the next forty years march 2012 michael lang, ceo revelytix
TRANSCRIPT

The Next Forty Years
March 2012
Michael Lang, CEO
Revelytix

Sixty Years Ago
“Turing's Cathedral” by George Dyson• In 1945 the DOD funds the Institute of Advanced Study in Princeton,
NJ to build MANIAC (Mathematical and Numerical Integrator and Computer)
• Command and memory address are in the same bit
• At that address was data represented in binary notation
• The only abstraction was the mapping of binary representation to decimal notation
• Between 1945 and 1970, computers were referred to as Numerical Computers
• So it began ...

In 1970, E.F. Codd with the IBM Research Laboratory in San Jose, California, wrote a paper published in ACM,
“A Relational Model of Data for Large Shared Data Banks”
•Codd wrote, “The problems treated here are those of data independence – the independence of application programs from the growth in data types and changes in data representation...”
•This problem is otherwise known as “abstraction”
•Codd’s paper set in motion the data management system architecture for the next forty years. These systems are known as relational database management systems (RDBMS)
Computers were referred to as “Information Technology” (IT)
The Last Forty Years

RDBMS
The RDBMS solves only some of Codd’s issues • Hardware and software were insufficient to solve the
whole problem at the time
• Applications continue to be severely impacted by the growth in data types or changes in data representation
• But, applications are independent of the ordering of the data and the indexing schemes
• RDBMS do provide ACID guarantees for CRUD operations, --which was Codd's original goal

Paradigm Shift
In 1985 the mainframe/terminal paradigm was replaced by the client/server paradigm•Oracle, Sybase and others ported their new RDBMS to this paradigm
•Thought RDBMSs had been around for ~8 years, market acceptance did not take off until they beat IMS and VSAM to the new client/server paradigm
•It’s hard to say which technology was the chicken and which was the egg

Transactional Systems
The primary early use of RDBMS technology was to create and store transactions• RDBMS were and still are optimized for transactions;
they are very good at this task
• Later, businesses wanted to analyze the collections of data being created
• Can systems optimized for transactions also be optimized for analysis?
There are two large issues…

Issue # 1
Systems optimized for creating data in a transactional framework require a fixed schema• The meaning of the data elements are fixed by the
schema
• There is no requirement for schema evolution in RDBMS because the primary mission is ACID/CRUD operations
• No way to say how data defined in one schema relates to data defined by another schema

Issue # 2
The required data is typically stored in many databanks• It needs to be moved and combined
• What assurance is there that similar data in different databanks represent the same thing?
• Analysis is not possible until precise meaning of all required data in all databanks is known
• Data is not easily combined

Data Warehouse
We have twisted the RDBMS and the client/server paradigm into the realm of analysis through ETL and data warehousing• All of the data is moved to the same databank
• Lots of highly custom, one-off work is done to determine the meaning of each data element and how it needs to be transformed for the new target schema
• It remains a rigid schema and a siloed server!
• We need to deal with massively distributed data

The Last Forty Years
Siloed Information Management Systems• All data in a single shared databank
• Rigid schemas
• Data and metadata are different types of things
• Query processor only knows about its local data expressed in a fixed schema
• Schema not fixed for NoSQL
• Excellent ACID / CRUD capability
Enterprise data management remains an elusive goal

Timeline
1970 - Codd proposes the relational paradigm
1977 – First RDBMS arrives, Oracle, INGRES
1980 – SQL developed and several other RDBMS arrive, Sybase, SQL Server, DB2, Informix
1985 – Client-server paradigm
1990 - RDBMS mainstream
Elapsed time = Twenty Years

Acceptance of New Paradigm
20 years required for large enterprises to accept an idea introduced in 1970
Why?• New products had to be created
• A new networking paradigm had to fall into place
• Strategic uses of the new technology had to be articulated and translated to business uses

Paradigm Shift

DARPA and DAML
After DARPA created ARPAnet (TCP/IP) in 1990, it turned its attention to the problem of understanding the meaning of the data
• Their computers could “hear” each other, but could not understand each other
DARPA created DAML (DARPA Agent Markup Language) in 2000 to create a common language
www.daml.org

