unconventional architectures with reconfigurable...
TRANSCRIPT

Unconventional Architectures with Reconfigurable ComputingMichaela Blott, Principal Engineer, Xilinx Research

© Copyright 2015 Xilinx.
Page 2
Agenda
Introductions
Industry landscape
Platform characterization & performance estimation
Some unconventional examples
Summary & future plans

© Copyright 2015 Xilinx.
Page 3
Introductions – FPGAs, Xilinx, Xilinx research and the labs in Dublin
Industry landscape
Platform characterization & performance estimation
Some unconventional examples
Summary & future plans

© Copyright 2015 Xilinx.
Page 4
What are FPGAs?Customizable, Programmable Hardware Architectures
Great vehicle for implementation of unconventional architectures
© Copyright 2015 Xilinx.
Customized hardware
Page 5
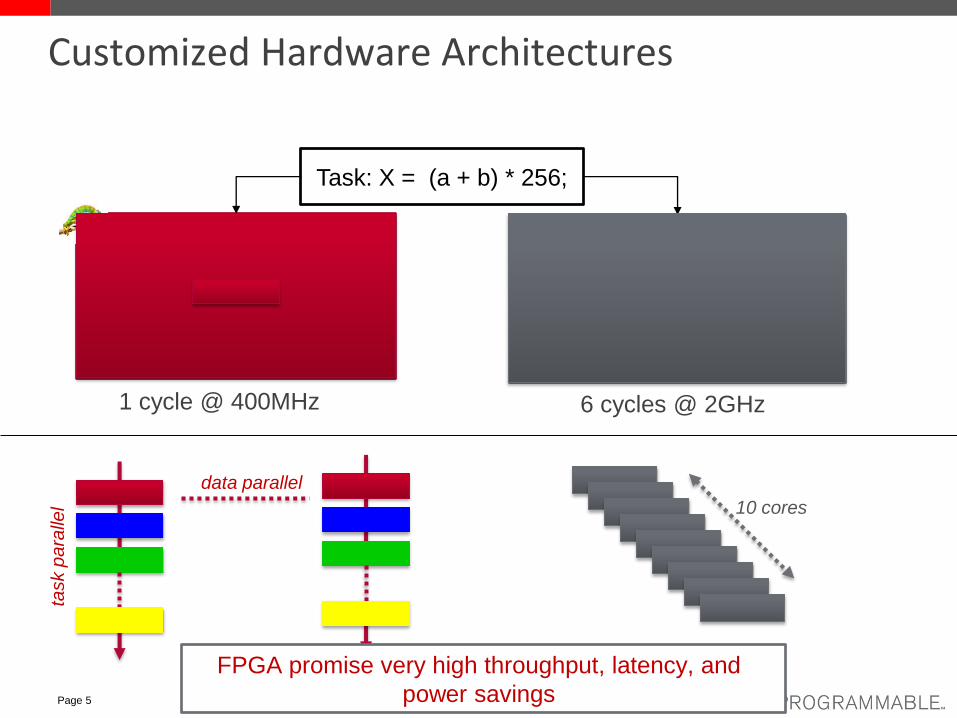
Customized Hardware Architectures
R0 = Load a;
R1 = Load b;
R2 = Load 0x256;
R1 = Add(R1,R0);
R2 = Mult(R1,R2);
Mem[0x0003] = Store(R2);
+ << 9
Task: X = (a + b) * 256;
1 cycle @ 400MHz 6 cycles @ 2GHz
General Purpose Processor
data parallel
task p
ara
llel 10 cores
FPGA promise very high throughput, latency, and
power savings
© Copyright 2015 Xilinx.
Page 6
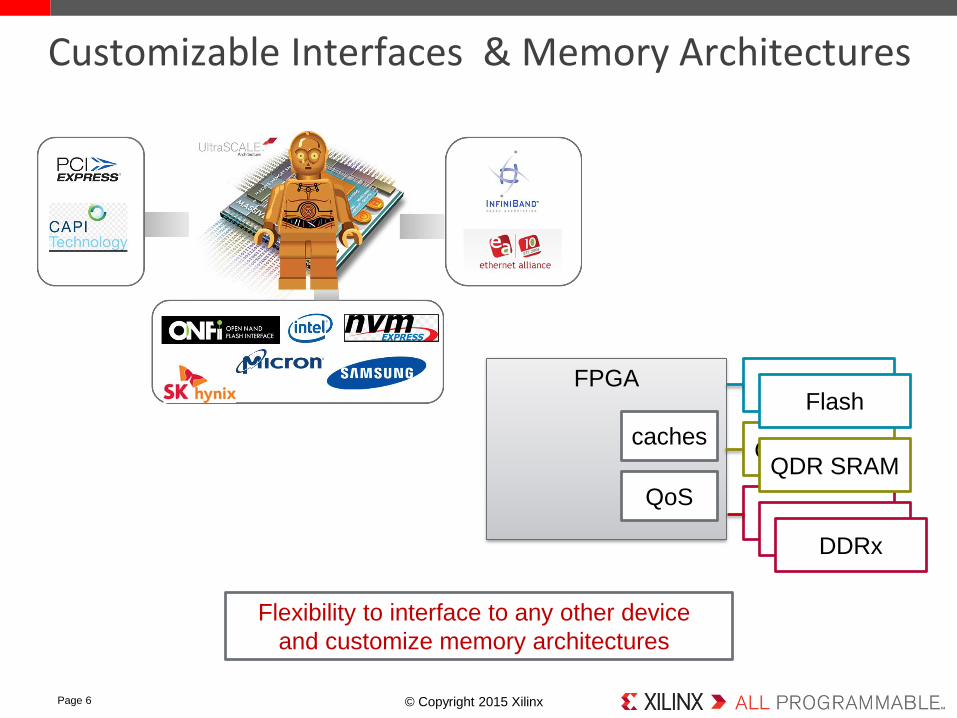
Customizable Interfaces & Memory Architectures
Flexibility to interface to any other device
and customize memory architectures
FPGA
DDRx
QDR SRAM
Flash
caches
QoS
DDRxDDRx
QDR SRAM
Flash

