessivelosses.
The cost of a router port is also determined bythe complexity of the internal connections betweenthe control paths and the data paths in the portcard. In some designs, a centralized controllersends commands to each port through the switchfabric and the portÕs internal bu�ers. Careful en-gineering of the control protocol is necessary toreduce the cost of the port control circuitry andalso the loss of command packets which will cer-tainly need retransmission.
The design principles of router fabrics are wellknown, at least for some common switch fabrics.In many cases it is possible to leverage many of thedesign principles from ATM switches into nextgeneration multigigabit routers. Although the de-sign principles for most fabrics are well establishedby now, the design is complicated by consider-ations for fault tolerance, multicasting, and
queueing priorities. Fault tolerance implies thenecessity of redundant resources in the fabric. Thestraightforward approach of duplicating parallelplanes may also improve throughput. Alterna-tively, various ways exist to add redundancywithin a single fabric plane. Multicasting dependson the fabric design because some design ap-proaches inherently broadcast every packet. Forspace division fabrics, including large fabricsconstructed by interconnection of small modules,multicasting can be complex.
It will also be necessary to manage multiplebu�ers to satisfy the QoS requirements of thedi�erent tra�c classes. Bu�er management consistof packet scheduling and discarding policies,which determine the manner in which packets areinput into and output from the bu�ers. The packetscheduling policy attempts to satisfy the delay re-quirements as indicated by delay priorities. Thepacket discarding policy attempts to satisfy theloss requirements as indicated by packet loss pri-orities.
Signi®cant advances have been made in routerdesigns to address the most demanding customerissues regarding high-speed packet forwarding(e.g., route lookup algorithms, high-speed switch-ing cores and forwarding engines), low per-portcost, ¯exibility and programmability, reliability,and ease of con®guration. While these advanceshave been made in the design of IP routers, someimportant open issues still remain to be resolved.These include packet classi®cation and resourceprovisioning, improved price/performance routerdesigns, ``active networking'' [91] and ease ofcon®guration, reliability and fault tolerance de-signs, and Internet billing/pricing. Extensive workis being carried out both in the research commu-nity and industry to address these problems.
References
[1] P. Newman, T. Lyon, G. Minshall, Flow labelled IP: a
connectionless approach to ATM, in: Proceedings of the
IEEE Infocom Õ96, San Francisco, CA, March 1996, pp.
1251±1260.
[2] Y. Katsube, K. Nagami, H. Esaki, ToshibaÕs router
architecture extensions for ATM: overview, in: IETF
RFC 2098, April 1997.
508 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

[3] Y. Rekhter, B. Davie, D. Katz, E. Rosen, G. Swallow,
Cisco systems tag switching architecture overview, in:
IETF RFC 2105, February 1997.
[4] F. Baker, Requirements for IP Version 4 routers, in: IETF
RFC 1812, June 1995.
[5] H. Ahmadi, W. Denzel, A survey of modern high perfor-
mance switching techniques, IEEE J. Selected Areas
Commun. 7 (1989) 1091±1103.
[6] F. Tobagi, Fast packet switch architectures for broadband
integrated services digital networks, Proc. IEEE 78 (1990)
133±178.
[7] R.Y. Awdeh, H.T. Mouftah, Survey of ATM switch
architectures, Computer Net. and ISDN Syst. 27 (1995)
1567±1613.
[8] R. Perlman, Interconnections: Bridges and Routers, Add-
ison-Wesley, Reading, MA, 1992.
[9] C. Huitema, Routing in the Internet, Prentice Hall,
Englewood Cli�s, NJ, 1996.
[10] J. Moy, OSPF: Anatomy of an Internet Routing Protocol,
1998.
[11] W.R. Stevens, TCP/IP Illustrated, vol. 1, The Protocols,
Addison-Wesley, Reading, MA, 1994.
[12] C.A. Kent, J.C. Mogul, Fragmentation considered harm-
ful, Computer Commun. Rev. 17 (5) (1987) 390±401.
[13] J. Mogul, S. Deering, Path MTU Discovery IETF RFC
1191, April 1990.
[14] D. Plummer, Ethernet address resolution protocol: or
converting network protocol addresses to 48-bit ethernet
addresses for transmission on ethernet hardware, in: IETF
RFC 826, November 1982.
[15] T. Bradley, C. Brown, Inverse address resolution protocol,
in: IETF RFC 1293, January 1992.
[16] V. Fuller et al., Classless inter-domain routing, in: IETF
RFC 1519, June 1993.