The World Wide Web Consortium
The W3C had evolved ARPAnet into a highly reliable, distributed system for managing unstructured content using TCP/HTTP/HTML• Grand slam for distributed information management
• The system did not work for structured content, data
2004 – DARPA hands off DAML to the W3C • The W3C evolves DAML into the RDF, OWL and SPARQL
standards
• Collectively these standards comprise what most people mean by “semantic technology”

The World Wide Web
The WWW brings the next paradigm shift in information technology after client/server
• It is a highly distributed architecture, vastly more so than client/server
• Domain Names
• Uniform Resource Locators (URL)
• Uniform Resource Identifiers (URI)
Can we build on this highly distributed infrastructure to benefit enterprise information management?

Semantic Technology
This paradigm assumes data is completely distributed, but that anyone/anything should be able to find it and use it• RDF is the data model
• OWL is the schema model
• SPARQL is the query language
• URIs are the unique identifiers
• URLs are the locators

Description
RDF and OWL are excellent formal description languagesAnyone can say Anything about Anything, Anywhere
• Descriptions are both human and machine readable
• Locations are already described by URLs and identified by IRIs
• The meaning and location of any data can now be interpreted by computers, or humans
These technologies enable the new paradigm

The Next Forty Years
The information management technology for the next forty years will all rest on precise, formalized descriptions of “things”• Schema, Data, The real world, Mappings, Rules, Business
terms, Processes, Logic, Relationships between descriptions .....
• Descriptions provide a level of abstraction above current information management infrastructure
• Descriptions are absolutely required to use distributed data

The Next Forty Years
DIMSDistributed Information Management System

The Next Forty Years
Distributed Information Management Systems• Data, metadata and logic are completely distributed but,
all machine readable
• All information is immediately accessible by computers and people
Extensibility• Constant change is assumed
• Distributed & Federated
Emergent Analytic Capability• Reasoning

DIMS
A Distributed Information Management System is a layer above your current DBMS, just like a DBMS is a layer above a file system
• Both provide an additional level of abstraction
• Both bundle new computational capabilities into the system
• Both simplify the access to and use of data by applications and developers

Timeline
2002 – DARPA publishes work on DAML
2004 – W3C creates RDF and OWL recommendations
2006 – the first triple stores and RDF editing tools are available, SPARQL is recommendation
2011 – The first DIMS is available
We are just getting to the point of enterprise adoption
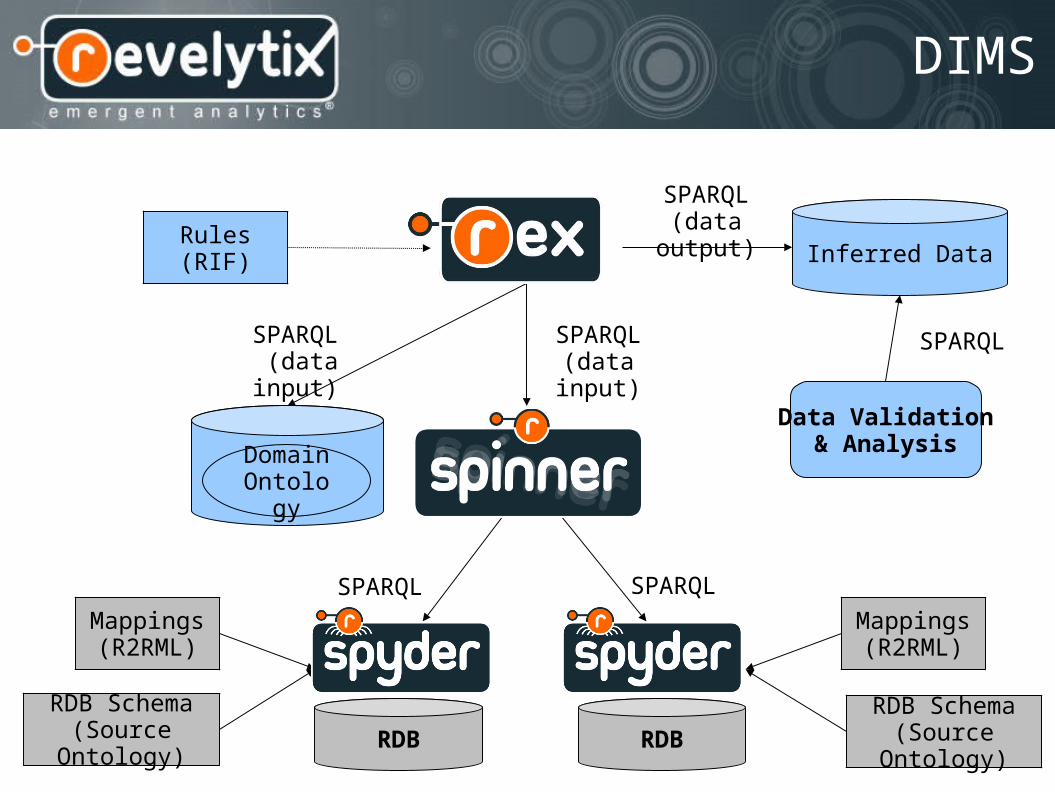
RDB RDB
Mappings(R2RML)
RDB Schema(Source
Ontology)
Mappings(R2RML)
Data Validation& Analysis
SPARQLSPARQL
RDB Schema(Source
Ontology)
Rules(RIF)
DomainOntology
SPARQL(data input)
SPARQL(data input)
Inferred Data
SPARQL(data output)
SPARQL
DIMS

