synchronisationsmodul informatik teil-modul … · – data definition language – ddl – zur...
TRANSCRIPT

Kapitel 5 - 1 Schestag Synchronisationsmodul DB (Master DS)
Synchronisationsmodul Informatik
Teil-Modul „Datenbanken“
Kapitel 5: SQL - Structured Query Language

Kapitel 5 - 2 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
Inhalte des Kapitels
• SQL – Data Definition Language DDL
• Systemkatalog, Reverse-Engineering und Schichtenarchitektur
• SQL – Data Manipulation Language DML – Explain-Analysen
• Views und Rechtevergabe
Lernziele
• ein SQL-Skript zur Generierung einer Datenbank sowohl selbst schreiben
als auch korrekt interpretieren und sinnvoll modifizieren können
• die Auswirkungen von Constraints, insbesondere PK- und FK-Constraints
kennen und strategisch korrekt einsetzen können
• Aufbau und Funktion eines Systemkatalogs verstehen, auch im Hinblick auf
das Reverse-Engineering, sowie den Zusammenhang zur 3-Ebenen-
Architektur kennen
• SQL-Datenmanipulation und Rechtevergabe (insbesondere im Zusammen-
hang mit Views) kennen und anwenden können, ebenso die Optimierung
durch Explain-Analyse

Kapitel 5 - 3 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
Die mathematische Basis
des Relationenmodells ist die Relationen-Algebra - auf deren Basis Edgar
F. Codd Anfang der 70er Jahre eine Data-Sublanguage DSL definieren
konnte. SQL ist in die folgenden Komponenten unterteilt:
– Data Definition Language – DDL – zur Definition der Struktur bzw.
des Schemas einer Datenbank
– Data Manipulation Language – DML – zur Manipulation der Daten
und zur Recherche auf den Daten
– Data Control Language – DCL – zur Vergabe und Zurücknahme von
Rechten
Die klare mathematische Struktur
dieser Sprache ermöglichte die relativ schnelle Definition eines Standards,
der Structured Query Language – SQL.

Kapitel 5 - 4 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
• SQL ist eine interpretierte Sprache.
• SQL verfügt über keinerlei Kontrollstrukturen und stellt in ihrer DML-
Syntax ausschließlich mengenorientierte Operatoren zur Verfügung.
• Die Einbettung von SQL in Programmiersprachen, die Kontroll-
strukturen enthalten ist eine Möglichkeit, um Datenbankinhalte
dynamisch in Applikationen zu integrieren. Die hierfür erforderlichen
Sprachkomponenten sind im Standard unter dem Begriff Embedded SQL
(ESQL) definiert (vgl. Kapitel 6).
• Weitere Möglichkeiten zum Zugriff auf RDBMS aus höheren Programmier-
sprachen liefern entsprechende API, z.B. JDBC im Bereich der Java-
Anwendungsentwicklung (vgl. ebenfalls Kapitel 6).

Kapitel 5 - 5 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language, Historie
SQL ist heute „de-facto“ Standard in der relationalen Welt.
1969 / 70
1974
1975 / 79
1986 / 87
1989
1992
1999
2003
2006
2008
2011
E. F. Codd: „A Relational Model of Data for Large Shared Data Banks“
SEQUEL (Structured English Query Language) als Vorläufer von SQL
wird definiert
SYSTEM R (IBM) als Prototyp wird entwickelt
SQL-86 ANSI/ISO Standard erste genormte Version von SQL – SQL1
X/OPEN Standard für UNIX Systeme, IBM SAA Standard
SQL-89
SQL-92 – SQL2 wird von der ISO verabschiedet mit 3 Leveln: Entry
Level, Intermediate Level, Full Level
SQL:1999 – SQL3
SQL:2003 – ISO/IEC 9075:2003
SQL:2006 – ISO/IEC 9075-14:2006 Verwendung von SQL im
Zusammenhang mit XML
SQL:2008 – ISO/IEC 9075(1-4,9-11,13,14):2008
SQL:2011 ISO/IEC 9075:2011, aktuelle Revision

Kapitel 5 - 6 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (1)
• Zur Verwaltung von Strukturobjekten einer Datenbank stehen in der DDL
von SQL die folgenden Operatoren zur Verfügung *):
• Im Systemkatalog (s.u.) werden alle
– Informationen zu Strukturobjekten sowie
– statistische Informationen zu den Daten verwaltet.
• Der Systemkatalog selbst hat ebenfalls die Struktur eines Relationensche-
mas. So gibt es z.B. eine Systemtabelle, in der Informationen zu allen
Tabellen der DB enthalten sind, eine Systemtabelle mit Informationen zu
allen Spalten etc.
*) SQL ist in den meisten DBMS nicht case sensitive, d.h. unterscheidet nicht zwischen Groß- und Kleinschreibung.
Aus didaktischen Gründen werden SQL-Operatoren im Skript oft in Großbuchstaben geschrieben.
CREATE Generierung eines Strukturobjektes
ALTER Ändern eines Strukturobjektes
DROP Löschen eines Strukturobjektes

Kapitel 5 - 7 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (2)
• Die Generierung des logischen Datenbanknamens (des Schema-
Namens) und Zuweisung des verfügbaren Plattenbereiches erfolgt mit
der CREATE DATABASE ... - Anweisung.
• Hierbei wir der logische Namen der Datenbank auf vorgegebenem
physischen Plattenbereich mit vorgegebener aber erweiterbarer Größe
festgelegt, z.B.:
• Die CREATE DATABASE-Anweisung wird in der Regel vom Datenbank-
Administrator – DBA ausgeführt. Sie ist in der Syntax der verwendeten
Klauseln und Parameter von System zu System oft sehr unterschiedlich.
create database <Datenbank>
datafile <Dateiangabe>{,<Dateiangabe>}
character set <Zeichensatz>
national character set <NatZeichensatz>
...;

Kapitel 5 - 8 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (3)
Tabellen – Tables
Table_Elemente sind
- <Columnn_Name> [DEFAULT_Definition]
<Column-Type> und NULL-Fähigkeit, oder
- <Table_Constraint_Definition>
Table_Constraint_Definitionen sind
- primary key constraint <pk>:
PRIMARY KEY (<Columnn_Element>,)
- candidate key constraint:
UNIQUE (<Columnn_Element>,)
- foreign key constraint <fk> und
- “check constraint” – Definitionen:
s. Folien 5-10 ff
Syntax: CREATE TABLE <Table_Name> (<Table_Element>,) ;
BestellID INTEGER
<pk>
Kundennr INTEGER
<fk>
BDatum DATE
Bestellung

Kapitel 5 - 9 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (4)
• Es empfiehlt sich (und die meisten DBMS fordern es auch), jede Zeile
eindeutig über einen PRIMARY KEY zu definieren.
In einer Tabelle gibt es höchstens einen PRIMARY KEY-Constraint, aber
beliebig viele UNIQUE-Constraints.
• Das DBMS übernimmt aufgrund der UNIQUE-Deklaration bei Primary Key- und UNIQUE-Constraints die Verantwortung dafür, dass keine
Spalteneinträge für die entsprechenden Spalten doppelt vorkommen.
Wie kann das DBMS dies performant gewährleisten?
Welche Operationen müssen dafür vom DBMS auf den entsprechenden
Tabellen „beobachtet“ werden?
vgl. hierzu auch Praktikum 3!

Kapitel 5 - 10 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (5)
• Ein FOREIGN KEY-constraint ist die Implementierung einer Beziehung
aus dem ER-Modell im Relationenmodell. Er garantiert referentielle
Integrität bei allen schreibenden Operationen auf den Datensätzen der
beiden an der Beziehung beteiligten Tabellen:
An welcher Stelle der Daten-
modellierung wird festgelegt, ob die FK-Spalte NULL-fähig ist oder nicht?
E1
PK1 <pk>
A1
E2
PK2 <pk>
PK1 <fk>
E1.PK1=E2.PK1
create table E1
( PK1 INTEGER not null,
A1 VARCHAR(20) null,
constraint PK_E1 primary key (PK1)
);
create table E2
( PK2 INTEGER not null,
PK1 INTEGER [not] null,
constraint PK_E2 primary key (PK2),
constraint FK_E2_REL_E1 foreign key (PK1) references E1 (PK1)
);
1. 2.

Kapitel 5 - 11 Schestag Synchronisationsmodul DB (Master DS)
Fremdschlüssel-Constraints bei Update- und Delete-Operationen
• Man spricht von referentieller Integrität, wenn zu jedem Zeitpunkt die Referenz eines Primärschlüsselwertes durch den Wert einer Fremd-schlüsselspalte gewährleistet ist.
Welche Veränderungen an den beiden Tabellen würden darüber hinaus zu einer Verletzung der referentiellen Integrität führen? (vgl. hierzu auch Kapitel 3)
Verlag
VID <pk> VerlagBez
123 ‘ABC ‘
234 ‘XYZ ‘
Buch
ISBN <pk> Titel VID <fk>
3-548-… ‘A…. ‘ 123
0-122-… ‘B…. ‘ 123
2-456-… ‘C…. ‘ 234
9-768-… ‘D…. ‘ 567
3-672-… ‘E…. ‘ 234
0-398-… ‘F…. ‘ 123
?
333
SQL – Data Definition Language DDL (6)

Kapitel 5 - 12 Schestag Synchronisationsmodul DB (Master DS)
• Standard SQL: Definition unterschiedlicher Optionen, die ergänzend zu FK-
Constraints im Update- oder Delete-Fall des referenzierten Datensatzes
deklariert werden. Ein integritätssicherndes Verhalten des DBMS wird dann
auch im „Konfliktfall“ gewährleistet:
CONSTRAINT <c-name> FOREIGN KEY (<Columnn_Element>,)
REFERENCES <Table_Name> [(<Columnn_Element>,)]
[ON DELETE <option>]
[ON UPDATE <option>]
mit option =
NO ACTION entspricht dem default: Die Operation wird abgewiesen,
wenn es referenzierende Datensätze gibt
CASCADE abhängige Datensätze werden kaskadisch mit gelöscht
bzw. geändert
SET DEFAULT abhängige Datensätze bleiben erhalten, der FK-Wert
SET NULL wird auf einen Defaultwert (Update) oder NULL (Delete)
geändert
SQL – Data Definition Language DDL (7)

Kapitel 5 - 13 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (8)
Zusammenfassung
• Constraints sind Prüfungen, die vom DBMS bei bestimmten DB-Operatio-
nen durchgeführt werden:
• PK- und UNIQUE-Constraints prüfen bei einem Insert und einem Update,
ob der neue bzw. geänderte PK-Wert nicht bereits in der Tabelle enthalten
ist, d.h. dieser Constraint garantiert die Eindeutigkeit des PK-Wertes.
• FK-Constraints garantieren beim Insert und Update für die referenzierende
Tabelle bzw. beim Update und Delete der referenzierten Tabelle, dass die
Referenz auf das entsprechende PK-Element tatsächlich gewährleistet ist.
• "check constraints": CHECK (<Constraint_Bedingung>)
Eine Datenbankoperation wird nur dann ausgeführt, wenn die Constraint-
Bedingung den Rückgabewert “TRUE” liefert. Andernfalls wird die
Operation nicht zugelassen.

