turning privacy leaks into floods: surreptitious discovery of social network friendships michael t....
Post on 19-Dec-2015
215 views
TRANSCRIPT

Turning Privacy Leaks into Floods: Surreptitious Discovery of Social Network Friendships
Michael T. GoodrichUniv. of California, Irvine
joint w/ Arthur U. Asuncion

Problem Definition• Discover the friendships

Problem Definition• Discover the friendships

Leveraging Information Leaks• Leak: Friendship list can be
viewed by friends-of-friends. This allows:– Given two people, X and Y, we can tell
whether X and Y have a friend in common.
• Leverage: We use this to discover the friends list for members of the network

Abstracting the Problem• Viewed abstractly, we are trying to
learn binary attribute vectors.

Group Testing• Input: n items, numbered 0,1, …, n-1, at most d
of which are defective.• Output: the indices of the defective items.• Items can be grouped into subsets, each of which
can be tested to see it contains a defective item or not.
• Goal: minimize the total number of tests• Original problem: Testing blood samples.

Testing Schemes
• Non-adaptive: All tests must be done in parallel
• Adaptive: Tests can be done sequentially
• Adaptive is easier, but our framework requires a non-adaptive approach

Facebook Application• Each member has a “vector” of friendships• For any member M, the system returns a bit
for whether M has a friend in common with the attacker, even if M restricts this information to friends-of-friends
• We can use non-adaptive scheme to learn friendship relationships in any sub-community in Facebook.

DNA Application• DNA sequences are stored in a database,
D.• For any sequence Q, the database returns a
score for how close Q is to each sequence in D
• We form a binary vector w.r.t. places where mutations happen relative to a reference string R
• We can use non-adaptive scheme to learn DNA strings in D.

Netflix Application• Movie ratings vectors are stored in a
database, D.• For any vector V, the database returns a
score for how close V is to each vector in the database
• We can form a binary attribute vector for movies
• We can use non-adaptive scheme to learn ratings vectors in D.

Matrix View of Testing• A non-adaptive testing regimen can be
viewed as a t x n binary matrix M:
– M[i,j] = 1 if and only if test i includes item j
• M is d-disjunct if the Boolean sum of any d columns does not contain any other column.– An item is defective iff all its tests are positive
• M is d-separable if the Boolean sums of each set of at most d columns are distinct (harder analysis algorithm)
t
n
M

Randomized Approach• Use a randomized approach motivated
by Bloom filtering.• Construct a matrix M, but relax
requirements• Given a set D of d columns in M and a
column j, say j is distinguishable from D if there is a row i such that M[i,j]=1 but M[i,j’]=0 for each j’ in D.
• M is D-distinguishable if, for a particular collection D of subsets, the matrix M will find them distinguishable.

Constructing the Matrix• Given t (set in the analysis), let M
be a 2t x n matrix defined randomly:– For each column j, choose t/d rows of
M at random and set these entries to 1.
– that is, we “inject” j into those t/d tests

