soc design llectureecture 1100: oonn-cchip...
TRANSCRIPT

SoC DesignLecture 10: On-Chip Interconnection NetworksLecture 10: On Chip Interconnection Networks
Shaahin Hessabi
Department of Computer Engineeringg g
Sharif University of Technology

Signal Transmission on SoCWe focus on global wires
Local wires can scale with technology, and present design styles may still apply.
Global wires are on top level metals (with higher pitch and width).Increased pitch reduces cross-coupling (improving noise immunity).
Increased width reduces wire resistance.
Increased spacing around the wire prevents capacitance growth.
Inductive effects grows relative to resistance and capacitance.g pFuture global wires modeled as lossy transmission lines, as opposed to RC models.
Causes signal attenuation and dispersion in frequency of fast signals.
Can be reduced by splitting wires in several sections with buffers in betweenCan be reduced by splitting wires in several sections with buffers in between.
o Impedance matching required due to line inductance.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks2

Signal IntegritySignal integrity: error-free information transfer (at the physical level) on global wires will become harder, due to:
Signal swings are reduced, with a corresponding reduction in voltage noise margins.
Crosstalk increases.
M EMI b f ll lt i d ll d i t itMore EMI because of smaller voltage swings and smaller dynamic storage capacitances.
More synchronization failures and/or metastability, because of transmission speed changes, local clock frequency changes, timing noise ( jitter), and so on.
Soft errors will be a potential hazard for large SoCs as well.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks3

On-Chip Interconnection Networks
Shared-Medium Networks
Switched-media Networks (Direct and Indirect Networks)
Hybrid NetworksHybrid Networks
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks4
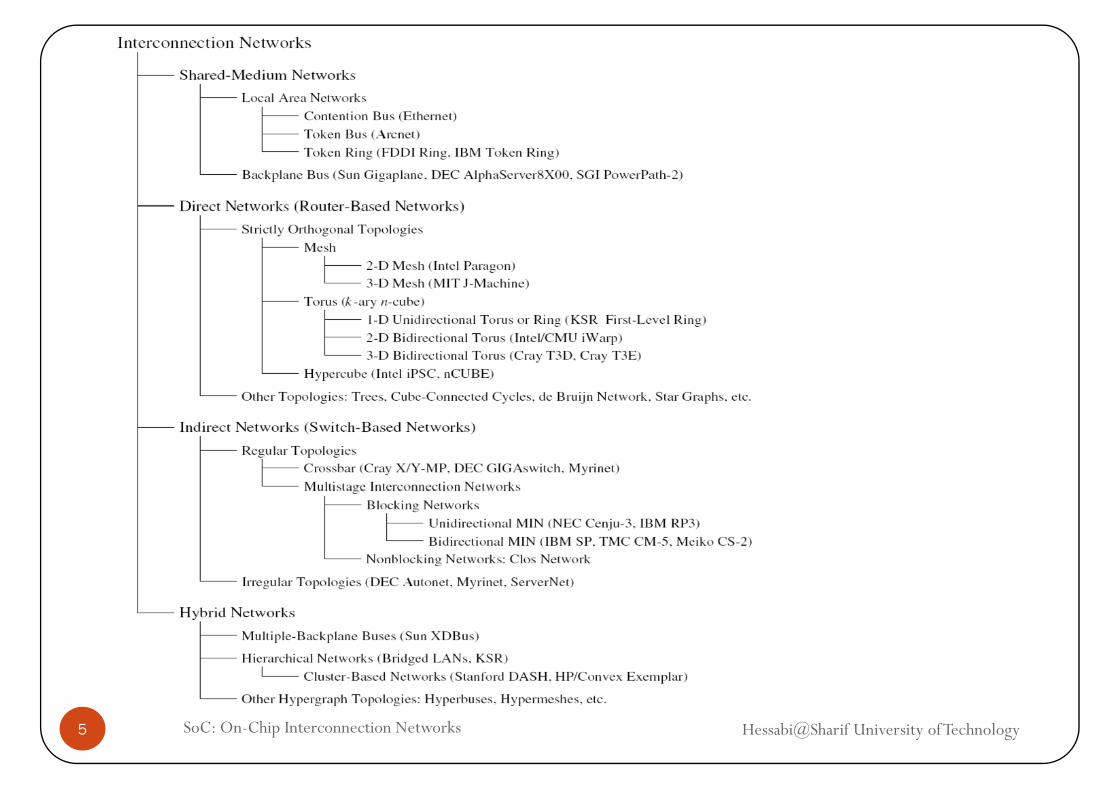
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks5

Shared-Medium NetworksSimplest interconnect structures.
Transmission medium is shared by all communication devices.y
Network is usually passive: does not generate control or data messages.
Serialization: Only one component can send a message at any given time.y p g y gOrder of messages.
Interconnection structures:Point-to-point
On-chip bus
On-chip networkOn-chip network
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks6
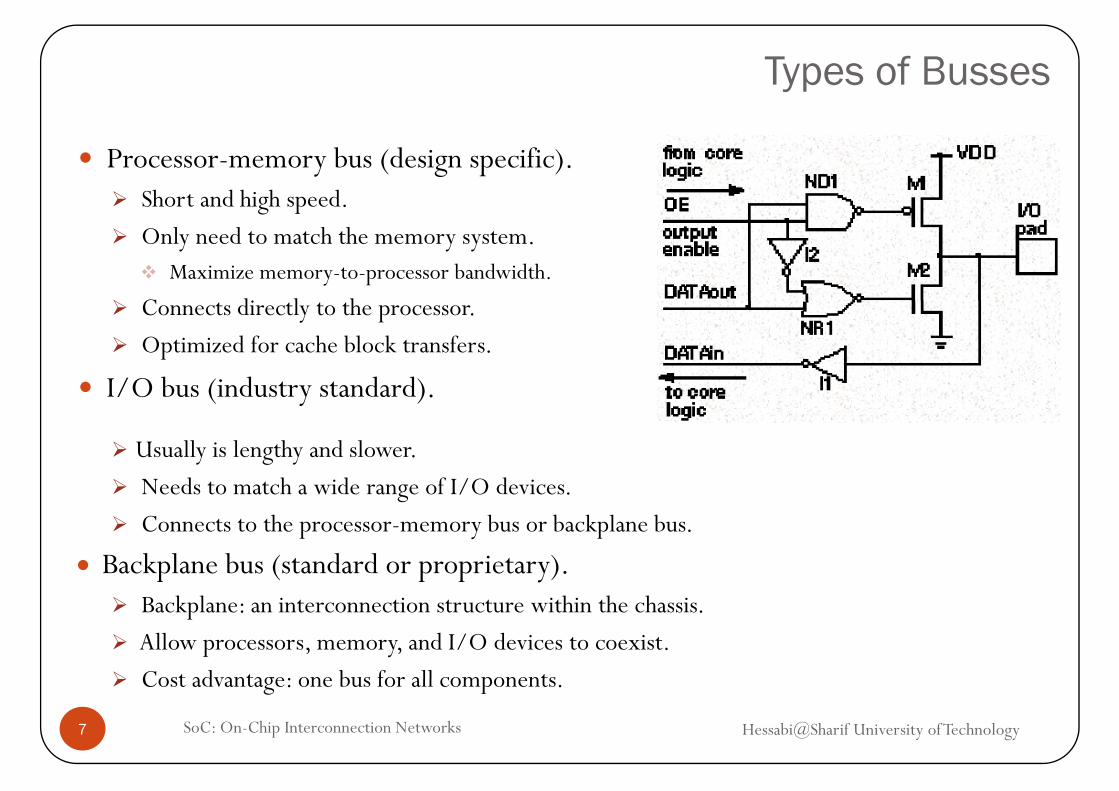
Types of Busses
Processor-memory bus (design specific).Short and high speed.Short and high speed.
Only need to match the memory system.Maximize memory-to-processor bandwidth.
C di l h Connects directly to the processor.
Optimized for cache block transfers.
I/O bus (industry standard). I/O bus (industry standard).
Usually is lengthy and slower.
Needs to match a wide range of I/O devicesNeeds to match a wide range of I/O devices.
Connects to the processor-memory bus or backplane bus.
• Backplane bus (standard or proprietary).Backplane: an interconnection structure within the chassis.
Allow processors, memory, and I/O devices to coexist.
Cost advantage: one bus for all components
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks7
Cost advantage: one bus for all components.

