∂u∂u multi-tenanted framework: distributed near duplicate detection for big data
TRANSCRIPT

∂u∂u Multi-Tenanted Framework:Distributed Near Duplicate Detection for Big Data
Pradeeban Kathiravelu, Helena Galhardas, Luıs Veiga
INESC-ID LisboaInstituto Superior Tecnico, Universidade de Lisboa
Lisbon, Portugal
23rd International Conference on Cooperative Information Systems (CoopIS 2015)28-30 October 2015, Rhodes, Greece.
Distributed Near Duplicate Detection ∂u∂u 1 / 23

Introduction
Introduction
Data cleaning is essential for enterprise information systems.
Finding near duplicates is an important task in data cleaning.
Near duplicate detection algorithms to find “almost” identicalentries.
Massive datasets require large memory and processing power.
Distributed Near Duplicate Detection ∂u∂u 2 / 23

Introduction
Motivation
Most data cleaning algorithms are sequential.
Recent use of MapReduce frameworks in near duplicate detection.
In-Memory Data Grids (IMDG) offer a view of a large computer byunifying the resources across a distributed computer cluster.
What if..?
Distributed Near Duplicate Detection ∂u∂u 3 / 23

Introduction
∂u∂u
A distributed architecture for near duplicate detection.
An efficient distribution strategy for the blocks over IMDGs.Adapting the existing algorithms.
To execute on a computer cluster or a public/private cloud.
Leverage MapReduce framework offered by the IMDG.
In identifying the blocks.
Distributed Near Duplicate Detection ∂u∂u 4 / 23

∂u∂u Architecture
Contributions
Faster near duplicate detection over massive datasets.
which may not have been possible to execute on the utility computers.High speedup and lower communication and coordination overhead.
Multi-tenanted parallel processing architecture.
Coordinated for multi-pass over multiple keys.More accurate and precise duplicate detection.
Strategy and algorithms loosely coupled to the base algorithms.
Potential to distribute more algorithms.Configuring based on user preferences.
Adaptively involving the instances in near duplicate detection.
Distributed Near Duplicate Detection ∂u∂u 5 / 23
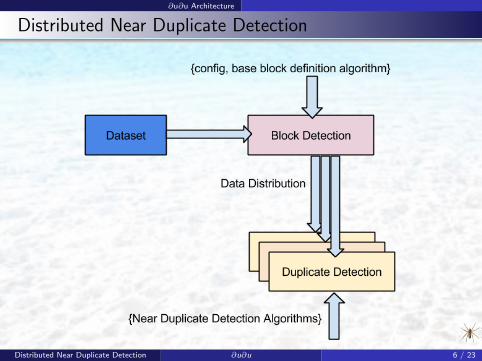
∂u∂u Architecture
Distributed Near Duplicate Detection
Distributed Near Duplicate Detection ∂u∂u 6 / 23

