the modern palimpsest
TRANSCRIPT

The Modern Palimpsest
Leigh Dodds, Engineering Manager, IngentaConnectIngenta Publisher Forum
28th November 2005

Introduction
• An analogy: The Modern Palimpsest
• What could we do with better data?
• Reaching a new market?

Palimpsests
A little history lesson


The Palimpsest
• Scriptio inferior (“underwriting”)– Useful information just under the surface
• Reaction to high cost of publishing
• A form of re-use?– Certainly not was intended or hoped for!

The Modern Palimpsest
Lets take a look…
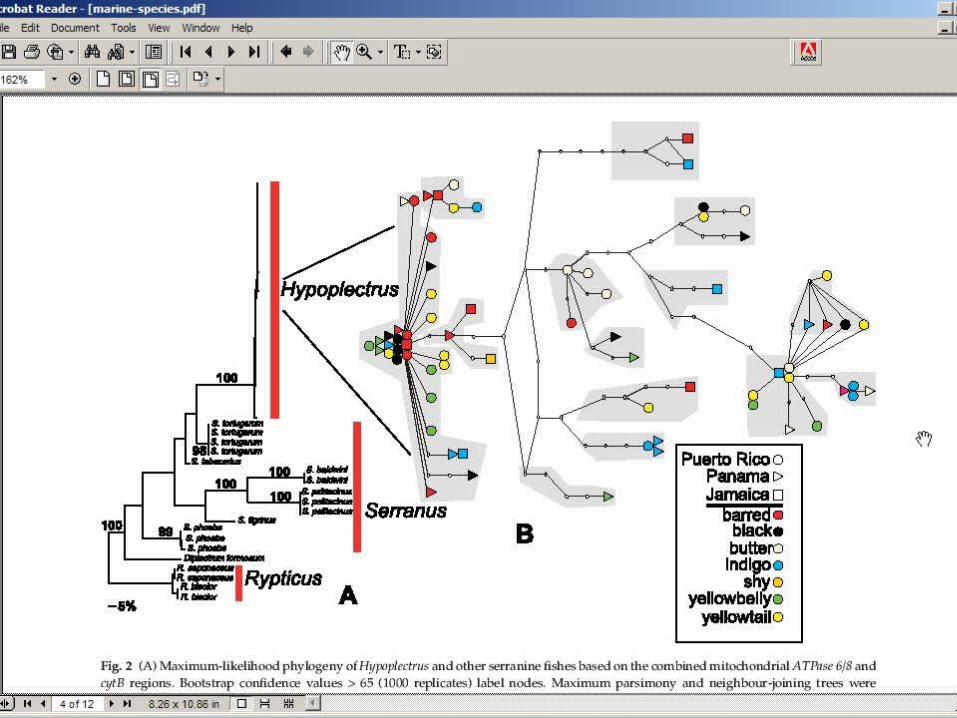

The Academic Paper as Palimpsest
• “Loss” of data during authoring and publishing– But useful information beneath the surface
• Limited Re-use– Fixed data presentation– Non-web native format
• Limited Life time– Once its been read, then what?

…the times they are a-changin'
Web 2.0

Current Trends
• Standardisation of data formats and identifiers
• Maturation of browser technologies– XML, CSS, Javascript
• The Two Way Web– Users actively engaging with content AND
data