Traditional Bus vs. OCB
Traditional Bus (Off-Chip Bus) OCB (On-Chip Bus)
Shared I/O
Fixed interconnection scheme
Routing resource in target device (e.g., FPGA, ASIC)
Fixed timing requirement
Dedicated address decoding
Bandwidth and latency are important
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks8
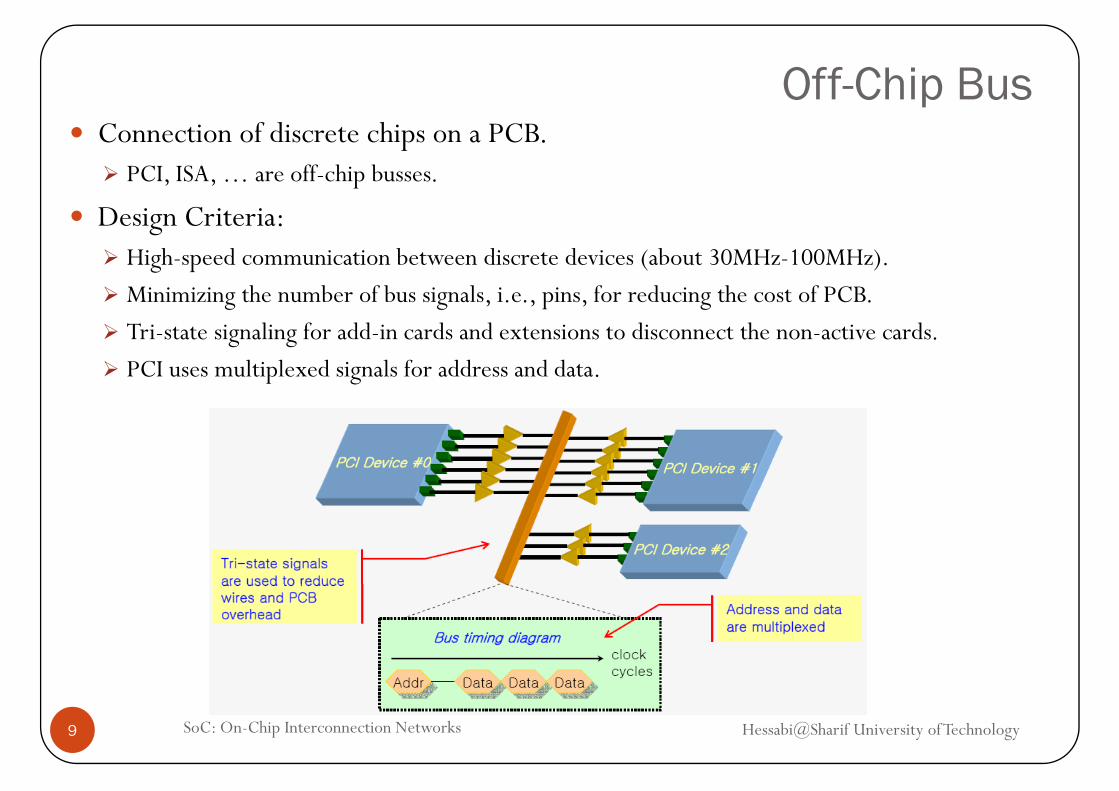
Off-Chip BusConnection of discrete chips on a PCB.
PCI, ISA, … are off-chip busses.
Design Criteria:High-speed communication between discrete devices (about 30MHz-100MHz).
Minimizing the number of bus signals, i.e., pins, for reducing the cost of PCB.Minimizing the number of bus signals, i.e., pins, for reducing the cost of PCB.
Tri-state signaling for add-in cards and extensions to disconnect the non-active cards.
PCI uses multiplexed signals for address and data.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks9

On-Chip BussesNo use of tri-state signals : Tri-state bus is difficult for static timing analysis as the bus loading is only identified through dynamic simulation.
High-performance transaction schemesPoint-to-point protocol
Split transactionSplit transaction
Efficient arbitration schemes are adopted.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks10
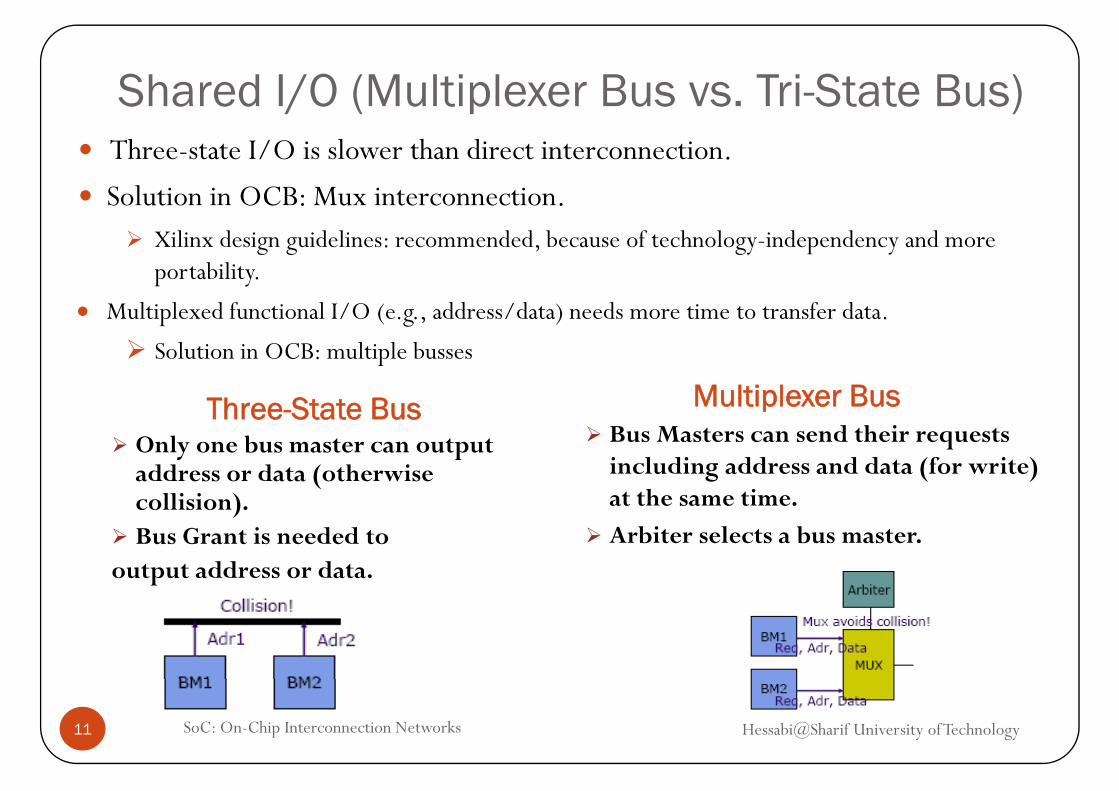
Shared I/O (Multiplexer Bus vs. Tri-State Bus)/ ( p )Three-state I/O is slower than direct interconnection.
Solution in OCB: Mux interconnection.Xilinx design guidelines: recommended, because of technology-independency and more portability.
Multiplexer Bus
• Multiplexed functional I/O (e.g., address/data) needs more time to transfer data.
Solution in OCB: multiple busses
Three-State BusOnly one bus master can output address or data (otherwise
Multiplexer BusBus Masters can send their requests including address and data (for write)
h icollision).Bus Grant is needed to
output address or data.
at the same time.Arbiter selects a bus master.
p
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks11

Physical ConstraintsFixed interconnection scheme:
Traditional busses usually routed across a standard backplane.
OCB allows variable interconnection scheme, defined by system integrator (tool level)
Fixed timing requirement:Traditional busses have fixed timing requirements:
Highly capacitive and inductive loads.
Designed for the worst case operating conditions, when unknown bus modules are connected together.
OCB has a variable timing specification that:Can be enforced by place & route tools (tool level).
Usually do not specify absolute timingUsually do not specify absolute timing.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks12

Bus ComponentsSwitch or node
Arbitration, routing
Converter or bridge (type converter)From one protocol to another
Size converterBuffering capacity
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks13

Bussing StrategiesRegister-to-Register Communications:
Point-to-point.
Single shared bus.
Multiple special purpose busses.
T d ff b d h/ l l i d f ll li Tradeoffs between datapath/control complexity and amount of parallelism supported by the hardware.
Master vs SlaveMaster vs. Slave
A bus transaction includes two parts:Master: Issuing the command (and address) – request.g ( ) q
Slave: Transferring the data – action.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks14
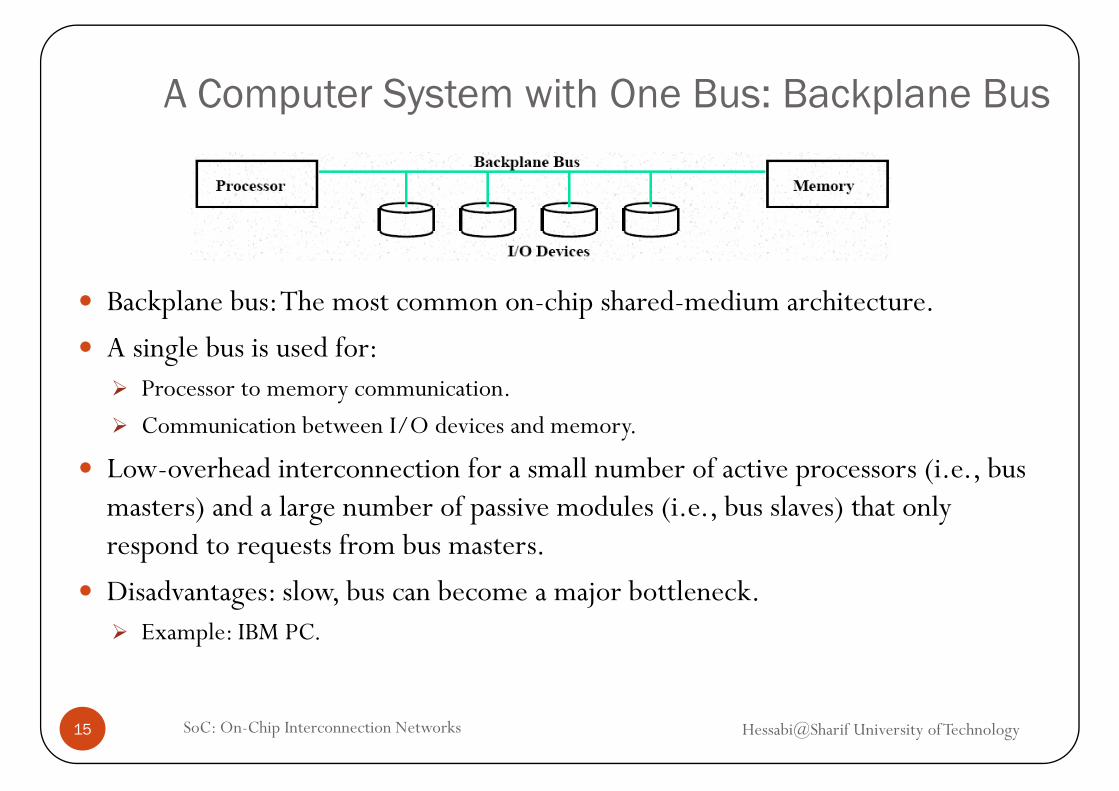
A Computer System with One Bus: Backplane Busp y p
Backplane bus: The most common on chip shared medium architectureBackplane bus: The most common on-chip shared-medium architecture.
A single bus is used for:Processor to memory communication.Processor to memory communication.
Communication between I/O devices and memory.
Low-overhead interconnection for a small number of active processors (i.e., bus masters) and a large number of passive modules (i.e., bus slaves) that only respond to requests from bus masters.
Di d l b b j b l kDisadvantages: slow, bus can become a major bottleneck.Example: IBM PC.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks15