∂u∂u Architecture
Distributed Near Duplicate Detection
Distributed Near Duplicate Detection ∂u∂u 7 / 23
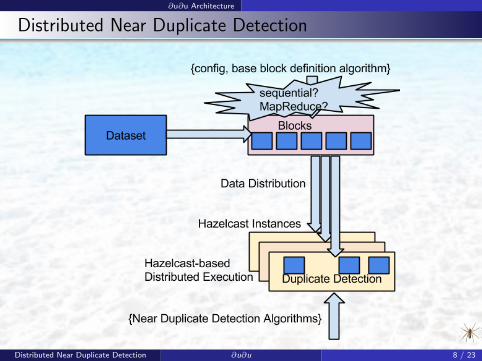
∂u∂u Architecture
Distributed Near Duplicate Detection
Distributed Near Duplicate Detection ∂u∂u 8 / 23
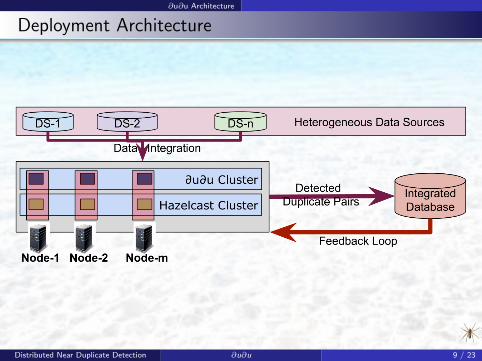
∂u∂u Architecture
Deployment Architecture
Distributed Near Duplicate Detection ∂u∂u 9 / 23
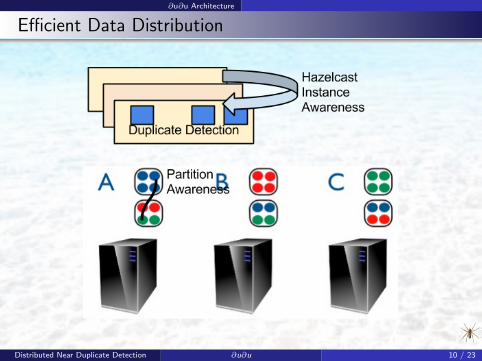
∂u∂u Architecture
Efficient Data Distribution
Distributed Near Duplicate Detection ∂u∂u 10 / 23

∂u∂u Architecture
Partition of storage and execution across the instances
Distributed Near Duplicate Detection ∂u∂u 11 / 23
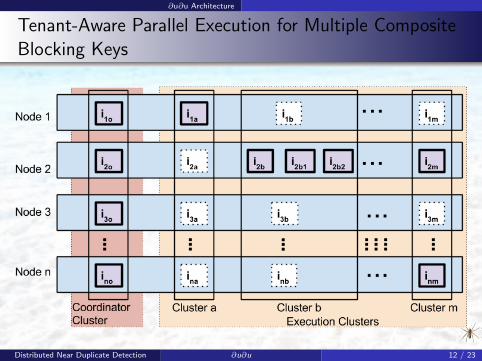
∂u∂u Architecture
Tenant-Aware Parallel Execution for Multiple CompositeBlocking Keys
Distributed Near Duplicate Detection ∂u∂u 12 / 23

∂u∂u Architecture
Matrix Notation
Distributed Near Duplicate Detection ∂u∂u 13 / 23

∂u∂u Architecture
Software Architecture
Distributed Near Duplicate Detection ∂u∂u 14 / 23

∂u∂u Prototype
Prototype Implementation
Java 1.8.0 as the programming language.
Hazelcast 3.4 as the in-memory data grid.
Data sources connected through their respective Java driver APIs.
MongoDB 2.4.9.MySQL 5.5.41-0ubuntu0.14.04.1.
PPJoin as the base near duplicate detection algorithm.
Extended for distributed execution on Hazelcast.
Distributed Near Duplicate Detection ∂u∂u 15 / 23

Evaluation
Prototype Deployment
Intel R© CoreTM i7-4700MQ
CPU @ 2.40GHz 8 processor.8 GB memory.Ubuntu 14.04 LTS 64 bit operating system.
Two Mongo databases connected as the data sources.
Having the potential duplicate pairs.
Hadoop HDFS to store the detected duplicate pairs.
Distributed Near Duplicate Detection ∂u∂u 16 / 23

Evaluation
Evaluation System Configurations
Around 100 datasets of varying sizes above 1 GB.
With varying number of nodes configured to execute in a cluster.Each cluster configured to have an executor instance.
Fairness in evaluations.
Number of iterations and the blocking keys maintained to be sameacross all the experiments.
Distributed Near Duplicate Detection ∂u∂u 17 / 23

