understanding the simd efficiency of graph traversal on gpu yichao cheng, hong an, zhitao chen, feng...
TRANSCRIPT

Understanding the SIMD Efficiency of Graph Traversal on GPUYichao Cheng, Hong An, Zhitao Chen, Feng Li, Zhaohui Wang, Xia Jiang and Yi Peng
University of Science and Technology of China

Breadth-first Search (BFS)
A C
D E F
G H I
A C
DE F
G
H I
1 1
2 22
3 3
4
Source

Breadth-first Search (BFS)
A
B
C
DE F
G
H I
BFS_Iteration:for u ∈ Current Frontier for v ∈ u’ s neighbors do if v has not been labeled label v put v in Next Frontier

Application of BFS• Many datasets in real world are represented by graph• VLSI circuits• Social relationship• Road connections
• Primitive for building complex algorithms• Path-finding• Belief propagation• Points-to Analysis (PTA)

The Problem•GPU relies on high SIMD lanes occupancy to boost performance • 100% efficiency is achieved only if all SIMD lanes fall in the same path
I
Do_something_common();If (thread_id > 5) { do_something_red(); } else { do something_blue();}
100% utilization

The Problem•GPU relies on high SIMD lanes occupancy to boost performance • 100% efficiency is achieved only if all SIMD lanes fall in the same path
I
37.5% utilization
Do_something_common();If (thread_id > 5) { do_something_red(); } else { do something_blue();}

The Problem•GPU relies on high SIMD lanes occupancy to boost performance • 100% efficiency is achieved only if all SIMD lanes fall in the same path
I
62.5% utilization
Do_something_common();If (thread_id > 5) { do_something_red(); } else { do something_blue();}

Traditional ImplementationGPU_BFS_Iteration u = C[tid] for v ∈ u’ s neighbors do
end for
The # of sub-iterations depends on
the size of u ’s adjacent list
task 1 = 4 sub-iterations
task 2 = 2 sub-iterations
…

Visualizing the Irregularity
vertex range < 8
Highly skewedoutlier exists
irregular but concentrate
distributedbetween a wide rage

Alternative Way• Assign each task with a warp of threads• Vectorize the sub-iterations!
I
So, what’s the relationship between graph topology and SIMD efficiency?

Topology and Utilization• Assign each vertex with a group of threads
Thread Warp Group
task 1 = 2 sub-iterationstask 2 = 1 sub-iteration

Topology and Utilization
Divide the SIMD underutilization into two parts• InteR-group Underutilization (UR)
• IntrA-group Underutilization (UA)
SIMD Window

Conclusions From the Model
•UR is induced by the heterogeneity of workloads• Affected by the graph topology
•UR is sensitive to the group size (S)• Large logical SIMD window can narrow the gap• When S = 32, UR = 0
•UA is determined by the intrinsic irregularity of vertex degree• It can be limited by shrink the S• When S = 1, UA = 0
•UR and UA can convert to each other

Comparing Different Mapping Strategies
Expansion Rate (ME/s)
Scalability
good
poor
low high

Evaluating the SIMD Efficiency•Metrics derived from the model:
UR = inter-group underutilizationUA = intra-group underutilizationME = mapping efficiency UR + UA + ME = 100%
• Captures utilization trend with increasing S

Explaining the Result
Expansion Rate (ME/s)
Scalability
good
poor
low high
alleviate the UR , introducing minor UA

Explaining the Result
Expansion Rate (ME/s)
Scalability
good
poor
low high
ME in a high level (~80%)

Explaining the Result
Expansion Rate (ME/s)
Scalability
good
poor
low high
outweighed by the fast-growing UA
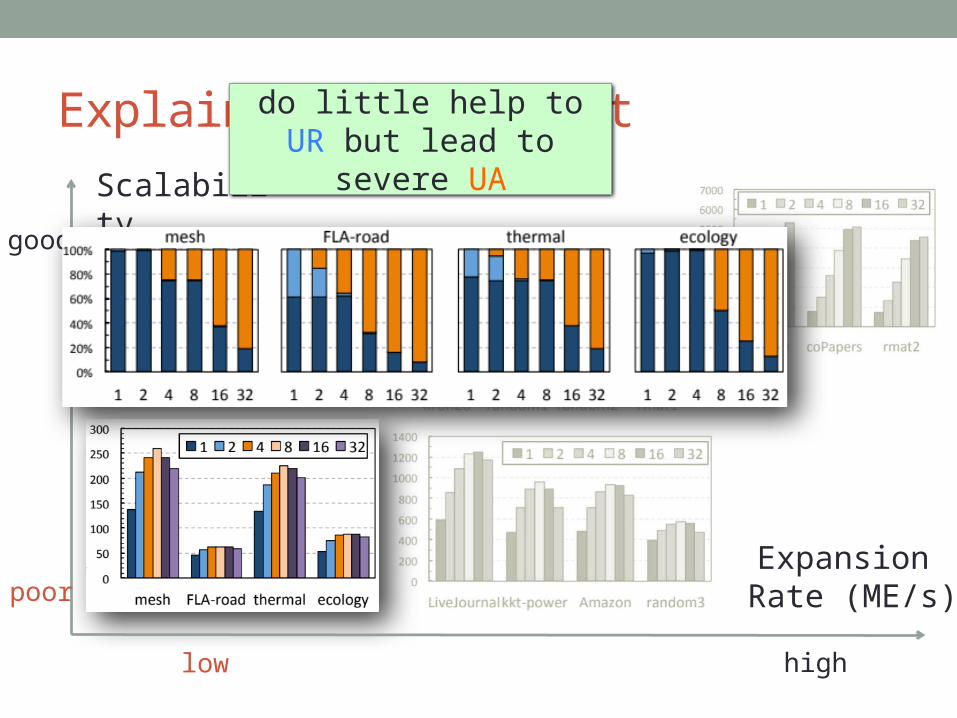
Explaining the Result
Expansion Rate (ME/s)
Scalability
good
poor
low high
do little help to UR but lead to severe UA

Conclusion• Study the link between graph topo & hardware util• Present a model for analyzing the components of SIMD underutilization• Discover that the SIMD are wasted due to:•Develop 3 metrics for quantifying SIMD efficiency• Provide a foundation for developing techniques of static analysis and runtime optimization
imbalance of vertex degree distribution heterogeneity of
each vertex degree

Q&A