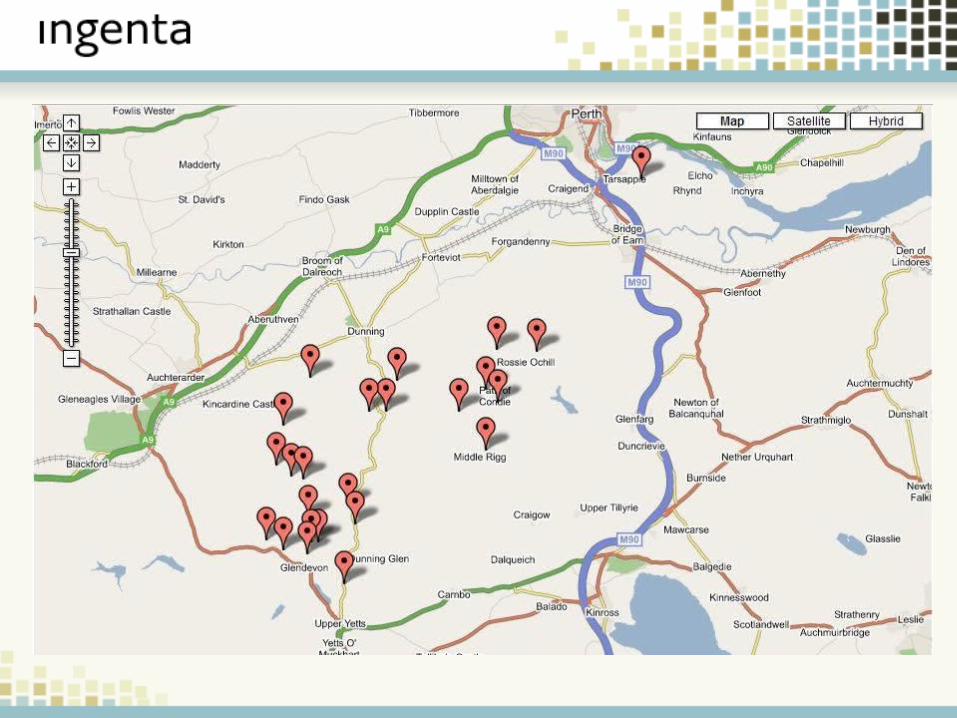
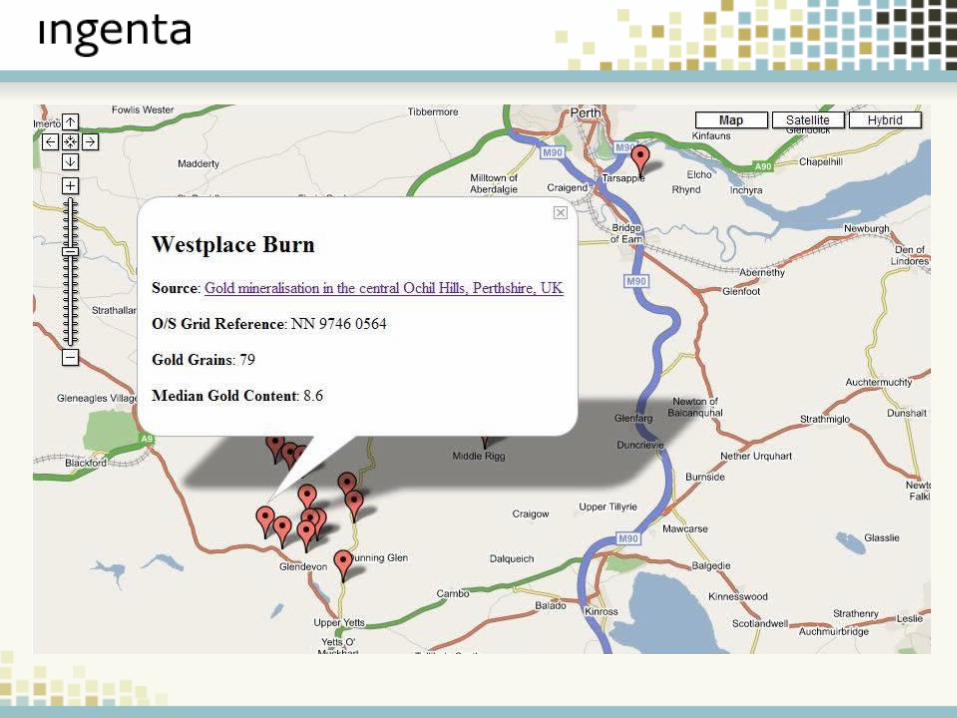
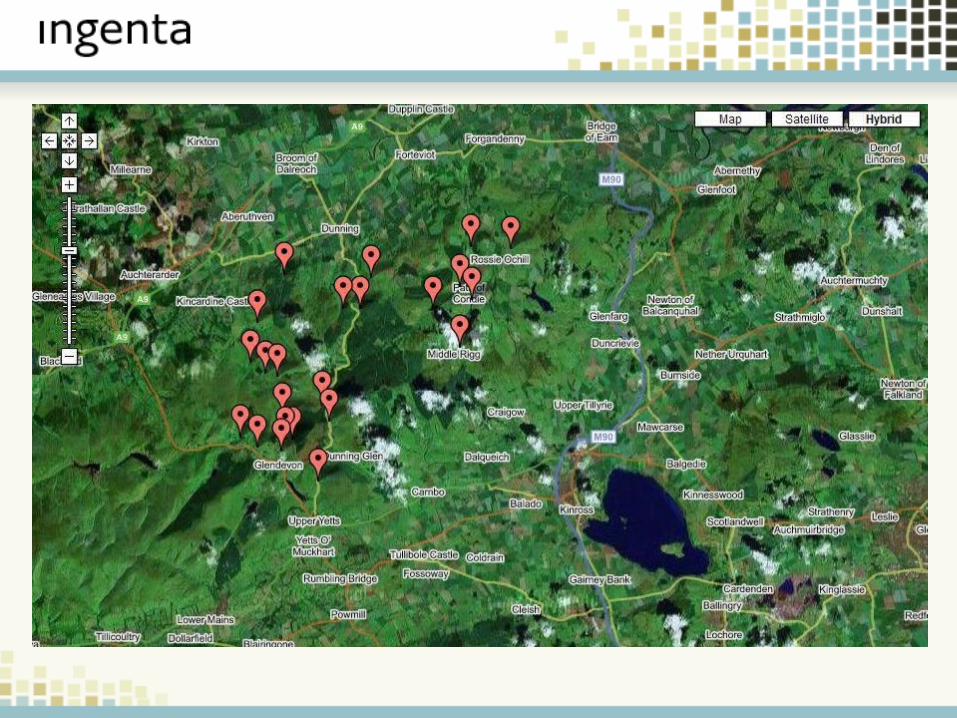