© Copyright 2015 Xilinx.
Fabless semiconductor company
Founded in Silicon Valley in 1984
Today: Approximately 3,500 employees and $2.25B revenue
20,000 Customers
Introduction to Xilinx
64 FF
128 3-input LUTs
58 IOs
2um
3.4M FF
1.7M 6-input LUTs
6.3Tbps IO
16nm
+ DSPs, ARM, 2.5D…
Ultrascale +: VU13P1st FPGA in 1985: XC2064
30 years
Page 7

© Copyright 2015 Xilinx.
Xilinx is Diversified Across Multiple Markets
Page 8

© Copyright 2015 Xilinx.
Xilinx Research - Ireland
Page 9
Applications & Architectures
Through application-driven
technology development with
customers, partners, and
engineering & marketing

© Copyright 2015 Xilinx.
Page 10
Introductions
Industry landscape
Platform characterization & performance estimation
Some unconventional examples
Summary & future plans

© Copyright 2015 Xilinx.
Moore’s Law & The Technology Pipeline
Page 11
Scaling becomes increasingly esoteric

© Copyright 2015 Xilinx.
Transistor Cost Trend
Calculation of Cost Per Transistor by Node
Source: IBS
.0700
.0600
.0500
.0400
.0300
.0200
.0100
.000090nm 65nm 40nm 28nm 20nm 14nm
.0636
.0521
.0362
.0278.0275.0267
Wrong Trend
Co
st
per
mil
lio
n g
ate
s
Economics become questionable
Page 12

© Copyright 2015 Xilinx.
End of Dennard Scaling
Page 13
Source: Intel
Power dissipation becomes problematic

© Copyright 2015 Xilinx.
Applications require
– Increasing compute (machine learning, data
analytics)
– Increasing storage capacity (photos, videos)
– Lower power (OPEX = 2x CAPEX)
Heterogeneous compute is required to
provide further performance scaling and
reducing power consumption
Accelerator integration transitions from
– Loosely coupled IO device, coherent
accelerators (CAPI, QPI, CCIX) to on-chip
integration with processors and memory
Computing: Increasingly Heterogeneous and Integrated
Page 14
New decade of application-driven architecturesDiversification with increasingly heterogeneous devices