[17] K. Sklower, A tree-based packet routing table for Berkeley
Unix, in: USENIX, Winter Õ91, Dallas, TX, 1991.
[18] W. Doeringer, G. Karjoth, M. Nassehi, Routing on
longest-matching pre®xes, IEEE/ACM Trans. Networking
4 (1) (1996) 86±97.
[19] D.R. Morrison, Patricia ± practical algorithm to retrieve
information coded in alphanumeric, J. ACM 15 (4) (1968)
515±534.
[20] D.C. Feldmeier, Improving gateway performance with a
routing-table cache, in: Proceedings of the IEEE Infocom
Õ88, New Orleans, LI, March 1988.
[21] C. Partridge, Locality and route caches, in: NSF Work-
shop on Internet Statistics Measurement and Analysis, San
Diego, CA, February 1996.
[22] D. Knuth, The Art of Computer Programming, vol. 3,
Sorting and Searching, Addison-Wesley, Reading, MA,
1973.
[23] M. Degermark, Small forwarding tables for fast routing
lookups, in: Proceedings of the ACM SIGCOMM Õ97,
Cannes, France, September 1997.
[24] H.Y. Tzeng, Longest pre®x search using compressed trees,
in: Proceedings of the Globecom Õ98, Sydney, Australia,
November 1998.
[25] M. Waldvogel, G. Varghese, J. Turner, B. Plattner,
Scalable high speed IP routing lookup, in: Proceedings of
the ACM SIGCOMM Õ97, Cannes, France, September
1997.
[26] V. Srinivasan, G. Varghese, Faster IP lookups using
controlled pre®x expansion, in: Proceedings of the ACM
SIGMETRICS, May 1998.
[27] S. Nilsson, G. Karlsson, Fast address look-up for internet
routers, in: Proceedings of the IEEE Broadband Commu-
nications Õ98, April 1998.
[28] E. Filippi, V. Innocenti, V. Vercellone, Address lookup
solutions for gigabit switch/router, in: Proceedings of the
Globecom Õ98, Sydney, Australia, November 1998.
[29] A.J. McAuley, P. Francis, Fast routing table lookup using
CAMs, in: Proceedings of the IEEE Infocom Õ93, San
Francisco, CA, March 1993, pp. 1382±1391.
[30] T.B. Pei, C. Zukowski, Putting routing tables in silicon,
IEEE Network 6 (1992) 42±50.
[31] M. Zitterbart et al., HeaRT: high performance routing
table lookup, in: Fourth IEEE Workshop on Architecture
and Implementation of High Performance Communica-
tions Subsystems, Thessaloniki, Greece, June 1997.
[32] P. Gupta, S. Lin, N. McKeown, Routing lookups in
hardware at memory access speeds, in: Proceedings of the
IEEE Infocom Õ98, March 1998.
[33] C. Rigney, A. Rubens, W. Simpson, S. Willens, Remote
Authentication Dial-In User Service (RADIUS), in: IETF
RFC 2138, April 1997.
[34] V. Jacobson, Congestion avoidance and control, Comput.
Commun. Rev. 18 (4) (1988).
[35] W. Stevens, TCP slow start, congestion avoidance, fast
retransmit and fast recovery algorithms, in: IETF RFC
2001, January 1997.
[36] S. Floyd, V. Jacobson, Random early detection gateways
for congestion avoidance, IEEE/ACM Trans. Networking
1 (4) (1993).
[37] A. Demers, S. Keshav, S. Shenker, Analysis and simulation
of a fair queueing algorithm, Journal of Internetworking:
Research and Experience 1 (1990).
[38] S. Floyd, V. Jacobson, Link sharing and resource man-
agement models for packet networks, IEEE/ACM Trans.
Networking 3 (4) (1995).
[39] L. Zhang, S. Deering, D. Estrin, S. Shenker, D. Zappala,
RSVP: A new resource reservation protocol, in: IEEE
Network, September 1993.
[40] K. Nichols, S. Blake, Di�erentiated services operational
model and de®nitions, in: IETF Work in progress.
[41] S. Blake, An architecture for di�erentiated services, in:
IETF Work in progress.
[42] S.F. Bryant, D.L.A. Brash, The DECNIS 500/600 multi-
protocol bridge router and gateway, Digital Technical
Journal 5 (1) (1993).