Technique for Social Networks• Insert a small set of network
members• Form connections with random
network members• Test common-friends condition for the fictional members
Image from http://www.politicsforum.org/images/flame_warriors/flame_53.php
Exploiting Sparse Data Sets
0 500 1000 15000
50
100
150Facebook-Uniform
0 500 1000 15000
1000
2000
3000
4000Facebook-UNC
0 50 100 1500
100
200
300
400LiveJournal
0 50 1000
20
40
60Genomic
0 5 10 15 200
500
1000
1500
2000Power Grid
0 500 1000 15000
50
100
150
200Netflix
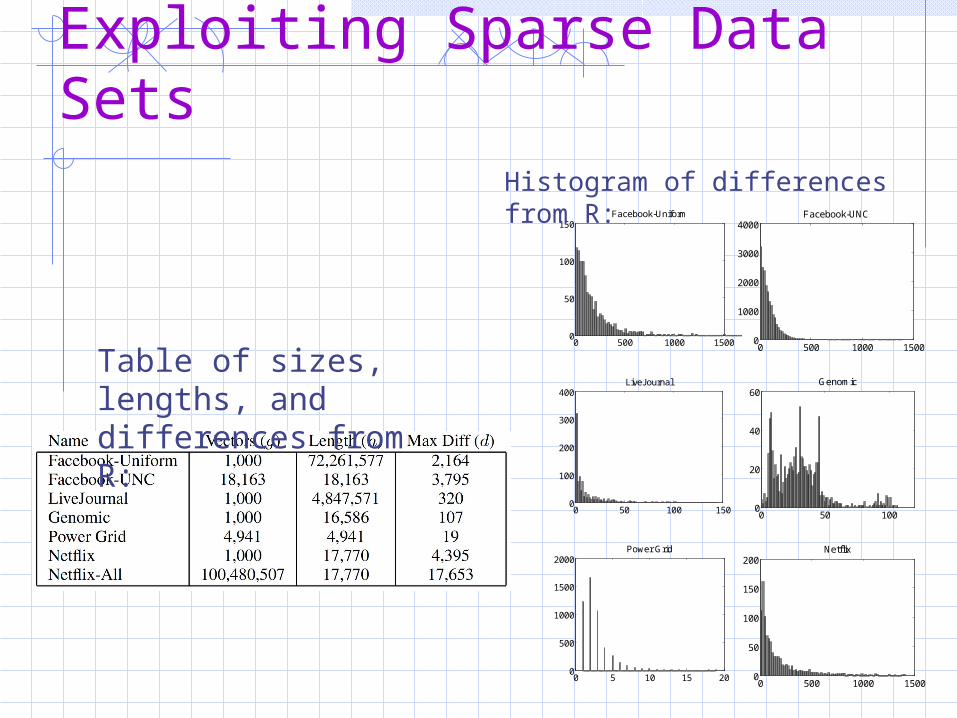
Histogram of differences from R:
Table of sizes, lengths, and differences from R:
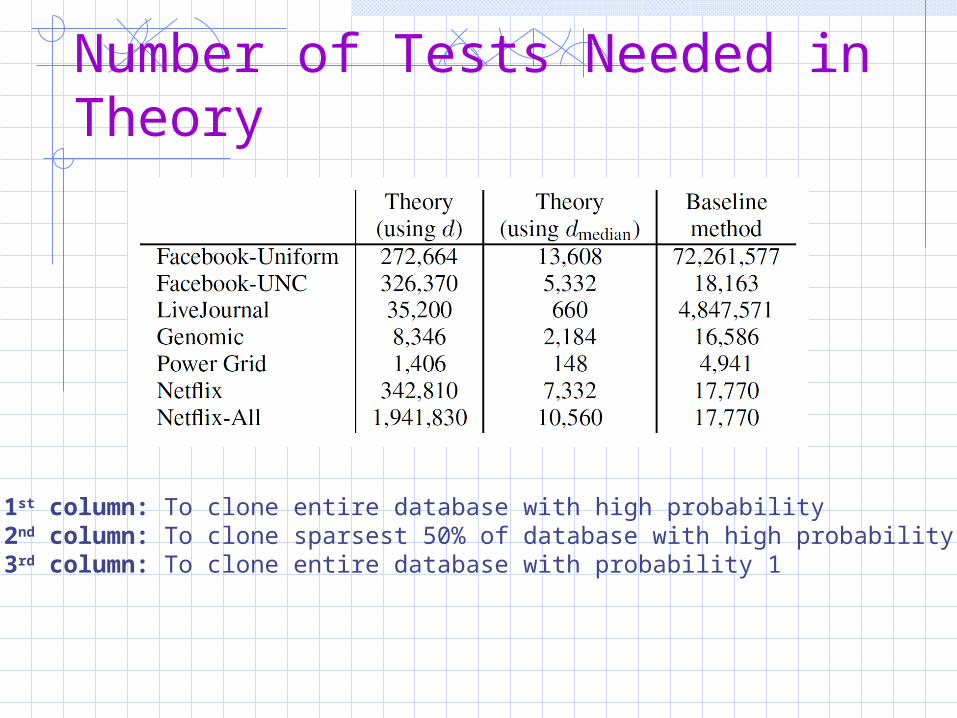
Number of Tests Needed in Theory
1st column: To clone entire database with high probability2nd column: To clone sparsest 50% of database with high probability3rd column: To clone entire database with probability 1

