uc santa cruz providing high reliability in a minimum redundancy archival storage system deepavali...
TRANSCRIPT

UC Santa Cruz
Providing High Reliability in a Minimum Redundancy Archival
Storage System
Deepavali BhagwatKristal Pollack
Darrell D. E. LongEthan L. Miller
Storage Systems Research Center
University of California, Santa Cruz
Thomas SchwarzComputer Engineering
DepartmentSanta Clara University
Jehan-François PârisDepartment of Computer
ScienceUniversity of Houston,
Texas

2
Introduction
Archival data will increase ten-fold from 2007 to 2010• J. McKnight, T. Asaro, and B. Babineau, Digital Archiving:End-User Survey and
Market Forecast 2006 - 2010. The Enterprise Strategy Group, Jan. 2006.
Data compression techniques used to reduce storage costs
Deep Store - An archival storage system• Uses interfile and intrafile compression techniques• Uses chunking
Compression hurts reliability• Loss of a shared chunk Disproportionate data loss
Our solution: Reinvest the saved storage space to improve reliability• Selective replication of chunks
Our results:• Better reliability compared to that of mirrored Lempel-Ziv compressed files using only about half of the storage space

3
Deep Store: An overview
Whole File Hashing• Content Addressable Storage
Delta Compression Chunk-based Compression
• File broken down into variable-length chunks using a sliding window technique
• A chunk identifier/digest used to look for identical chunks
• Only unique chunks stored
wfixed size window
chunk end/start
variablechunk size
window fingerprint chunk ID(content address)
sliding window

4
Effects of Compression on Reliability
Chunk-based compression Interfile dependencies
Loss of a shared chunk Disproportionate amount of data loss
Files
Chunks

5
Effects of Compression on Reliability….. Simple experiment to show the effects of interfile
dependencies:• 9.8 GB of data from several websites, The Internet
Archive• Compressed using chunking to 1.83 GB. (5.62 GB using
gzip)• Chunks were mirrored and distributed evenly onto 179
devices, 20 MB each.

6
Compression and Reliability
Chunking:• Minimizes redundancies. Gives us excellent compression ratios
• Introduces interfile dependencies• Interfile dependencies are detrimental to reliability
Hence, reintroduce redundancies• Selective replication of chunks
Some chunks more important than others. How important?• The amount of data depending on a chunk (byte count)
• The number of files depending on a chunk (reference count)
Selective replication strategy• Weight of a chunk (w) Number of replicas for a chunk (k)
• We use a heuristic function to calculate k

7
k : Number of replicas w : Weight of a chunk a : Base level of replication, independent of w b : To boost the number of replicas for chunks
with high weight
Every chunk is mirrored kmax : Maximum number of replicas
• As replicas increase the gain in reliability obtained as a result of every additional replica reduces
k rounded off to the nearest integer.
Heuristic Function

8
Distribution of Chunks
An archival system receives files in batches Files stored onto a disk until the disk is full
For every file• Chunks extracted and compressed• Unique chunks stored
A non unique chunk stored only if:• The present disk does not contain the chunk• For this chunk, k < kmax
At the end of the batch• All chunks revisited and replicas made for appropriate chunks
A chunk is not proactively replicated • Wait for a chunk’s replica to arrive as a chunk of a future file
• Reduce inter-device dependencies for a file.

9
Experimental Setup
We measure Robustness:• The fraction of the data available given a certain percentage of unavailable storage devices
We use Replication to introduce redundancies• Future work will investigate erasure codes
Data Set:• HTML, PDF, image files from The Internet Archive. (9.8 GB)
• HTML, image (JPG and TIFF), PDF, Microsoft Word files from The Santa Cruz Sentinel (40.22 GB)
We compare the Robustness and Storage Space utilization of archives that use:• Chunking with selective redundancies and• Lempel-Ziv compression with mirroring

