synthesizable, space and time efficient algorithms for string editing problem. vamsi k. kundeti
Post on 21-Dec-2015
236 views
TRANSCRIPT

Synthesizable, Space and Time Efficient Algorithms for String Editing
Problem.
Vamsi K. Kundeti

Agenda.
• Synthesizable: – Digital circuit to implement edit distance
in hardware.– High speed and area efficient
• Space and Time efficient algorithms:– Computing the edit script and edit
distance in time O(n2/log(n)) and O(n) space.

Edit Distance Optimization Problem

Edit Distance in hardware.
• Related work.– Parallel systolic array based designs.– Issues with systolic arrays.– e.g. [lipton86] , [lopresti87] & [sastry95]
• Sequential design.– Area efficient and high speed.– Adding edit distance to instruction set of
general CPU.– Speedup by reduction in constants.

Basic idea behind systolic arrays
PE-1 PE-2 PE-3 PE-4PE-5
PE-7
PE-6
PE-5
PE-7
Entries computed By a single processor
Entries computed In parallel.
Linear array.

Basic idea behind systolic arrays
PE-1 PE-2 PE-3 PE-4PE-5
PE-7
PE-6
PE-5
PE-7
Entries computed By a single processor
Entries computed In parallel.
T = x Can be computed in parallel

Basic idea behind systolic arrays
PE-1 PE-2 PE-3 PE-4PE-5
PE-7
PE-6
PE-5
PE-7
Entries computed By a single processor
Entries computed In parallel.
T = x+1 T = x+2
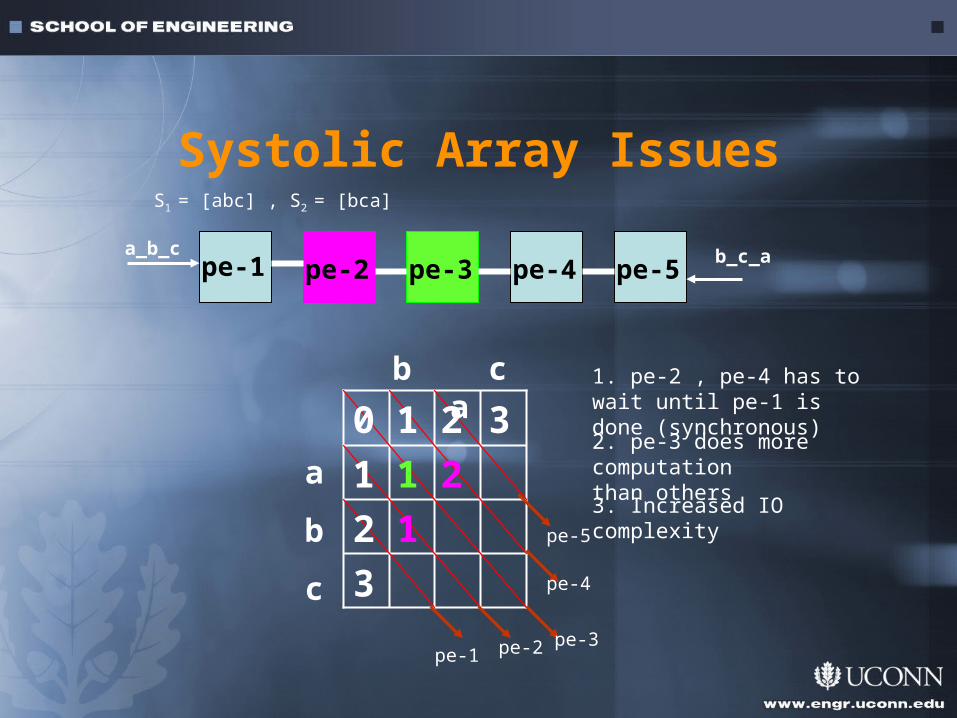
Systolic Array IssuesS1 = [abc] , S2 = [bca]
a_b_c b_c_a
a
b
c
b c a
pe-1 pe-5pe-4pe-3pe-2
0 1 2 3
1 1 2
2 1
3
pe-5
pe-4
pe-3pe-2pe-1
1. pe-2 , pe-4 has to wait until pe-1 is done (synchronous)
2. pe-3 does more computationthan others
3. Increased IO complexity

Systolic Array Problems.
• Pros:– Need only O(n) steps to compute edit distance
• Cons:– Design is too complex.– Although we need only O(n) time we pay big price.
• Clock Speed Reduction: The design needs a clock with large time period, so can only give speed in MHz. This is due to synchronous nature of design
• [sastry95] design is only 80MHz speed.– Increased Area, redundancy in form of PE’s doing less work.– I/O bandwidth limits the cost model, constraints the cost of
operations under a range.– Needs custom hardware and limits the usage of hardware.
• Issues with the systolic arrays makes their usage very limited.