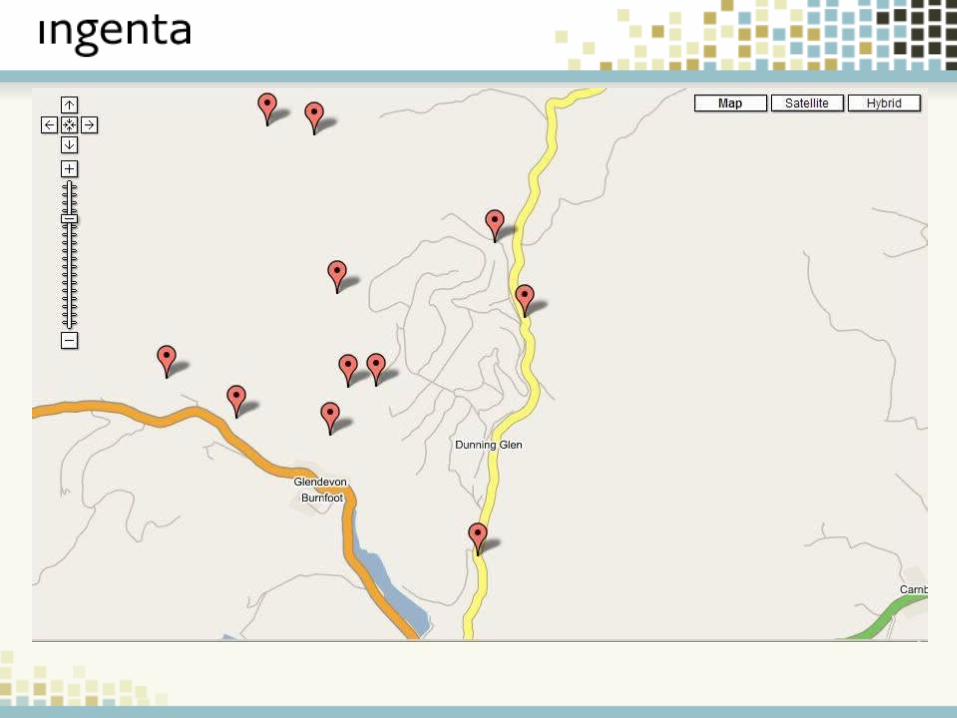
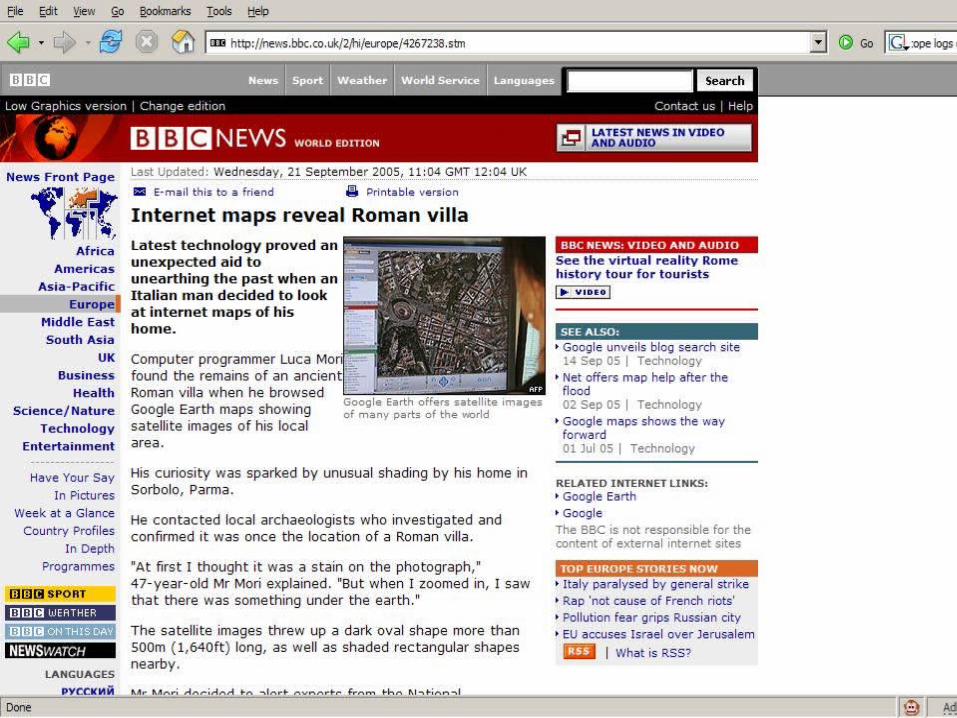
