(some) research trends in question answering...
TRANSCRIPT

(Some) Research Trends in Question Answering (QA)
Manoj Kumar Chinnakotla
Senior Applied Scientist
Artificial Intelligence and Research (AI&R)
Microsoft, India
Advanced Topics in AI (Spring 2017)IIT Delhi

Lecture Objective and Outline
• To cover some interesting trends in QA research• Especially in applying deep learning techniques
• With minimal manual intervention and feature design
• QA from various different sources• Unstructured Text Web, Free Text, Entities
• Knowledge Bases Freebase, REVERB, DBPedia
• Community Forums Stack overflow, Yahoo! Answers etc.
• Will be covering three different and recent papers in each of the above stream

A Neural Network for Factoid QA over Paragraphs
Mohit Iyyer, Jordan Boyd-Graber, Leonardo Claudino,
Richard Socher
(EMNLP 2014)

Factoid QA
• Given a description of an entity, identify the• Person• Place• Thing
• Quiz Bowl• Quiz competition for high-school and college level students• Need to guess entities based on a question given in raw text• Each question has 4-6 sentences• Each sentence has unique clues about target entity• Players can answer any time – earlier the answer, more points scored• Questions follow “pyramidality” – earlier clues are harder
Holy Roman Empire

How do they solve it?
• Dependency Tree RNN (DT-RNN)
• Trans-sentential Averaging
• Resultant Model named as QANTA• Question Answering Neural Network with Trans-Sentential Averaging (QANTA)

Example Model Construction

Training

Dataset
• 100,000 Quiz Bowl Question/Answer pairs from 1998-2013
• From the above, only Literature and History questions – 40%• History – 21,041• Literature – 22, 956
• Answer Based Filtering• 65.6% of answers only occur once or twice and are eliminated• All answers which do not occur at least 6 times are eliminated
• Final number of unique questions• History: 451• Literature: 595
• Total Dataset• History: 4,460• Literature: 5,685

Experimental Setup
Train Test
History Questions: 3,761Sentences: 14,217
Questions: 699Sentences: 2,768
Literature Questions: 4,777Sentences: 17,972
Questions: 908Sentences: 3,577
Baselines• Bag of Words (BOW)• Bag of Words with DT based features (BOW-DT)• IR-QB: Maps questions to answers using Whoosh – a state-of-the-art IR engine• IR-Wiki: Maps questions to answers using Whoosh where answers also have their wiki text