Data/ App Layer
Data/ App Layer
<XML>
<XML>
<XML>
Multiple vendor DB Multiple file formats
ApplicationLayer
ApplicationLayer
Reporting &
Analytic Search
Business Application
Data Services Ad hoc data Services
e-discovery &
live data services
Maturity Level 1 No Agility; Does Not Scale

Data Service
Layer
Data Service
Layer
Virtualization Layer
Virtualization Layer
Data/ App Layer
Data/ App Layer
<XML>
<XML>
<XML>
Multiple vendor DB Multiple file formats Application Data Services
SOA
Data Service
Pub-Sub
Service
API Data
Service
Optional Cache DB
ApplicationLayer
ApplicationLayer
Rationalization & Virtualization of Data
Data Services
(SOA, Web service..)
•File Services•(ASCII, XML, Batch..)
Connectivity (JDBC, ODBC, Native..)
Reporting &
Analytic Search
Business Application
Data Services Ad hoc data Services
e-discovery &
live data services
Maturity Level 2Better; Data Management Still an Issue
Workarounds

Semantic Storage
Layer
Semantic Storage
Layer
Semantic/Catalog
Layer
Semantic/Catalog
Layer
Data Service
Layer
Data Service
Layer
Virtualization Layer
Virtualization Layer
Data/ App Layer
Data/ App Layer
<XML>
<XML>
<XML>
Multiple vendor DB Multiple file formats Application Data Services
SOA
Data Service
Pub-Sub
Service
API Data
Service
Optional Cache DB
ApplicationLayer
ApplicationLayer
Rationalization & Virtualization of Data
RDF <XML> data Storage
Semantic Integration Services Meta data services
Semantic Search
(RDF Search, SPARQL)
Data Services