[43] P. Marimuthu, I. Viniotis, T.L. Sheu, A parallel router
architecture for high speed LAN internetworking, in:
Proceedings of the 17th IEEE Conference on Local
Computer Networks, Minneapolis, Minnesota, September
1992.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 509

[44] S. Asthana, C. Delph, H.V. Jagadish, P. Krzyzanowski,
Towards a gigabit IP router, Journal of High Speed
Networks 1 (4) (1992).
[45] C. Partridge, A 50Gb/s IP router, IEEE/ACM Trans.
Networking 6 (3) (1998) 237±248.
[46] K. Thomson, G.J. Miller, R. Wilder, Wide-area tra�c
patterns and characteristics, in: IEEE Network, December
1997.
[47] V.P. Kumar, T.V. Lakshman, D. Stiliadis, Beyond best
e�ort: router architectures for the di�erentiated services of
tomorrowÕs internet, in: IEEE Commun. Mag., May 1998,
pp. 152±164.
[48] A. Tantawy, O. Koufopavlou, M. Zitterbart, J. Abler, On
the design of a multigigabit IP router, Journal of High
Speed Networks 3 (1994) 209±232.
[49] O. Koufopavlou, A. Tantawy, M. Zitterbart, IP-Routing
among gigabit networks, in: S. Rao (Ed.), Interoperability
in Broadband Networks, IOS Press, 1994, pp. 282±289.
[50] O. Koufopavlou, A. Tantawy, M. Zitterbart, A compar-
ison of gigabit router architectures, in: E. Fdida (Ed.),
High Performance Networking, North-Holland, Amster-
dam, 1994.
[51] Implementing the Routing Switch: How to Route at Switch
Speeds and Switch Costs, White Paper, Bay Networks,
1997.
[52] Catalyst 8510 Architecture, White Paper, Cisco Systems,
1998.
[53] Catalyst 8500 Campus Switch Router Series, White Paper,
Cisco Systems, 1998 .
[54] Cisco 12000 Gigabit Switch Router, White Paper, Cisco
Systems, 1997.
[55] Performance Optimized Ethernet Switching, Cajun White
Paper #1, Lucent Technologies.
[56] Internet Backbone Routers and Evolving Internet Design,
White Paper, Juniper Networks, September 1998.
[57] The Integrated Network Services Switch Architecture and
Technology, White Paper, Berkeley Networks, 1997.
[58] Torrent IP9000 Gigabit Router, White Paper, Torrent
Networking Technologies, 1997.
[59] Wire-Speed IP Routing, White Paper, Extreme Networks,
1997.
[60] PE-4884 Gigabit Routing Switch, White Paper, Packet
Engines, 1997.
[61] GRF 400 White Paper: A Practical IP Switch for Next-
Generation Networks, White Paper, Ascend Communica-
tions, 1998.
[62] Rule Your Networks: An Overview of StreamProcessor
Applications, White Paper, NEO Networks, 1997.
[63] S. Keshav, R. Sharma, Issues and Trends in Router
Design, IEEE Commun. Mag., May 1998, pp. 144±151.
[64] M. Karol, M. Hluchyj, S. Morgan, Input versus output
queueing on a space-division packet switch, IEEE Trans.
Commun. 35 (1987) 1337±1356.
[65] M. Hluchyj, M. Karol, Qeueuing in high-performance
packet switching, IEEE J. Selected Areas Commun. 6
(1988) 1587±1597.
[66] Y.S. Yeh, M. Hluchyj, A.S. Acampora, The knockout
switch: a simple modular architecture for high-perfor-
mance packet switching, IEEE J. Selected Areas Commun.
5 (8) (1987) 1274±1282.
[67] S.Q. Li, Performance of a non-blocking space-division
packet switch with correlated input tra�c, in: Proceedings
of the IEEE Globecom Õ89, 1989, pp. 1754±1763.
[68] C.Y. Chang, A.J. Paulraj, T. Kailath, A broadband packet
switch architecture with input and output queueing, in:
Proceedings of the Globecom Õ94, 1994.
[69] I. Iliadis, W. Denzel, Performance of packet switches with
input and output queueing, in: Proc. ICC Õ90, 1990.
[70] R. Guerin, K.N. Sivarajan, Delay and throughput perfor-
mance of speed-up input-queueing packet switches, in:
IBM Research Report RC 20892, June 1997.
[71] N. McKeown, V. Anantharam, J. Walrand, Achieving
100% Throughput in an input-queued switch, in: Proceed-
ings of the IEEE Infocom Õ96, 1996, pp. 296±302.