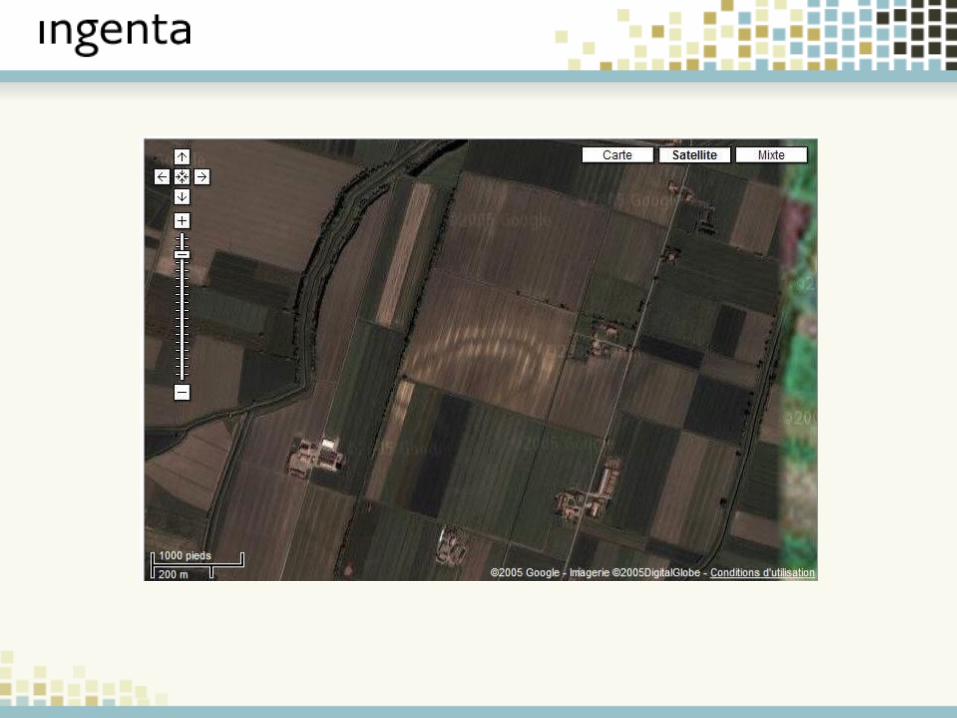
Example 1: Mapping
New Ways to Explore DataImproved Browser Technologies