Kapitel 5 - 14 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (9)
• Eine Tabelle, die mit CREATE TABLE generiert wurde, nennt man auch Base Table.
Tabellen ändern
neue Spalte hinzufügen *):
ALTER TABLE <Table_Name>
ADD COLUMN <Column-Name, column_Typ/Domain, [Default …]>
• Definition eines neuen default-Wertes für eine exisiterende Spalte
• Löschen eines existierenden Spalten-defaults
• Löschen einer existierenden Spalte
• Definition eines neuen Table Integritäts-constraints
• Löschen eines bestehenden Table Integritäts-constraints
*) Bei Oracle: alter table <table_name> add <Column-Name, Column_Typ/Domain,[Default ...]>;

Kapitel 5 - 15 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (10)
Tabellen löschen
DROP TABLE <Table_Name> <option>
<option> = RESTRICTED: DROP wird nur ausgeführt, wenn die Tabelle
von keiner anderen referenziert wird.
<option> = CASCADE*): Die gesamte Tabelle und ihre Sichten (vgl. VIEW,
s.u.) sowie die FK-Constraints der referenzieren-
den Tabelle(n) werden gelöscht.
*) Bei Oracle: drop table <table_name> cascade constraints;

Kapitel 5 - 16 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (11)
Tabelleninhalte(!) löschen
TRUNCATE TABLE <Table_Name> ; *)
• Löscht die Inhalte einer Tabelle, aber nicht die Tabellenstruktur selbst (im
Unterschied zu DROP TABLE!).
• Berücksichtigt keine ON DELETE-Trigger, d.h. dieser Befehl kann nicht
angewandt werden für Tabellen, die von anderen Tabellen referenziert
werden.
• Unmittelbar nach der Ausführung wird der physische Speicherbereich, der
von den Datensätzen genutzt wurde, freigegeben.
• Die gelöschten Datensätze werden nicht im Rollback-Segment vorgehalten.
Weitere Details zur Nutzung und Auswirkung dieser SQL-Anweisung s.
Kapitel 7, Transaktionsmanagement – insbesondere zur Abgrenzung gegen
den DELETE-Operator (s.u. bei DML-Operatoren).
*) im SQL-Standard seit SQL:2008

Kapitel 5 - 17 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (12)
Datentypen und Domains
• Bei der Generierung von Tabellen müssen den Spalten Datentypen
zugewiesen werden oder selbst definierte Domains:
Skalare Datentypen
• Für die Generierung von Tabellen und deren Spaltenelementen stehen in
SQL verschiedene skalare Datentypen zur Verfügung, die je nach
Datenbanksystem unterschiedliche Bezeichner haben können und im
Prinzip den Standard-Datentypen höherer Programmiersprachen
entsprechen. Warum nur skalare Datentypen?
Domains (Wertebereiche) (in Oracle “Type” ab Version 8)
• Aus Basis der skalaren Datentypen können eingeschränkte Domains /
Wertebereiche definiert werden, die zur Sicherung von Wertebereichs-
integritäten dienen:

Kapitel 5 - 18 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (13)
Domains (Wertebereiche) – Fortsetzung
Beispiel
• Ein DOMAIN ist eine Menge erlaubter Werte eines Datentyps. Beim
CREATE TABLE kann der DOMAIN-Name an Stelle eines skalaren
Datentyps angegeben werden. Optional können auch DEFAULT-Werte
zugewiesen werden.
Syntax: CREATE DOMAIN <Domain_Name> < Datentyp >
[DEFAULT <...>]
[CONSTRAINT <Constraint_Name>
CHECK (VALUE in (<...>,) ] ;
create domain Fachbereich varchar(20)
default 'Informatik'
check (value in ('Informatik','Mathematik','Elektrotechnik'));

Kapitel 5 - 19 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (14)
Domains (Wertebereiche) - Fortsetzung
• DOMAIN ändern
ALTER DOMAIN <Domain> DROP CONSTRAINT <Constraint>
ALTER DOMAIN <Domain_Name> ADD <Constraint_Name>
• DOMAIN löschen
DROP DOMAIN <Domain_Name> RESTRICTED - oder
DROP DOMAIN <Domain_Name> CASCADE
RESTRICTED: DROP wird nicht ausgeführt, wenn der DOMAIN an
mindestens einer Stelle benutzt wird
CASCADE: DROP wird immer ausgeführt; statt des DOMAIN erhält die
Spalte dann z.B. den zugrunde liegenden Datentyp des Domain ohne
Constraints.
Der grundlegende Datentyp einer Spalte kann jedoch nicht verändert
werden.

Kapitel 5 - 20 Schestag Synchronisationsmodul DB (Master DS)
SQL – Data Definition Language DDL (15)
Indexe
• Indexe sollten in der Regel erst dann eingerichtet werden, wenn eine Tabelle mit Daten erstmalig bestückt wurde: Werden die Daten zunächst in index-lose Tabellen eingefügt, so wird nicht durch jedes Einfügen eines Tupels eine Index-Aktualisierung ausgelöst.
• Ein Index kann nicht nur über eine einzelne Spalte, sondern auch über Spaltenkombinationen angelegt werden (vgl. auch Kapitel 4).
• Ein Primärindex wird nie explizit angelegt, da jedes DBMS auf einem Primärschlüssel automatisch einen Primärindex anlegt – warum ?
Syntax: CREATE INDEX <Index_Name>
ON <Table_Name> (<Col_1>,...,<Col_n>) [ASC|DESC];

Kapitel 5 - 21 Schestag Synchronisationsmodul DB (Master DS)
Vorkenntnisse: Ergebnisse des Eingangstests* 1
Fragen und Antworten aus dem Bereich „Constraints“
1. Was versteht man unter dem Primärschlüssel (PS) einer Tabelle
bzw. einem Primary Key Constraint? (9/11)
richtig falsch im Prinzip richtig, aber …
Ein PS ist ein eindeutiges Merkmal einer Tabelle und wird häufig dazu benutzt, [???]
Der PS ist eine Variable anhand derer eine eindeutige Zuordnung eines Objektes erfolgen kann.
PS: weist ein Objekt spezifisch aus
Der PS spezifiziert die Individuität eines Datensatzes in der Tabelle.
Ein Merkmal, das zur eindeutigen Identifizierung verwendet werden kann.
Schlüssel, über den auf eine Tabelle zugegriffen wird.
* insgesamt 11 Teilnehmer

Kapitel 5 - 22 Schestag Synchronisationsmodul DB (Master DS)
Vorkenntnisse: Ergebnisse des Eingangstests 2
Fragen und Antworten aus dem Bereich „Constraints“ - Fortsetzung
Wie würden Sie die Antwort nach Kapitel 5 formulieren?
1. Was versteht man unter dem Primärschlüssel (PS) einer Tabelle bzw. einem Primary Key Constraint? (9/11) – Fortsetzung
richtig falsch im Prinzip richtig, aber …
Mit einem PS können Datensätze aus mehreren Tabellen verbunden werden.
Ein PS ist ein eindeutiges Wiedererkennungs-merkmal. Es muss immer einer vorhanden sein (pro Daten-tupel)
Mit einem PS kann man eine Entität eindeutig identifizieren.

Kapitel 5 - 23 Schestag Synchronisationsmodul DB (Master DS)
Vorkenntnisse: Ergebnisse des Eingangstests 2
Wie würden Sie die Antwort nach Kapitel 5 formulieren?
2. Was versteht man unter dem Fremdschlüssel (FS) einer Tabelle bzw. einem Foreign Key Constraing (5/11)
richtig falsch im Prinzip richtig, aber …
Ein FS ist der Primärschlüssel einer anderen Tabelle. Er wird in der vorliegenden Tabelle hinterlegt, um bestimmte Kardinalitäten bzw. Verbindungen zwischen den Tabellen ab- zubilden.
Ein FS is der Primärschlüssel einer anderen Entität.
FS: ist ein Schlüssel, der als Bezugspunkt genutzt wird.
FS stellt Beziehung zu anderer Tabelle her
schwer zu erklären; wenn jedem Datensatz ein Primary Key aus einer anderen Tabelle zugeordnet wird.

Kapitel 5 - 24 Schestag Synchronisationsmodul DB (Master DS)
Vorkenntnisse: Ergebnisse des Eingangstests 3
Wie würden Sie die Antwort nach Kapitel 5 formulieren?
3. Was versteht man unter referentieller Integrität? (1/11) richtig falsch im Prinzip richtig, aber …
Referentielle Integrität beschreibt die Konsistenz zwischen den Tabellen, indem die Schlüssel eindeutig sind.

Kapitel 5 - 25 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
• Systemkatalog, Reverse-Engineering und Schichtenarchitektur
• SQL – Data Manipulation Language DML
• Sichten: VIEW
• Rechtevergabe

Kapitel 5 - 26 Schestag Synchronisationsmodul DB (Master DS)
• Alle Metadaten zu einem Objekt einer Datenbank, also alle Daten zu den
erzeugten Schemaobjekten wie Tabellen, Views, Indexe etc., werden von
einem DBMS in speziellen Systemtabellen gespeichert, dem so genannten
Systemkatalog (man spricht auch von Data Dictionary).
• Die Inhalte der Tabellen des Systemkatalogs können mit der SQL-SELECT-Anweisung abgefragt werden.
• Die einzelnen Tabellen des Systemkatalogs stehen miteinander in Bezie-
hung, sodass dem Systemkatalog ein eigenes Relationenmodell zugrunde
liegt. Die Tabellen des Systemkatalog werden z.B. immer dann modifiziert,
wenn eine Datenbankstruktur angelegt (create), geändert (alter) oder
gelöscht (drop) wird.
• Die Bezeichner für die Systemtabellen variieren von System zu System.
Bei vielen DBMS beginnen die Systemtabellen mit dem Präfix SYS, z.B. bei
DB2, Informix und MS SQL-Server, und haben ansonsten sprechende Be-
zeichner, z.B. SYSTABLES, SYSCOLUMNS, SYSVIEWS, SYSREFERENCES etc.
Der Systemkatalog (1)

Kapitel 5 - 27 Schestag Synchronisationsmodul DB (Master DS)
Beispiel des Informix-Systemkatalogs von 1997*)
Bis heute hat sich die Anzahl der Systemtabellen in einem Systemkatalog
stark vervielfacht, vor allem nach der Erweiterung um objekt-relationale
Konzepte.
*) Ausschnitt aus einem DBA-Handbuch der Firma Informix aus dem Jahr 1997
Der Systemkatalog (2)

Kapitel 5 - 28 Schestag Synchronisationsmodul DB (Master DS)
• Namenskonventionen der Systemtabellen bei Oracle
Die Systemtabellen sind bei Oracle nach folgendem Schema aufgebaut:
• Das Präfix schränkt die anzuzeigenden Objekte wie folgt ein:
USER_ alle Schemaobjekte des aktuellen Users, also des
entsprechenden Schemas
ALL_ alle Schemaobjekte, auf die der User Zugriffsrechte hat
DBA_ alle Schemaobjekte; nur ein Datenbankadministrator (der
User DBA) darf hierauf zugreifen
• Eine Auswahl von wichtigen Schemaobjekten *):
TABLES, TAB_COLUMNS, CONS_COLUMNS, CONSTRAINTS,
INDEXES, TABLESPACES, TRIGGERS, VIEWS, ... *) Die Tabellenstruktur der Schemaobjekte kann durch entsprechendes DESC <Tablename>
erfragt werden.
<Präfix>_<Schemaobjekt>
Der Systemkatalog (3)

Kapitel 5 - 29 Schestag Synchronisationsmodul DB (Master DS)
Beispiel
create table Auftrag (
ANR integer not null, ADAT date not null, KNR integer not null,
primary key (ANR), foreign key (KNR) references Kunde (KNR) );
Der Systemkatalog (4)
MyDatabase
Auftrag ANR ADAT KNR
ein insert into user_tables ...
drei insert into user_tab_columns ...
zwei insert into user_constraints ... und user_cons_columns
Systemkatalog
zu MyDatabase

Kapitel 5 - 30 Schestag Synchronisationsmodul DB (Master DS)
• Welche Informationen liefert diese SELECT-Anweisung?
• Neben den statischen Daten zur Datenbankstruktur werden im System-
katalog auch dynamisch statistische Daten zu den Datenbankinhalten
gespeichert, wie z.B. Anzahl der Zeilen pro Tabelle, maximale und minimale
Ausprägung der Spalten jeder Tabelle, etc.
• Diese statistischen Daten werden insbesondere zur Ermittlung des
optimalen Anfrageweges durch den Optimizer benutzt (s.u.).
• Statistische Daten werden i.d.R. wegen der erheblichen Belastung des
Systems nicht automatisch nach jedem Schreibvorgang, sondern z.B. im
Rahmen der Nachtverarbeitung durch explizit gestartete Prozesse aktuali-
siert (z.B. UPDATE STATISTICS, RUNSTATS etc.).
select * from all_tab_columns order by table_name;
Der Systemkatalog (5)

Kapitel 5 - 31 Schestag Synchronisationsmodul DB (Master DS)
Select table_name from user_tables;
…
Zahlreiche Re-Engineering-Tools nutzen den Systemkatalog, um im
Reverse-Verfahren ein entsprechendes Relationenmodell und auf dessen
Basis ein eER-Modell der Datenbank zu generieren.
Reverse Engineering (1)
Der Systemkatalog ist insbesondere dann wichtig,
wenn mangels Dokumentation zum Relationenmodell keine
schriftlichen Informationen über das Datenbankschema vorliegen!*)
MyDatabase Systemkatalog
zu MyDatabase ? *) dies ist in den meisten Unternehmen der „default“ :-/

Kapitel 5 - 32 Schestag Synchronisationsmodul DB (Master DS)
• Im CASE-Tool PowerDesigner kann für alle vom System unterstützten
DBMS ein Reverse Engineering durchgeführt werden:
Reverse Engineering (2)
Entweder über ein
bestehendes SQL-Skript …
… oder über einen ODBC-
Zugriff direkt auf den
Systemkatalog der DB.