Motivation behind our work.
• CPU’s are every where – servers, desktops, laptops etc…
• Almost all the Bio-Informatics software runs on general CPU’s rather than custom hardware (systolic arrays).
• Can we add edit distance instruction to the processor instruction set ?
• This can really help software by reducing the constants in asymptotic complexity.

Our Contribution.
• Key idea behind our design– “Can we compute edit distance using
exactly n+2 memory locations”
• We know if that if we need to compute only edit distance we just need to keep track of two rows which is 2n memory locations.

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x
Needed for further computation.
Just Computed.

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x+1
Needed for further computation.
Computed in previousstep
Redundant
JustComputed
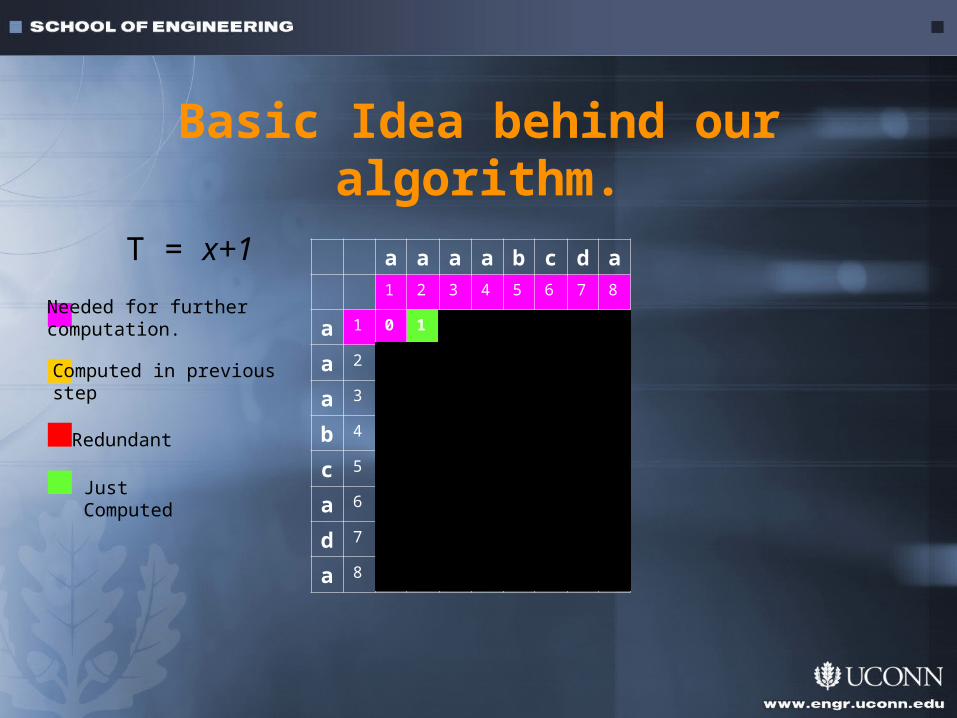
Basic Idea behind our algorithm.
a a a a b c d a
1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x+1
Needed for further computation.
Computed in previousstep
Redundant
JustComputed
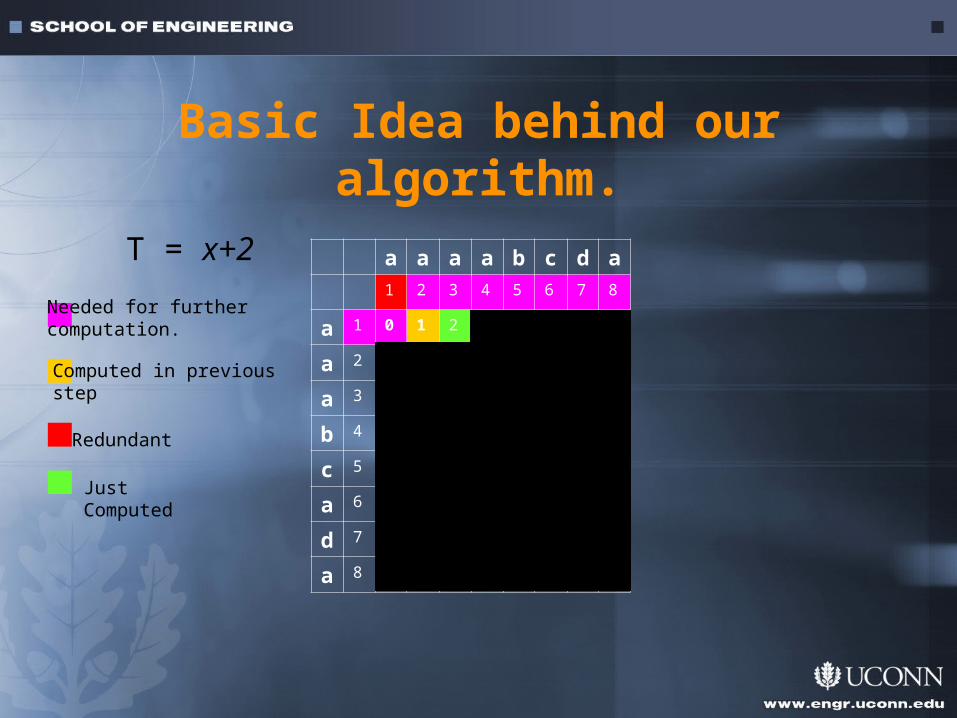
Basic Idea behind our algorithm.
a a a a b c d a
1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x+2
Needed for further computation.
Computed in previousstep
Redundant
JustComputed