© Copyright 2015 Xilinx.
New Generation of Design Environments (FPGAs)make it easier
• ISE, RTL-based design entry with IP library
Legacy
• Microblaze, SDK, EDK
Embedded CPU integration
• Vivado HLS
• SDNet (DSL PX)
• Block stitching and manual integration in platform in RTL
Raised abstraction for accelerators
• SDSoC, SDNet, SDAccel
• Predefined methods for data transfer & automated implementation
Simplified host integration & automated infrastructure creation
Tim
e
Abstra
ctio
n
Monitoring & profiling infrastructure, Runtime OS, Dynamic and
static workload partitioning, Cloud integration

© Copyright 2015 Xilinx.
For a given application, which
architecture should I build?
For a given architecture, which
applications are suitable?
=> Characterization & benchmarking
The Question
Page 16

© Copyright 2015 Xilinx.
Page 17
Agenda
Introductions
Industry landscape
Platform characterization & performance estimation
Some unconventional examples
Summary & future plans

© Copyright 2015 Xilinx.
Page 18
Agenda
Introductions
Industry landscape
Platform characterization & performance estimation
Some unconventional examples
Summary & future plans

© Copyright 2015 Xilinx.
Peak performance as a function of operational intensity
– PT = min{ OI*BW; P}
– Takes into account maximum compute performance and memory
bandwidth
UC Berkeley’s Rooflines for Hardware Platforms
Operational intensity
of an implementation
OPS:Byte
(log)
Achievable
Performance
GOPS/sec
(log)
maximum
performance
Memory bound Compute bound
Hardware:
P=100GOPS/s
BW= 1GB/s
Implementation
OI = 1OPS/Byte
Estimated peak performance for I:
1GOPS/s
Page 19
Very crude but useful for performance estimates and platform comparison

© Copyright 2015 Xilinx.
Allows performance estimates & tracking of optimizations
Performance Estimation & Tracking
OPS:Byte
(log)
Achievable
Performance
GOPS/sec
(log)
Estimated
peak performance
Implementation
of Application A
Measurements
Page 20
Current project: refining rooflines
SP mult
8b add
Average cost for a mix of operations
© Copyright 2015 Xilinx.
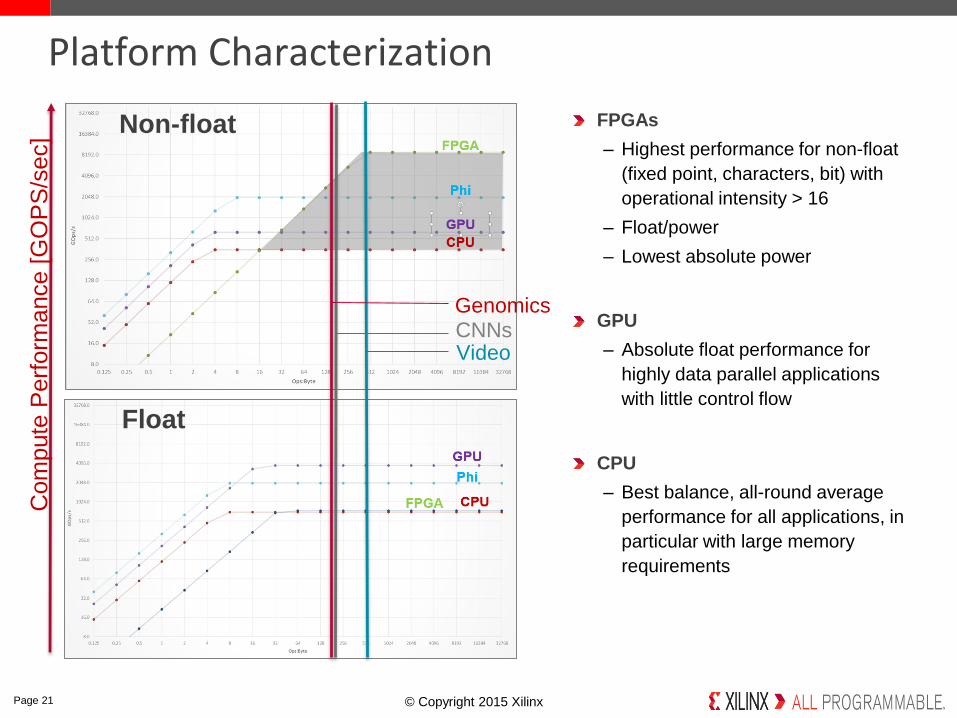
FPGAs
– Highest performance for non-float
(fixed point, characters, bit) with
operational intensity > 16
– Float/power
– Lowest absolute power
GPU
– Absolute float performance for
highly data parallel applications
with little control flow
CPU
– Best balance, all-round average
performance for all applications, in
particular with large memory
requirements
Platform Characterization
CNNsGenomics
Video
Com
pute
Perf
orm
ance [
GO
PS
/sec]
Non-float
Float
Page 21