Kapitel 5 - 33 Schestag Synchronisationsmodul DB (Master DS)
• Nach erfolgreichem Zugriff auf SQL-Skript oder Systemkatalog bietet der
PowerDesigner die Option, für bestimmte Tabellen und zugehörige Struktur-
elemente das Reverse Engineering durchzuführen:
Reverse Engineering (3)

Kapitel 5 - 34 Schestag Synchronisationsmodul DB (Master DS)
• Das Ergebnis ist ein Relationenmodell, auf dessen Basis wiederum ein
DBMS-unabhängiges ER-Modell und/oder ein SQL-Skript zur Generierung
der Datenbank erzeugt werden kann:
Reverse Engineering (4)

Kapitel 5 - 35 Schestag Synchronisationsmodul DB (Master DS)
Ein Datenbank-Dump enthält als Export aus einer relationalen Datenbank
• Schema-Informationen – als SQL DDL-Skript und (möglicherweise)
• Daten – in Form von INSERT-Anweisungen.
Die meisten Admin-Tools von RDBMS stellen eine Exportfunktion zur
Generierung eines Dumps zur Verfügung.
Zum Export und Import von großen Datenbeständen empfiehlt es sich,
UNLOAD- bzw. LOAD-Prozesse der Hersteller in proprietärem, binären
Datenformat zu nutzen.
Datenbank-Dump vs. UNLOAD & LOAD
MyDatabase Systemkatalog
zu MyDatabase
create table Auftrag (
ANR integer not null, ADAT date not null, KNR integer not null,
… ); … insert into Auftrag values (1,20.05.2013,123); …

Kapitel 5 - 36 Schestag Synchronisationsmodul DB (Master DS)
Architekturmodelle für Datenbanksysteme
• Zur Beschreibung von System-Architekturen benutzt man Referenz-
architekturen. Diese Architekturen dienen dazu, Schnittstellen zu
definieren und dann zu standardisieren.
Ein Referenzmodell ist ein idealisiertes Architekturmodell eines Systems.
Referenzmodelle können unter unterschiedlichen Aspekten entwickelt
werden:
– komponentenbasierend
– funktionsbasierend, oder
– datenbasierend.
• In diesem Abschnitt wird das ANSI / SPARC-Modell 3-Ebenen-Modell als
das wichtigste daten- und funktionsbasierende Referenzmodell für Daten-
banksysteme vorgestellt *).
*) Ein Beispiel für ein komponentenbasierendes Referenzmodell für Datenbanksysteme sind
Client/Server-Architekturen.

Kapitel 5 - 37 Schestag Synchronisationsmodul DB (Master DS)
Die drei Ebenen des ANSI / SPARC-Modells
• Von der ANSI / SPARC-Studiengruppe für DBMS*) wurde Anfang der
70er Jahre eine Drei-Ebenen-Architektur vorgeschlagen, die sich in der
Systemarchitektur eines Datenbanksystems widerspiegeln:
*) ANSI = American National Standards Institute
SPARC = Standards Planning and Requirements Committee
externes
Schema 1
konzeptionelles
Schema
internes / physisches
Schema
externes
Schema 2
externes
Schema 2 externe Ebene
Datensicht für einzelne User
konzeptionelle Ebene
Sicht auf die Gesamtheit aller Daten
interne / physische Ebene
physische Speicherstrukturen

Kapitel 5 - 38 Schestag Synchronisationsmodul DB (Master DS)
Dienste des DBMS …
… im Zusammenhang mit dem 3-Ebenen-Modell
• Das DBMS unterstützt schreibende und lesende Zugriffe der Anwender auf
die Datenbank, d.h. Update- und Retrieval-Operationen.
• Der Systemkatalog enthält als Metainformationen u. a. die Beschreibung
der erforderlichen Schemata, um die Informationen von einer Ebene zur
nächsten zu transformieren:

Kapitel 5 - 39 Schestag Synchronisationsmodul DB (Master DS)
Dienste des DBMS … (2)
Systemkatalog
(DataDicitonary,
Meta-Daten)
User Interface Anwendungsprogramm ...
Semantische Datenkontrolle
Anfrage-Optimizer
Transaktions-Manager
Recovery-Manager
Runtime Support Processor
DB
MS
User Interface Handler
Anfragebearbeitung
UserAnfragen
SystemAntworten
Daten
konzeptionelles
Schemakonzeptionelles
Schema
internes
Schemainternes
Schema
externe
Schemataexterne
Schemataexterne
Schemataexterne
Schemataexterne
Schemataexterne
Schemata

Kapitel 5 - 40 Schestag Synchronisationsmodul DB (Master DS)
Dienste des DBMS … (3)
User Interface Handler
Von der externen Ebene aus stellt der User Interface Handler die
Schnittstelle dar, die die Kommunikation eines Anwender oder einer
Applikation mit dem DBMS ermöglicht.
Die Data Sublanguage (DSL) enthält eine Sprachkomponente für die
externe Ebene, die Datenmanipulationssprache (Data Manipulation
Language – DML, mit der die Daten der Datenbank gelesen und
geschrieben werden können.
Semantische Datenkontrolle
Zusätzlich zur syntaktischen Kontrolle der DSL-Anweisung findet eine
semantische Datenkontrolle statt, die semantische Informationen zur
hinterlegten Datenstruktur überprüft, z.B. die Eindeutigkeit eines Primär-
schlüsselwertes oder die referentielle Integrität zwischen den Spalten
zweier Tabellen.

Kapitel 5 - 41 Schestag Synchronisationsmodul DB (Master DS)
Dienste des DBMS … (4)
Anfrage-Optimizer
Der Anfrage-Optimizer optimiert den Anfrageplan aufgrund der Metainfor-
mationen im konzeptionellen Schema des Systemkatalogs. Der „optimale“
Anfrageplan wird zur Ausführung an die Anfragebearbeitung weitergeleitet.
Transaktions-Manager
Der Transaktions-Manager gewährleistet den geregelten Ablauf von Trans-
aktionen und versucht dabei, die permanente Konsistenz der Datenbank
sowie die Vermeidung von Konflikten bei konkurrierenden Zugriffen auf
gleiche Daten zu gewährleisten (vgl. auch Kapitel 7).
Ein wichtiger Bestandteil des Transaktions-Managers ist der so genannte
Scheduler, der die quasiparallele Abfolge der einzelnen Datenbankopera-
tionen jeder einzelnen Transaktion ermittelt, die durch die Anfragebearbei-
tung ausgeführt werden.
Anfragebearbeitung
Die Anfragebearbeitung führt entsprechend des vom Optimizer vorgegebe-
nen Anfrageplanes die Anfrage auf die Datenbank aus.

Kapitel 5 - 42 Schestag Synchronisationsmodul DB (Master DS)
Dienste des DBMS … (5)
Recovery-Manager
Der Recovery-Manager sorgt dafür, dass für den Fall eines Systemausfalls
beim Wideranlauf des Systems in möglichst kurzer Zeit ein möglichst voll-
ständiger, konsistenter Zustand der Datenbank hergestellt wird.
Hierfür ist eine geeignete Strategie des Loggings sowie des Buffermanage-
ment für den volatilen Datenbankbuffer wichtig (vgl. auch Kapitel 7).
Runtime Support Processor
Diese Komponente ist dafür verantwortlich, dass über das Betriebssystem
die Daten vom Speichermedium gelesen oder auf das Speichermedium
geschrieben werden.
Auf dieser Ebene werden Informationen des internen Schemas benötigt.
Für diese Ebene stellt die DSL eine Datenadministrationssprache (Data
Administration Language – DAL) zur Verfügung, die sowohl eine
Komponente zur Speicherdefinition (Storage Description Language –
SDL) besitzt als auch Sprachkonstrukte für die Zugriffskontrolle und
Ablaufsteuerung (Data Control Language – DCL).

Kapitel 5 - 43 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
Systemkatalog, Reverse-Engineering und Schichtenarchitektur
• SQL – Data Manipulation Language DML *)
– Update-Operatoren: INSERT, UPDATE, DELETE
– Relationen-Algebra
– Retrieval-Operator: SELECT
– Verbundoperationen: JOIN
– Spalten- (bzw. Aggregat-) Funktionen
• Sichten: VIEW
• Rechtevergabe
*) Die Beispiele in diesem Abschnitt beziehen sich auf die „Flug-Datenbank“ (ER- und Relationen-
modell, DDL- und Insert-Skript finden Sie unter „Materialien zum Download“).

Kapitel 5 - 44 Schestag Synchronisationsmodul DB (Master DS)
Update-Operatoren: Insert (1)
SQL unterscheidet die drei Update-Opertoren für Daten:
Der Insert-Operator
• Mit Hilfe des Insert-Operators wird eine neue Zeile (Datensatz, Ausprägung,
Tupel, Instanz) in eine Tabelle eingefügt.
INSERT Datensätze einfügen datensatzorientiert
UPDATE Spalten ändern spaltenorientiert
DELETE Datensätze löschen datensatzorientiert
Syntax: INSERT INTO <Table_Name>
[(<Column_Name>,)]
VALUES (<Column_Werte>,) ;
INSERT INTO
C1 C2 C3 C4

Kapitel 5 - 45 Schestag Synchronisationsmodul DB (Master DS)
Update-Operatoren: Insert (2)
• Mit dem INSERT-Statement können in eine Tabelle eine oder mehrere Zeil-
en eingefügt werden (s.u.).
• Werden die Namen der Spalten nicht angegeben, so müssen die Werte in
der Reihenfolge der Spalten wie im CREATE-Statement der Tabelle ange-
geben werden.
• Es muss dann auch für jede Spalte ein Wert angegeben werden.
• Spalten, die beim INSERT nicht angegeben werden, erhalten den Wert
NULL, falls dies aufgrund der Table-Definition möglich ist.
• Ist für eine Spalte ein DEFAULT definiert, so kann dieser als Column-Wert
angegeben werden:
INSERT INTO ... VALUES (..., DEFAULT, ...)
• Die VALUES-Klausel kann durch ein geeignetes SELECT-Statement
(s. Retrieval-Operator SELECT) ersetzt werden:
Jede mit Hilfe eines SELECT ermittelte Menge kann auf diese Weise in eine
passende Tabelle gespeichert werden.

Kapitel 5 - 46 Schestag Synchronisationsmodul DB (Master DS)
Update-Operatoren: Insert (3)
Beispiel 1
Beispiel 2
INSERT INTO pilot
VALUES (10010001,'Boeing','B737','10.04.99',8978);
INSERT INTO abflug
(AB_DATUM, F_BEZ, HERST, TYP, SER_NR, PER_NR, AB_ZEIT)
VALUES ('13.11.09','LH-341','Boeing','B737','ba23-0012',10010001,10.23);
Die Angabe der Spaltenbezeichner
erzwingt eine Anordnung der Values in
der entsprechenden Reihenfolge.
Die fehldende Angabe der
Spaltenbezeichner erzwingt eine
Anordnung aller(!) Values in der
Reihenfolge.des create-table-Skripts.