Basic Idea behind our algorithm.
a a a a b c d a
2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x+2
Needed for further computation.
Computed in previousstep
Redundant
JustComputed
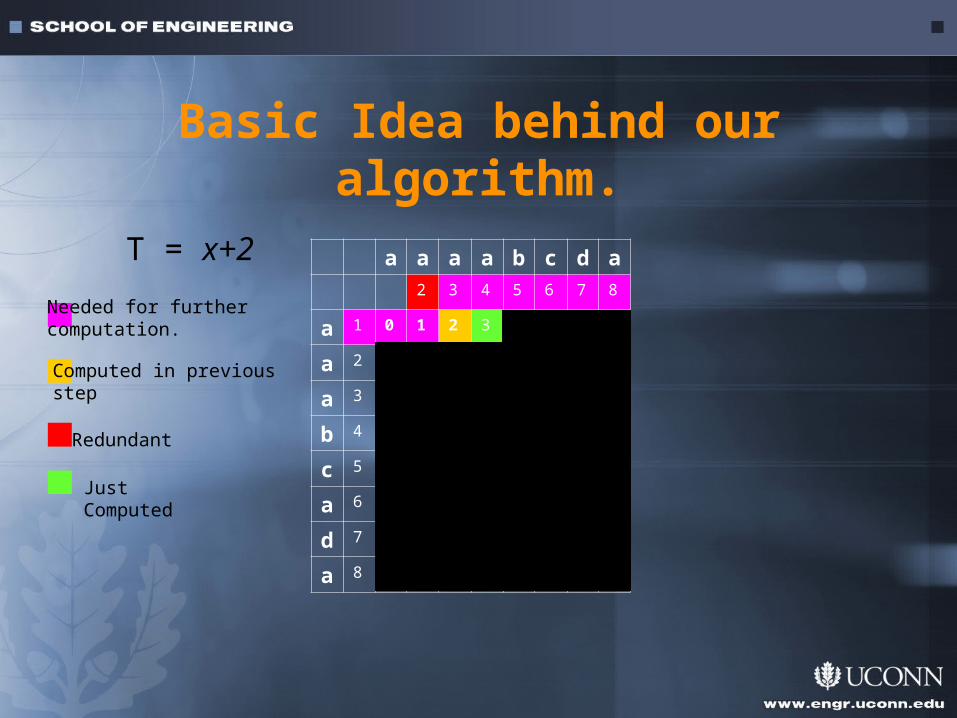
Basic Idea behind our algorithm.
a a a a b c d a
2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x+2
Needed for further computation.
Computed in previousstep
Redundant
JustComputed
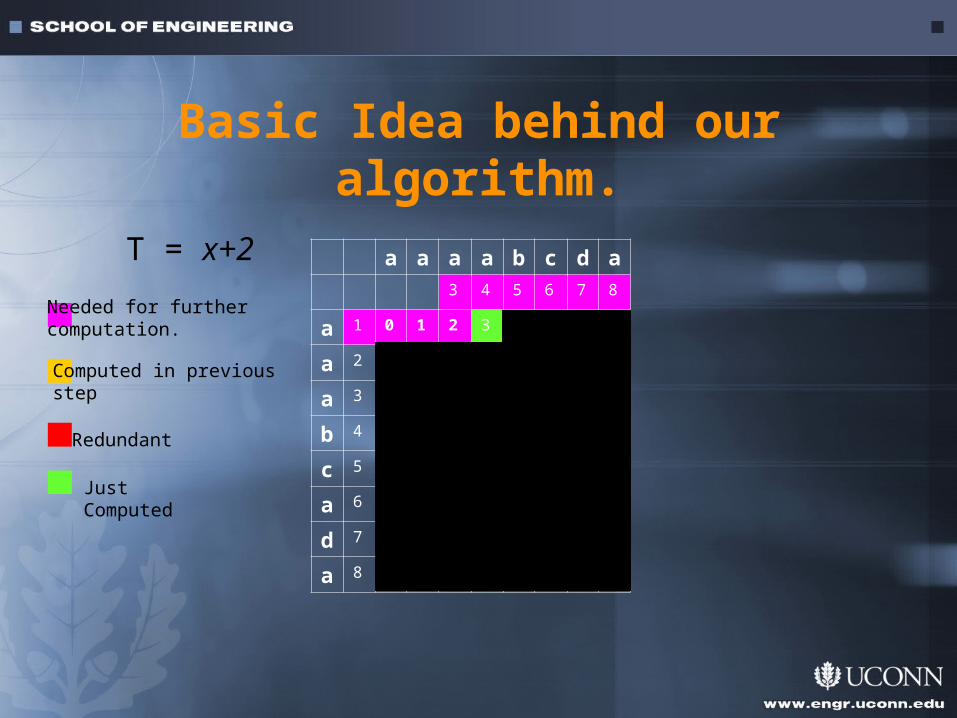
Basic Idea behind our algorithm.
a a a a b c d a
3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
T = x+2
Needed for further computation.
Computed in previousstep
Redundant
JustComputed