A Two-Bus System
I/O busses tap into the processor-memory bus via bus adaptors:Processor-memory bus: mainly for processor-memory traffic.
I/O buses: provide expansion slots for I/O devices.
A l M i h IIApple Macintosh-II:NuBus: Processor, memory, and a few selected I/O devices.
SCCI Bus: the rest of the I/O devices.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks16
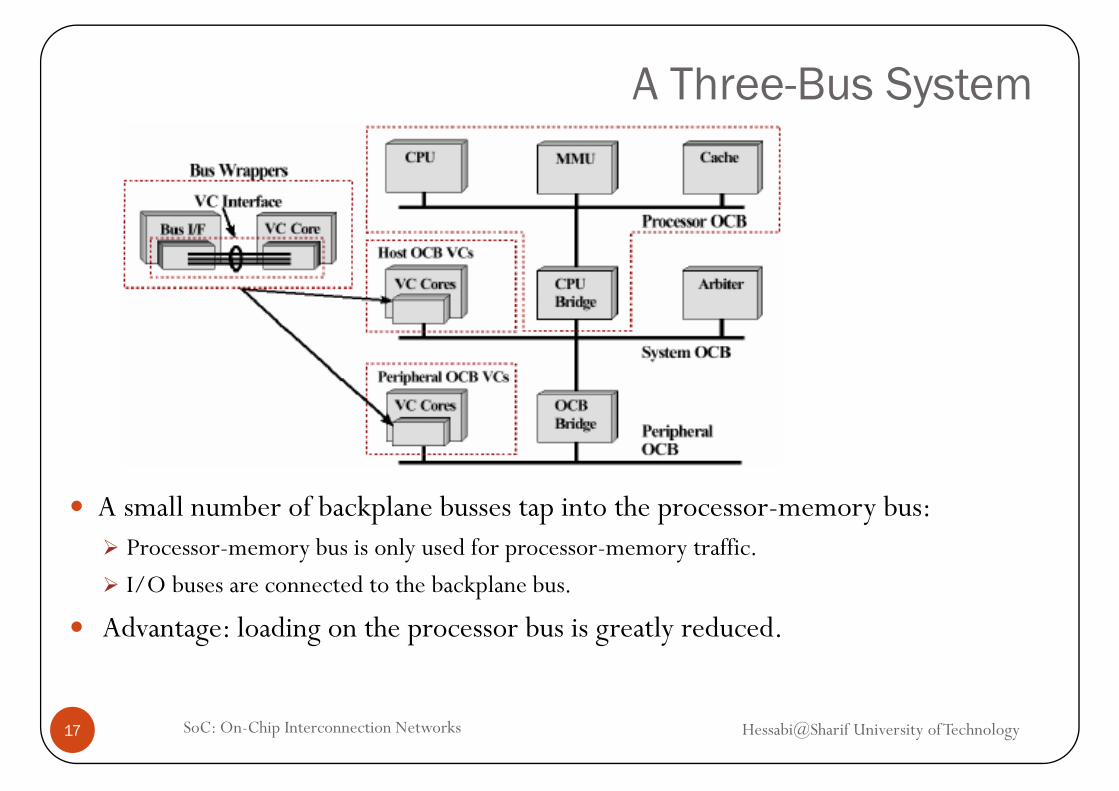
A Three-Bus System
A small number of backplane busses tap into the processor-memory bus:Processor-memory bus is only used for processor-memory traffic.
I/O buses are connected to the backplane busI/O buses are connected to the backplane bus.
Advantage: loading on the processor bus is greatly reduced.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks17

Bus AdvantagesVersatility: Any bus is almost directly compatible with most available IPs.
New devices can be added easily.
Peripherals can be moved between computer systems that use the same bus standard.
Low cost: The silicon cost of a bus is near zero.
Bus latency is zero once arbiter has granted control.
Concepts are simple and well understood.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks18

Bus DisadvantagesScalability
Contention
Power issues
Creates a communication bottleneck.Bandwidth of bus can limit the maximum I/O throughput.
The maximum bus speed is largely limited by:The length of the bus.
The number of devices on the bus (bus loading).Every unit attached adds parasitic capacitanceEvery unit attached adds parasitic capacitance.
The need to support a range of devices with:Widely varying latencies.
W d l d f Widely varying data transfer rates.
Bus arbiter delay grows with the number of masters.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks19
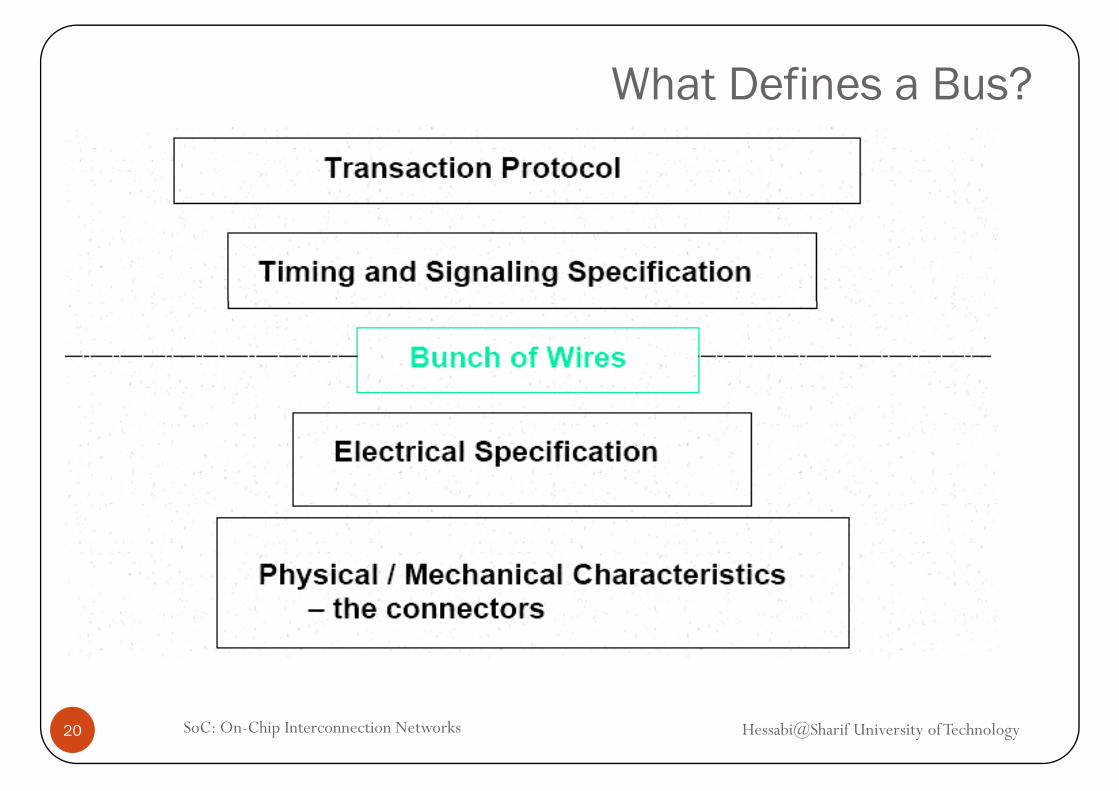
What Defines a Bus?
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks20

Bus ProtocolsProtocols determine:
The transactions that are supported.
The timing of their cycles.
How modules are addressed.
Allocation of resourcesAllocation of resources.
Without a special bus protocol the bus is not efficiently used.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks21

Bus PipeliningA memory access consists of several cycles (including arbitration).
Bus not used in all cycles pipelining used to increase the performance.us ot use a cyc es p pe g use to c ease t e pe o a ce.
Only one transaction canReceive the grant during a given cycle.
Use the bus during a given cycle.
Pipelining leads to an efficient use of the bus.
Stalls are inserted since only one instance can use the bus.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks22
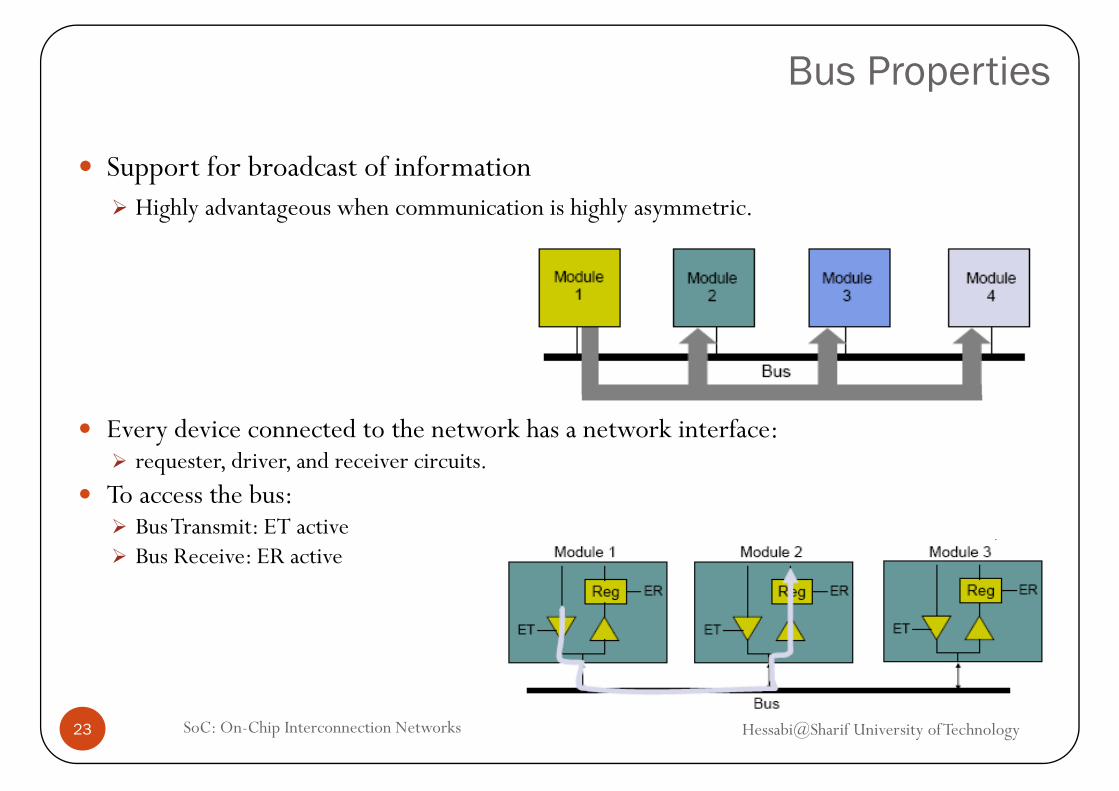
Bus Properties
Support for broadcast of informationHighly advantageous when communication is highly asymmetricHighly advantageous when communication is highly asymmetric.
Every device connected to the network has a network interface:requester, driver, and receiver circuits.
T th bTo access the bus:Bus Transmit: ET activeBus Receive: ER active
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks23

