structural databases lecture 5 structural bioinformatics dr. avraham samson 81-871
TRANSCRIPT

Structural databases
Lecture 5Structural Bioinformatics
Dr. Avraham Samson81-871

Protein Data Bank (PDB)
2

PDB
3Is protein universe space infinite?

4
http://www.rcsb.org/pdb/static.do?p=general_information/pdb_statistics

Data access
• RCSB PDB http://www.rcsb.org
• FTP ftp://ftp.rcsb.org/
• BMRB http://www.bmrb.wisc.edu
5

Nucleic acid database
6

Structure validation databases
• PDBSum
• Procheck
• What_Check
• SFPCheck
• PDB validation server
• Protein-Protein interaction server
• Protein-DNA interaction server
7

Structure Classification: Introduction
The explosion of protein structures has led to the development of hierarchical systems for comparing and classifying them.
Effective protein classification systems allow us to address several fundamental and important questions:
-If two proteins have similar structures, are they related by common ancestry, or did they converge on a common theme from two different starting points? -How likely is that two proteins with similar structures have the same function?
You already understand many of the terms associated with protein structure: e.g. primary, secondary, tertiary, quaternary, beta-sheet, alpha-helix, turn, etc. In discussing classification, I want to introduce two additional levels for describing structure, the domain and the motif.

Proteins are made up of one or more domains
• proteins often have a modular organization
• single polypeptide chain may be divisible into smaller independent units of tertiary structure called domains
• domains are the fundamental units of structure classification
• different domains in a protein are also often associated with different functions carried out by the protein, though some functions occur at the interface between domains
1 60 100 300 324 355 363 393
activation domain
sequence-specificDNA binding domain
tetramer-izationdomain
non-specificDNA-bindingdomain
domain organization of P53 tumor suppressor

Definition of domain
• “A polypeptide or part of a polypeptide chain that can independently fold into a stable tertiary structure...”
from Introduction to Protein Structure, by Branden & Tooze
• “Compact units within the folding pattern of a single chain that look as if they should have independent stability.”
from Introduction to Protein Architecture, by Lesk
• There are algorithms that divide protein structures into constituent domains (DOMAK, DIAL etc.)
two domains of a bifunctional enzyme,from “Intro to ProteinStructure” by Branden & Tooze

Another useful structural term: the Motif (Supersecondary Structure)
• there are certain favored arrangements of multiple secondary structure elements that recur again and again in proteins--these are known as motifs or supersecondary structures
• a motif is usually smaller than a domain but can encompass an entire domain. Sometimes the structures of domains are partly named after motifs that they contain, e.g. “greek key beta barrel”
• it should be noted that the term motif, when used in conjunction with proteins, sometimes also refers to sequence features with an associated function, e.g. the “copper binding motif” HXXXXH.
“greek key” motif beta-alpha-beta motif

Structure classification databases
• SCOP (Structure Classification Of Proteins) – purely manual (Murzin et al.) http://scop.mrc-lmb.cam.ac.uk/scop/
• CATH (Class, Architecture, Topology, and homologous superfamily) - mostly automated (Orengo et al.) http://www.biochem.ucl.ac.uk/bsm/cath/
• DALI/FSSP (Domain dictionnary) – purely automated (Holm et al.) http://ekhidna.biocenter.helsinki.fi/dali
12

The CATH Hierarchy1. Divide PDB structure entries into domains (using domain recognition algorithms--
domain is the fundamental unit of structure classification
2. Classify each domain according to a five level hierarchy:
ClassArchitectureTopologyHomologous SuperfamilySequence Family
the top 3 levels of the hierarchyare purely phenetic--basedon characteristics of the structure,not on evolutionary relationships
the bottom two levels includesome phyletic classification as well--groupings according to putativecommon ancestry based on structural similarity, functionalsimilarity, and sequence similarity
There is no purely phyleticsystem of protein classification!(also unlikely that there is anycommon ancestor to all proteins)

Class level
• In the CATH hierarchy, Class simply describes what type of secondary structure is present or dominant.
• There are only four classes:
mainly mainly
domains with few secondary structures
• 90% of structures are trivial to assign at this level.

Architecture level• Architecture is hard to define precisely
• In CATH it is defined broadly as describing “general features of protein shape” such as arrangements of secondary structure in 3D space
• It does not define connectivities between secondary structural elements--that’s what the topology level (next level down the hierarchy) does. It does not even explicitly define directionality of secondary structure, e.g. parallel or antiparallel beta-sheets.
• in CATH, architectures are presently assigned manually, by visual inspection.