© Copyright 2015 Xilinx.
Page 22
Introductions
Industry landscape
Platform characterization & performance estimation
Some unconventional examples
Summary & future plans

© Copyright 2015 Xilinx.
Applications under Investigation
Key value stores
Machine learning
Vision Processing
Genomics
Networking
Stencils
Fintech
Synthetic workloads
Page 23
© Copyright 2015 Xilinx.
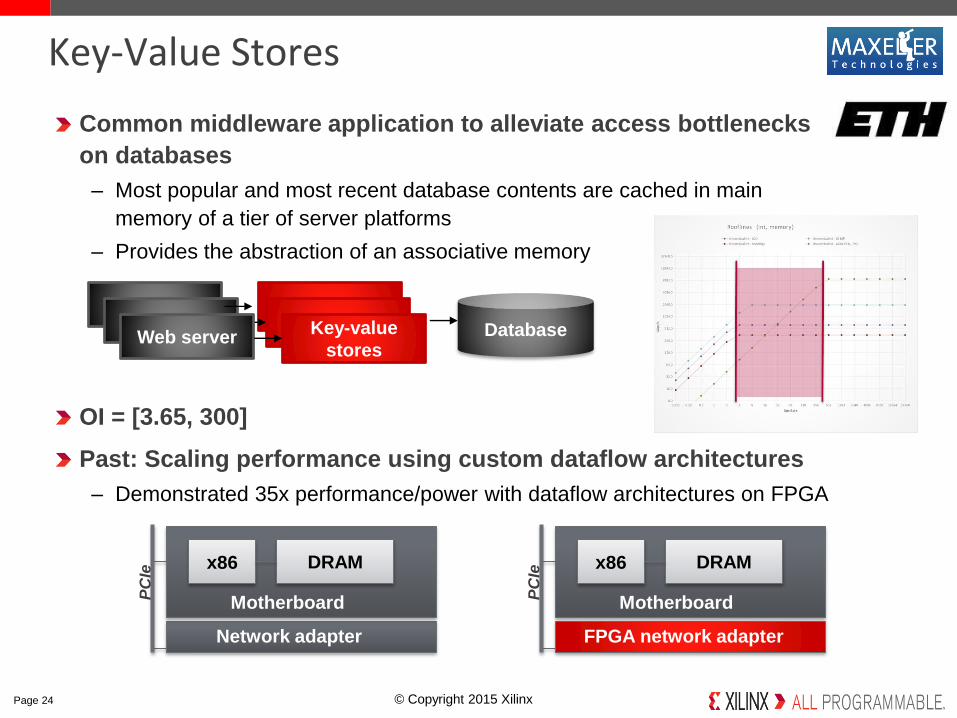
Key-Value Stores
Common middleware application to alleviate access bottlenecks
on databases
– Most popular and most recent database contents are cached in main
memory of a tier of server platforms
– Provides the abstraction of an associative memory
OI = [3.65, 300]
Past: Scaling performance using custom dataflow architectures
– Demonstrated 35x performance/power with dataflow architectures on FPGA
MemcachedWeb server
DatabaseMemcachedKey-value
stores
Web serverWeb server
© Copyright 2015 Xilinx
Motherboard
DRAMx86
Network adapter
PC
Ie
Motherboard
DRAMx86
FPGA network adapter
PC
Ie
Page 24