Cycles, Messages and TransactionsMessage: Logical unit of information
A read message contains an address and control signals for read.
Three classes of information units on a bus: data, address, and control.Either time-multiplexed on the bus, or travel over dedicated busses/wires.
Tradeoff between hardware cost (area) and performanceTradeoff between hardware cost (area) and performance.
Cycles: A message requires a number of cycles to be sent from sender to receiver over the bus.
Transaction: A sequence of messages which together form a transaction.A memory read requires a memory read message and a reply with the requested data.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks24

Bus Options
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks25

Increasing the Bus BandwidthSeparate versus multiplexed address and data lines:
Address and data can be transmitted in one cycle with separate address and data lines.
Cost: (a) more bus lines, (b) increased complexity.
Data bus width:By increasing the bus width, transfers of multiple words require fewer bus cycles.
Example: SPARCstation 20’s memory bus is 128 bit wide.
Cost: more bus lines.
Block transfers:Allow the bus to transfer multiple words in back-to-back bus cycles.
Only one address needs to be sent at the beginning.
The bus is not released until the last word is transferred.
Cost:Cost:Increased complexity.
Decreased response time for request.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks26

Increasing Transaction Rate on Multi-master BusOverlapped arbitration.
Perform arbitration for next transaction during current transaction.
Bus parking.Master holds onto bus and performs multiple transactions as long as no other master makes
trequest.
Overlapped address / data phases.
Split phase (or packet switched) busSplit-phase (or packet switched) bus.Completely separate address and data phases.
Arbitrate separately for each.
Address phase yield a tag which is matched with data phase.
All of the above in most modern memory busses.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks27

Synchronous vs. Asynchronous OperationSynchronous bus: includes a common clock in the control lines.
Examples: AMBA bus, PC busses (PCI, ISA, etc), Sun P/M, SCSI, …
A fixed protocol for communication that is relative to the clock.Advantage: involves very little logic and can run very fast.Disadvantages:Disadvantages:
Every device on the bus must run at the same clock rate.To avoid clock skew, they cannot be long if they are fast.
A h b l k d b i h d h ki lAsynchronous bus: not clocked, but requires a handshaking protocol.Examples: MicroChannel (IBM), SCSI 2, VME, MARBLE (AMULET), …Custom designed bussesCan accommodate a wide range of devices.Can be lengthened without worrying about clock skew.
Current commercial on-chip busses are synchronous.p yBus clock is slower than the clock of fast masters.
Simplicity and ease of testing/debugging is prioritized over performance.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks28

Routing, Arbitration, SwitchingRouting
Which of the possible paths are allowable (valid) for packets?Provides the set of operations needed to compute a valid path.Executed at source, intermediate, or even at destination nodes.
Arbitrationt at oWhen are paths available for packets? (along with flow control)Resolves packets requesting the same resources at the same time. For every arbitration there is a winner and possibly many losersFor every arbitration, there is a winner and possibly many losers.Losers are buffered (lossless) or dropped on overflow (lossy).
Lossy networks: Packets are dropped (discarded) at receiver when buffers fill up. Sender is notified to retransmit packets (via time out or NACK)retransmit packets (via time-out or NACK).
SwitchingHow are paths allocated to packets?The winning packet (from arbitration) proceeds towards destination.Paths can be established one fragment at a time or in their entirety.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks29
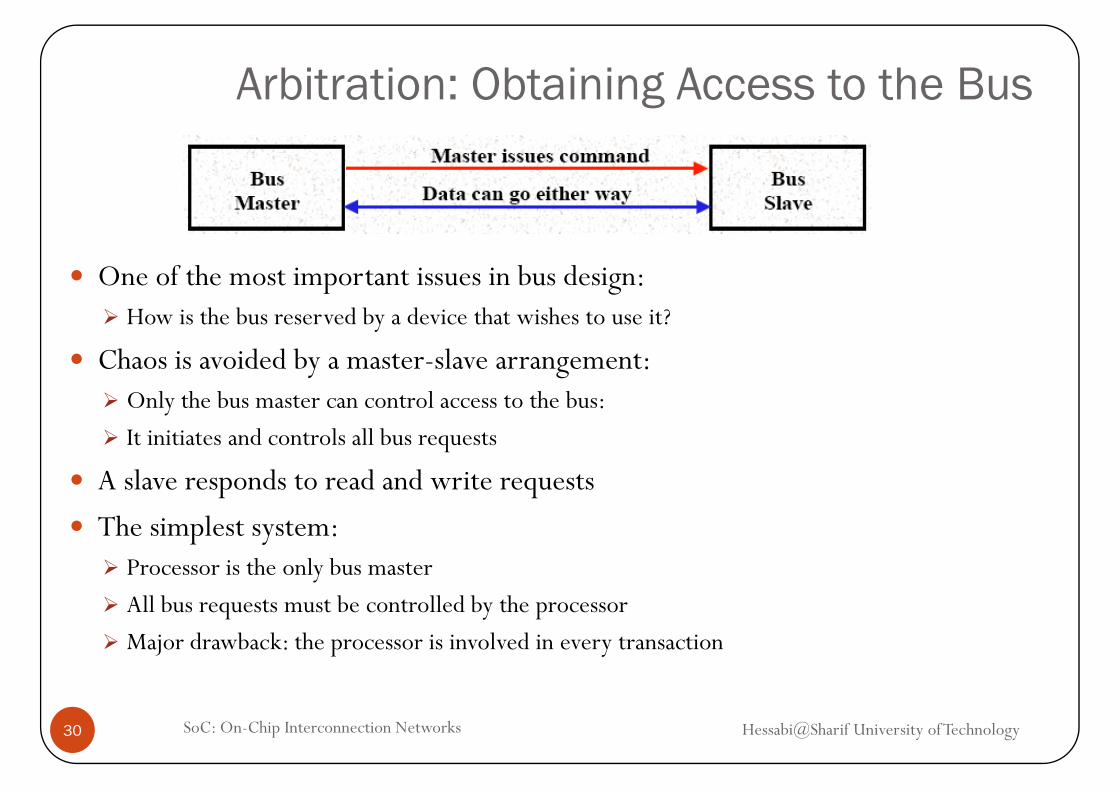
Arbitration: Obtaining Access to the Bus
One of the most important issues in bus design:How is the bus reserved by a device that wishes to use it?
Chaos is avoided by a master-slave arrangement:O l th b t t l t th bOnly the bus master can control access to the bus:
It initiates and controls all bus requests
A slave responds to read and write requestsp q
The simplest system:Processor is the only bus master
All bus requests must be controlled by the processor
Major drawback: the processor is involved in every transaction
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks30