Evaluation
Preliminary Assessments
Performance and speed up
With multi-pass in 4 different execution clusters.Compared to the sequential execution of PPJoin in a single computer.
Efficiency in distributing the storage and execution.
With multiple instances in the execution cluster.
Distributed Near Duplicate Detection ∂u∂u 18 / 23
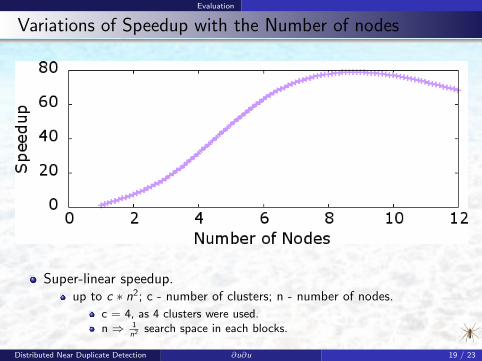
Evaluation
Variations of Speedup with the Number of nodes
Super-linear speedup.up to c ∗ n2; c - number of clusters; n - number of nodes.
c = 4, as 4 clusters were used.n ⇒ 1
n2 search space in each blocks.
Distributed Near Duplicate Detection ∂u∂u 19 / 23
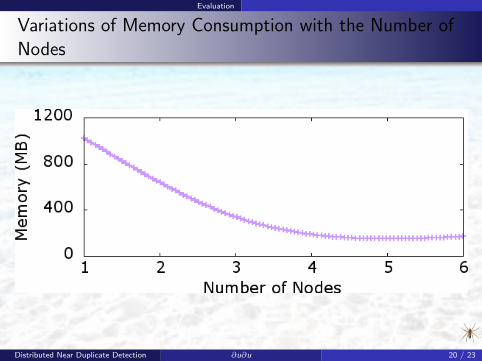
Evaluation
Variations of Memory Consumption with the Number ofNodes
Distributed Near Duplicate Detection ∂u∂u 20 / 23

Conclusion
Related Work
MapReduce frameworks for near duplicate detection.
MapDupReducer [CW 2010], Dedoop [LK 2012], . . .Generalizing the existing algorithms to execute in a MapReduceframework.Do not consider all aspects of the near duplicate detection.Coupled to the MapReduce framework or the near duplicate detectionalgorithms.
In-Memory Data Grids such as Hazelcast and Infinispan are notleveraged in existing data cleaning approaches.
Distributed Near Duplicate Detection ∂u∂u 21 / 23

Conclusion
Conclusion
Conclusions
In-memory data grids for a scalable near duplicate detection.Adoption of the existing algorithms for a distributed environment.Multi-tenanted environment for accurate near duplicate detection.
with parallel usage of multiple blocking keys.
Future Work
Extending and leveraging ∂u∂u distributed execution approach for datawarehouse construction and other data cleaning processes.
Distributed Near Duplicate Detection ∂u∂u 22 / 23
Conclusion
References
CX 2011 Xiao, C., Wang, W., Lin, X., Yu, J. X., & Wang, G. (2011). Efficient similarity joins for near-duplicate detection. ACMTransactions on Database Systems (TODS), 36(3), 15.
LK 2012 Kolb, L., Thor, A., & Rahm, E. (2012). Dedoop: efficient deduplication with Hadoop. Proceedings of the VLDBEndowment, 5(12), 1878-1881.
CW 2010 Wang, C., Wang, J., Lin, X., Wang, W., Wang, H., Li, H., ... & Li, R. (2010, June). MapDupReducer: detecting nearduplicates over massive datasets. In Proceedings of the 2010 ACM SIGMOD International Conference on Managementof data (pp. 1119-1122). ACM.
RV 2010 Vernica, R., Carey, M. J., & Li, C. (2010, June). Efficient parallel set-similarity joins using MapReduce. In Proceedingsof the 2010 ACM SIGMOD International Conference on Management of data (pp. 495-506). ACM.
PK 2014 Kathiravelu, P. & L. Veiga (2014). An Adaptive Distributed Simulator for Cloud and MapReduce Algorithms andArchitectures. In IEEE/ACM 7th International Conference on Utility and Cloud Computing (UCC 2014), London, UK.pp. 79 – 88. IEEE Computer Society.
Thank you!Questions?
Distributed Near Duplicate Detection ∂u∂u 23 / 23