10
Details of the Experimental Data

11
When using dependent data (byte count) as a heuristic:• w = D/d• D : sum of the sizes of all files depending on a chunk
• d : average size of a chunk When using the number of files (reference count) as a heuristic:• w = F• F : number of files depending on a chunk
Weight of a Chunk
12
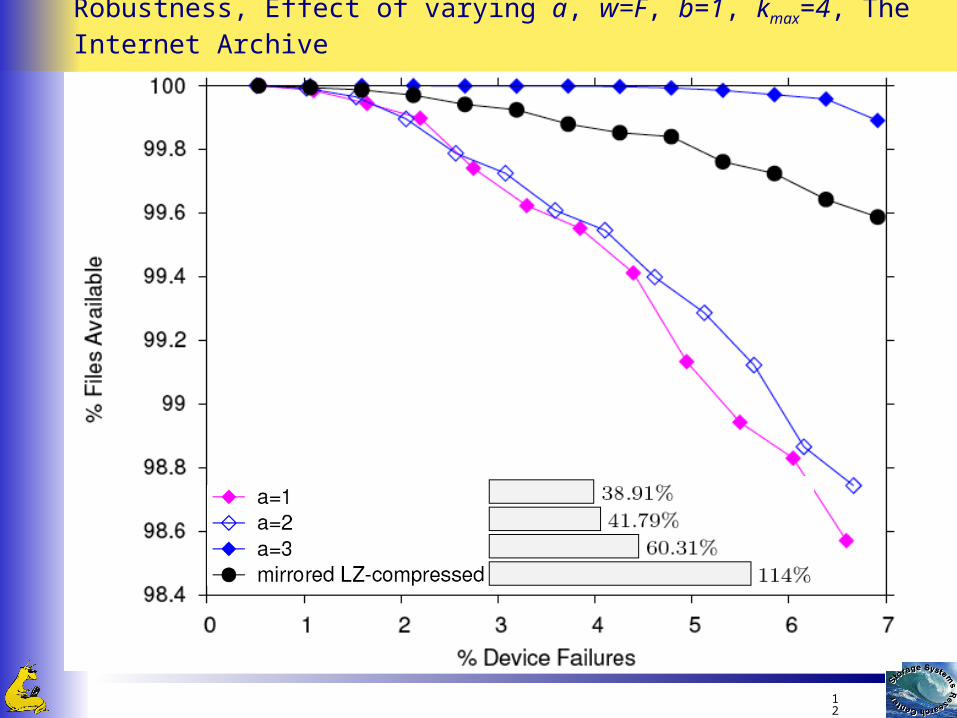
Robustness, Effect of varying a, w=F, b=1, kmax=4, The Internet Archive
13
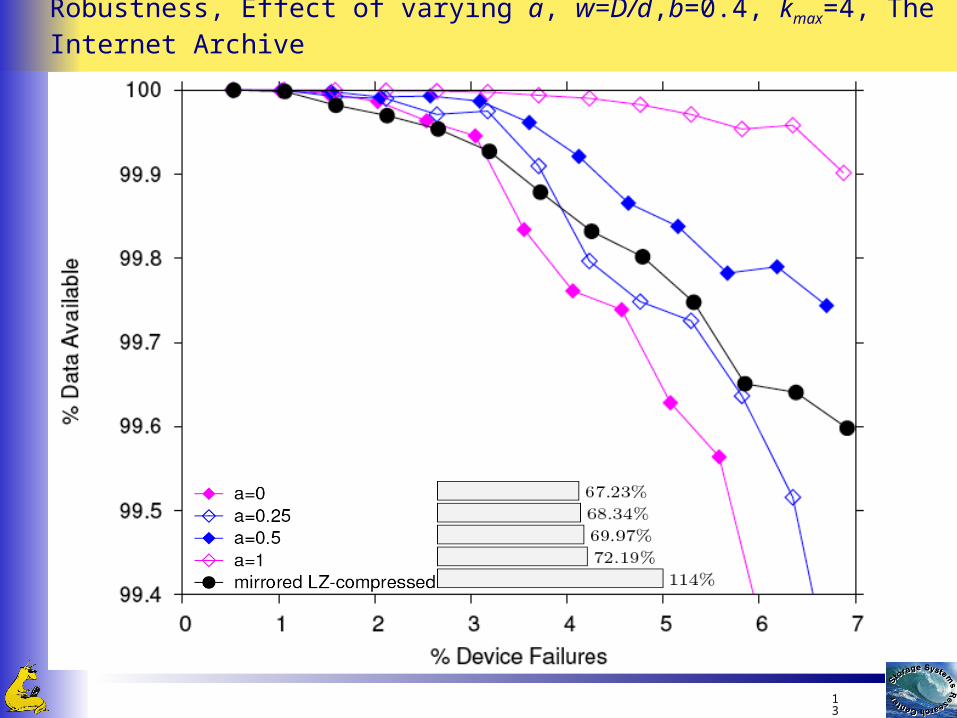
Robustness, Effect of varying a, w=D/d,b=0.4, kmax=4, The Internet Archive