Multiple Bus Masters: Need for ArbitrationBus arbitration scheme:
A bus master wanting to use the bus asserts the bus request.A bus master cannot use the bus until its request is grantedA bus master cannot use the bus until its request is granted.A bus master must signal to the arbiter the end of the bus utilization.
StarvationArises when packets can never gain access to requested resourcesArises when packets can never gain access to requested resources.Solution: Grant resources to packets with fairness, even if prioritized.
Bus arbitration schemes usually try to balance two factors:Bus priority: the highest priority device should be serviced firstBus priority: the highest priority device should be serviced first.Fairness: even the lowest priority device should never be completely locked out from the bus.
Bus arbitration schemes can be divided into four broad classes:Daisy chain arbitrationDaisy chain arbitration.Centralized, parallel arbitration.Distributed arbitration by self-selection: each device wanting the bus places a code indicating its identity on the bus.yDistributed arbitration by collision detection: each device just “goes for it”. Problems found after the fact. (Ethernet).
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks31
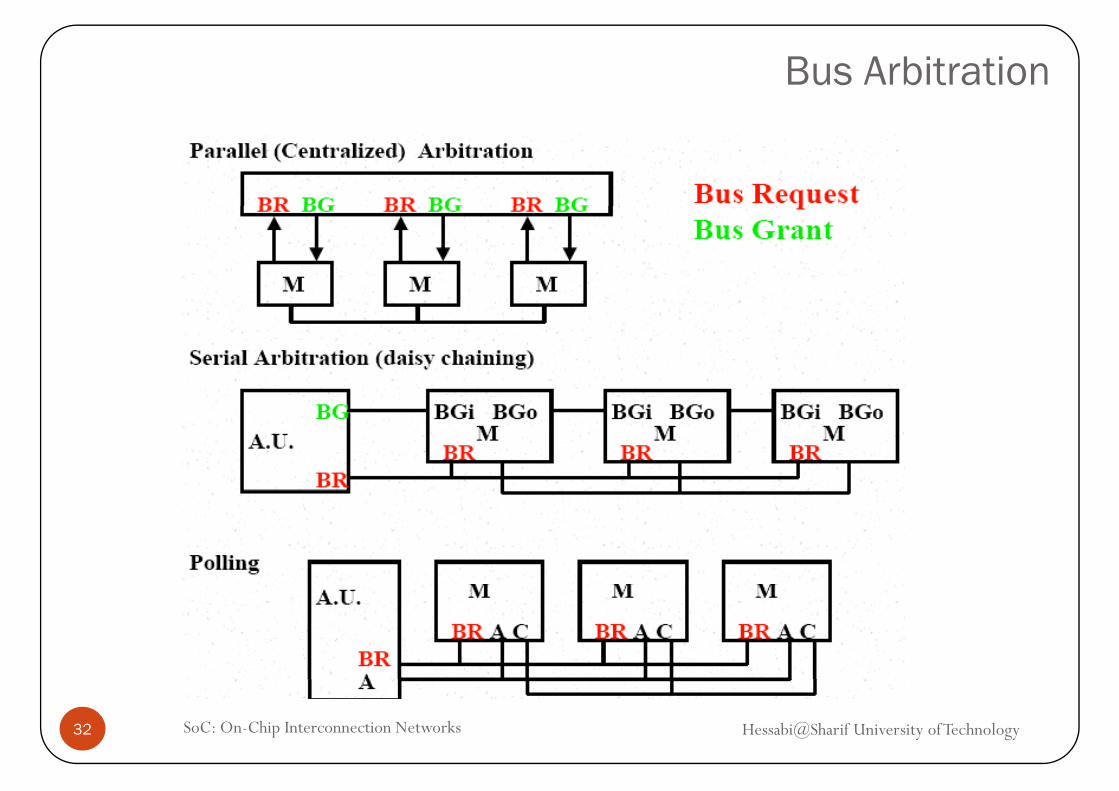
Bus Arbitration
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks32

The Daisy Chain Bus Arbitrations Scheme
Advantage: simpleAdvantage: simple.
Disadvantages:Cannot assure fairness: A low-priority device may be locked out indefinitely.p y y y
The use of the daisy chain grant signal also limits the bus speed.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks33

Centralized Parallel Arbitration
Used in essentially all processor-memory busses and in high-speed I/O busses.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks34

Arbitration MechanismsCurrently performed centralized by a bus arbiter module.
Processor must first gain bus mastership from the arbiter.g pImplies a control transaction and communication performance loss.
Arbitration should be as fast, and as rare, as possible.
Al f l b l f lAlso, response time of slow bus slaves may cause serious performance losses.Because bus remains idle while the master waits for the slave to respond.
Arbiters are not only used in bus-system, but everywhere where several devices y y , yrequest shared resources.
In NoCs, arbitration is needed, if two or more packets want to enter the same channel
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks35

Arbiter InterfacesArbiter interface can be used to give a bus grant for:
a fixed number of cycles;
variable lengths.Grant is hold as long as the “hold”-line (controlled by client) is asserted.
F i i k t f bitFairness is a key property of an arbiter:Weak fairness: Every request is eventually served.
Strong fairness: Requests will be served equally often.g q q y
Weighted strong fairness: # of times requester i is served is equal to its weight wi
FIFO fairness: Requests are served in the order the requests have been made.
l l b l f h l f b b fLocal vs. global fairness: a system with several fir arbiters may not be fair:
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks36

Fixed-Priority ArbiterA fixed-priority arbiter can be constructed as an iterative circuit
Each cell receives a request input ri and a carry input ci and generates a grant output gi and a carry output ci+1
The resulting arbiter is not fair, since a continuously asserted t th t f th th t ill b request r0 means that none of the other requests will ever be
served!
Fair arbiter can be generated by changing the priority from cycle Fair arbiter can be generated by changing the priority from cycle to cycle.
Only one input pi has the value 1. Other inputs pj have value 0.y p pi p pj
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks37
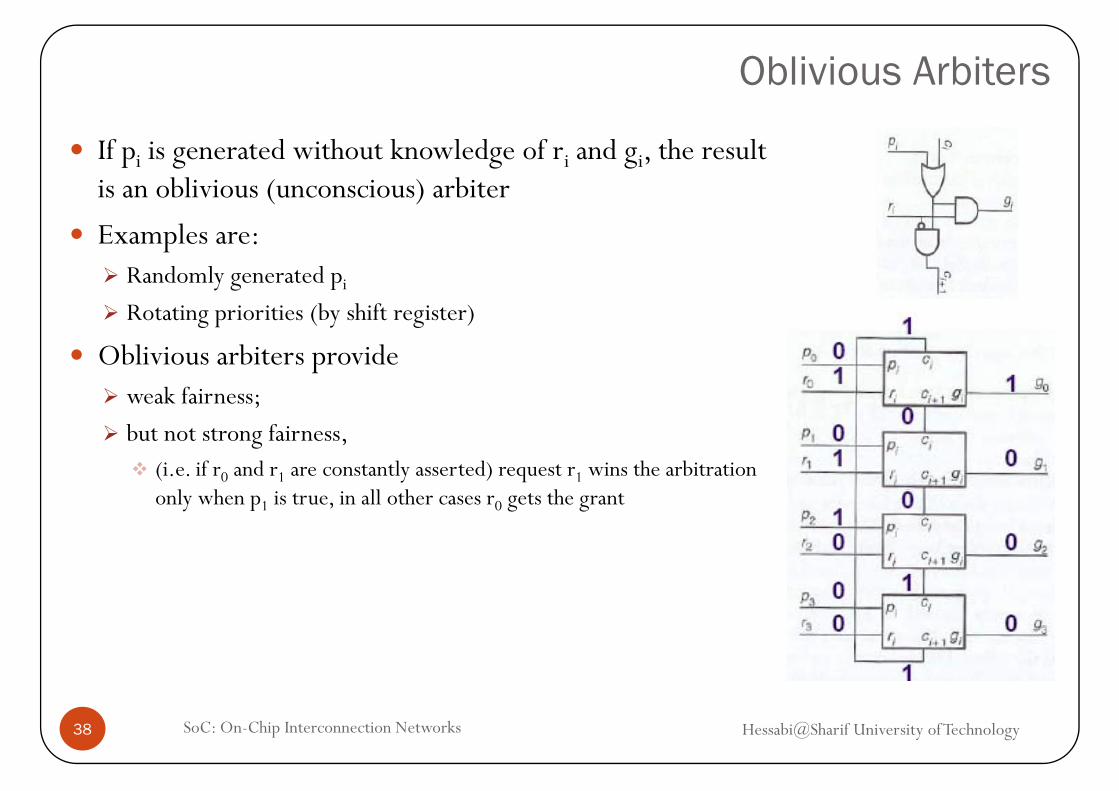
Oblivious Arbiters
If pi is generated without knowledge of ri and gi, the result is an oblivious (unconscious) arbiter
Examples are:Randomly generated pi
Rotating priorities (by shift register)
Oblivious arbiters provideweak fairness;weak fairness;
but not strong fairness,(i.e. if r0 and r1 are constantly asserted) request r1 wins the arbitration
l h ll h h only when p1 is true, in all other cases r0 gets the grant
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks38

Round-Robin ArbiterA round-robin arbiter achieves strong fairness.
A request that was just served gets the lowest priority.q j g p y
A weighted round-robin arbiter allows to give requesters a larger number of grants than other requesters in a controlled fashion.
If three devices have the weight 1,2,3 they get 1/6, 1/3 and ½ of the grants.
The preset line is activated periodically after N (here 6) cycles to load the counter with its weight.
If some modules do not issue any requests during that interval, the shared ill i idl il h lresource will remain idle until the next preset cycle.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks39

Matrix ArbiterA matrix arbiter implements a least recently served priority scheme by maintaining a triangular array of state bits wij for all i < j.g y j
Fast, easy to implement, and provides strong fairness.Hence, very good suited for a small number of inputs.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks40

Queuing ArbiterA queuing arbiter provides FIFO fairness.
It assigns each request a time stamp when it is asserted.g q p
The request with the earliest time stamp receives the grant.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks41

Split-Transaction BusIn a split-transaction bus a transaction is split into two transactions.
”request”-transaction
”reply”-transaction
Both transactions have to compete for the bus by arbitration.
The advantages of the split-transaction bus are evident, if there is a variable delay for requests.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks42