Best way to understand the idea of architecture is to look at examples:
Below, some architectures in the “mainly ” class

Examples of “” architectures

Topology level (also called “Fold”)
• if two domains have the same topology, it means they have the same number and arrangement of secondary structures, and the connectivities between these elements are the same.
• this is also sometimes called the fold of a protein domain.
• in CATH, automated structure alignment using a program called SSAP is used to group domains according to topology.

“Common core”• What does it mean exactly for two proteins to be classified as having the same
fold/topology?• It is usually not strictly required that the number and type of secondary structure
elements is exactly the same • Many pairs of domain structures share a common core of structurally related
elements but differ in presence or absence of a secondary structure element or two. Such proteins are usually classed as having the same fold or topology even though, under a really strict topological definition, they don’t.
tenascin (right) and Ig variable domain (far right) would be classed in CATH as having the same fold
7-strand common coreshown in green

“Fold” is the most commonly used general description of the structure of a domain
Just as a domain is the fundamental unit of structural classification, fold (or topology) is the most fundamental qualitative descriptor of the structure of a domain.
If I know what the fold of a protein is, I have a pretty reasonable idea of what the general structure is, though not an exact picture. If two proteins have the same fold, their structures are pretty similar.
This is why the term “fold” enjoys such common usage: for example, efforts to annotate genomes with structural information are usually referred to as “fold assignment” schemes. The first question most people ask when they see a structure is, what is the fold?
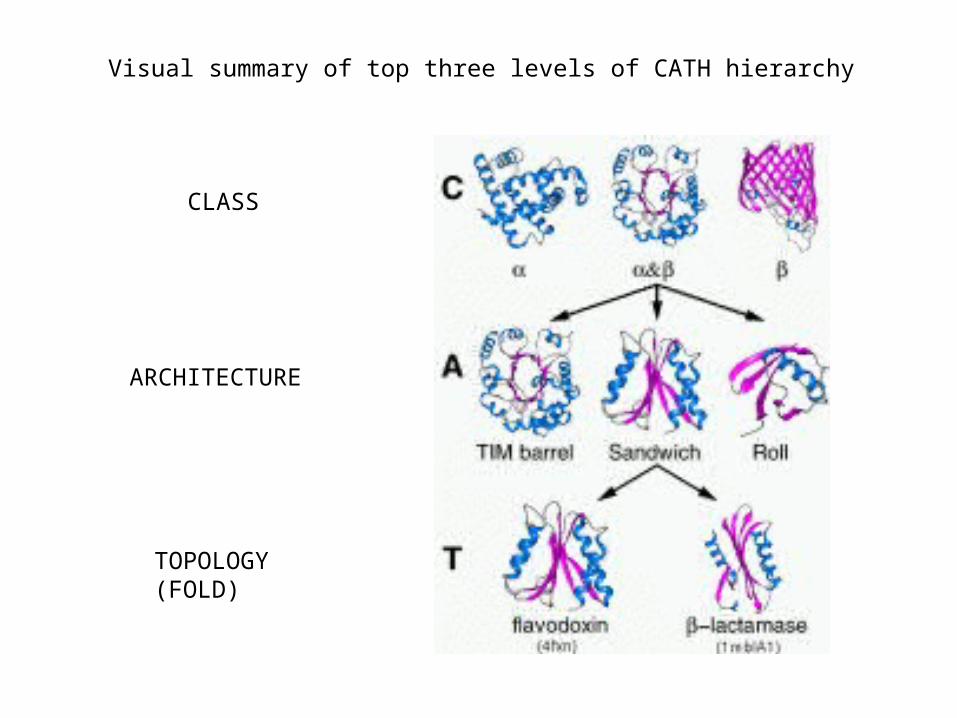
Visual summary of top three levels of CATH hierarchy
CLASS
ARCHITECTURE
TOPOLOGY(FOLD)

Homologous superfamily
• The bottom two levels in the CATH hierarchy, homologous superfamily and sequence family, relate to how good the evidence is for homology among proteins which share the same topology (fold).
• if two proteins with the same topology have relatively low sequence identity (say < 30%) but show other evidence (usually functional) that they might have a common ancestor, they are placed in the same homologous superfamily.
For example, the sequences of hemoglobin and myoglobin, superimposed above,are only 24% identical, but they bind hemein the same place and have veryclosely related biological functions. This is taken as evidence for common ancestry.