Kapitel 5 - 47 Schestag Synchronisationsmodul DB (Master DS)
Update-Operatoren: Update (1)
Der Update-Operator
• Mit Hilfe des Update-Operators kann der Werte einer bestimmten Spalte in
einer oder mehreren Zeilen einer Tabelle geändert werden.
Syntax: UPDATE <Table_Name>
SET <Column_Name> = <Column_Wert>
[WHERE <Zusatzbedingung>] ;
UPDATE ... SET C3 =... WHERE ...
C1 C2 C3 C4

Kapitel 5 - 48 Schestag Synchronisationsmodul DB (Master DS)
Update-Operatoren: Update (2)
Der Update-Operator (Fortsetzung)
• Der <Column_Wert> kann ein beliebiger Ausdruck sein, z.B. auch ein
SELECT-Ergebnis.
• Mit dem UPDATE-Statement können in einer Tabelle eine oder mehrere
Zeilen verändert werden.
• Soll eine einzelne Zeile verändert werden, so ist der Primärschlüssel als
Filter geeignet:
Beispiel 3
• Mit einem einzigen Befehl können alle Sätze einer Tabelle verändert
werden:
Beispiel 4
• Einem UPDATE muss kein “read for update” vorangehen.
UPDATE eteil
SET e_preis = e_preis * 1.19;
UPDATE eteil
SET e_preis = 5.24
WHERE e_nr = 67891;

Kapitel 5 - 49 Schestag Synchronisationsmodul DB (Master DS)
Update-Operatoren: Delete (1)
Der Delete-Operator
• Mit Hilfe des Delete-Operators können eine bestimmte Zeile oder mehrere
Zeilen einer Tabelle gelöscht werden.
Syntax: DELETE FROM <Table_Name>
[WHERE <Column_Name> = <Column_Wert>] ;
DELETE FROM ... WHERE ...
C1 C2 C3 C4

Kapitel 5 - 50 Schestag Synchronisationsmodul DB (Master DS)
Update-Operatoren: Delete (2)
Der Delete-Operator (Fortsetzung)
• Soll eine einzelne Zeile gelöscht werden, so ist der Primärschlüssel als Filter geeignet:
Beispiel 5
• Mit einem einzigen Befehl können alle Zeilen einer Tabelle gelöscht werden.
• Nach dem Löschen aller Zeilen bleibt die Tabelle erhalten:
Beispiel 6 DELETE FROM pilot;
DELETE FROM pilot
WHERE per_nr = '10010002';
Diese Anweisung löscht alle Datensätze
der Tabelle Pilot, aber nicht die Tabelle
als Struktur!
Dies erfolgt mit DROP TABLE pilot; (s. 5-13).

Kapitel 5 - 51 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
Systemkatalog, Reverse-Engineering und Schichtenarchitektur
SQL – Data Manipulation Language DML
Update-Operatoren: INSERT, UPDATE, DELETE
– Relationen-Algebra
– Retrieval-Operator: SELECT
– Verbundoperationen: JOIN
– Spalten- (bzw. Aggregat-) Funktionen
• Sichten: VIEW
• Rechtevergabe

Kapitel 5 - 52 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (1)
• Mit der DDL – dem Sprachumfang der Data Definition Language von
SQL, werden Strukturobjekte angelegt und Metadaten zu diesen Objekten
im Systemkatalog abgelegt.
• Mit der DML – dem Sprachumfang der Data Manipulation Language von
SQL, werden die Daten selbst verwaltet:
– Daten einfügen
– Daten ändern
– Daten löschen
– Daten abfragen (lesen).
• Die Definition der Operatoren zur Abfrage von Daten basiert auf der Theorie
der Relationen-Algebra, die auf den folgenden Folien kurz vorgestellt wird:
Daten schreiben Update-Operationen

Kapitel 5 - 53 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (2)
• In der Mathematik ist eine Algebra definiert durch einen Wertebereich sowie darauf definierten Operationen.
Für Datenbankanfragen entsprechen die Relationen den Werten, Operationen dienen der Ermittlung von Anfrageergebnisse.
Anfrageoperationen sind beliebig kombinierbar und bilden eine Algebra zum „Rechnen mit Tabellen (Relationen)“ – die so genannte relationale Algebra oder auch Relationen-Algebra.
• Die Operationen der Relationen-Algebra erlauben es, Operationen auf
Relationen ausführen, die als Ergebnis wiederum Relationen darstellen.
Auf Basis der formalen Sprache der Relationen-Algebra wurde SQL als DSL für relationale DBMS definiert.

Kapitel 5 - 54 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (3)
Operationen der Relationen-Algebra
• Spalten heraussuchen: Projektion
• Zeilen heraussuchen: Selektion
• Tabellen verknüpfen: Verbund (Join)
• Tabellen vereinigen: Vereinigung U
• Tabellen voneinander abziehen: Differenz −
• Spalten umbenennen: Umbenennung β
(wichtig für , U, −)

Kapitel 5 - 55 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (4)
Operationen der Relationen-Algebra
• Spalten heraussuchen: Projektion
Auswahl von Spalten durch Angabe einer Attributliste
Syntax:
Definition: A(R ) := { t(A) | t R } mit Attributmenge A R
Achtung: Die Projektion entfernt Duplikate (Mengensemantik):
• Beispiele: PNR, ANR(PERSON) ANR(PERSON)
Attributmenge(Relation)
PNR ANR
406 K55
123 K51
829 K53
574 K55
ANR
K55
K51
K53

Kapitel 5 - 56 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (5)
Operationen der Relationen-Algebra
• Zeilen heraussuchen: Selektion
Auswahl von Zeilen einer Tabelle anhand eines Selektionsprädikats
Syntax:
• Beispiel: ANR=‘K55‘(PERSON)
Bedingung(Relation)
PERSON: PNR NAME ALTER GEHALT ANR
406 Coy 47 50700 K55
123 Müller 32 43500 K51
829 Schmid 36 45200 K53
574 Abel 28 36000 K55
ERGEBNIS: PNR NAME ALTER GEHALT ANR
406 Coy 47 50700 K55
574 Abel 28 36000 K55

Kapitel 5 - 57 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (6)
Operationen der Relationen-Algebra
• Kartesisches Produkt: K = R x S
Zusammenfügen von Zeilen unterschiedlicher Tabellen
Syntax:
K = R x S := { k | x R, y S: (k = <x1, x2, …, yr, y1, y2, …, ys>) }
ABT x PERSON: ANR ANAME AORT PNR NAME ALTER GEHALT ANR'
K51 Planung Darmstadt 406 Coy 47 50700 K55
K51 Planung Darmstadt 123 Müller 32 43500 K51
K51 Planung Darmstadt 829 Schmid 36 45200 K53
K51 Planung Darmstadt 574 Abel 28 36000 K55
K53 Einkauf Frankfurt 406 Coy 47 50700 K55
K53 Einkauf Frankfurt 123 Müller 32 43500 K51
K53 Einkauf Frankfurt 829 Schmid 36 45200 K53
K53 Einkauf Frankfurt 574 Abel 28 36000 K55
K55 Vertrieb Frankfurt 406 Coy 47 50700 K55
K55 Vertrieb Frankfurt 123 Müller 32 43500 K51
… … … … … … … …

Kapitel 5 - 58 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (7)
Operationen der Relationen-Algebra
• Tabellen verknüpfen: Verbund (Join)
Zusammenfügen von Zeilen unterschiedlicher Tabellen
• Ein Verbund ist ein kartesisches Produkt zwischen zwei Relationen R und
S, eingeschränkt durch eine -Beziehung zwischen Attribut A von R und
Attribut B von S mit {<, =, >, ≤, ≠, ≥ }
Syntax:
• Wichtigster Spezialfall: = ‘=‘ (Gleichverbund – Equi Join)
• Beispiel: ABT PERSON
R S = AB(RxS)
ABTxPERSON: ANR ANAME AORT PNR NAME ALTER GEHALT ANR'
K51 Planung Darmstadt 123 Müller 32 43500 K51
K53 Einkauf Frankfurt 829 Schmid 36 45200 K53
K55 Vertrieb Frankfurt 406 Coy 47 50700 K55
K55 Vertrieb Frankfurt 574 Abel 28 36000 K55
ANR=ANR

Kapitel 5 - 59 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (8)
Operationen der Relationen-Algebra
• Gleichverbund (Fortsetzung)
Verlustbehafteter Gleichverbund
– wenn Tupel in ABT oder PERS keinen Verbundpartner finden (dangling
tuples), z.B. (K56, Finanzen, München)
Verlustfreier Gleichverbund (losless join)
– Ein Gleichverbund zwischen R und S heißt verlustfrei, wenn alle Tupel
von R und S am Verbund teilnehmen.
• Natürlicher Verbund (Natural Join)
Ein natürlicher Verbund ist ein Gleichverbund über alle gleichen Attribute
und Projektion über die verschiedenen Attribute.
• Syntax:
R S

Kapitel 5 - 60 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (9)
Operationen der Relationen-Algebra
• Natürlicher Verbund (Fortsetzung)
• Beispiel:
ABT PERSON
= ANR, ANAME, AORT, PNR, NAME, ALTER, GEHALT(ANR=ANR(ABT x PERSON)) :
ABT x PERSON: ANR ANAME AORT PNR NAME ALTER GEHALT
K51 Planung Darmstadt 123 Müller 32 43500
K53 Einkauf Frankfurt 829 Schmid 36 45200
K55 Vertrieb Frankfurt 406 Coy 47 50700
K55 Vertrieb Frankfurt 574 Abel 28 36000

Kapitel 5 - 61 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (10)
Operationen der Relationen-Algebra
• Verbundvarianten
Ziel: Verlustfreier Verbund soll erzwungen werden
Übernahme von „dangling tuples“ in das Ergebnis und Auffüllen mit
Nullwerten
• voller äußerer Verbund (full outer join) übernimmt alle Tupel beider
Operanden
R S
• linker äußerer Verbund (left outer join) übernimmt alle Tupel des linken
Operanden
R S
• rechter äußerer Verbund (right outer join) übernimmt alle Tupel des
rechten Operanden
R S

Kapitel 5 - 62 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (11)
Operationen der Relationen-Algebra
• Verbundvarianten – Beispiele
LINKS RECHTS
A B
1 2
2 3
B C D
3 4 x
4 5 y
A B C D
2 3 4 x
A B C D
2 3 4 x
4 5 y
A B C D
1 2
2 3 4 x
A B C D
1 2
2 3 4 x
4 5 y

Kapitel 5 - 63 Schestag Synchronisationsmodul DB (Master DS)
Relationen-Algebra (12)
Mengenoperationen der Relationen-Algebra • Vereinigung
Eine Vereinigung sammelt die Tupelmengen zweier Relationen unter einem
gemeinsamen Schema auf.
Die Attributmengen beider Relationen müssen identisch (bzw.
vereinigungsverträglich) sein – dies gilt für alle nachfolgenden
Mengenoperationen.
Syntax:
• Differenz
Eine Differenz eliminiert die Tupel aus der ersten Relation, die auch in der
zweiten Relation vorkommen.
Syntax:
• Durchschnitt
Ein Durchschnitt liefert die Tupel, die in beiden Relationen gemeinsam
vorkommen.
Syntax:
R U S := { t | t R v t S }
R - S := { t | t R Λ t S }
R ∩ S := { t | t R Λ t S }

Kapitel 5 - 64 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
Systemkatalog, Reverse-Engineering und Schichtenarchitektur
SQL – Data Manipulation Language DML
Update-Operatoren: INSERT, UPDATE, DELETE
Relationen-Algebra
– Retrieval-Operator: SELECT
– Verbundoperationen: JOIN
– Spalten- (bzw. Aggregat-) Funktionen
• Sichten: VIEW
• Rechtevergabe

Kapitel 5 - 65 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (1)
Der Select-Operator
• Mit Hilfe des Select-Operators können Informationen aus der Datenbank
ausgelesen werden.
• Ein SELECT-Ausdruck besteht neben dem SELECT-Operator aus
mehreren Klauseln:
FROM ..., WHERE ..., GROUP BY ..., HAVING ..., ORDER BY ... .
Die letzten vier Klauseln sind optional.
Das Ergebnis jeder SELECT-Operation
ist wieder eine Tabelle (Relation).