Terms and DefinitionsBandwidth (BW): Maximum rate (bps or Bps) at which information can be transferred (including packet header, payload, trailer)
Aggregate BW:Total data bandwidth supplied by networkEffective BW(throughput): fraction of aggregate bandwidth delivered to application
Time of flight: Time for first bit of a packet to arrive at the receiverTime of flight: Time for first bit of a packet to arrive at the receiverIncludes the time for a packet to pass through the network, not including the transmission time
Transmission time: The time for a packet to pass through the network, not i l di h i f fli hincluding the time of flight
Equal to the packet size divided by the data bandwidth of the link
Transport latency:Time of flight + transmission timeTransport latency:Time of flight transmission timeMeasures the time that a packet spends in the network
Sending overhead (latency): Time to prepare a packet for injection, including hardware/software
A constant term (packet size) plus a variable term (buffer copies)
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks43
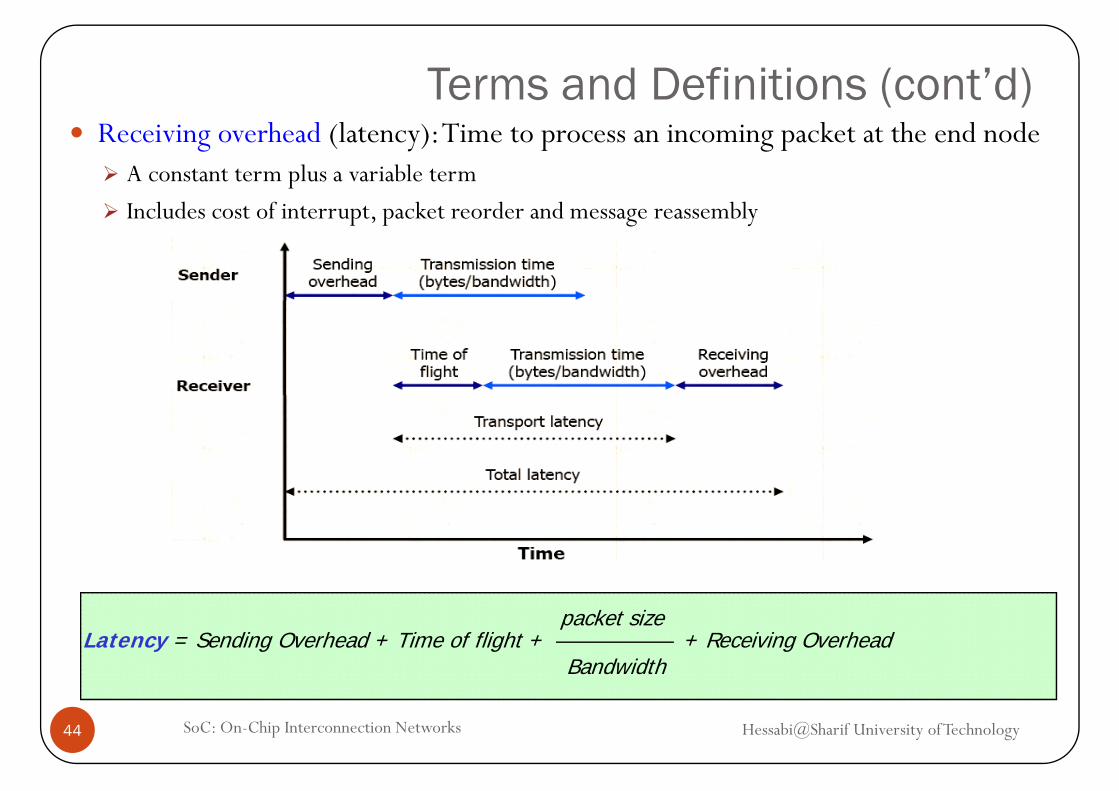
Terms and Definitions (cont’d)Receiving overhead (latency): Time to process an incoming packet at the end node
A constant term plus a variable term
I l d t f i t t k t d d blIncludes cost of interrupt, packet reorder and message reassembly
Latency = Sending Overhead + Time of flight + + Receiving Overheadpacket size
Bandwidth
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks44

Terms and Definitions (cont’d)Effective bandwidth with link pipelining
Pipeline the flight and transmission of packets over the links
Overlap the sending overhead with the transport latency and receiving overhead of prior packets
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks45
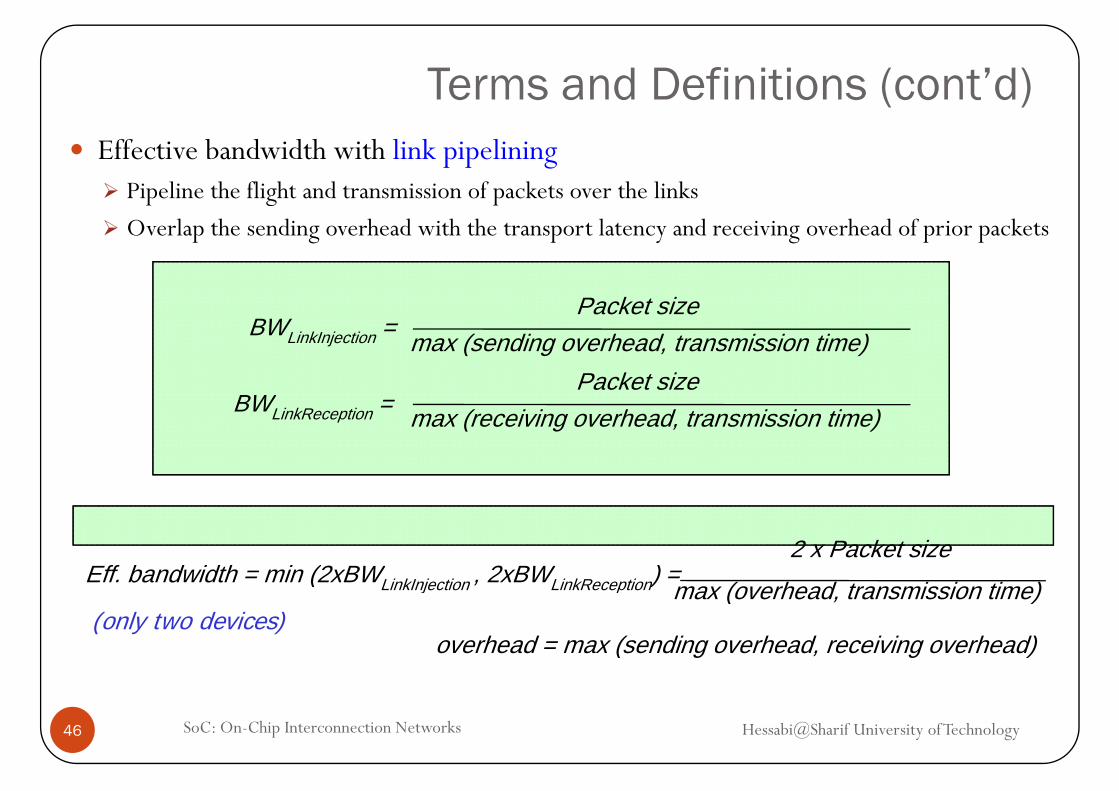
Terms and Definitions (cont’d)Effective bandwidth with link pipelining
Pipeline the flight and transmission of packets over the links
Overlap the sending overhead with the transport latency and receiving overhead of prior packets
P k t iBWLinkInjection =
Packet sizemax (sending overhead, transmission time)
BWPacket size
BWLinkReception = max (receiving overhead, transmission time)
Eff. bandwidth = min (2xBWLinkInjection , 2xBWLinkReception) = 2 x Packet size
( h d t i i ti )( LinkInjection , LinkReception) max (overhead, transmission time)
overhead = max (sending overhead, receiving overhead)(only two devices)
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks46

Shared-Medium Networks SummaryThe network media is shared by all the devices.
ArbitrationCentralized arbiter for smaller distances between devices
Dedicated control lines
D b d f f bDistributed forms of arbitersCSMA/CD: Carrier Sense Multiple Access with Collision Detection
The device first checks the network (carrier sensing)
Then checks if the data sent was garbled (collision detection)
If collision retransmission: wait an increasing exponential random amount of time beforehand
Fairness is not guaranteedg
Token ring—provides fairness
Owning the token provides permission to use network media
Node Node Nodetokenholder X
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks47

Shared-Medium Networks Summary (cont’d)Switching is straightforward: the granted device connects to the shared media
Routing: routing is straightforwardg g gPerformed at all the potential destinations
Each end node device checks whether it is the target of the packet
B d d l lBroadcast and multicast is easy to implementEvery end node devices sees the data sent on shared link anyway
Established order: arbitration, switching, and then routing, g, g
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks48

Shared-Medium Networks Summary (cont’d)Advantages:
Simple topology,
Low area cost,
Easy to build, Efficient to implement.
Di dDisadvantages:Larger load per data bus line,
Longer delay for data transfer,g y ,
Larger energy consumption,Since every data transfer is broadcast.
L b d idthLower bandwidth,Cannot be solved by using a low-voltage swing signaling technique.
Scalability is seriously limited.Convenient for current SoCs that integrate less than 5 processors and rarely more than 10 bus masters.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks49

On-Chip Interconnection Networks
Shared Medium NetworksShared-Medium Networks
Switched-media Networks (Direct and Indirect Networks)
Hybrid Networks
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks50
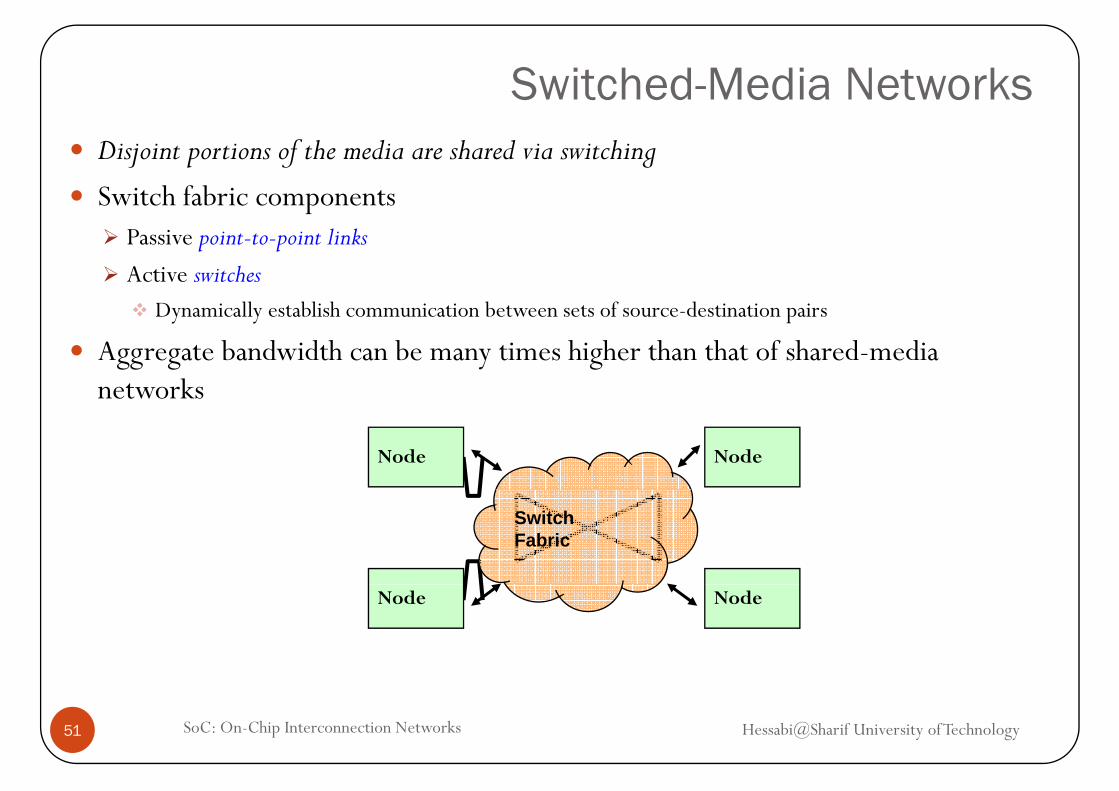
Switched-Media NetworksDisjoint portions of the media are shared via switching
Switch fabric componentspPassive point-to-point links
Active switchesDynamically establish communication between sets of source-destination pairs
Aggregate bandwidth can be many times higher than that of shared-media networksnetworks
Node Node
Switch Fabric
Node Node
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks51