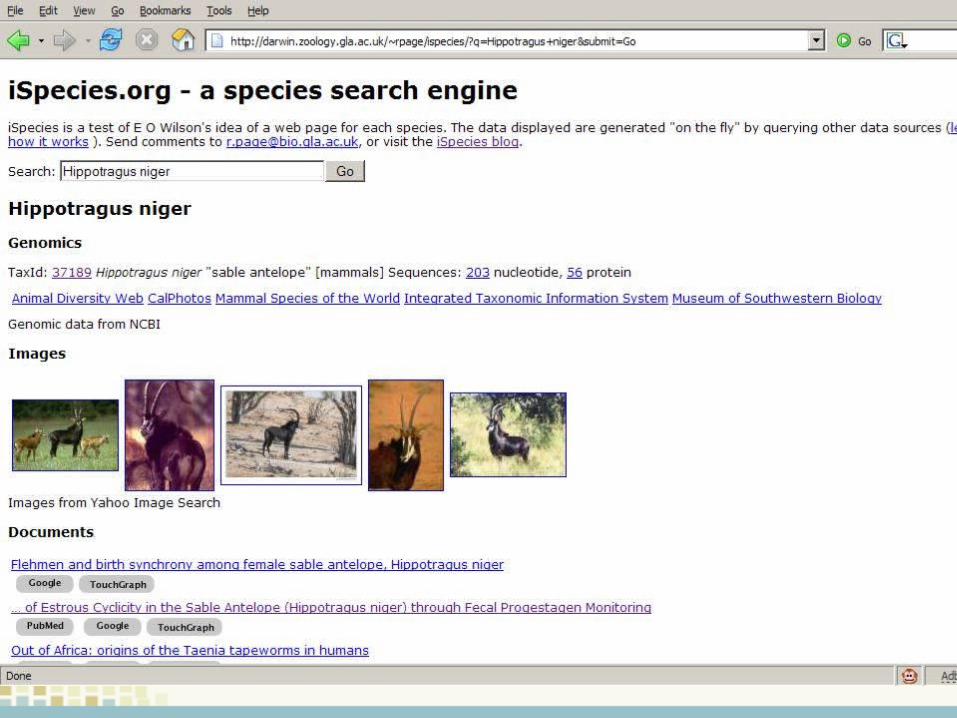
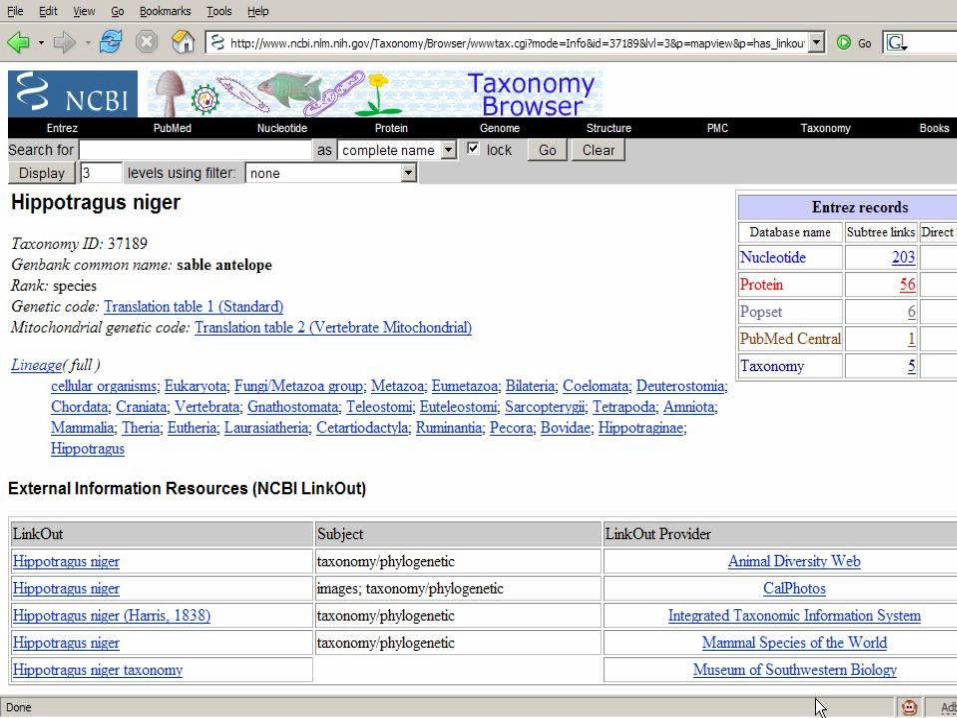
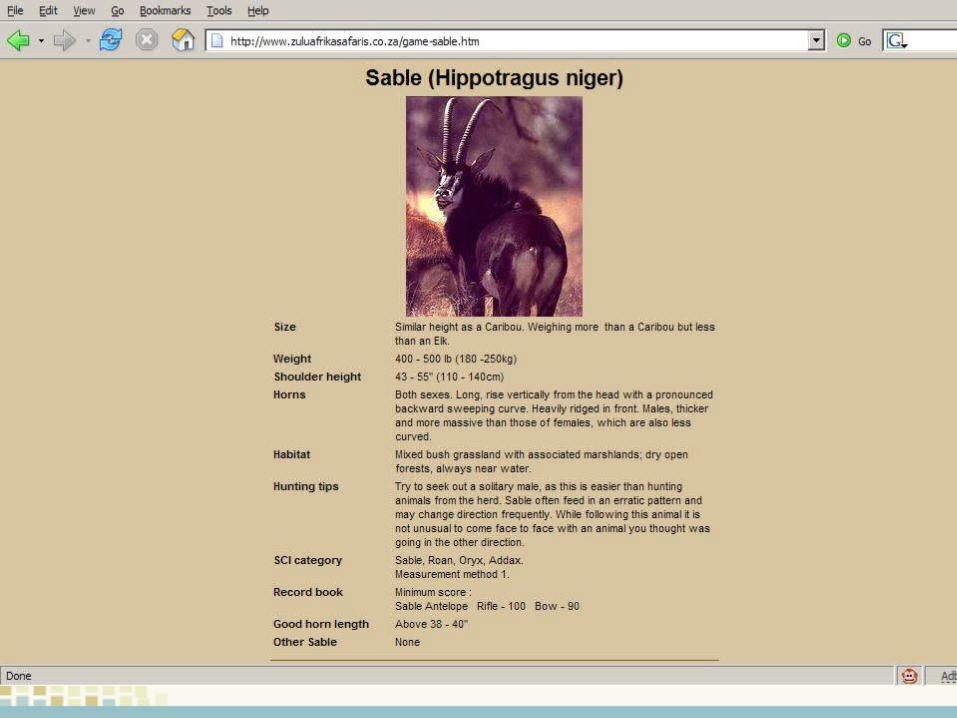