Kapitel 5 - 66 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (2)
Der Select-Operator (Fortsetzung)
Syntax: SELECT [ALL | DISTINCT] <Column_Elemente,>
FROM <Table_Name,> ;
SELECT C1, C2, C3 FROM ...;
C1 C2 C3 C4
C1 C2 C3

Kapitel 5 - 67 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (3)
Der Select-Operator (Fortsetzung)
• Die Liste der Column_Elemente darf nicht leer sein.
• Sollen alle Spalten einer Tabelle selektiert werden, so kann * als Platz-
halter verwendet werden.
• Für das Auflisten der Column_Elemente gibt es keine vordefinierte Ordnung
der Spalten oder Zeilen, es sei denn, man benutzt die ORDER-Klausel, s.u.
• Beispiel 7:
• Die Option DISTINCT bewirkt, dass doppelte Zeilen aus der Ergebnis-
tabelle eliminiert werden (interner Aufwand?), die Option ALL bewirkt, dass
doppelte Zeilen in der Ergebnistabelle auch doppelt angezeigt werden.
• Ist weder ALL noch DISTINCT explizit angegeben, so wird ALL als default
angenommen.
SELECT * FROM angestellter; per_nr name adr beruf gehalt ... ... ... ... ...

Kapitel 5 - 68 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (4)
Der Select-Operator (Fortsetzung)
• Die Liste der Table_Namen darf nicht leer sein. Referenziert die Tabellen-
liste die Tabellen A, B und C, so berücksichtigt das Selektionsergebnis
zunächst das kartesische Produkt A x B x C der drei Tabellen.
• Die Ergebnistabelle enthält dann alle Spalten aus A, B und C.
• Jede Zeile der einen Tabelle wird mit allen Zeilen der anderen Tabelle
angelistet.
SELECT * FROM A, B ;
ist semantisch äquivalent zu
SELECT * FROM A CROSS JOIN B ;
• Beispiel 8:
SELECT * FROM maschine, flugzeug;
herst typ km_h sitze herst typ ser_nr f_std an_datum ... ... ... ... ... ... ... ... ...

Kapitel 5 - 69 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (5)
Der Select-Operator (Fortsetzung)
• Die Auswahl bestimmter Zeilen einer Tabelle nennt
man Selektion.
• Die Auswahl bestimmter Spalten einer Tabelle
nennt man Projektion.
• Spaltennamen können qualifiziert bzw. umbenannt werden (z.B. Bezeichner
in anderer Sprache):
SELECT <Column_Name/Wert> AS <Column_Name_neu> ...
• Beispiel 9:
C1 C2 C3 C4
C1 C2 C3 C4
select name, gehalt as salary
from angestellter;
name salary ... ...

Kapitel 5 - 70 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (6)
Die ORDER BY – Klausel
• Mit der ORDER BY – Klausel kann die Ergebnistabelle einer SELECT-
Operation nach den Werten einer (oder mehrerer) Spalten aufsteigend oder
absteigend sortiert werden.
• Nur mit Hilfe der Klausel ORDER BY ist sichergestellt, dass die Daten in
der gewünschten Reihenfolge angelistet werden.
• Die Optionen ASC (ascending = aufsteigend) bzw. DESC (descending =
absteigend) ermöglichen das Sortieren in unterschiedlichen Reihenfolgen;
der default ist ASC.
• Das (geschachtelte) Sortieren nach mehreren Spalten ist möglich.
• Die Identifizierung der Spalte, nach der sortiert werden soll, ist möglich
durch eine Zahl, die die absolute Position der Spalte in der Ergebnistabelle
darstellt: die Zahl referenziert das Column-Element der Ergebnistabelle:
Syntax: SELECT <Column_Element,>
FROM <Table_Name,>
ORDER BY <Column_Element [ASC | DESC],>

Kapitel 5 - 71 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (7)
Die ORDER BY-Klausel (Fortsetzung)
• Beispiel 10:
Die WHERE - Klausel
• Mit der WHERE-Klausel kann auf den zugrunde liegenden Tabellen der
SELECT-Operation ein Filter definiert werden.
SELECT name, adr, beruf, gehalt FROM angestellter ORDER BY beruf, gehalt;
SELECT name, adr, beruf, gehalt FROM angestellter ORDER BY 3, 4;
Syntax: SELECT <Column_Element,>
FROM <Table_Name,>
WHERE <logische Bedingung(en)>

Kapitel 5 - 72 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (8)
Die WHERE-Klausel (Fortsetzung)
• Die Bedingungen, die der WHERE-Klausel folgen, werden mit den
üblichen Operatoren und mit Hilfe von Klammern gebildet : AND, NOT,
OR, >, >=, <, <=, (, ) .
• Die Ergebnistabelle enthält nur Zeilen, für die der Wahrheitswert TRUE
ermittelt wird. NULL-Elemente können nicht logisch zugeordnet werden
In SQL gibt es drei Wahrheitswerte: TRUE, FALSE und UNKNOWN.
Beispiel 11:
Beispiel 12:
SELECT name, adr, per_nr
FROM angestellter
WHERE beruf='Pilot';
SELECT typ, ser_nr, f_std
FROM flugzeug
WHERE (typ = 'A330' OR typ = 'B777')
AND f_std < 6000;

Kapitel 5 - 73 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (9)
SELECT mit arithmetischen Ausdrücken
• Als arithmetische Operatoren mit Klammern “(” bzw. “)” stehen zur
Verfügung:
+, –, *, / . Die Bildung der Potenz ist nicht möglich.
• Hat einer der Operanden einen unbekannten Wert (= NULL), dann ist auch
das Ergebnis der arithmetischen Operation unbekannt.
Beispiel 13:
SELECT per_nr AS PersonalNr, gehalt AS "altes Gehalt", gehalt * 1.05 AS "neues Gehalt" FROM angestellter;
PersonalNr altes Gehalt neues Gehalt
... ... ...

Kapitel 5 - 74 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (10)
SELECT ... WHERE ... BETWEEN ...
• BETWEEN entspricht größer / gleich und kleiner / gleich.
• Es können auch char-Variablen sortiert werden, z.B. beruf between 'a' and
'b' zeigt alle Datensätze mit Berufen an, die mit 'a' anfangen und den Beruf
'b' (aber nicht mehr den Datensatz mit Beruf 'bb' !)
• Die Sortierung hängt vom maschinensprachlichen characterset ab:
– EBCDIC: Zahlen > Buchstaben
Extended binary coded decimal interchange code
– ASCII: Zahlen < Buchstaben
• Beispiel 14:
SELECT ab_datum,f_bez
FROM abflug
WHERE ab_datum BETWEEN '14.05.01' AND '30.06.01';

Kapitel 5 - 75 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (11)
SELECT ... WHERE ... IN ...
• Mit dieser Klausel kann die Übereinstimmung eines Spaltenwertes mit einer
vorgegebenen Menge von Werten als Filter geprüft werden.
Beispiel 15:
SELECT ... WHERE ... LIKE ...
• LIKE ist einsetzbar für CHAR und VARCHAR. Beispiel 16:
• “%”: beliebige Anzahl von Zeichen; die Anzahl
kann auch null sein, z.B. beruf like '%Ing%'
• “_”: ein einzelnes Zeichen.
ist äquivalent zu
SELECT ab_datum,f_bez
FROM abflug
WHERE ab_datum IN ('13.05.01','14.05.01');
SELECT f_bez, ab_datum
FROM abflug
WHERE ab_datum = '13.05.01'
OR ab_datum = '14.05.01';
SELECT per_nr, name
FROM angestellter
WHERE name LIKE 'M%';

Kapitel 5 - 76 Schestag Synchronisationsmodul DB (Master DS)
Der Retrieval-Operator Select (12)
Der SUBSTRING-Operator hat die folgende Syntax:
• Die Verknüpfung (Concatination) von varchar-Variablen ist möglich durch
den || – Operator.
Beispiel 17:
SELECT ... WHERE ... IS NULL ...
• Der Spaltenwert NULL kann für Null-fähige Spalten abgefragt werden mit
Hilfe der Bedingung ... IS NULL ... (und nicht … = NULL …, da der NULL-
Wert typen-unabhängig ist).
• Entsprechend der Ausprägung von null-fähigen Spalten können Bedingun-
gen außer den boolschen Konstanten TRUE (T) und FALSE (F) auch noch
den boolschen Wert UNKNOWN (U) haben.
SUBSTRING ( [VAR]CHAR-Column, <ab Position>, <Länge>) = ' .... '
SELECT per_nr, name
FROM angestellter
WHERE SUBSTR(name,1,1) = 'M';

Kapitel 5 - 77 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
Systemkatalog, Reverse-Engineering und Schichtenarchitektur
SQL – Data Manipulation Language DML
Update-Operatoren: INSERT, UPDATE, DELETE
Relationen-Algebra
Retrieval-Operator: SELECT
– Verbundoperationen: JOIN
– Spalten- (bzw. Aggregat-) Funktionen
• Sichten: VIEW
• Rechtevergabe

Kapitel 5 - 78 Schestag Synchronisationsmodul DB (Master DS)
JOIN-Ausdrücke
• Ein SELECT über mehrere Tabellen erfolgt über die Referenzierung ent-
sprechender Spalten und erfordert eine Zuordnung derjenigen Datensätze,
deren Primär- und Fremdschlüsselspalten die gleichen Werte haben:
SELECT a.per_nr, a.name, p.p_std
FROM angestellter a, pilot p
WHERE a.per_nr = p.per_nr;
Syntax: SELECT <Column_ Elemente,> FROM <TAB1>, <TAB2>
WHERE <TAB1>.<PK1> = <TAB2>.<PK1> ;
referenzierende Relat ionship
Tab1
Primary Key 1
Tab2
Primary Key 2PK1 = PK1
TAB1
PK1 INTEGER
TAB2
PK2 CHAR(6)
PK1 INTEGER
Im ER-Modell sind dies
referenzierende Relationships,
im Relationenmodell Fremd- & Primär-
schlüsselspalten gleichen Wertes
PER_NR = PER_NR
ANGESTELLTER
PER_NR NUMBER(8)
NAME CHAR(15)
ADR CHAR(20)
BERUF CHAR(25)
GEHALT NUMBER(8,2)
PILOT
PER_NR NUMBER(8)
HERST CHAR(15)
TYP CHAR(10)
LIZ CHAR(15)
P_STD INTEGER