(SOA, Web service..)
•File Services•(ASCII, XML, Batch..)
Connectivity (JDBC, ODBC, Native..)
Reporting &
Analytic Search
Business Application
Data Services Ad hoc data Services
e-discovery &
live data services
Maturity Level 3Best Practice; Solid Data Management
& Reduced Risk
Semantic Storage
Layer
Semantic Storage
Layer
Data Service
Layer
Data Service
Layer
Data/ App Layer
Data/ App Layer
<XML>
<XML>
<XML>
Multiple vendor DB Multiple file formats Application Data Services
SOA
Data Service
Pub-Sub
Service
API Data
Service
Optional Cache DB
ApplicationLayer
ApplicationLayer
Rationalization & Virtualization of Data
RDF <XML> data Storage
Semantic Integration Services Meta data services
Semantic Search
(RDF Search, SPARQL)
Data Services
(SOA, Web service..)
•File Services•(ASCII, XML, Batch..)
Connectivity (JDBC, ODBC, Native..)
Reporting &
Analytic Search
Business Application
Data Services Ad hoc data Services
e-discovery &
live data services
RDF Data Store
Virtualization Layer
Virtualization Layer
Semantic/Catalog
Layer
Semantic/Catalog
Layer
SPARQL
Queries
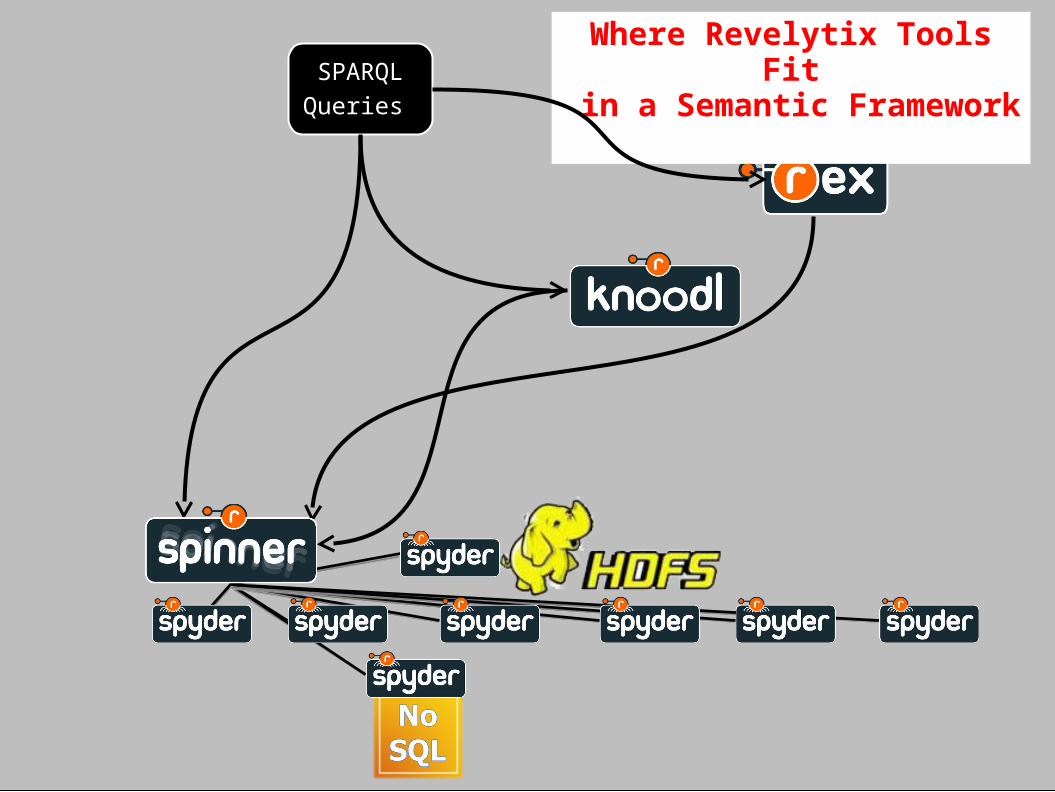
Where Revelytix Tools Fit in a Semantic Framework

Two Use Cases
Classifying swaps and aggregating risk by counterparty using the FIBO ontology
• Working with EDMC and regulators
Information provenance to infer which data sets to use for specific applications
• Working with customers to automate data discovery and access in very complex, large data centers