© Copyright 2015 Xilinx.
10GRequest
Parser
Response
Formatter
Hash
TableValue Store10G
Dataflow architectures to scale performance
10Gbps demonstrated with a 64b data path @ 156MHz using 3% of FPGA
resources
80Gbps can be achieved by using a 512b @ 156MHz pipeline for example
DRAM Controller
DRAM
FPGA
Hash
Table
Value
Store
© Copyright 2015 Xilinx
Streaming architecture:
Flow-controlled series of processing
stages which manipulate and pass
through packets and their associated
state
Numerous requests are processed
back to back exploiting task level
parallelism
Source: [4] Blott et al: Achieving 10Gbps line-rate key-value stores with FPGAs; HotCloud 2013
Page 25

© Copyright 2015 Xilinx.
Last Year: Scaling Capacity
FPGAs enable custom memory architectures whereby storage
media can be leveraged to their advantages
Example:
– SSDs combined with DDRx channels can be used to build high capacity &
high performance key value stores
– Concepts and early prototype to scale to 40TB & 80Gbps key value stores
Host memory
(via CAPI)
Source: HotStorage 2015, Scaling out to a Single-Node 80Gbps Memcached Server with 40Terabytes of Memory
Page 26

© Copyright 2015 Xilinx.
Advantages:
– Larger objects require larger storage
– Larger granular access to flash suits page-size access granularity of flash
Concerns:
– Large access latency on flash
– Variations in access bandwidth and latency between DRAM and flash
Object distribution on the basis of size
Source: [3] Atikoglu et al: Workload analysis of a large-scale key-value store; SIGMETRICS 2012
[13] Lim et al: Thin servers with smart pipes: designing {SoC} accelerators for memcached; ISCA 2013