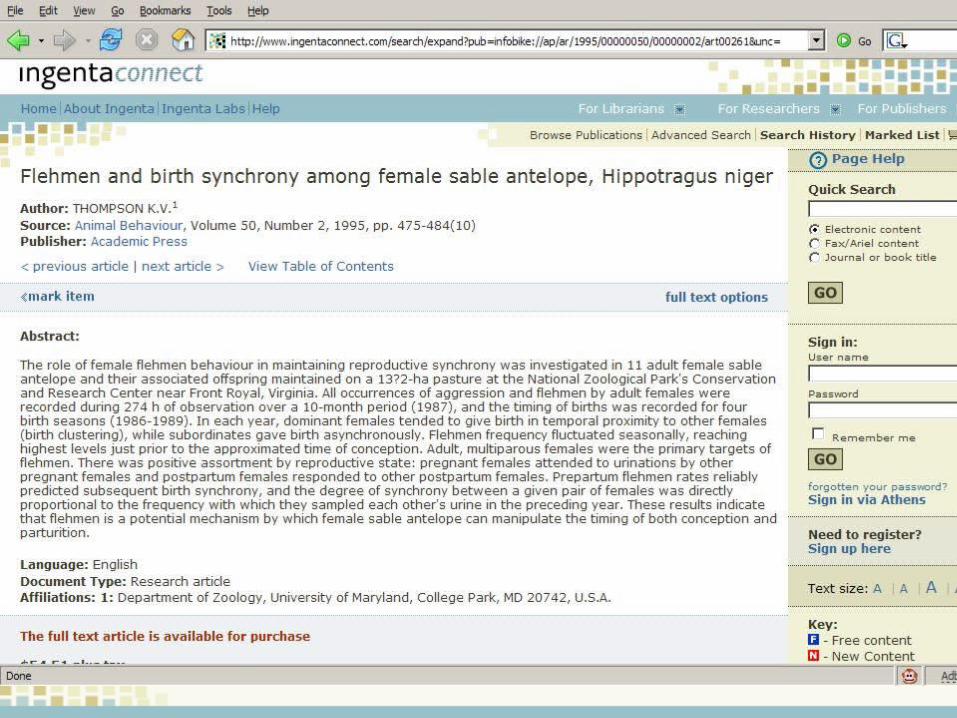
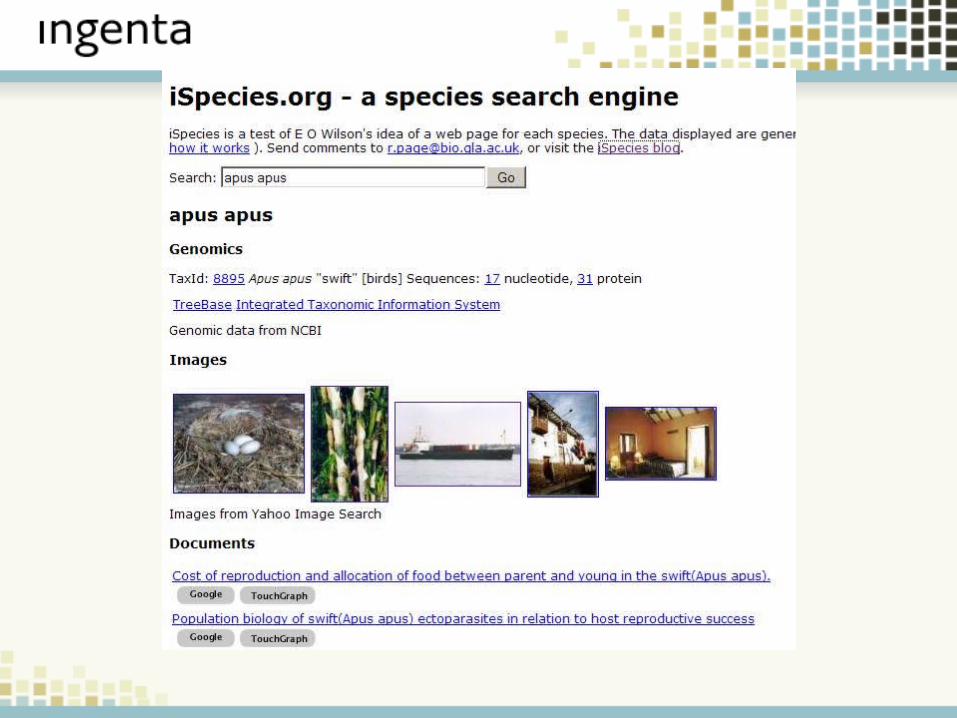
Example 2 - iSpecies
New Ways to Find DataComposing Services (“Mashups”)