Results

Positive Examples
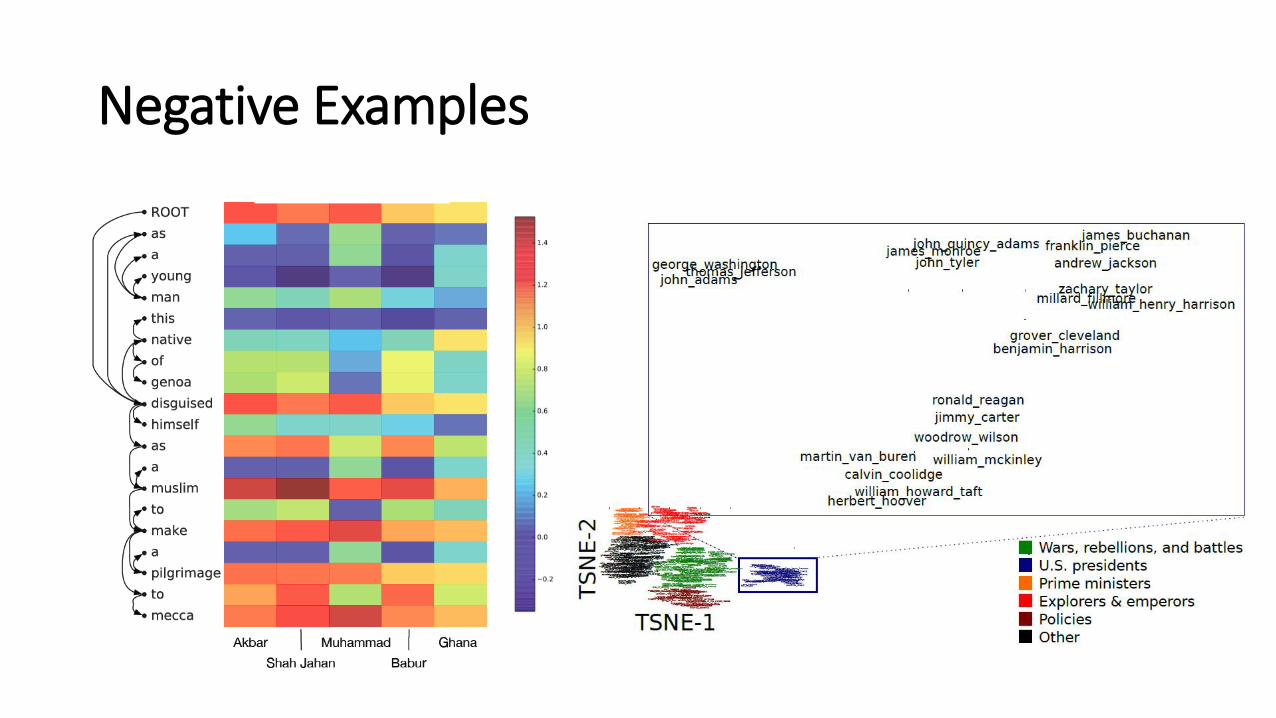
Negative Examples

Nice Things about the Paper
• Their use of dependency trees instead of bag of words or a mere sequence of words was nice. They tried to use sophisticated linguistic information in their model.
• Joint learning of answer and question representations in the same vector"most answers are themselves words (features) in other questions (e.g., a question on World War II might mention the Battle of the Bulge and vice versa). Thus, word vectors associated with such answers can be trained in the same vector space as question text enabling us to model relationships between answers instead of assuming incorrectly that all answers are independent.“
• Nice Error Analysis in Sections 5.2 and 5.3
• Tried some obvious extensions and provided reasoning for not working"We tried transforming Wikipedia sentences into quiz bowl sentences by replacing answer mentions with appropriate descriptors (e.g., \Joseph Heller" with \this author"), but the resulting sentences suffered from a variety of grammatical issues and did not help the final result."

Shortcomings
• RNNs need multiple redundant training examples for learning powerful meaning representations. In real world, how will we get those?• In some sense, they had lots of data about each question which can be used
to learn such rich representations. This is an unrealistic assumption.
• They whittled down their training and test data to a small set of QA pairs that *fit* their needs (no messy data)
"451 history answers and 595 literature answers that occur on average twelve times in the corpus".

Open Question Answering with Weakly Supervised
Embedding Models
Bordes A, Weston J and Usunier N
(ECML PKDD 2014)

Task Definition
Scoring function over all KB triples

Training Data
• REVERB• 14M Triples
• 2M Entities
• 600K Relationships
• Extracted from ClueWeb09 Corpus
• Contains lots of noise• For instance, the following are three different entities:

Automatic Training Data Generation
• Generate Question-Triple pairs automatically using the following 16 rules
• For each triple, generate these 16 questions• Some exceptions: Only *-in.r
relation can generate “where did e r?” pattern question
• Approximate size of Question-Triple pairs: 16 X 14M
• Syntactic structure is simple• Some of them may not be semantically valid

Essence of the Technique
• Project both question (bag of words or n-grams) and KB triple into a shared embedding space
• Compute the similarity score in the shared embedding space and rank triples based on it

Training Data
• Positive Training Samples• All questions generated from triples using rules
• Negative Samples• For each original triple (q, t), randomly select a triple from KB • Replace each field of original triple t with ttmp with probability of 0.66• This way, it is possible to create negative samples which are close enough to the
original triples
• Pose it as a ranking problem
• Ranking Loss:
• Constraints:

Training Algorithm
• Stochastic Gradient Descent (SGD)
1. Randomly initialize W and V (mean 0, std. dev. 1
𝑘)
2. Sample a positive training pair (qi,ti) from D
3. Create a corrupted triple ti1 such that ti
1 ≠ ti
4. Use ranking loss and compute SGD update
5. Enfore W and V are normalized at each step
• Learning rate adapted using ADA-GRAD

Capturing Question Variations using WIKIANSWERS• 2.5 M distinct questions
• 18 M distinct paraphrase pairs

Multitask Learning with Paraphrases
V V WW
qtiti1qp
Ranking LossRanking Loss
800K Vocabulary3.5M Entities
(2 embeddings per entity)250M Examples
(Rules + Paraphrases)
64 dimensions64 dimensions64 dimensions64 dimensions

Fine-Tuning of Similarity Function
• The earlier model usually doesn’t converge to global optimum and many correct answers still not ranked at the top
• For further improvement, introduce one more weighting factor into the query-triple similarity metric
• After fixing W and V, M could be learnt using

Evaluation Results
• Test Set• 37 questions from WikiANSWERS which has at least one answer in REVERB
• Additional paraphrase questions – 691 questions
• Run various versions of PARALEX to get candidate triples and get them human-judged
• Total: 48K triples labeled