Kapitel 5 - 79 Schestag Synchronisationsmodul DB (Master DS)
JOIN-Ausdrücke – Inner Joins
• Die Ergebnistabelle eines JOINs entsteht durch
Auswahl bestimmter Spalten und Zeilen des karte-
sischen Produkts der beteiligten Tabellen.
• I. d. R. erfolgt der JOIN über Primärschlüssel- und
Fremdschlüsselspalten.
• Ein JOIN ist aber auch über beliebige Spalten mög-
lich, sofern es semantisch sinnvoll ist und die Daten-
typen der JOIN-Spalten kompatibel sind.
• Äquivalente Formulierungen zur Syntax der
vorhergehenden Folie sind:
TAB1 JOIN TAB2 ON WHERE-Bedingung
TAB1 JOIN TAB2 USING (gemeinsame Spalte),
dies setzt natürlich voraus, dass die JOIN-
Spalten bei beiden Tabellen gleich heißen.
TAB1 NATURAL JOIN TAB2
Weitere Join-Typen, auch Outer Joins
vgl. Beispielskripts in SQL_Kapitel5.sql
PER_NR = PER_NR
PER_NR = PER_NR
F_BEZ = F_BEZ
ANGESTELLTER
PER_NR NUMBER(8)
NAME CHAR(15)
ADR CHAR(20)
BERUF CHAR(25)
GEHALT NUMBER(8,2)
PILOT
PER_NR NUMBER(8)
HERST CHAR(15)
TYP CHAR(10)
LIZ CHAR(15)
P_STD INTEGER
ABFLUG
F_BEZ CHAR(15)
AB_DATUM DATE
PER_NR NUMBER(8)
HERST CHAR(15)
TYP CHAR(10)
SER_NR CHAR(15)
AB_ZEIT NUMBER(4,2)
FLUG
F_BEZ CHAR(15)
S_ORT CHAR(15)
Z_ORT CHAR(15)
ZEIT NUMBER(5,2)
KM INTEGER
Kapitel 5 - 80 Schestag Synchronisationsmodul DB (Master DS)
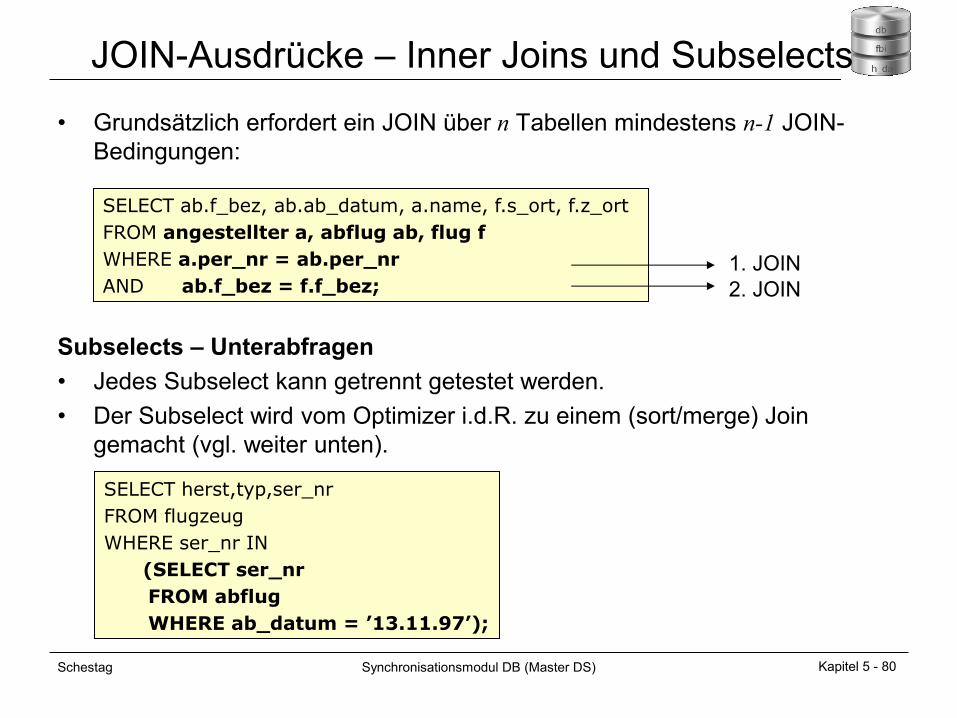
JOIN-Ausdrücke – Inner Joins und Subselects
• Grundsätzlich erfordert ein JOIN über n Tabellen mindestens n-1 JOIN-
Bedingungen:
Subselects – Unterabfragen
• Jedes Subselect kann getrennt getestet werden.
• Der Subselect wird vom Optimizer i.d.R. zu einem (sort/merge) Join
gemacht (vgl. weiter unten).
SELECT ab.f_bez, ab.ab_datum, a.name, f.s_ort, f.z_ort
FROM angestellter a, abflug ab, flug f
WHERE a.per_nr = ab.per_nr
AND ab.f_bez = f.f_bez; 1. JOIN
2. JOIN
SELECT herst,typ,ser_nr
FROM flugzeug
WHERE ser_nr IN
(SELECT ser_nr
FROM abflug
WHERE ab_datum = ’13.11.97’);

Kapitel 5 - 81 Schestag Synchronisationsmodul DB (Master DS)
JOIN-Ausdrücke – Inner Joins und Subselects
Subselects (Fortsetzung)
• In Subselects können über die Spaltenfunktionen auch Vergleichswerte
herangezogen werden, allerdings nur dann, wenn der Subselect eine
1-spaltige Ergebnisrelation ermittelt.
• Innerhalb einer SELECT-Anweisung können beliebig viele Subselects ver- wendet werden.
SELECT per_nr,name
FROM angestellter
WHERE per_nr IN
(SELECT per_nr
FROM abflug
WHERE f_bez IN
(SELECT f_bez
FROM flug
WHERE start ='Luxemburg'));

Kapitel 5 - 82 Schestag Synchronisationsmodul DB (Master DS)
JOIN-Strategien eines Optimizers (1)
• Die drei unten aufgeführten Join-Strategien *) sollen exemplarisch anhand der folgenden SQL-Abfrage erklärt werden:
Verschachtelter Loop-Join (Nested Loop)
*) vergleiche hierzu auch Praktikum 2, Teil II
select * from b, c where c.x=b.w
and c.z=17;
erste Tabelle zweite Tabelle
Tabelle C z x
17 cc
17 aa
18 ee
17 ff
Tabelle B w y
aa 2
cc 3
ff 1
resultierendes Tupel
z x w y
17 cc cc 3
17 aa aa 2
17 ff ff 1

Kapitel 5 - 83 Schestag Synchronisationsmodul DB (Master DS)
JOIN-Strategien eines Optimizers (2)
Sort/Merge-Join
Sort+Filter
Tabelle C z x
17 aa
17 cc
17 ff
sortierte
Tabelle B w y
aa 2
cc 3
ff 1
Tupel aus C und B
z x w y
17 aa aa 2
17 cc cc 3
17 ff ff 1

Kapitel 5 - 84 Schestag Synchronisationsmodul DB (Master DS)
JOIN-Strategien eines Optimizers (3)
Hash-Join
Zeilen-
Header
Zeilen
Tabelle 2
Tabelle 1
1. Tabelle 2 wird gelesen
und in einer Hash-Tabel-
le abgelegt.
1. Tabelle 2 wird gelesen
und in einer Hash-Tabel-
le abgelegt.
2. Werte von Tabelle 1 werden
in der Hash-Tabelle gesucht.
2. Werte von Tabelle 1 werden
in der Hash-Tabelle gesucht.
Was nicht in den Speicher
passt, wird auf Platte aus-
gelagert.
Platten-
bereich

Kapitel 5 - 85 Schestag Synchronisationsmodul DB (Master DS)
Optimizer-Strategien und Explain
Welche „Freiheitsgrade“ hat der Optimizer bei der Festlegung des
Ausführungsplans?
select * from a, b where a.pka=b.pka;
a pka c1 c2
b pkb pka c3
a.pka=b.pka pka c1 c2 pkb pka c3 --------------------- 1 A x 5 1 z 2 B w 8 2 t 3 M s 7 3 z
? Welches ist der
günstigste
Ausführungsplan

Kapitel 5 - 86 Schestag Synchronisationsmodul DB (Master DS)
Optimizer-Strategien und Explain
• Die Strategie des Optimizers wird beeinflusst durch
– geschätzte Kosten,
– geschätzte Anzahl der Ausgabezeilen,
– Notwendigkeit für temporäre Dateien,
– Verwendung von Indexen, Verwendung von Hash-Joins,
– Möglichkeit des parallelen Scans auf fragmentierten Tabellen,
– erforderliche Zugriffe auf remote-Datenquellen, etc.
Der Optimizer eines DBMS wählt aus verschiedenen möglichen Ausfüh-rungsplänen zur Bearbeitung einer SQL-Anfrage den „kostengünstigsten“ *) Ausführungsplan aus.
*) Eine Vertiefung dieser Thematik ist u.a. Inhalt der Vorlesung „Architektur von Daten- banksystemen“ (41.4814 ) aus dem Master-Studiengang.

Kapitel 5 - 87 Schestag Synchronisationsmodul DB (Master DS)
Optimizer-Strategien und Explain
• Um das Verhalten des Optimizers zu beobachten, kann der vom Optimizer
ausgewählte Ausführungsplan pro SQL-Anfrage angezeigt und so das
Performanceverhalten analysiert werden.
• Hierfür stellen DBMS die Möglichkeit zur Verfügung, über eine EXPLAIN-
Funktionalität den Ausführungsplan textuell oder grafisch – als
„Operatorbaum“ – anzeigen zu lassen, ohne dass die Anfrage tatsächlich
ausgeführt wird.
• Die Strategie des Optimizers kann vom DBA durch die interne
Datenorganisation und andere Parameter beeinflusst werden.
Kapitel 5 - 88 Schestag Synchronisationsmodul DB (Master DS)
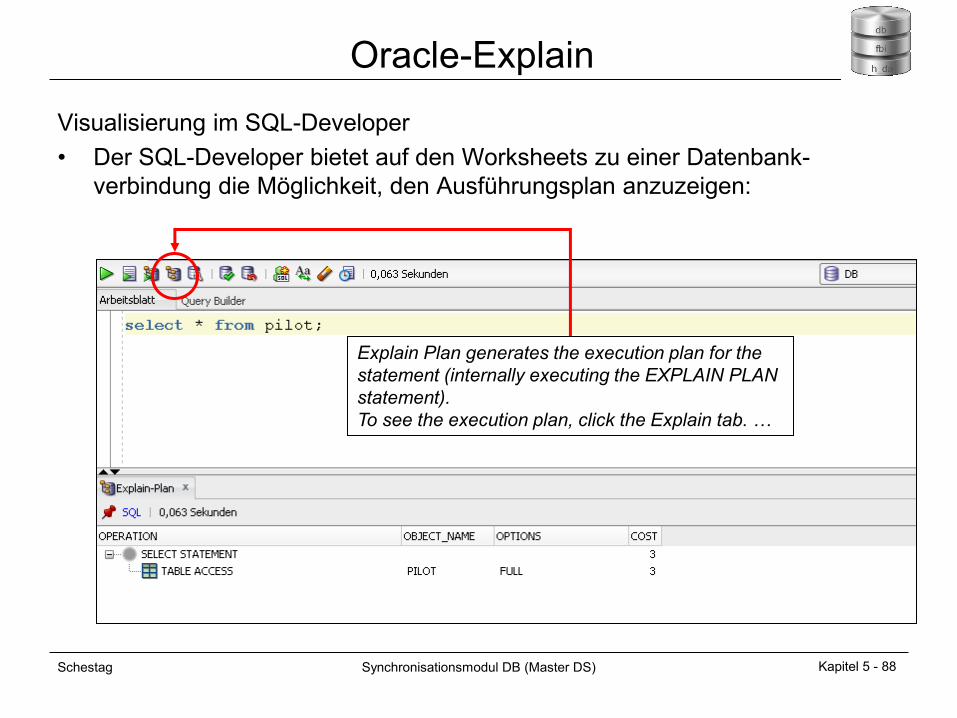
Oracle-Explain
Visualisierung im SQL-Developer
• Der SQL-Developer bietet auf den Worksheets zu einer Datenbank-
verbindung die Möglichkeit, den Ausführungsplan anzuzeigen:
Explain Plan generates the execution plan for the
statement (internally executing the EXPLAIN PLAN
statement).
To see the execution plan, click the Explain tab. …

Kapitel 5 - 89 Schestag Synchronisationsmodul DB (Master DS)
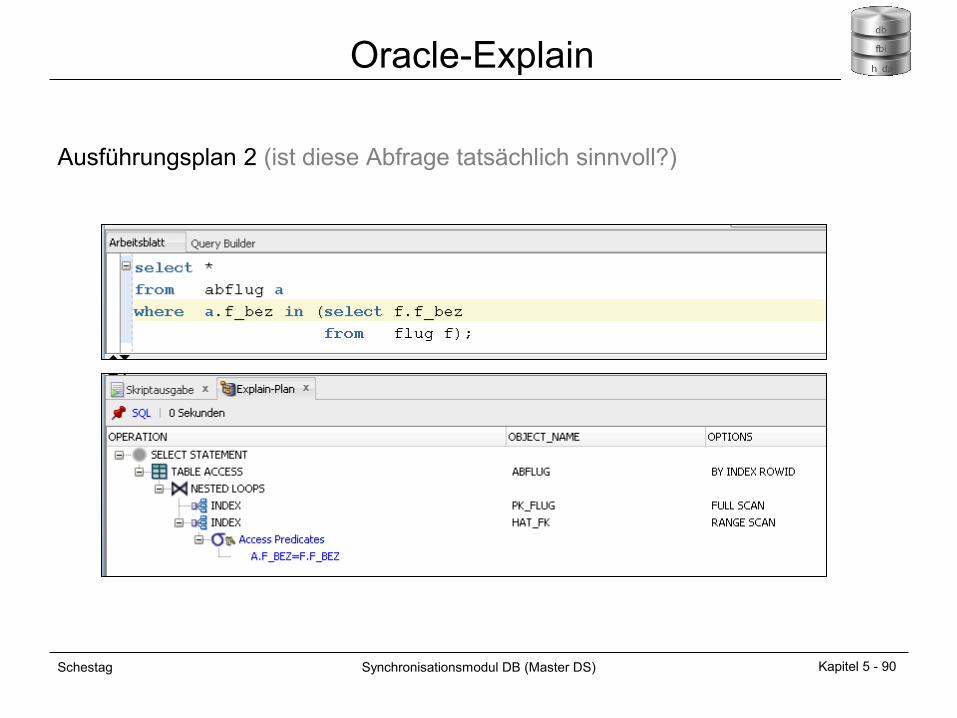
Oracle-Explain
Welche Strategien des Optimizers können Sie den Ausführungsplänen auf
den folgenden Folien entnehmen?
Ausführungsplan 1
Kapitel 5 - 90 Schestag Synchronisationsmodul DB (Master DS)
Oracle-Explain
Ausführungsplan 2 (ist diese Abfrage tatsächlich sinnvoll?)