Switched-Media Networks (cont’d)Routing
Every time a packet enters the network, it is routed
ArbitrationCentralized or distributed
Resolves conflicts among concurrent requests
SwitchingOnce conflicts are resolved the network “switches in” the required connectionsOnce conflicts are resolved, the network switches in the required connections
Established order: routing, arbitration, and then switching
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks52
Shared- vs. Switched-Media NetworksShared-media networks
Low cost
Aggregate network bandwidth does not scale with number of devices
Global arbitration scheme required (a possible bottleneck)
Time of flight increases with the number of end nodesTime of flight increases with the number of end nodes
Switched-media networksAggregate network bandwidth scales with number of devicesgg g
Concurrent communicationPotentially much higher network effective bandwidth
B i ffi i t d i it iblBeware: inefficient designs are quite possibleSuperlinear network cost but sublinear network effective bandwidth
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks53

Distributed Switched (Direct) NetworksDirect or point-to-point networks: as the number of nodes in the system increases, the total communication bandwidth also increases.
Overcomes the scalability problems.Popular for building large-scale systems.
Each node directly connected with a subset of other nodes in the network (neighboring nodes)Each node directly connected with a subset of other nodes in the network (neighboring nodes).
Nodes are on-chip computational units, contain a network interface block (router), which handles communication-related tasks.
Each router is directly connected with the routers of the neighboring nodes.
More energy efficient than shared medium networks.Since energy per transfer on a point to point communication channel is smaller than that on a Since energy per transfer on a point-to-point communication channel is smaller than that on a large shared-medium architecture.
Should consider the energy for several point-to-point links.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks54

Direct Network Example: RAW architectureA fully (tiles=PEs, interconnects) programmable SoC, consisting of an array of identical Tile 0 Tile 1 Tile 2 Tile 3
Router
RISC
g ycomputational tiles with local storage.
To accomplish programmable communication, each tile has a programmable router (switch processor)
Tile 4 Tile 5 Tile 6 Tile 7
tile has a programmable router (switch processor).
RAW can be viewed as a direct network.
Inside the router: Tile 8 Tile 9 Tile 10 Tile 11
Tile 12 Tile 13 Tile 14 Tile 15
Schedulerselect out
Buf West
requestinWest West
Crossbar outout
in
in
configBuf West
Buf South
Buf East
South
East
North
West
South
East
router μarchitecturein
5 x 5 outinBuf North
Buf Localoutgrant
North
LocalNorth
Local
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks55
router μarchitecture
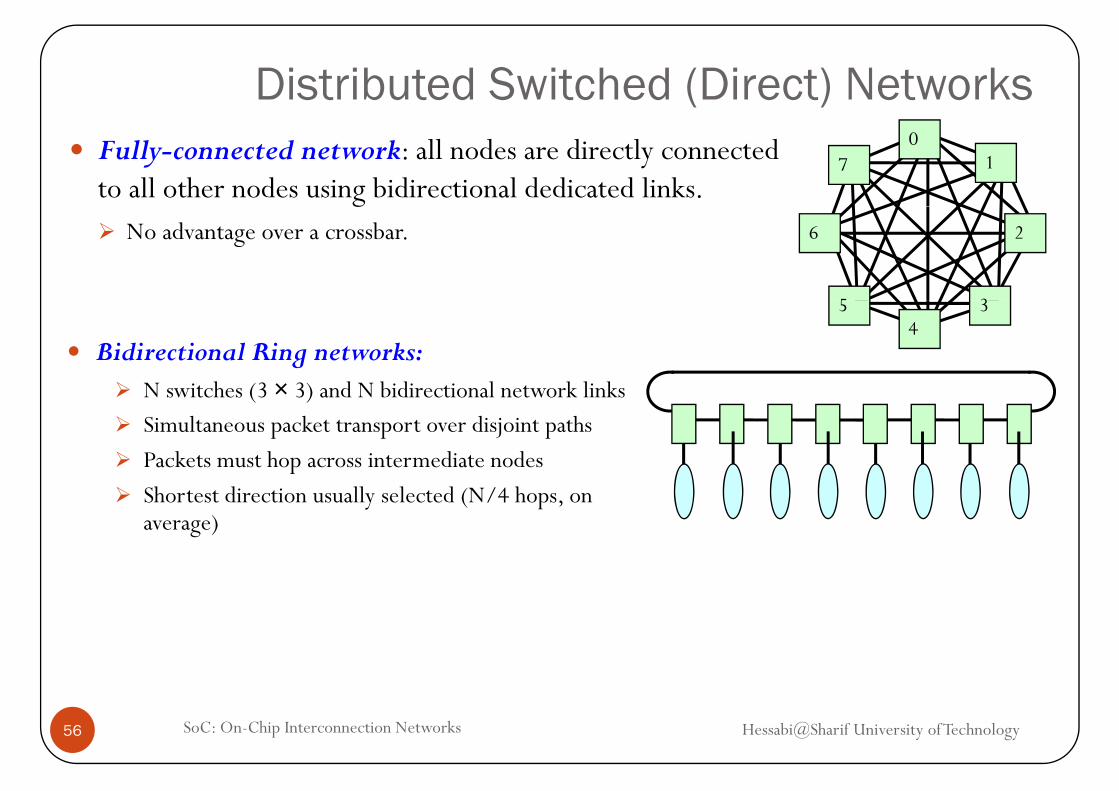
Distributed Switched (Direct) NetworksFully-connected network: all nodes are directly connected to all other nodes using bidirectional dedicated links.
70
1g
No advantage over a crossbar. 6 2
5 34
5 3
Bidirectional Ring networks:N switches (3 × 3) and N bidirectional network linksN switches (3 3) and N bidirectional network linksSimultaneous packet transport over disjoint paths
Packets must hop across intermediate nodes
Sh di i ll l d (N/4 h Shortest direction usually selected (N/4 hops, on average)
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks56
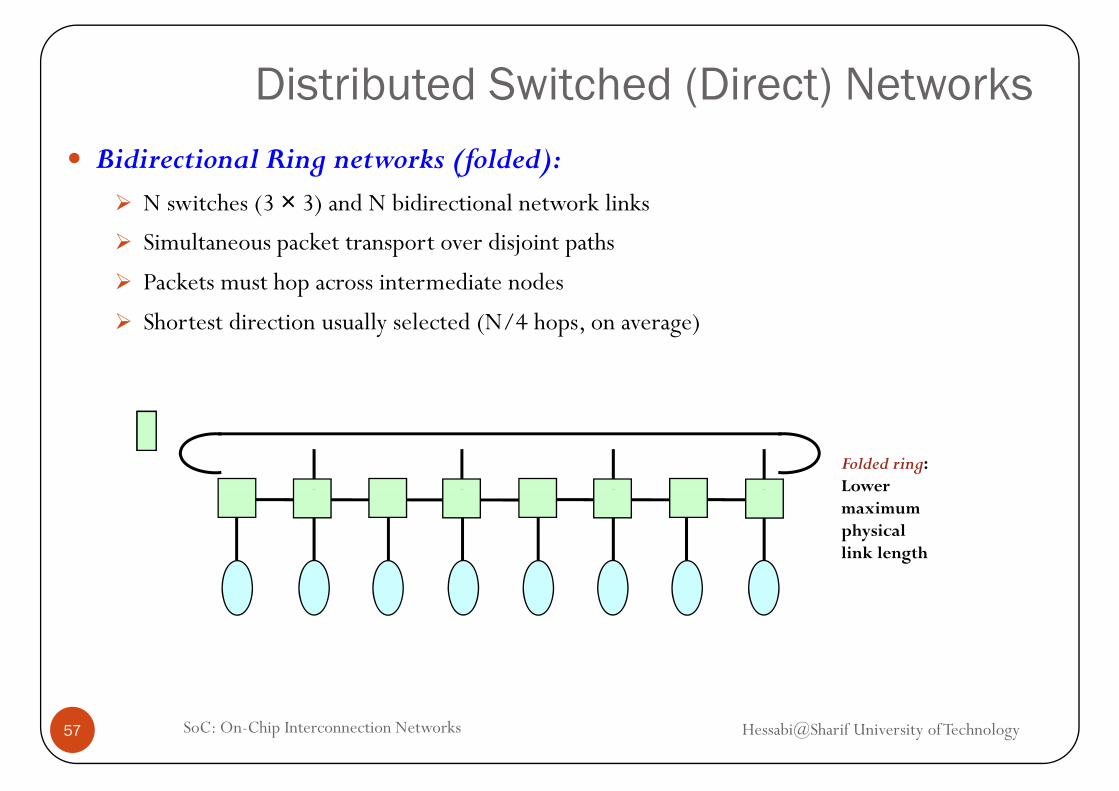
Distributed Switched (Direct) NetworksBidirectional Ring networks (folded):
N switches (3 × 3) and N bidirectional network linksN switches (3 × 3) and N bidirectional network links
Simultaneous packet transport over disjoint paths
Packets must hop across intermediate nodes
Shortest direction usually selected (N/4 hops, on average)
Folded ring:Lower Lower maximum physicallink length
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks57