[72] T.E. Anderson, S.S. Owicki, J.B. Saxe, C.P. Thacker, High
speed switch scheduling for local area networks, ACM
Trans. Computer Sys. 11 (4) (1993) 319±352.
[73] D. Stiliadis, A. Verma, Providing bandwidth guarantees in
an input-bu�ered crossbar switch, Proc. IEEE Infocom '95
(1995) 960±968.
[74] C. Lund, S. Phillips, N. Reingold, Fair prioritized sched-
uling in an input-bu�ered switch, in: Proceedings of the
Broadband Communications, 1996.
[75] A. Mekkittikul, N. McKeown, A practical scheduling
algorithm to achieve 100% throughput in input-queued
switches, in: Proceedings of the IEEE Infocom Õ98, March
1998.
[76] N. McKeown, B. Prabhakar, M. Zhu, Matching output
queueing with combined input and output queueing, in:
Proceedings of the 35th Annual Allerton Conference on
Communications, Control and Computing, October 1997.
[77] B. Prabhakar, N. McKeown, On the speedup required for
combined input and output queueing switching, Computer
Systems Lab, Technical Report CSL-TR-97-738, Stanford
University.
[78] N. Endo et al., Shared bu�er memory switch for an ATM
exchange, IEEE Trans. Commun. 41 (1993) 237±245.
[79] H. Kuwahara, A shared bu�er memory switch for an ATM
exchange, in: Proceedings of the ICC Õ89, Boston, 1989, pp.
118±122.
[80] Y. Sakurai, ATM switching systems for B-ISDN, Hitachi
Rev. 40 (1990) 193±198.
[81] N. McKeown, Fast Switched Backplane for a Gigabit
Switched Router, Technical Report, Department of Elec-
trical Engineering, Stanford University.
[82] T. Lee, A modular architecture for very large packet
switches, IEEE Trans. Commun. 38 (1990) 1097±1106.
[83] T. Bandwell, Physical design issues for very large scale atm
switching systems, IEEE J. Selected Areas Commun. 9
(1991) 1227±1238.
[84] K. Murano, Technologies towards broadband ISDN,
IEEE Commun. Mag. 28 (1990) 66±70.
510 J. Aweya / Journal of Systems Architecture 46 (2000) 483±511

[85] A. Itoh et al., Practical implementation and packaging
technologies for a large-scale ATM switching system, IEEE
J. Selected Areas Commun 9 (1991) 1280±1288.
[86] T. Kozaki et al., 32 ´ 32 Shared bu�er type ATM switch
VLSIÕs for B-ISDNÕs, IEEE J. Selected Areas Commun. 9
(1991) 1239±1247.
[87] V. Kumar, S. Wang, Reliability enhancement by time and
space redundancy in multistage interconnection networks,
IEEE Trans. Reliability 40 (1991) 461±473.
[88] G. Adams et al., A survey and comparison of fault-tolerant
multistage interconnection networks, IEEE Comput. 20
(1987) 14±27.
[89] D. Agrawal, Testing and fault-tolerance of multistage
interconnection networks, IEEE Comput. 15 (1982) 41±53.
[90] A. Itoh, A fault-tolerant switching network for BISDN,
IEEE J. Selected Areas Commun. 9 (1991) 1218±1226.
[91] D. Tennenhouse et al., A Survey of Active Network
Research, in: IEEE Commun. Mag., January 1997.
[92] A. Rijsinghani, Computation of the Internet Checksum via
Incremental Update, in: IETF RFC 1624, May 1994.
James Aweya received his B.Sc. (Hon)degree from the University of Scienceand Technology, Kumasi, Ghana, andhis M.Sc. degree from the Universityof Saskatchewan, Saskatoon, Canada,all in electrical engineering. He re-cently completed his Ph.D. studies inelectrical engineering at the Universityof Ottawa. In 1986 he joined theElectricity Corporation of Ghana,where he worked on the design andoperation of electric distribution sys-tems. From 1987 to 1990, he was with
the Volta River Authority where he was engaged in the in-strumentation and control of electric power systems. Since 1996he has been with Nortel Networks where he is a Systems DesignEngineer. He is currently involved in the design of resourcemanagement functions for IP and ATM networks, architecturalissues and design of IP routers, and network architectures andprotocols. He has published more than 25 journal and confer-ence papers and has 5 patents pending. In addition to computernetworks and protocols, he has other interest in fuzzy logiccontrol, neural networks, and application of arti®cial intelli-gence to computer networking.
J. Aweya / Journal of Systems Architecture 46 (2000) 483±511 511