Kapitel 5 - 91 Schestag Synchronisationsmodul DB (Master DS)
Oracle-Explain
Ausführungsplan 3

Kapitel 5 - 92 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
Systemkatalog, Reverse-Engineering und Schichtenarchitektur
SQL – Data Manipulation Language DML
Update-Operatoren: INSERT, UPDATE, DELETE
Relationen-Algebra
Retrieval-Operator: SELECT
Verbundoperationen: JOIN
– Spalten- (bzw. Aggregat-) Funktionen
• Sichten: VIEW
• Rechtevergabe

Kapitel 5 - 93 Schestag Synchronisationsmodul DB (Master DS)
Die Spaltenfunktionen (1)
• SQL bietet die Möglichkeit, auf Spalten von (Ergebnis-)Tabellen oder
Zeilengruppen solcher Tabellen spezielle Funktionen anzuwenden:
• Solche Funktionen nennt man Spalten- oder auch Aggregatfunktionen,
da sie auf Spalten angewandt werden können bzw. aggregierte Informati-
onen zu einem Spaltenwert berechnen können.
• Alle aufgeführten Spaltenfunktionen berücksichtigen keine NULL-Werte!
COUNT(Spalte) Anzahl von Werten einer Spalte (Zeilenanzahl)
SUM(Spalte) Summe der Werte einer Spalte
(nur für numerische Argumente)
AVG(Spalte) Durchschnitt der Werte einer Spalte
(nur für numerische Argumente)
MIN(Spalte) kleinster Wert aller Werte einer Spalte
MAX(Spalte) größter Wert aller Werte einer Spalte

Kapitel 5 - 94 Schestag Synchronisationsmodul DB (Master DS)
Die Spaltenfunktionen (2)
• Die Spaltenfunktion COUNT( ) ist die einzige, die als Argument * zulässt,
da sie die Anzahl der Zeilen ermittelt und dieser Wert nicht von einer
bestimmten Spalte abhängig ist.
• Hat das Argument einen expliziten Spaltennamen, so werden die Einträge
ungleich NULL in dieser Spalte gezählt.
• Sollen nur Zeilen unterschiedlichen Inhalts gezählt werden, so erreicht man
dies durch Einfügen des Schlüsselwortes DISTINCT im Argument.
• Alle anderen Spaltenfunktionen müssen als Argument einen Spaltennamen
der entsprechenden Tabelle erhalten.
• Spalten, die durch die Anwendung von Spaltenfunktionen neu entstehen,
sollte man mit Hilfe der AS-Klausel einen sinnvollen Namen geben:
SELECT COUNT(*) as Anzahl
FROM flug;
SELECT COUNT(DISTINCT z_ort)
FROM flug;
SELECT COUNT(*) as Anzahl
FROM maschine
WHERE sitze > 230;
SELECT SUM(e_preis) as Summe
FROM eteil;

Kapitel 5 - 95 Schestag Synchronisationsmodul DB (Master DS)
Die Spaltenfunktionen (3)
• Zur Erstellung von Listen / Reports ist es oft wünschenswert, Ergebnis-
tabellen einer Select-Anfrage nach bestimmten Spaltenwerten zeilenweise
zu gruppieren.
Die GROUP BY- Klausel unterstützt die zeilenweise Gruppierung von
Tabellen. Diese Klausel findet häufig Anwendung im Zusammenhang mit
Spaltenfunktionen, da (aggregierte) Informationen über Gruppen von Zeilen
und nicht über jede einzelne Ausprägung der Gruppe erwünscht sind.
Beispiel 18
Man interessiert sich für das durchschnittliche Gehalt in jeder Berufsgruppe
einer Organisation.
• Intern erfolgt zunächst immer ein SORT nach der Spalte, nach der gruppiert
wird (im Beispiel ist dies die Spalte beruf). Es ist wichtig, sich dessen
bewusst zu sein, da ein SORT immer mit erheblichen Aufwänden
verbunden ist (Performance!).

Kapitel 5 - 96 Schestag Synchronisationsmodul DB (Master DS)
Die Spaltenfunktionen (4)
• Nun wird die angegebene Spaltenfunktion auf alle Zeilen angewandt, die
bzgl. der Gruppierungsspalte den gleichen Wert haben, d.h. solange, bis in
der entsprechenden Spalte ein so genannter Gruppenwechsel eintritt.
SELECT beruf, AVG(gehalt)as average
FROM angestellter
GROUP BY beruf
ORDER BY 2 DESC;

Kapitel 5 - 97 Schestag Synchronisationsmodul DB (Master DS)
Die Spaltenfunktionen (5)
Weitere Besonderheiten bei Anwendung der GROUP BY-Klausel:
• Alle Column-Elemente nach SELECT müssen mit Spaltenfunktionen er-
mittelt werden, mit Ausnahme der GROUP BY-Spalte (die aus semanti-
schen Gründen immer in der Ergebnistabelle enthalten sein sollte).
• Die GROUP BY-Klausel kann um eine HAVING-Klausel erweitert werden,
die aus den ermittelten Gruppen bestimmte Gruppen herausfiltert:
Mit HAVING können Gruppen ausgewählt werden.
• GROUP BY ... HAVING steht immer ganz am Ende eines (Sub-)
SELECTS (ggf. gefolgt von einer ORDER BY-Anweisung).

Kapitel 5 - 98 Schestag Synchronisationsmodul DB (Master DS)
Die Spaltenfunktionen (6)
• In einer SELECT-Anweisung können sowohl WHERE- als auch HAVING-
Klauseln vorkommen:
• SQL unterstützt nur einstufige Gruppenwechsel.
• Mehrstufige Gruppenwechsel werden ggf. von Reportgeneratoren
unterstützt.
WHERE auf Zeilenebene entspricht HAVING auf Gruppenebene
filtert VOR dem Gruppieren filtert NACH dem Gruppieren
SELECT beruf, AVG(gehalt)as average
FROM angestellter
WHERE adr = "Kaiserslautern"
GROUP BY beruf
HAVING AVG(gehalt) > 5000.0;
filtert alle Angestellten aus „Kaiserslautern“
vor dem internen SORT und GROUP BY.
filtert alle Berufsgruppen mit AVG(gehalt) > 5000
nach dem internen SORT und GROUP BY.

Kapitel 5 - 99 Schestag Synchronisationsmodul DB (Master DS)
Vorkenntnisse: Ergebnisse des Eingangstests* 1
Fragen und Antworten aus dem Bereich „SQL – Structured Query Language“
1. Wie lautet die SQL-Anweisung, mit der man aus einer Tabelle
„Kunde“ alle Datensätze mit allen Spalten ausliest? (9/11)
richtig falsch im Prinzip richtig, aber …
SELECT * FROM Kunde; (8 mal) – nicht case-sensitiv! x
SQL SELECT t1.Kunde FROM Data1 as t1 x
* insgesamt 11 Teilnehmer
2. Wie lautet die SQL-Anweisung, mit der man den maixmalen Wert der Spalte „Gehalt“ in einer Tabelle „Mitarbeiter“ ausliest? (9/11)
richtig falsch im Prinzip richtig, aber …
SELECT Max(Gehalt) FROM Mitarbeiter; (3 mal – ähnlich) x
select max Gehalt from Mitarbeiter (2 mal) x
SELECT TABLE Max Gehalt FROM Mitarbeiter x
SELECT ″Gehalt″ FROM ″Mitarbeiter″ WHERE ″Gehalt″ = MAX (3mal – so ähnlich)
x

Kapitel 5 - 100 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
Systemkatalog, Reverse-Engineering und Schichtenarchitektur
SQL – Data Manipulation Language DML
Update-Operatoren: INSERT, UPDATE, DELETE
Relationen-Algebra
Retrieval-Operator: SELECT
Verbundoperationen: JOIN
Spalten- (bzw. Aggregat-) Funktionen
• Sichten: VIEW
• Rechtevergabe

Kapitel 5 - 101 Schestag Synchronisationsmodul DB (Master DS)
VIEW – Sichten
• Eine VIEW ist eine virtuelle Tabelle, die sich bzgl. der DML-Operationen
für die Benutzer wie eine normale Tabelle verhält.
• Eine VIEW ist aber kein eigenständiges Objekt, sondern wird immer
dynamisch aus den Spalten anderer Tabellen oder Views abgeleitet. Eine
VIEW ist ein dynamisches Fenster, das als “Maske” nur einen Ausschnitt
der Datenbank zeigt.
ETEIL (TABLE) VBRUTTO (VIEW)
NR BEZ BRUTTO E_NR HERST TYP E_BEZ E_PREIS E_MNG
* 1.19 VBR (VIEW)
Bezeichnung Bruttopreis
Kapitel 5 - 102 Schestag Synchronisationsmodul DB (Master DS)
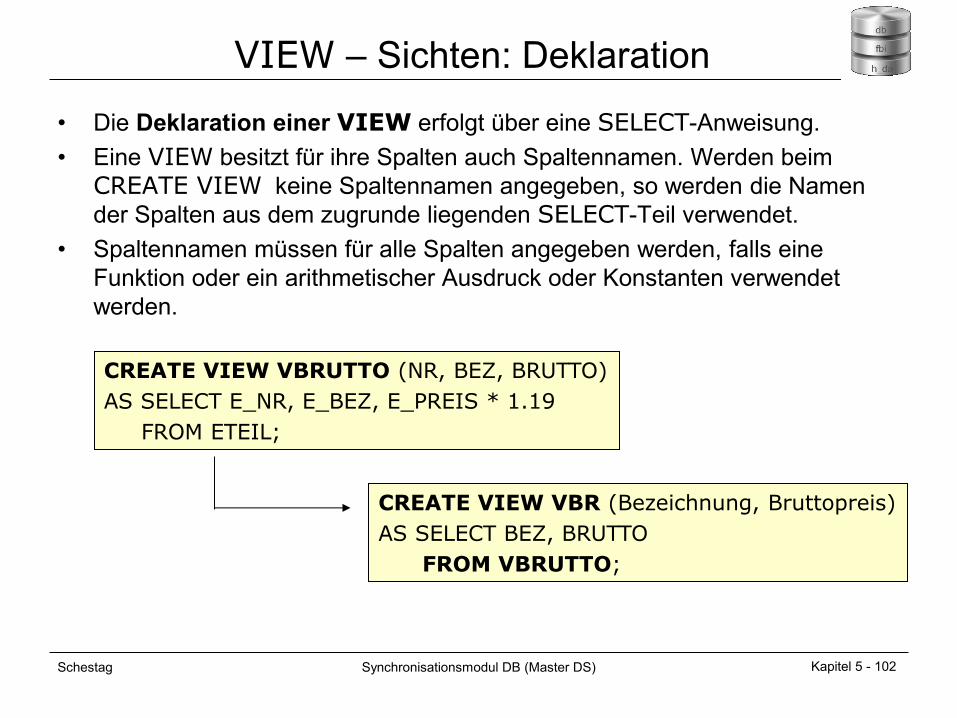
VIEW – Sichten: Deklaration
• Die Deklaration einer VIEW erfolgt über eine SELECT-Anweisung.
• Eine VIEW besitzt für ihre Spalten auch Spaltennamen. Werden beim
CREATE VIEW keine Spaltennamen angegeben, so werden die Namen
der Spalten aus dem zugrunde liegenden SELECT-Teil verwendet.
• Spaltennamen müssen für alle Spalten angegeben werden, falls eine
Funktion oder ein arithmetischer Ausdruck oder Konstanten verwendet
werden.
CREATE VIEW VBRUTTO (NR, BEZ, BRUTTO)
AS SELECT E_NR, E_BEZ, E_PREIS * 1.19
FROM ETEIL;
CREATE VIEW VBR (Bezeichnung, Bruttopreis)
AS SELECT BEZ, BRUTTO
FROM VBRUTTO;

Kapitel 5 - 103 Schestag Synchronisationsmodul DB (Master DS)
VIEW – Sichten: DML-Operationen
• Der Datentyp der Spalten einer VIEW bestimmt sich aus dem Format der
Spalten des SELECT-Teils.
• Der Anwender kann nicht erkennen, ob er DML-Operationen auf eine
TABLE oder eine VIEW absetzt.
• Es entsteht kein Duplikat der Daten bei der Generierung einer VIEW (andernfalls spricht man von MATERIALIZED VIEW). Bei jeder Abfrage
wird mit Hilfe der zugrunde liegenden SELECT-Anweisung die VIEW
generiert (dies hat Einfluss auf die Performance!).
• Auf der Basis einer VIEW kann eine weitere VIEW definiert werden (vgl.
Beispiel VBR oben).
• Ein INSERT über eine VIEW ist nicht möglich, wenn die verborgenen
Spalten mit NOT NULL definiert sind, ein UPDATE nur dann, wenn die
geänderten Werte eindeutig einer Basistabelle zugeordnet werden können
( Join-View!).