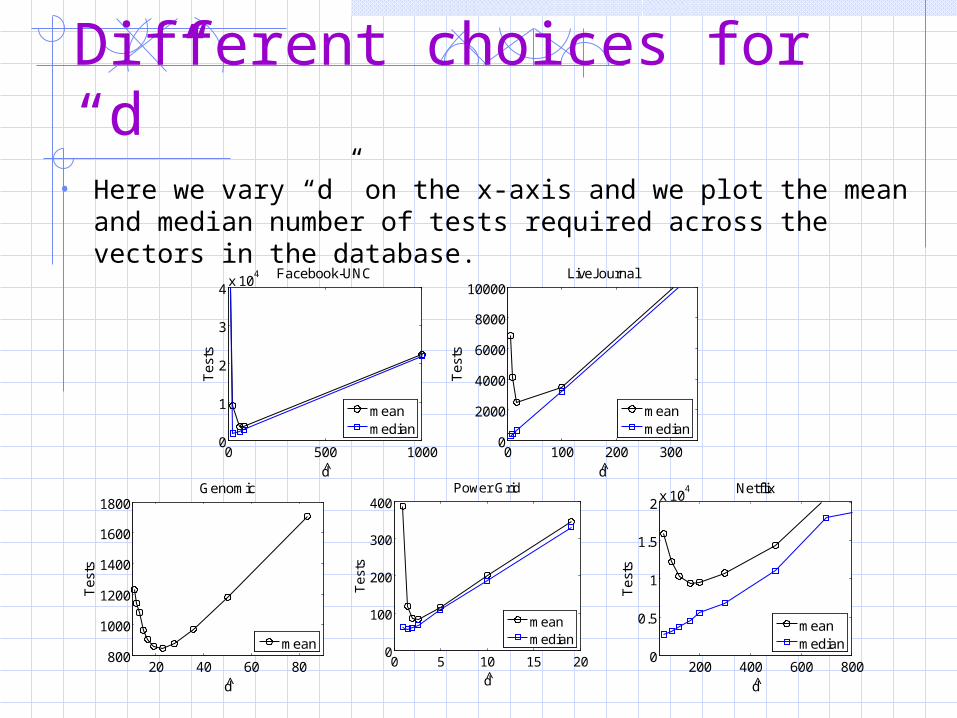
Different Choices for “d” • Tradeoff:
– The smaller the “d”, the faster we can recover sparse vectors– With very small “d”, it can take a long time to recover the
vectors that are not so sparse.
• But most vectors are sparse so we generally want a pretty small “d”
1000 2000 3000 4000 50000
0.5
1
1.5
2x 10
4
Tests
L1 E
rror
d̂ = 998
d̂ = 165
d̂ = 98
d̂ = 60 Attack on a Netflix user who has rated 98 movies.
With smaller “d”, the rate of convergence is faster.
0 500 10000
1
2
3
4x 10
4 Facebook-UNC
d̂
Tes
ts
meanmedian
20 40 60 80800
1000
1200
1400
1600
1800Genomic
d̂
Tes
ts
mean0 5 10 15 20
0
100
200
300
400Power Grid
d̂
Tes
ts
meanmedian
0 100 200 3000
2000
4000
6000
8000
10000LiveJournal
d̂T
ests
meanmedian
200 400 600 8000
0.5
1
1.5
2x 10
4 Netflix
d̂
Tes
tsmeanmedian
Different choices for “d” • Here we vary “d” on the x-axis and we plot the mean and
median number of tests required across the vectors in the database.
0 200 400 6000