Stored in DRAM Stored in Flash
128 256 512 768 1K 4K 8K 32K 1M
0.55 0.075 0.275 0 0 0 0 0 0.1
0 0 0 0.1 0.85 0.05 0 0 0
0 0 0.2 0.1 0.4 0.29 0.008 0.001 0.001
0 0 0 0 0 0.9 0.05 0.03 0.02
Value Size (B)
Wiki
Flickr
Page 27
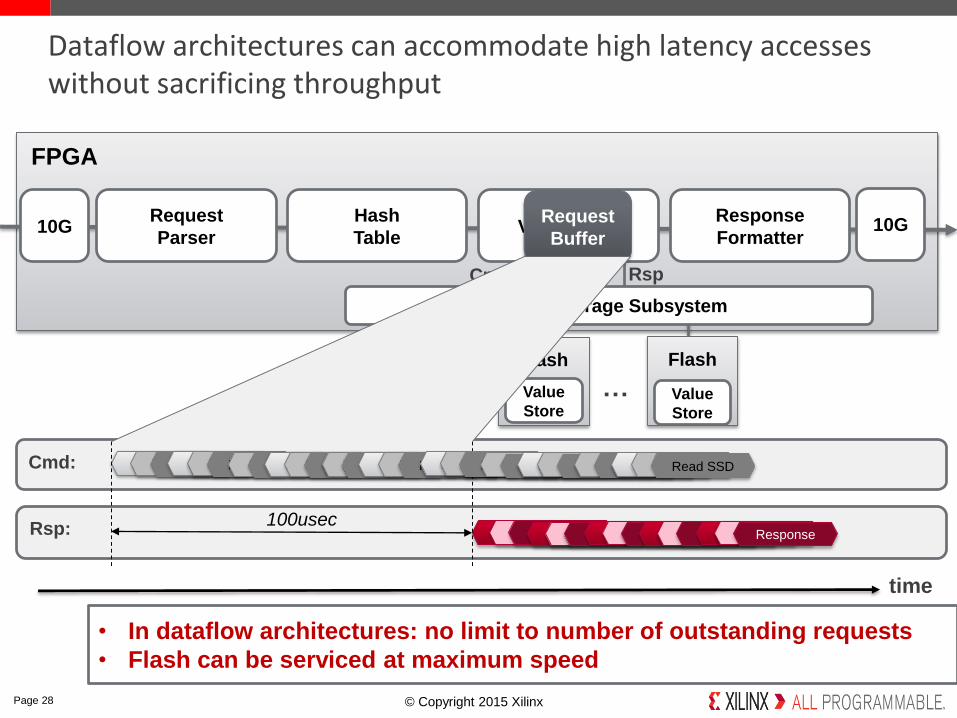
© Copyright 2015 Xilinx.
Dataflow architectures can accommodate high latency accesses without sacrificing throughput
Read SSDRead SSDRead SSD
100usec
• In dataflow architectures: no limit to number of outstanding requests
• Flash can be serviced at maximum speed
10GRequest
Parser
Response
Formatter
Hash
TableValue Store10G
FPGA
Flash
Value
Store
Hybrid Storage Subsystem
Flash
Value
Store
…
Read SSDRead SSDRead SSD
time
Read SSDRead SSDRead SSDRead SSDRead SSD
Request
Buffer
Read SSDRead SSDRead SSDRead SSDRead SSD
ResponseResponseResponseResponseResponseResponseResponseResponseResponseResponseResponseResponseResponseResponseResponse
Cmd:
Rsp:
Read SSDRead SSDRead SSDRead SSDRead SSDRead SSDRead SSDRead SSDRead SSDRead SSDRead SSDRead SSDRead SSD
Cmd Rsp
Page 28
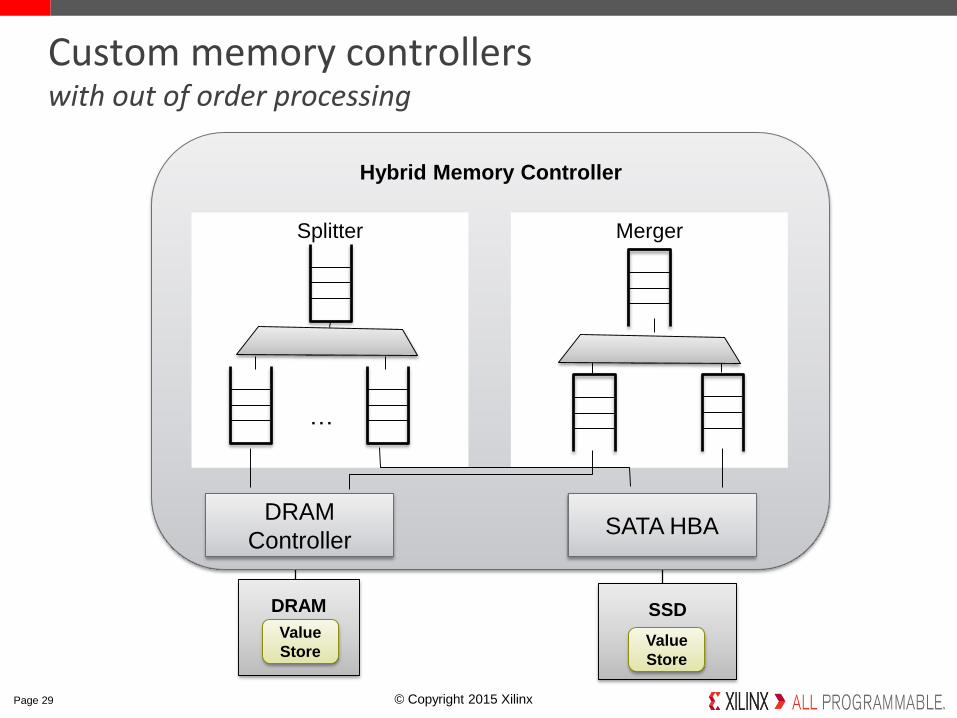
© Copyright 2015 Xilinx.
Custom memory controllers with out of order processing
SSD
Value
Store
DRAM
Value
Store
Hybrid Memory Controller
Splitter Merger
…
DRAM
ControllerSATA HBA
© Copyright 2015 XilinxPage 29

© Copyright 2015 Xilinx.
PCIe X16 (256Gb/s)
Dual SFP+
2x 10/25 Gbps
Dual M.2 SSD
2x 512 GB
Dual DDR4 SODIMM
16GB x72 ECC DR
273 Gb/s @ 2133 Mb/s
16nm MPSoC
Quad A53 CPU
Embedded FPGA
Today:Networked Object Storage Board with MPSoC50Gbps key value store with 2TB, 25W
Page 30
Unconventional memory architecture to achieve high
capacity while maintaining performance