Kapitel 5 - 104 Schestag Synchronisationsmodul DB (Master DS)
VIEW – Sichten: WITH CHECK OPTION
VIEW mit CHECK OPTION
• Datensätze können über die VIEW nur manipuliert werden, wenn sie über
die VIEW auch wieder sichtbar werden.
Die Klausel WITH CHECK OPTION garantiert dabei, dass bei einem
INSERT oder UPDATE auf die VIEW die entsprechende Bedingung geprüft
wird.
• Beispiel
Das Gehalt kann in diesem Beispiel nicht mit einer UPDATE-Anweisung auf
einen Wert 10000.0 erhöht werden:
CREATE VIEW personal (pers_nr, name, adresse, beruf)
AS SELECT per_nr, name, adr, beruf
FROM angestellter
WHERE gehalt < 10000.0
WITH CHECK OPTION;

Kapitel 5 - 105 Schestag Synchronisationsmodul DB (Master DS)
VIEW – Sichten: Vorteile
Die Handhabung der Datenbank wird erleichtert.
• Es ist nicht nötig, eine SELECT-Anweisung immer wieder einzugeben. Für
häufig benötigte, komplexe Abfragen wird eine VIEW definiert und getestet.
Aus dieser VIEW können dann einzelne Datensätze selektiert werden. Der
Endanwender benützt für komplexe Abfragen vordefinierte Views.
Datenschutz
• Der Endanwender kann im Zusammenhang mit der Vergabe von speziellen
Zugriffsrechten auf Views nur die Daten sehen, für die er berechtigt ist
(z.B. alle Personalstammsätze mit Gehältern unter 10.000,-- EUR).
Datenunabhängigkeit
• Sichten werden verwendet, um innerhalb eines DB-Systems einen hohen
Grad an Datenunabhängigkeit zu erreichen. Der Benutzer muss nicht
wissen, in welcher TABLE sich die benötigten Daten befinden. Er greift auf
die Daten über eine VIEW zu. Bei einer Änderung der DB-Struktur muss
eventuell die VIEW neu definiert werden, aber die Anwendungsprogramme
müssen nicht geändert werden (Wartungsfreundlichkeit).

Kapitel 5 - 106 Schestag Synchronisationsmodul DB (Master DS)
SQL - Structured Query Language
SQL – Data Definition Language DDL
Systemkatalog, Reverse-Engineering und Schichtenarchitektur
SQL – Data Manipulation Language DML
Update-Operatoren: INSERT, UPDATE, DELETE
Relationen-Algebra
Retrieval-Operator: SELECT
Verbundoperationen: JOIN
Spalten- (bzw. Aggregat-) Funktionen
Sichten (VIEW)
• Rechtevergabe

Kapitel 5 - 107 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe
Die Vergabe von Zugriffsrechten: GRANT, REVOKE, ROLES
• In der Regel sollen nicht alle Informationen eines Datenbanksystems allen
Benutzergruppen gleichermaßen zur Verfügung stehen. Mit Hilfe von SQL
können unterschiedliche Zugriffsrechte auf die Objekte relationaler Daten-
banken vergeben werden.
• Bei der Vergabe von Zugriffsrechten auf Datenbanken müssen grundsätz-
lich drei Aspekte berücksichtigt werden:
WER wird autorisiert (Subjekt),
für WELCHE OBJEKTE wird das Subjekt autorisiert,
für WELCHE OPERATIONEN darf der Zugriff auf die Objekte erfolgen.
• Die Verwaltung der erteilten Zugriffsrechte erfolgt ausschließlich über das
DBMS.

Kapitel 5 - 108 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe – GRANT (1)
• Jeder Creator eines Datenbankobjektes erhält automatisch alle Rechte, die
für dieses Objekt sinnvoll sind.
Beispiel
Der Creator einer Tabelle B erhält automatisch SELECT, INSERT,
UPDATE, DELETE und REFERENCES Rechte auf B (s. nächste Folie).
• Außerdem hat der Creator das Recht, alle diese Rechte vollständig oder
eingeschränkt an andere Benutzer(gruppen) weiter zu vergeben.
• Es ist wichtig, für jeden Benutzer zu speichern, zu welchem Zeitpunkt und
von welchen Benutzern er Rechte erhalten hat (vgl. auch Folie 4 - 108).
Syntax: GRANT <Recht,>
ON <Objekt> TO <User,> [WITH GRANT OPTION];

Kapitel 5 - 109 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe – GRANT (2)
• < Recht, > In der Liste der Rechte kann das Schlüsselwort all (Lang-
form all privileges) als Platzhalter für alle zu vergebenden
Rechte stehen, oder es können die folgenden Schlüssel-
wörter verwendet werden:
– select (Leserecht),
– insert [(column,)],
– update [(column,)], Schreibrechte
– delete,
– usage (zur Recht-Vergabe im Zusammenhang mit Domains),
– references [(column,)] (zur Rechte-Vergabe im Zusammenhang
mit der Referenzierung einer speziellen Tabelle im Rahmen eines
Foreign Key-Constraints).

Kapitel 5 - 110 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe – GRANT (3)
• < Objekt > Ein Zugriffsobjekt ist in der Regel eine
– TABLE, aber auch eine
– VIEW, oder ein
– DOMAIN.
• Ist das Objekt eine TABLE oder eine VIEW so reicht es, den Namen des
Objektes zu nennen; die Angabe des Schlüsselwortes TABLE bzw. VIEW
ist optional.
• Ist das Objekt ein Domain, so lautet die Syntax.
... ON DOMAIN <domain-Name>

Kapitel 5 - 111 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe – GRANT (4)
• < User, > Diese Liste besteht in der Regel aus einem oder mehreren
Benutzerkennungen, oder aus dem Schlüsselwort
PUBLIC, mit dem alle Benutzerkennungen für das System
zu jedem Zeitpunkt gemeint sind.
• WITH GRANT OPTION
Mit dieser Option wird das Recht auf die Erteilung von
Rechten bzgl. der Rechteliste und des Objektes der GRANT-
Anweisung vergeben.
Beispiel
create view MeinAuftrag as select * from Auftrag where Kunde = user with check option; grant select, insert on MeinAuftrag to public;
Welche Wirkung hat die Definition der VIEW
MeinAuftrag und die darauf basierende
Rechtevergabe?
Jeder darf SEINE Aufträge einfügen und an-
schauen, aber nicht ändern, löschen, ebenso
nicht die Aufträge anderer User selektieren und
manipulieren!

Kapitel 5 - 112 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe – REVOKE (1)
• Alle mit einer GRANT-Anweisung vergebenen Rechte können mit einer
REVOKE-Anweisung wieder zurück genommen werden:
• Die RESTRICT- bzw. CASCADE-Klausel regelt innerhalb der REVOKE-
Anweisung den Umgang mit weitergereichten Rechten:
RESTRICT: Die REVOKE-Anweisung wird abgebrochen, wenn das Recht
von dem User, dem es entzogen werden soll, an Dritte weitergegeben
wurde.
CASCADE: Die REVOKE-Anweisung setzt sich automatisch fort über alle
entsprechenden Rechtevergaben durch den User an Dritte.
GRANT OPTION FOR: Bei Nutzung dieser Schlüsselworte im Rahmen
der REVOKE-Anweisung werden dem User nicht die Rechte an sich,
sondern nur das Recht auf die Erteilung dieser Rechte entzogen.
Syntax: REVOKE [GRANT OPTION FOR] <Recht,> ON <Objekt>
FROM <User,> {RESTRICT | CASCADE};

Kapitel 5 - 113 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe – REVOKE (2)
Beispiel
user1
Recht r besitzt
user2
Recht r besitzt
WITH GRANT OPTION WITH GRANT OPTION
zeit t Was geschieht, wenn user1 zu einem Zeitpunkt t4 das Recht r zurück zieht?
Recht r
GRANT r TO USER3
user3
besitzt t3
user4
Recht r besitzt
GRANT r TO USER4
t2
user3
Recht r besitzt
GRANT r TO USER3
t1
t0

Kapitel 5 - 114 Schestag Synchronisationsmodul DB (Master DS)
Rechtevergabe – ROLE
• Um personen-unabhängig Rechte zu vergeben ist es seit SQL-99 möglich,
Rollen zu generieren, für die man mit Hilfe der GRANT- und REVOKE-
Anweisungen Rechte verwalten kann:
• Ein bestimmter User wird mit Hilfe der GRANT-Anweisung einer (oder
mehreren) Rolle(n) zugewiesen:
• Einer Rolle kann unabhängig davon, ob und wie viele Benutzer ihr gerade
angehören, eine Menge von Rechten zugewiesen werden.
• Die Rechte einer bestimmten Person bestehen also aus den persönlichen
Rechten und allen Rechten derjenigen Rollen, denen diese Person zuge-
ordnet wurde.
• Zur Gewährleistung der Sicherheit von Datenbanken gibt es noch zahl-
reiche weiterführende Konzepte (vgl. hierzu die Literatur).
Syntax: CREATE ROLE <Rollen-Name>;
Syntax: GRANT <Rollen-Name> TO <User>;

Kapitel 5 - 115 Schestag Synchronisationsmodul DB (Master DS)
Zusammenfassung
• Die standardisierte, mengen-orientierte Data Sub Language SQL –
Structured Query Language kapselt den Zugriff auf die Objekte und Daten
einer relationalen Datenbank.
• Im Zusammenhang mit DDL-Operationen werden Metadaten zur Struktur
der Daten (DB-Schema) und der Datenbank im Systemkatalog gespeichert.
• Darüber hinaus können statistische Informationen zu den Daten durch ent-
sprechende, explizit ausgeführte Jobs, im Systemkatalog ergänzt werden.
• Primary- und Foreign-Key-Contraints sind wirksame Methoden, die Eindeu-
tigkeit der Datensätze bzw. die Integrität der Daten zu gewährleisten – man
spricht auch von „referentieller Integrität“.
• Mit Hilfe von Sichten (VIEW) und der Rechtevergabe können beliebig
granular Zugriffsrechte auf Objekte der Datenbank vergeben werden.
Kapitel 5 - 116 Schestag Synchronisationsmodul DB (Master DS)
Datenbanken
Einführung
Semantische Datenmodellierung
Relationenmodell
Interne Datenorganisation
SQL - Structured Query Language
6. Prozedurale Spracherweiterungen von SQL, Stored Procedure
und Trigger, JDBC
7. Transaktionsmanagement