Sequence family
• Proteins that show direct evidence for homology based on sequence similarity (for example > 30% identity over 150 residues or more) are grouped in the same sequence family.

SCOP: A different (but similar) taxonomy system
Correspondences between SCOP and CATH hierarchies:
SCOP CATH
class class
architecture
fold topology
homologous superfamily
superfamily
family sequence family
domain domain
CATH more directed toward structural classification, whereas SCOPpays more attention to evolutionary relationships. Both have in common that they have manual aspects and are curated by experts.Are there automated ways of identifying similarities in structures theway there are for sequences? See Appendix describing DALI.

What does protein taxonomy tell us?
• diversity of protein universe--e.g. how many folds are there?
• divergence of structure--what structural differences and similarities exist among recognizably related proteins? If two proteins share a given level of sequence similarity, how similar are their structures?
• convergence of structure--do two proteins which share a common fold always share common ancestry? Homology vs. analogy. How would one distinguish homology and analogy?
• structure and function--is a given type of function always performed using the same fold? Can some types of fold be used for different functions?

How many different domain folds are
there?• structural taxonomy reveals that although
structures are being solved more rapidly than ever, fewer and fewer of them have new folds, suggesting that the day may not be too far off when representatives of all fold types will be solved. CATH now lists more than 800 different domain folds. By some estimates there are ~2000 total folds in Nature.
blue bars: new foldsred bars: total known folds

If I know the fold, do I know the function?
About 95% of folds have only one associated superfamily. Domains within these superfamilies are usually functionally related (indeed, this is often the reason they are assigned to the same superfamily). So in these cases, knowing the fold of a domain would tell you quite a bit about the function.
0
50
100
150
200
250
300
1 2 3 4 5 6 7 8 9 10 11 12 13
nu
mb
er
of
fold
s
number of superfamilies per fold
A cautionary note would be that there are a number of cases in which proteins are undoubtedly homologous (e.g. by significant sequence similarity) but have very different functions. The classic example is the recruitment of lactate dehydrogenases as structural proteins in the eye lens.
adapted from Brenner, Chothia and Hubbard. Curr Opin Struct Biol 7, 369 (1997)

Folds with many functions: superfolds
About 5% of foldshave multiplehomologoussuperfamilies,which usually meansthey are usedfor a varietyof functions.these are called“superfolds” or FODs(frequently occurring domains)
some architectureshave many folds--“superarchitecture”

Superfolds: convergence to the same fold, or divergence of function? Homology and analogy
The existence of multiple superfamilies for single folds seems to suggest that some proteins with the same fold are not homologous. This is not a completely uncontroversial idea--one problem is that it’s hard to prove that two proteins are not related! More often, the lack of common ancestry is simply assumed from the lack of clear positive evidence (for example, the lack of any functional or sequence similarity). Two proteins which have the same fold but otherwise appear unrelated are usually called analogues as opposed to homologues. Analogues may have converged on the same fold from different origins.
Tryptophan bound to the trp RNA-binding attenuation protein (TRAP; near right) and cyclic AMP bound to regulatory subunit of catabolite activator protein (CAP; far right). No significant sequence similarity (in pairwise BLAST), and very different ligand, but common fold and common binding site. Analogues or homologues? Not easy to tell!
Russell, Sasieni and Sternberg,J Mol Biol 282, 903 (1998)

The Immunoglobulin Fold: A clear case of structural convergence?
Domains with the immunoglobulin fold not only do not share the same function, they don’t even have a common ligand binding site! It is widely believed that proteins that share the same fold but show no sequence similarity and no functional similarity (i.e. no relationship between ligands, chemistry, or binding site) are not homologous, but are instead analogous. In other words, they are independently evolved domains that converged to a similar structure.
There’s no common functional theme among the immunoglobulin fold superfamilies. So why is Ig a superfold? Perhaps because it has a simple topology (greek key motif based) which is easy to fold correctly and which might be likely to evolve independently multiple times (facile folding kinetics and likelihood of evolution).
each of the ligands shown represents a different binding site on the Ig fold. The 21 Ig-fold superfamilies show little correlation in binding site
Russell, Sasieni and Sternberg,J Mol Biol 282, 903 (1998)

TIM barrels: some folds contain natural binding sites/active sites
The C-terminal mouth of a TIM barrel is a nice place to bind a ligand, and catalytic groups are easily appended from the loops at the C-terminal ends of the parallel -strands
Hence, TIM barrels are superfolds which are commonly used as enzymes, and the active site is almost always in the same place.
The TIM barrel is also an example of a fold with a straightforward topology that may facilitate kinetic folding.