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2

Basic Idea behind our algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
Shift register of sizen+2
Elements are shifted in as they are computed. Andredundant elements shiftedout.

Top Level Circuit Diagram
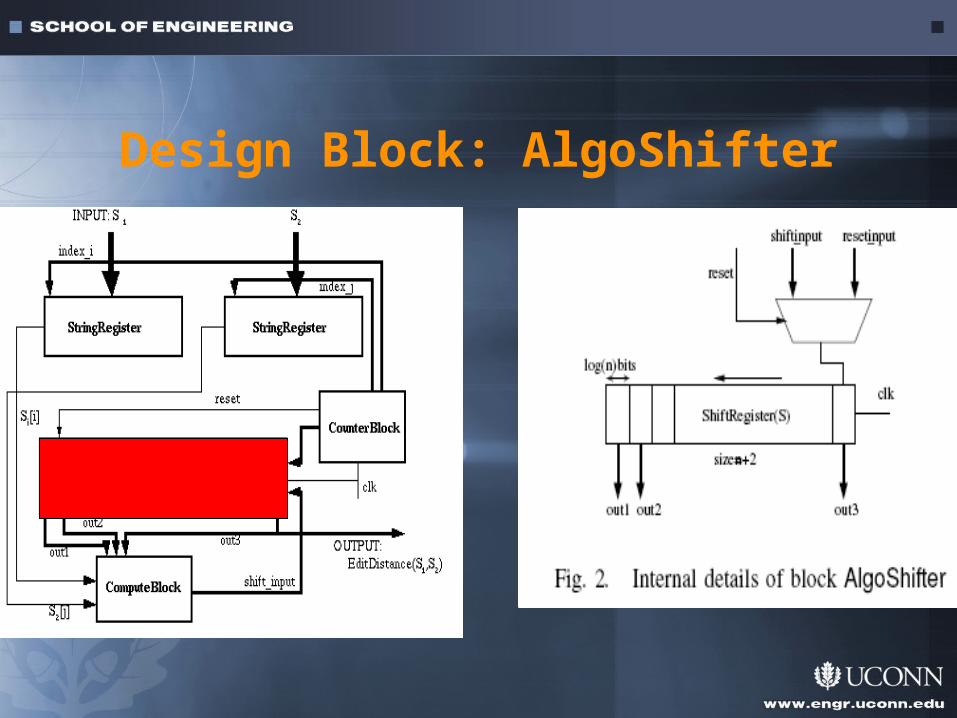
Design Block: AlgoShifter
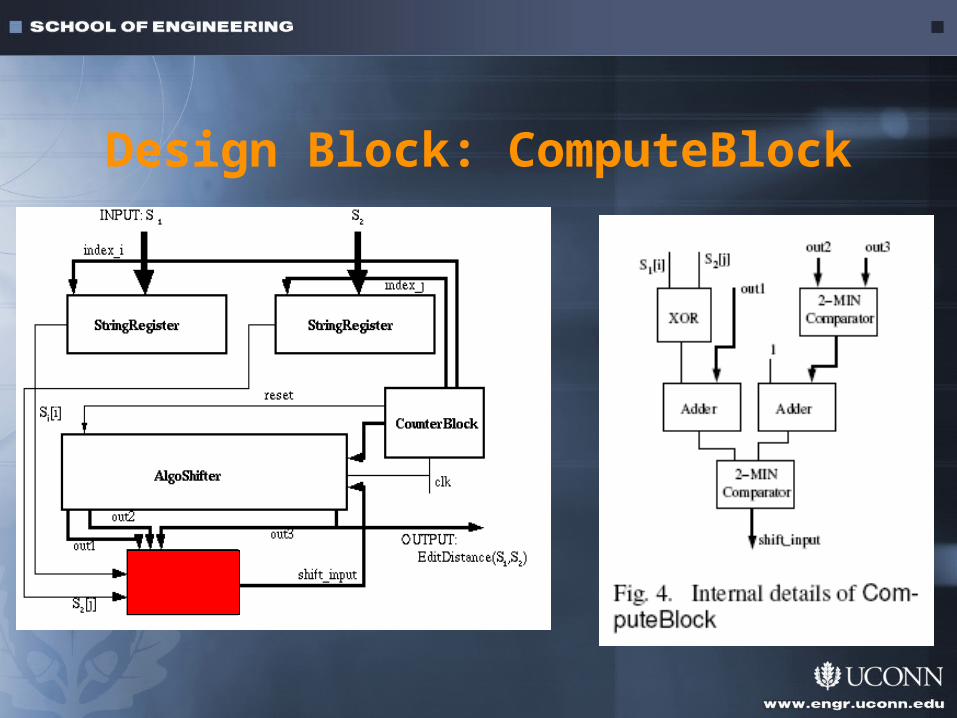
Design Block: ComputeBlock
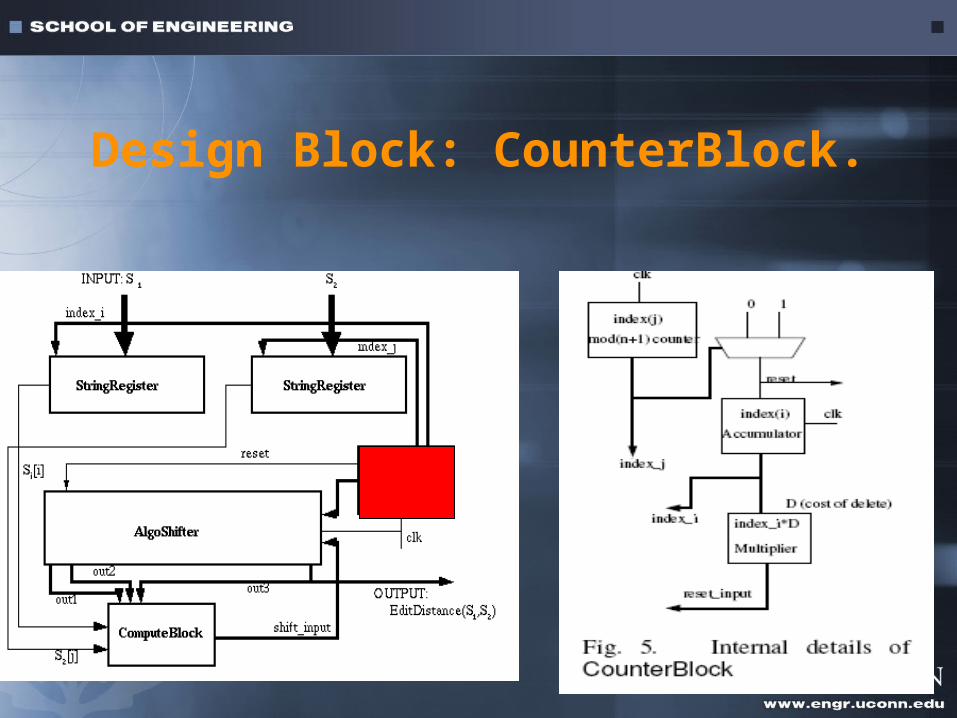
Design Block: CounterBlock.
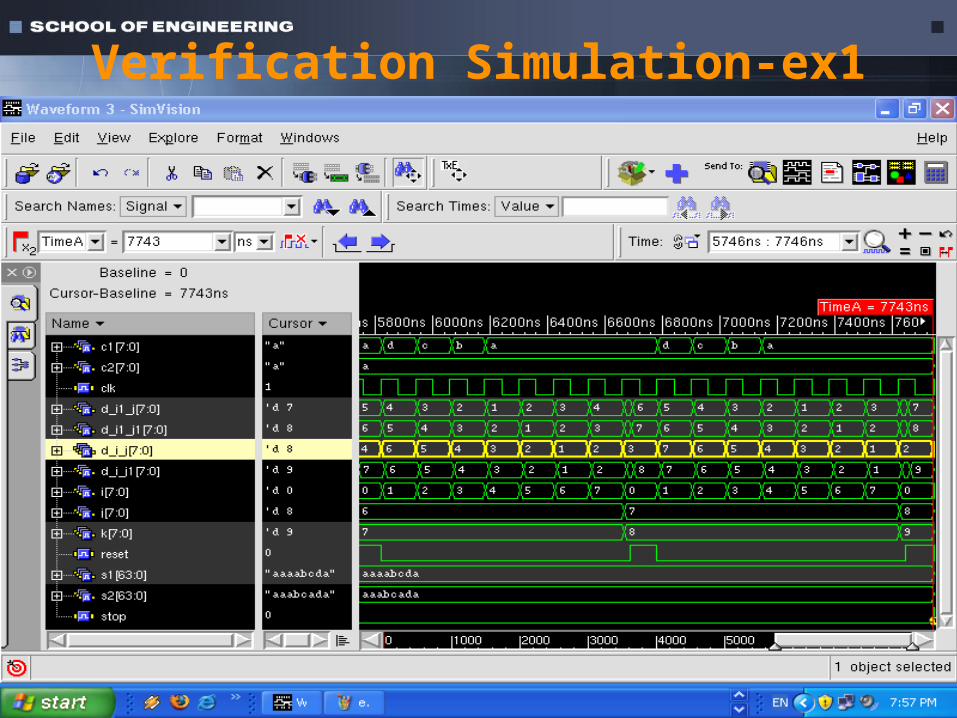
Verification Simulation-ex1