Distributed Switched (Direct) Networks: Fully connected and ring topologies: the two extremes
The ideal topology:p gyCost approaching a ring
Performance approaching a fully connected (crossbar) topology
More practical topologies:k-ary n-cubes (meshes, torus, hypercubes)
k nodes connected in each dimension with n total dimensionsk nodes connected in each dimension, with n total dimensions
Symmetry and regularity
network implementation is simplified
i i i lifi drouting is simplified
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks58

Centralized Switched (Indirect) NetworksA connection between nodes has to go through a set of switches.
The network adapter associated with each node connects to a port of a switch.
Switches only provide a programmable connection between their ports; i.e., set up a communication path that can be changed over time.
Distinction between direct and indirect networks is blurringDistinction between direct and indirect networks is blurring,Since routers and switches are getting more complex and absorb each other’s functionality.
Reconfigurable micronetworks exploit programmable routers/switches. Use multiplexers whose control signals are set by configuration bits in local storage, as in the case of FPGAs.
Interface circuitry and network control policies must be kept extremely simple for FPGAs,Interface circuitry and network control policies must be kept extremely simple for FPGAs,can be much more complex when supporting coarser grain information transfers.
2 topologies:Crossbar network
Multistage interconnection networks (MINs)
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks59

ExamplesXilinx SpartanII FPGA: CLBs are connected via a hierarchy of routing channels.
Thus each chip has an indirect network over a homogeneous fabric.
Xilinx VirtexII FPGAs: various configurable elements (CLBs, RAMs, multipliers, …).
Programmable interconnection is achieved by routing switches.
VirtexII can be seen as an indirect network over a heterogeneous fabric.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks60

Crossbar NetworkCrosspoint switch complexity increases quadratically with the number of crossbar input/output ports, N, i.e., grows as O(N2)g
Has the property of being non-blocking
0
76543210
0
76543210
2
1
0
2
1
0
5
4
3
5
4
3
7
6
7
6
5
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks61
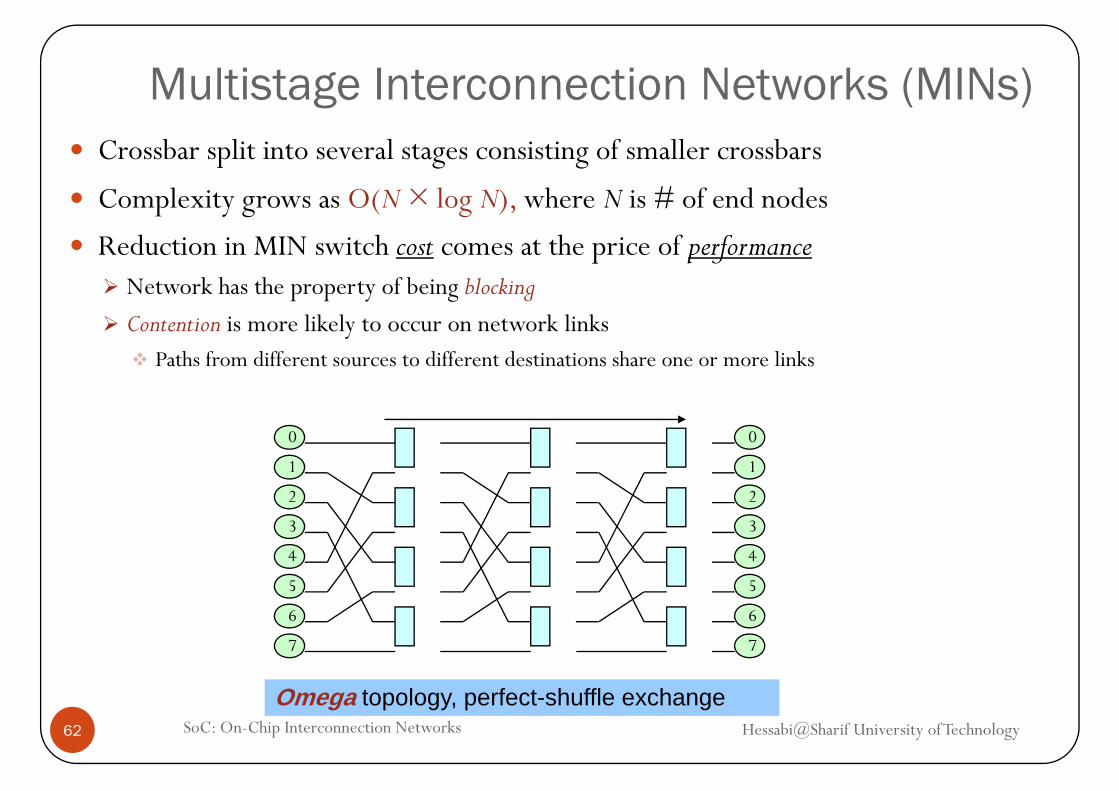
Multistage Interconnection Networks (MINs)Crossbar split into several stages consisting of smaller crossbars
Complexity grows as O(N × log N), where N is # of end nodesComplexity grows as O(N log N), where N is # of end nodes
Reduction in MIN switch cost comes at the price of performanceNetwork has the property of being blockingp p y g g
Contention is more likely to occur on network linksPaths from different sources to different destinations share one or more links
1
0
1
0
5
4
3
2
5
4
3
2
7
6
5
7
6
5
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks62
Omega topology, perfect-shuffle exchange

Blocking
0
76543210
X0 0
3
2
1
3
2
1
3
2
1
6
5
4
3
5
4
5
4
blocking topologynon-blocking topology
7
6
7
6
7
6
How to reduce blocking in MINs? Provide alternative paths!
blocking topologynon blocking topology
Use larger switches (can equate to using more switches)
Use more switches
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks63
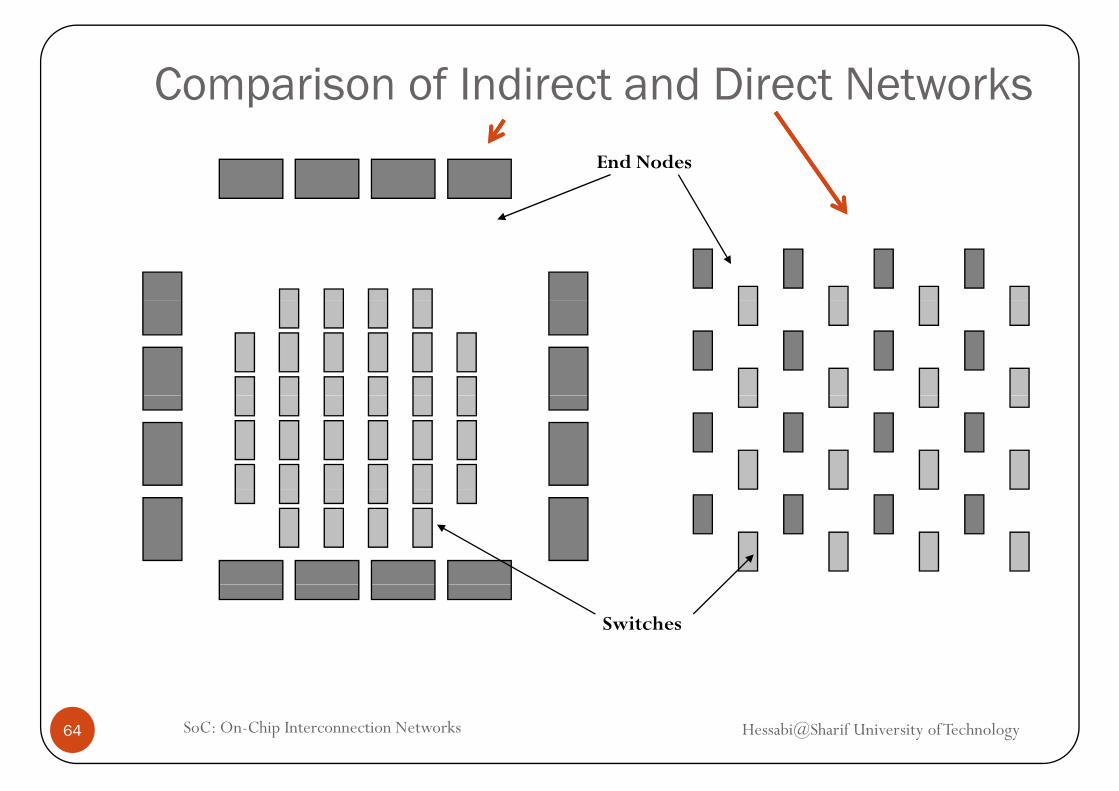
Comparison of Indirect and Direct NetworksEnd Nodes
Switches
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks64

On-Chip Interconnection Networks
Shared-Medium Networks
Switched-media Networks (Direct and Indirect Networks)
Hybrid NetworksHybrid Networks
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks65

Hybrid NetworksAdvantages of homogeneous interconnection architectures:
Facilitate modular design,
Easily scaled up by replication.
Suitable for general-purpose computing
H b l fl ibili d fi i f hi li i However, obstacle to flexibility and fine tuning of architectures to application characteristics.
Systems developed for a particular application can benefit from a more heterogeneous y p p pp gcommunication infrastructure.
Provides high bandwidth in a localized fashion only where it is needed to eliminate bottlenecks.
Hence heterogeneous or hybrid interconnection architecturesHence, heterogeneous, or hybrid interconnection architectures.
Energy efficiency is a strong driver toward hybrid architectures.Examples: multiple-backplane and hierarchical (or bridged) busses.
3 busses in AMBA.
Hessabi@Sharif University of TechnologySoC: On-Chip Interconnection Networks66