Financial Industry Business Ontology
IndustryStandards
ISO 20022FpML
XBRL OMG
Input
Generate
(via ODM)
Graphical Displays
Built in
FIBO
Securities
Loans
Derivatives
Business Entities
Corporate Actions
RDF/OWL
Semantic Web Ontologies
UMLTool
MISMO
FIX
Diverse Formats
Industry initiative to define financial industry terms, definitions and synonyms using semantic web principles 30
11/17/2011
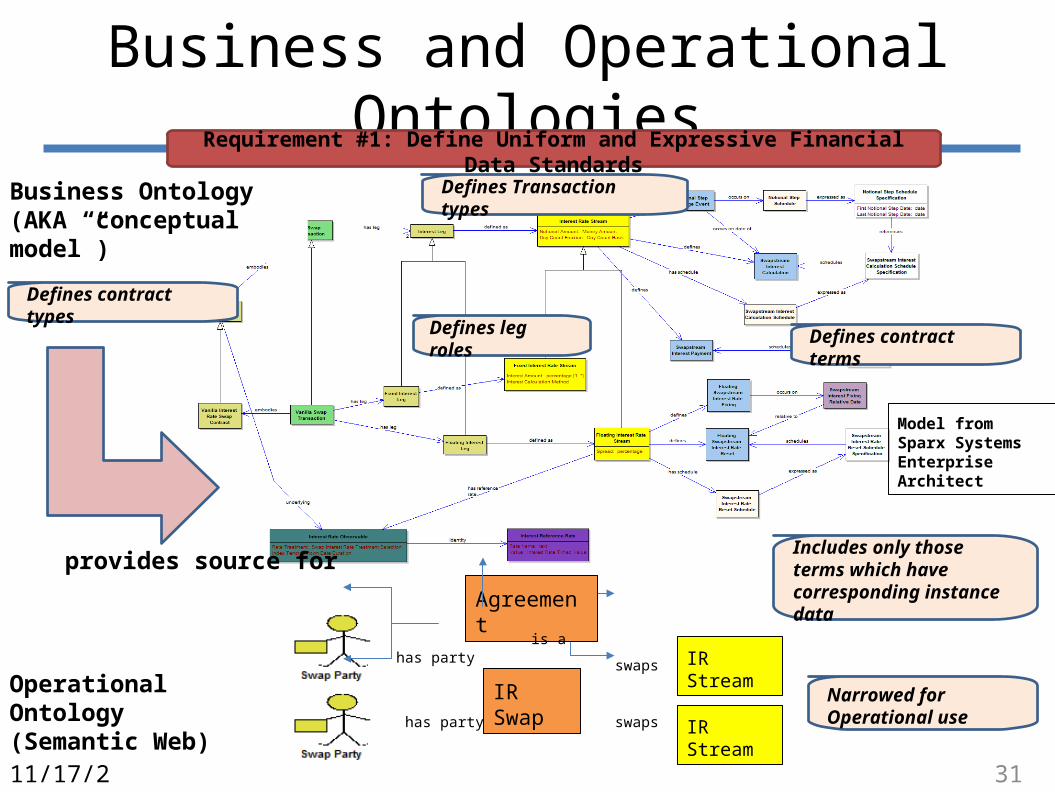
Business and Operational Ontologies
31
Defines Transaction types
Defines contract types
Defines leg roles Defines contract terms
Operational Ontology (Semantic Web)
IR Stream
IR Stream
IR Swap
Agreement
has party
has party
is a
swaps
swaps
Includes only those terms which have corresponding instance data
Requirement #1: Define Uniform and Expressive Financial Data Standards
Model from Sparx SystemsEnterprise Architect
Business Ontology (AKA “conceptual model”)
provides source for
Narrowed for Operational use
11/17/2011

Demo Architecture

Data Set Inference
Data Set Relationships• Version of, mirror of, index of...
Provenance• History and origin of data• Transformations, relocations...
Best Source Inference• Describe activities and processes• Describe goals
• Freshness, speed, completeness, authoritativeness..
• Infer best data source for your task

External
• Regulatory demands of robust data quality controls and proof of data reliability
Internal• Monitoring and controlling Operational Risk
• Internal expectations to find more productivity and reduce expenses
Why Now?

Data Set Suitability
Many business activities require the use of multiple data sets
• Analytics, audits, risk, performance monitoring
Data landscapes in large enterprises are extremely complicated
• Lots of related data sets
• Poor metadata management tools
Finding the right data sets for a particular activity is difficult
• We need more description
• Data sets need to be described better
• Processes, activities, and goals must be described better

Ontology Overview

Suitability for Use
User describes activity• E.g. External audit of manufacturing processes
Rules engine reads knowledgebase of descriptions
• Data sets, activities, processes, goals, people...
Rules engine infers which data sets are best for the activity





Closing
Paradigm shifts in IT*occur over a period of 20 years and last about 40 years
• We only have 2 examples, small sample
Highly distributed data is an expensive problem• Applications take longer and longer to build
• Analysis is incomplete, because the data is incomplete
• Compliance with policies, regulations and laws is very hard to determine
*or numerical computers, depending on the era

The Shift is On(we are in the middle of an IT paradigm shift)
A Distributed Information Management Systemis available now

Revelytix.com for much additional information
Thank You