Verification Simulation ex-2

Edit Distance Instruction.
If we have a t x t edit distance instruction we spend only O(n2/ t2) time insoftware , thus this instruction is helpful in reducing the constants and speed-upedit distance computation.
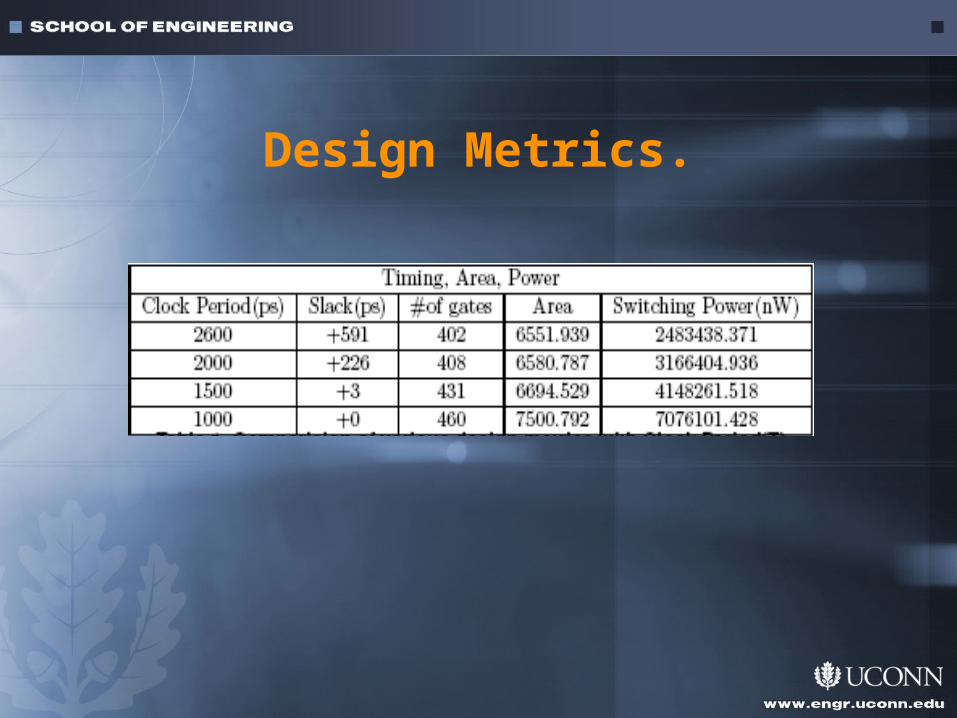
Design Metrics.