© Copyright 2015 Xilinx.
Machine Learning:Top-5 accuracy image classificationImage-Net Large-Scale Visual Recognition Challenge (ILSVRC*)
* http://image-net.org/challenges/LSVRC/
**http://www.slideshare.net/NVIDIA/nvidia-ces-2016-press-conference, pg 10
*** Russakovsky, et al 2014, http://arxiv.org/pdf/1409.0575.pdf
Human @95%
CNNs deliver super-human accuracy
Page 31

© Copyright 2015 Xilinx.
Compute and Memory Requirements
CNN
for ImageNet datasets
Memory (SP)
[MB]
Operations
[MOPS]
Operational Intensity
[OPS:B]
AlexNet – convolutions only 9.3 1332 143
AlexNet – complete 244 1456 5.97
VGG-16 552 30823 55.84
GoogleNet 27.2 1502 55.24
CNNs are highly compute and highly memory intensive
GPUs deliver highest performance for AlexNet with 4000+ fps
Page 32

© Copyright 2015 Xilinx.
Reducing precision is shown today to work to 6b
– 50x reduction in model size (no external memory needed) [1]
Reducing to the extreme: binary neural networks (BNNs)
Emerging: Low-Precision Networks
[2] Sung et al., “Resiliency of Deep Neural
Networks Under Quantization”, ICLR’16
(fully connected network layers for phoneme recognition)
[1] Iandola et al. "SqueezeNet: AlexNet-level accuracy with
50x fewer parameters and< 1MB model size." (2016).
Bipolar NN
SP float NN
Page 33

© Copyright 2015 Xilinx.
Binary and Almost Binary NetworksAccuracy (published & reproduced results)
[1] Courbariaux, Matthieu, and Yoshua Bengio. "BinaryNet: Training deep neural networks with weights and activations constrained
to+ 1 or-1." arXiv preprint arXiv:1602.02830 (2016).
[2] Rastegari, Mohammad, et al. "XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks." arXiv preprint
arXiv:1603.05279 (2016).
[3] Xundong Wu: High Performance Binarized Neural Networks trained on the ImageNet Classification Task” arXiv:1604.03058
[4] S. Zhou, z.Ni, X. Zhou, H.Wen, Y.Wu, Y. Zou: “DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low
Bitwidth Gradients”, http://arxiv.org/abs/1606.06160#
Dataset FP32 BNN Source
MNIST 99% 99% [1]
CIFAR-10 92% 90% [1]
ImageNet(GoogleNet arch)
90% top-5 86% top-5 [2] binary weights
ImageNet(DoReFaNet)
56% top-1 50% top-1 [4] 2-bit activations
Page 34

© Copyright 2015 Xilinx.
8
16
32
64
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
0.125 0.5 2 8 32 128 512 2048 8192 32768
GO
ps
/s
Ops:Byte
Xilinx FPGA Rooflines
AlexNet (complete) AlexNet (Conv+MaxPool) LeNet-5
VGG-16 GoogleNet SqueezeNet/FireCaffe
KU115-SP KU115-16bint KU115-8bint
KU115-1b
Page 35
Roofline model for KU115 (ADM-PCIE-8K5) & CNNs
2 Tops peak, 16b
BNN (avoid mem bw)
BN
N –
2.5
LU
Ts/O
P

© Copyright 2015 Xilinx.
Page 36
Lab setup using the MNIST dataset, Zynq chip
First prototype in Xilinx labs Dublin* shows
In hardware: 12Mfps for MNIST, 2usec latency, ~7.4Watt
*Yaman Umuroglu (NTNU, Xilinx); Nicholas Fraser (University of Sydney, Xilinx); Giulio Gambardella (Xilinx Research);
Michaela Blott (Xilinx Research)

© Copyright 2015 Xilinx.
Page 37
Introductions
Industry landscape
Platform characterization
Some unconventional examples
Summary & future plans

© Copyright 2015 Xilinx.
Trend towards unconventional architectures
– A diversification of increasingly heterogeneous system
Characterization leveraging Berkeley roofline models
– Visualizes application suitability for different accelerators and
performance estimation
Some unconventional examples
In collaboration with leading customers, partners and universities
Future:
– Facilitate ease of use for reconfigurable computing
– Bring clarity & understanding on applications
Summary & Future Plans
Page 38