Aside: Author Identifiers
• Industry needs a unique identifier for Authors– Why not use the DOI?
• More…– By this author (accurately!), or co-authors– By research group/institution– By research interest
• Social Networking, Trust

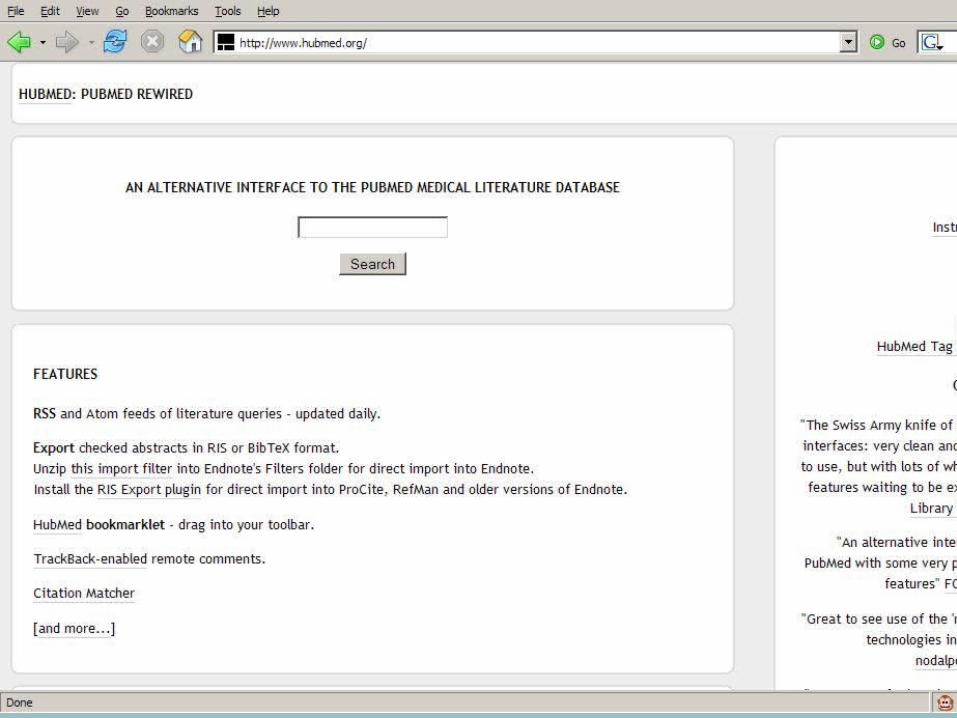
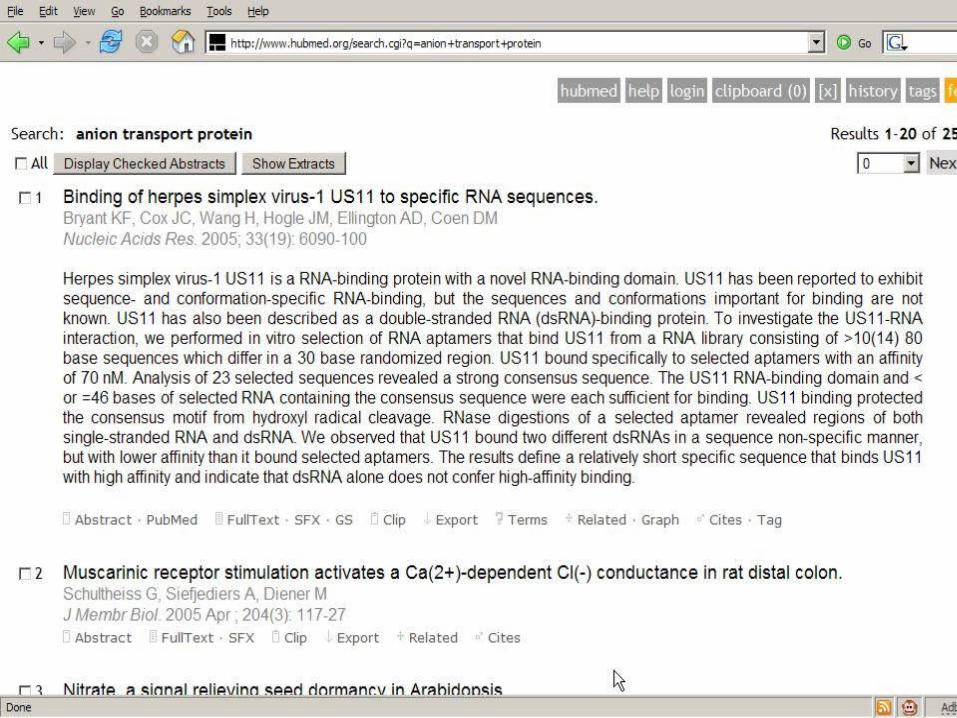
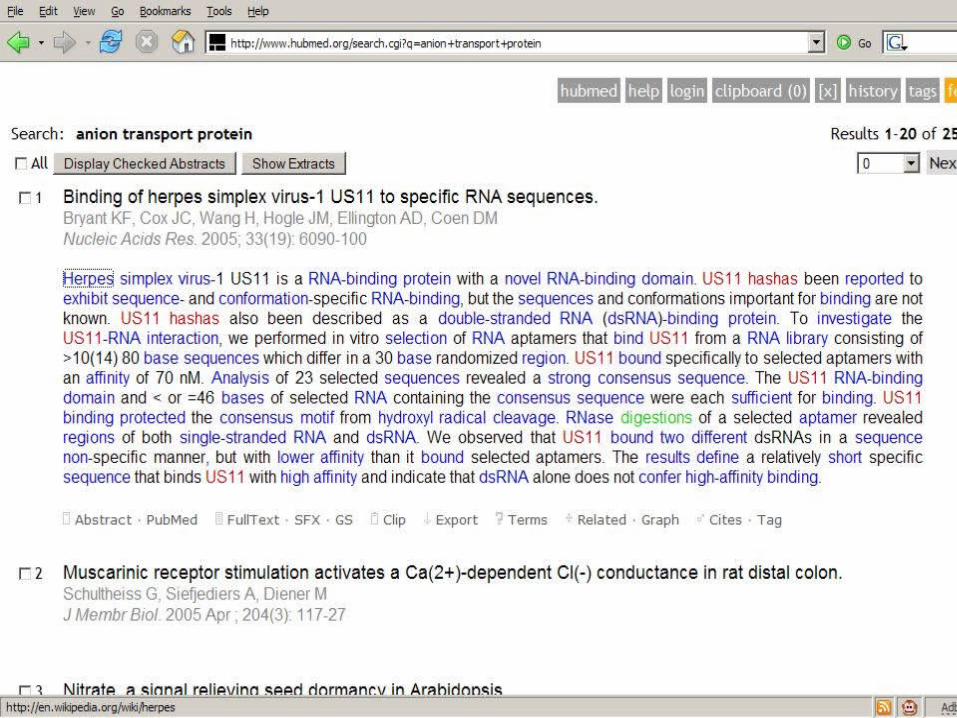
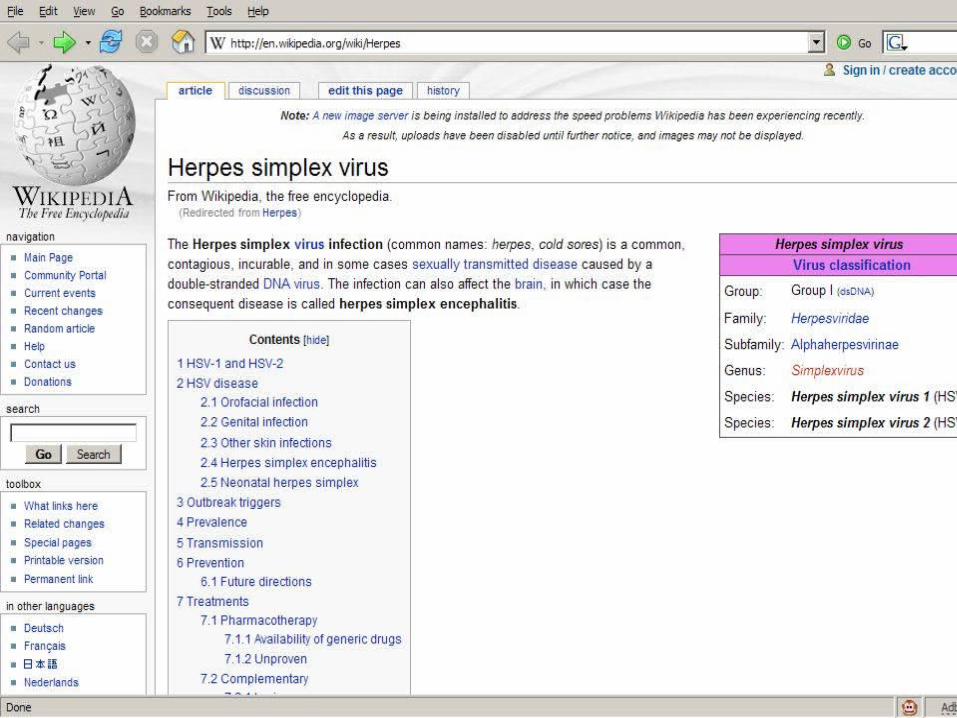
Example 3 - HubMed
Alternate User InterfacesHarvesting Collective Intelligence

Return of the Amateur?
“…an amateur may be as competent as a paid professional, yet is motivated by a love or passion for the activity”
http://en.wikipedia.org/wiki/Amateur

Summary
• Enable new markets by enabling new uses
• Deconstruct the Academic Paper
• Not just on the web, Part of the web

Publishing Richer Metadata

Publishing Richer Metadata
• Document Formats are Metadata Aware– Office tools are XML based– Open Office Bibliographic project– Adobe XMP
• Post production enrichment– Term extraction, e.g protein names, place names– Backfiles
• Supplementary Data– Publish data separately from documents

XML is Not Enough
The Semantic Web

XML is Not Enough
With the ongoing rapid increase in both volume and diversity of 'omic' data (genomics, transcriptomics, proteomics, and others), the development
and adoption of data standards is of paramount importance to realize the promise of systems biology. A recent trend in data standard development
has been to use extensible markup language (XML) as the preferred mechanism to define data representations. But as illustrated here with a
few examples from proteomics data, the syntactic and document-centric XML cannot achieve the level of interoperability required by the highly dynamic and integrated bioinformatics applications
-- “From XML to RDF: how semantic web technologies will change the design of 'omic' standards”
Nature Biotechnology 23, 1099 - 1103 (2005)