PART-2: Space and Time Efficient Algorithms for Edit Distance.
• Brief overview of Four Russian Algorithm [russian70].
• Brief overview of Hirschberg’s Algorithm [hirschberg75].
• Algorithm to compute edit distance and edit script in O(n2/log(n)) time and O(n) space.

The Four Russian Algorithm.
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
Row Overlap
Column Overlap
t-block
• n2/t2 blocks• idea is to do some pre processing to spend only O(t) time per block• runtime O(n2/t)
Spend only O(t)time to compute theentries in each block

Four Russian Algorithm
• In unit cost model the following is true
• | D[i+1,j] – D[i,j] | <= 1 (across col)• | D[i,j+1] – D[i,j] | <= 1 (across row)
• This helps us in characterizing any t-block by two vectors of size t.– The vectors will have only {-1,0,1}– e.g [0,1,2,3,….n] can be replaced by
vector [0,1,1,1,….n]
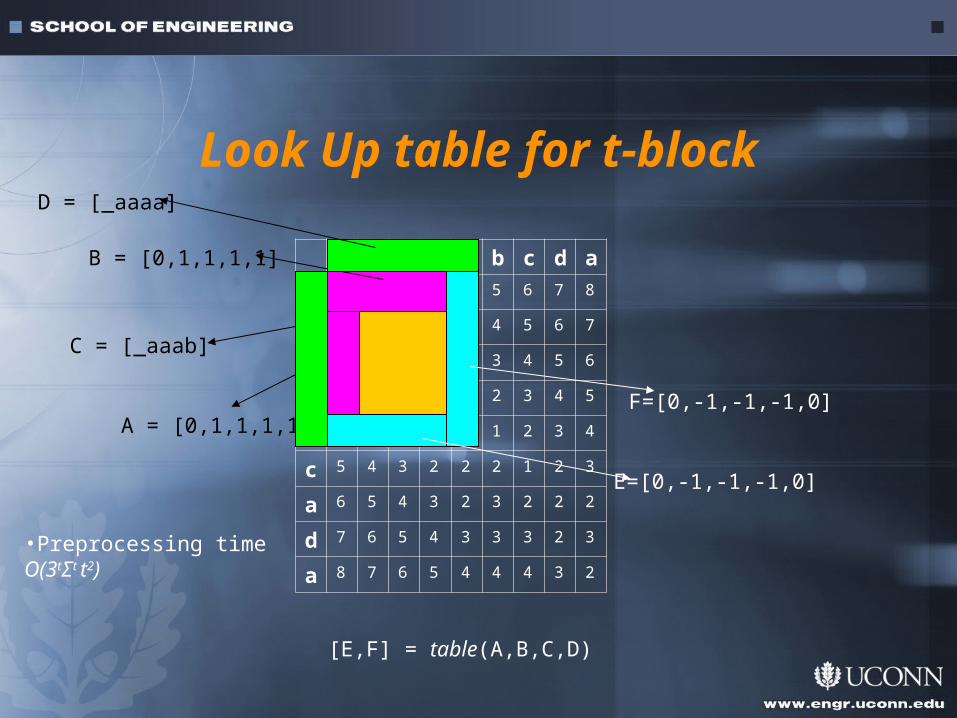
Look Up table for t-block
a a a a b c d a
0 1 2 3 4 5 6 7 8
a 1 0 1 2 3 4 5 6 7
a 2 1 0 1 2 3 4 5 6
a 3 2 1 0 1 2 3 4 5
b 4 3 2 1 1 1 2 3 4
c 5 4 3 2 2 2 1 2 3
a 6 5 4 3 2 3 2 2 2
d 7 6 5 4 3 3 3 2 3
a 8 7 6 5 4 4 4 3 2
A = [0,1,1,1,1]
B = [0,1,1,1,1]
C = [_aaab]
D = [_aaaa]
E=[0,-1,-1,-1,0]
F=[0,-1,-1,-1,0]
[E,F] = table(A,B,C,D)
•Preprocessing time O(3tΣt
t2)

Hirschberg’s Dynamic Programming formulation.
(a1 a2 ….an-1) an
(b1 b2 ….bn-1) bn
Standard DP
(a1 a2 ….an-1 an)
(b1 b2 ….bn-1 bn)
align
……..
(a1 a2…an/2 ) (an-1…an)
(.) (……………)
(a1 a2…an/2 ) (an-1…an)
(..) (…………)
(a1 a2…an/2 ) (an-1…an)
(…) (………)

Hirschberg's Algorithm runtime.