The same function can be carried out by different folds
chymotrypsin subtilisinsame serine protease catalytictriad, very different folds

Structural divergence of proteins• How does structure change as sequences diverge?
• For example, the structure of the CATH hierarchy implies that all homologous proteins (same family/superfamily) have the same fold (topology), and indeed structure is conserved a lot better than sequence in proteins. But of course the same fold doesn’t mean exactly the same structure, and one might imagine that more closely related proteins (same family as opposed to superfamily) might have more closely related structures.
• So for proteins with a given % identity, how similar will their structures be?

Superposition of protein structures
• if two proteins are similar enough in sequence that the sequences can be reliably aligned, structure comparison can proceed from the seq. alignment:
1. Do a pairwise alignment of the sequence
sequence 1: YIREV-GKL
sequence 2: YITQVRNKA
2. Superpose the structures to minimize the RMSD for equivalent residue pairs in the alignment
3. Often omit regions which have qualitatively dissimilar structures (i.e. not part of the common core, and/or which are difficult to align (e.g. loops)
note: thesestructures do notcorrespond to the sequences above

Structural divergence: Close relatives (>50% sequence identity)
• at this level, usually >90% of residues retain a qualitatively similar structure (common core)
• 90% of the identical residues would have similar sidechain conformations. 50% of the nonidentical residues would also show some similarity in sidechain conformation.
• Backbone atoms for common core would have 1.0 Å RMSD or less.

Structural divergence: Distant relatives: (<25% sequence identity)
plastocyanin azurin
same fold: common core of 7-stranded beta-sandwich is 50-60% of the total residues. Sequence identity within this common core is ~20%. RMSD of common core residues is ~2.2Å.
both havetwo-histidine copper bindingsiteat top
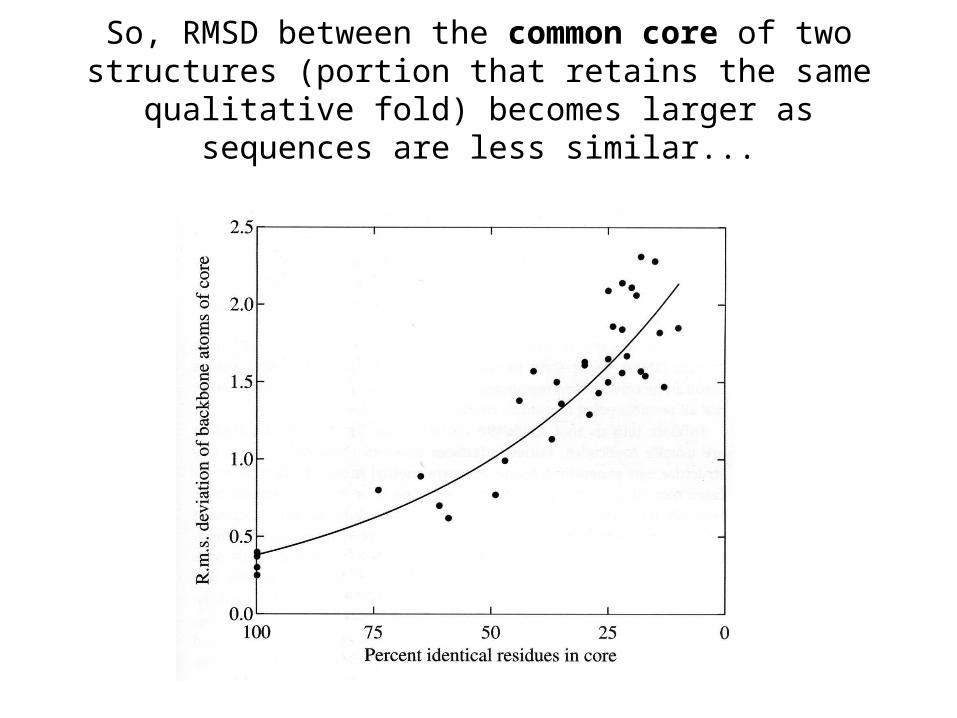
So, RMSD between the common core of two structures (portion that retains the same qualitative fold) becomes
larger as sequences are less similar...

...as does the percentage of the total residues which are definable as belonging to the common core...

39
Problems with StructureClassification and Function Prediction
Chymotrypsin
Subltilisin
Dehydratase
Hydrolase
Similar Function Different Fold
Similar FoldDifferent Function

Other problems
40
Almost identical sequences can have two folds