Candidate Generation using String Matching
• Construct a set of candidate strings containing• Do POS Tagging of the question
• Get the following candidate strings• All noun phrases that appear less than 1000 times in REVERB
• All proper nouns if any
• Augment these strings with their singular form removing trailing “s” if any
• Only consider triples which contain at least one of the above candidate strings in them
• Significantly reduces the number of candidates processed – 10K (on avg.) vs. 14M

Sample Embeddings

Nice things about the paper
• Doesn’t use any manual annotation and no prior information from any other dataset
• Works on a highly noisy Knowledge Based (KB) – REVERB
• Doesn’t assume the existence of “word alignment” tool for learning the term equivalences• In fact, it automatically learns these term equivalences
• Use of multi-task learning to combine learnings from paraphrases as well as Q, A pairs was interesting
• Achieves impressive results with minimal assumptions from training or other resources

Shortcomings
• Many adhoc decisions across the paper• Bag of words for modeling a question is very crude• “what are cats afraid of?” vs. “what are afraid of cats?”• Perhaps, a DT-RNN or semantic role based RNN is much better
• String matching based candidate generation was a major contributor in boosting the accuracy which was introduced towards the end as a rescue step!
• The fine-tuning step was introduced to improve the poor performance of the initial model
• Overall, more value seems to be coming from such hacks and tricks in stead of the original idea itself!

Potential Extensions
• Try out DT-RNN and variants for modeling the question
• Similarly, try word2vec/GLoVE entity embeddings for entity and object and model the predicate using a simple RNN
• Is it possible to model this problem using the sequence-to-sequence framework?• Question -> Entity, Predicate, Object

Hand in Glove: Deep Feature Fusion Network
Architectures for Answer Quality Prediction
Sai Praneeth, Goutham, Manoj Chinnakotla, Manish
Shrivastava
(SIGIR 2016, COLING 2016)

• Given a question Q and its set of community answers, rate the answers corresponding to their quality.
• Task announced in Sem Eval 2015 and Sem Eval 2016
• All the previous best performing systems were based on – a) purely hand-crafted feature engineering or b) only deep learning based systems
Question: Can I obtain Driving License my QID is written EmployeeDescription: Can I obtain Driving License my QID is written Employee, I saw list in gulf times but there isn't mentionedEMPLOYEE QID Profession.Answer1: the word employee is a general term that refers to all the staff in your company either the manager,secretary up to the lowest position or whatever positions they have. you are all considered employees of yourcompany. (Potential)Answer2: your QID should specify what is the actual profession you have. I think for me, your chances to have adrivers license is low. (Good)Answer3: dear Richard, his asking if he can obtain. means he have the drivers license. (Bad)Answer4: Slim chance...... (Good)
Answer Quality Prediction in Community QA Forums

• Central Idea• Exploit external resources available in the form of click-through data, Wikipedia text
etc. for improving the matching
• Combine both hand-crafted and deep learning features using various architectures
• Two solutions• Learn deep features using CNN and then combine with hand-crafted features using
a fully connected network (DFFN-CNN)
• Learn deep features using a Bi-directional LSTM and then combine with hand-crafted features using a fully connected network (DFFN-BLNA)
• Hand-crafted features focus on learning similarities with the help of various resources
Deep Feature Fusion Networks (DFFN)

• Wikipedia Based Features• TagMe Similarity• NE Similarity
• Anchor Text• Google Cross-Wiki Dictionary
• Clickthrough Data• DSSM Similarity• Paragraph2Vec similarity
• Metadata Features• Author reputation score• Was answer written by the seeker himself?• Position of the answer• Presence of URLs• Presence of special characters – question mark, smiley, excalamations
Hand Crafted Features (HCF)

Deep Feature Fusion Networks (DFFN) (Contd..)

• Both these models achieve state-of-the-art performance on Sem Eval2015 and Sem Eval 2016 tasks
SemEval 2015 SemEval 2016
Model F1 Accu. Model MAP F1 Accu.
DFFN-BLNA 62.01* 75.20* DFFN-BLNA 83.91* 66.70* 77.65*
DFFN-CNN 60.86 74.54 DFFN 81.77 65.75 76.42
JAIST 57.29 72.67 Kelp 79.19 64.36 75.11
HITSZ-ICRC 56.44 69.43 ConvKN 78.71 63.55 74.95
DFFN w/o HCF 56.04 69.73 DFFN w/o HCF 74.36 60.22 72.88
DFFN w/o CNN 51.65 67.12 DFFN w/o CNN 70.21 56.77 68.65
Deep Feature Fusion Networks (DFFN) (Contd..)

Qualitative Examples

Questions/Discussion
Thanks!