Our Algorithm.
• In hirschberg’s algorithm we spend O(n2) time to compute D[n/2,*] and Dr[n/2,*].
• Can we use the Four Russian framework to Compute D[n/2,*] and Dr[n/2,*] in time O(n2/log(n)) O(n) space?

Using Four Russian Framework at each level
Space Usage
D[n/2-1,*]
Dr[n/2-1,*]

Using Four Russian Framework at each level
Space Usage

Using Four Russian Framework at each level
Space Usage
Spend Only O(n2/t) time to compute D[n/2,*] and Dr[n/2,*]
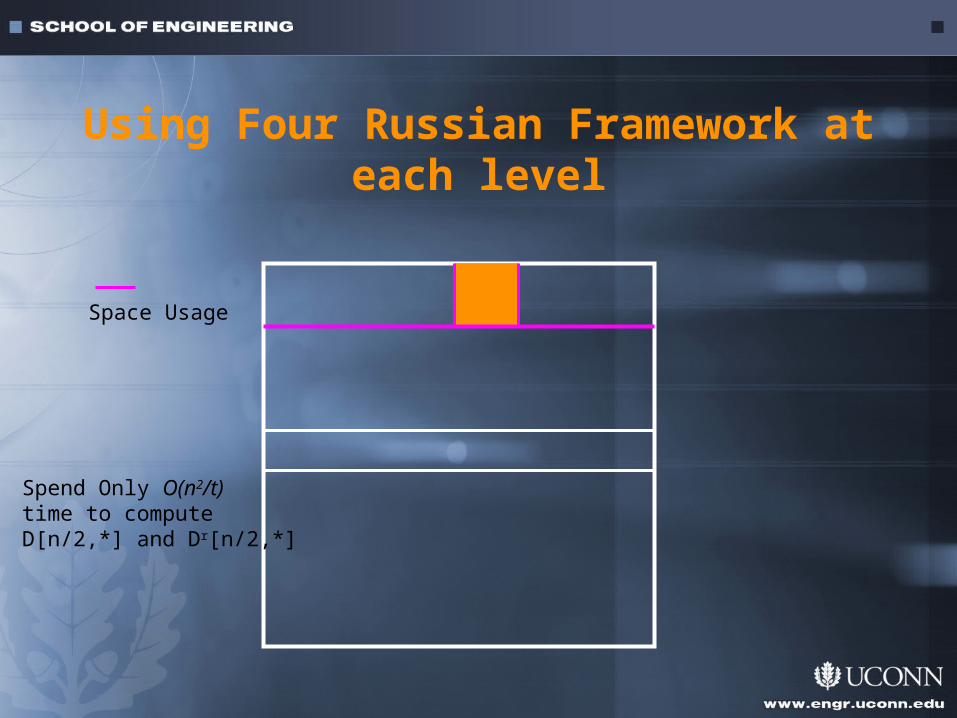
Using Four Russian Framework at each level
Space Usage
Spend Only O(n2/t) time to compute D[n/2,*] and Dr[n/2,*]

Cases which require row k which is not a multiple of t
Space Usage
Use Four Russianframework till FLOOR(k)spend at most O(nt) timeto compute row k.
However O(n2/t2) dominates
Required this row k

Runtime and Space Analysis.
Space:1. Space during the core algorithm, which we saw is linear.2. Space to hold the lookup table after the preprocessing.
then the space required would be linear for lookup table

References.[sastry95] R. Sastry, N. Ranganathan, and K. Remedios. CASM: A VLSI chip forapproximate string matching. IEEE Trans. Pattern Anal. Mach. Intell.,17(8):824–830, 1995.
[lopresti87] D. P. Lopresti. P-NAC: A systolic array for comparing nucleic acid sequences.Computer, 20(7):98–99, 1987.
[lipton85] R. J. Lipton and D. Lopresti. A systolic array for rapid string comparison.In Chapel Hill Conf. on VLSI, pages 363–376, 1985.
[russian70] V. L. Arlazarov, E. A. Dinic, M. A. Kronrod, and I. A. Faradzev. On economicconstruction of the transitive closure of a directed graph. Dokl. Akad. NaukSSSR, 194:487–488, 1970.
[hirschberg75] D. S. Hirschberg. Linear space algorithm for computing maximal commonsubsequences. Communications of the ACM, 18(6):341–343, 1975.