14
Robustness, Effect of limiting k, w=D/d, b=0.55, a=0, The Internet Archive

15
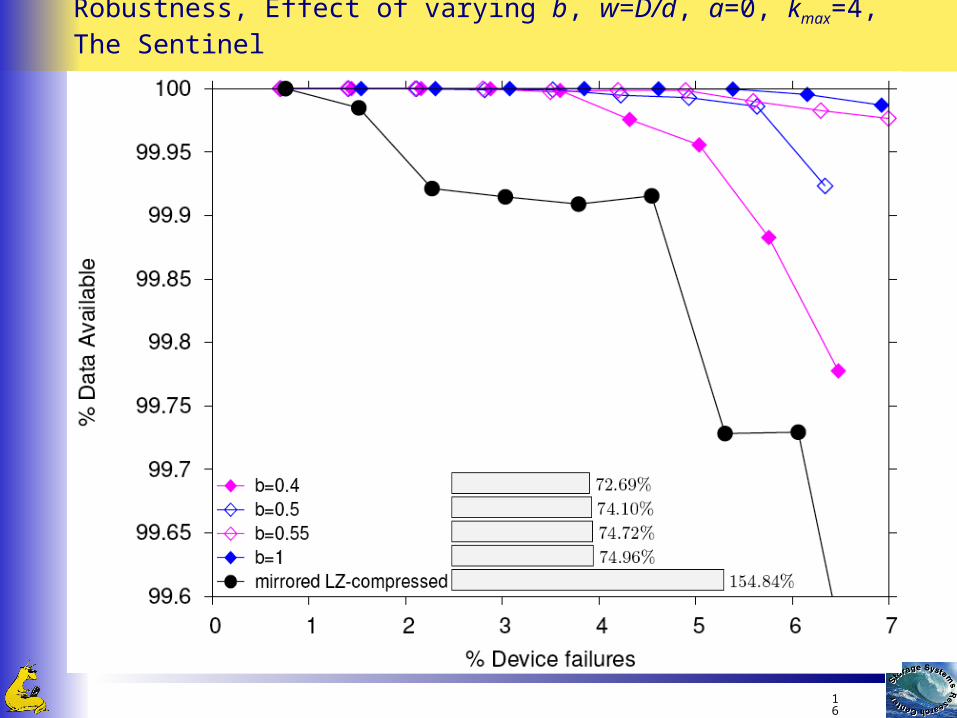
Robustness, Effect of varying b, w=D/d, a=0, kmax=4, The Internet Archive
16
Robustness, Effect of varying b, w=D/d, a=0, kmax=4, The Sentinel

17
Choice of a Heuristic
Choice of a heuristic depends on the corpus• If file size is indicative of file importance, choose w=D/d
• If file’s importance is independent of its size, choose w=F
• Use the same metric to measure robustness

18
Future Work
Study reliability of Deep Store• With a recovery model in place• When using delta compression
Use different redundancy mechanisms such as erasure codes
Data placement in conjunction with hardware statistics

19
Related Work
Many archival systems use Content Addressable Storage:• EMC’s Centera• Variable-length chunks: LBFS• Fixed-size chunks: Venti
OceanStore aims to provide continuous access to persistent data • uses automatic replication for high reliability• erasure codes for high availability
FARSITE: a distributed file system• Replication of metadata, replication chosen avoid the overhead of data reconstruction when using erasure codes
PASIS, Glacier use aggressive replication as a protection against data loss
LOCKSS provides long term access to digital data• uses peer-to-peer audit and repair protocol to preserve the integrity and long-term access to document collections

20
Conclusion
Chunking gives excellent compression ratios but introduces interfile dependencies that adversely affect system reliability.
Selective replication of chunks using heuristics gives• better robustness than mirrored LZ-compressed files
• significantly high storage space efficiency -- only uses about half of the space used by mirrored LZ-compressed files
We use simple replication. Our results will only improve with other forms of redundancies.

UC Santa Cruz
Providing High Reliability in a Minimum Redundancy Archival
Storage System
Deepavali BhagwatKristal Pollack
Darrell D. E. LongEthan L. Miller
Storage Systems Research Center
University of California, Santa Cruz
Thomas SchwarzComputer Engineering
DepartmentSanta Clara University
Jehan-François PârisDepartment of Computer
ScienceUniversity of Houston,
Texas