1
2
3
4
5x 10
4
Distance from R
Tes
ts
Facebook-UNC
d̂=25
d̂=62
d̂=84
d̂=1000
0 50 1000
2000
4000
6000
8000
10000
Distance from R
Tes
ts
Genomic
d̂=22
0 5 10 15 200
1000
2000
3000
Distance from R
Tes
ts
Power Grid
d̂ = 1.5
d̂ = 2
d̂ = 5
d̂ = 19
0 100 200 3000
1
2
3
4x 10
4
Distance from R
Te
sts
LiveJournal
d̂=6
d̂=17
d̂=100
d̂=320
0 500 10000
1
2
3
4
5x 10
4
Distance from R
Tes
ts
Netflix
d̂=165
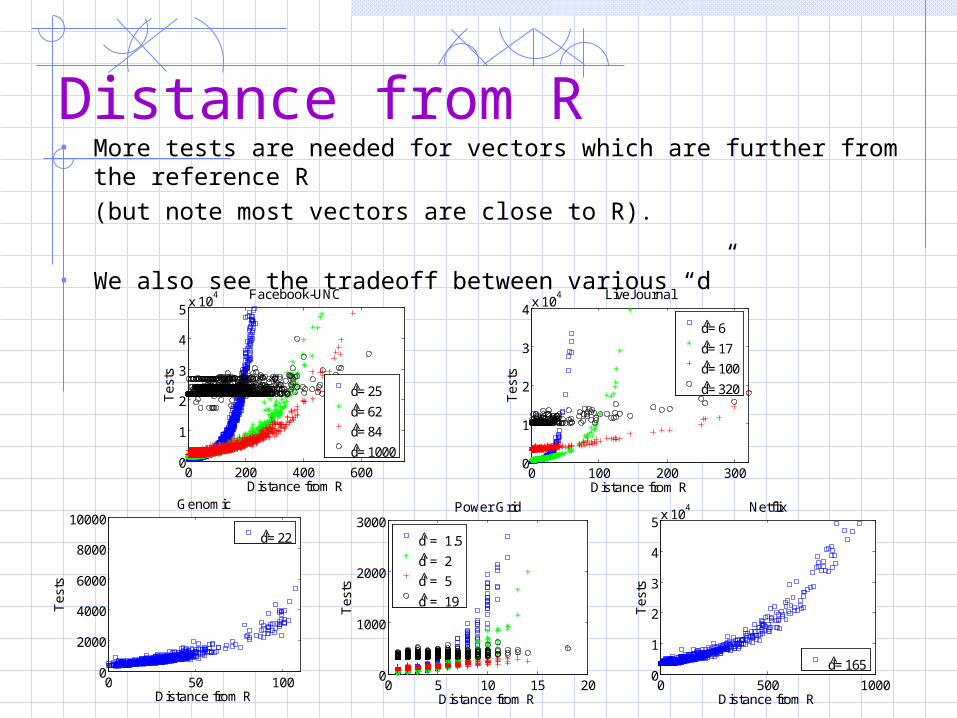
Distance from R • More tests are needed for vectors which are further from the
reference R (but note most vectors are close to R).
• We also see the tradeoff between various “d”
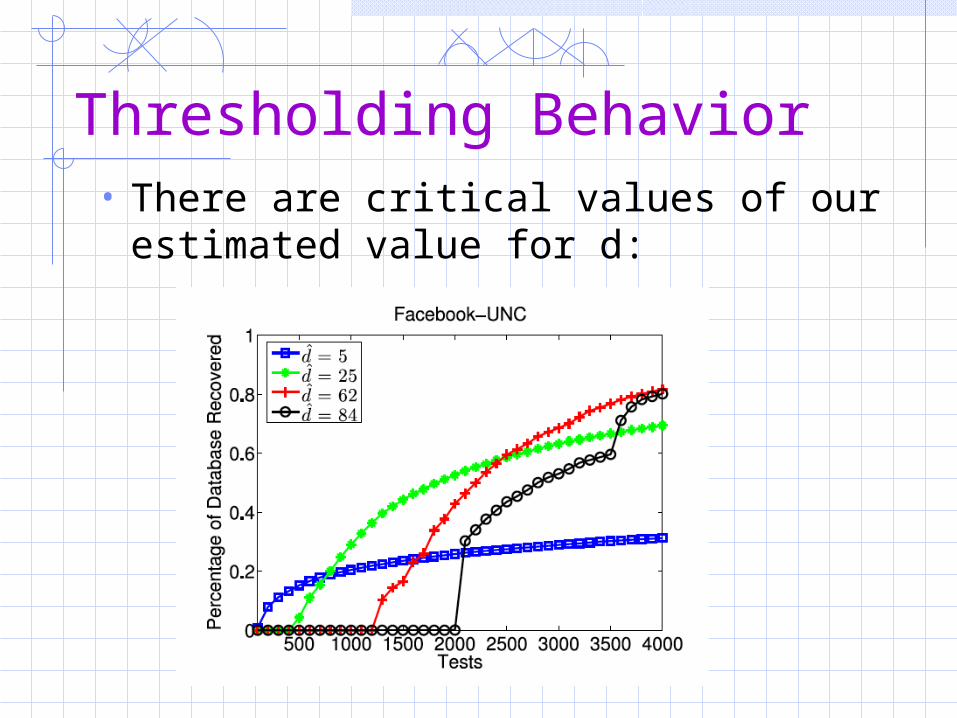
Thresholding Behavior• There are critical values of our
estimated value for d:

Conclusion and Future Work• We have presented a
way to turn privacy leaks into floods, with a number of applications:– Social networks– DNA databases– Ratings vectors
• Future work: extend our approach to non-binary vectors (e.g., friends and foes)